<- Option(dir.listFiles).toList logDir <- dirContent if logDir.isDirectory } yield { ★複数スレッドを起動して初期化処理を並列実行★ CoreUtils.runnable { debug("Loading log '" + logDir.getName + "'") (※省略) ★以下でエラー発生すると、どこに問題があるかがわからずに初期化失敗★ val current = Log(dir = logDir, config = config, logStartOffset = logStartOffset, recoveryPoint = logRecoveryPoint, maxProducerIdExpirationMs = maxPidExpirationMs, scheduler = scheduler, time = time, brokerTopicStats = brokerTopicStats) if (logDir.getName.endsWith(Log.DeleteDirSuffix)) { this.logsToBeDeleted.add(current) } else { val previous = this.logs.put(topicPartition, current) if (previous != null) { throw new IllegalArgumentException( "Duplicate log directories found: %s, %s!".format( current.dir.getAbsolutePath, previous.dir.getAbsolutePath)) LogLevel=debug設定、 スレッドIDと「Loading log」を用いて一つ一つ切分け (該当スレッドでLoading logが 最後に出力されるログが破損被疑) ファイル全削除>全同期は 容量的に避けたかったため。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
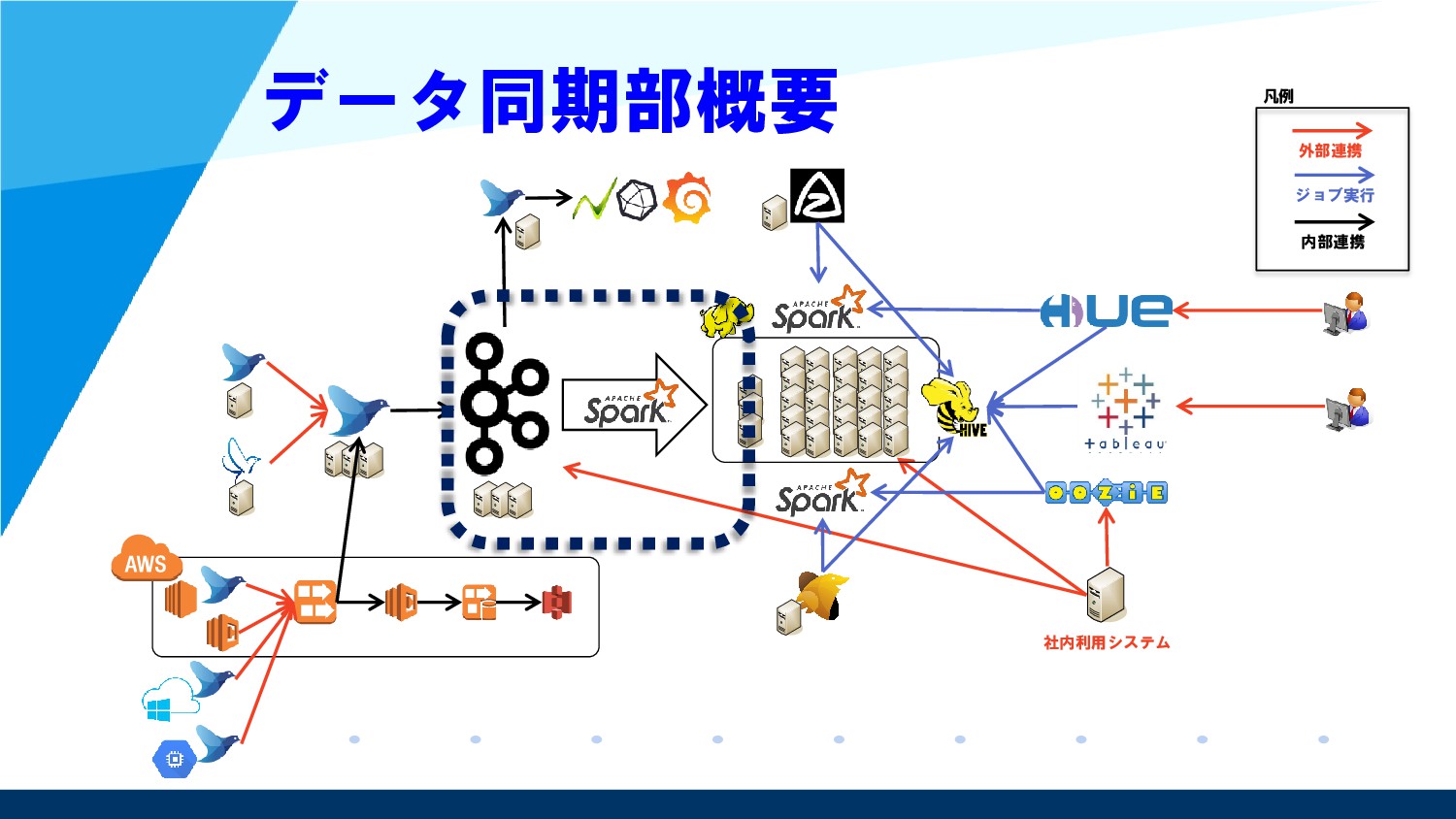{kind=link}
{kind=link}
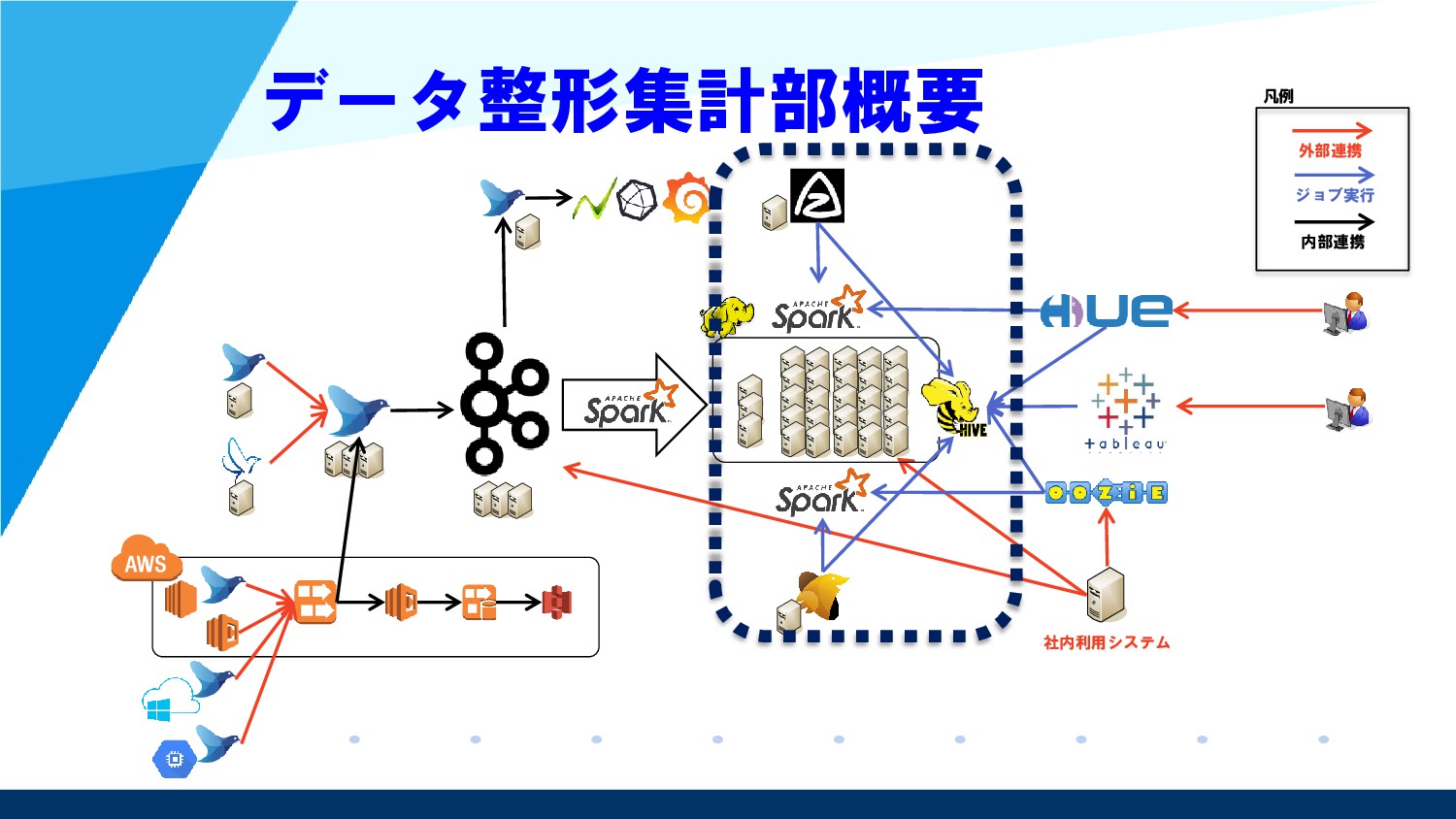{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![メタデータ破損 •発生事象 – ある平和な日中、電源障害でKafkaのホストがダウン – 再起動をかけてみると・・・ FATAL [Kafka Server 1],](https://files.speakerdeck.com/presentations/b053a4f88b574a26bfbcf6762a393b87/slide_18.jpg){kind=link}
