Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Journal club] Parallel Vertex Diffusion for Un...
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Semantic Machine Intelligence Lab., Keio Univ.
PRO
March 07, 2024
Technology
1.4k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Journal club] Parallel Vertex Diffusion for Unified Visual Grounding
Semantic Machine Intelligence Lab., Keio Univ.
PRO
March 07, 2024
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
81
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
86
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
98
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
仕様駆動開発、導入半年。「本当に速くなってるの?」にデータで答える / AICon2026_hirakawa
rakus_dev
0
320
Aurora MySQL 8.4リリース! Rubyistが備えること / what-rubyist-should-prepare-for-aurora-mysql-8-4
fkmy
0
630
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
280
生成 AI 時代にいま一度「問い合わせ」について考えてみる
kazzpapa3
1
130
Amazon Quick 入門!
ysuzuki
2
130
Network Firewallやっていき!
news_it_enj
0
260
AICoEでAIネイティブ組織への進化
yukiogawa
0
210
複数プロダクト組織のAIネイティブ化における戦略 / AICon2026_kude
rakus_dev
0
300
Webアプリ認証の全体像 / The Big Picture of Web App Authentication
kitano_yuichi
1
420
「守りたい体験」を渡すだけで E2E を生成させられるようになった話
hinac0
2
1k
SoccerMaster: A Vision Foundation Model for Soccer Understanding
kzykmyzw
0
160
