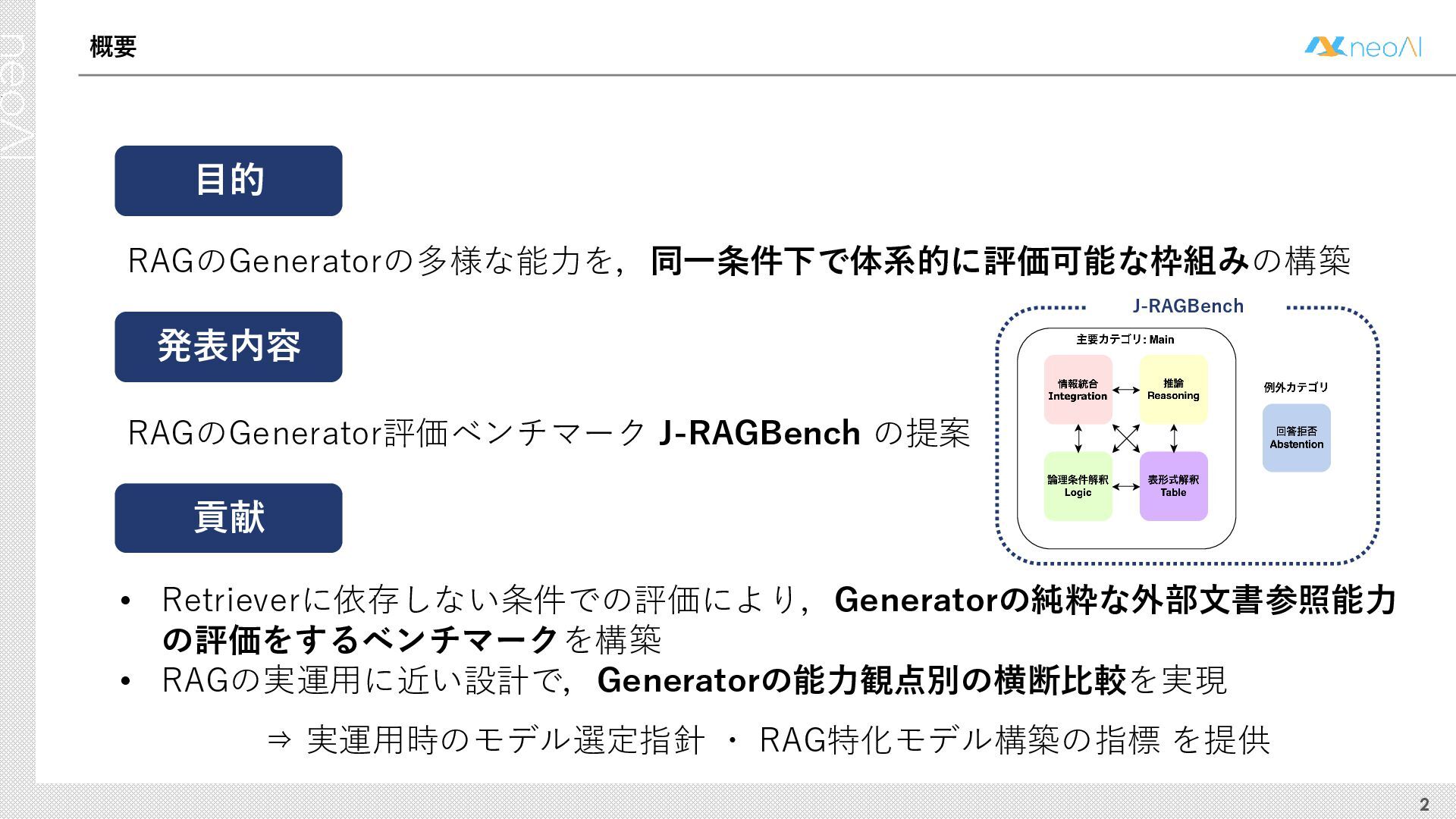
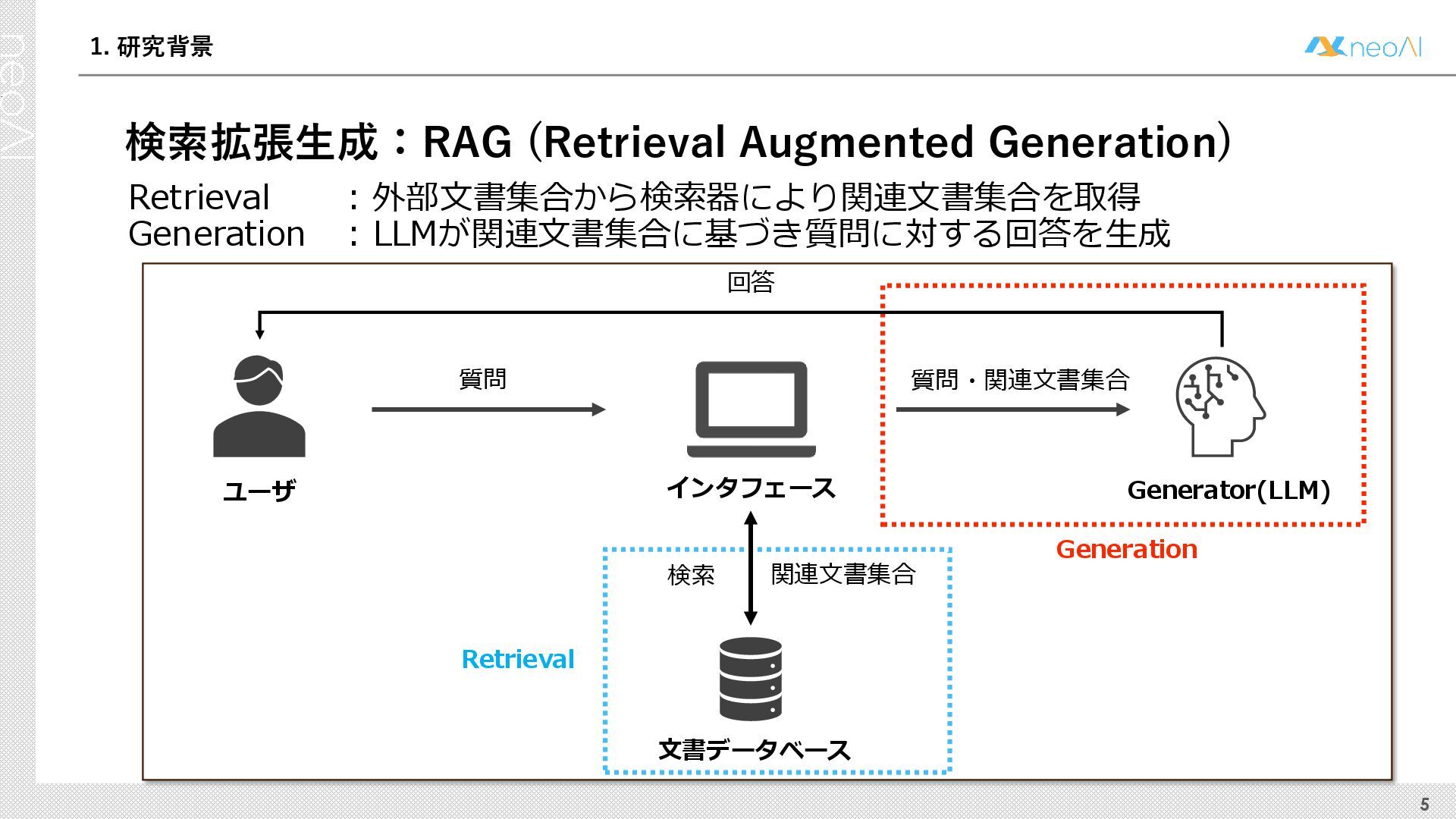
