Share
Dojo ++ 「GPUなしでもここまでできるAI構築シリーズ Part 2」 https://connpass.com/event/190151/ インテルがチューンしたPythonとTensorFlowをつかってみる
インテル 大内山さんが話す当日の資料です。
手元で動作を確認するための環境構築手順書が別にあります。 ぜひそちらもご参照ください。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
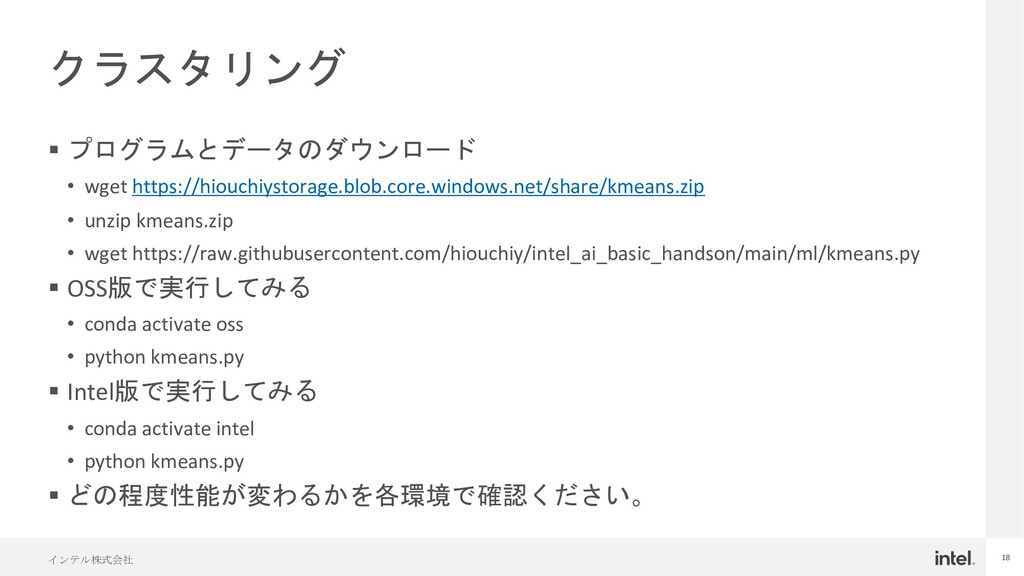{kind=link}
{kind=link}