ここは地獄!つらい朝会を体験することで、チームとしてのより良い振る舞いに気づくワークショップ / The stand-up meeting from hell in the game industry
scrummasudar
0
220
Featured
See All Featured
How to Talk to Developers About Accessibility
jct
2
420
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
250
Joys of Absence: A Defence of Solitary Play
codingconduct
1
420
Building Adaptive Systems
keathley
44
3.1k
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
970
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
エンジニアに許された特別な時間の終わり
watany
108
250k
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2.1k
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
390
Testing 201, or: Great Expectations
jmmastey
46
8.2k
WCS-LA-2024
lcolladotor
0
750
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
160
Transcript
Parallel Vertex Diffusion for Unified Visual Grounding 慶應義塾大学 杉浦孔明研究室 畑中駿平
Cheng, Z. et al. "Parallel Vertex Diffusion for Unified Visual Grounding." AAAI, 2024. Zesen Cheng1 Kehan Li1 Peng Jin1 Xiangyang Ji3 Li Yuan1,2 Chang Liu3† Jie Chen1,2† 1 School of Electronic and Computer Engineering, Peking University 2 Peng Cheng Laboratoy 3 Tsinghua Universiy † Corresponding author AAAI2024
▸ Visual grounding:与えられた参照表現を画像に接地させること ▹ 画像とテキスト間の細かい対応を確立することが可能 [Li+, CVPR22] ▸ Visual groundingは2つのサブタスクに分類
