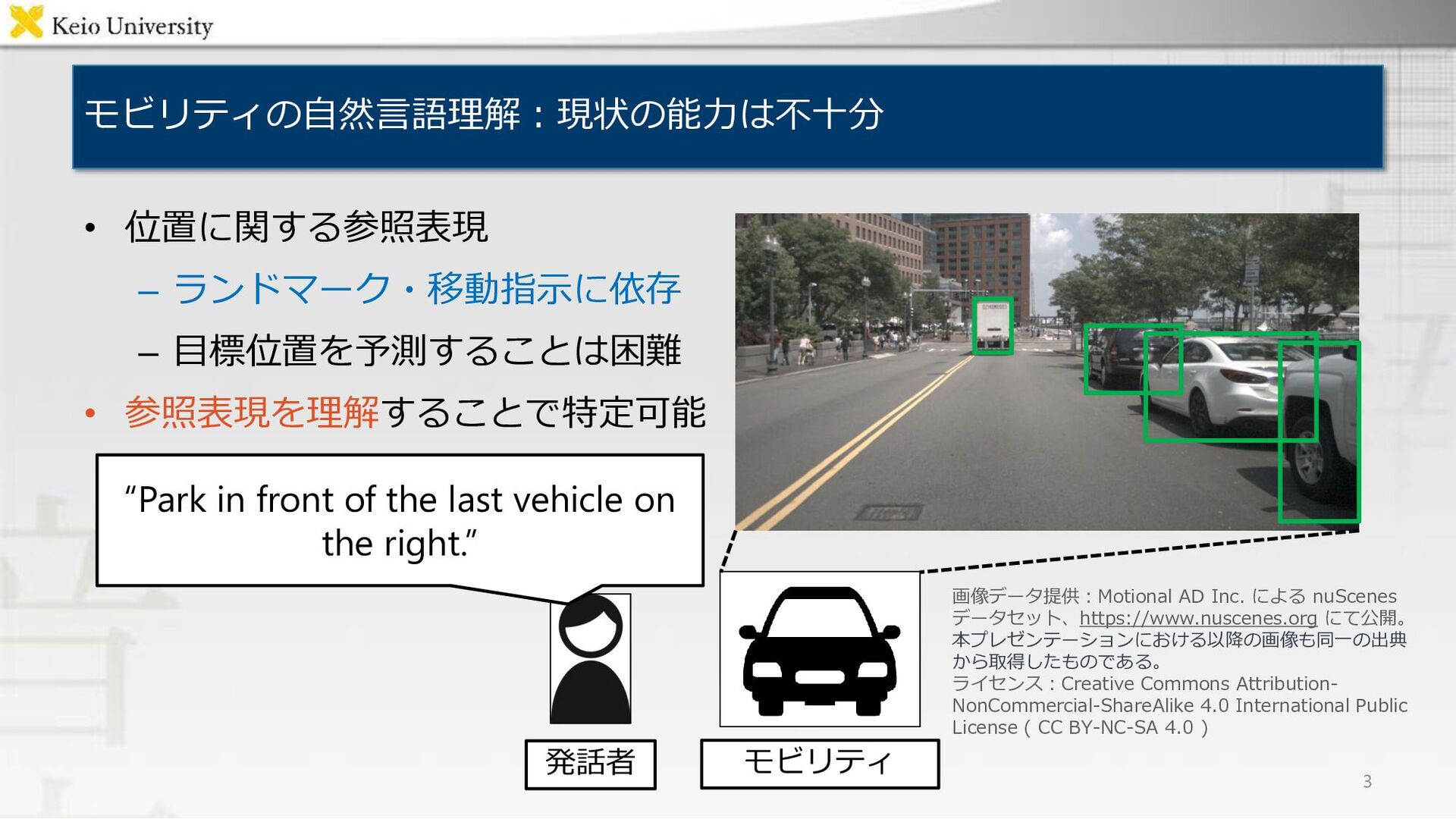
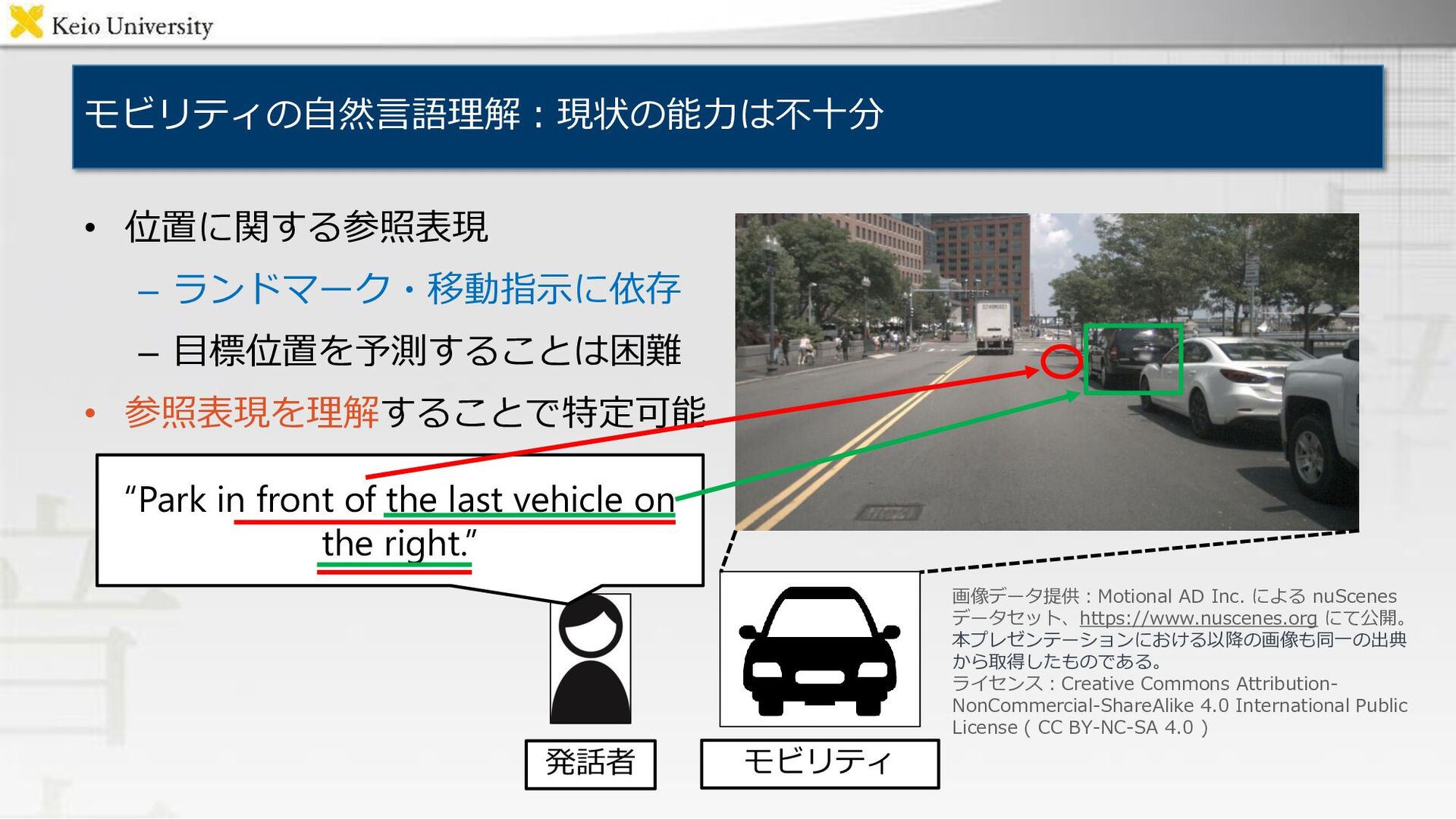
発話者 “Park in front of the last vehicle on the right.” 3 画像データ提供:Motional AD Inc. による nuScenes データセット、https://www.nuscenes.org にて公開。 本プレゼンテーションにおける以降の画像も同一の出典 から取得したものである。 ライセンス:Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International Public License ( CC BY-NC-SA 4.0 )