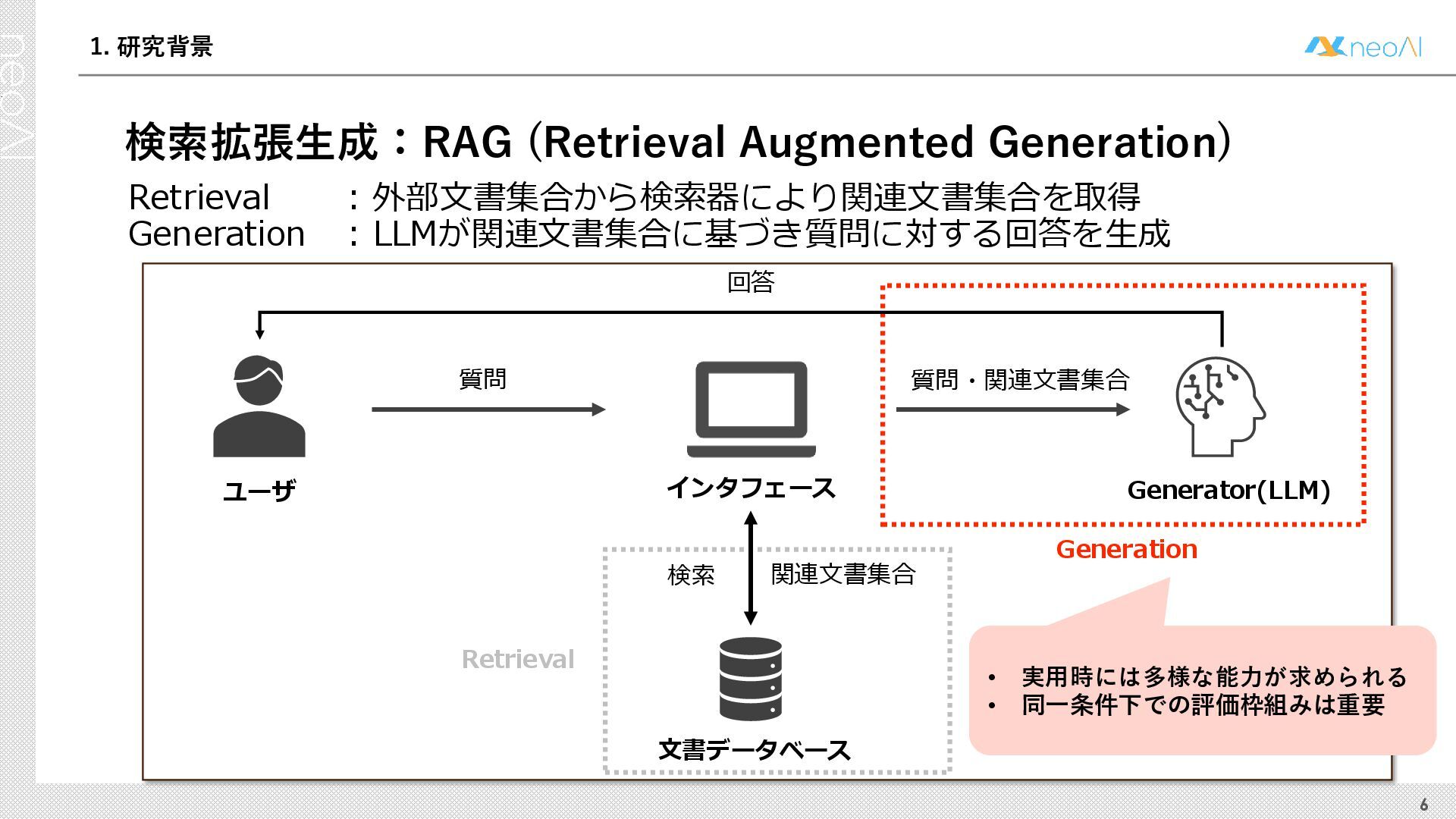
