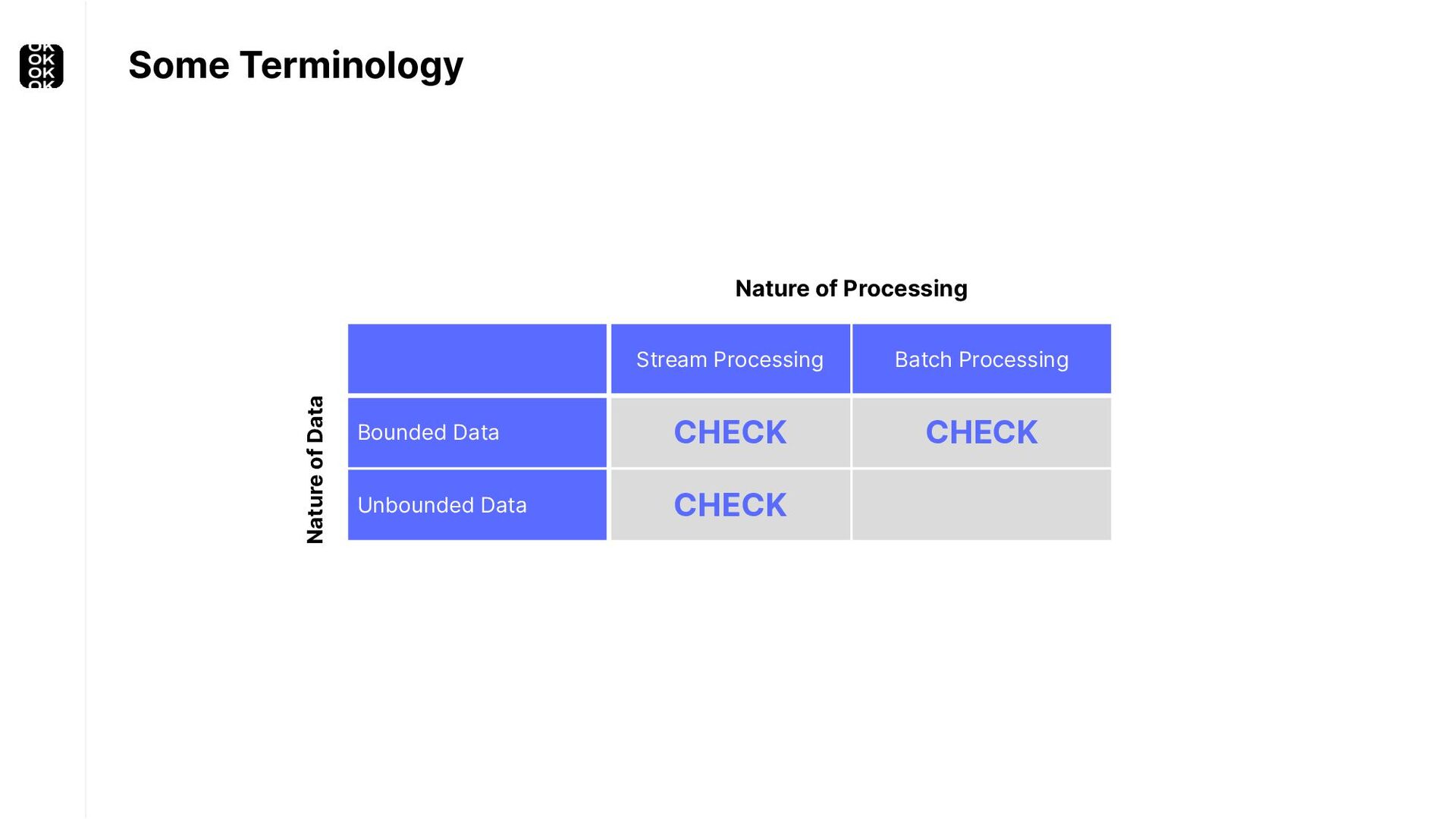
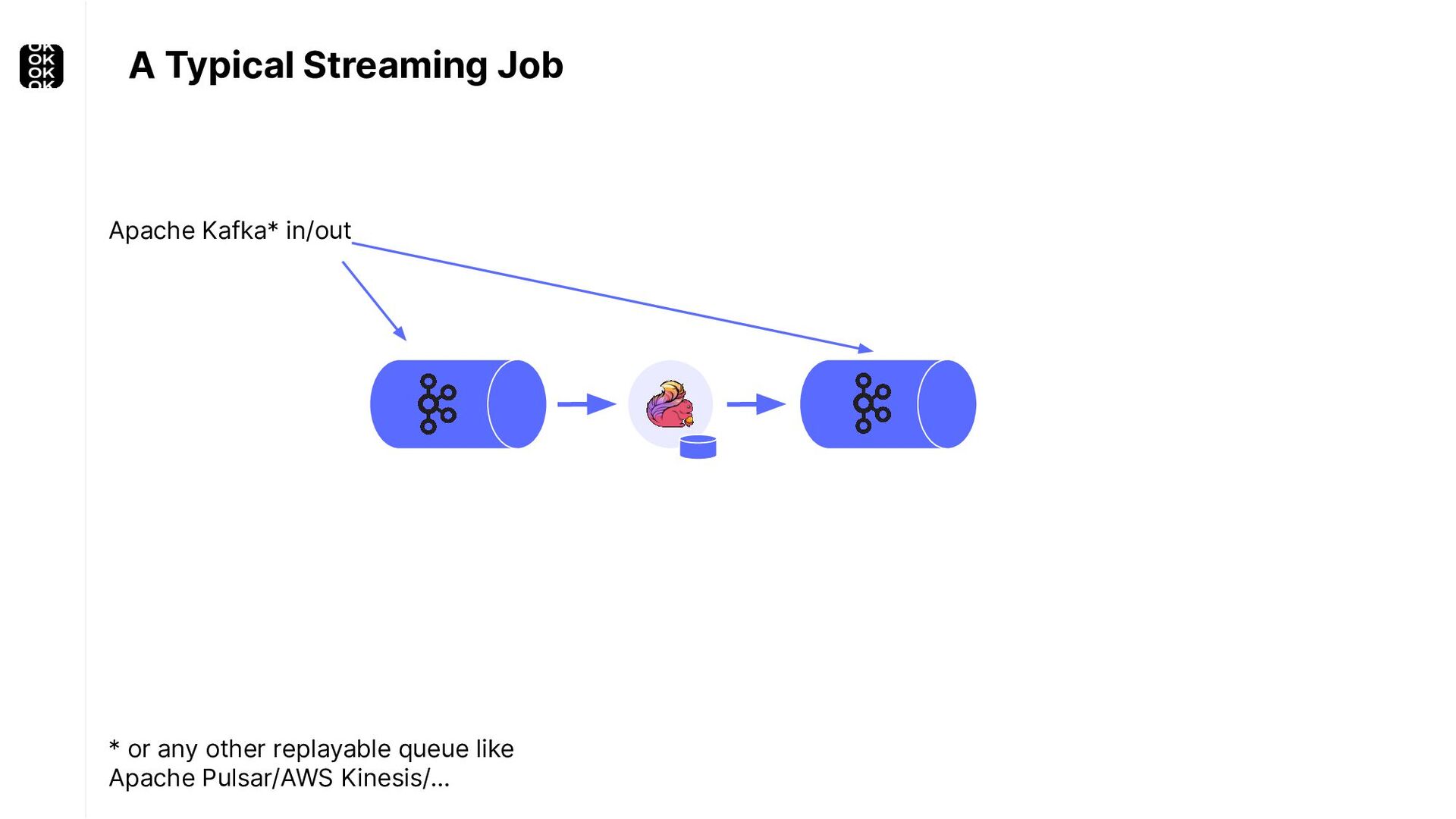
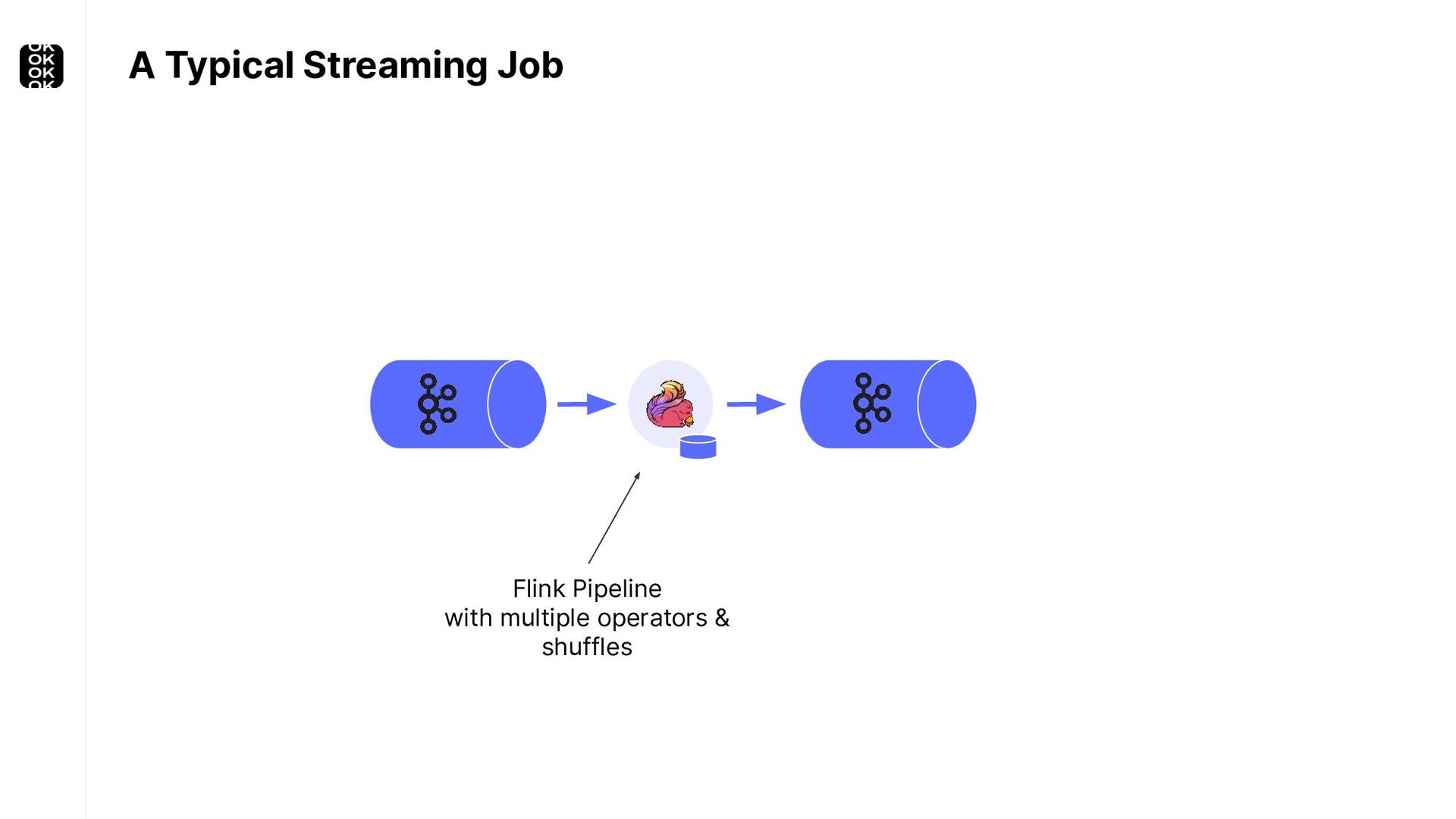
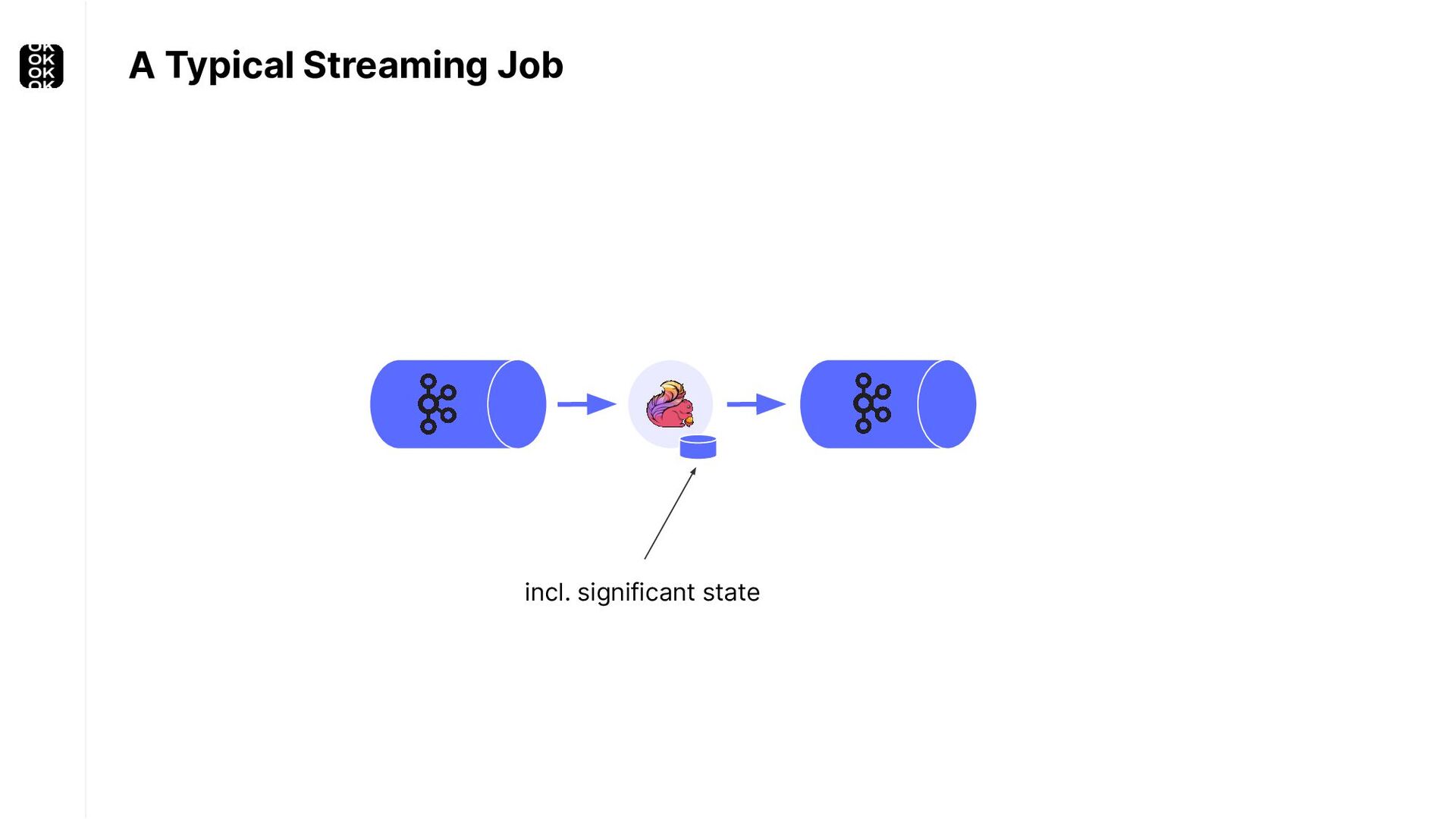
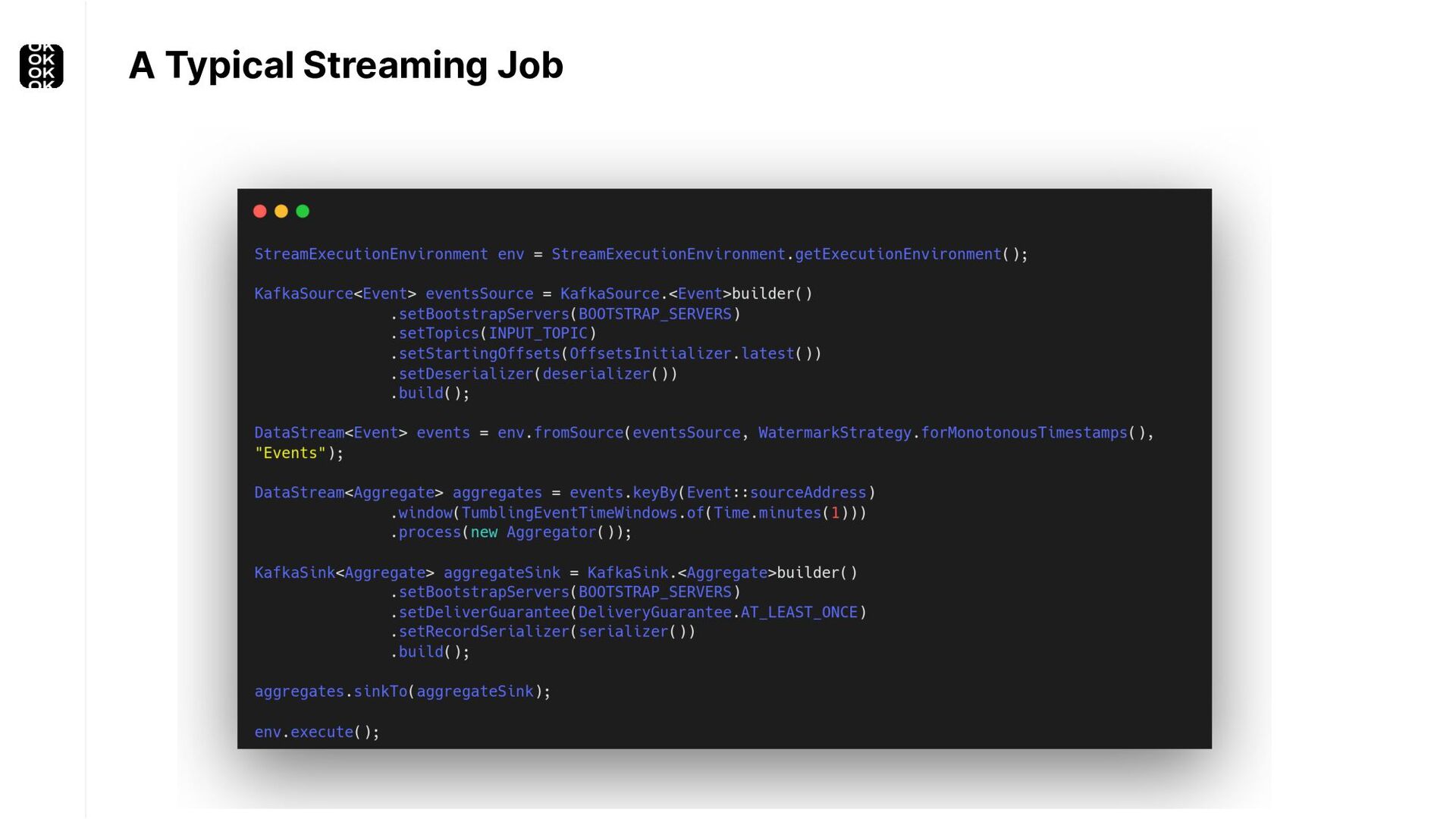
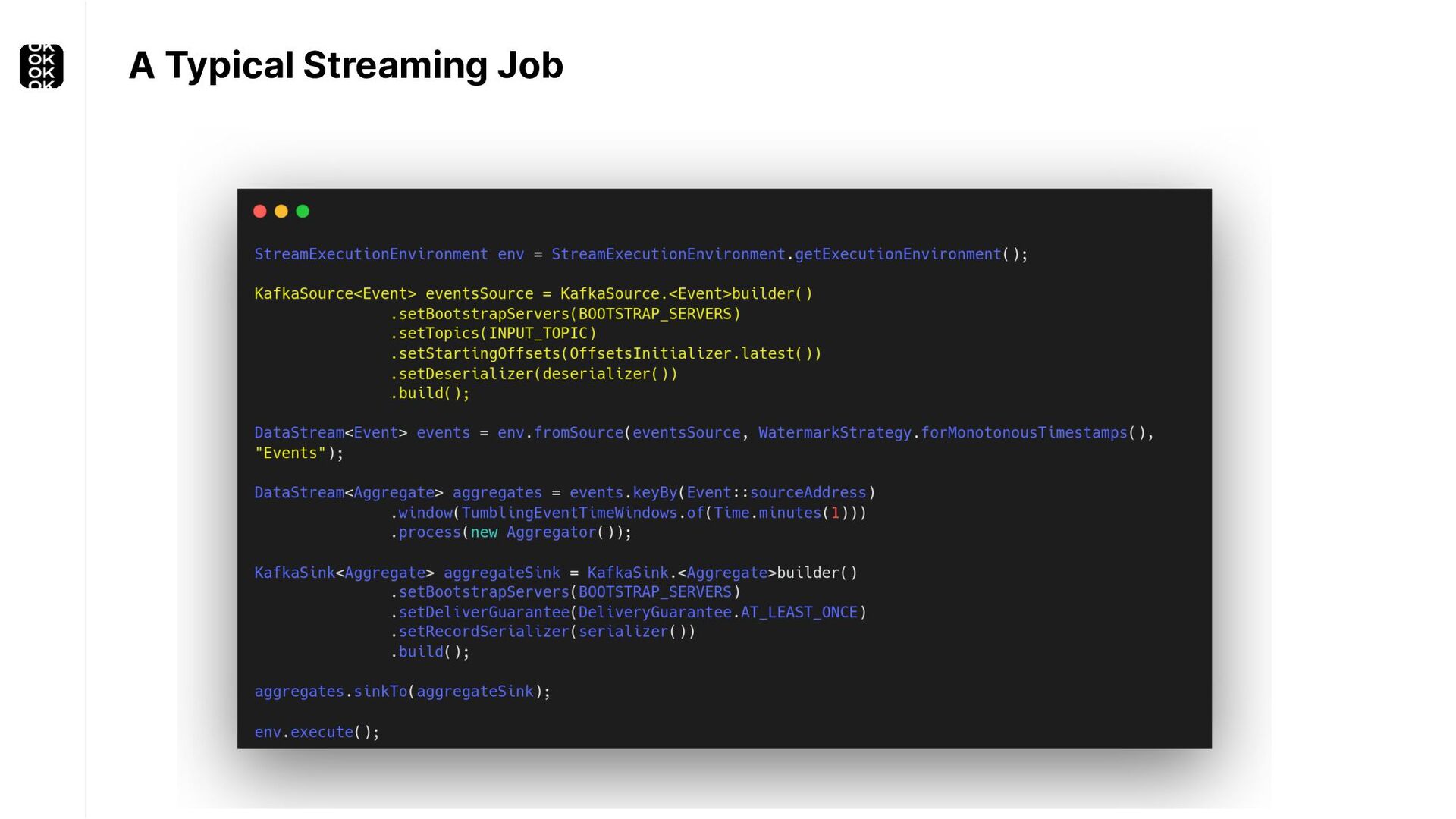
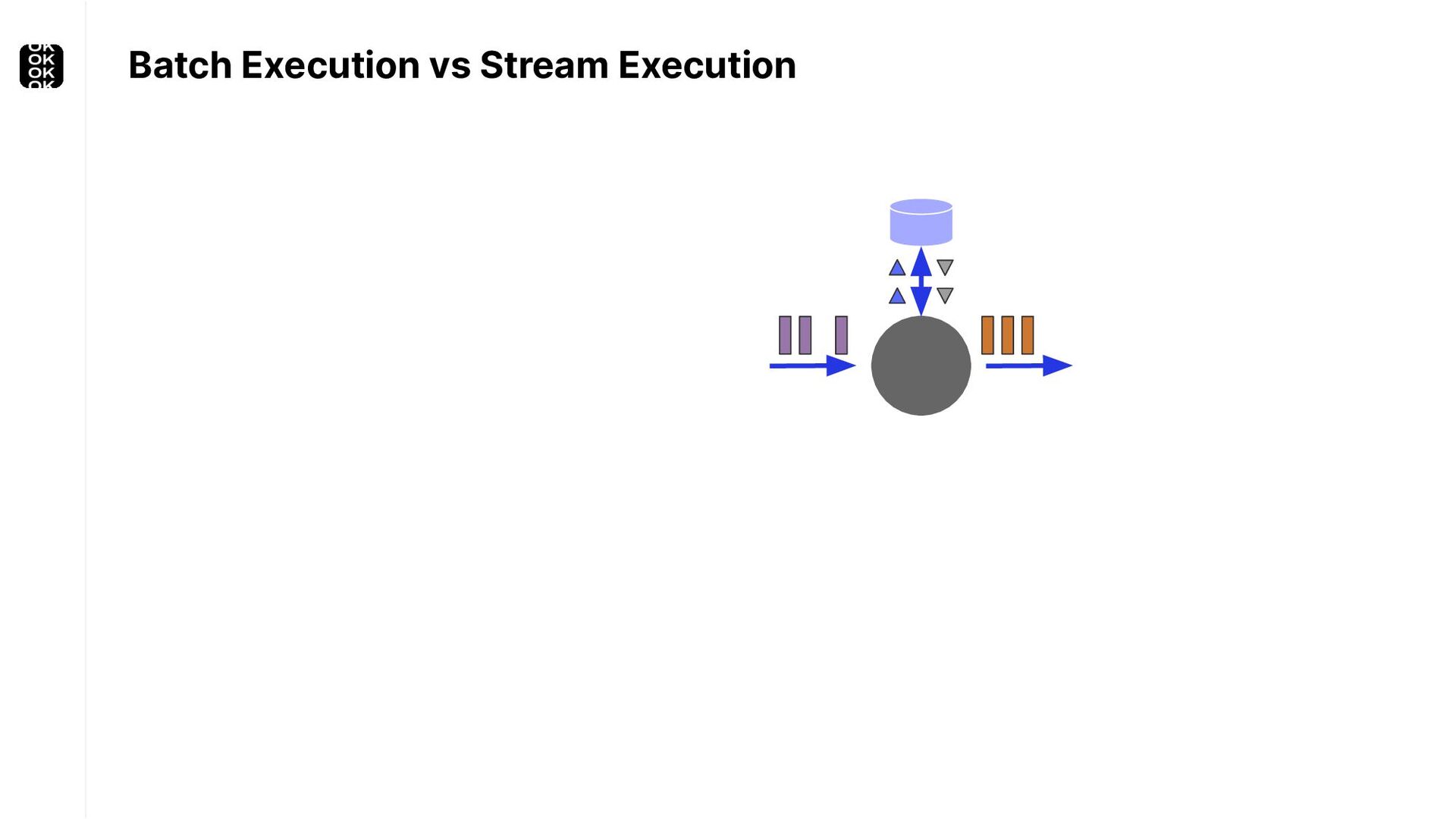
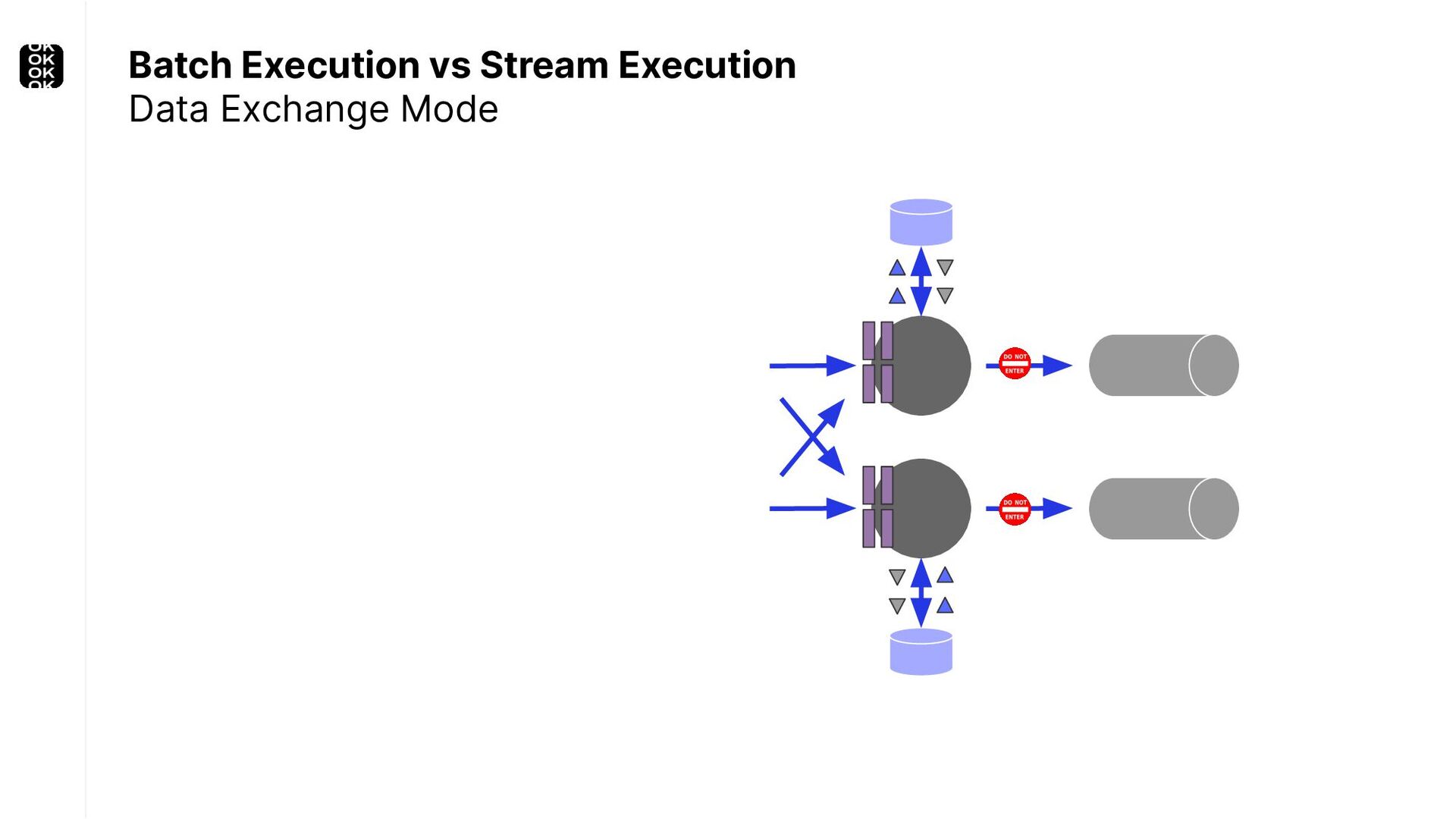
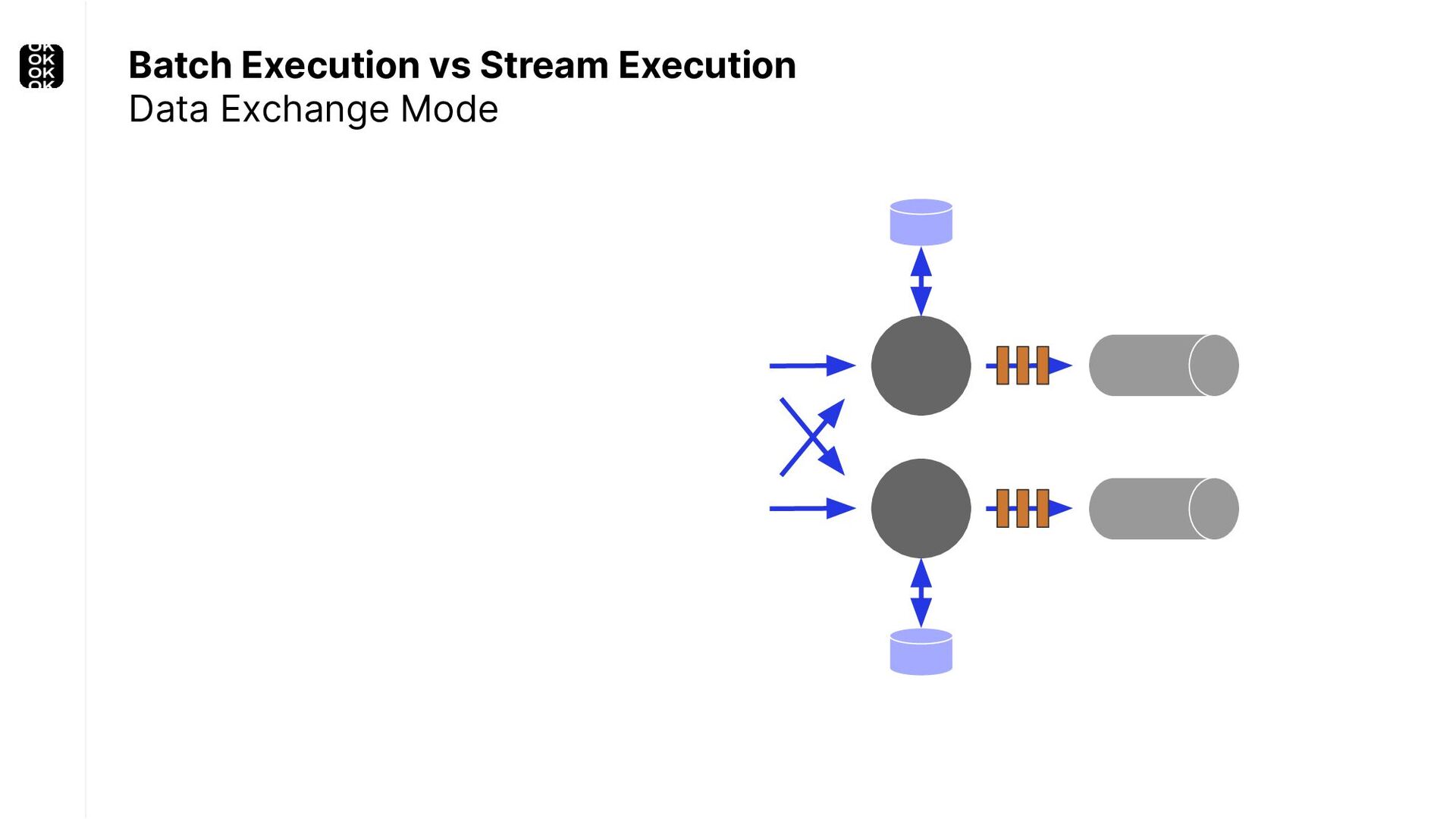