▹ Referring Expression Comprehension (REC) [Hu+, CVPR16]:bboxで予測 ▹ Referring Expression Segmentation (RES) [Hu+, ECCV16]:マスクで予測 2 背景:Visual groundingはvision-language分野のタスクで 重要なタスクである [Hu+, CVPR16] [Hu+, ECCV16]
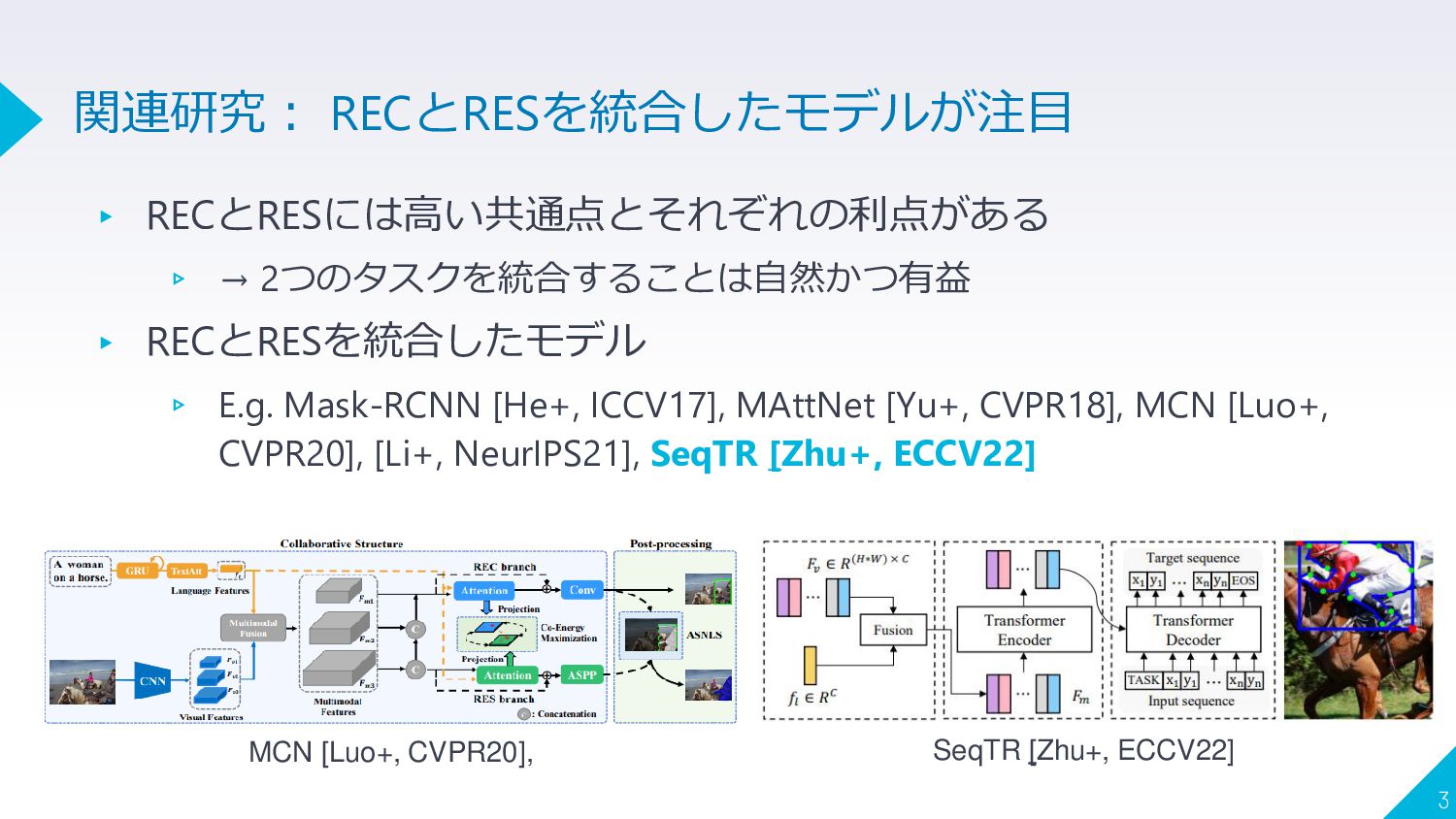
▸ RECとRESには高い共通点とそれぞれの利点がある ▹ → 2つのタスクを統合することは自然かつ有益 ▸ RECとRESを統合したモデル ▹ E.g. Mask-RCNN
[He+, ICCV17], MAttNet [Yu+, CVPR18], MCN [Luo+, CVPR20], [Li+, NeurIPS21], SeqTR [Zhu+, ECCV22] 3 関連研究: RECとRESを統合したモデルが注目 MCN [Luo+, CVPR20], SeqTR [Zhu+, ECCV22]
▸ SeqTR [Zhu+, ECCV22]:自己回帰モデル (Pix2Seq [Chen+, ICLR21]) によってRECとRESを同時に自己回帰頂点生成問題としてモデル化 ▸ SeqTRの問題点
▹ 頂点列の上流の精度が十分でない場合,誤差が増大する ▹ 高次元になると生成のための反復回数が増加し推論に時間がかかる 4 既存手法の問題点:自己回帰モデルの逐次頂点生成は性能 の上限に制限がある テキスト:“center baseman”
▸ SeqTR [Zhu+, ECCV22]:自己回帰モデル (Pix2Seq [Chen+, ICLR21]) によってRECとRESを同時に自己回帰頂点生成問題としてモデル化 ▸ SeqTRの問題点
▹ 頂点列の上流の精度が十分でない場合,誤差が増大する ▹ 高次元になると生成のための反復回数が増加し推論に時間がかかる 5 既存手法の問題点:自己回帰モデルの逐次頂点生成は性能 の上限に制限がある テキスト:“center baseman” 最初の頂点が右側の野球選手に予測 するとその後のリカバリーが困難
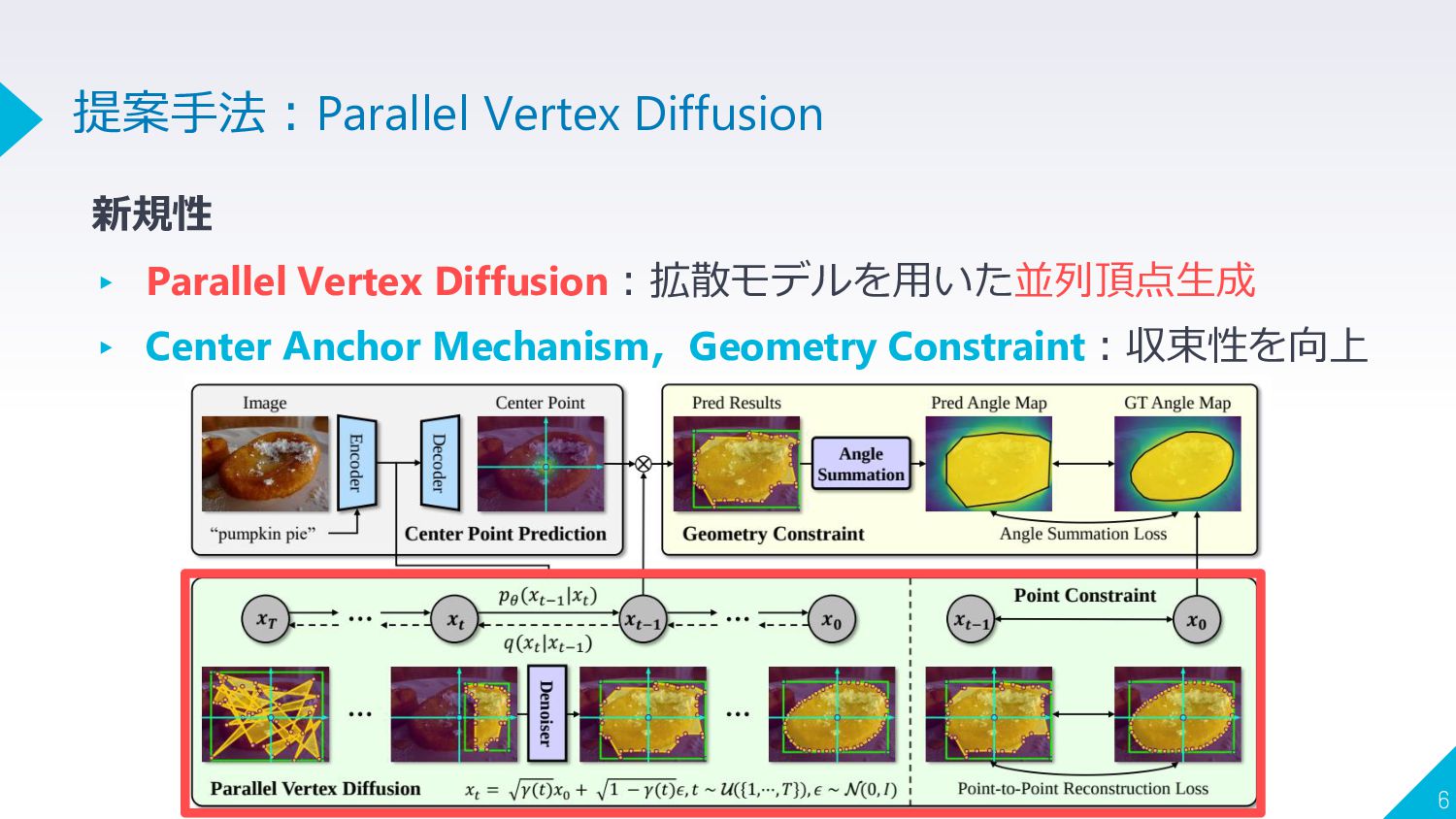
新規性 ▸ Parallel Vertex Diffusion:拡散モデルを用いた並列頂点生成 ▸ Center Anchor Mechanism,Geometry Constraint:収束性を向上
6 提案手法:Parallel Vertex Diffusion
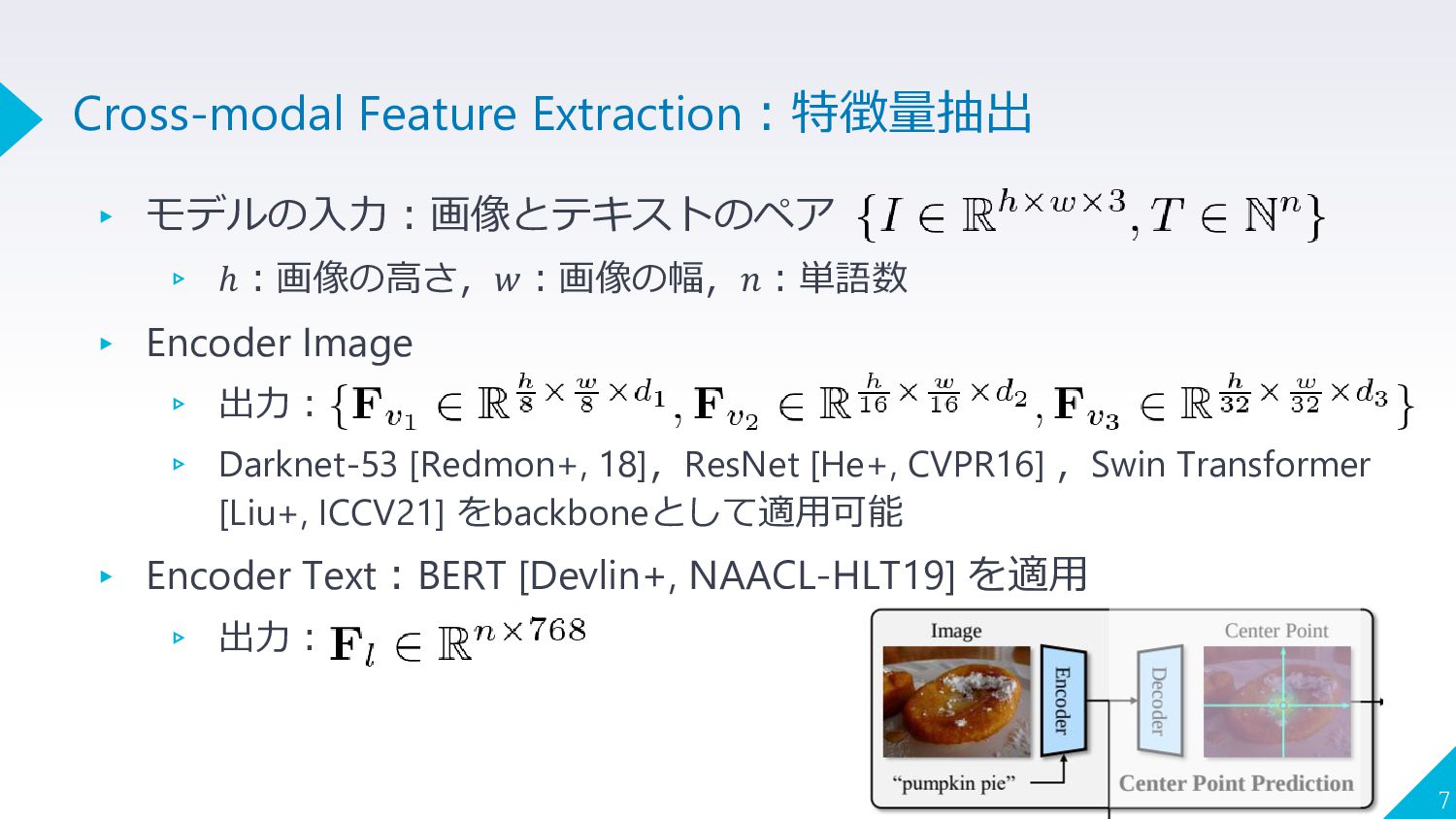
▸ モデルの入力:画像とテキストのペア ▹ ℎ:画像の高さ,𝑤:画像の幅,𝑛:単語数 ▸ Encoder Image ▹ 出力: ▹
