Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Journal club] Rapid Exploration for Open-World...
Search
Semantic Machine Intelligence Lab., Keio Univ.
PRO
July 27, 2022
Technology
1.2k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Journal club] Rapid Exploration for Open-World Navigation with Latent Goal Models
Semantic Machine Intelligence Lab., Keio Univ.
PRO
July 27, 2022
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
76
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
85
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
96
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
Alphaモジュール使っていいのかい!?いけないのかい!?どっちなんだいっ!?
watany
1
300
データエンジニアリングとドメイン駆動設計
masuda220
PRO
10
1.7k
世界、断片、モデル。そして理解
ardbeg1958
1
140
ファミコンでPHPを動かす / PHP on the Famicom
tomzoh
2
540
複数プロダクト組織のAIネイティブ化における戦略 / AICon2026_kude
rakus_dev
0
260
[2026-07-15] AI Ready なはずだったアーキテクチャと、見えてきた課題・次に目指す状態
wxyzzz
11
4.1k
公式ドキュメントの歩き方etc
coco_se
1
120
AIが実装を自走する時代の認知負債との戦い
lycorptech_jp
PRO
2
990
“それは自分の仕事じゃない"を 越えて行け
yuukiyo
1
500
プロダクト開発組織の現在地(Ver.2026/07) / product-organization
kaonavi
0
130
OpenTelemetryにおけるGoのゼロコード・コンパイル時計装について #fukuokago
quiver
0
170
Amplify Gen2でbackend.tsにCDKを定義する/しない事によるCDKの挙動の違いとユースケース
smt7174
1
450
Featured
See All Featured
GraphQLとの向き合い方2022年版
