efficiency • Hardware cost • Memory bandwidth • It is required to pass data from layer to layer • Processing bandwidth • How many data are processed simultaneously? • etc. (Re-programmability, Ease of use, …) https://www.altera.com/en_US/pdfs/literature/solution-sheets/efficient_neural_networks.pdf
by Hardware Description Language • Pros • Can re-program any kind of logics • Cons • Lack of resources (processing elements, memory, etc) • Hardware cost (compared to mass-produced devices)
processing, a sort of scientific simulations, etc. • FPGA: Prototyping of ASICs, Hardware-wise speed is needed and yet logics can be changed, etc. • Search engine accelerator, financial simulation, high frequency trading, etc.
% • Power Efficiency (Performance per Watt) • Cons & • Difficult implementation • Lack of memory bandwidth • Lack of processing elements for training • Most papers discuss only the inference phase? https://www.tractica.com/automation-robotics/fpgas-challenge-gpus-as-a-platform-for-deep-learning/
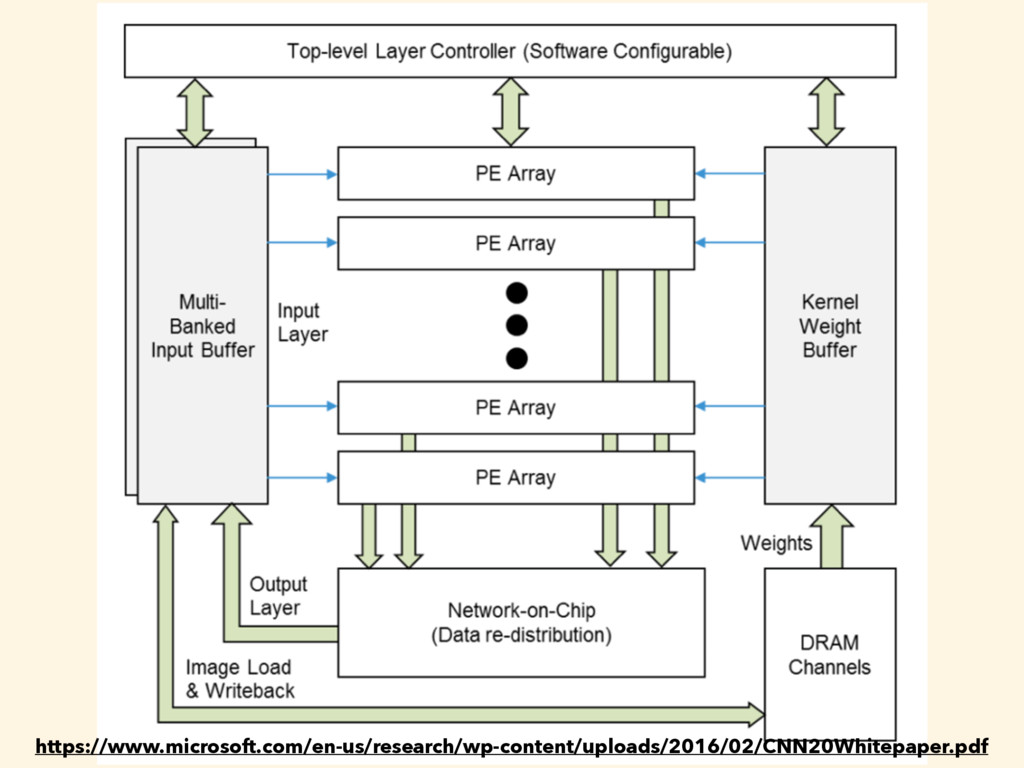
on a mid-range FPGA” (only the inference phase) • “Respectable performance relative to prior FPGA designs and high-end GPGPUs at a fraction of the power” https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/CNN20Whitepaper.pdf
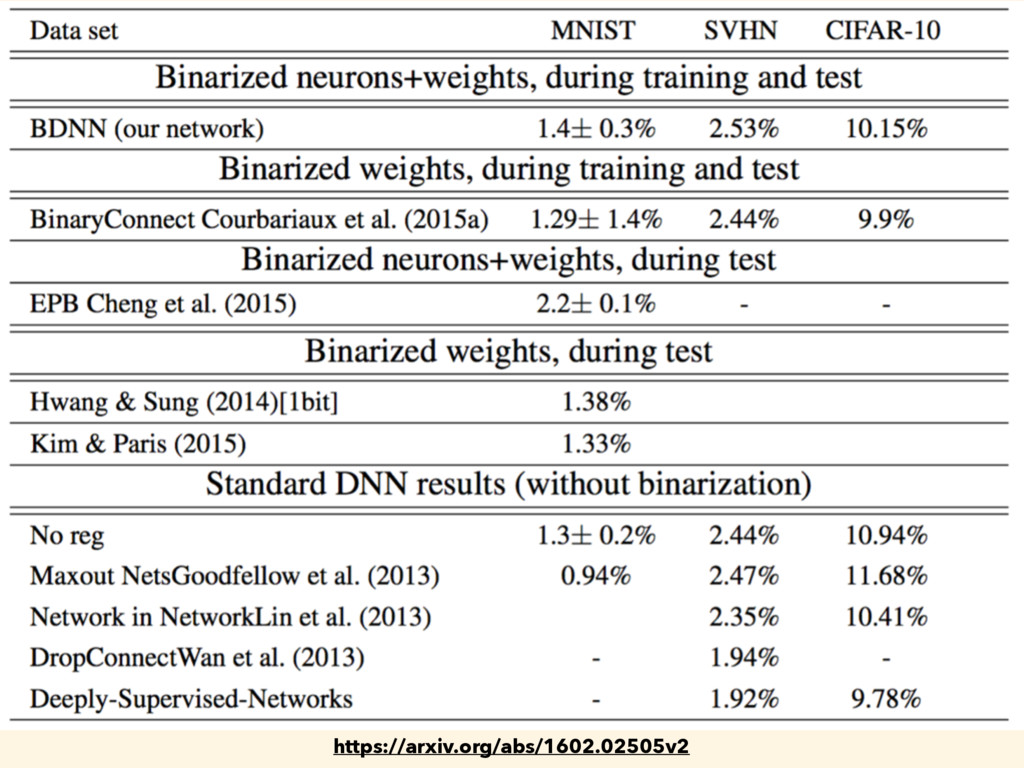
output and weights deterministically • Stored/Updated weights retain precision • “At test phase, BDNNs are fully binarized and can be implemented in hardware with low circuit complexity” • which means the learning phase is not yet fully binarized https://arxiv.org/abs/1602.02505v2
logic • Lack of computing resources • CNN is too big to be implemented - needs to be simplified • An approach: Binarized Neural Network • It is yet hard to binarize the learning phase fully
FPGAs, and Programmed with OpenCL • https://www.altera.com/en_US/pdfs/literature/solution-sheets/efficient_neural_networks.pdf • FPGAs on Mars • http://dea.unsj.edu.ar/sda/FPGA_On_Mars.pdf • FPGAs Challenge GPUs as a Platform for Deep Learning • https://www.tractica.com/automation-robotics/fpgas-challenge-gpus-as-a-platform-for-deep- learning/ • Accelerating Deep Convolutional Neural Networks Using Specialized Hardware • https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/CNN20Whitepaper.pdf • Banalized Neural Networks • https://arxiv.org/abs/1602.02505v2
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}