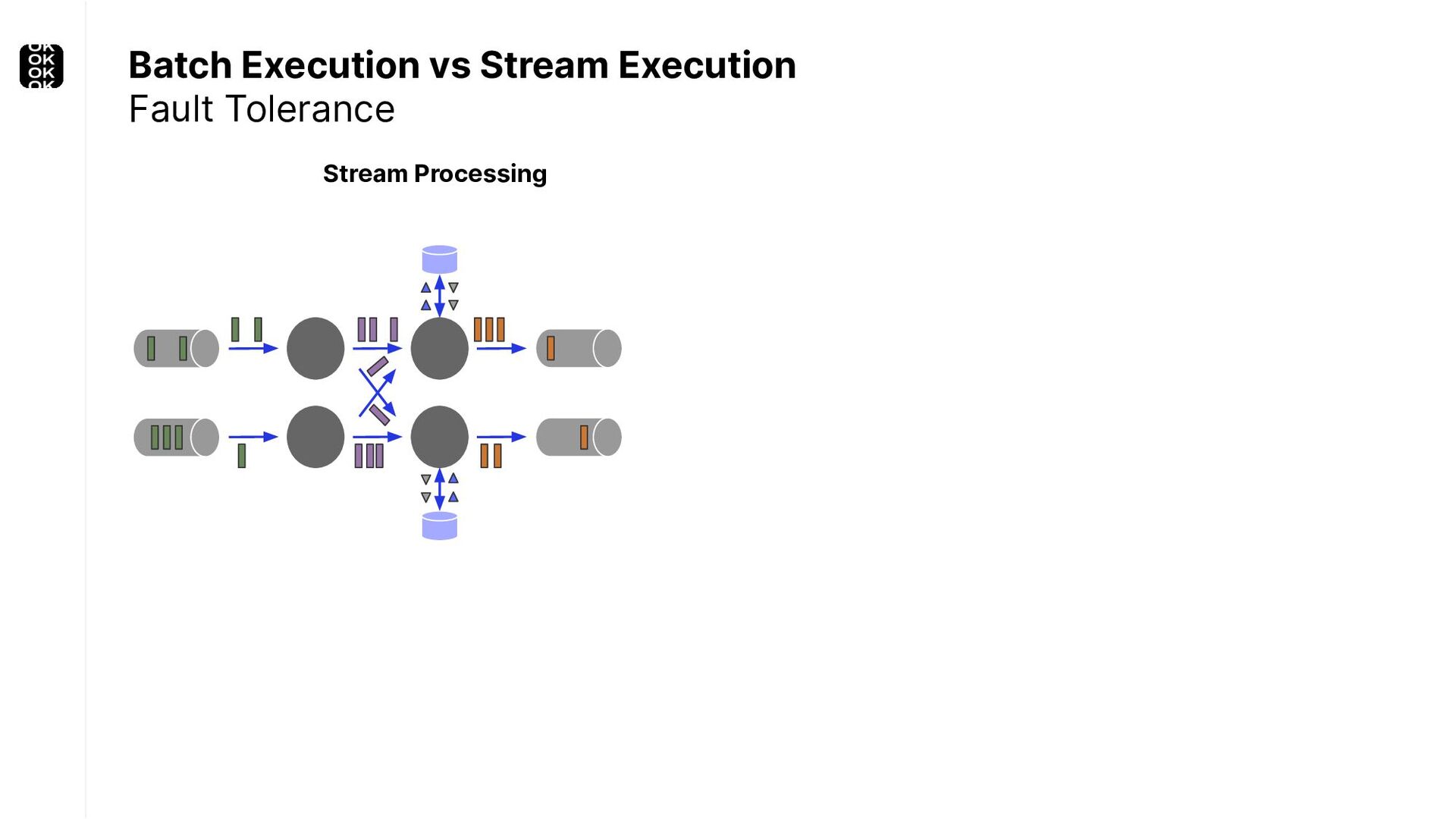
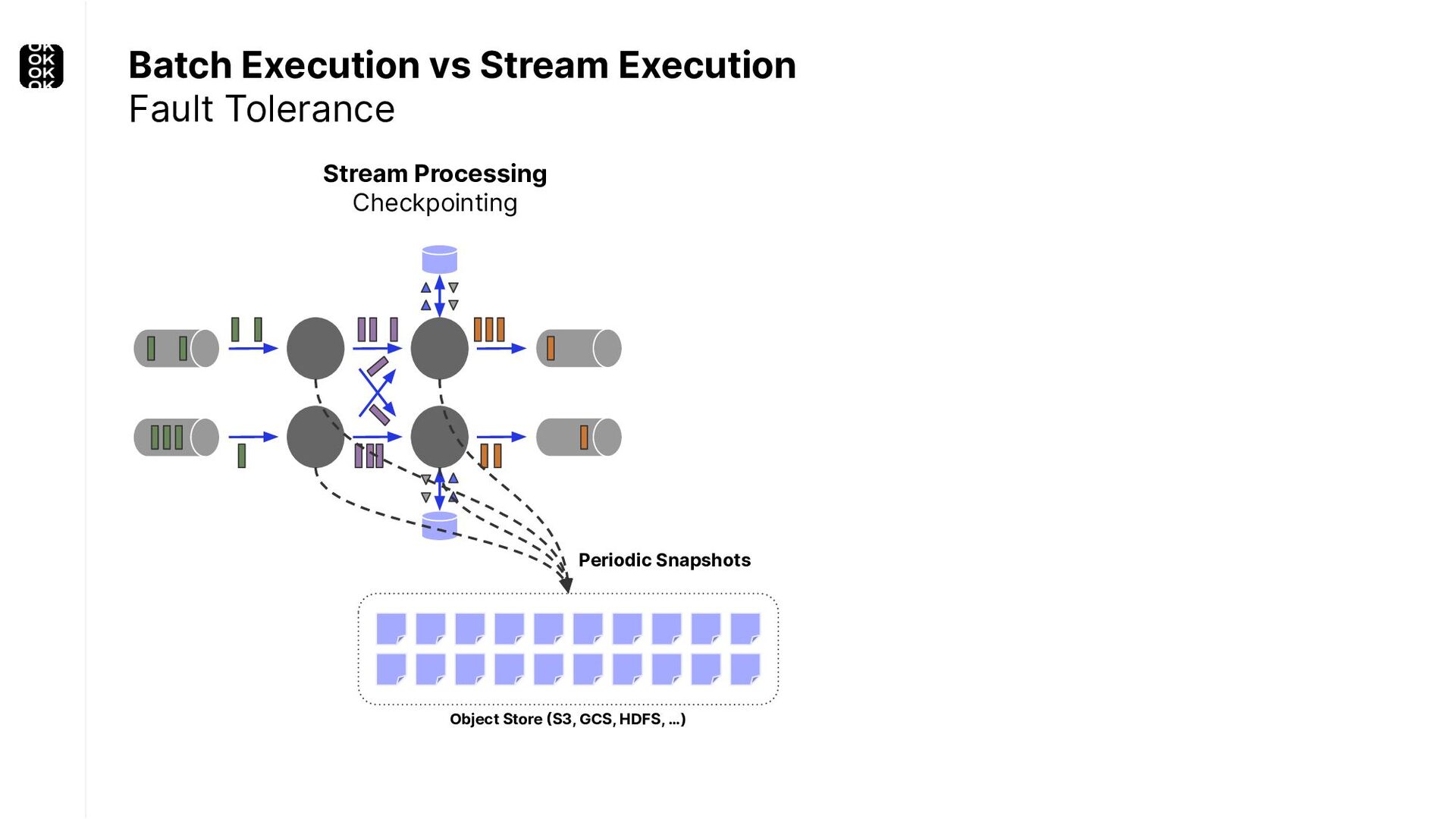
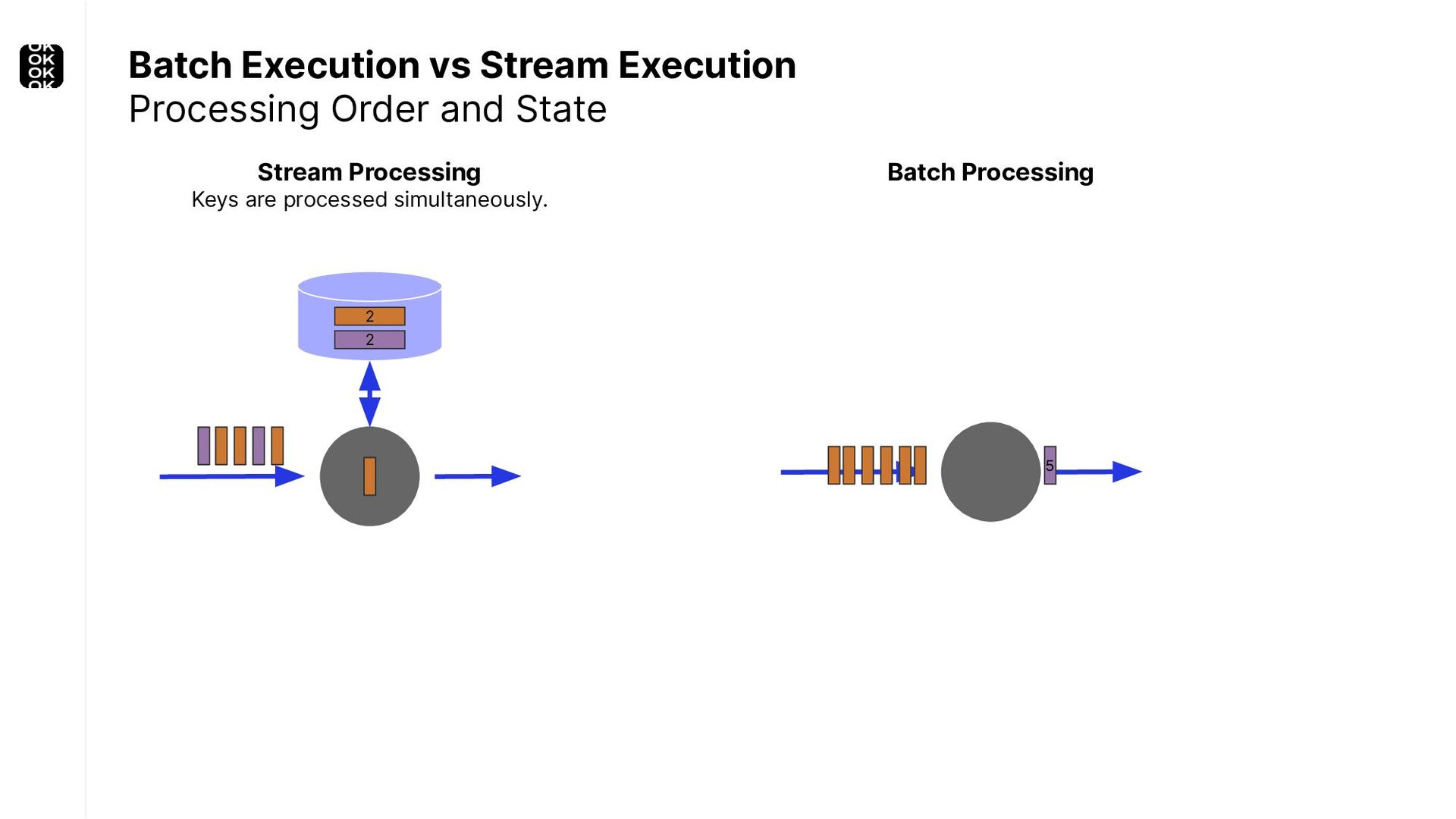
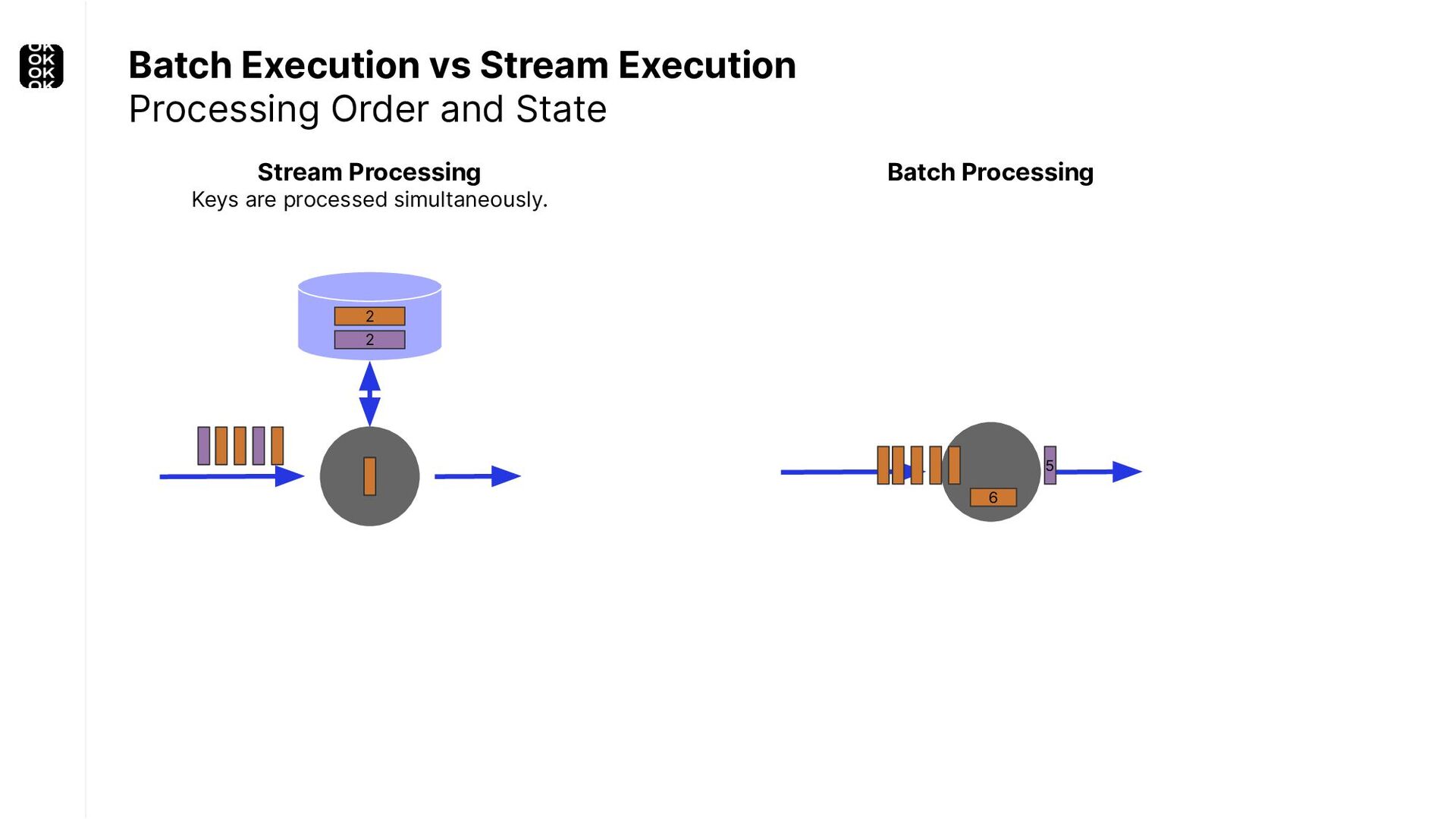
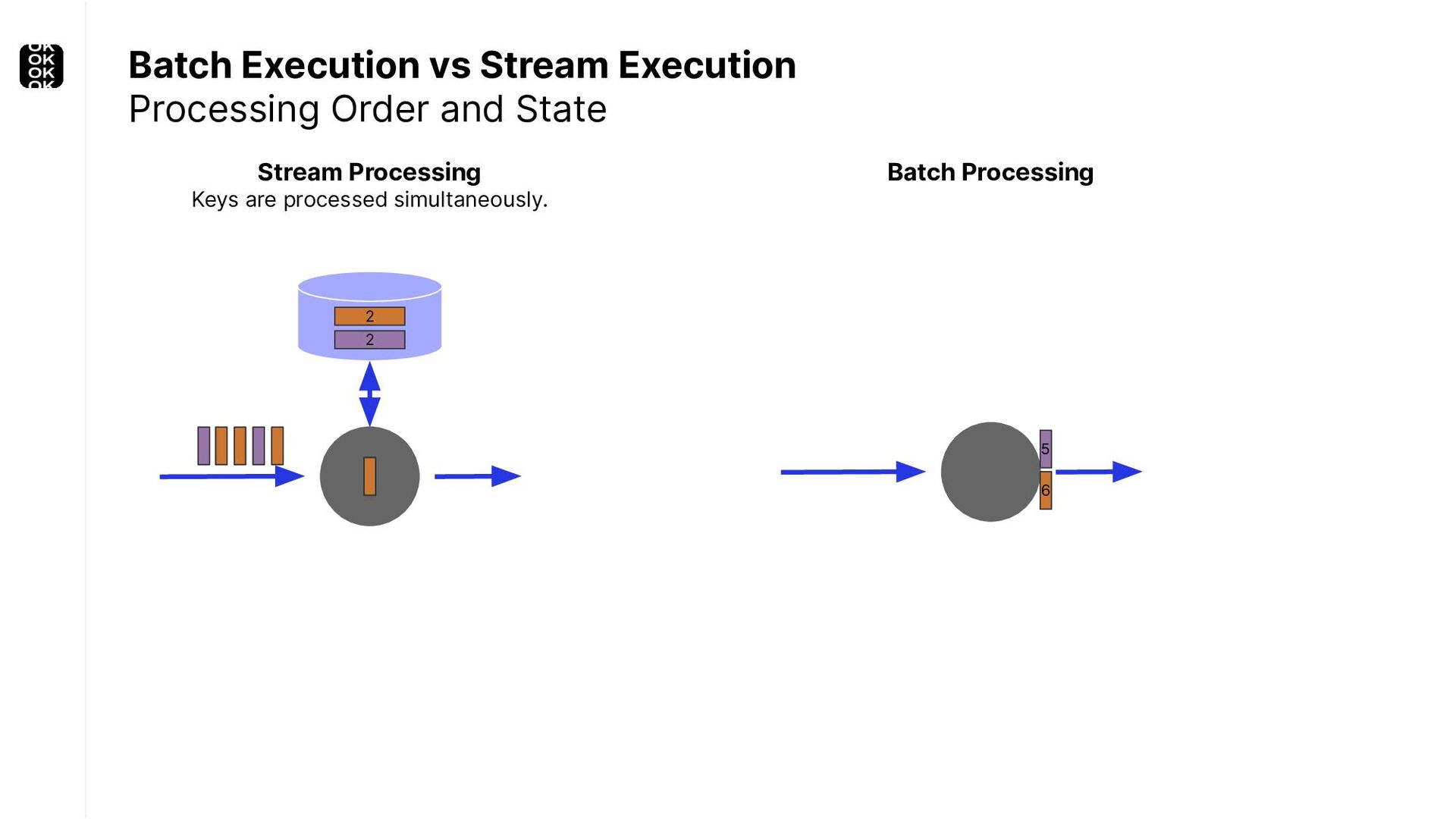
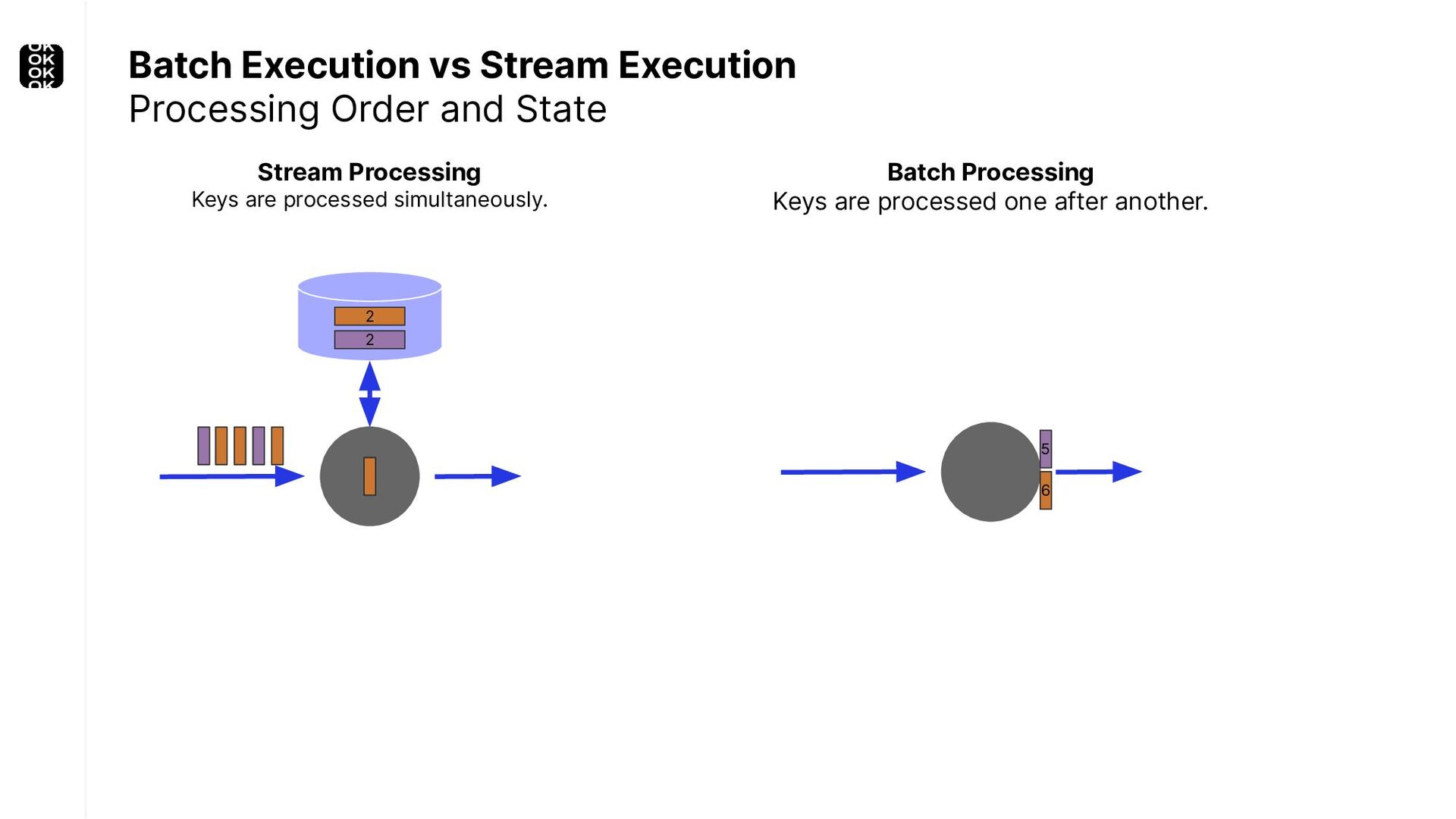
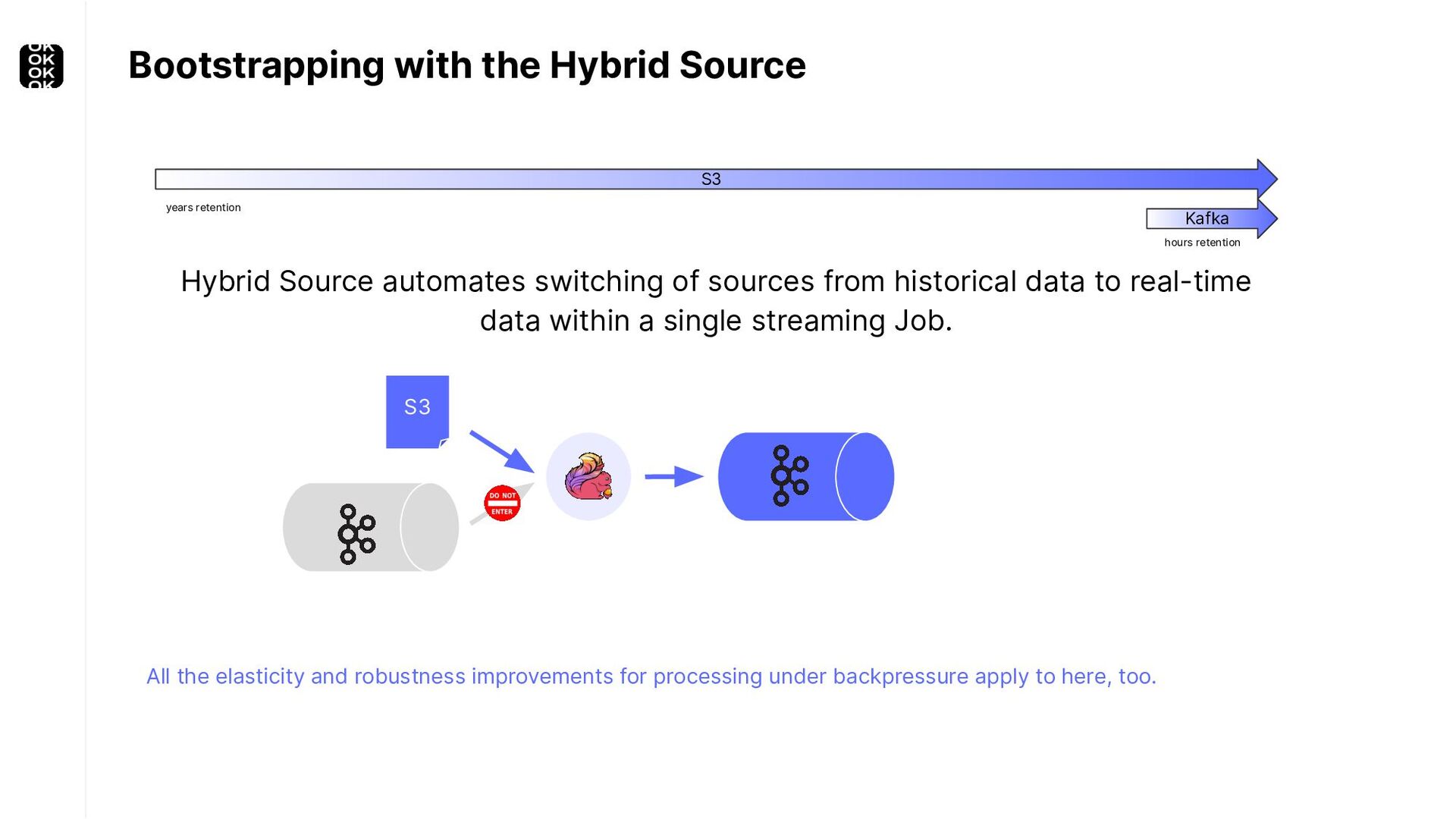
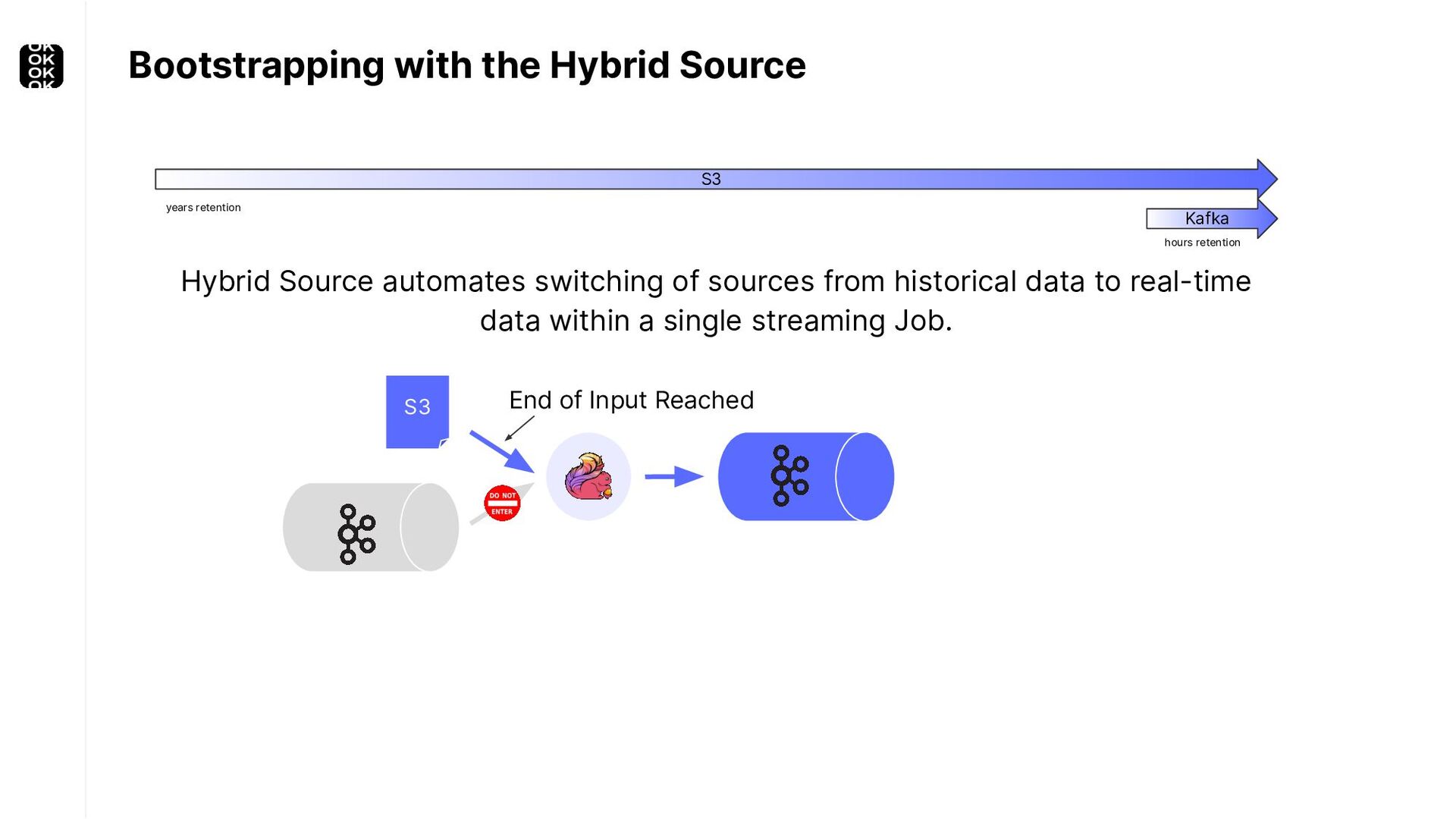
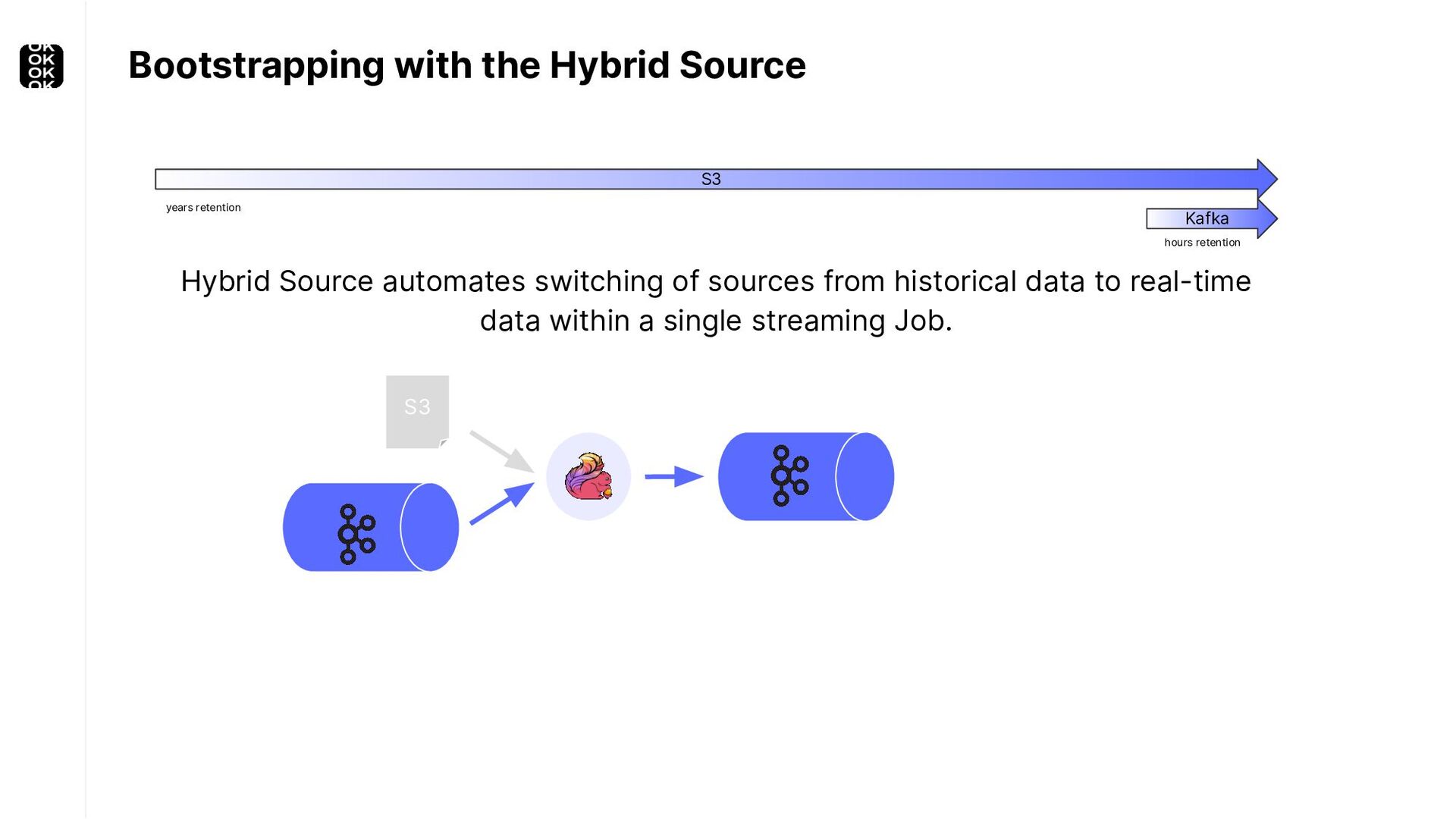