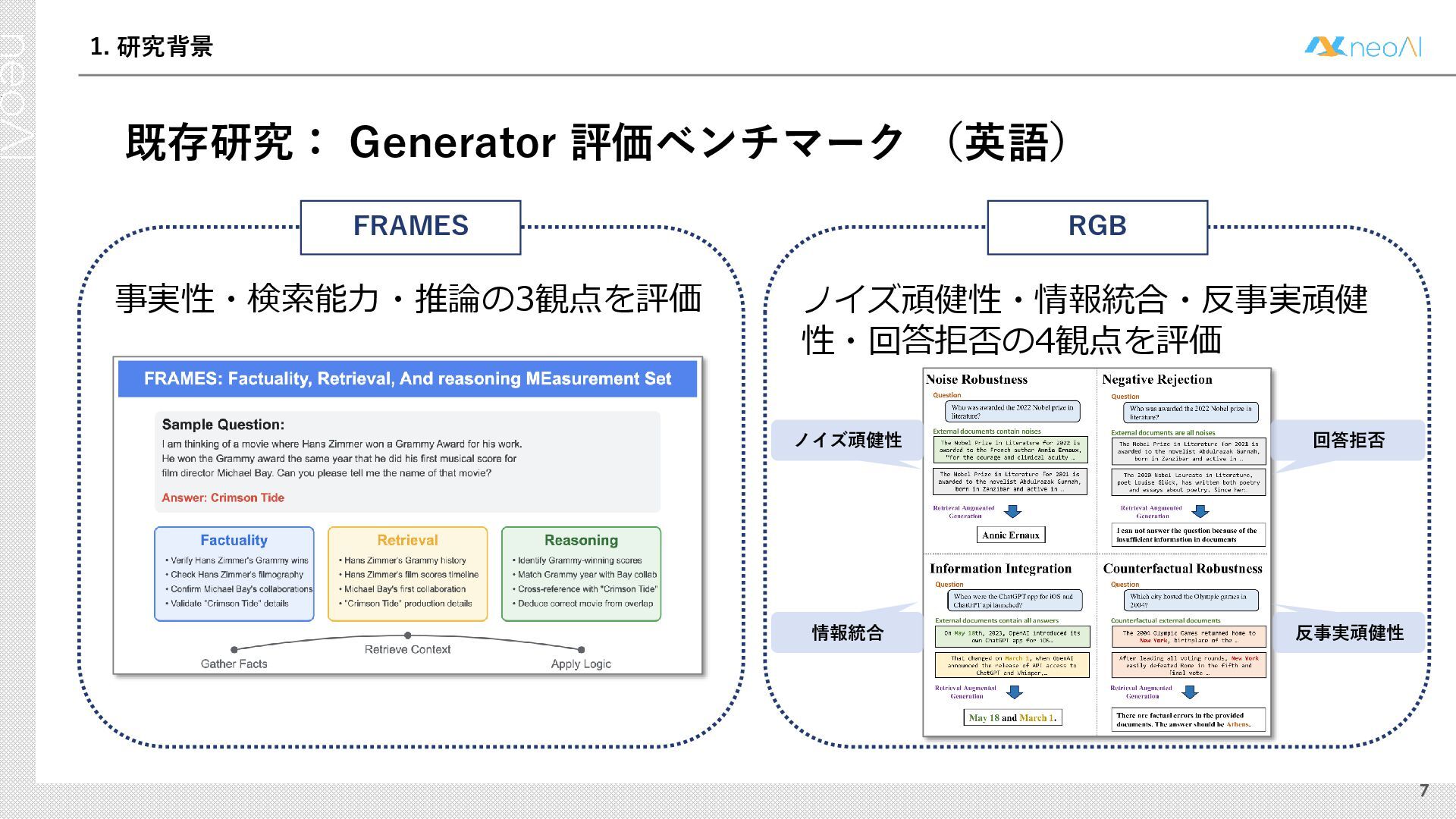
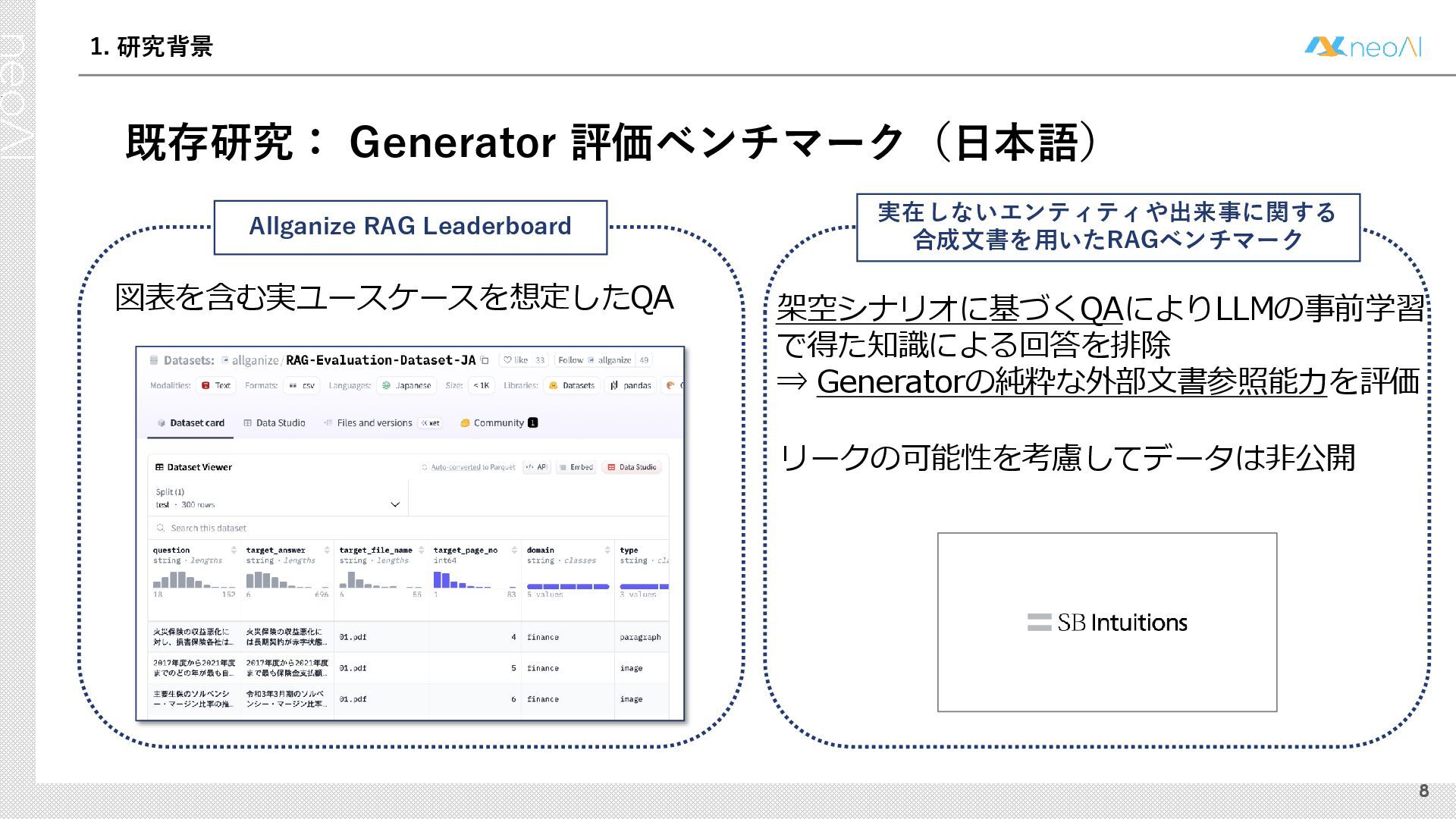
