Jiachen Li1, MangTik Chiu1, Ali Hassani1, Nikita Orlov3, Humphrey Shi1,3 , 1SHI Labs, 2IIT Roorkee, 3Picsart AI Research (PAIR), CVPR2023 慶應義塾大学 飯岡雄偉 Jain, Jitesh, et al. "Oneformer: One transformer to rule universal image segmentation." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
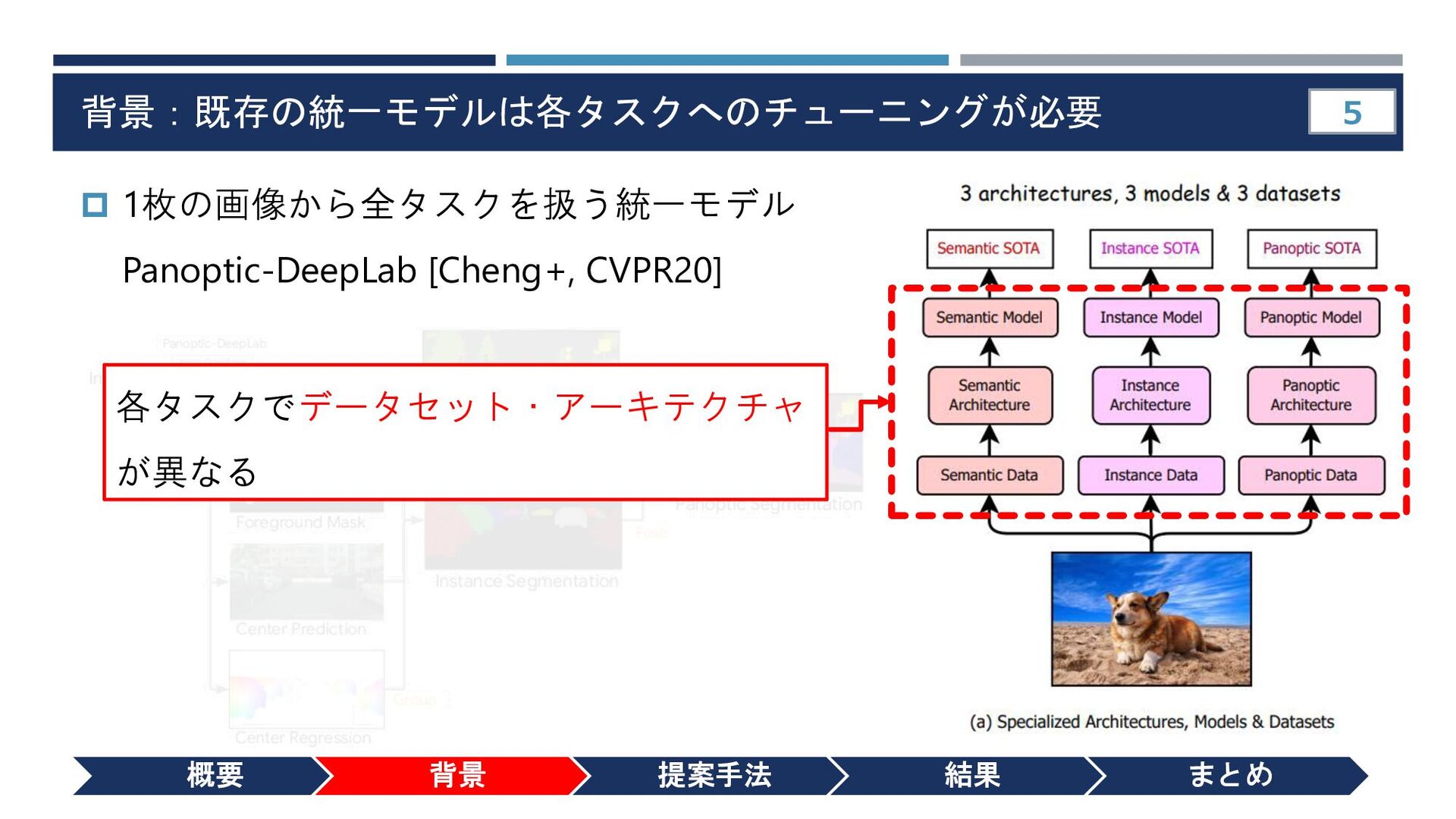{kind=link}
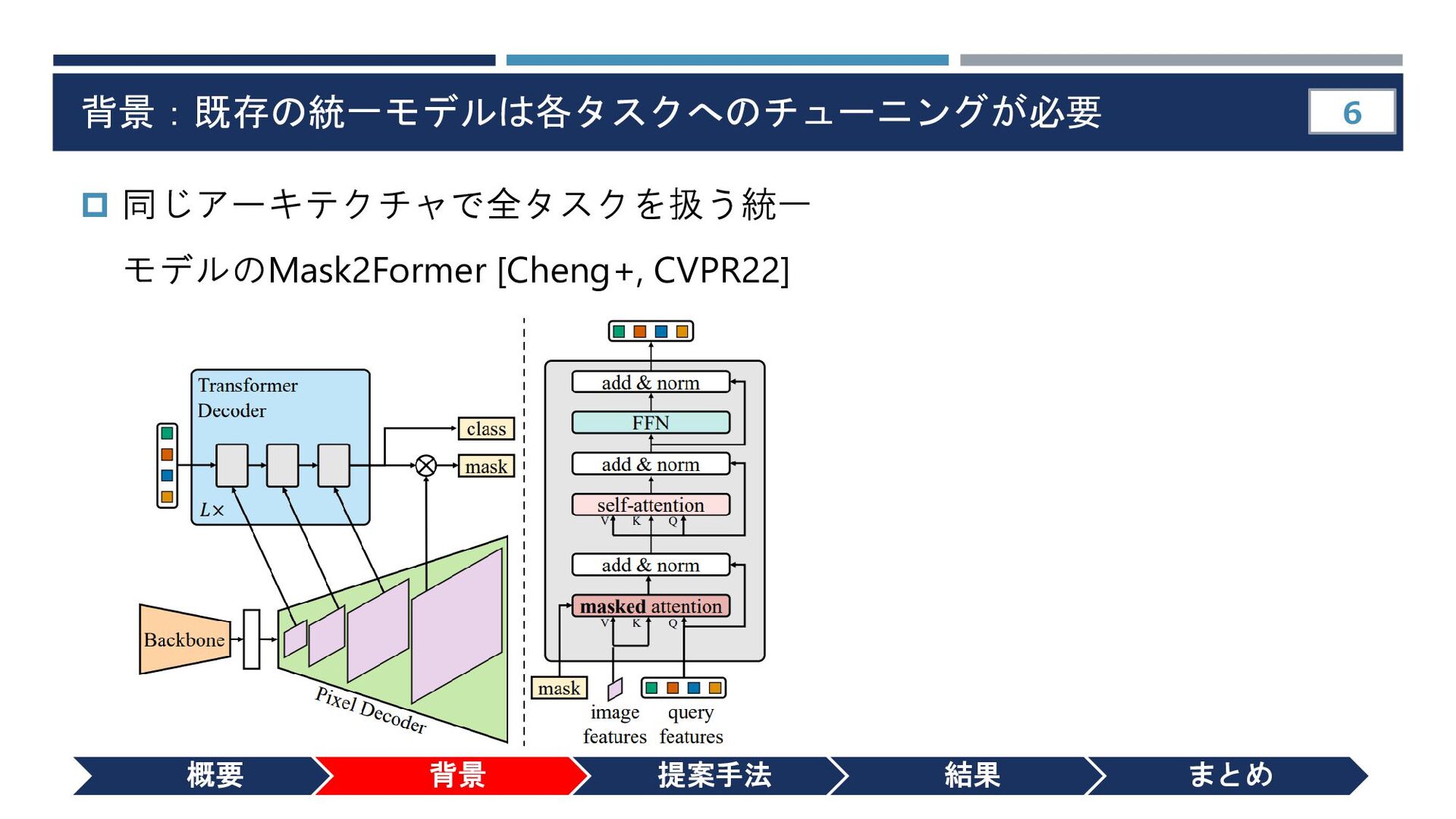{kind=link}