quramy
50
15k
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3.3k
Skip the Path - Find Your Career Trail
mkilby
1
170
The Cost Of JavaScript in 2023
addyosmani
55
10k
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
180
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
Test your architecture with Archunit
thirion
1
2.3k
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
390
Building Better People: How to give real-time feedback that sticks.
wjessup
370
20k
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
400
Designing for humans not robots
tammielis
254
26k
A designer walks into a library…
pauljervisheath
211
24k
Transcript
慶應義塾大学 杉浦孔明研究室 是方諒介 Rapid Exploration for Open-World Navigation with Latent
Goal Models Dhruv Shah1, Benjamin Eysenbach2, Nicholas Rhinehart1, Sergey Levine1 (1UC Berkeley, 2Carnegie Mellon University) CoRL 2021 Dhruv Shah, Benjamin Eysenbach, Nicholas Rhinehart and Sergey Levine. "Rapid Exploration for Open-World Navigation with Latent Goal Models." CoRL 2021.
概要 背景 ✓ 未知の屋外実環境における、画像による頑健なnavigation 提案 ✓ 大規模オフラインデータを用いた、ゴールまでの距離と行動に関する潜在変数モデル ✓ 探索時におけるトポロジカルなグラフの構築 結果
✓ 20分以内の探索で最大で80m遠方までのnavigationに成功 ✓ 非定常的な環境への頑健性を確認 2
背景:実環境navigationにおいて頑健性は重要 ◼ タスク:未知の屋外実環境において、画像で指定されたゴールへ移動 ◼ ロボットに搭載されたRGBカメラ画像のみ利用可 ◼ 課題 ✓ 非定常的な要素(e.g. 光)