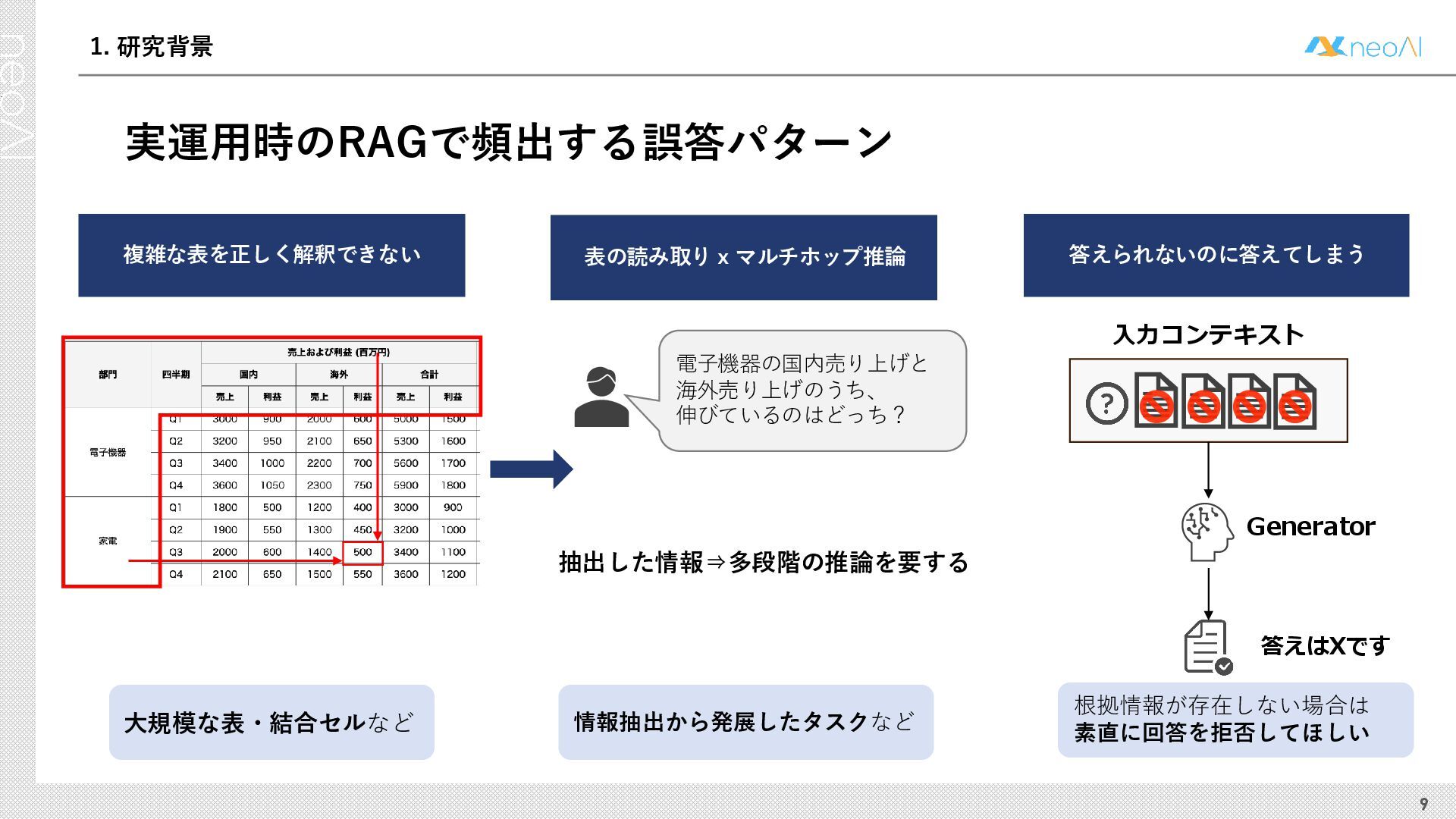