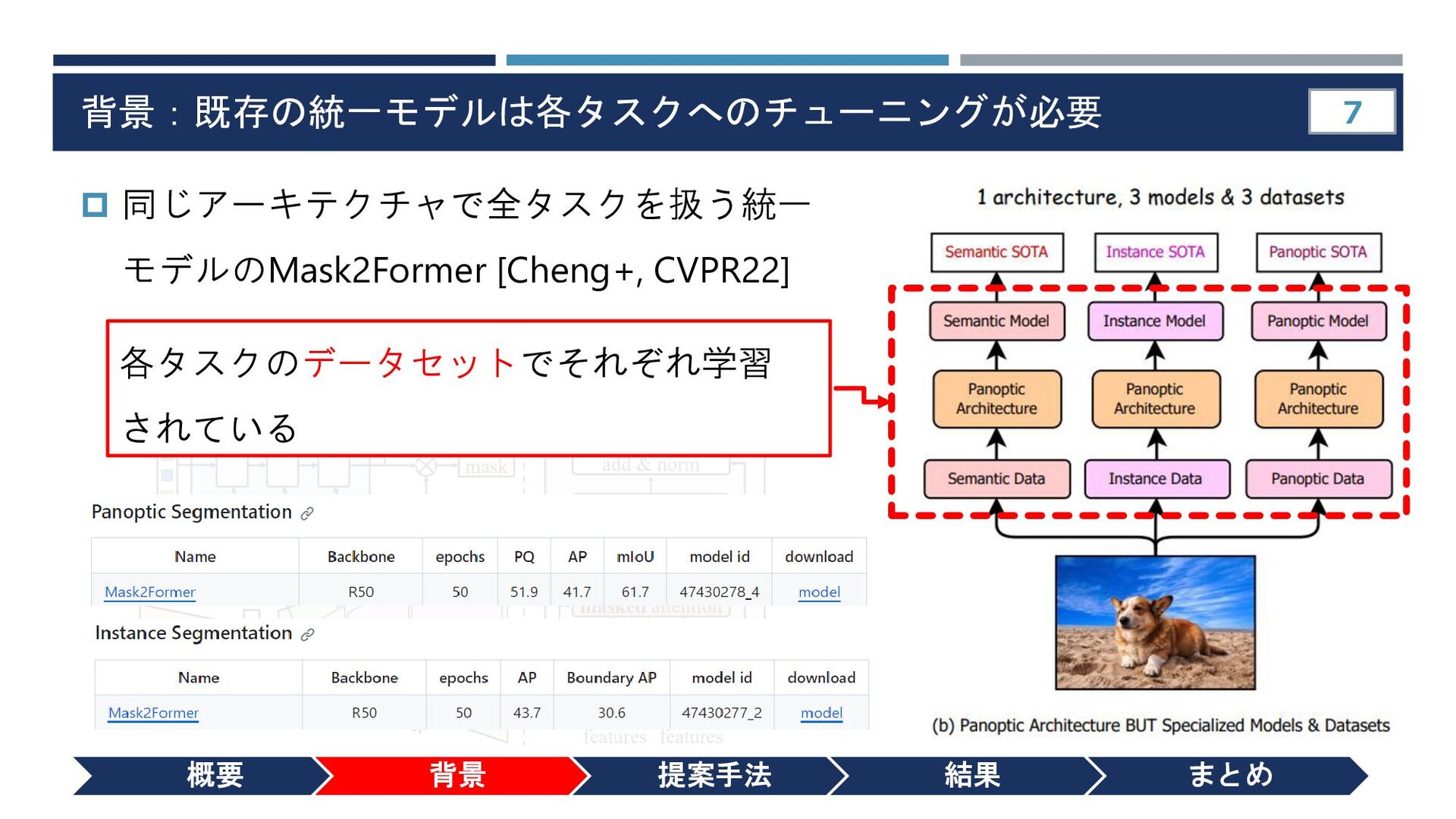{kind=link}
{kind=link}
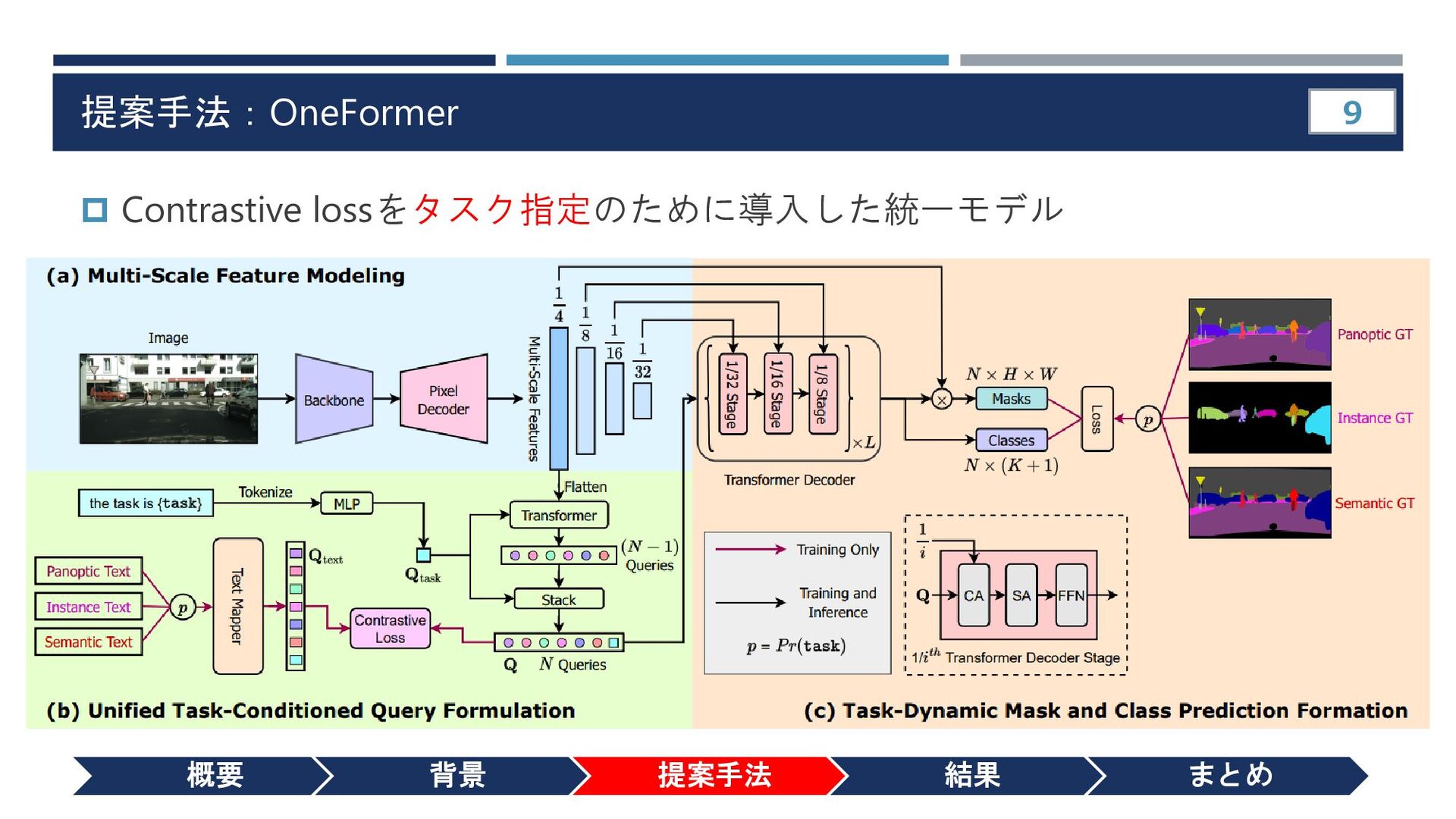{kind=link}