{kind=link}
{kind=link}
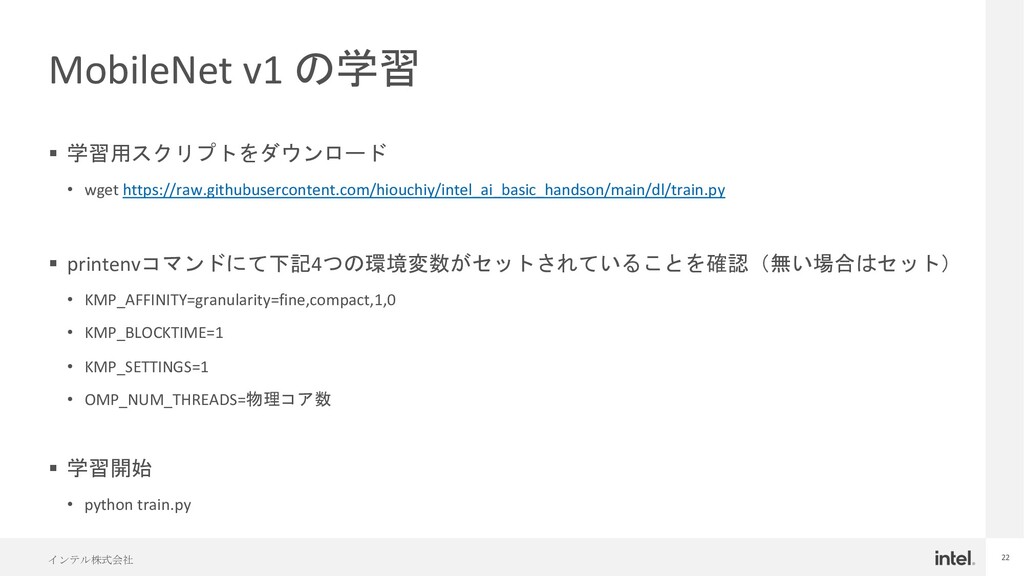{kind=link}
{kind=link}
{kind=link}
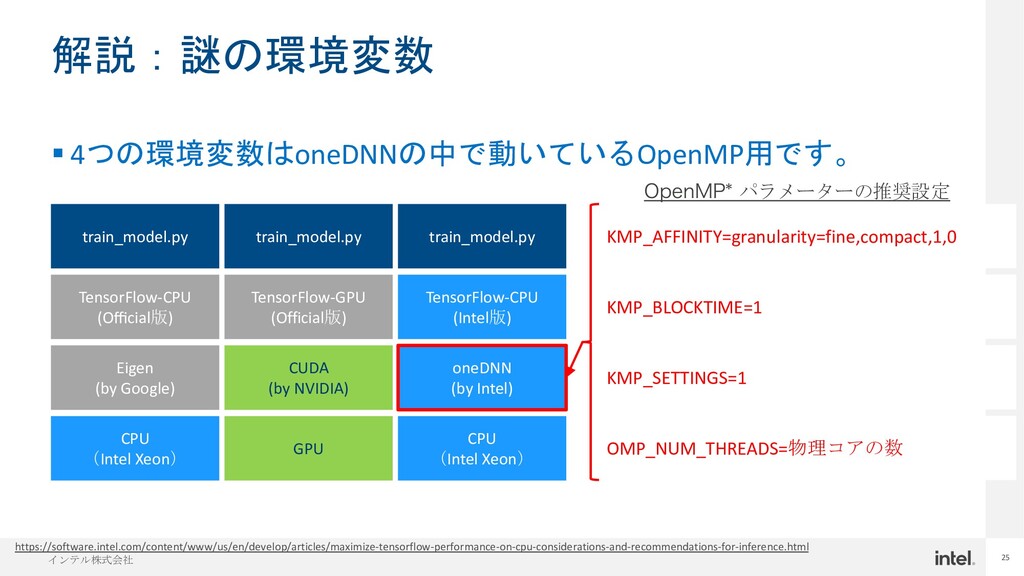{kind=link}
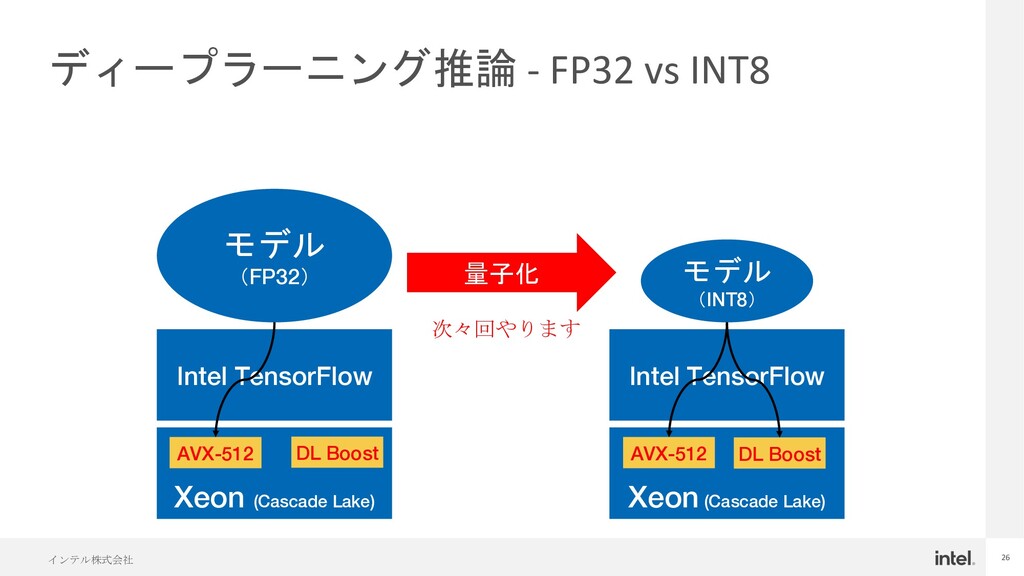{kind=link}
{kind=link}
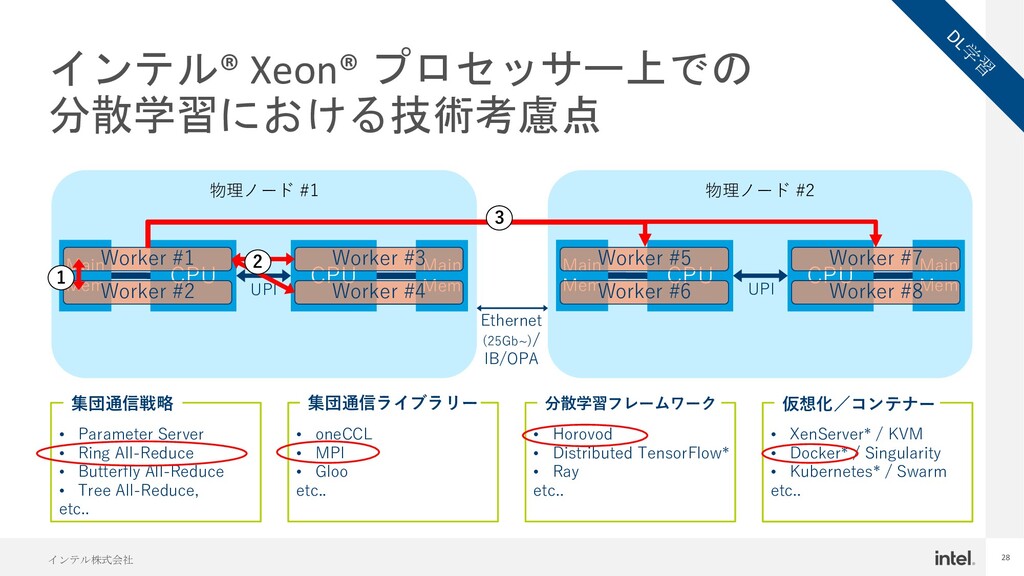{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}