発話者 “Park in front of the last vehicle on the right.” 画像データ提供:Motional AD Inc. による nuScenes データセット、https://www.nuscenes.org にて公開。 本プレゼンテーションにおける以降の画像も同一の出典 から取得したものである。 ライセンス:Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International Public License ( CC BY-NC-SA 4.0 )
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![既存手法(1/2):関連分野としてマルチモーダルなRECモデルと屋外でのVLN モデルの研究 タスク 手法 概要 REC ViLBERT [Lu+, NeurIPS2019] 画像と自然言語の相互表現を学習](https://files.speakerdeck.com/presentations/4bd9b59980524c159be82fa822b5bc1c/slide_5.jpg){kind=link}
![既存手法(2/2):関連手法は目標領域をマスクで予測するが,依然として目標領域の 曖昧さが残る タスク 手法 概要 RES [Rufus+, IROS2021] DETR [Carion+,](https://files.speakerdeck.com/presentations/4bd9b59980524c159be82fa822b5bc1c/slide_6.jpg){kind=link}
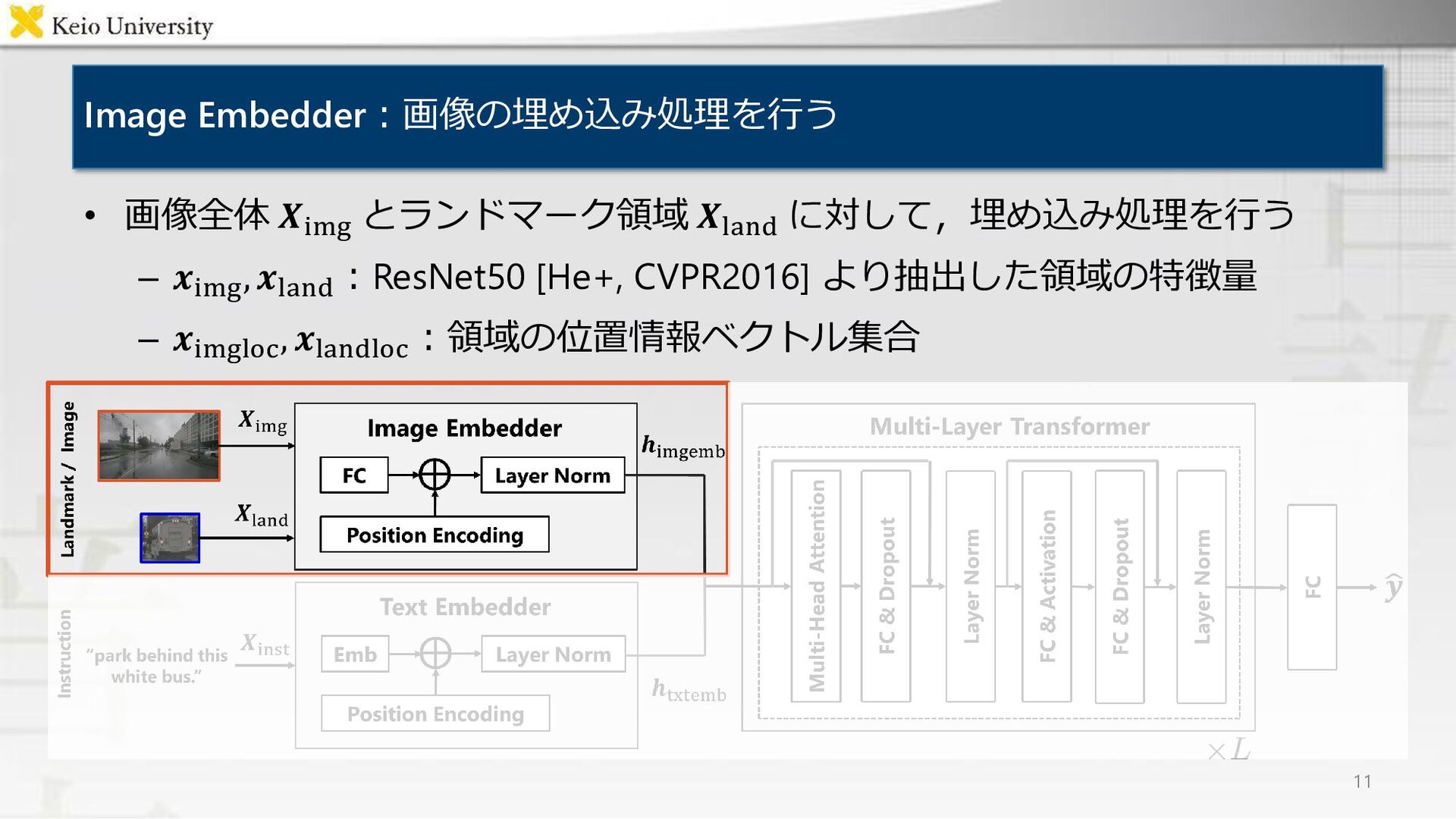
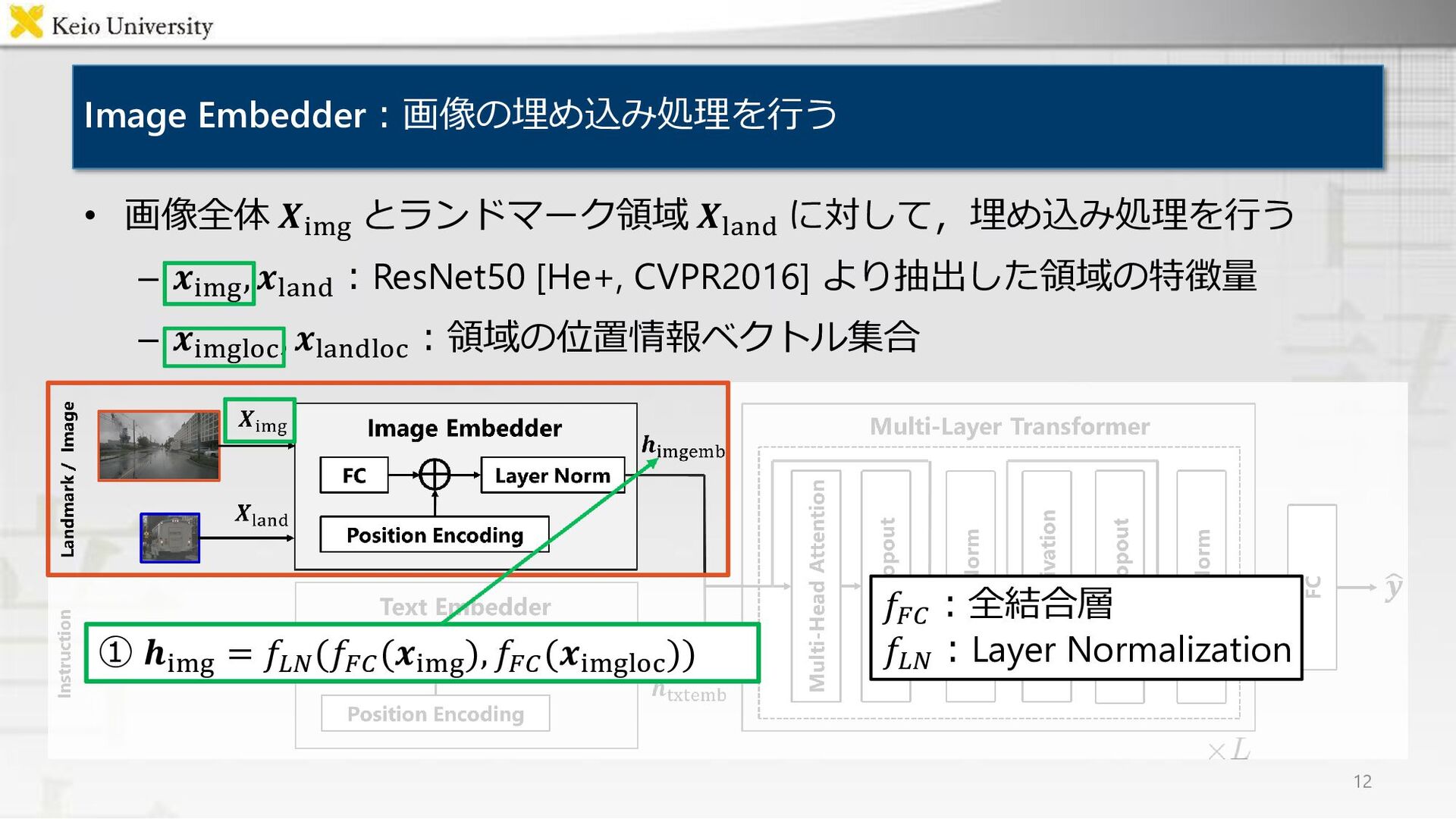
![提案手法:UNITER [Chen+, ECCV2020] を回帰タスクとして拡張 • UNITERを回帰タスクとして拡張したUNITER Regressorの提案 – 入力:画像全体・ランドマーク領域・移動指示文 –](https://files.speakerdeck.com/presentations/4bd9b59980524c159be82fa822b5bc1c/slide_7.jpg){kind=link}
![Text Embedder:移動指示文の埋め込み処理を行う • 移動指示文 𝑿inst に対して,WordPiece [Wu+, 16] によってトークン化を行う –](https://files.speakerdeck.com/presentations/4bd9b59980524c159be82fa822b5bc1c/slide_8.jpg){kind=link}
![Text Embedder:移動指示文の埋め込み処理を行う • 移動指示文 𝑿inst に対して,WordPiece [Wu+, 16] によってトークン化を行う –](https://files.speakerdeck.com/presentations/4bd9b59980524c159be82fa822b5bc1c/slide_9.jpg){kind=link}
{kind=link}
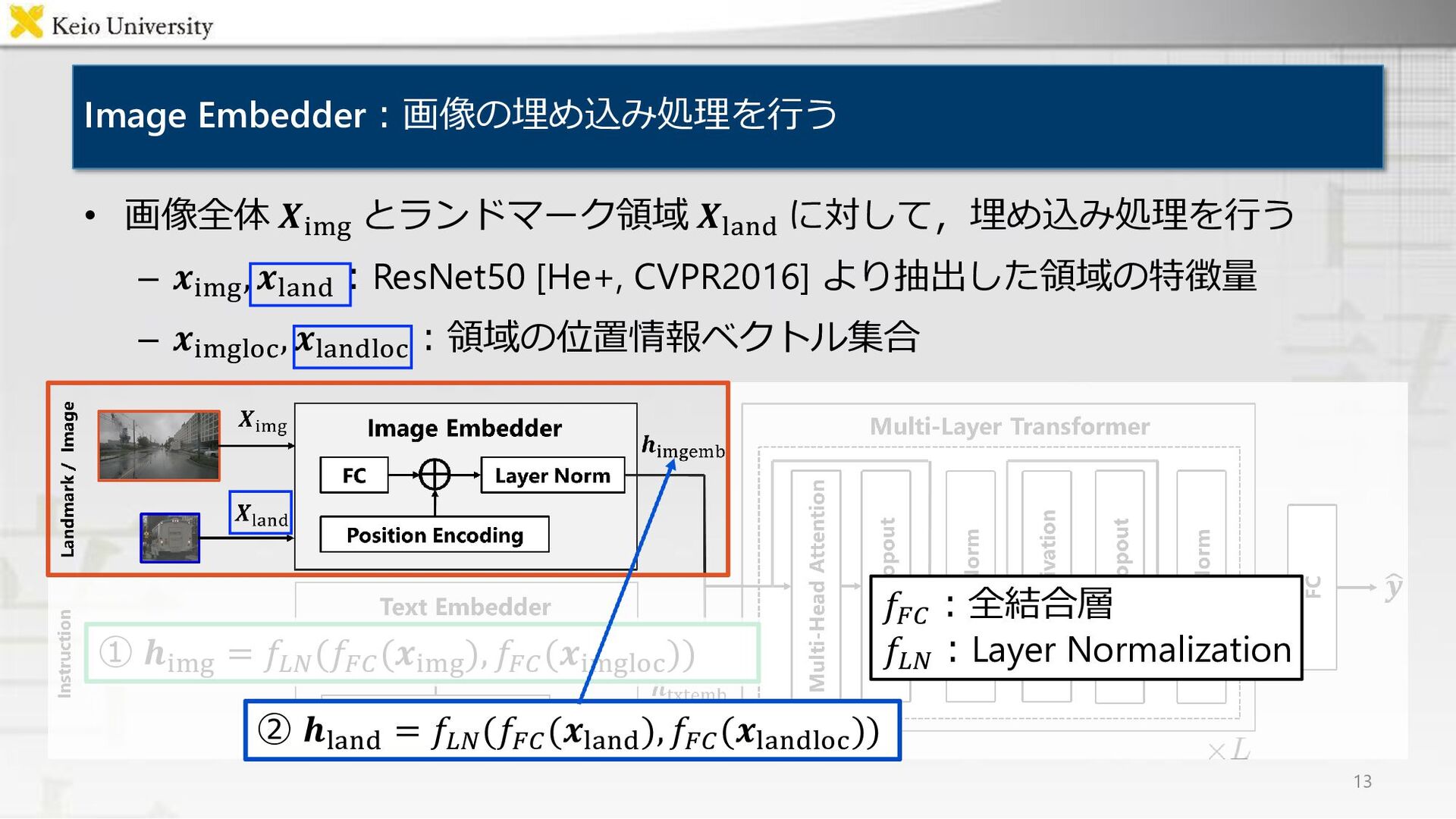
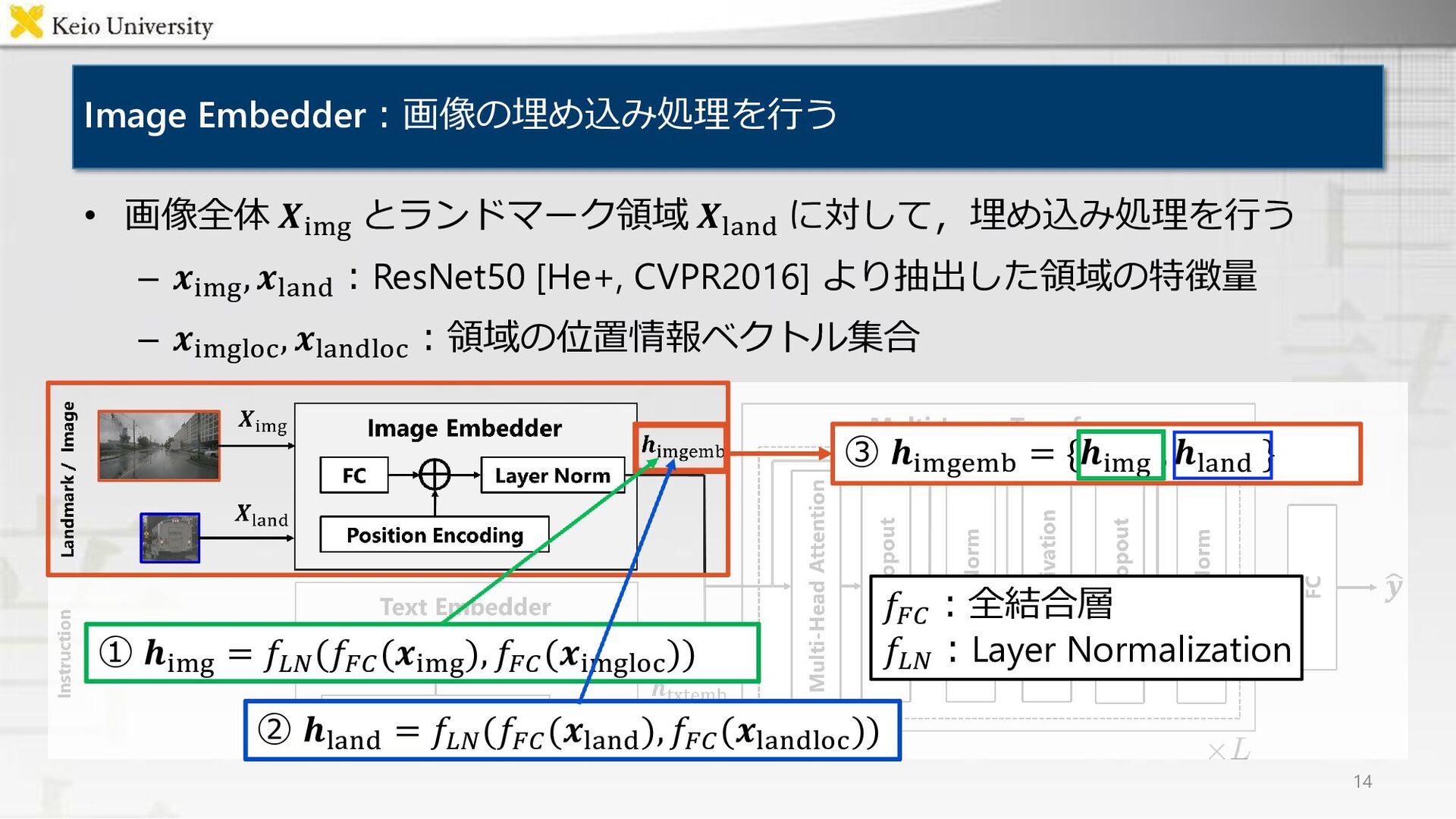
{kind=link}
{kind=link}
{kind=link}
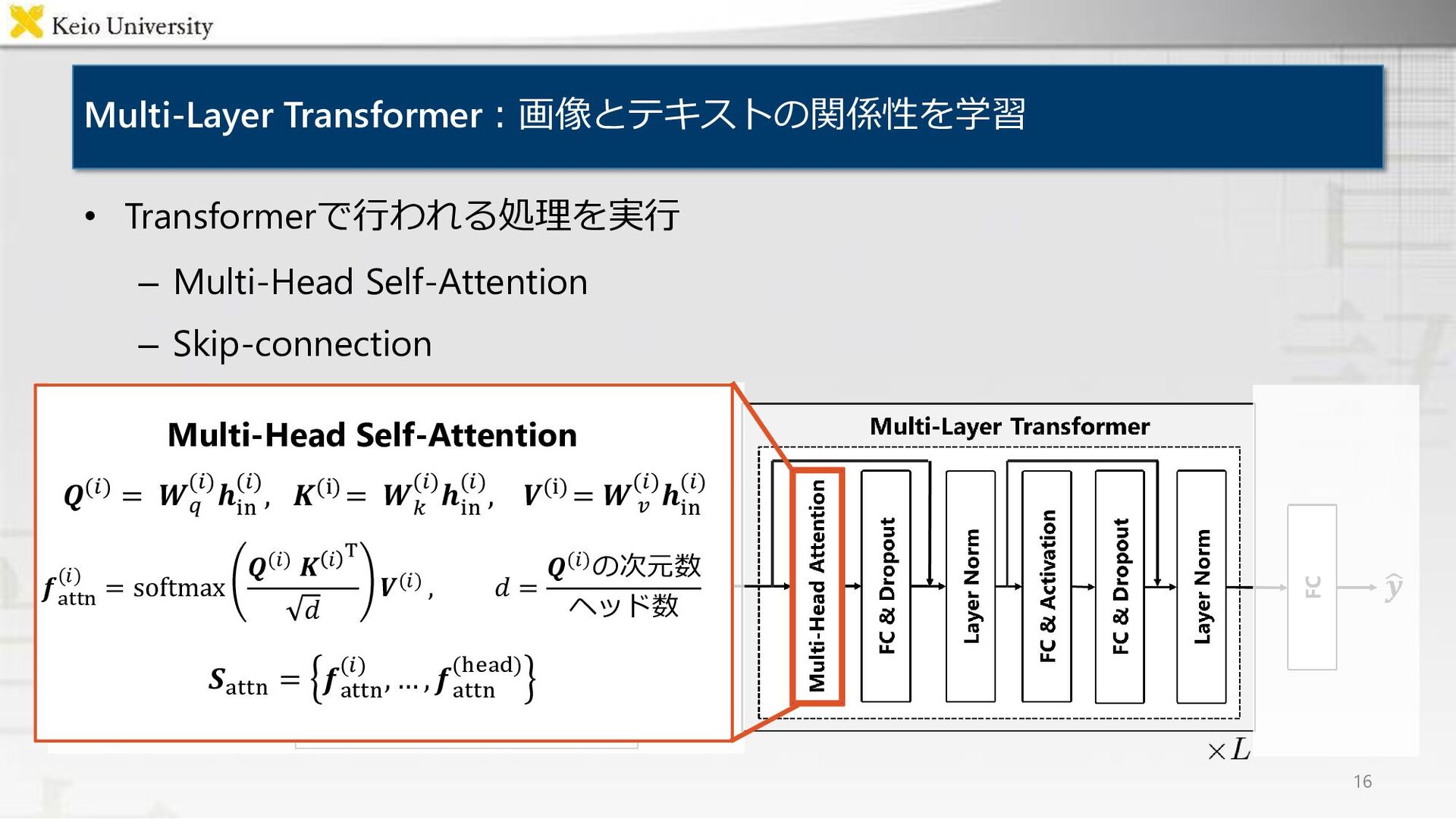
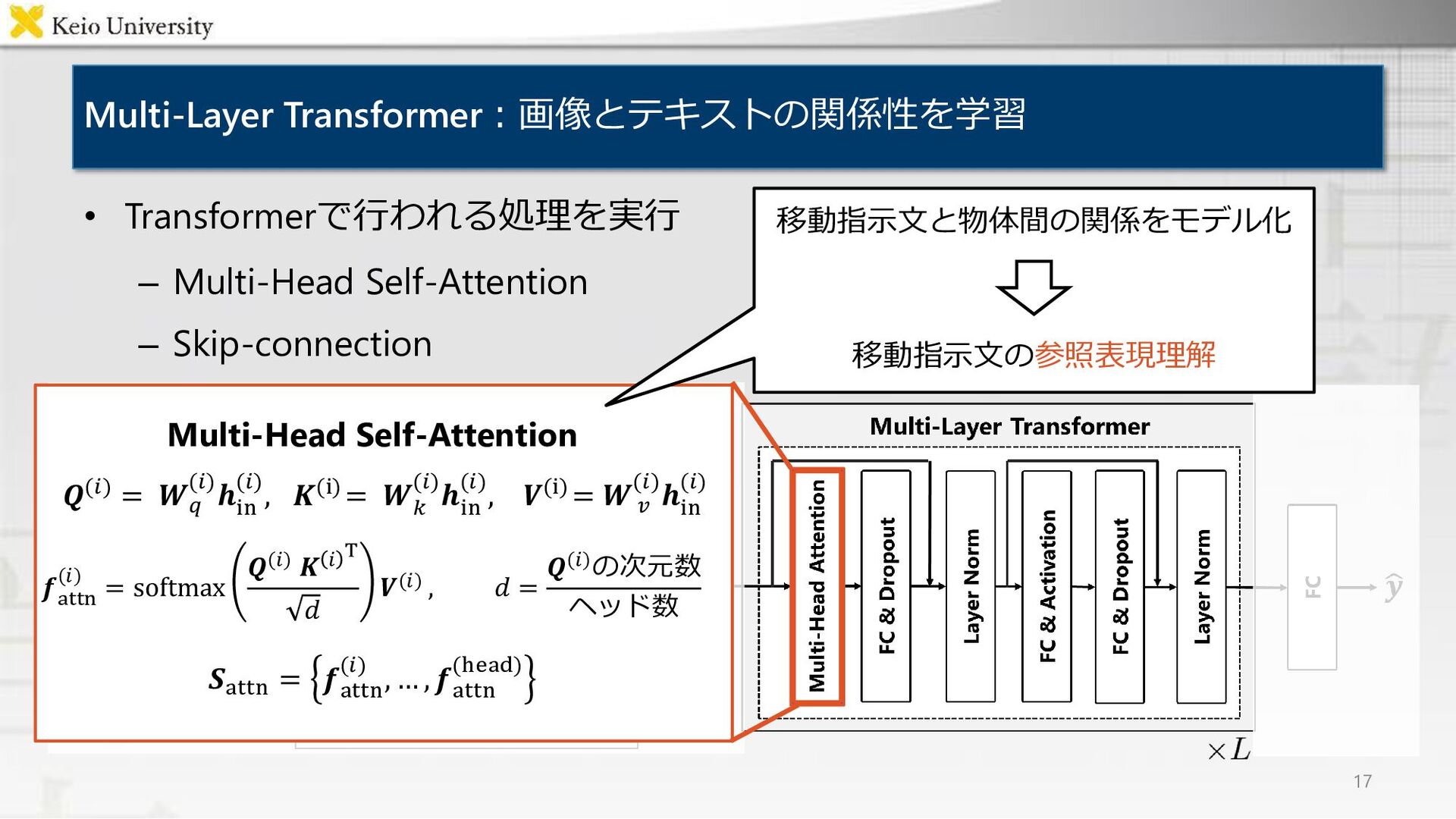