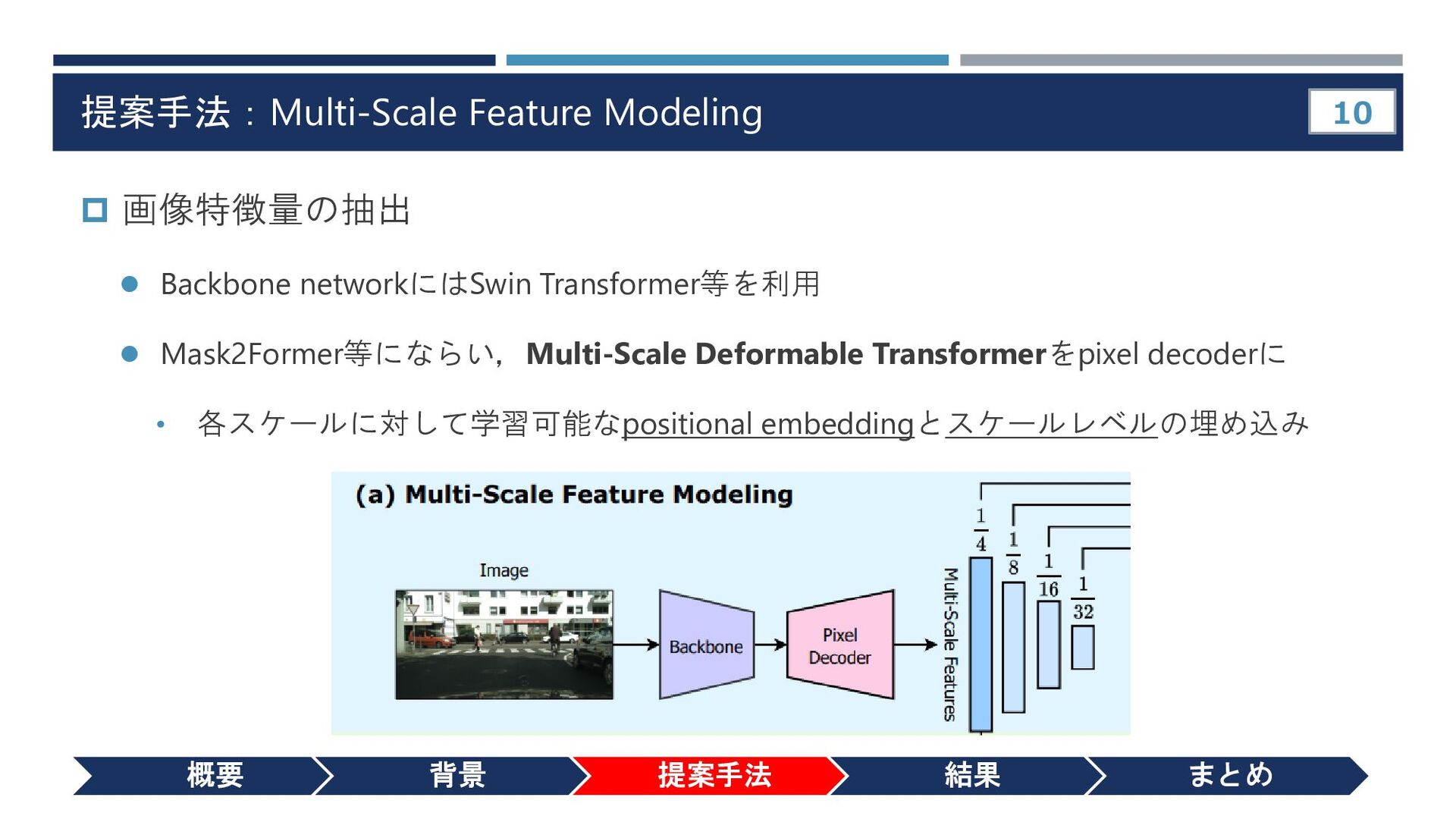{kind=link}
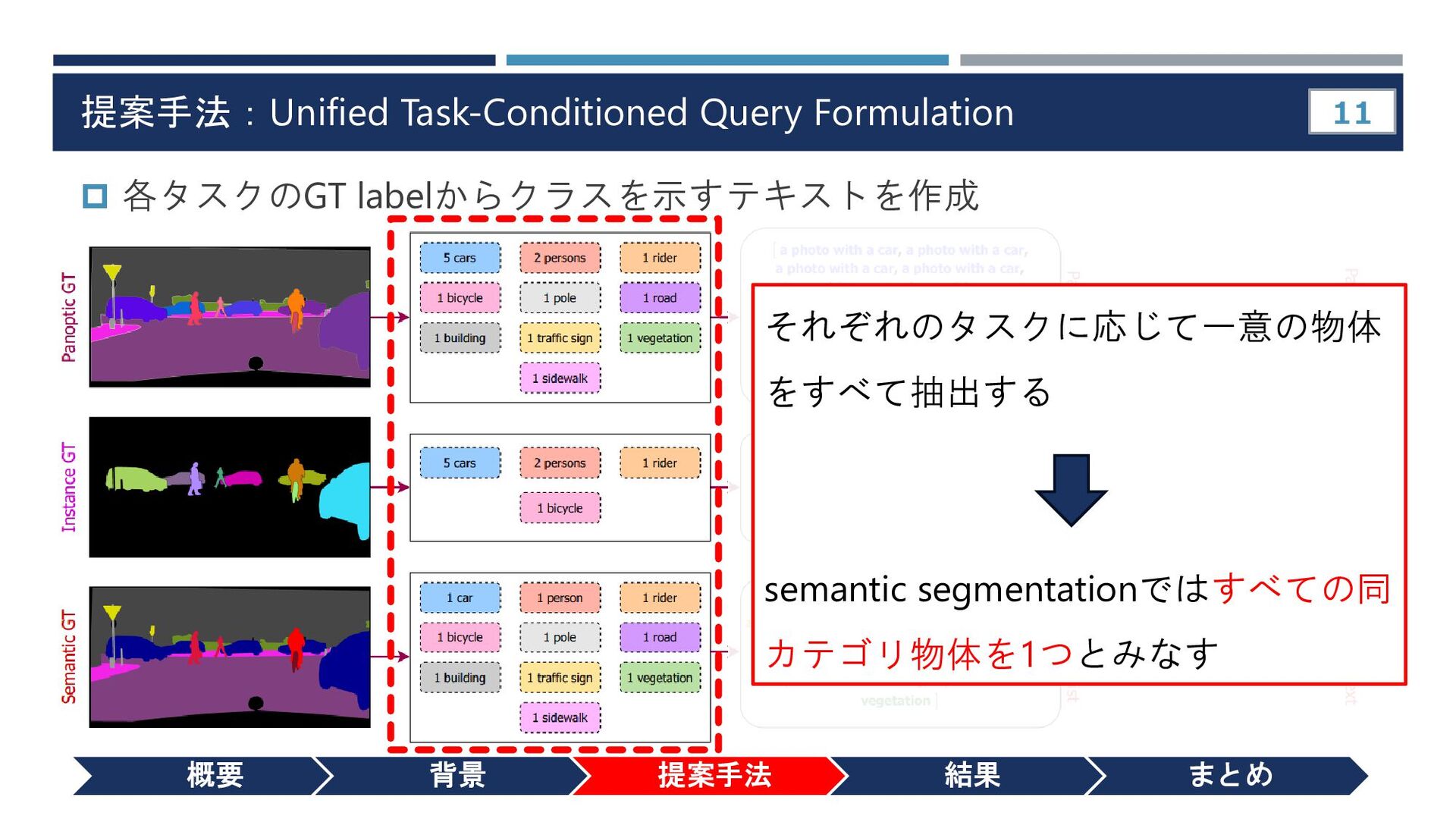{kind=link}
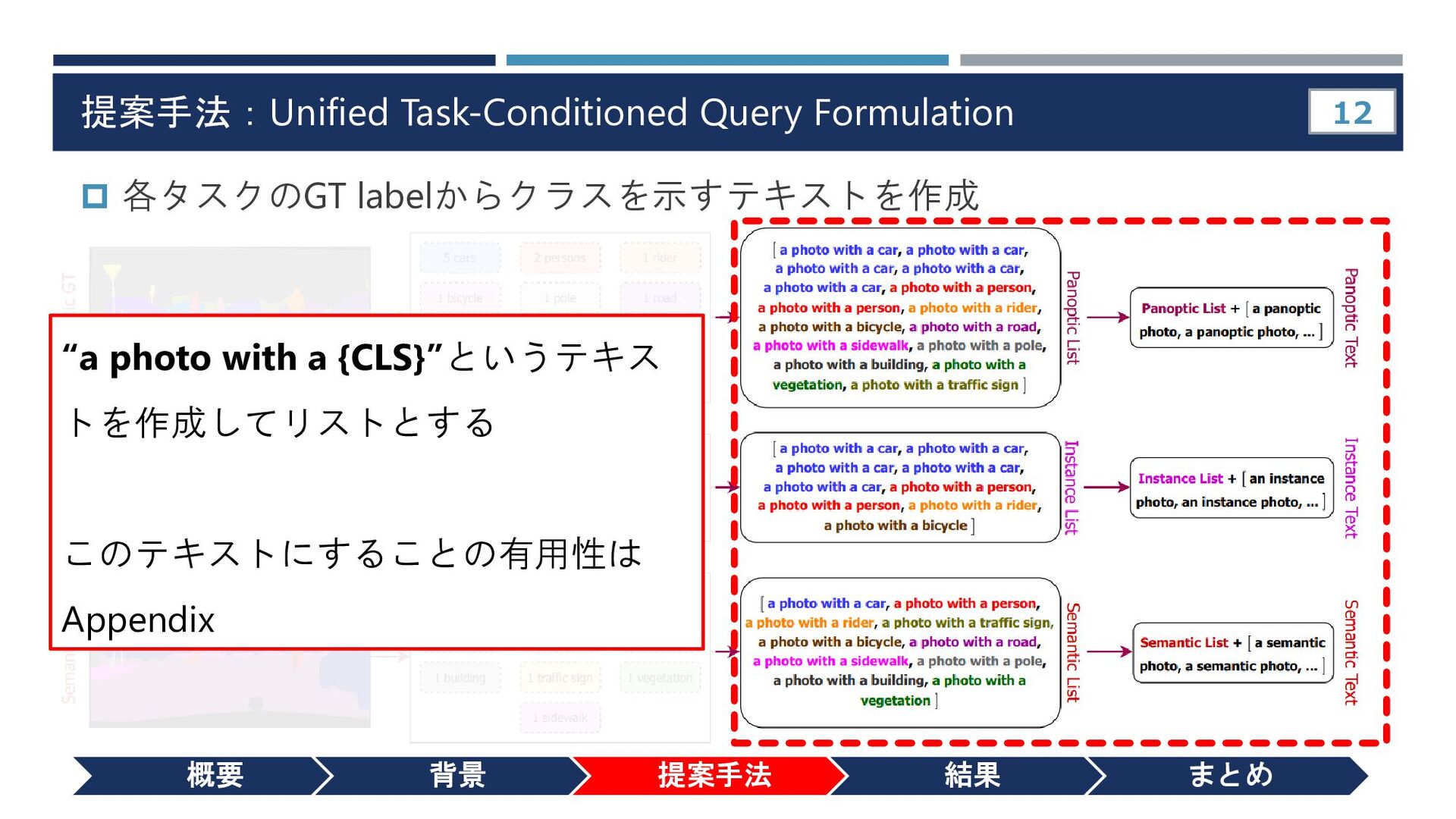