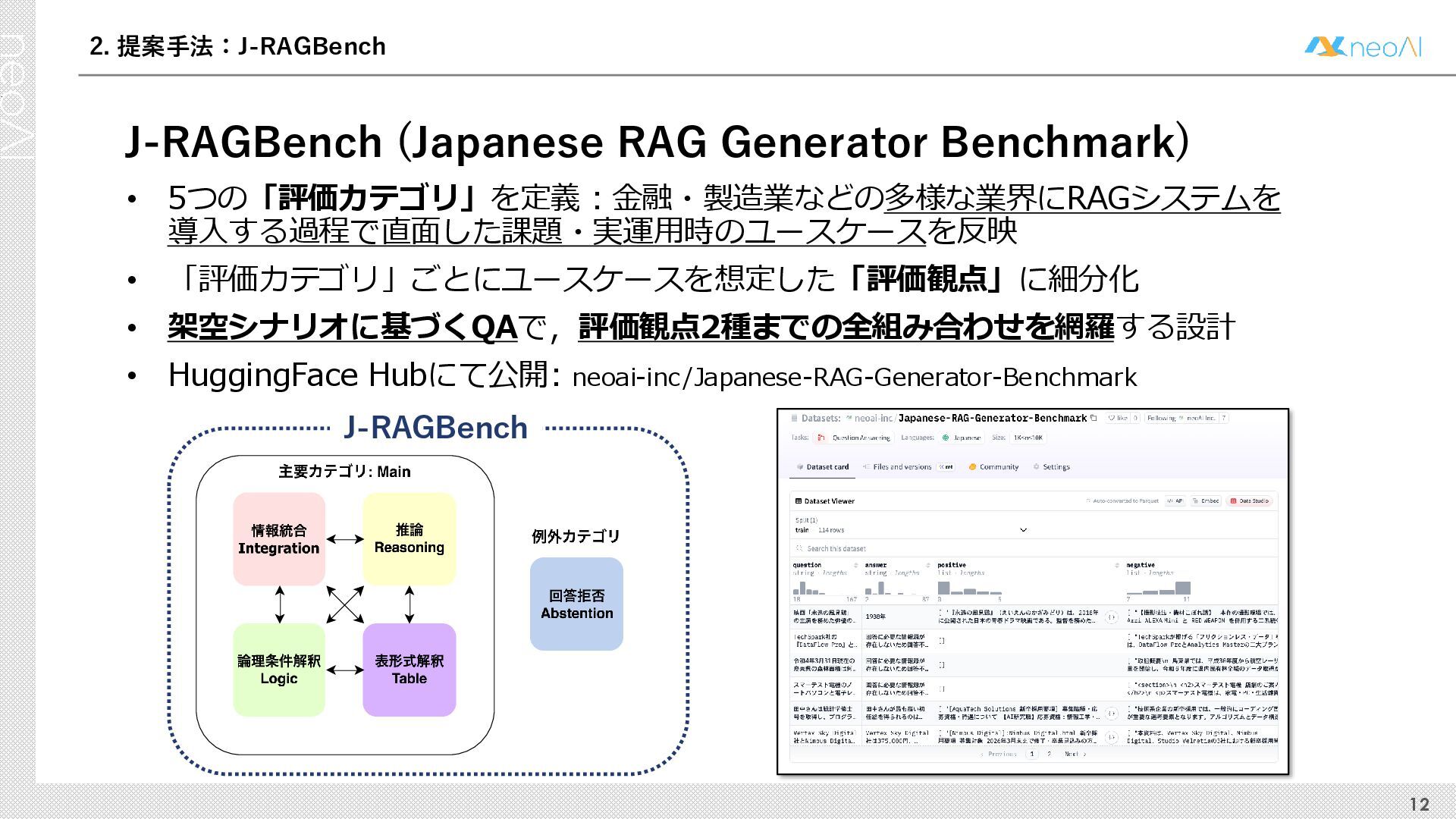
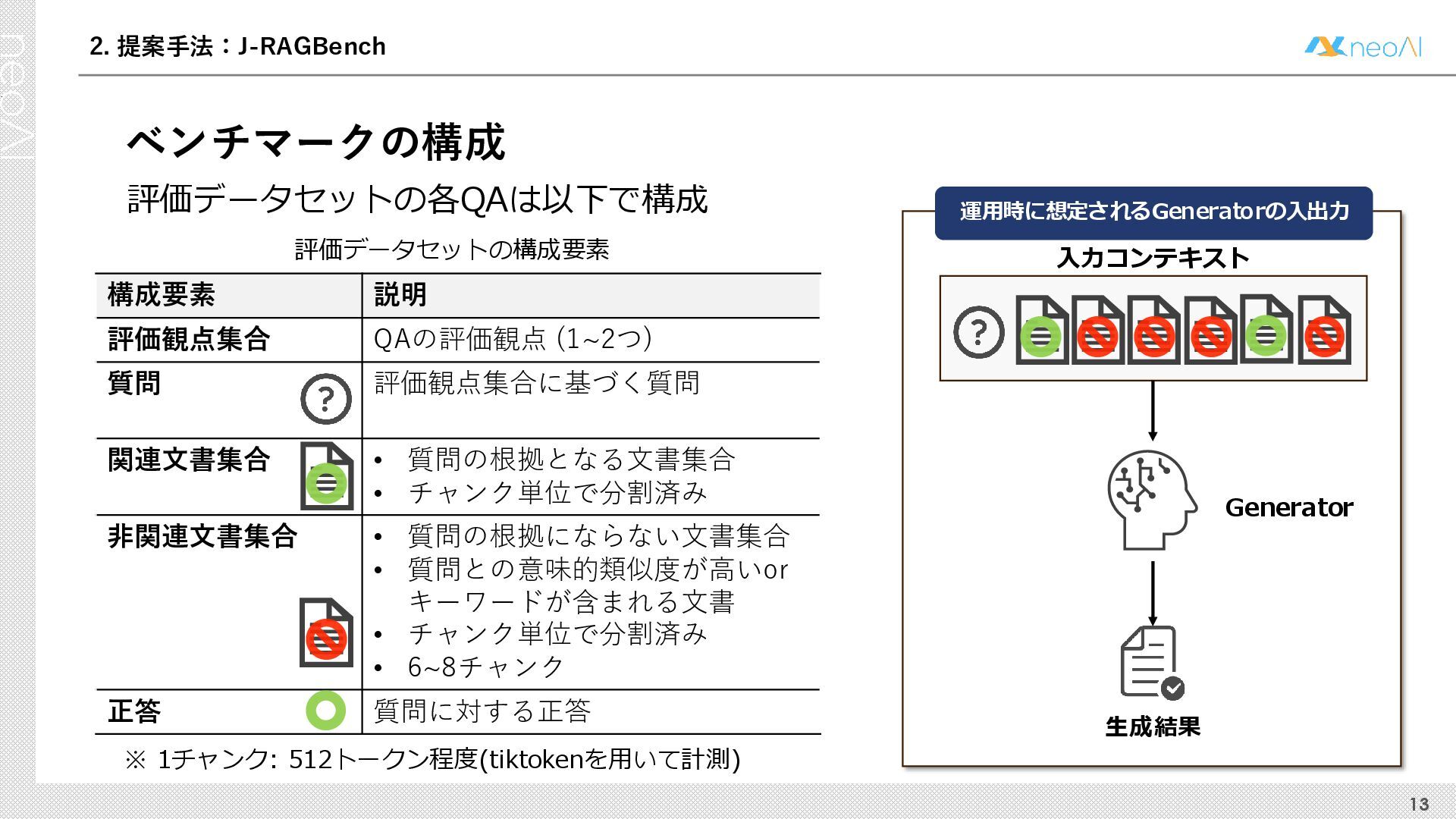
