• Review of Part 1 • Overview of new pipeline use cases • Overview of components • Glue, Redshift, Redshift Spectrum, Elasticsearch, and more Athena • Demo and Console tour of components • Look at Parquet data in s3, create Athena tables/queries • Set ES privs and query from command line • Query Redshift using join of standard and external Spectrum-sourced table • Dive into IaC • Meetup News & Notes • Q&A AGENDA 2
• Over a decade of experience in the industry • Software Development • .NET (C# and VB.NET) • JVM (Scala) • JavaScript • Data Streaming Architectures • Kafka, Kinesis, Event Hubs • Application Architecture • AWS, Azure, and on-prem solutions • Incessant traveler with a new-found skiing addiction • I Live in Denver, by way of St Louis, and grew up in TN INTRO: KEVIN TINN 3
available at https://github.com/kevasync/aws-meetup-group-data-services This link is available in the comments of the Meetup deets: https://www.meetup.com/AWSMeetupGroup/events/270511655/ Part 1 Meetup w/ useful links https://www.meetup.com/AWSMeetupGroup/events/269768602/ Please join the Meetup if you haven’t already REPO INFO 4
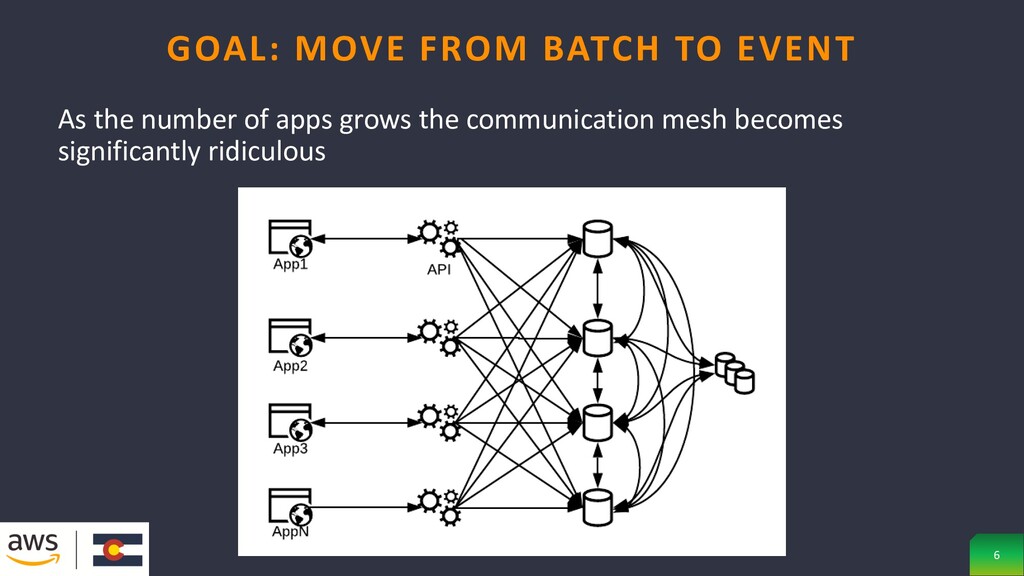
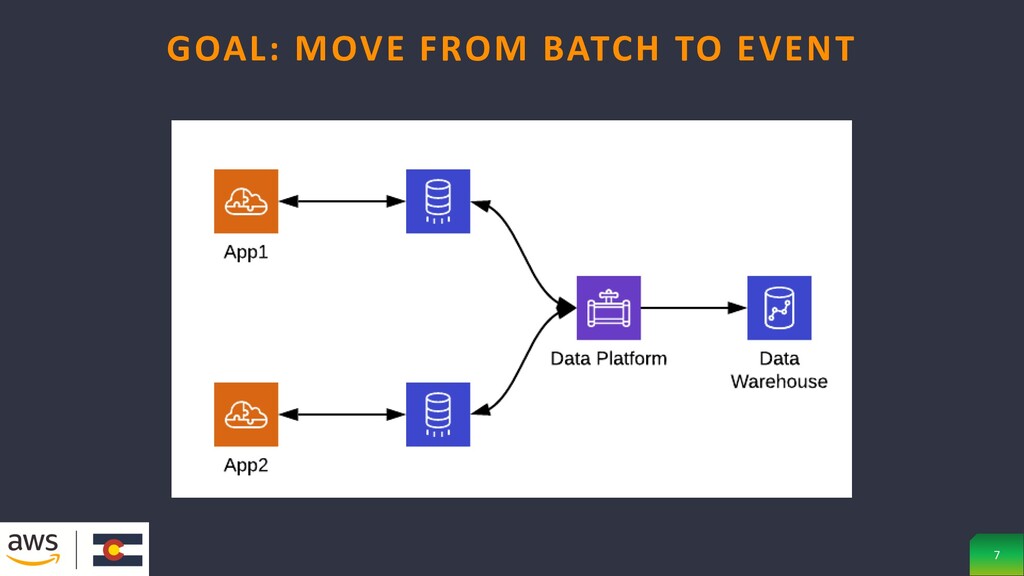
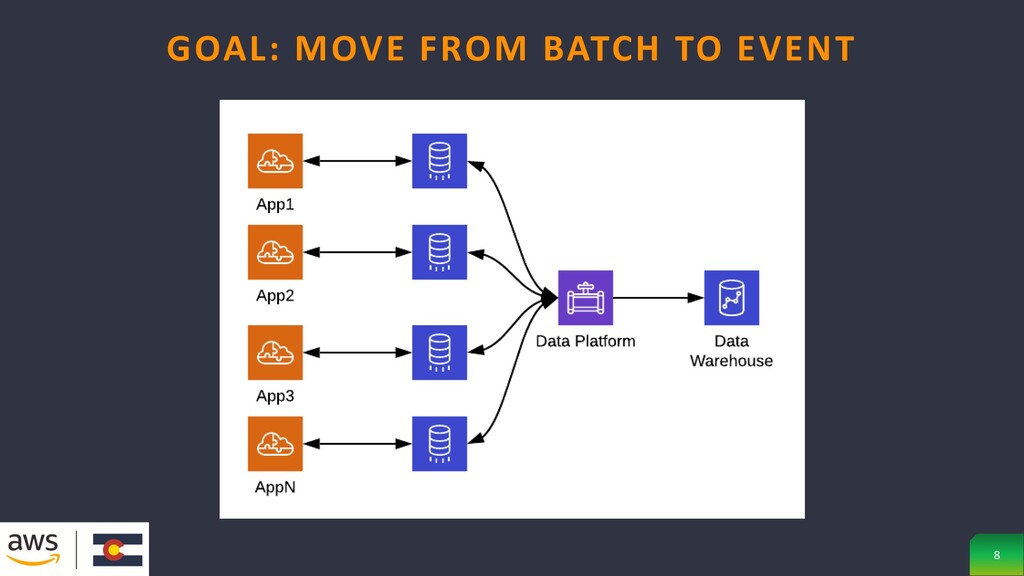
batches, which only allows apps to be as up to date, highly dependent systems may even write to each other’s persistence layer GOAL: MOVE FROM BATCH TO EVENT 5
out repo from my Terraform and Pulumi Meetup: https://github.com/kevasync/aws-meetup-group-terraform • Wanted to use Pulumi on this to try out the new v2.0 release • Introduces full fidelity between languages, including full C# support • Love Terraform too INTRO TO CODED INFRA AND DEPLOYMENT 9
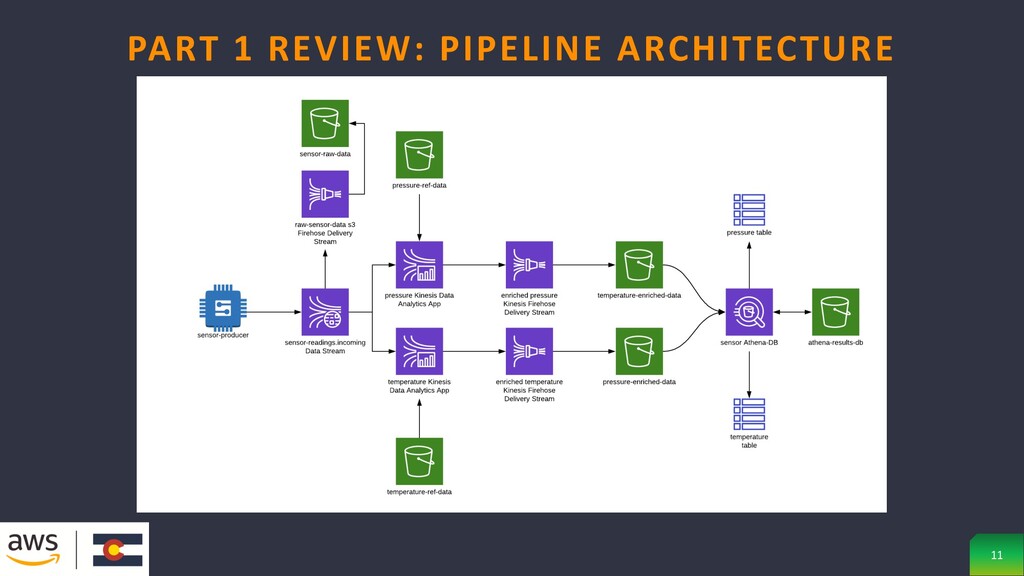
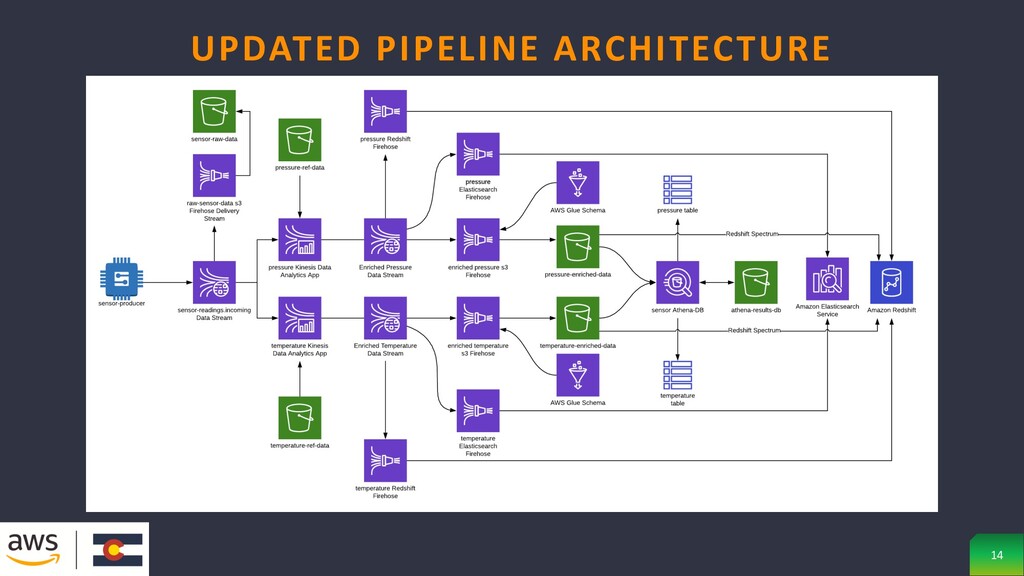
data • Produce messages for temperature and pressure readings at a manufacturing site • Raw data is stored for compliance purposes • Data is separated into separate streams of data: one for temp, the other for pressure • Enrich pressure data with altitude reference data • Enrich temperature data with ambient weather reference data • Store enriched data in s3 data lake with Athena query capabilities PART 1 REVIEW: DATA PIPELINE OVERVIEW 10