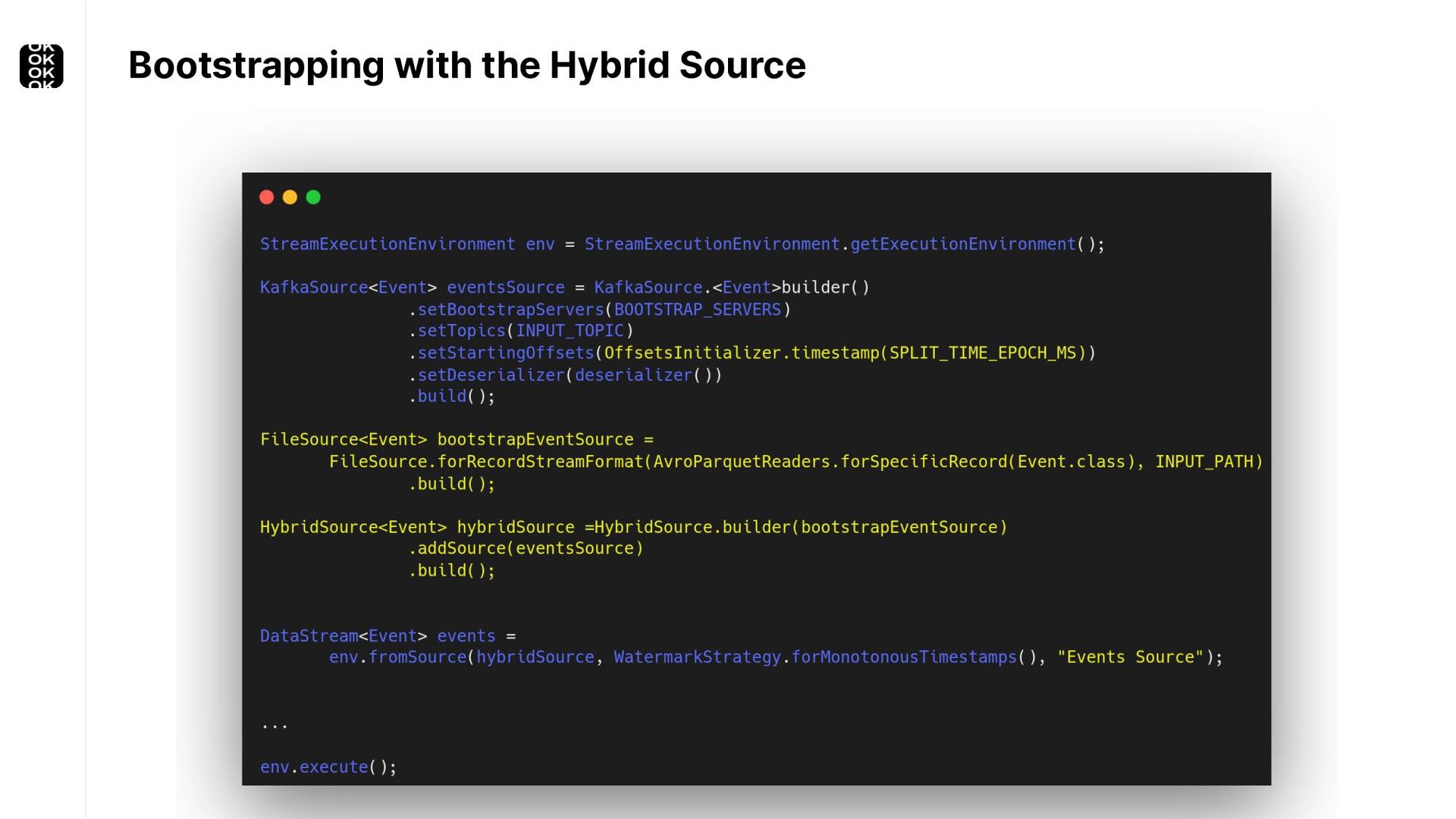
A streaming application is started once and then continuously ingests endless, fairly steady streams of events. That's as far as the theory goes. Unfortunately, reality is more complicated. Over time your application's ability to process large historical data sets robustly, efficiently and correctly will be critical:
* For exploratory data analysis during development
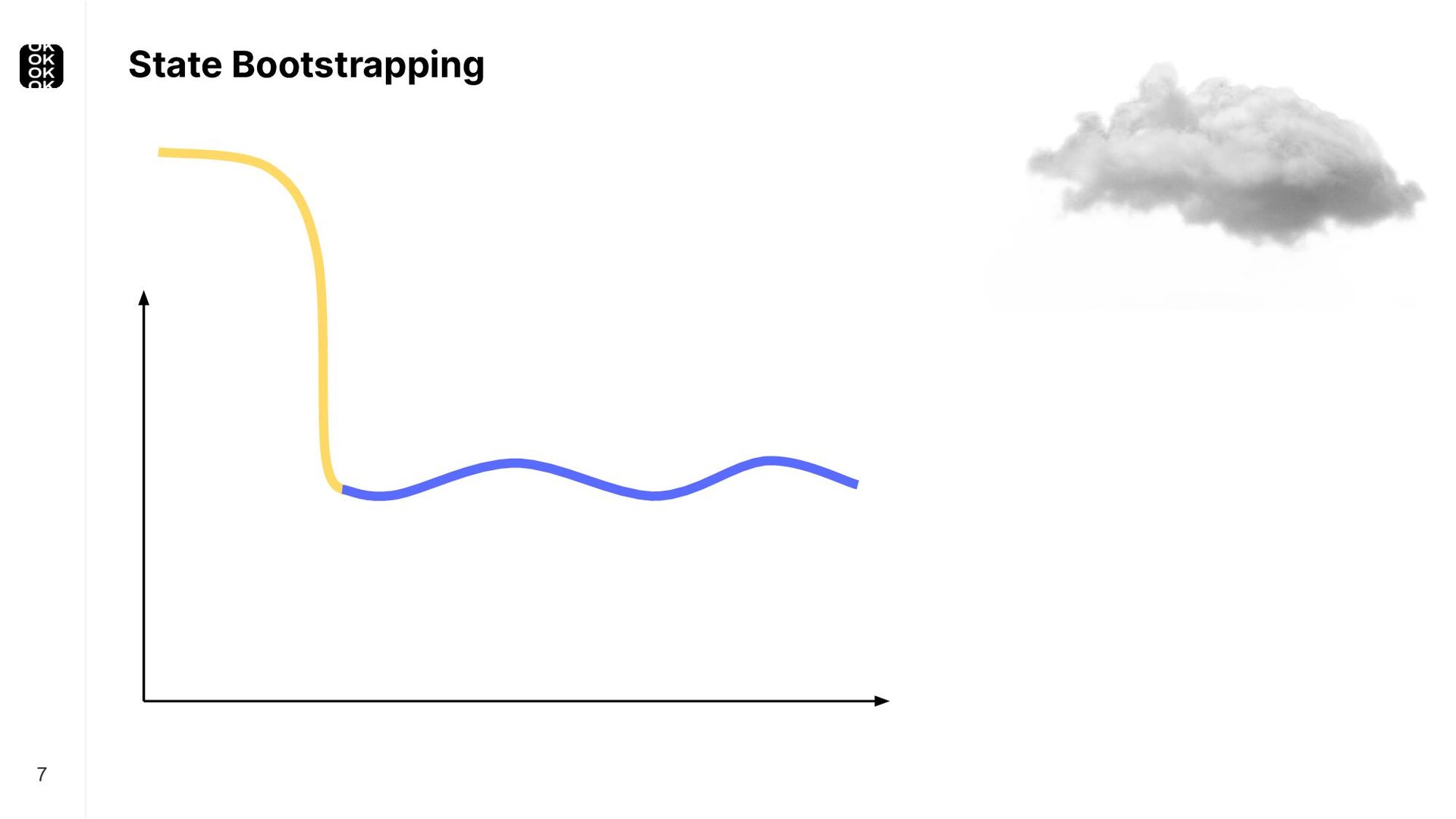
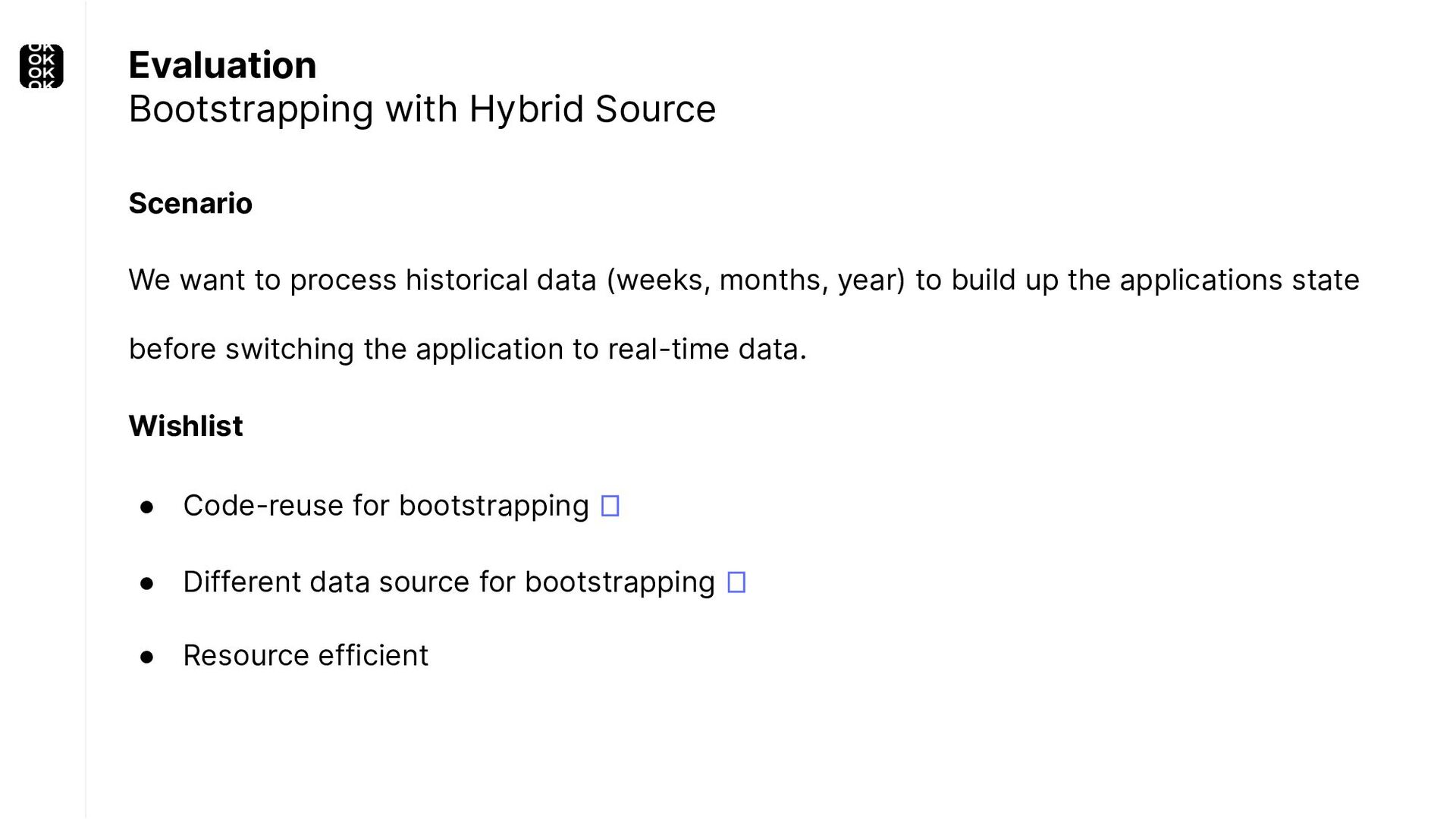
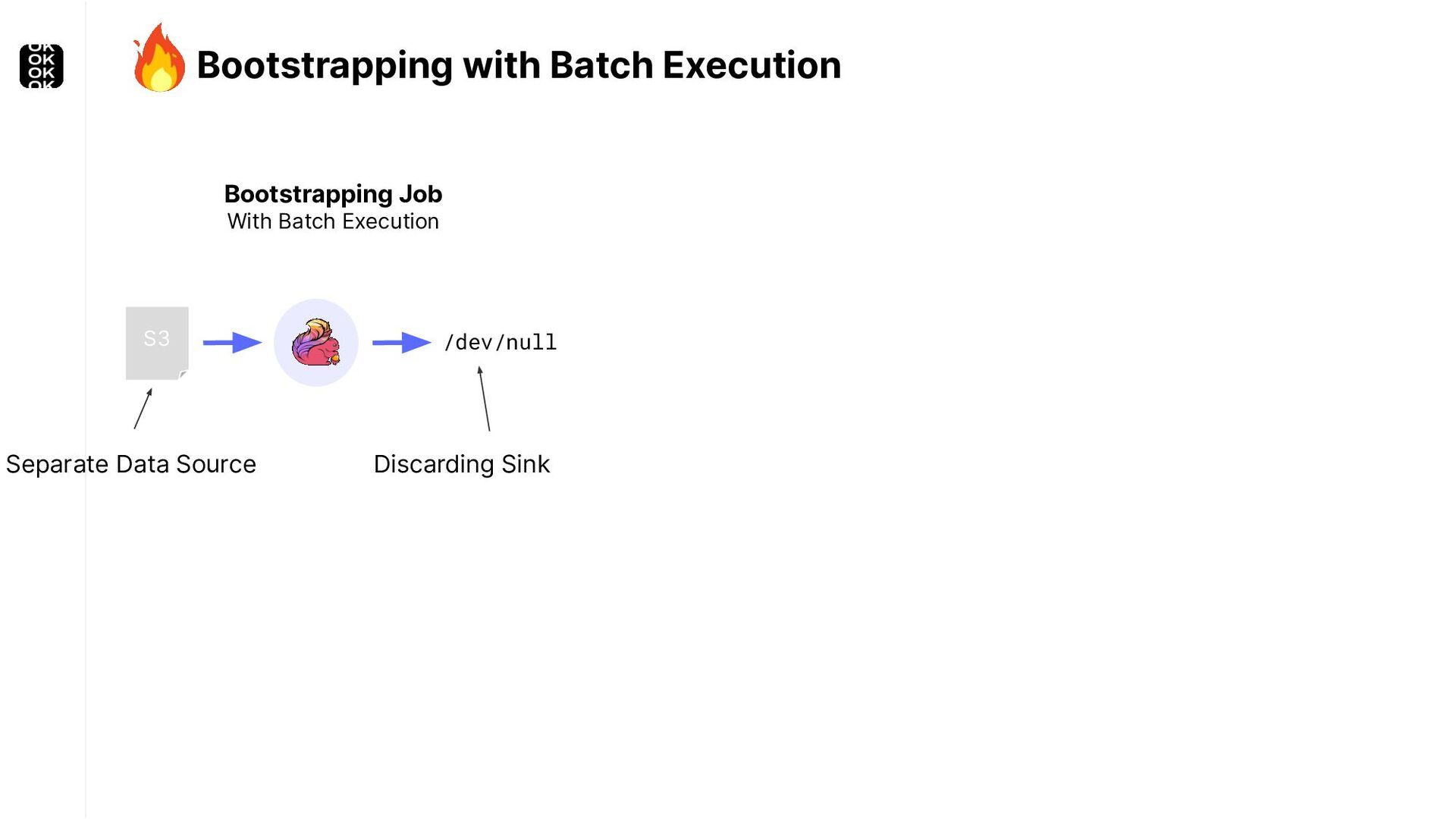
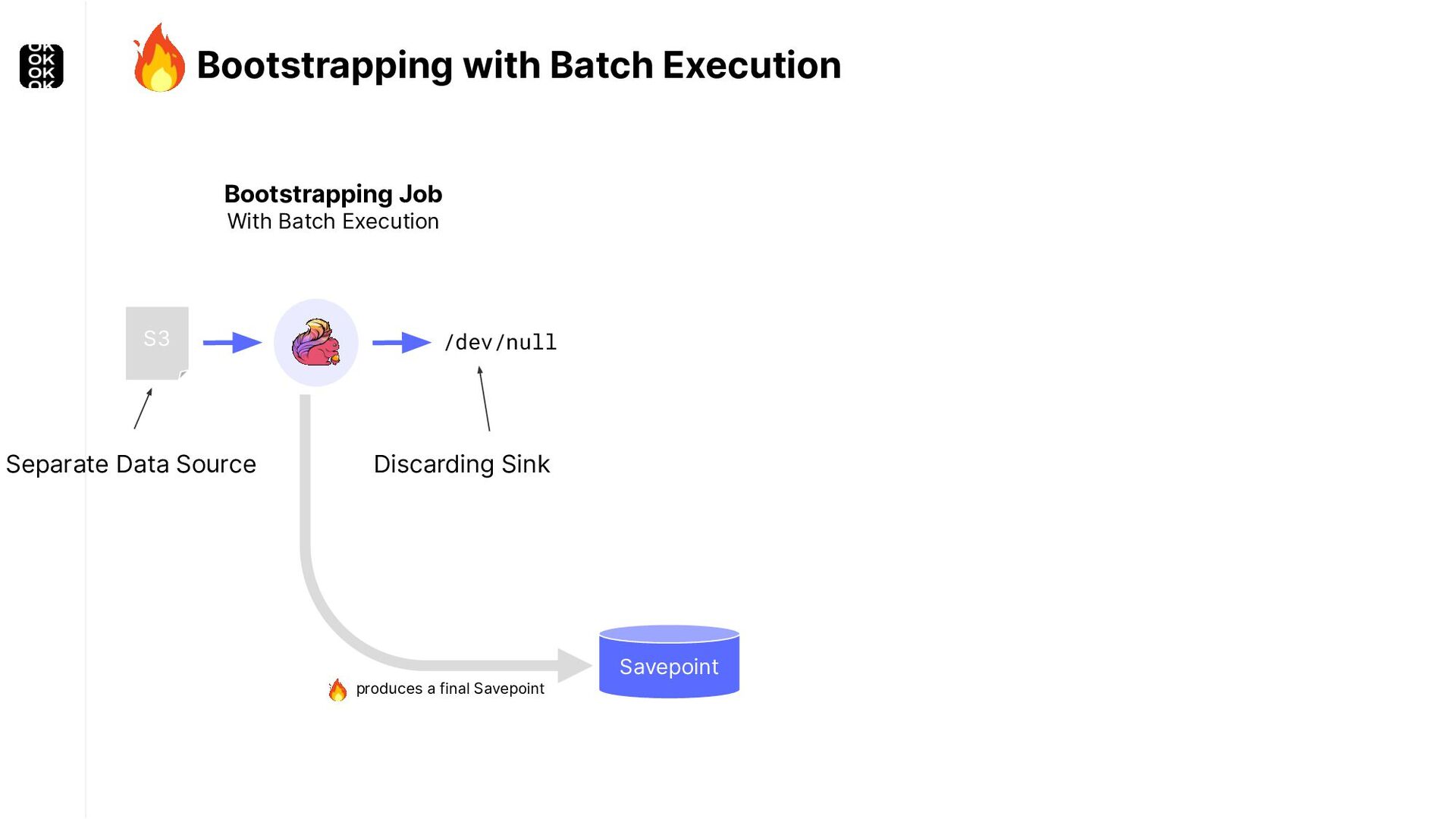
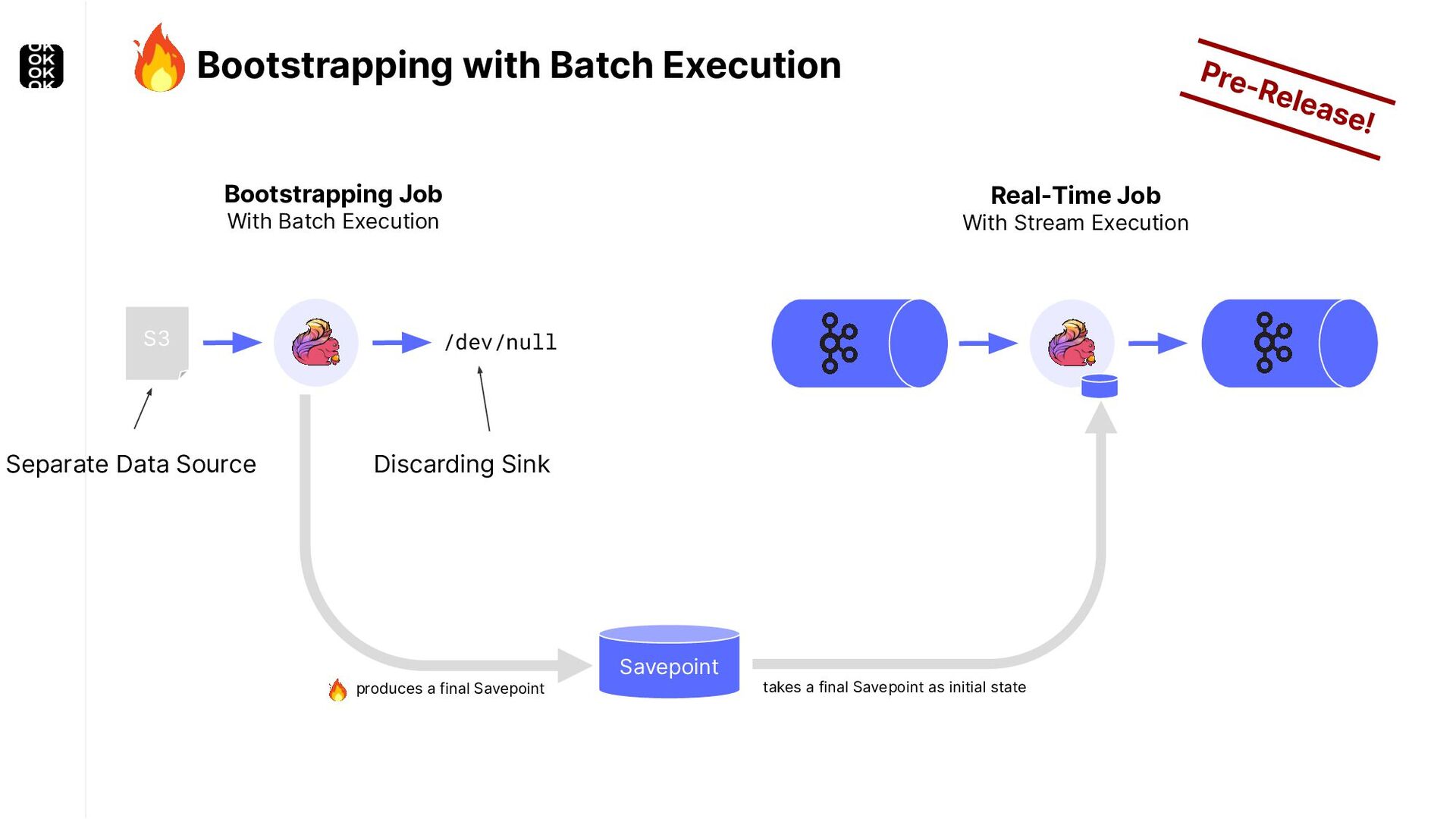
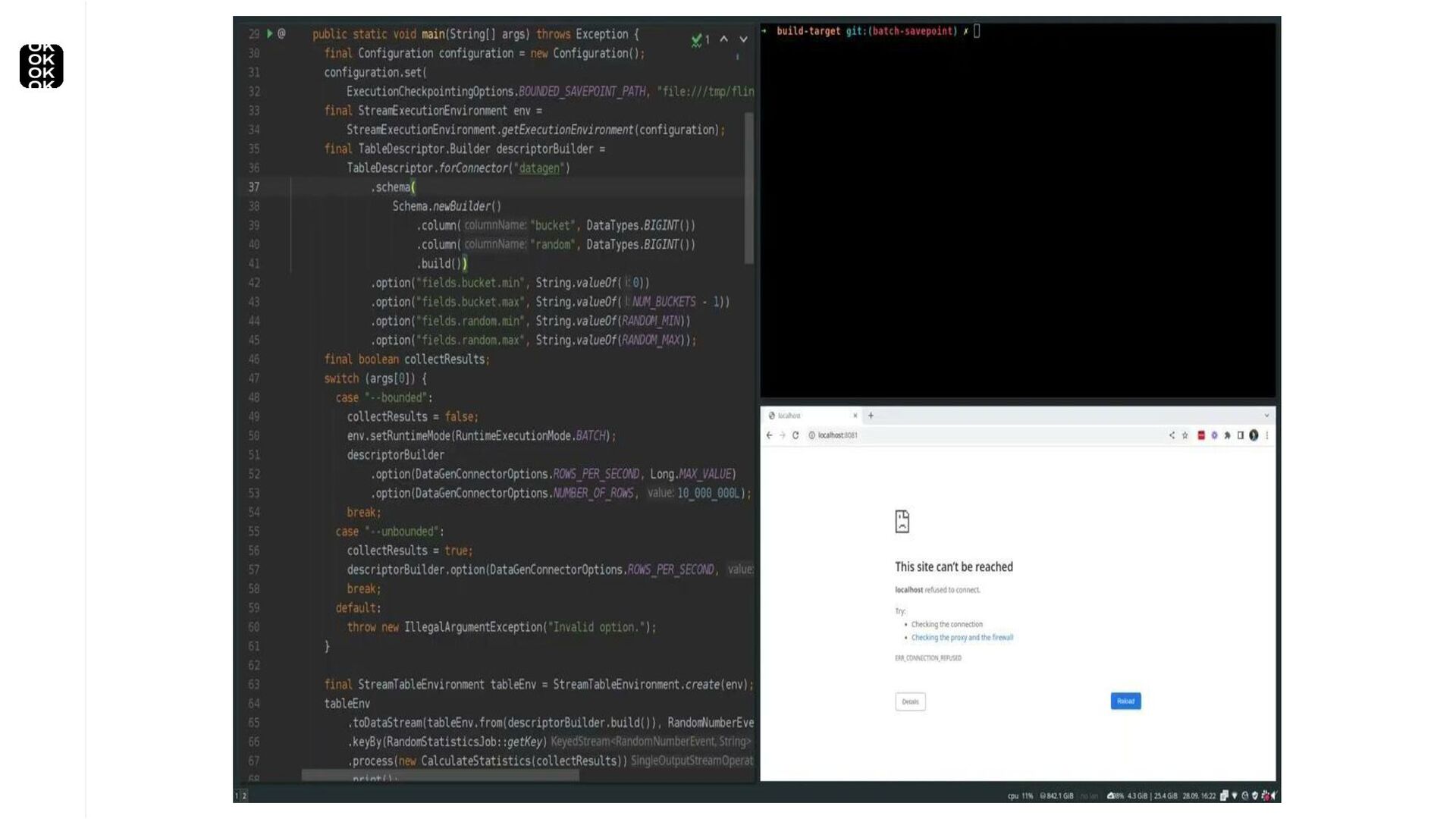
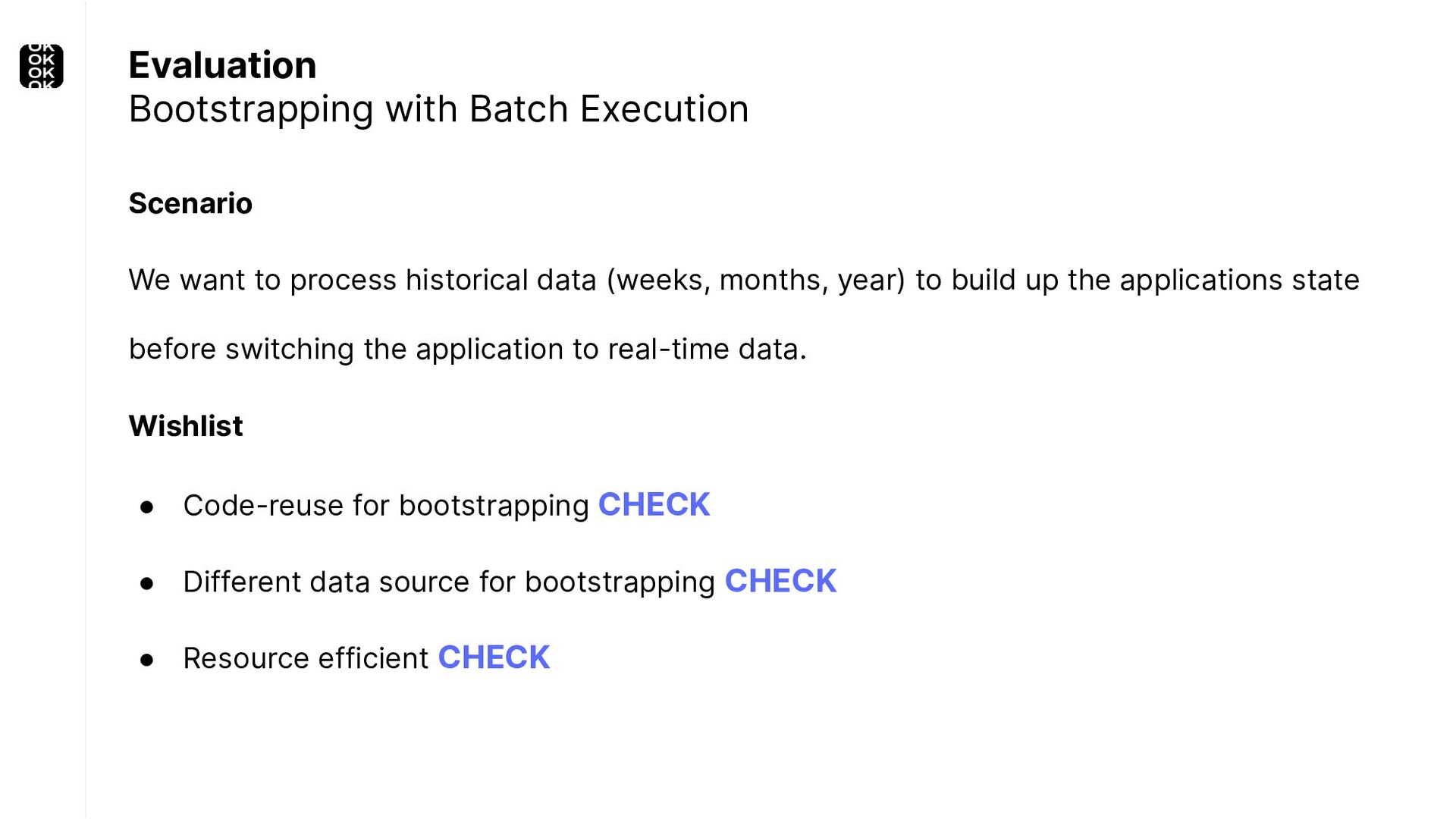