{kind=link}
{kind=link}
{kind=link}
{kind=link}
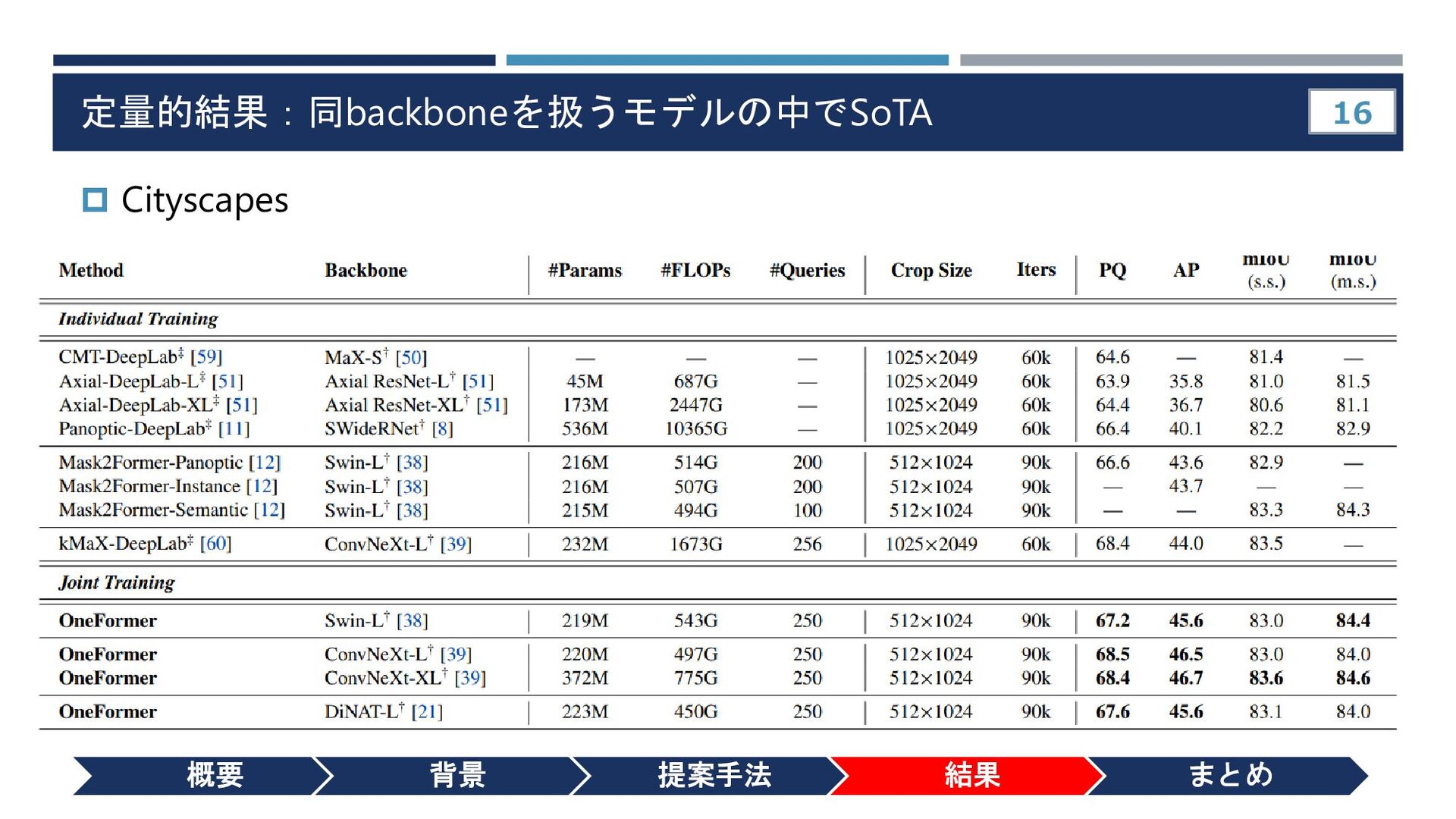{kind=link}
{kind=link}
