Share
8月13日に行われたオンラインの勉強会 AIMTG にて、 Prompt Depth Anything (DA)について紹介しました。
動画 https://youtu.be/dkhkAVadbII?t=3652
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
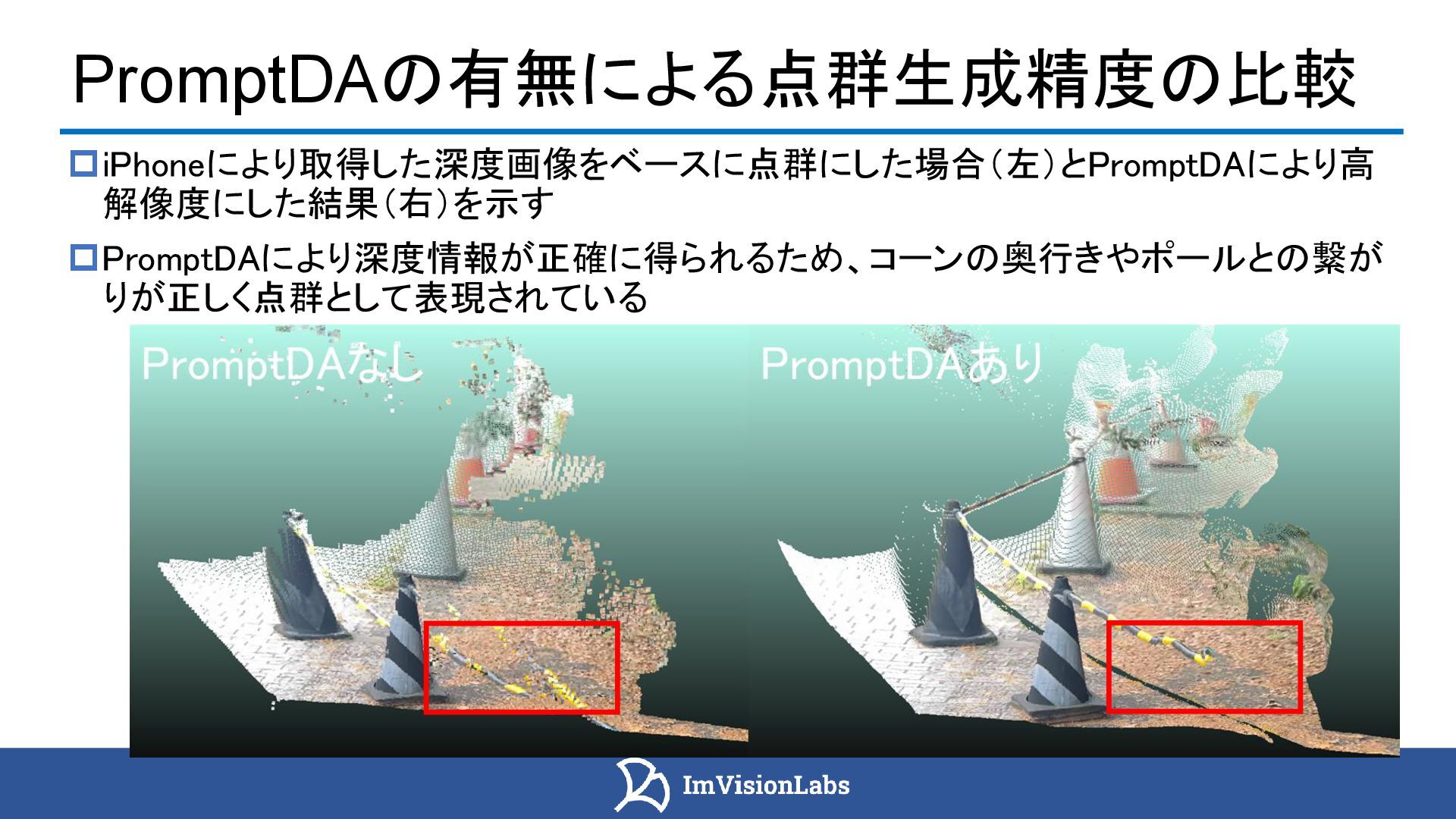{kind=link}
{kind=link}
{kind=link}
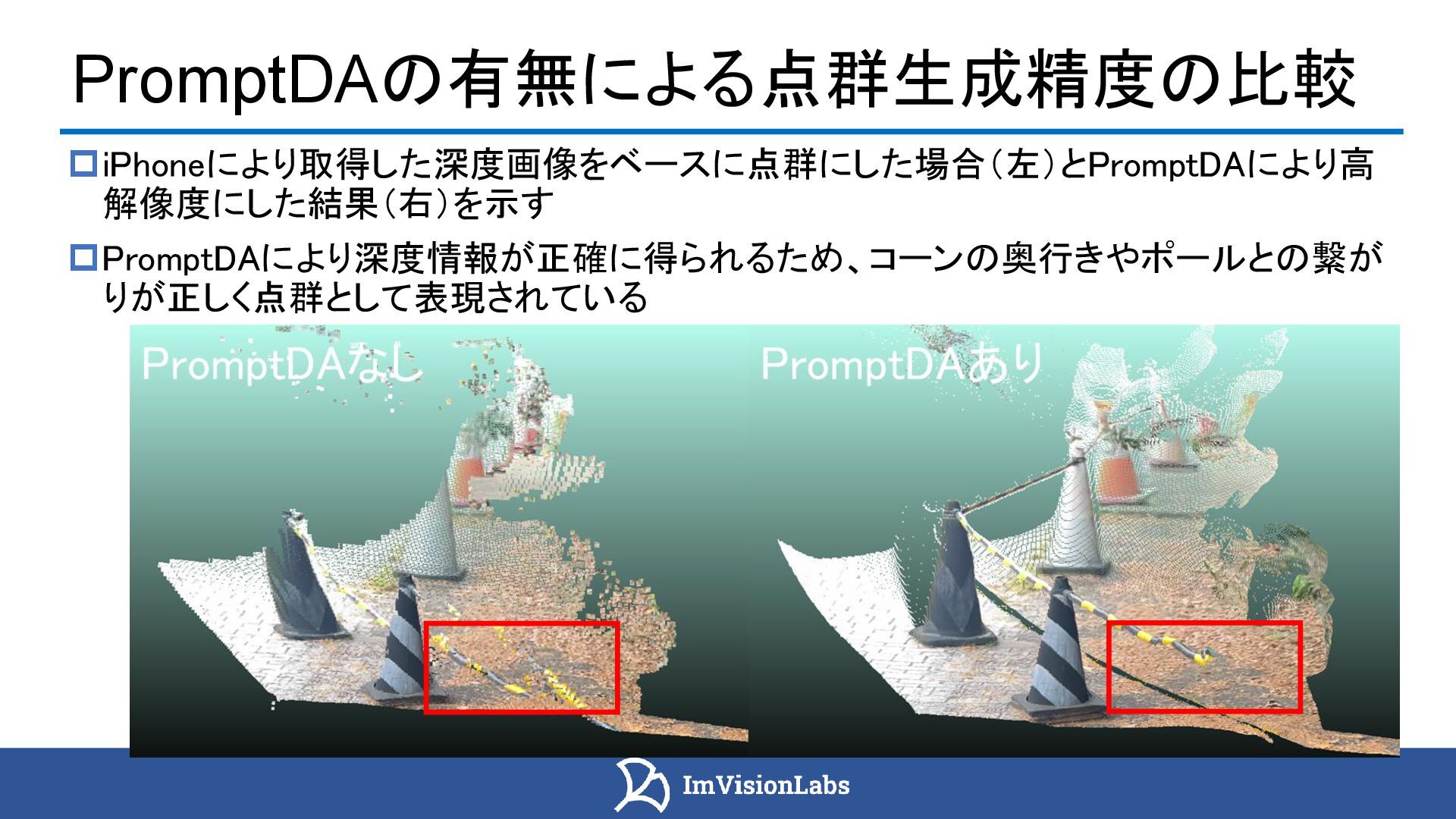{kind=link}
{kind=link}