* For bootstrapping the initial state of an application
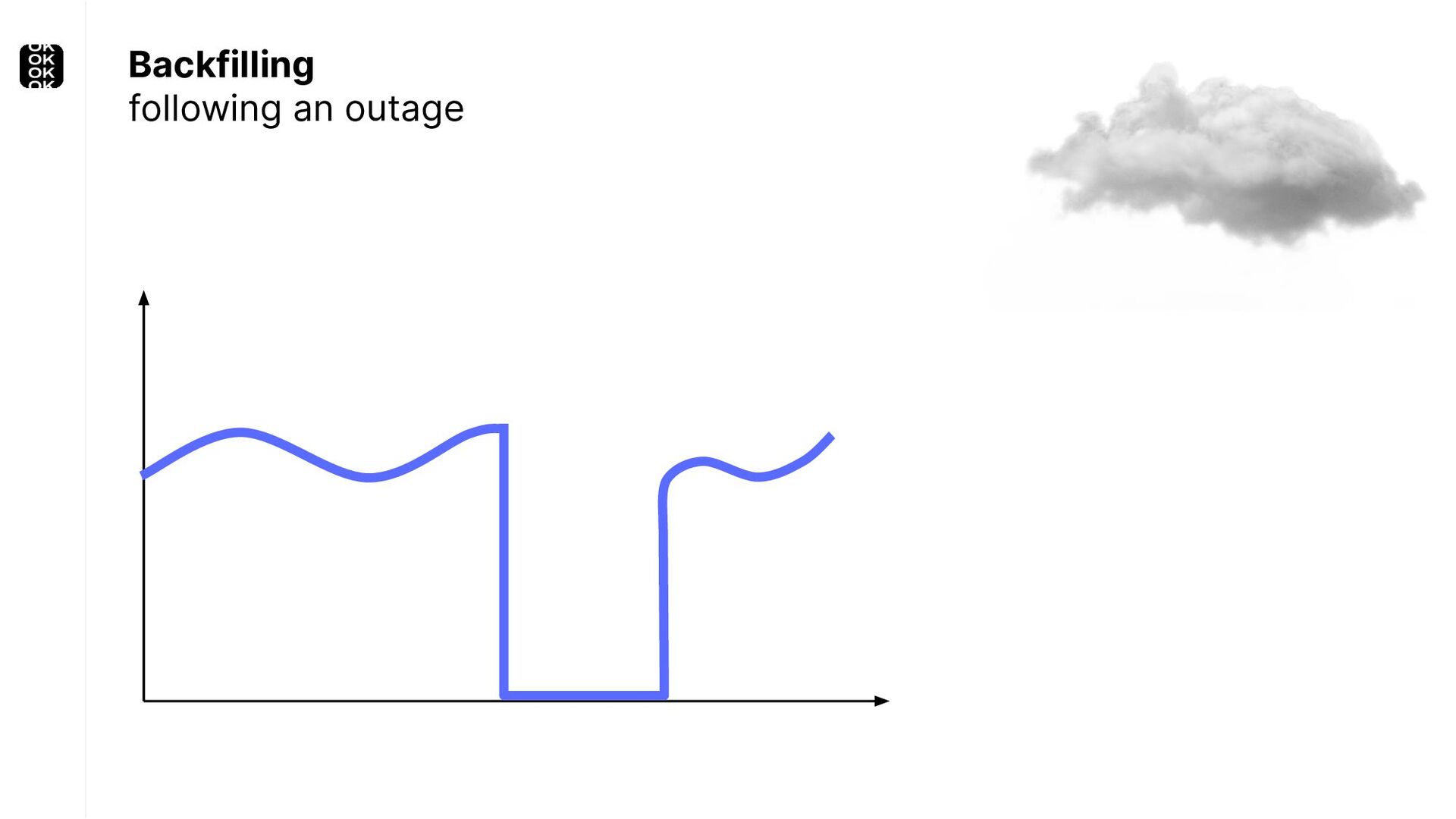
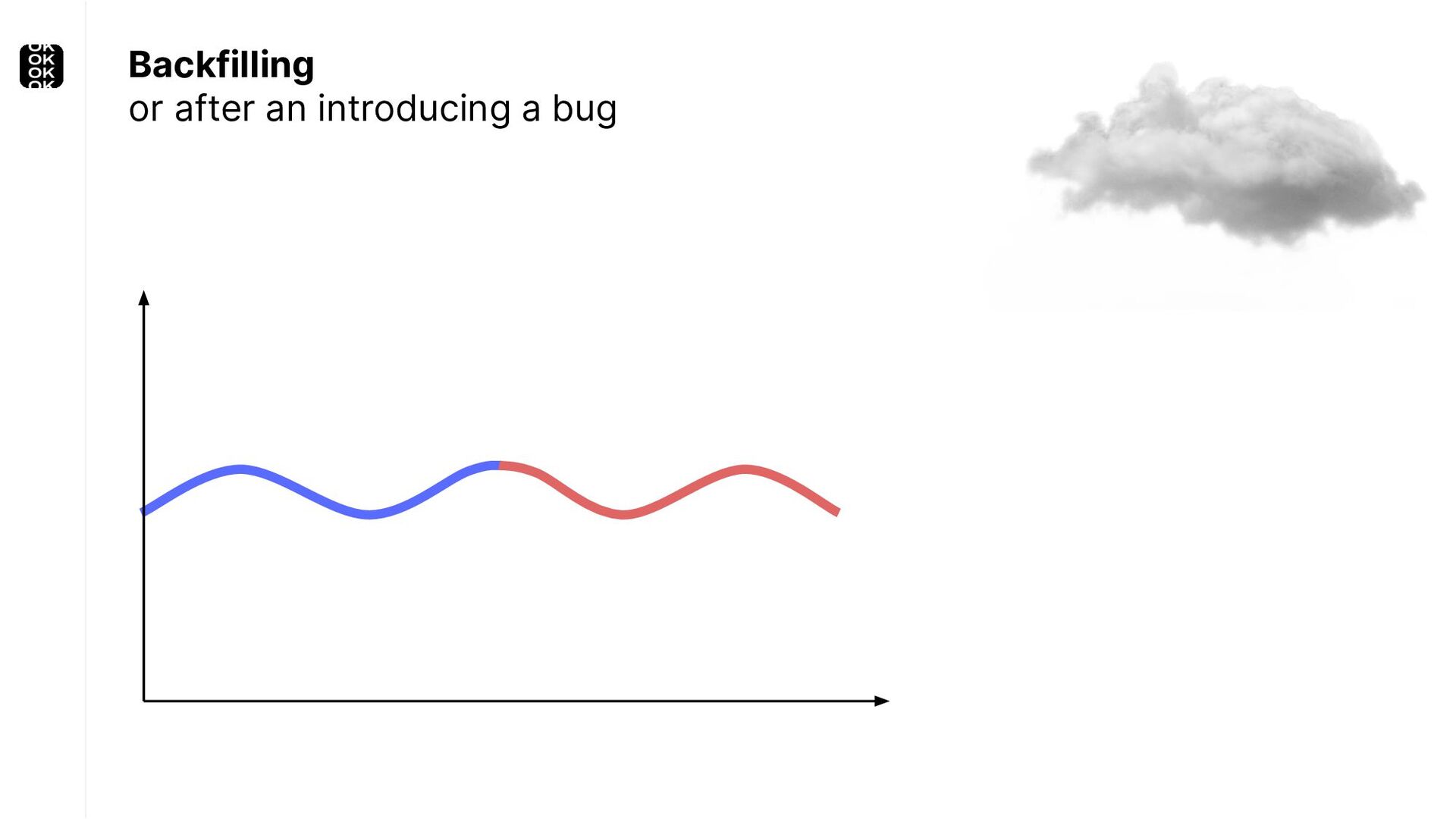
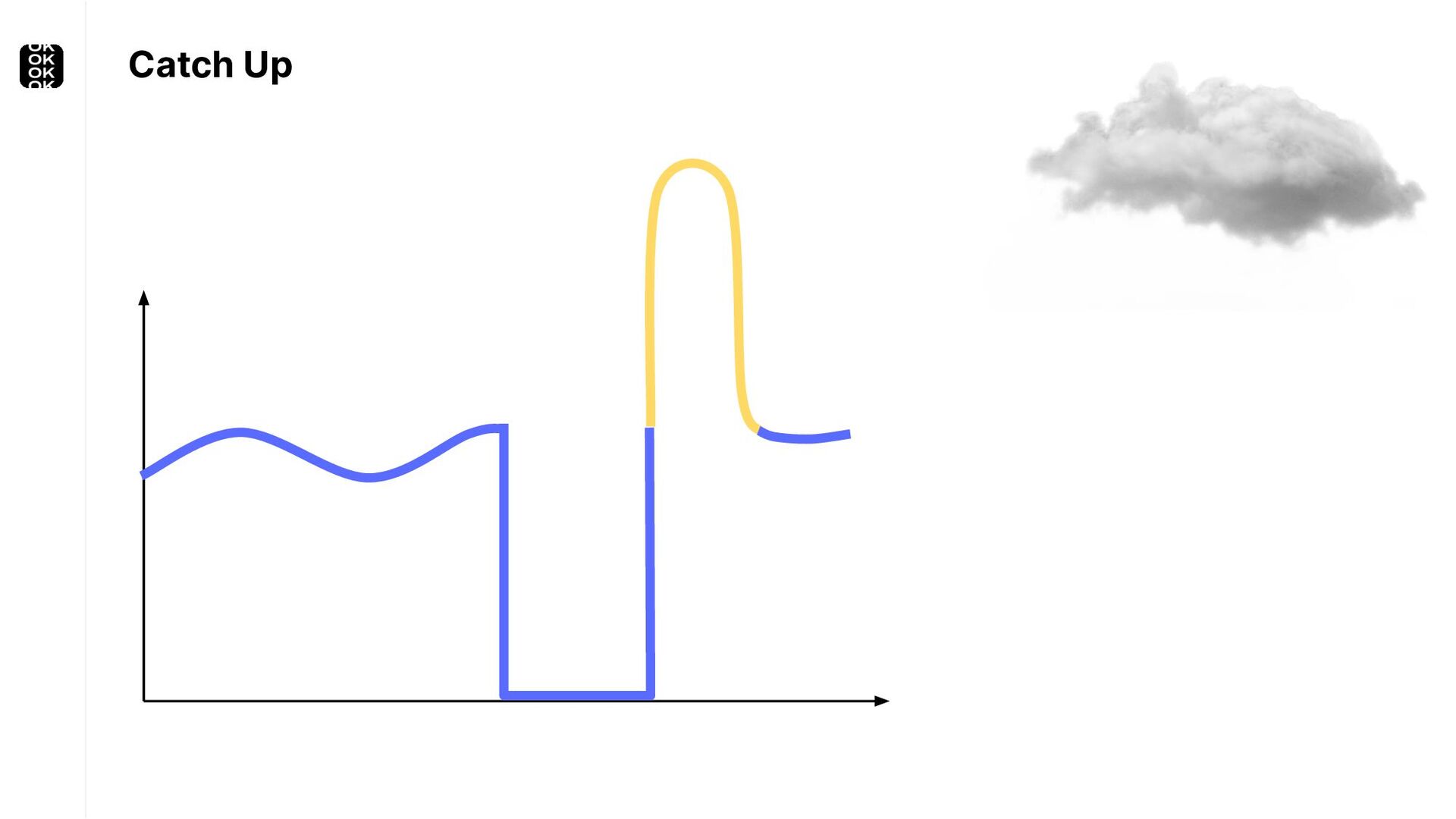
* For back-filling following an outage or bugfix
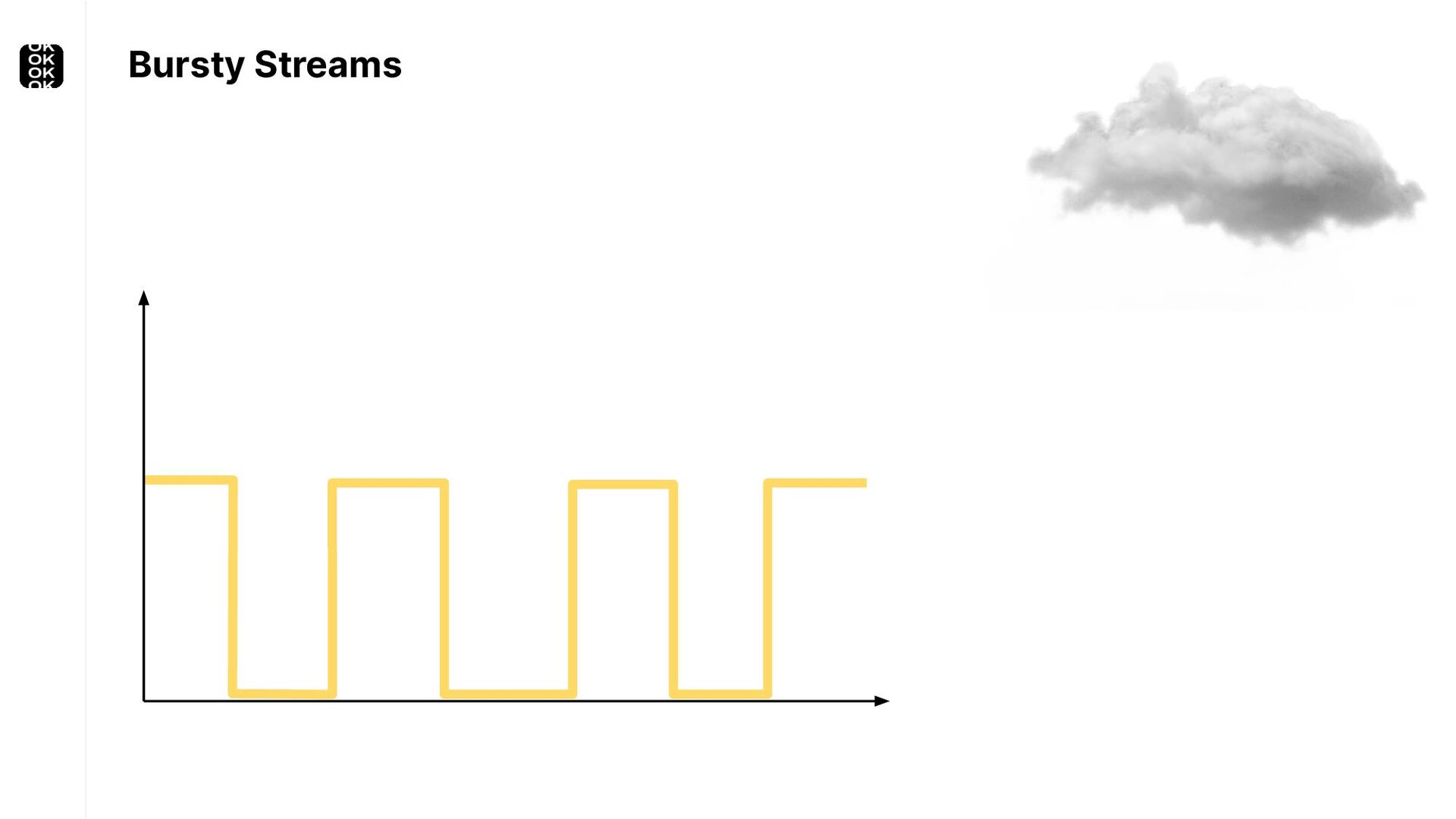
* For keeping up with bursty input streams
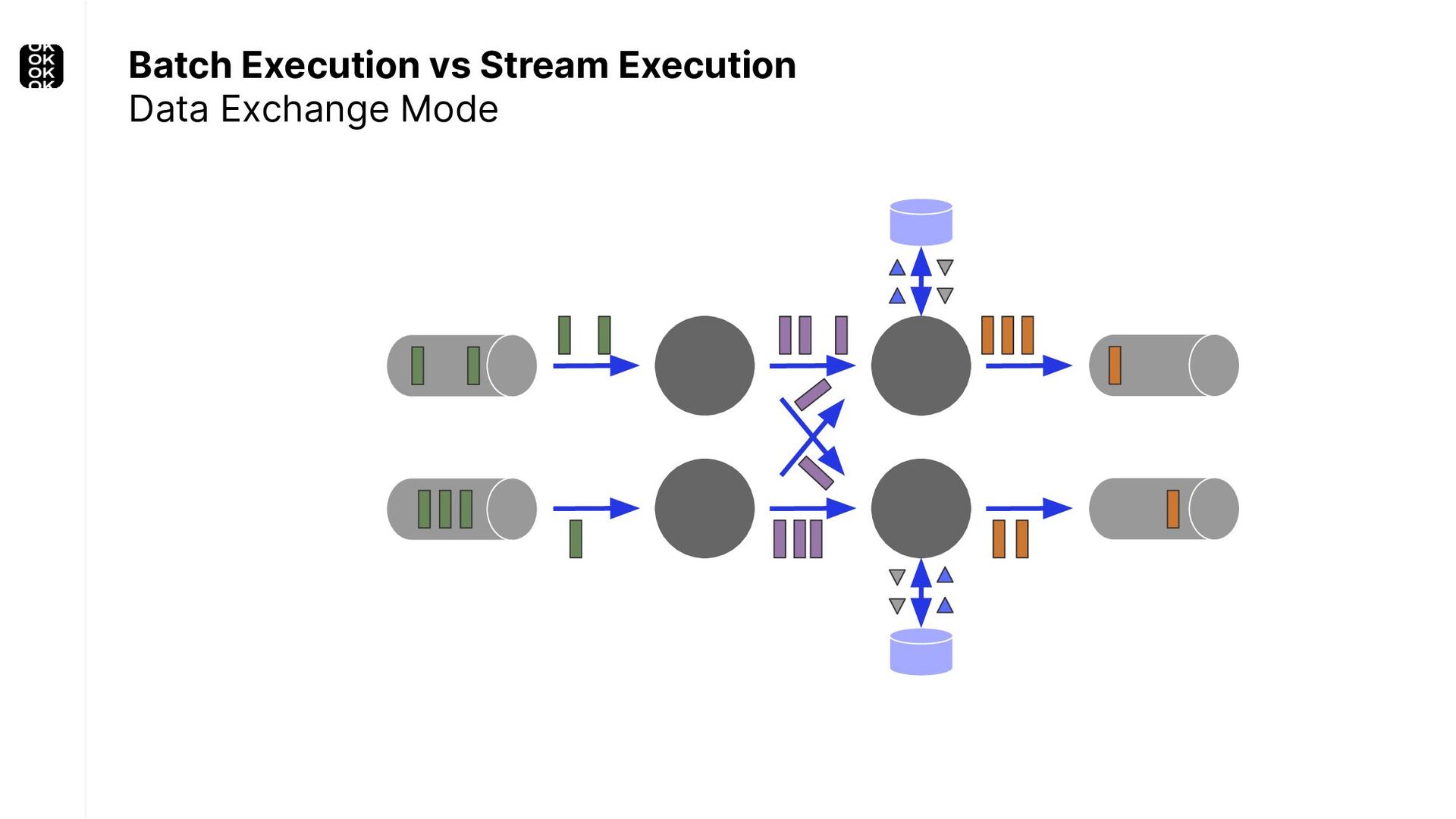
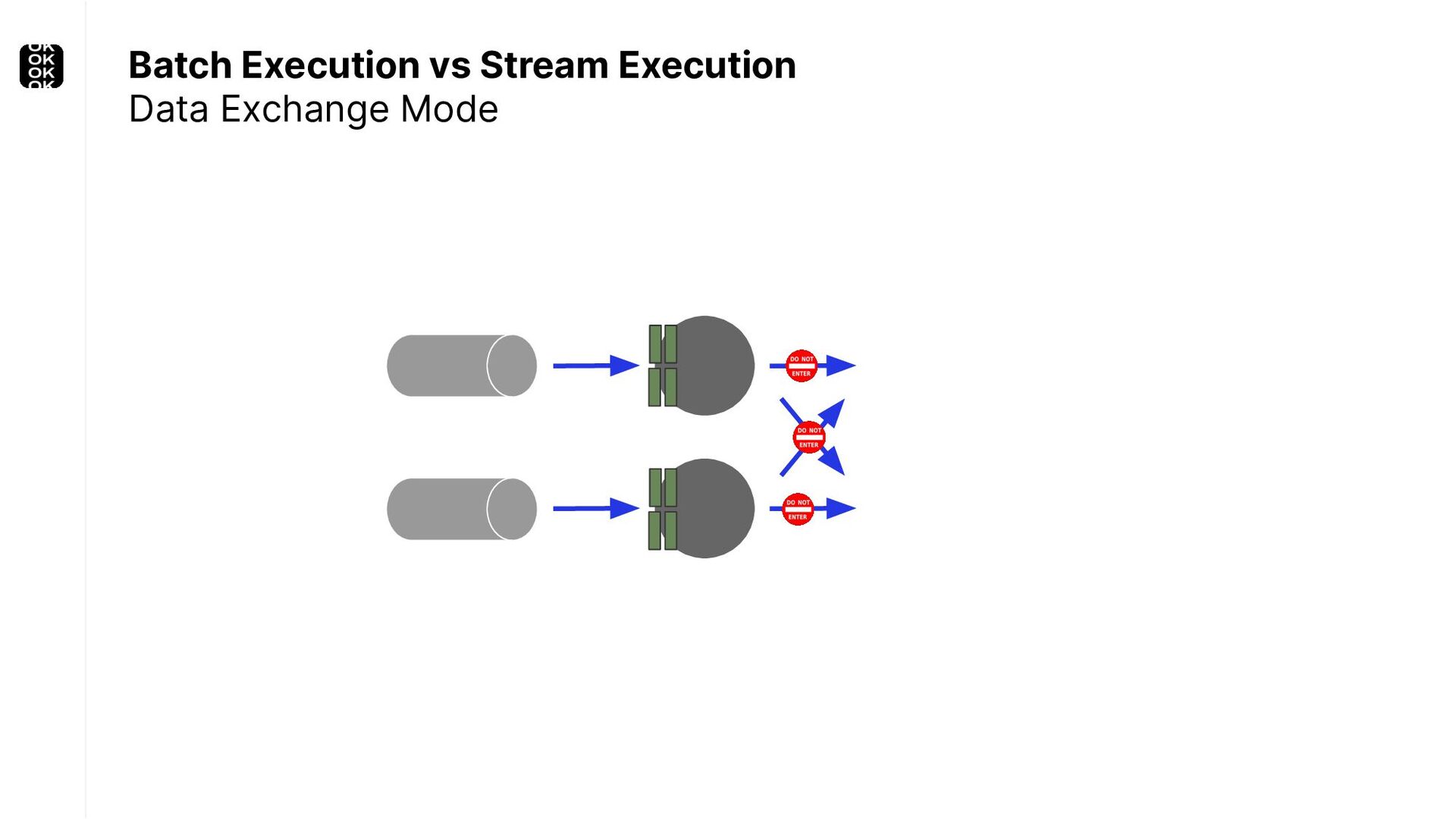