✓ 学習データと実環境の未知データとの差異 3 ゴール画像 エリア探索 navigation ロボット (Clearpath Jackal) 既知 未知
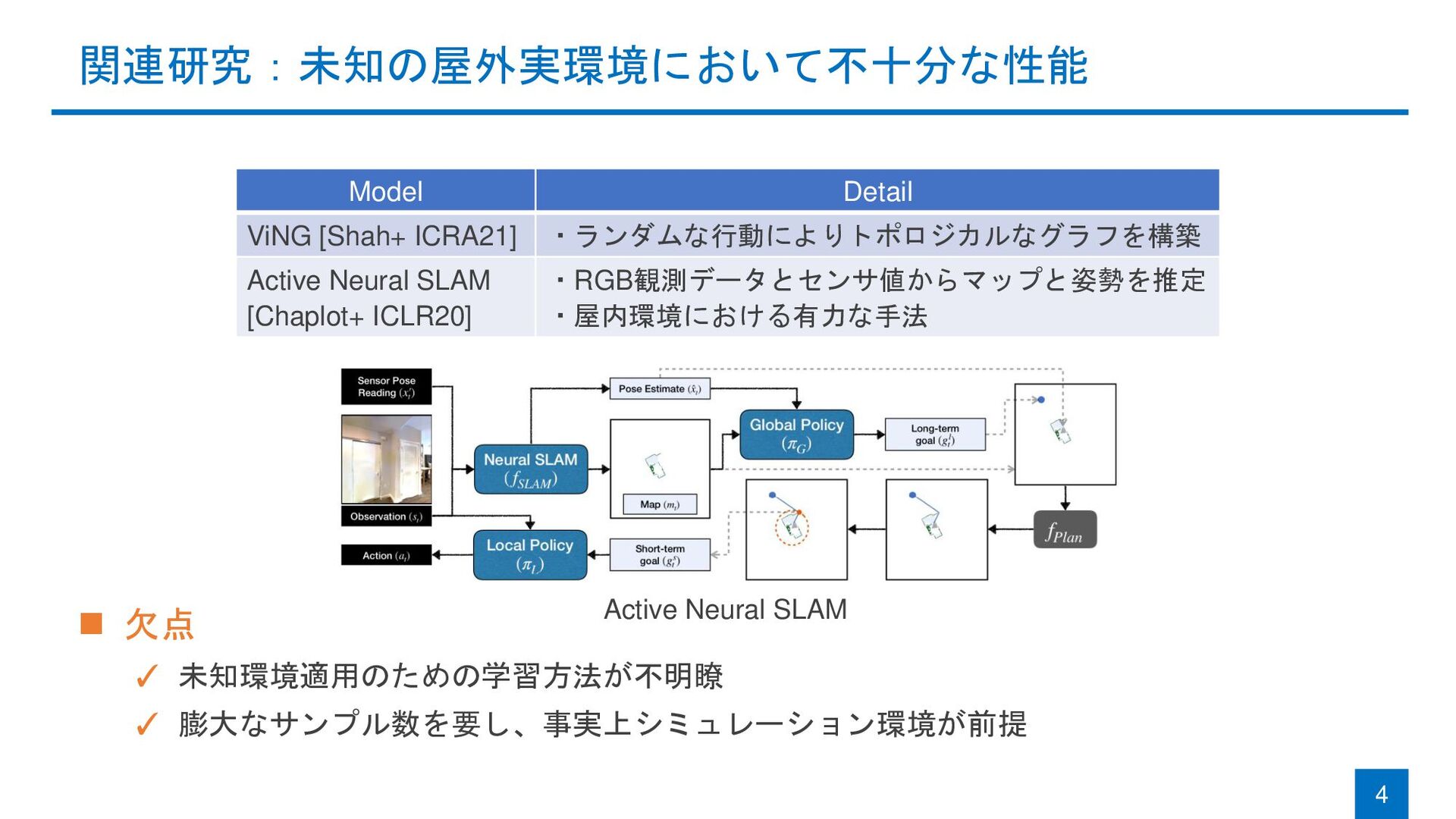
関連研究:未知の屋外実環境において不十分な性能 ◼ 欠点 ✓ 未知環境適用のための学習方法が不明瞭 ✓ 膨大なサンプル数を要し、事実上シミュレーション環境が前提 4 Model Detail
ViNG [Shah+ ICRA21] ・ランダムな行動によりトポロジカルなグラフを構築 Active Neural SLAM [Chaplot+ ICLR20] ・RGB観測データとセンサ値からマップと姿勢を推定 ・屋内環境における有力な手法 Active Neural SLAM
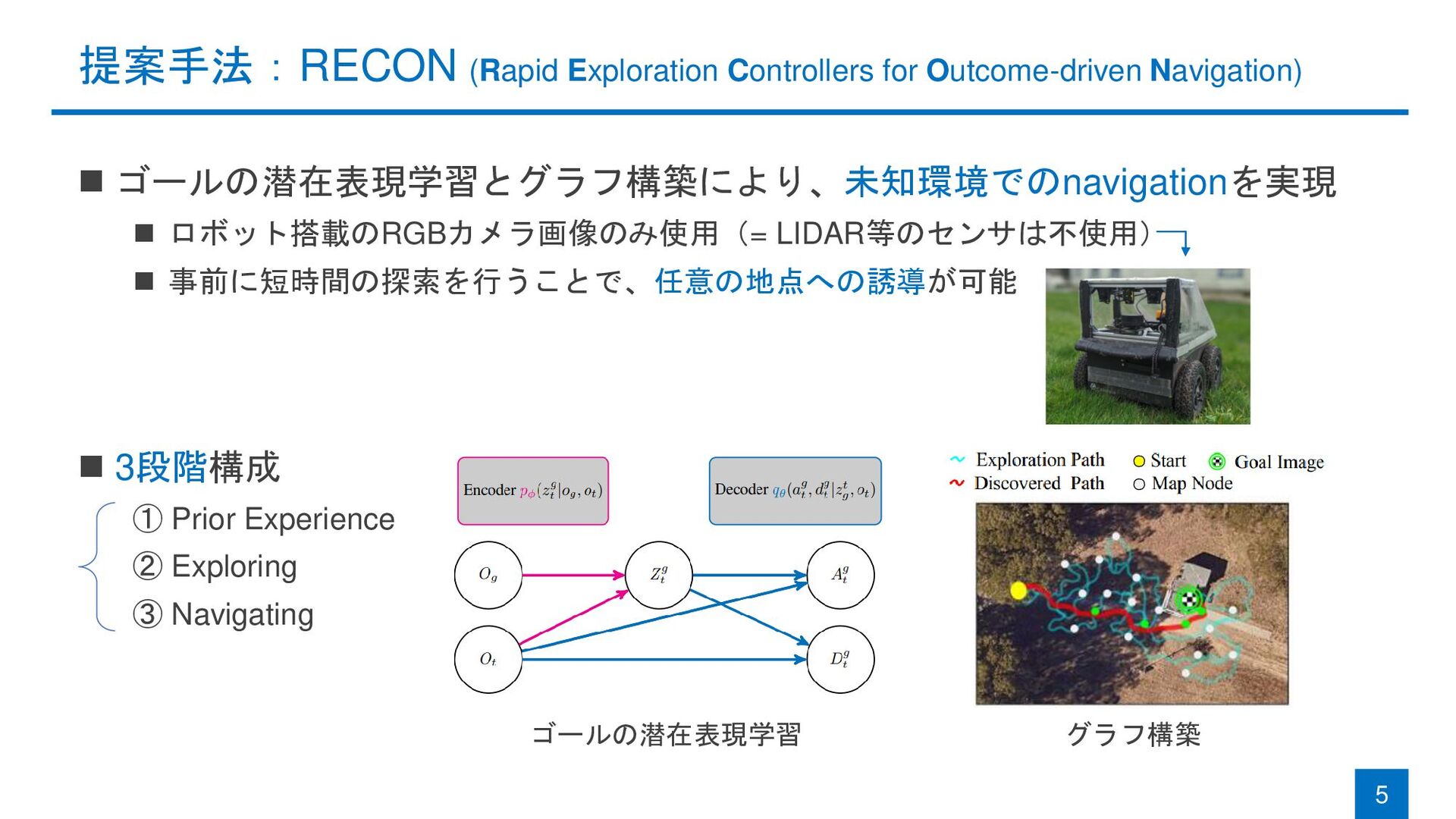
提案手法:RECON (Rapid Exploration Controllers for Outcome-driven Navigation) ◼ ゴールの潜在表現学習とグラフ構築により、未知環境でのnavigationを実現 ◼
ロボット搭載のRGBカメラ画像のみ使用(= LIDAR等のセンサは不使用) ◼ 事前に短時間の探索を行うことで、任意の地点への誘導が可能 ◼ 3段階構成 ① Prior Experience ② Exploring ③ Navigating 5 ゴールの潜在表現学習 グラフ構築