data ingestion and processing service optimized for streaming data • Kinesis Data Firehose is a fully managed service for delivering real-time streaming data to destinations • Kinesis Data Analytics allows for transforming, enriching, and analyzing streaming data using a SQL syntax • S3 or Simple Storage Service is a service offered by AWS that provides object storage through a web service interface • Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL PART 1 REVIEW: COMPONENTS 12
had with Athena only returning a single result • Adjust Firehose to convert data to Parquet format prior to loading into s3 • Parquet: columnar storage file format • Organizing by column allows for better compression, as data is more homogeneous • Load data into Elasticsearch from data streams for high-performance full- text application queries • Kinesis Data Analytics allows for transforming, enriching, and analyzing streaming data using a SQL syntax • S3 or Simple Storage Service is a service offered by AWS that provides object storage through a web service interface • Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL PART 2 USE CASES 13
load (ETL) service that makes it easy for customers to prepare and load their data for analytics. • We’re using it for the purpose of transformation to Parquet in our enriched s3 Firehoses • Components/Features • Data Catalog • Schema detection • Code generation • Data cleansing • Job scheduling • Streaming ETL (Hey that’s us!) COMPONENTS: GLUE 15
makes it easy for you to deploy, secure, and run Elasticsearch cost effectively at scale. • Based on Apache Lucene full-text search (From wiki): • While suitable for any application that requires full text indexing and searching capability, Lucene is recognized for its utility in the implementation of Internet search engines and local, single-site searching. • Lucene includes a feature to perform a fuzzy search based on edit distance. • AWS provides managed version, but with dedicated cluster that constantly incurs cost COMPONENTS: ELASTICSEARCH 16