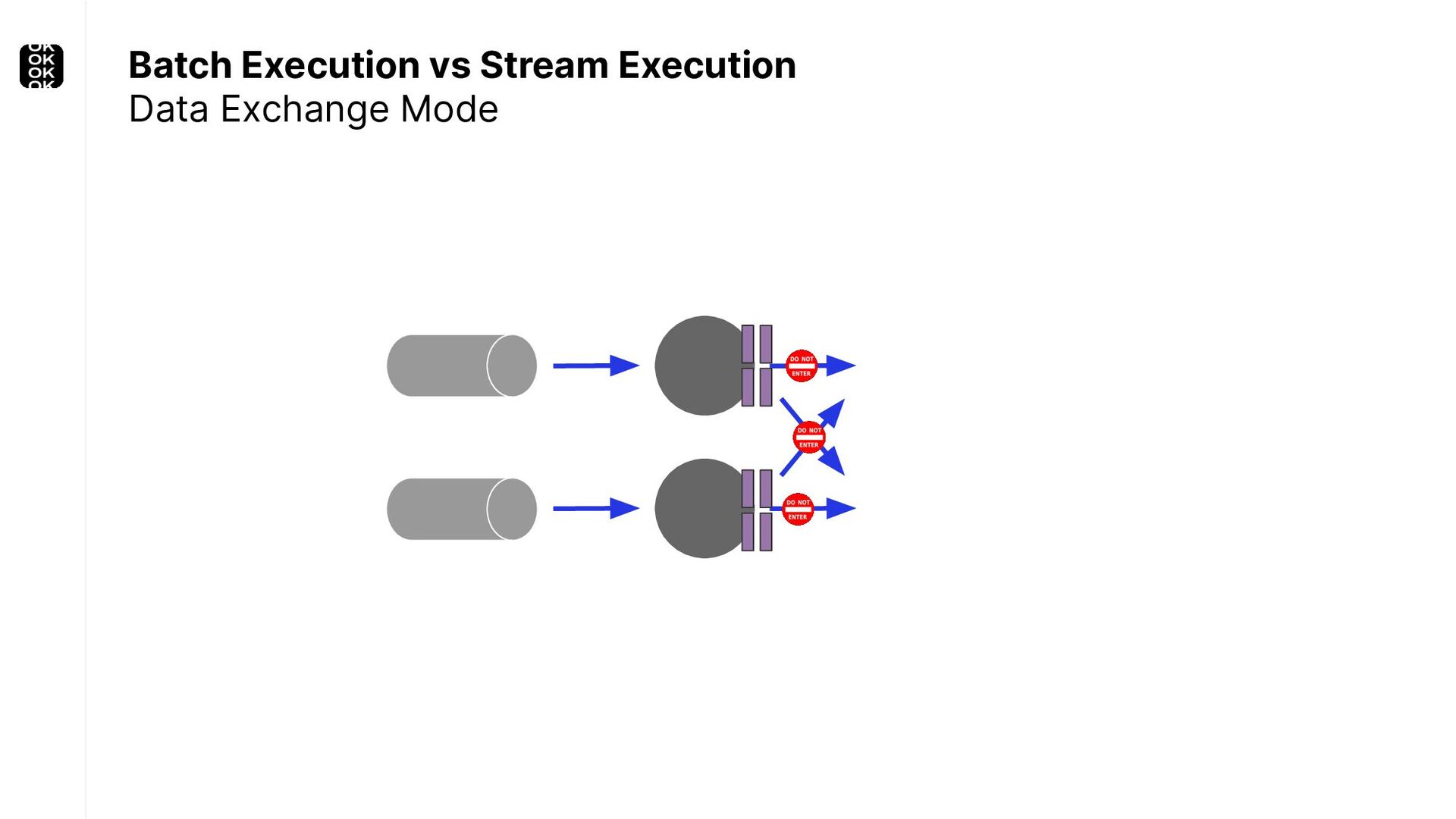
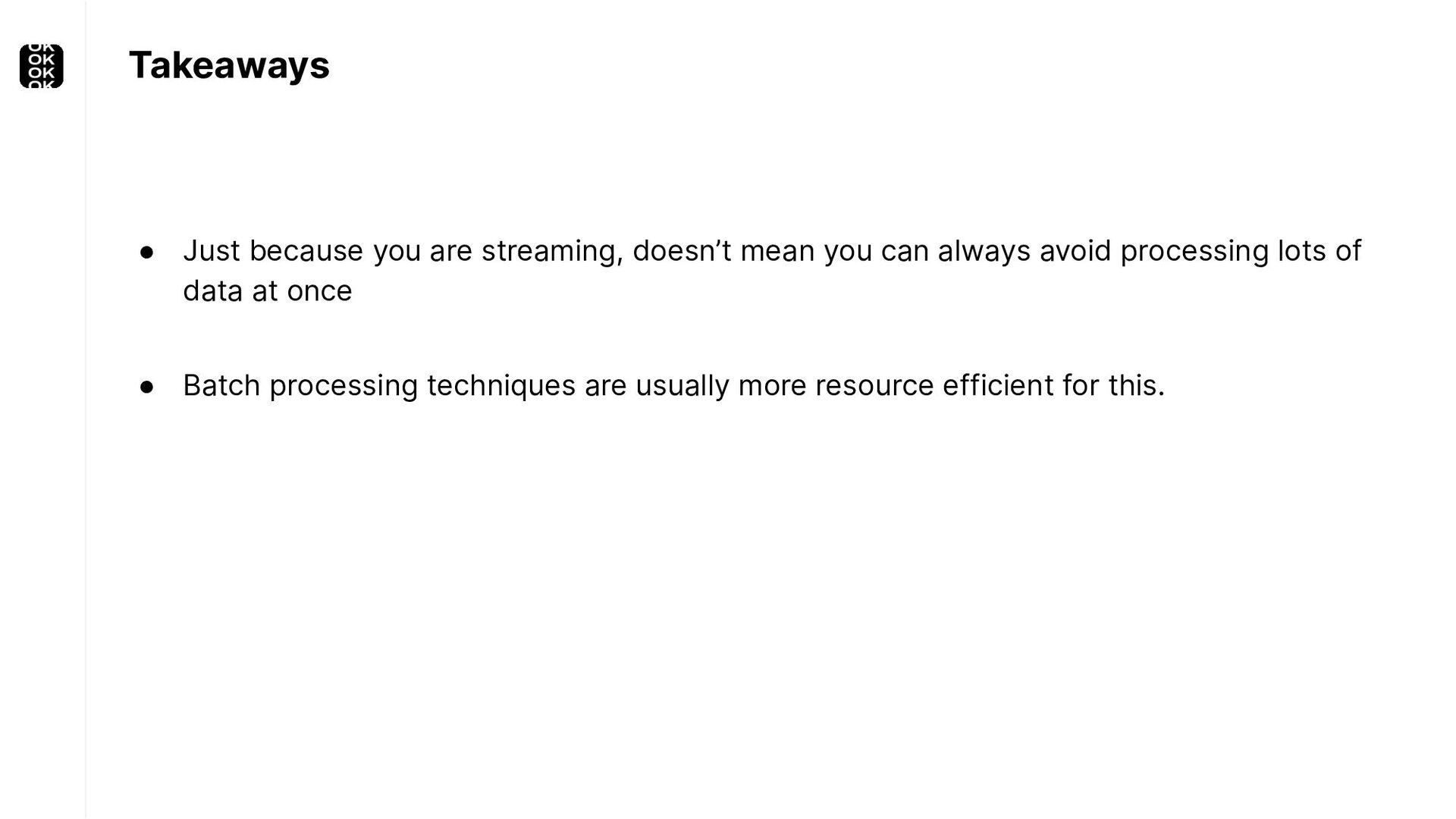
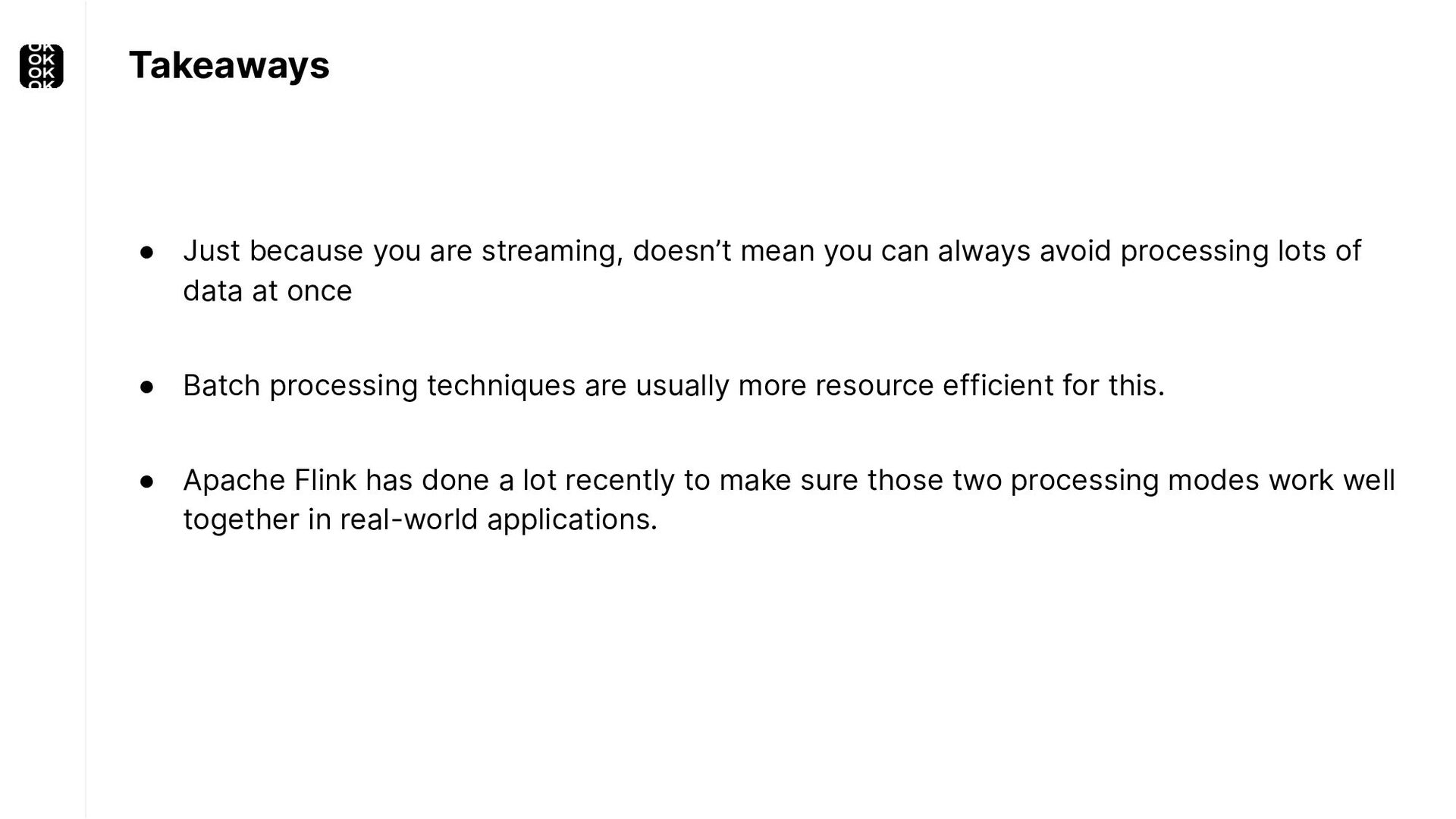
These scenarios call for batch processing techniques. Apache Flink is as streaming-first as it gets. Yet over the last releases, the community has invested significant resources into unifying stream- and batch processing on all layers of