Darknet-53 [Redmon+, 18],ResNet [He+, CVPR16] ,Swin Transformer [Liu+, ICCV21] をbackboneとして適用可能 ▸ Encoder Text:BERT [Devlin+, NAACL-HLT19] を適用 ▹ 出力: 7 Cross-modal Feature Extraction:特徴量抽出
▸ 𝑖層目の画像特徴量 と をSeqTRとMSDeformAttn [Zhu+, ICLR21] をベースに融合し を得る ▸ ▹
MLP:全結合層 ▹ 𝜎:活性化関数 ▹ ⨀:アダマール積 8 Cross-modal Feature Extraction:特徴量抽出 SeqTRとおなじ形
▸ CAMの動機:中心点を基準に正規化することで座標回帰の難易度が 下がることが期待される [Tian+, ICCV19] ▸ Center Point Prediction:物体の中央点をヒートマップ で予測
▹ : 正解の中心点の座標(正規化済み) ▹ 𝜎:画像サイズに適した標準偏差 9 Center Anchor Mechanism (CAM) :物体の中心点を予測
▸ CAMの動機:中心点を基準に正規化することで座標回帰の難易度が 下がることが期待される [Tian+, ICCV19] ▸ 正解 および予測されたヒートマップ に対してfocal loss
[Lin+, ICCV17] を用いて学習 10 Center Anchor Mechanism (CAM) :物体の中心点を予測
▸ 拡散モデルは効果的なスケーラブルなモデルとして活用 ▹ E.g. 画像生成タスク [Ramesh+, 22],識別タスク [Chen+, ICCV23] ▹
☺ ノイズの次元を変更するだけで,高次元設定の拡張可能 ▸ 拡散モデルを用いて頂点生成をより高次元かつ並列に行う Parallel Vertex Diffusionの提案 ▹ ※ Pix2Seq-D [Chen+, ICCV23] に基づいて構築(以降Denoiserと称す) 11 Parallel Vertex Diffusion:拡散モデルを用いて頂点を洗練
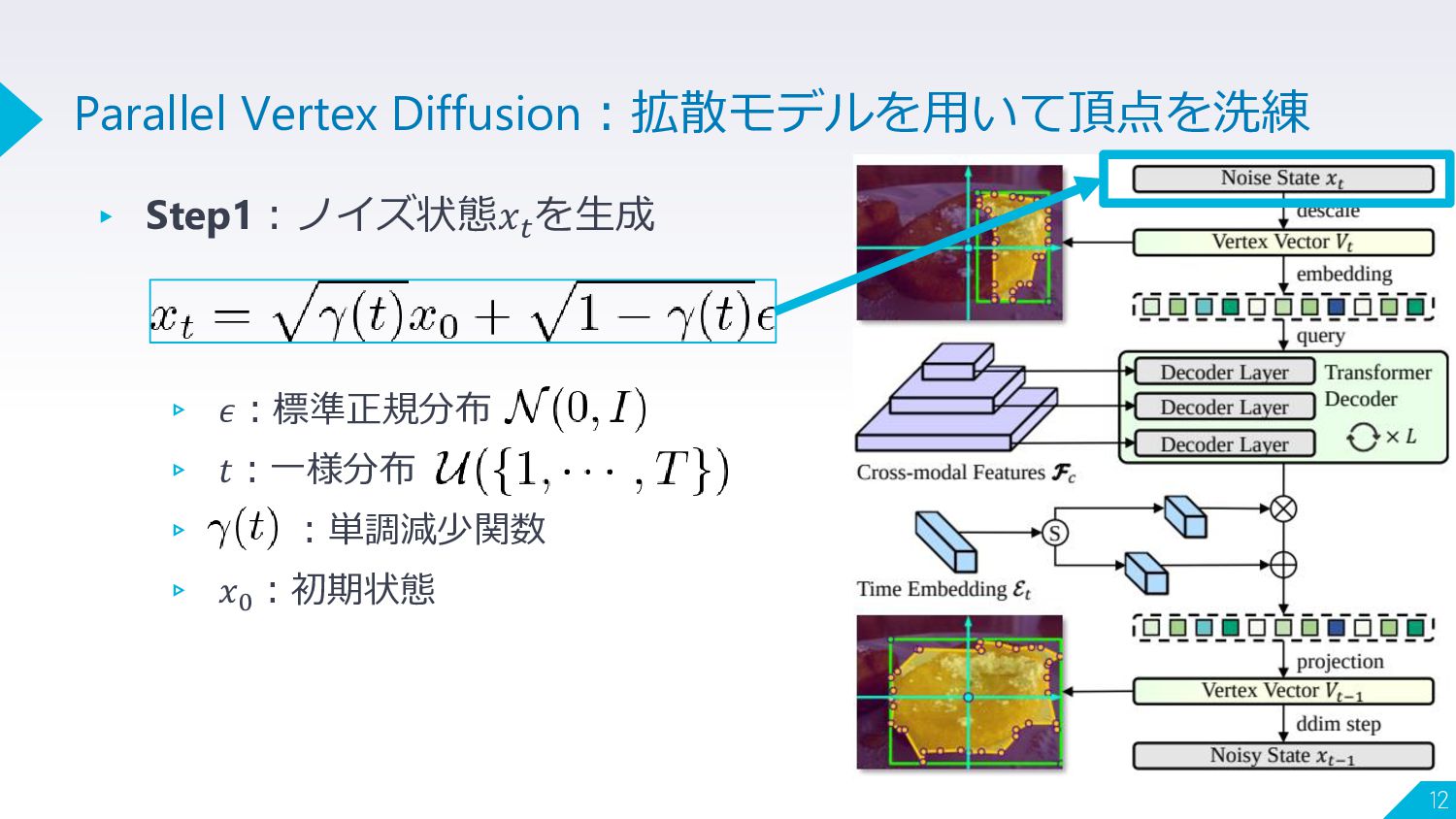
▸ Step1:ノイズ状態𝑥𝑡 を生成 ▹ 𝜖:標準正規分布 ▹ 𝑡:一様分布 ▹ :単調減少関数 ▹
𝑥0 :初期状態 12 Parallel Vertex Diffusion:拡散モデルを用いて頂点を洗練
▸ Step2:𝑥𝑡 を頂点ベクトル𝑉𝑡 に変換 ▸ Denoiserの頂点の正規化座標が [0, 1] のため[-1, 1]→[0,
1]にスケールダウン ▸ 𝑉𝑡 の次元数は(4 + 2𝑁)である ▹ 𝑁:ポリゴンの頂点数 13 Parallel Vertex Diffusion:拡散モデルを用いて頂点を洗練
▸ Step3:𝑉𝑡 を2次元座標埋め込みにより 𝑄𝑡 に変換 [Meng+, ICCV21] 14 Parallel Vertex