part of the larger cloud-computing platform Amazon Web Services. • Wiki: The name means to shift away from Oracle, red being an allusion to Oracle, whose corporate color is red and is informally referred to as "Big Red.” • Industry-leading performance • Efficient Storage • Massive Scalability (Petabyte-scale storage and analytics) • Extremely performant queries against vast columnar storage volumes • Improved query performance over large dataset • Managed EDW • Very competitive costs COMPONENTS: REDSHIFT 17
warehouses that unify data from a variety of internal and external sources • In-place queries allow data to be joined with internal Redshift sources while not requiring that data be stored in Redshift • Built-in to the Redshift SQL query language • Only pay for queries/scans that you run • It can still get expensive. If querying the same external data constantly, store it in Redshift * exabyte: 1 EB = 1018bytes = 10006bytes = 1000000000000000000B = 1000 petabytes = 1millionterabytes = 1billiongigabytes COMPONENTS: REDSHIFT SPECTRUM 19
Create Athena tables • Demo data going through Analytics Applications • Py data producer • View data in raw, enriched, and reference buckets • Dive into Analytics Application in console • SQL Syntax • Check out parquet data • Athena tables and full query capabilities demo CONSOLE STEPS 20
Create Redshift reference table data • Create Redshift Spectrum schema/database • Join S3 data and Redshift data using Redshift Spectrum queries CONSOLE STEPS 21
event driven architectures • Overview of demo architecture • Deployment of coded infrastructure • Overview of AWS components used • Manual steps to complete setup of Glue, Athena, Redshift, and Elasticsearch • Thank you for coming • Please message to me if you have further questions, or to talk shop CONCLUSION 23
• Upcoming: IoT Core, Last Wednesday of June – Kevin Tinn/Austin Loveless • We are updating the cadence of the Meetup • Going to once a month, the last Wednesday of every month • Hit us up and let us know what you would like to learn about, or if you are interested in speaking MEETUP NEWS AND NOTES 25
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}