N = slower processing ✤ Kebakaran (N=2) -> ke, eb, ba, ak, ka, ar, ra, an ✤ More N = need longer sample ✤ Kebakaran (N=4) -> keba, ebak, baka, akar, kara, aran
require special index/vector, can be done on- the-fly ✤ More relevant results ✤ Cons: ✤ Publish date ordering is more suitable for news website (Maybe? Needs research)
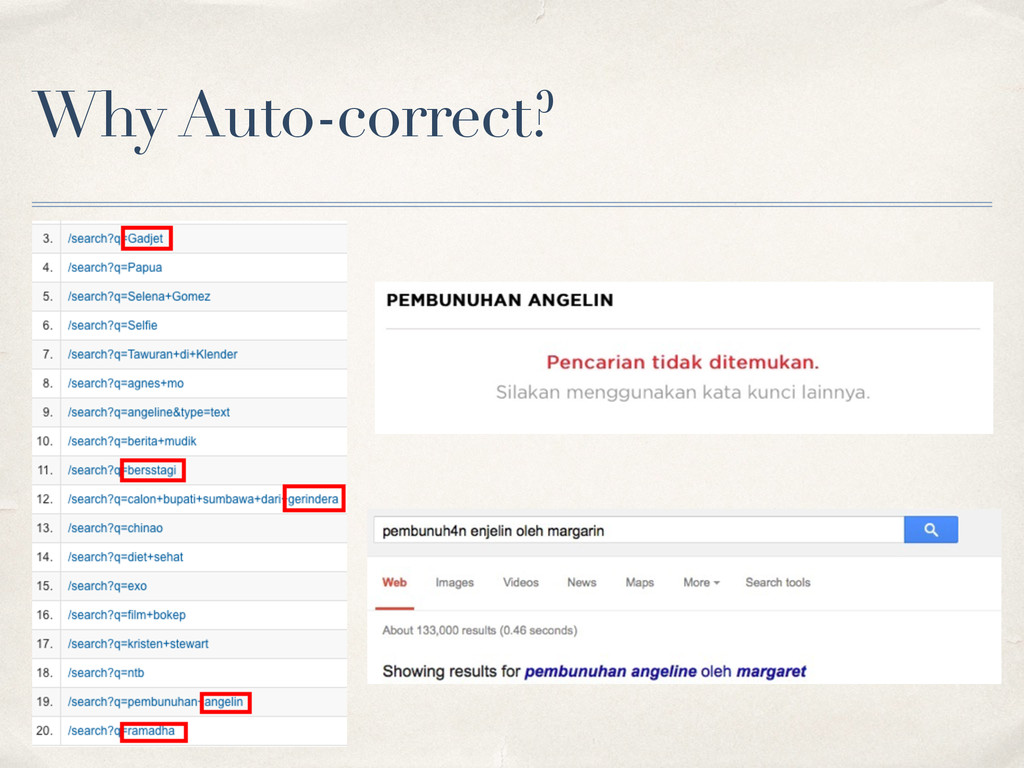
word to another ✤ Widely used for auto-correct ✤ Example: ✤ Distance between “angeline” and “enjelin” is 3 ✤ Change ‘a’ to ‘e’ -> engeline ✤ Change ‘g’ to ‘j’ -> enjeline ✤ Remove ‘e’ -> enjelin
vectors ✤ Store frequently searched words only ✤ Checks every words in user query ✤ If a word doesn’t exist on dictionary, correct it! ✤ Find word in dictionary with smallest distance ✤ Return search results based on corrected query
function ✤ int levenshtein ( string $str1, string $str2 ) ✤ Can be done using cache/dictionary instead of db vector ✤ Cons ✤ Expensive, needs to be done selectively
![Tech Talk - Yohan - http://yohan.id - [email protected] Advanced Search](https://files.speakerdeck.com/presentations/b6d5ee2cf6b34ca39a4a124175aef77f/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}