![FATAL [Kafka Server 1], Fatal error during KafkaServer startup. Prepare](https://files.speakerdeck.com/presentations/b053a4f88b574a26bfbcf6762a393b87/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
![メタデータ破損 •発生事象 – インタフェースの問題でディスクには問題ないことを確認 – インタフェースを交換後、再起動をかけてみると・・・ FATAL [Kafka Server 1],](https://files.speakerdeck.com/presentations/b053a4f88b574a26bfbcf6762a393b87/slide_22.jpg){kind=link}
![メタデータ破損 •発生事象 – インタフェースの問題でディスクには問題ないことを確認 – インタフェースを交換後、再起動をかけてみると・・・ FATAL [Kafka Server 1],](https://files.speakerdeck.com/presentations/b053a4f88b574a26bfbcf6762a393b87/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![OSのTimeoutまで送信ブロック •FluentdでDNS Roundrobinを設定し、 受信ホストの一部がダウンした場合、 サービス側で以下のログが大量出力、送信量が激減 [warn]: detached forwarding server 'XXXXX-aggregation'](https://files.speakerdeck.com/presentations/b053a4f88b574a26bfbcf6762a393b87/slide_43.jpg){kind=link}
{kind=link}
![out_forward時、メタデータ復元失敗 •Fluentdでout_forwardを有するプロセス再起動時 以下のエラーが稀に発生 [warn]: failed to flush the buffer. retry_time=0](https://files.speakerdeck.com/presentations/b053a4f88b574a26bfbcf6762a393b87/slide_45.jpg){kind=link}
{kind=link}
![データ圧縮時zlibエラー •ファイル出力時、圧縮すると以下のエラーが発生 – 該当ファイルが途中で壊れる – 別スクリプトで圧縮するようにして対応 •すみません、Cのコードに潜っていきたくないんです・・・ [warn]: failed to](https://files.speakerdeck.com/presentations/b053a4f88b574a26bfbcf6762a393b87/slide_47.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}