the stack: scheduler to APIs. In this talk, I'll introduce Apache Flink's approach to unified stream and batch processing and discuss - by example - how these scenarios can already be addressed today and what might be possible in the future.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
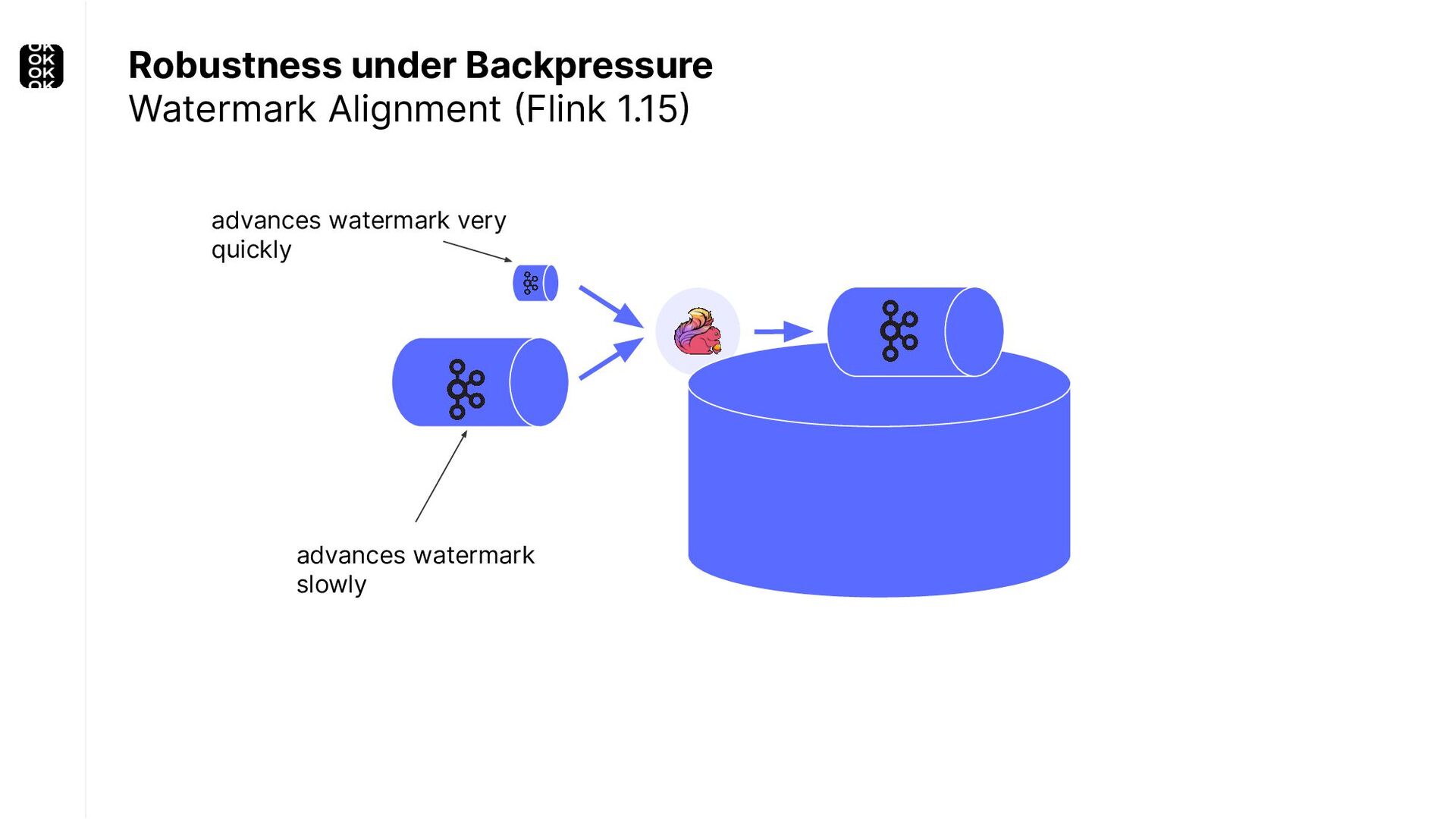{kind=link}