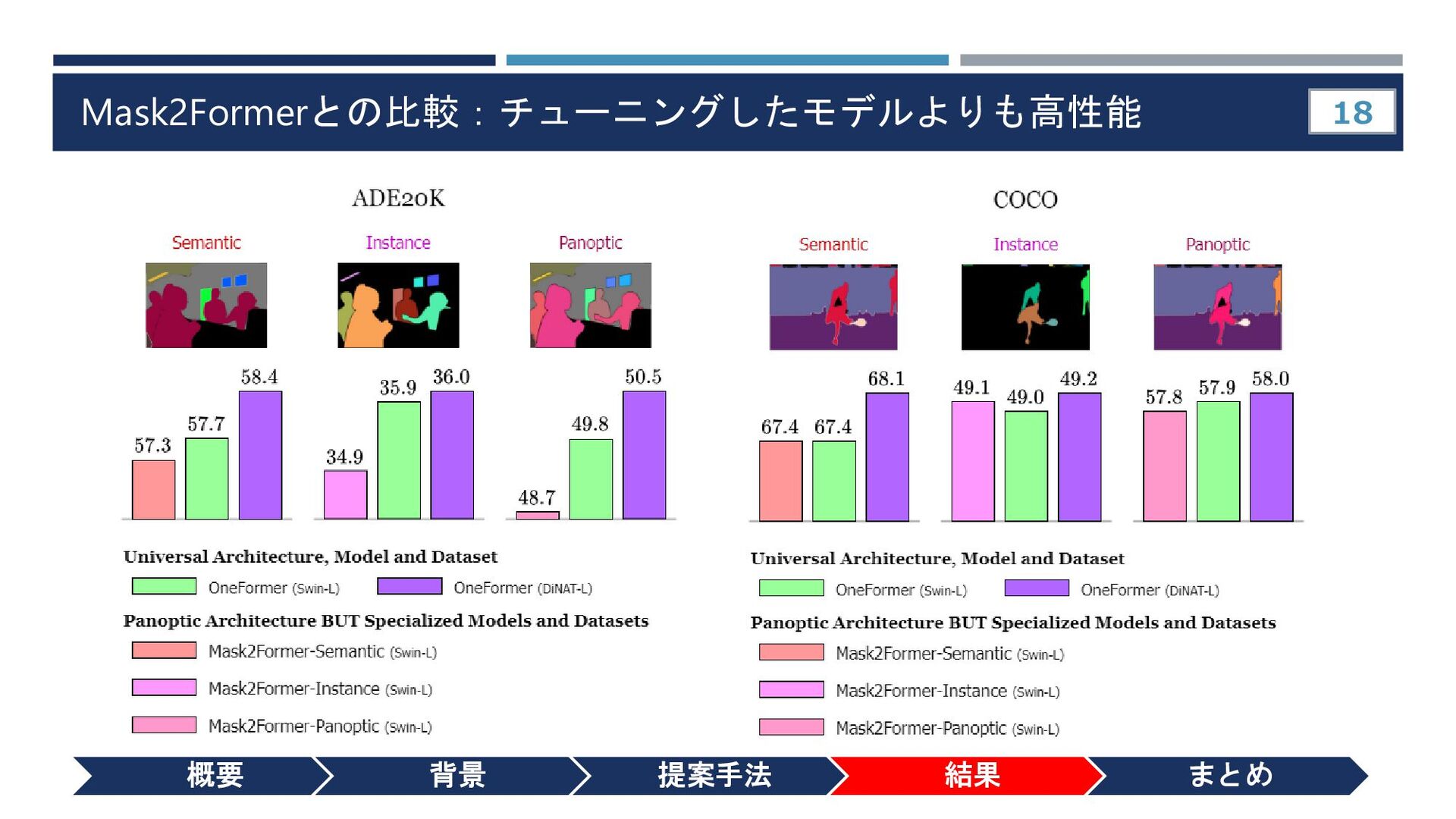{kind=link}
{kind=link}
{kind=link}
{kind=link}
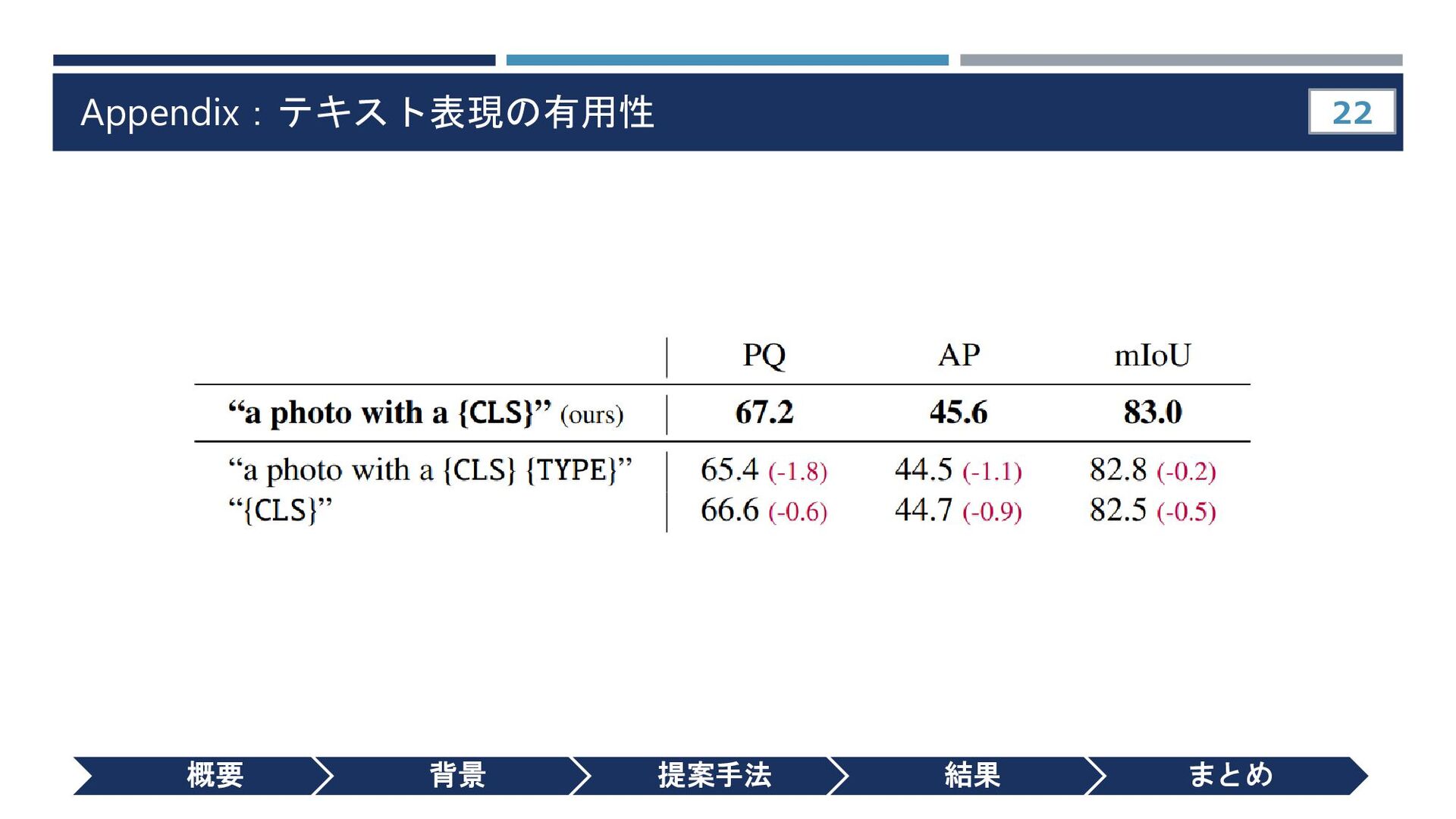{kind=link}