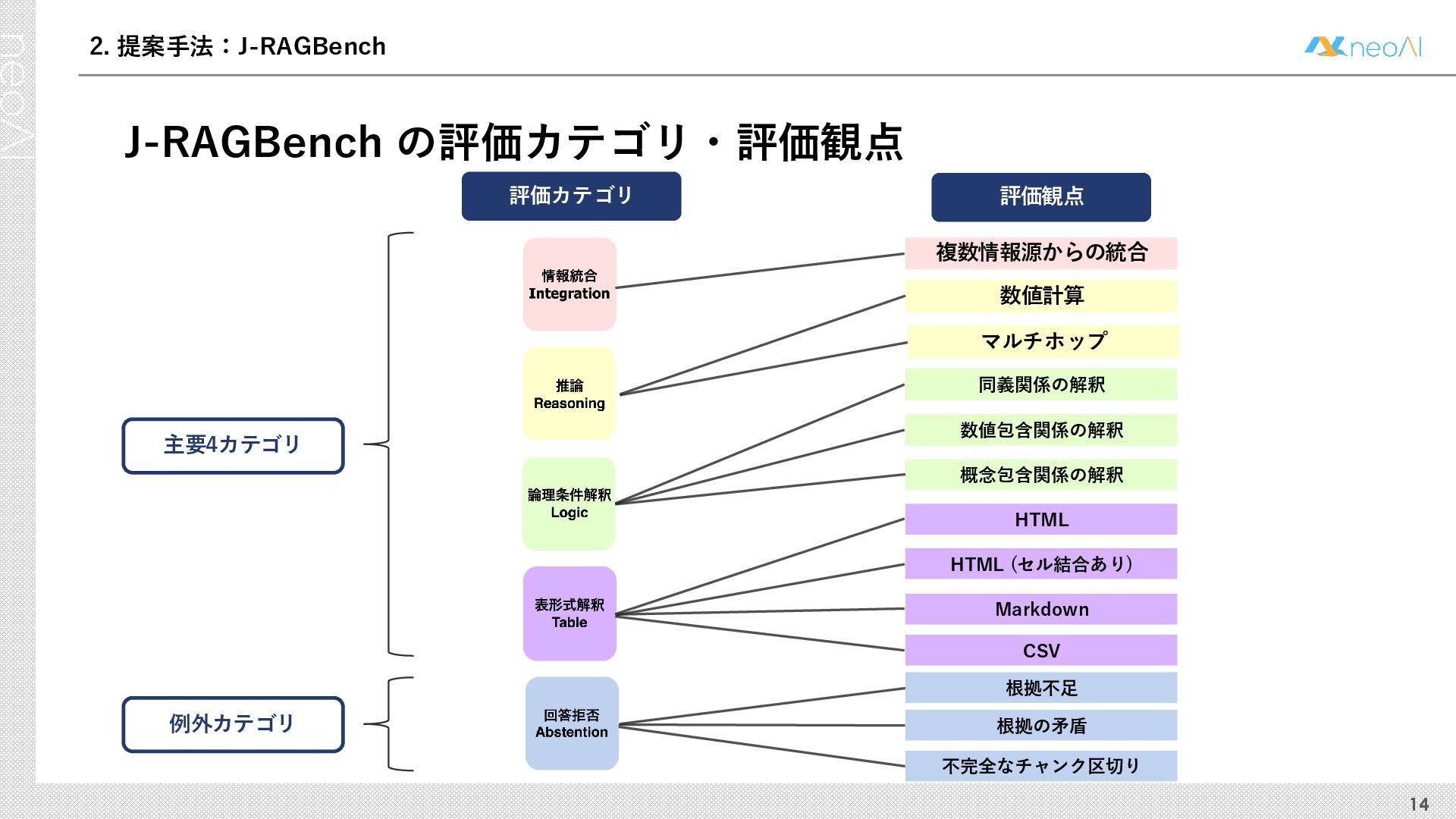
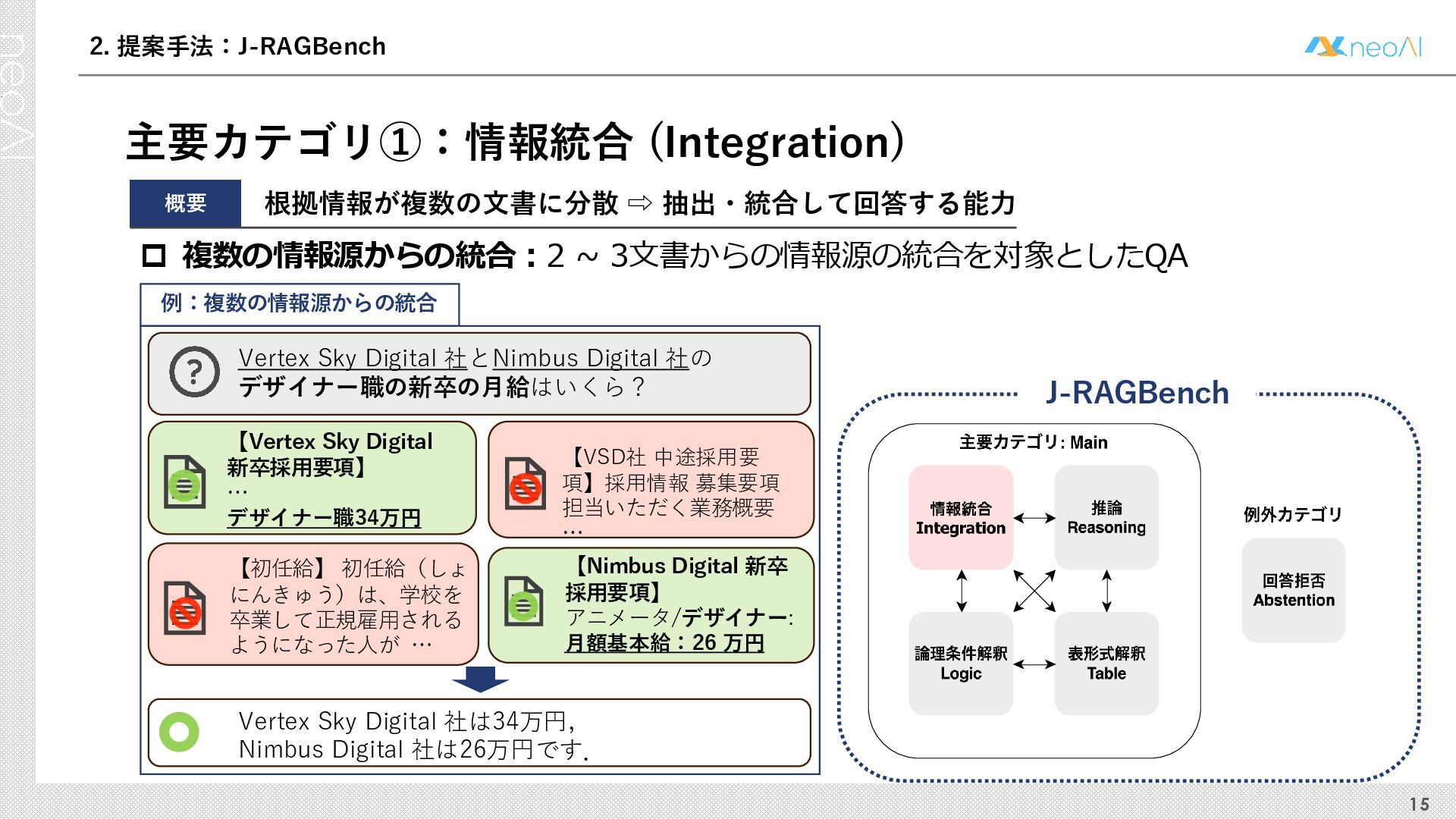