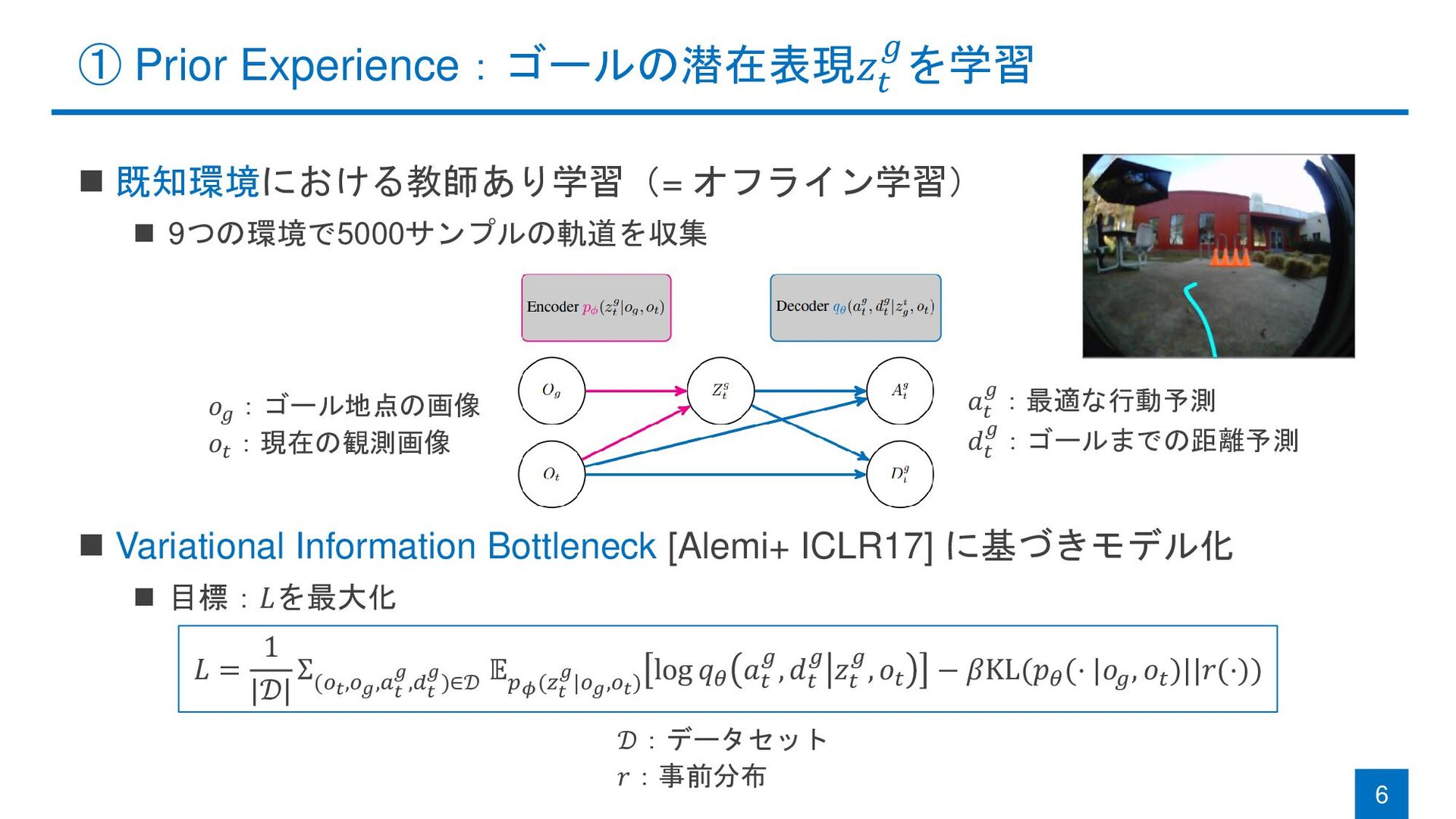
① Prior Experience:ゴールの潜在表現𝑧𝑡 𝑔を学習 ◼ 既知環境における教師あり学習(= オフライン学習) ◼ 9つの環境で5000サンプルの軌道を収集 ◼
Variational Information Bottleneck [Alemi+ ICLR17] に基づきモデル化 ◼ 目標:𝐿を最大化 6 𝑎𝑡 𝑔:最適な行動予測 𝑑𝑡 𝑔:ゴールまでの距離予測 𝑜𝑔 :ゴール地点の画像 𝑜𝑡 :現在の観測画像 𝐿 = 1 |𝒟| Σ (𝑜𝑡,𝑜𝑔,𝑎𝑡 𝑔,𝑑𝑡 𝑔)∈𝒟 𝔼 𝑝𝜙(𝑧𝑡 𝑔|𝑜𝑔,𝑜𝑡) log 𝑞𝜃 𝑎 𝑡 𝑔, 𝑑 𝑡 𝑔 𝑧 𝑡 𝑔, 𝑜𝑡 − 𝛽KL(𝑝𝜃 (⋅ |𝑜𝑔 , 𝑜𝑡 )||𝑟(⋅)) 𝒟:データセット 𝑟:事前分布
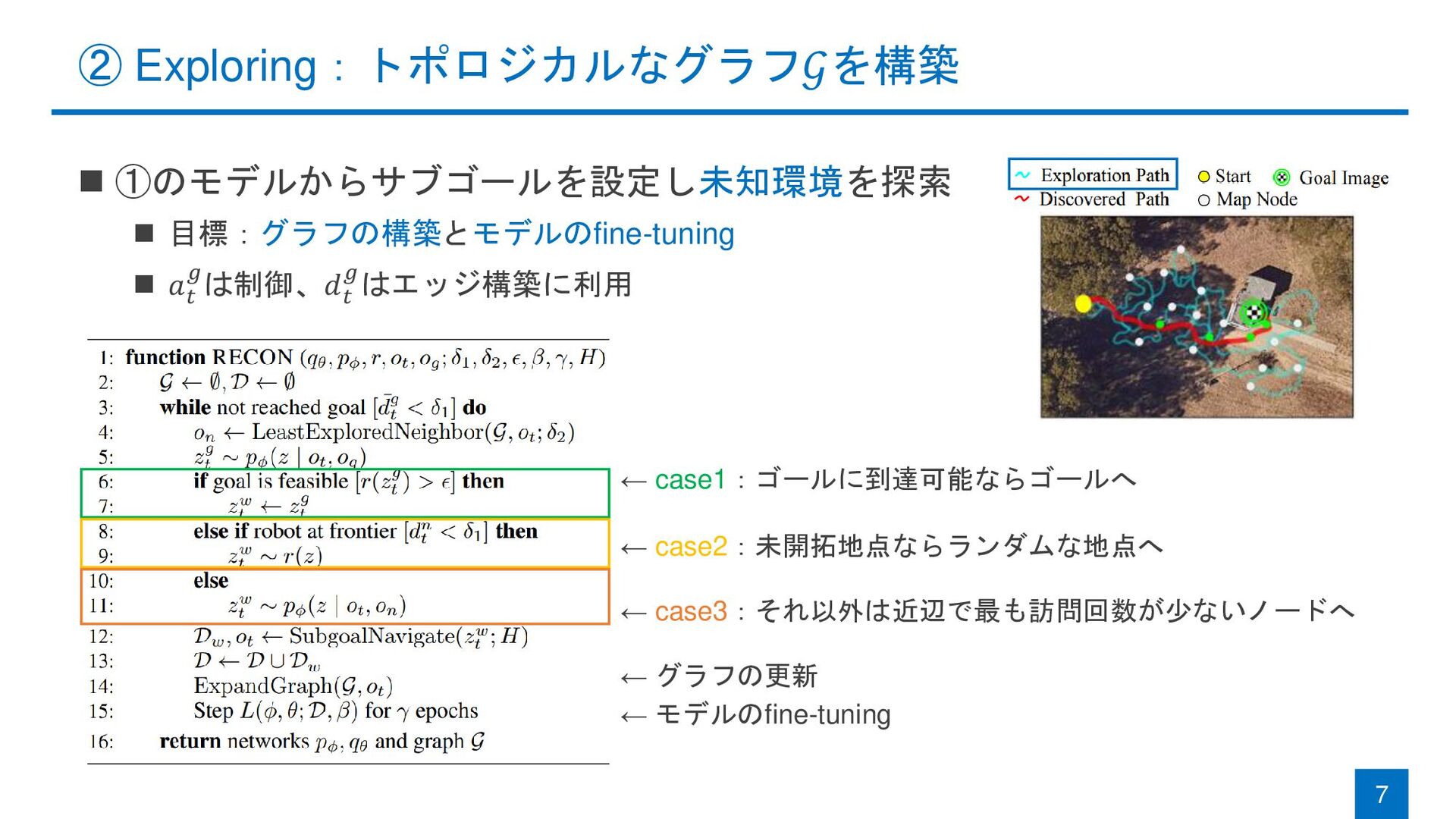
◼ ①のモデルからサブゴールを設定し未知環境を探索 ◼ 目標:グラフの構築とモデルのfine-tuning ◼ 𝑎 𝑡 𝑔は制御、𝑑 𝑡 𝑔はエッジ構築に利用
7 ② Exploring:トポロジカルなグラフ𝒢を構築 ← モデルのfine-tuning ← グラフの更新 ← case1:ゴールに到達可能ならゴールへ ← case2:未開拓地点ならランダムな地点へ ← case3:それ以外は近辺で最も訪問回数が少ないノードへ