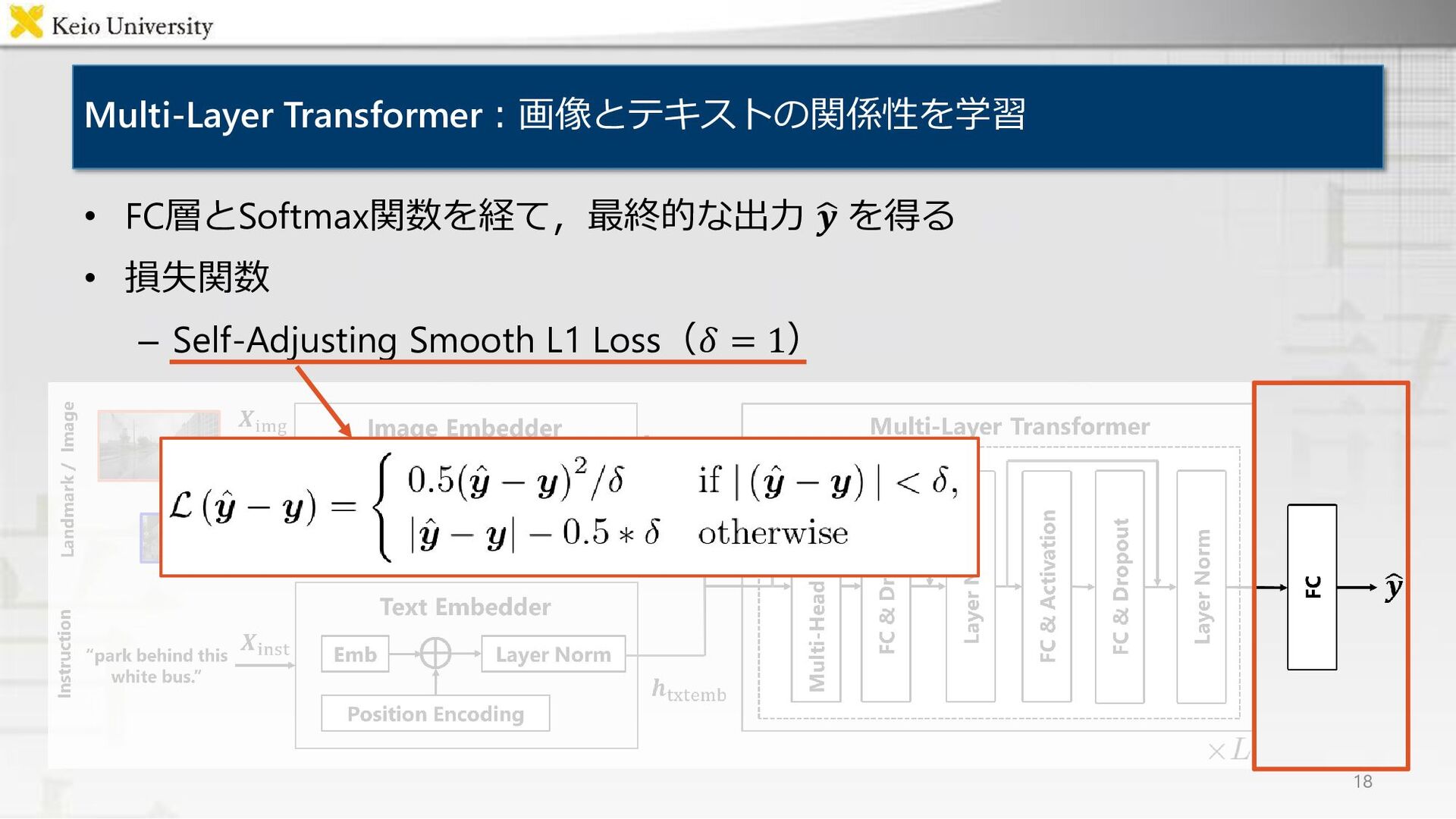
![Multi-Layer Transformer:画像とテキストの関係性を学習 15 • 𝐿層の Transformer [Vaswani+, NeurIPS17] で構成 •](https://files.speakerdeck.com/presentations/4bd9b59980524c159be82fa822b5bc1c/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Talk2Carデータセットの問題点:目標位置の正解データが与えられていない • Talk2Car [Deruyttere+, 2019] – 自動運転における実世界の 