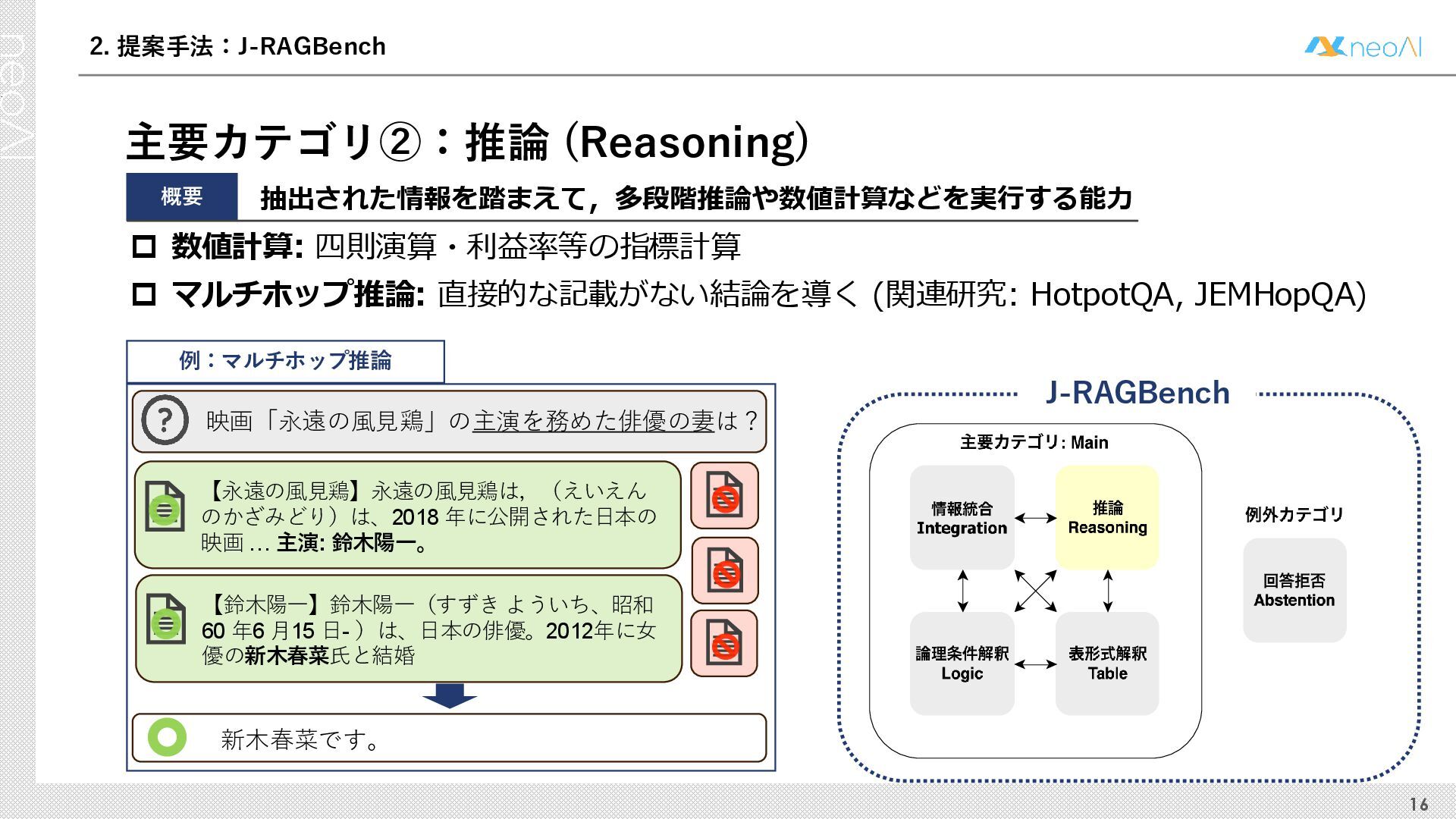