◼ スタートからゴールへの最短経路ノードがサブゴール ◼ 目標:画像で指定されたゴールへのnavigation ◼ 同じエリア内ではグラフの再利用が可能 8 ③ Navigating:グラフを基に段階的なサブゴールを設定 ←
𝑣𝑡 :スタート地点のノード ← 𝑣𝑔 :ゴール地点のノード ← ゴールまでの通過ノードをサブゴールに設定
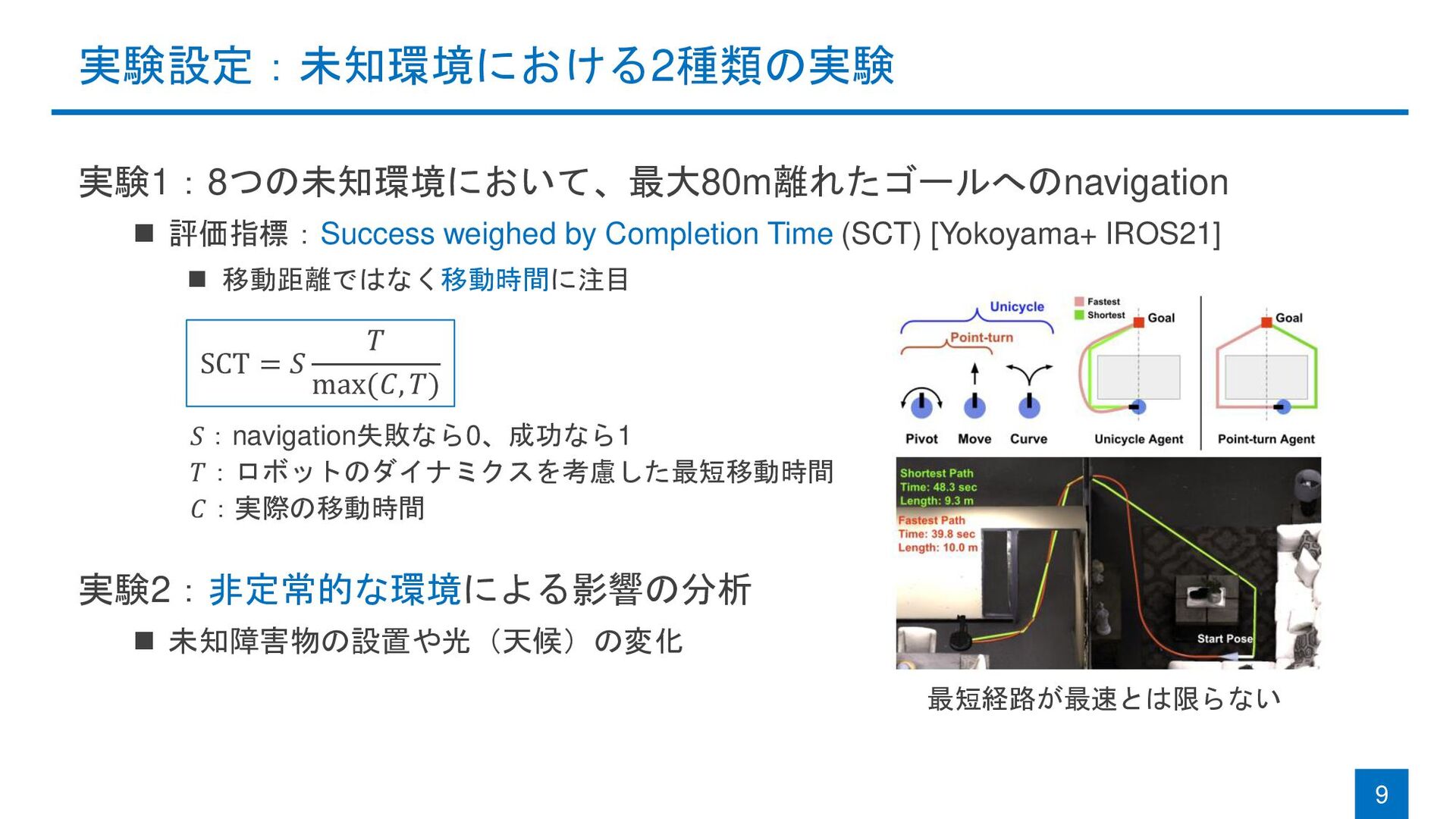
実験設定:未知環境における2種類の実験 実験1:8つの未知環境において、最大80m離れたゴールへのnavigation ◼ 評価指標:Success weighed by Completion Time (SCT) [Yokoyama+
IROS21] ◼ 移動距離ではなく移動時間に注目 実験2:非定常的な環境による影響の分析 ◼ 未知障害物の設置や光(天候)の変化 9 SCT = 𝑆 𝑇 max(𝐶, 𝑇) 𝑆:navigation失敗なら0、成功なら1 𝑇:ロボットのダイナミクスを考慮した最短移動時間 𝐶:実際の移動時間 最短経路が最速とは限らない
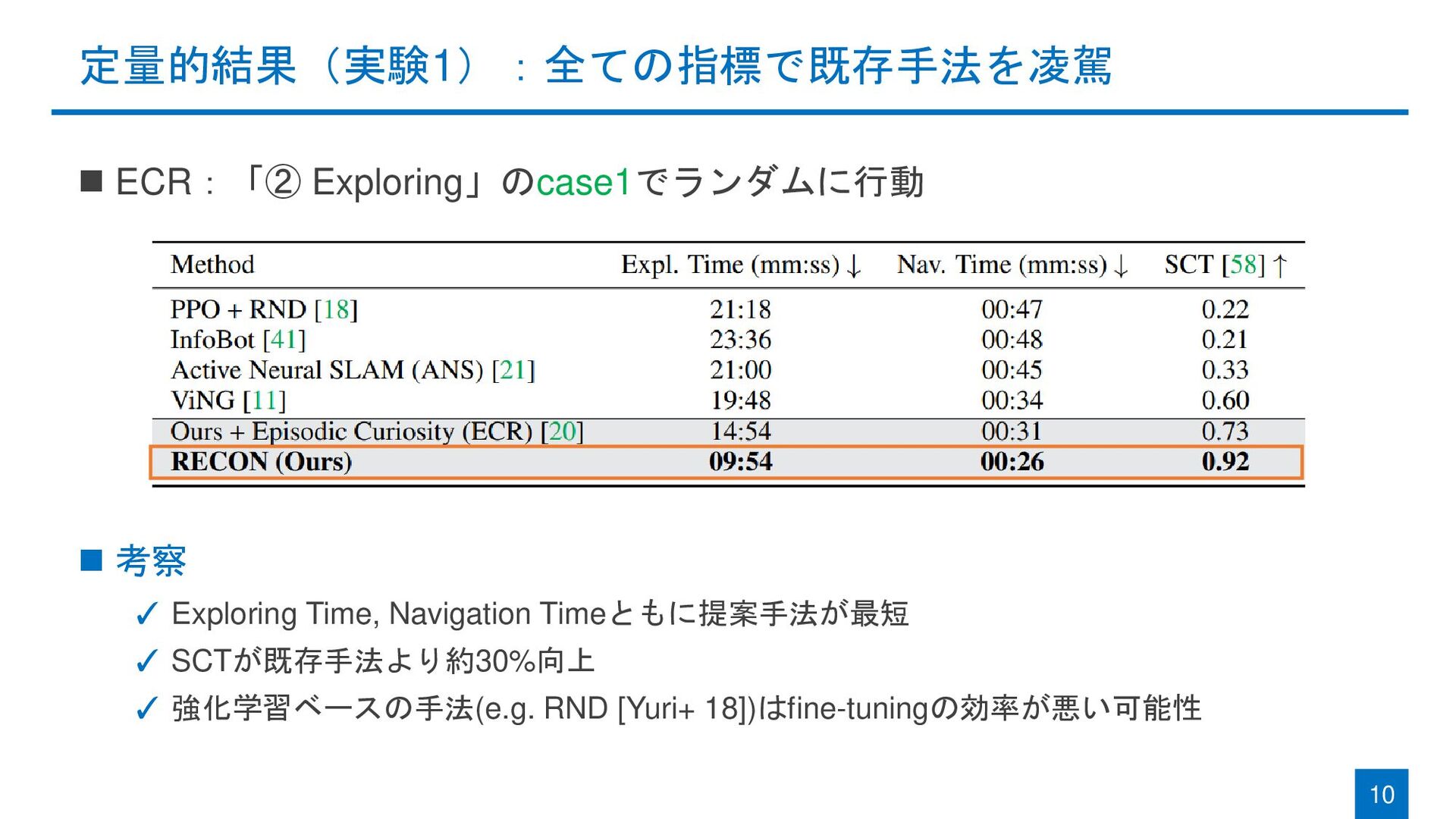