Diffusion:拡散モデルを用いて頂点を洗練
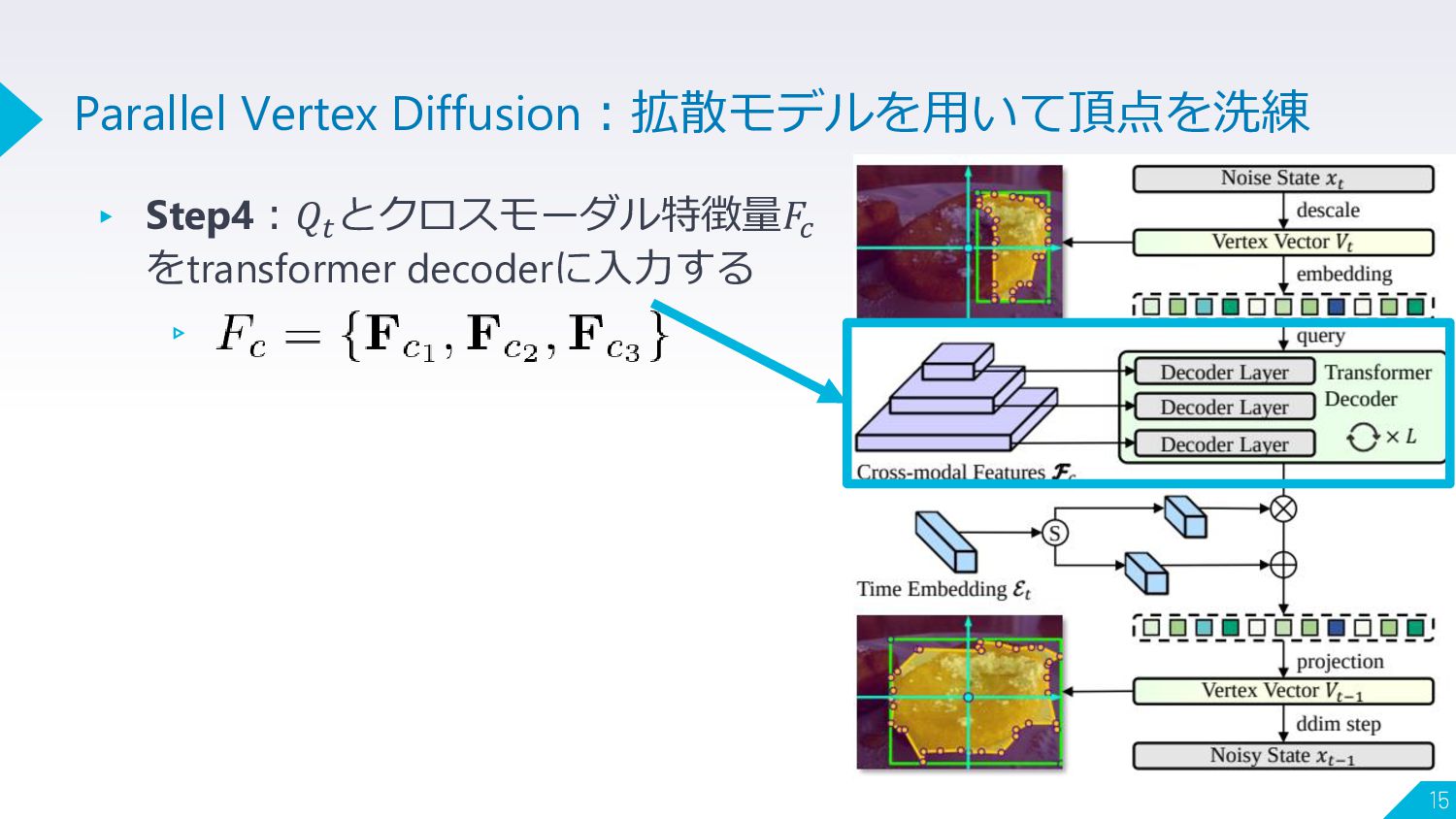
▸ Step4:𝑄𝑡 とクロスモーダル特徴量𝐹𝑐 をtransformer decoderに入力する ▹ 15 Parallel Vertex Diffusion:拡散モデルを用いて頂点を洗練
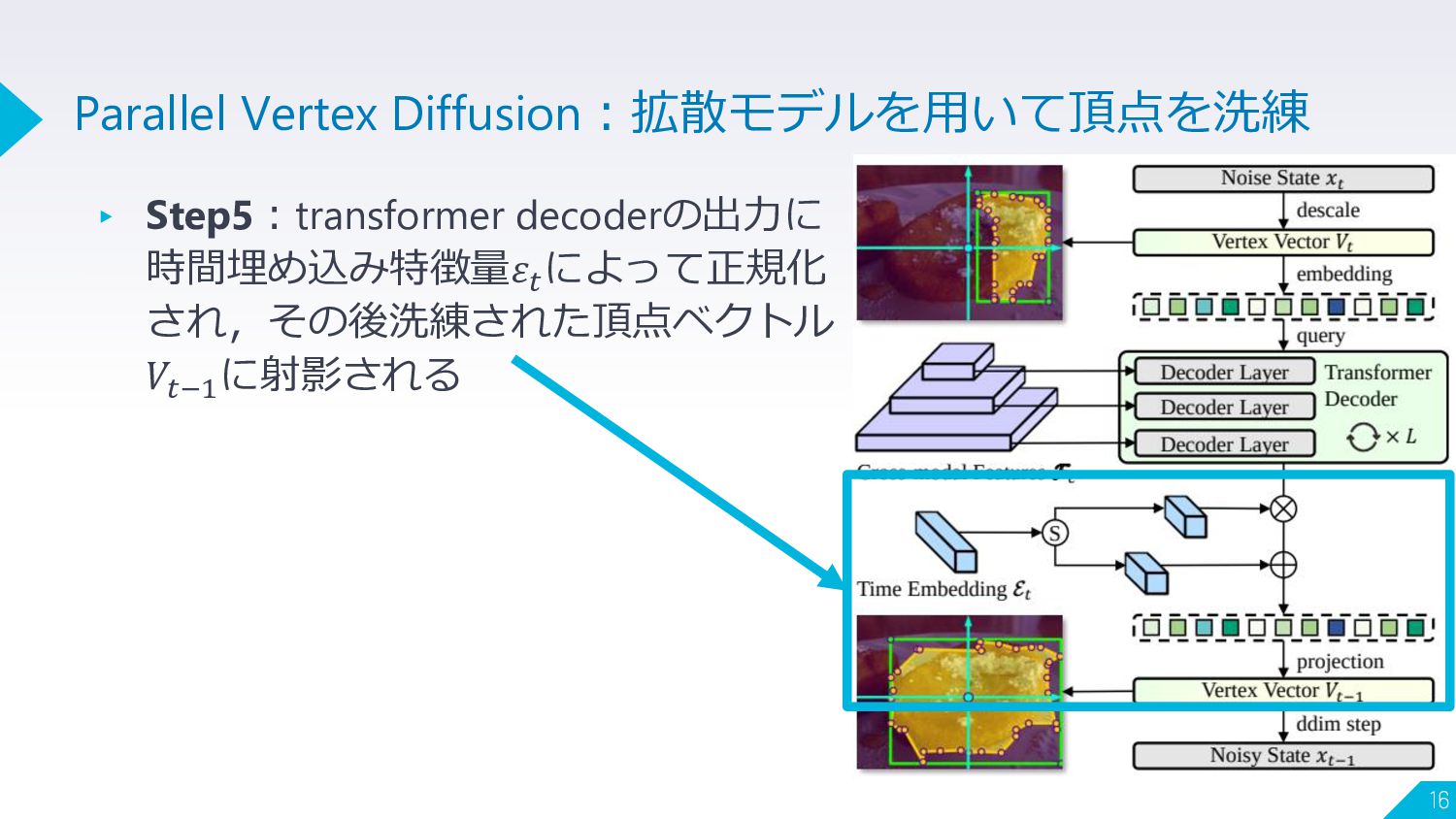
▸ Step5:transformer decoderの出力に 時間埋め込み特徴量𝜀𝑡 によって正規化 され,その後洗練された頂点ベクトル 𝑉𝑡−1 に射影される 16 Parallel
Vertex Diffusion:拡散モデルを用いて頂点を洗練
▸ Step6:次のノイズ状態𝑥𝑡−1 を取得 するために,DDIMステップ [Song+, ICLR21] によって処理される 17 Parallel Vertex
Diffusion:拡散モデルを用いて頂点を洗練
▸ Point Constraintの損失関数 [Chen+, ICLR23] ▹ :パラメータ化されたDenoiser ▹ 各ノイズ状態𝑥𝑡 は初期状態𝑥0
に近づくこと が求められる 18 Parallel Vertex Diffusion:拡散モデルを用いて頂点を洗練
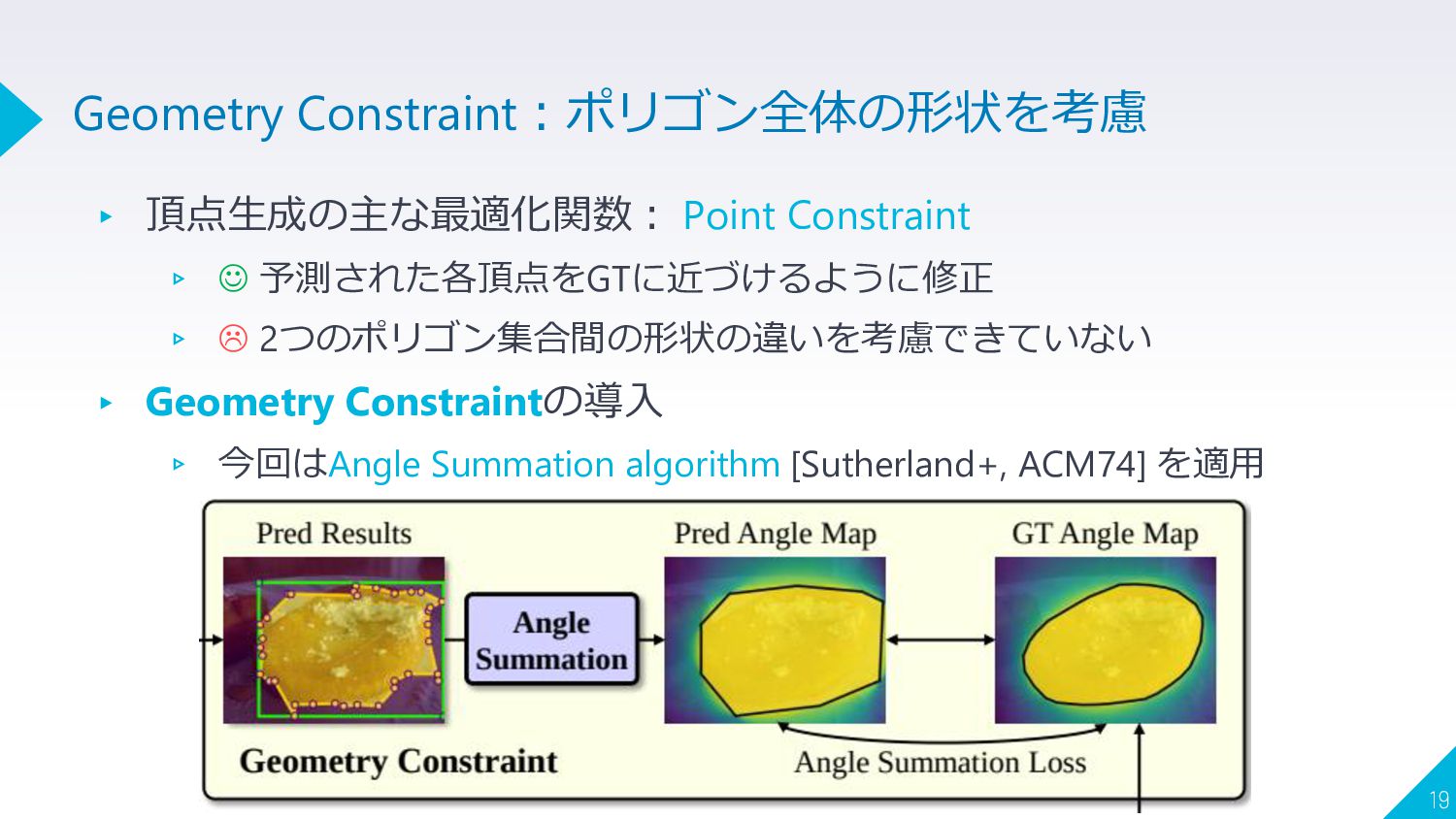
▸ 頂点生成の主な最適化関数: Point Constraint ▹ ☺ 予測された各頂点をGTに近づけるように修正 ▹ 2つのポリゴン集合間の形状の違いを考慮できていない
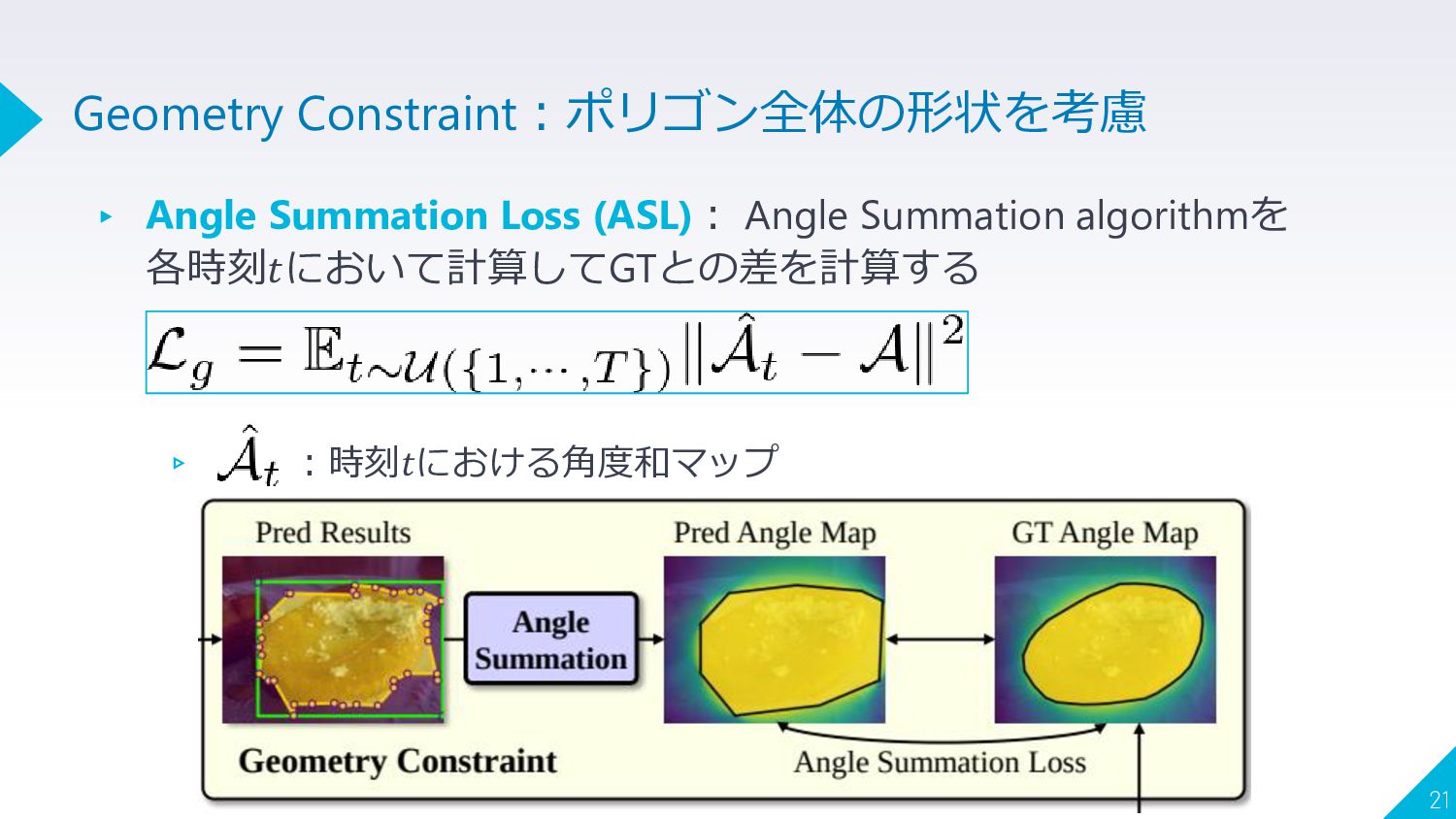
▸ Geometry Constraintの導入 ▹ 今回はAngle Summation algorithm [Sutherland+, ACM74] を適用 19 Geometry Constraint:ポリゴン全体の形状を考慮
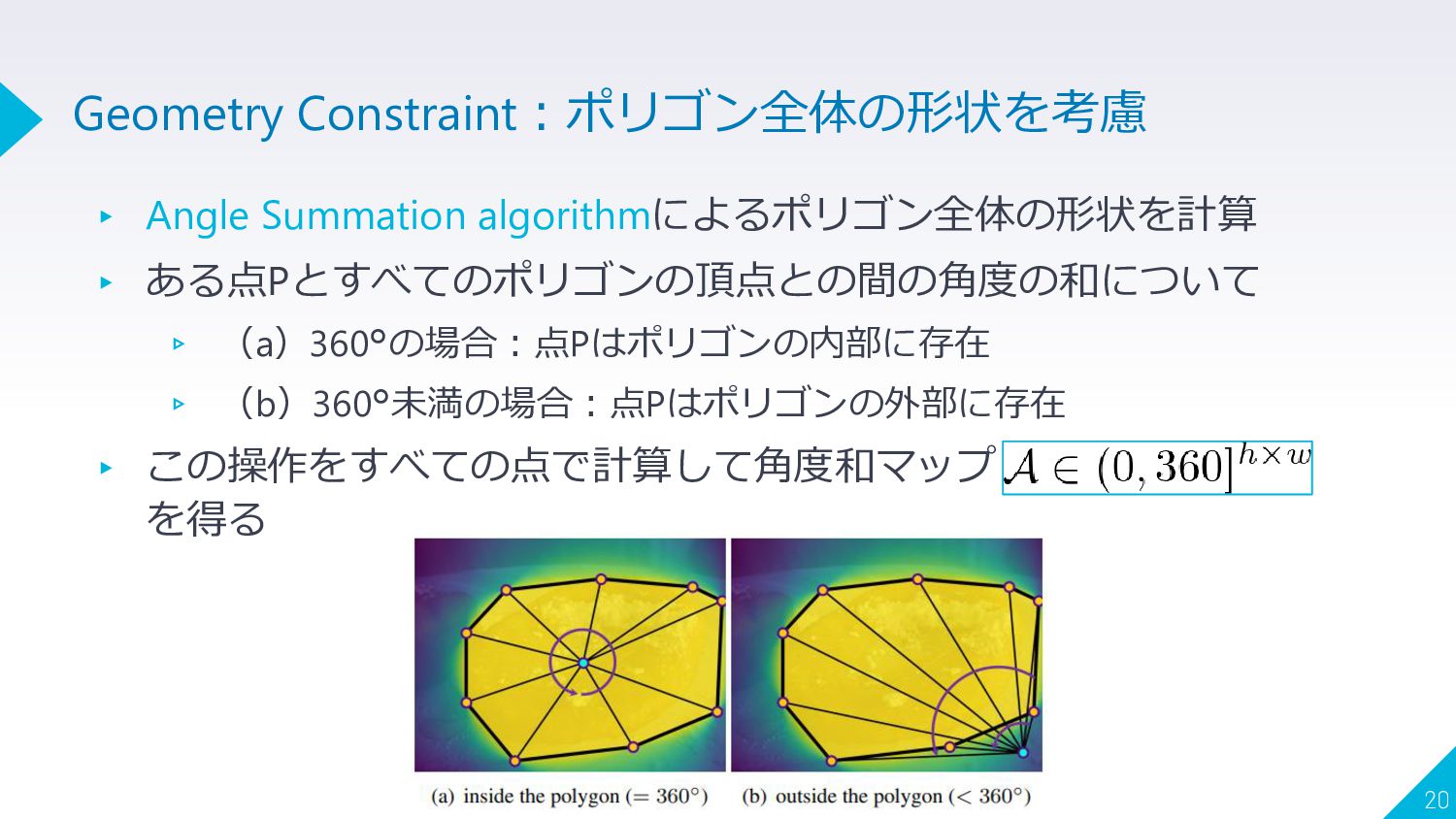
▸ Angle Summation algorithmによるポリゴン全体の形状を計算 ▸ ある点Pとすべてのポリゴンの頂点との間の角度の和について ▹ (a)360°の場合:点Pはポリゴンの内部に存在 ▹ (b)360°未満の場合:点Pはポリゴンの外部に存在
▸ この操作をすべての点で計算して角度和マップ を得る 20 Geometry Constraint:ポリゴン全体の形状を考慮
▸ Angle Summation Loss (ASL): Angle Summation algorithmを 各時刻𝑡において計算してGTとの差を計算する ▹
:時刻𝑡における角度和マップ 21 Geometry Constraint:ポリゴン全体の形状を考慮
▸ REC・RESタスクの標準データセット ▹ RefCOCO [Yu+, ECCV16],RefCOCO+ [Yu+, ECCV16], RefCOCOg [Mao+,