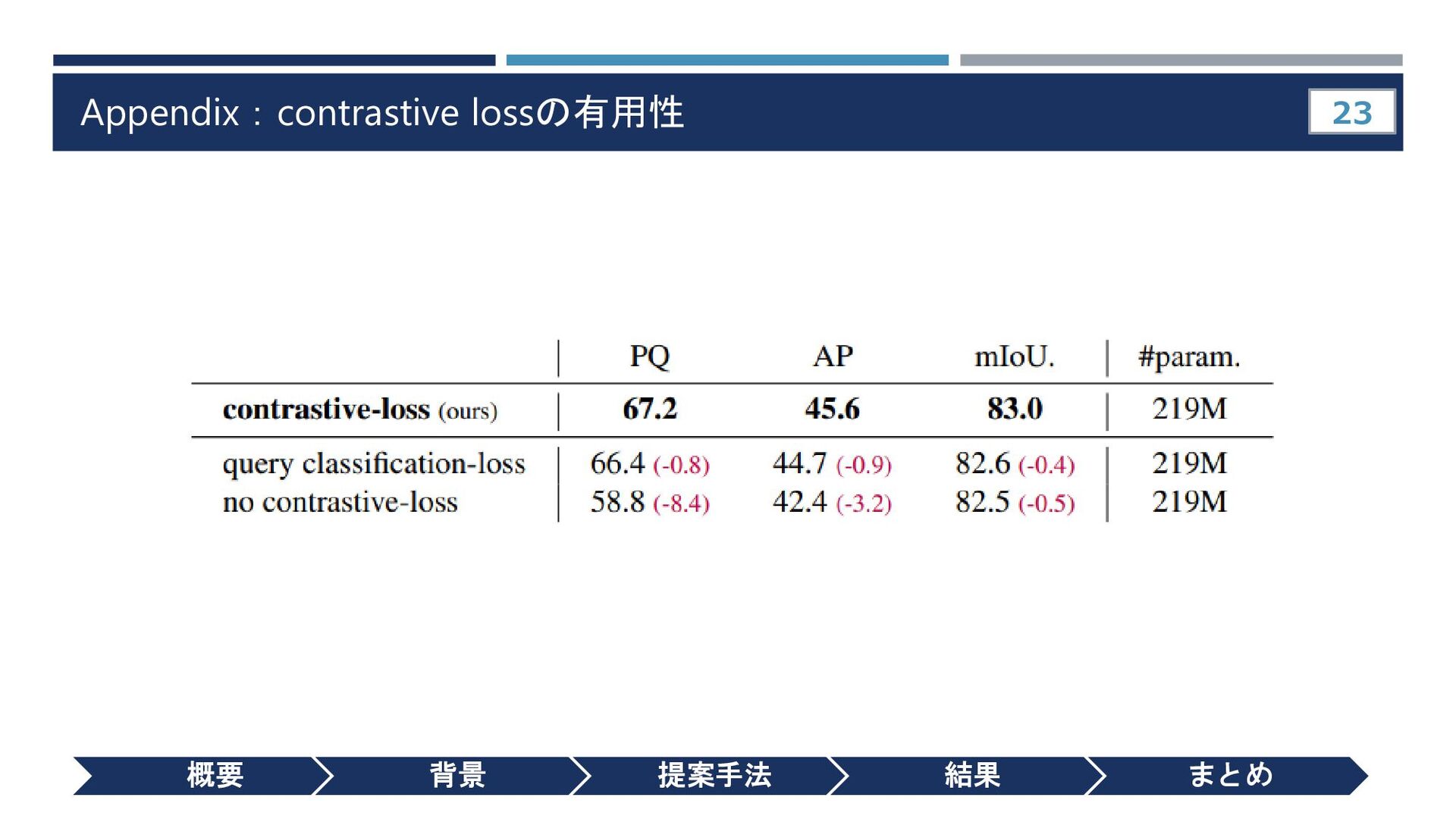{kind=link}
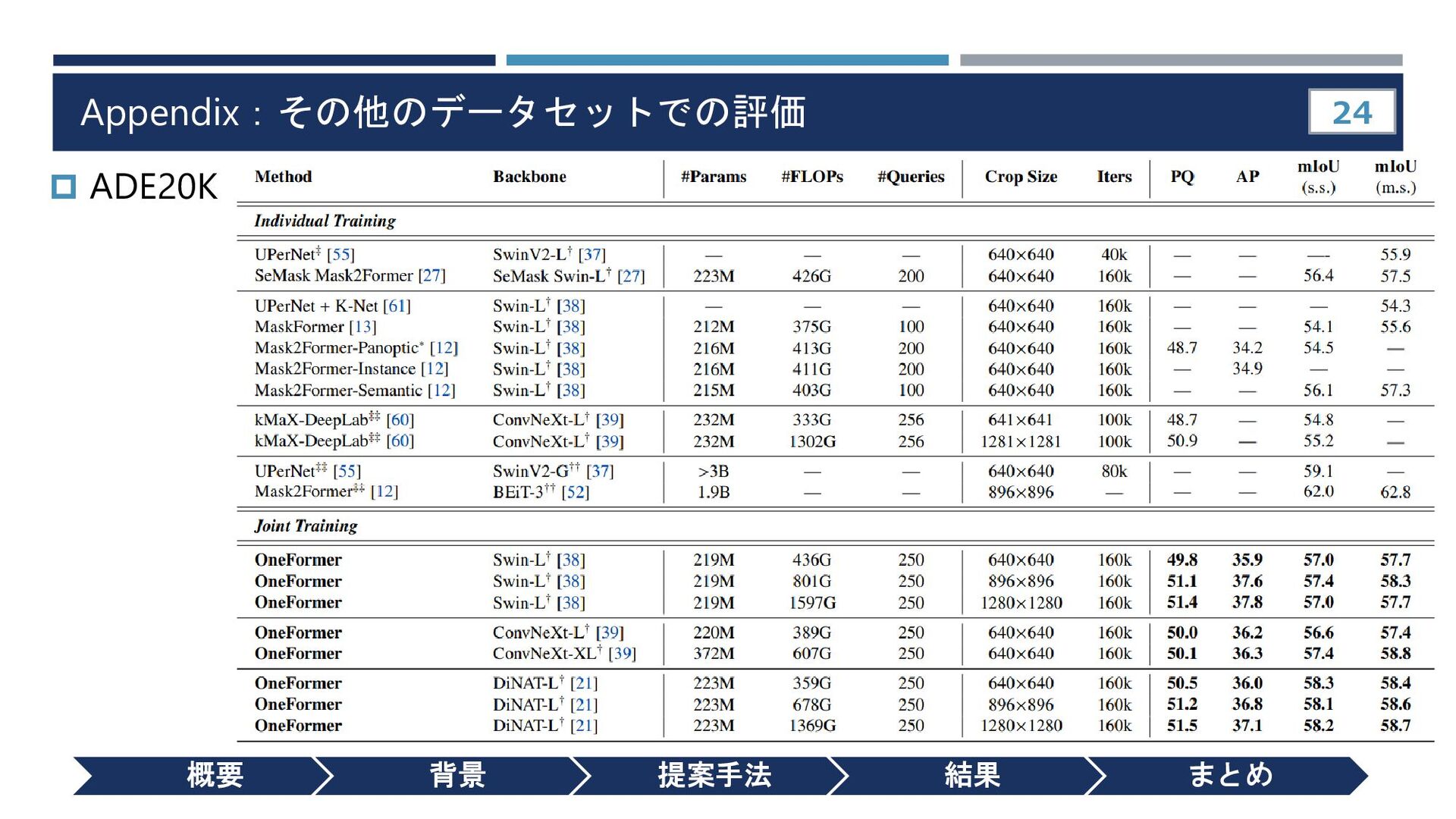{kind=link}
{kind=link}
{kind=link}