定量的結果(実験1):全ての指標で既存手法を凌駕 ◼ ECR:「② Exploring」のcase1でランダムに行動 ◼ 考察 ✓ Exploring Time, Navigation
Timeともに提案手法が最短 ✓ SCTが既存手法より約30%向上 ✓ 強化学習ベースの手法(e.g. RND [Yuri+ 18])はfine-tuningの効率が悪い可能性 10
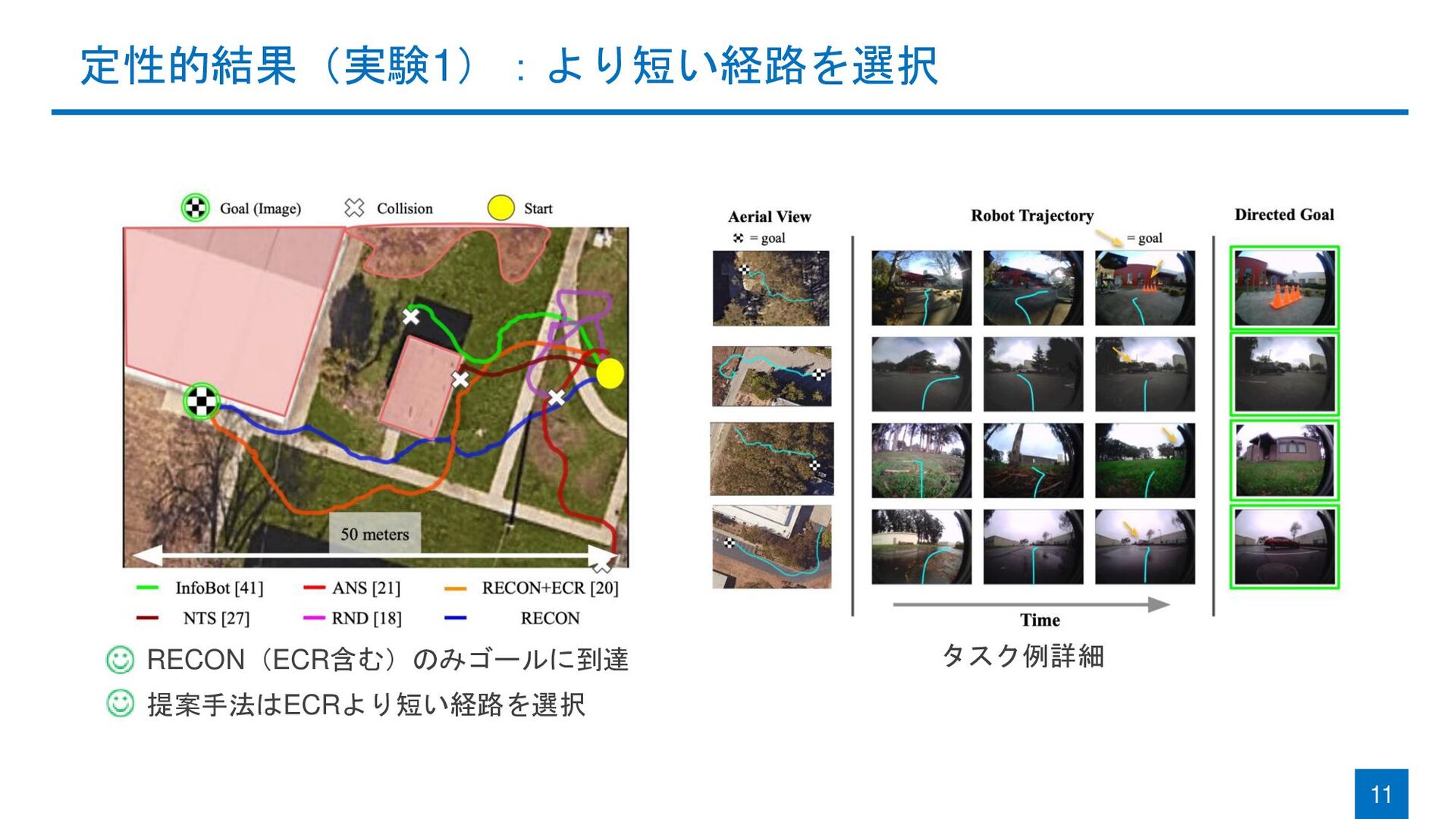
定性的結果(実験1):より短い経路を選択 11 提案手法はECRより短い経路を選択 RECON(ECR含む)のみゴールに到達 タスク例詳細
定性的結果(実験2):非定常的な環境に頑健 ◼ 平常時 ◼ 未知障害物を回避 ◼ 光(天候)に影響されづらい 12 ゴミ箱 カラーコーン
自動車 夕暮れ 晴れ 雨 / 曇り ゴール画像 平常時のパス
まとめ 背景 ✓ 未知の屋外実環境における、画像による頑健なnavigation 提案 ✓ 大規模オフラインデータを用いた、ゴールまでの距離と行動に関する潜在変数モデル ✓ 探索時におけるトポロジカルなグラフの構築 結果
✓ 20分以内の探索で最大で80m遠方までのnavigationに成功 ✓ 非定常的な環境への頑健性を確認 13
Appendix:実装の詳細 14 アーキテクチャ ハイパーパラメータ
Appendix:その他の疑似コード 15
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}