CVPR16] ▸ 評価尺度 ▹ REC:
[email protected]
▹ RES:overall IoU ▸ 学習設定等 ▹ GPU:4つのNVIDIA V100 ▹ デフォルトの頂点数𝑁 = 36 ▹ バッチサイズ 64,エポック数 100 22 実験設定:3種類の標準データセットで実験
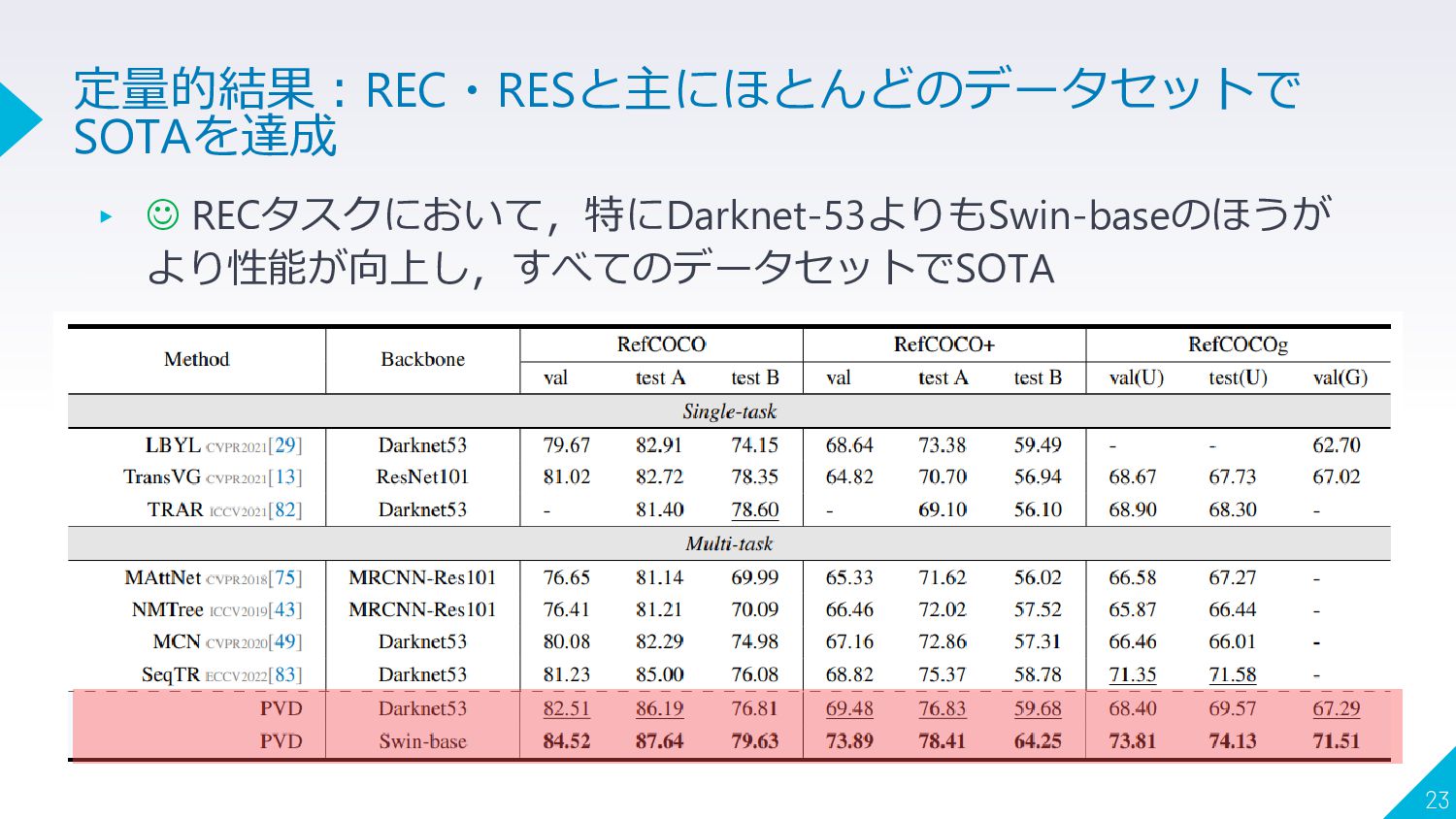
▸ ☺ RECタスクにおいて,特にDarknet-53よりもSwin-baseのほうが より性能が向上し,すべてのデータセットでSOTA 23 定量的結果:REC・RESと主にほとんどのデータセットで SOTAを達成
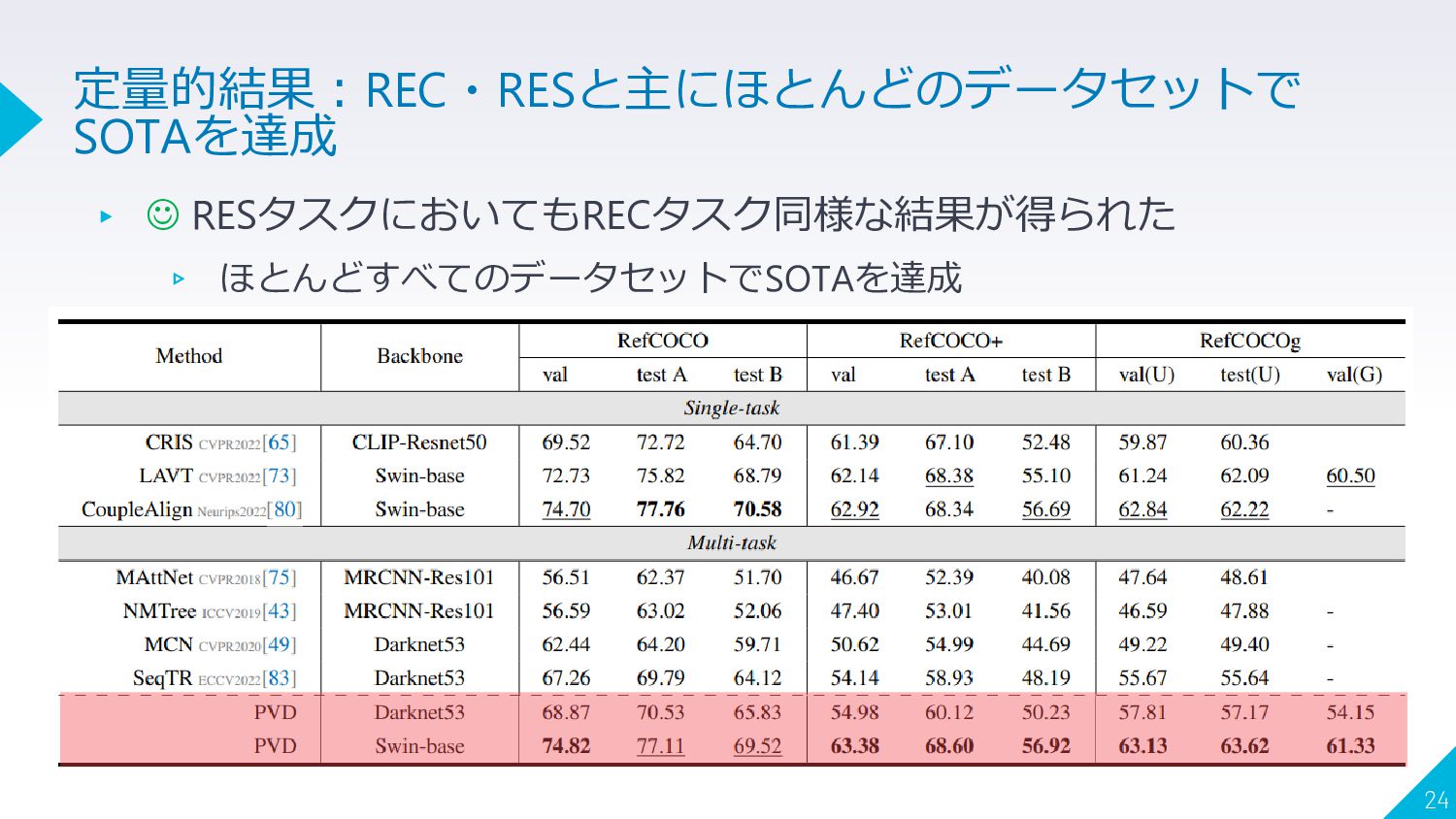
▸ ☺ RESタスクにおいてもRECタスク同様な結果が得られた ▹ ほとんどすべてのデータセットでSOTAを達成 24 定量的結果:REC・RESと主にほとんどのデータセットで SOTAを達成
▸ 特に,(b)や(d)はSeqTRよりもオクルージョンされた物体の輪郭を とらえることが可能 ▸ ※ 以降,SVG(sequential vertex generation)はSeqTRを指す 25 定性的結果:SeqTRと比較してより洗練されたマスクを生成
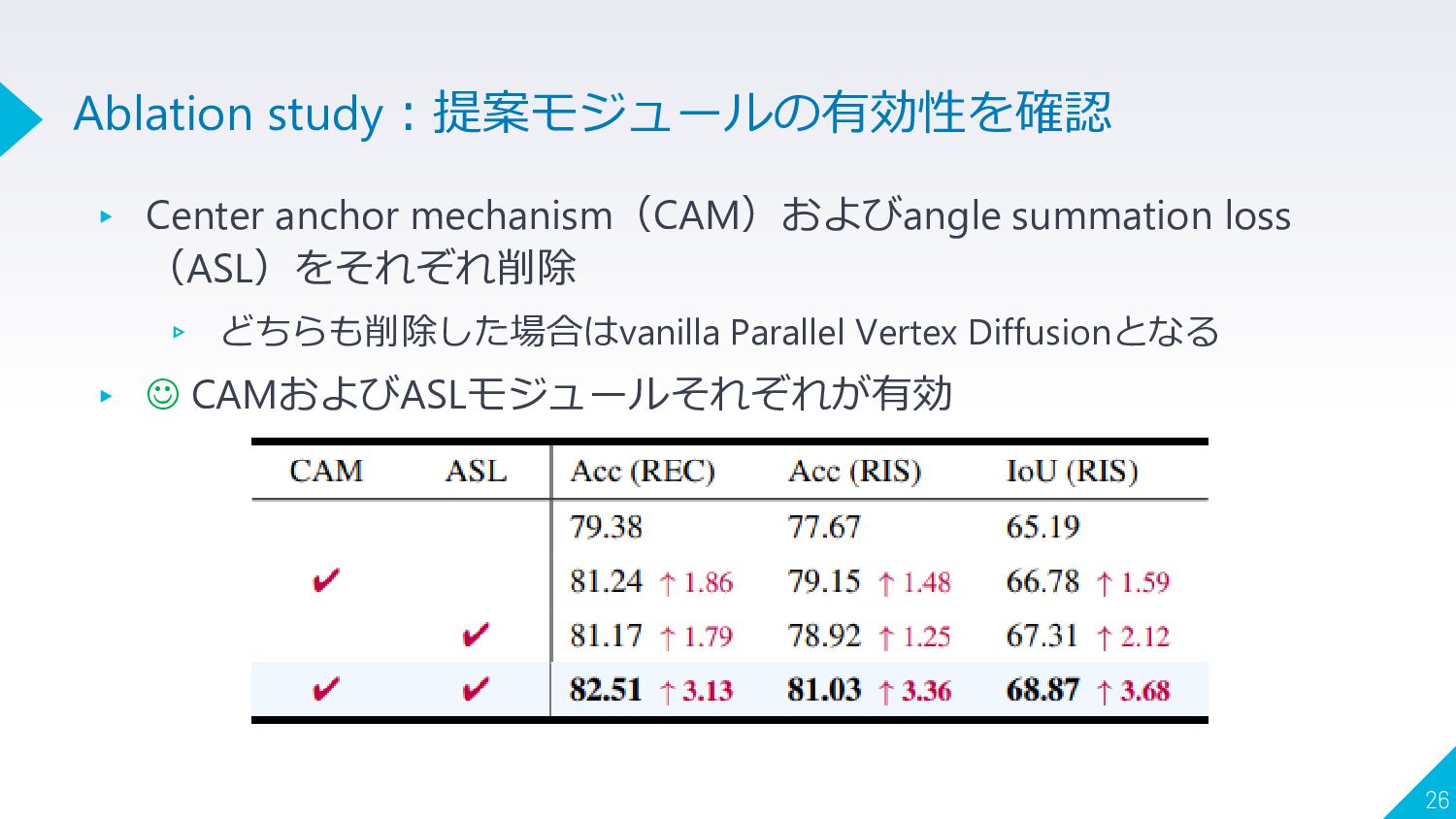
▸ Center anchor mechanism(CAM)およびangle summation loss (ASL)をそれぞれ削除 ▹ どちらも削除した場合はvanilla Parallel
Vertex Diffusionとなる ▸ ☺ CAMおよびASLモジュールそれぞれが有効 26 Ablation study:提案モジュールの有効性を確認
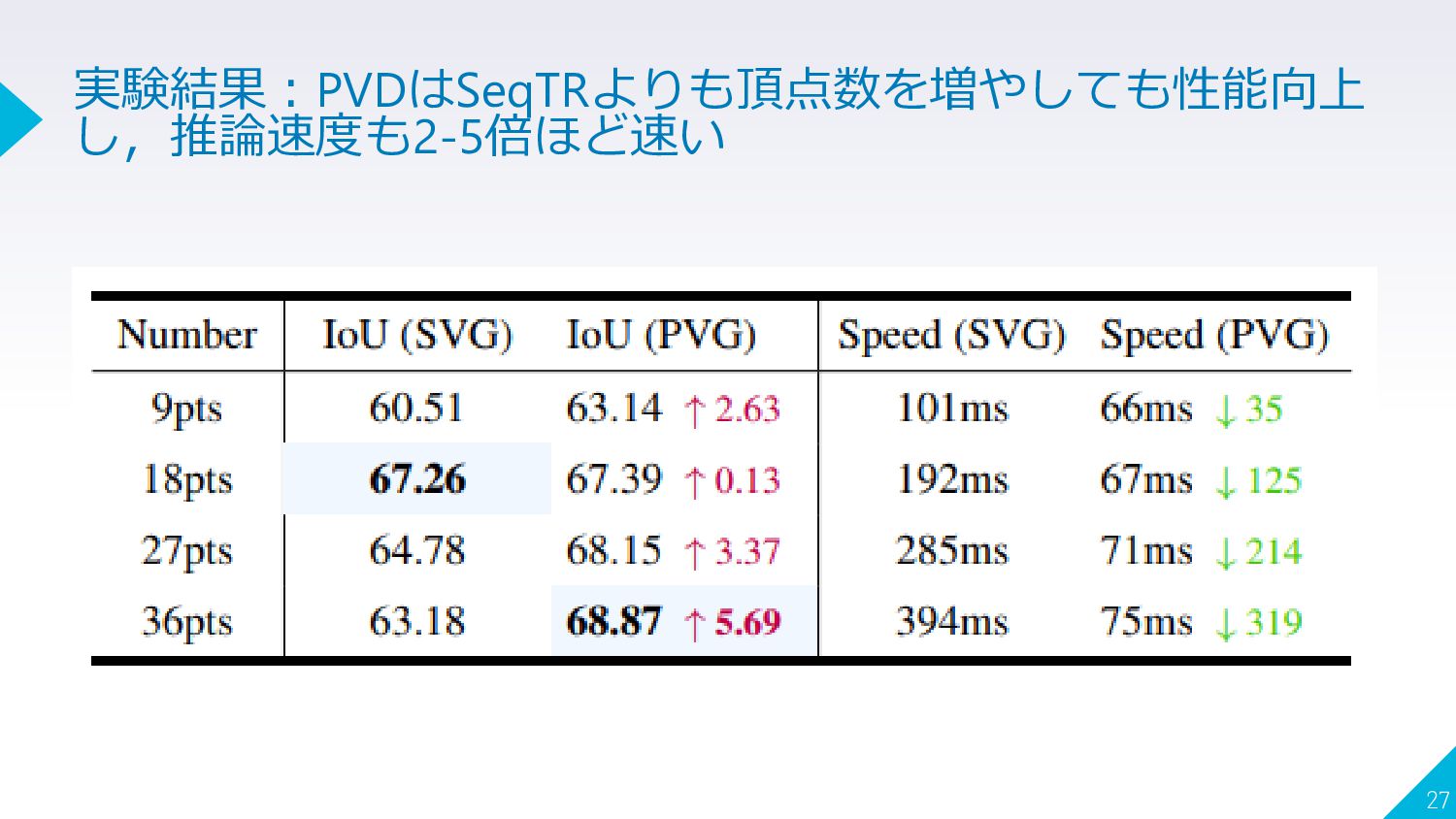
27 実験結果:PVDはSeqTRよりも頂点数を増やしても性能向上 し,推論速度も2-5倍ほど速い
Strengths ▸ 要所で図や新規性のmotivationが明記されていて理解しやすい ▸ 拡散モデルの特徴を活かして,スケーラビリティおよび推論速度の向上を実現 ▸ 実験設定が適切かつ豊富で提案手法の有効性を確認している Weaknesses ▸ SeqTRよりも頂点数の増やしているが(最大で2倍の36点),オクルージョンには依然として対応
できていない ▸ 表のキャプションが下側にある・typoが随所見られた(最新版は修正されているかもしれない) Others ▸ SeqTRによる後続研究が活発的である(e.g. PolyFormer [Liu+, CVPR23],Partial-RES [Qu+, CVPR23],PORTER [九曜+, NLP24]) ▸ ベースライン手法も含めて2020年以降のREC/RESモデルのbackboneにDarknet-53 [Redmon+, 18] を適用している手法が多い印象 28 所感