自然言語理解データセット – 発話内容からランドマーク領域](https://files.speakerdeck.com/presentations/4bd9b59980524c159be82fa822b5bc1c/slide_18.jpg){kind=link}
{kind=link}
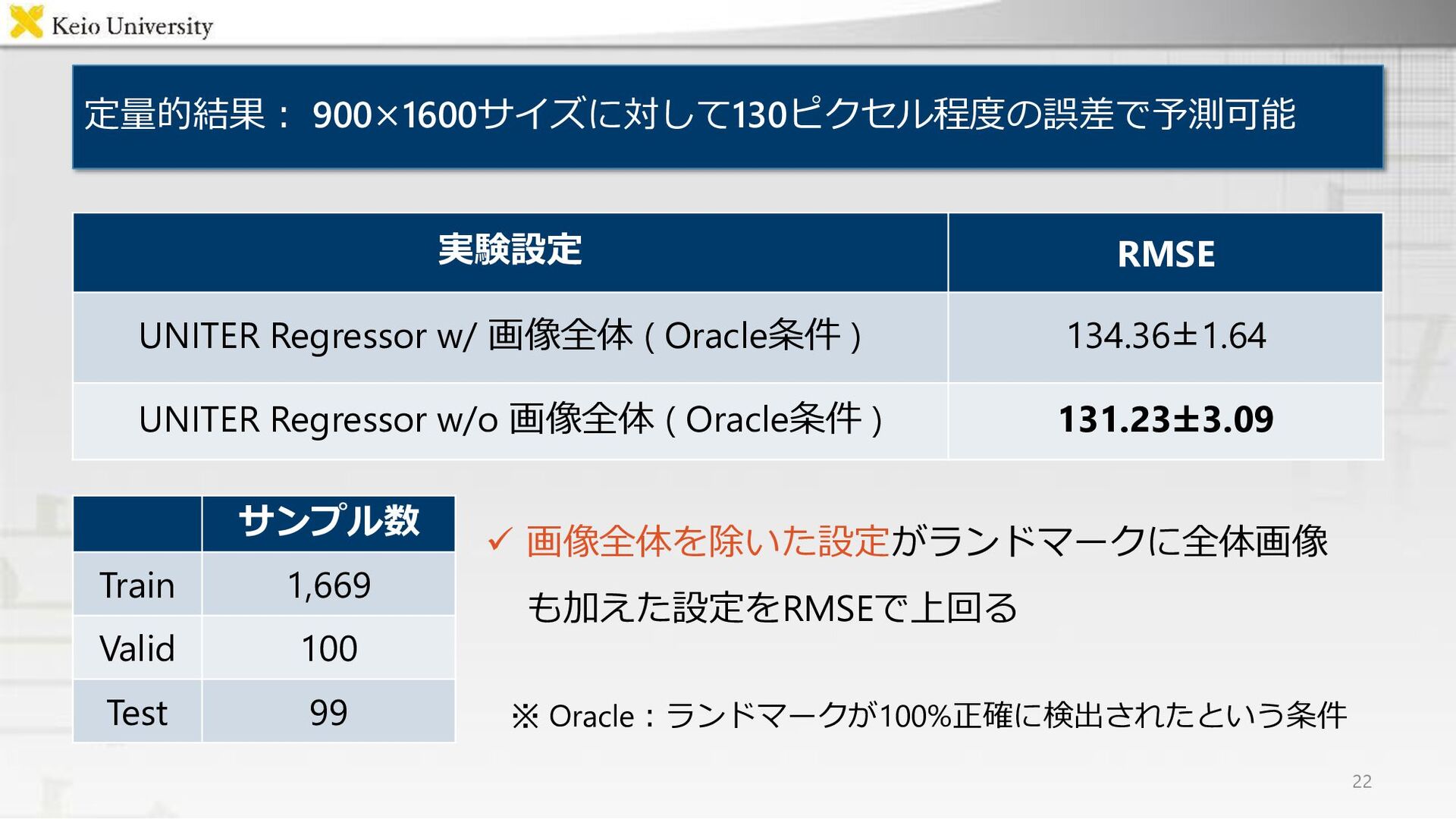
{kind=link}
{kind=link}
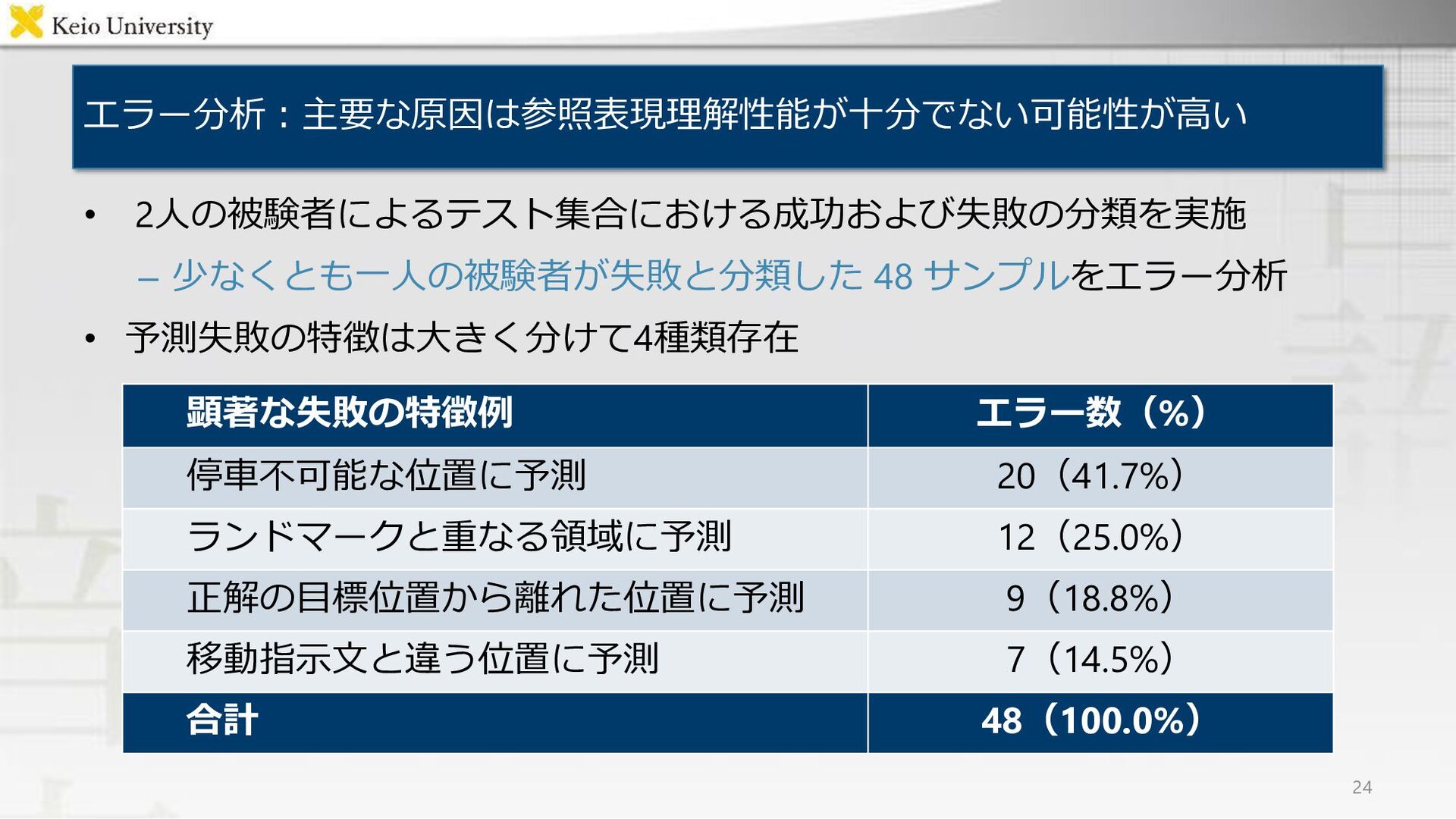
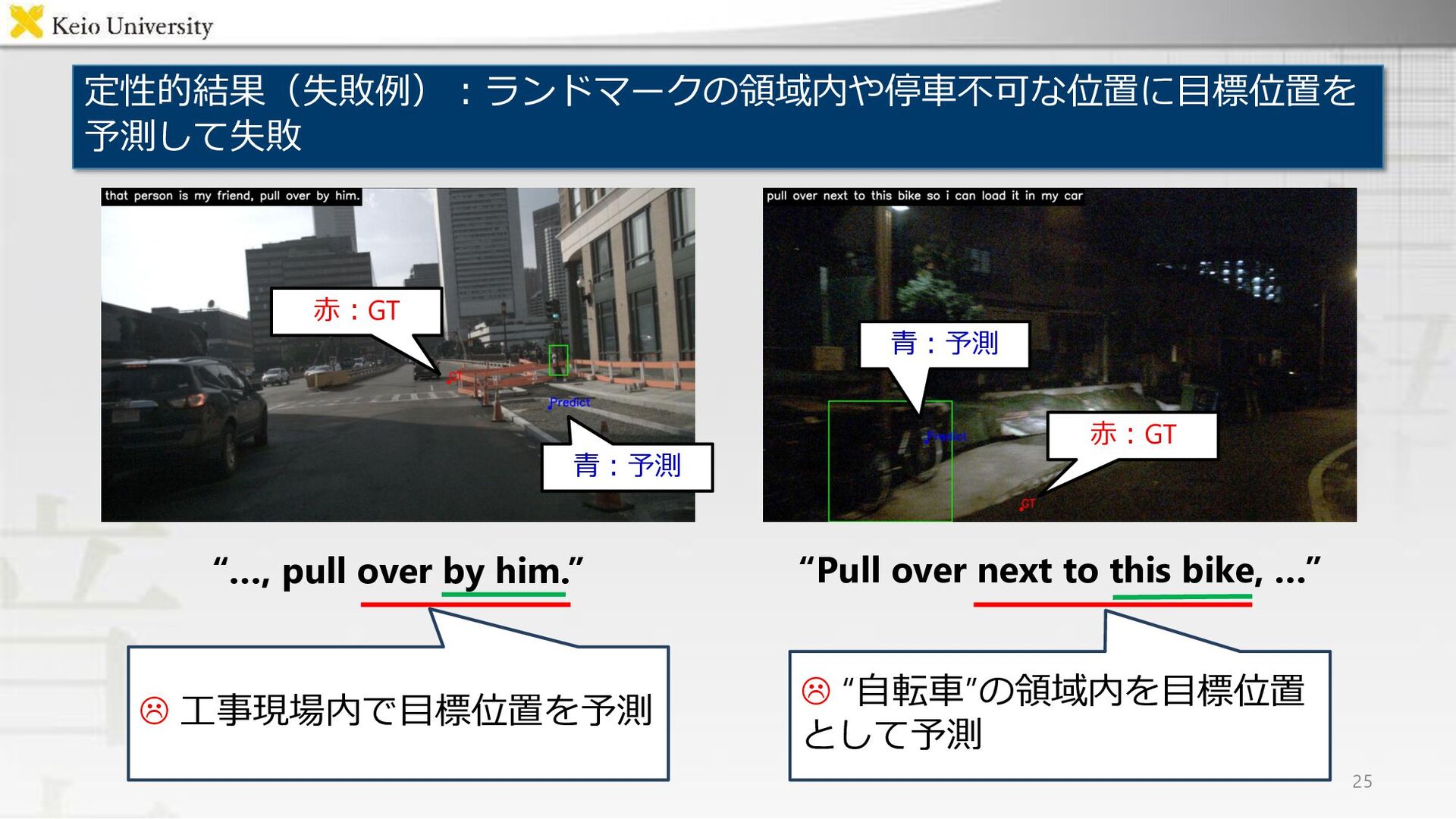
{kind=link}
{kind=link}
{kind=link}
{kind=link}