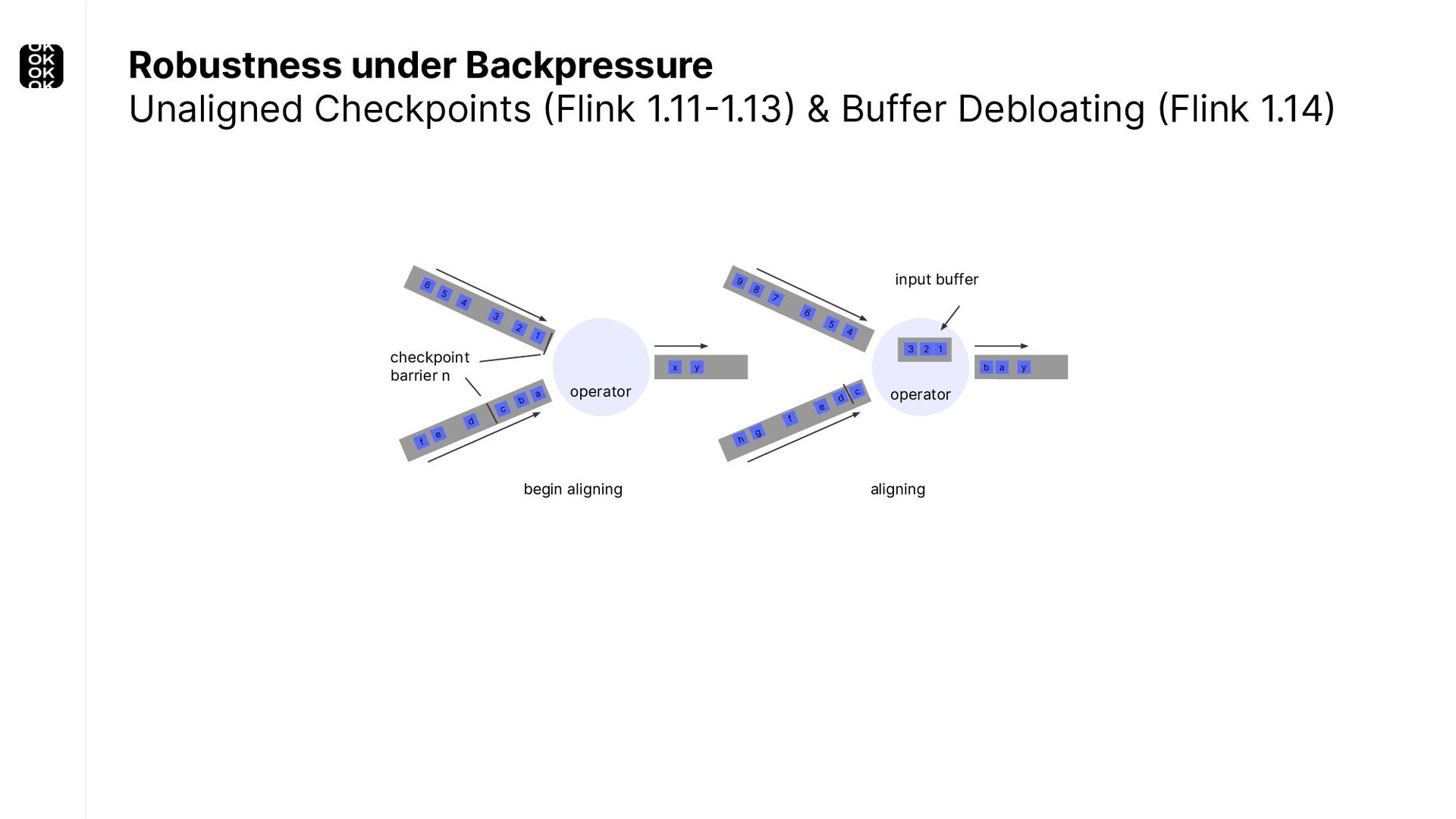{kind=link}
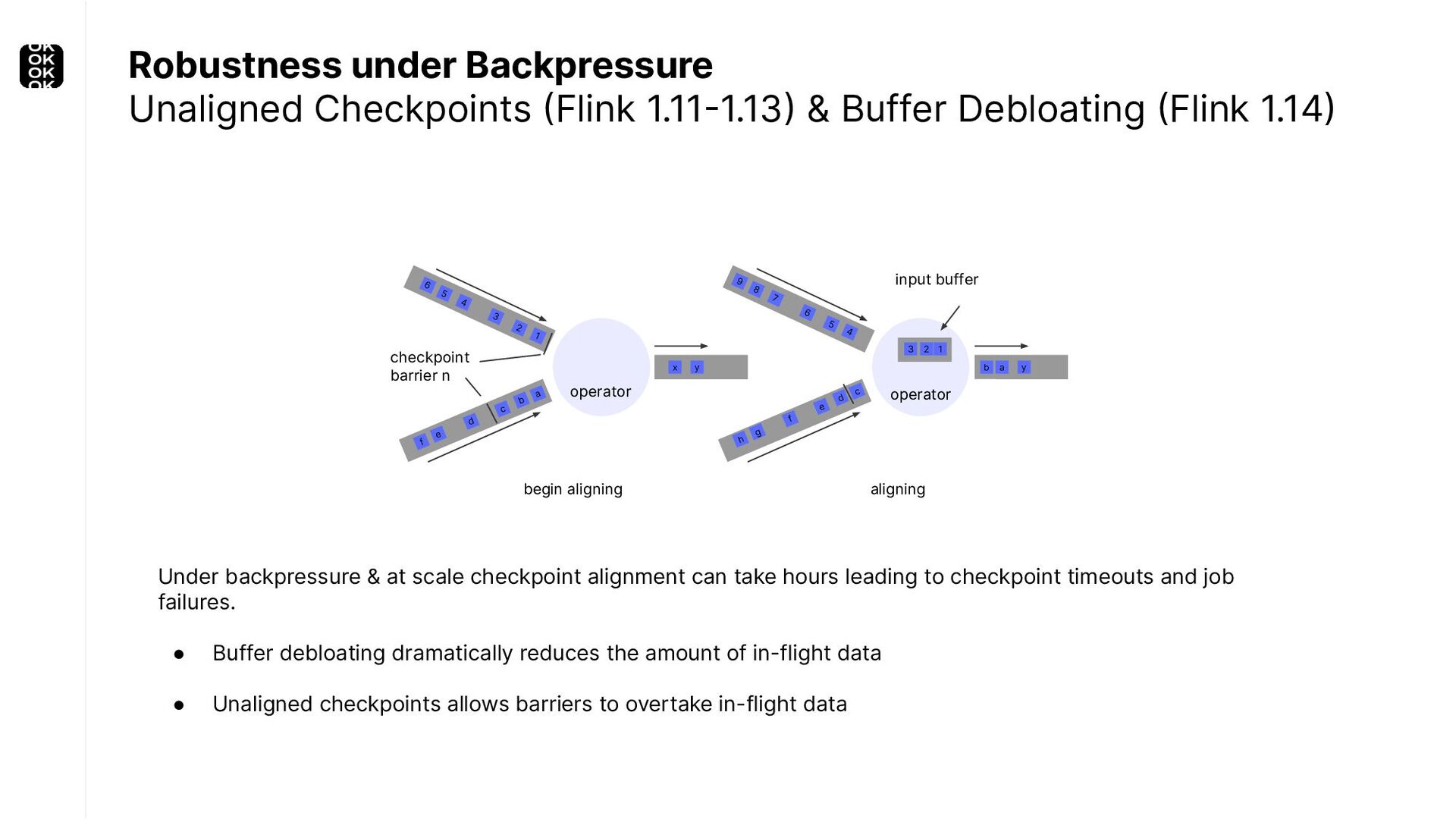{kind=link}
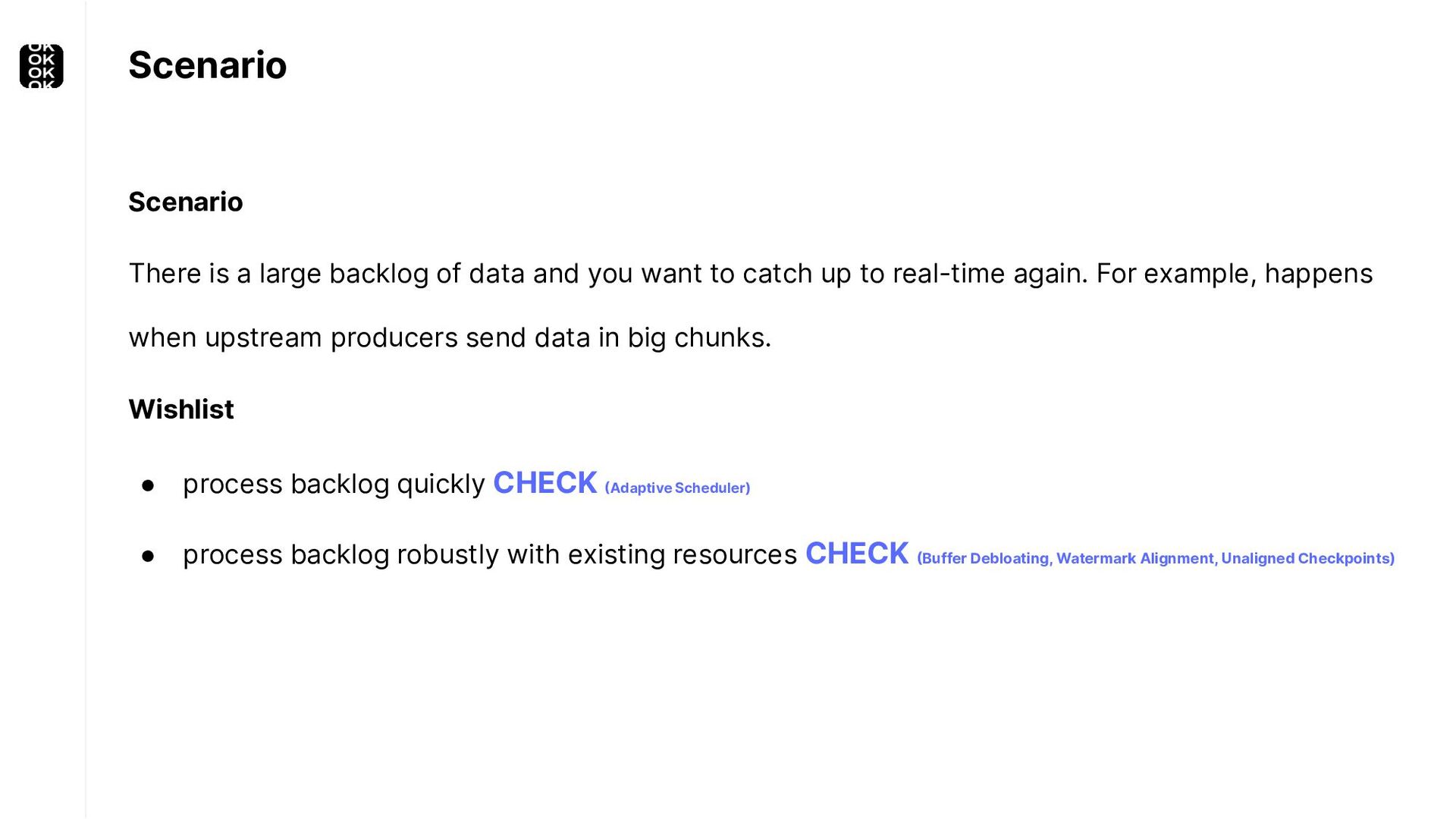{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks Konstantin Knauf @snntrable [email protected] CDC Stream Processing with Apache](https://files.speakerdeck.com/presentations/6bce3e6b76b14494b0e3324d69e0ff11/slide_100.jpg){kind=link}