背景 ▸ 自己回帰としての逐次頂点生成モデルは性能の上限が制限される 提案 ▸ 拡散モデルを用いて並列頂点生成モデルPVDの提案 結果 ▸ 性能に加えて,推論速度や複雑さの観点からでも既存手法を上回る 29
まとめ
{kind=link}
![▸ Visual grounding:与えられた参照表現を画像に接地させること ▹ 画像とテキスト間の細かい対応を確立することが可能 [Li+, CVPR22] ▸ Visual groundingは2つのサブタスクに分類](https://files.speakerdeck.com/presentations/409173c9aa494d67b194e2ea11e70f36/slide_1.jpg){kind=link}
{kind=link}
![▸ SeqTR [Zhu+, ECCV22]:自己回帰モデル (Pix2Seq [Chen+, ICLR21]) によってRECとRESを同時に自己回帰頂点生成問題としてモデル化 ▸ SeqTRの問題点](https://files.speakerdeck.com/presentations/409173c9aa494d67b194e2ea11e70f36/slide_3.jpg){kind=link}
![▸ SeqTR [Zhu+, ECCV22]:自己回帰モデル (Pix2Seq [Chen+, ICLR21]) によってRECとRESを同時に自己回帰頂点生成問題としてモデル化 ▸ SeqTRの問題点](https://files.speakerdeck.com/presentations/409173c9aa494d67b194e2ea11e70f36/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
![▸ 𝑖層目の画像特徴量 と をSeqTRとMSDeformAttn [Zhu+, ICLR21] をベースに融合し を得る ▸ ▹](https://files.speakerdeck.com/presentations/409173c9aa494d67b194e2ea11e70f36/slide_7.jpg){kind=link}
![▸ CAMの動機:中心点を基準に正規化することで座標回帰の難易度が 下がることが期待される [Tian+, ICCV19] ▸ Center Point Prediction:物体の中央点をヒートマップ で予測](https://files.speakerdeck.com/presentations/409173c9aa494d67b194e2ea11e70f36/slide_8.jpg){kind=link}
![▸ CAMの動機:中心点を基準に正規化することで座標回帰の難易度が 下がることが期待される [Tian+, ICCV19] ▸ 正解 および予測されたヒートマップ に対してfocal loss](https://files.speakerdeck.com/presentations/409173c9aa494d67b194e2ea11e70f36/slide_9.jpg){kind=link}
![▸ 拡散モデルは効果的なスケーラブルなモデルとして活用 ▹ E.g. 画像生成タスク [Ramesh+, 22],識別タスク [Chen+, ICCV23] ▹](https://files.speakerdeck.com/presentations/409173c9aa494d67b194e2ea11e70f36/slide_10.jpg){kind=link}
{kind=link}
![▸ Step2:𝑥𝑡 を頂点ベクトル𝑉𝑡 に変換 ▸ Denoiserの頂点の正規化座標が [0, 1] のため[-1, 1]→[0,](https://files.speakerdeck.com/presentations/409173c9aa494d67b194e2ea11e70f36/slide_12.jpg){kind=link}
![▸ Step3:𝑉𝑡 を2次元座標埋め込みにより 𝑄𝑡 に変換 [Meng+, ICCV21] 14 Parallel Vertex](https://files.speakerdeck.com/presentations/409173c9aa494d67b194e2ea11e70f36/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
![▸ Step6:次のノイズ状態𝑥𝑡−1 を取得 するために,DDIMステップ [Song+, ICLR21] によって処理される 17 Parallel Vertex](https://files.speakerdeck.com/presentations/409173c9aa494d67b194e2ea11e70f36/slide_16.jpg){kind=link}
![▸ Point Constraintの損失関数 [Chen+, ICLR23] ▹ :パラメータ化されたDenoiser ▹ 各ノイズ状態𝑥𝑡 は初期状態𝑥0](https://files.speakerdeck.com/presentations/409173c9aa494d67b194e2ea11e70f36/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![▸ REC・RESタスクの標準データセット ▹ RefCOCO [Yu+, ECCV16],RefCOCO+ [Yu+, ECCV16], RefCOCOg [Mao+,](https://files.speakerdeck.com/presentations/409173c9aa494d67b194e2ea11e70f36/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}