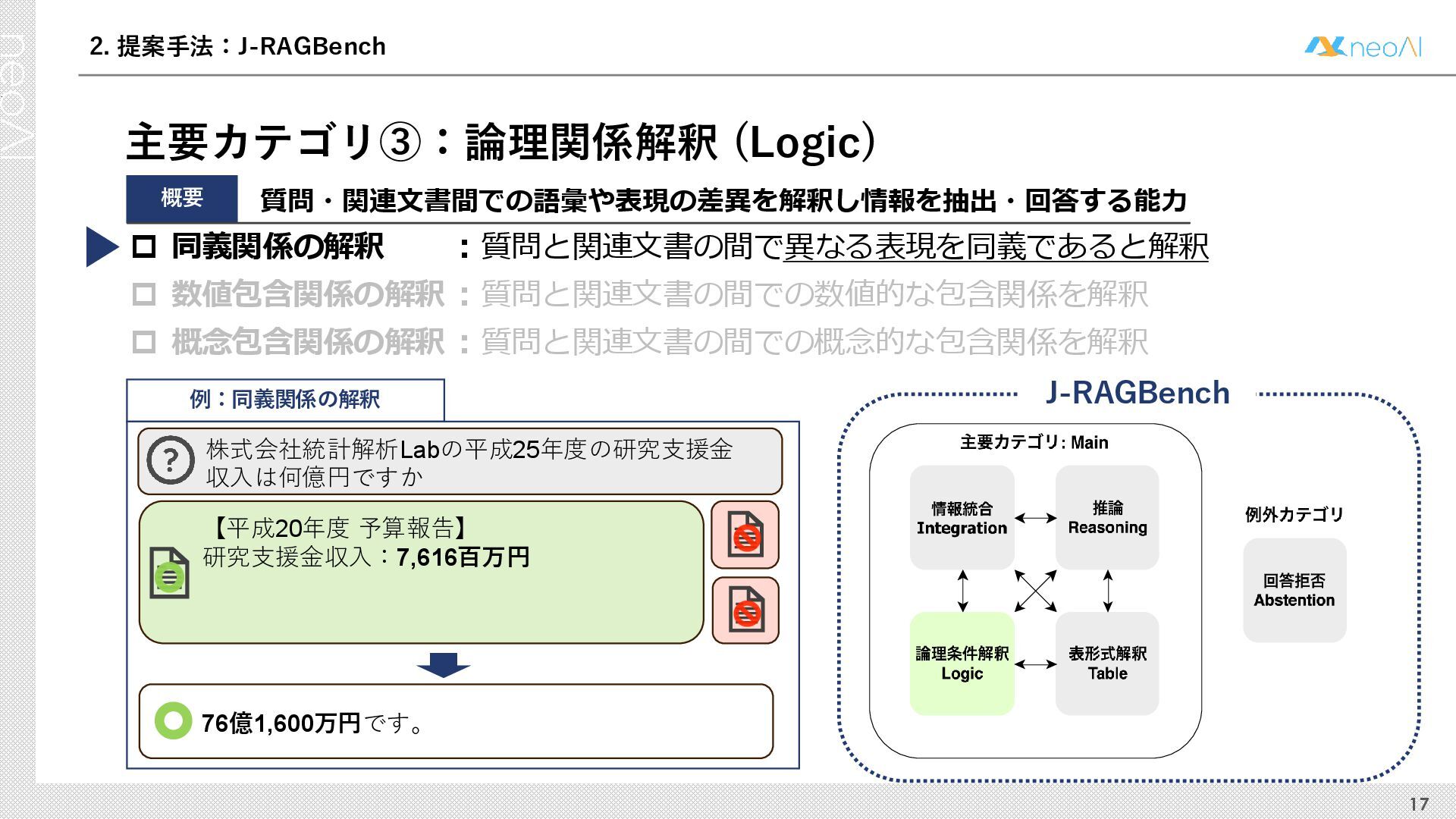
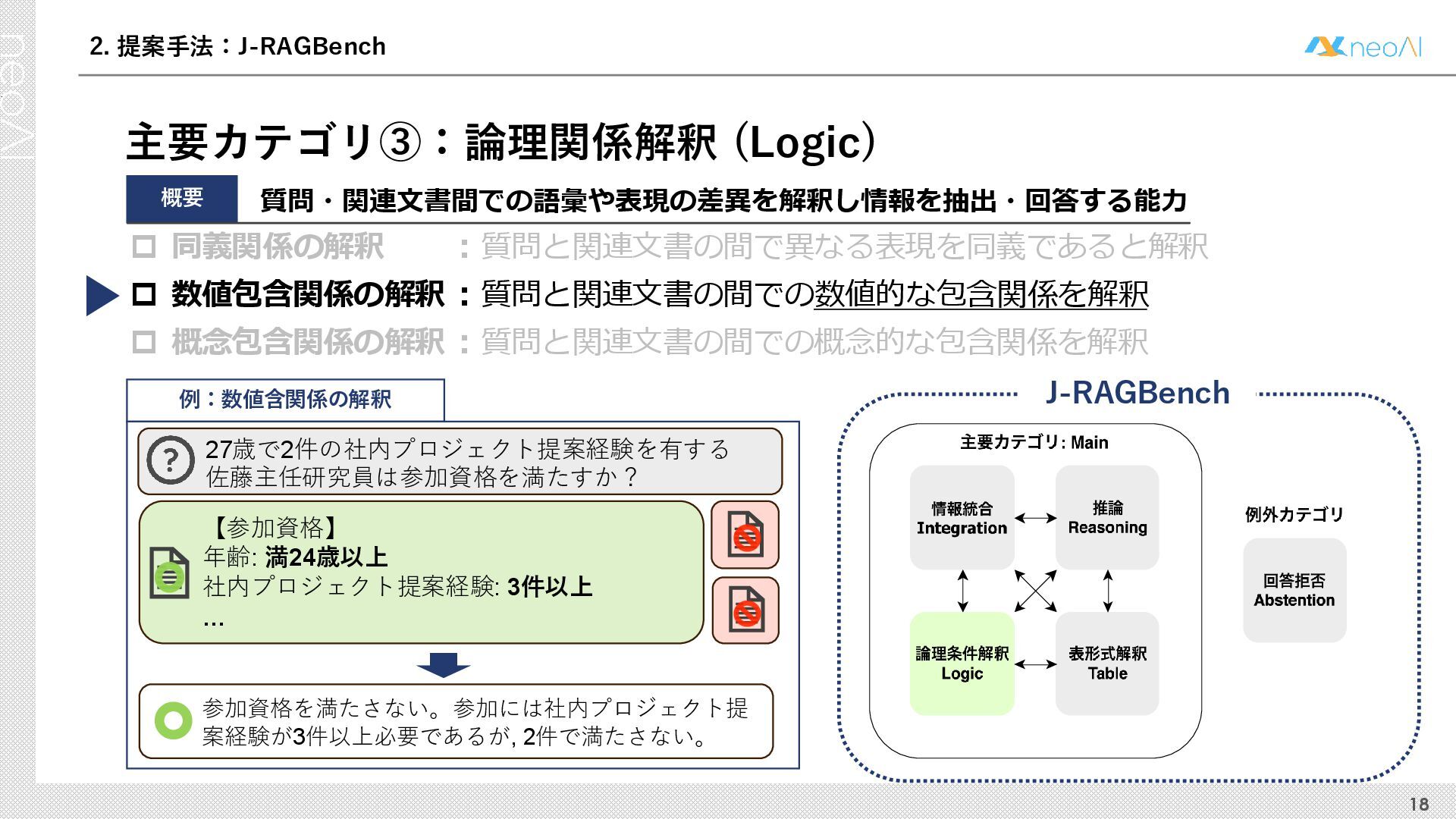
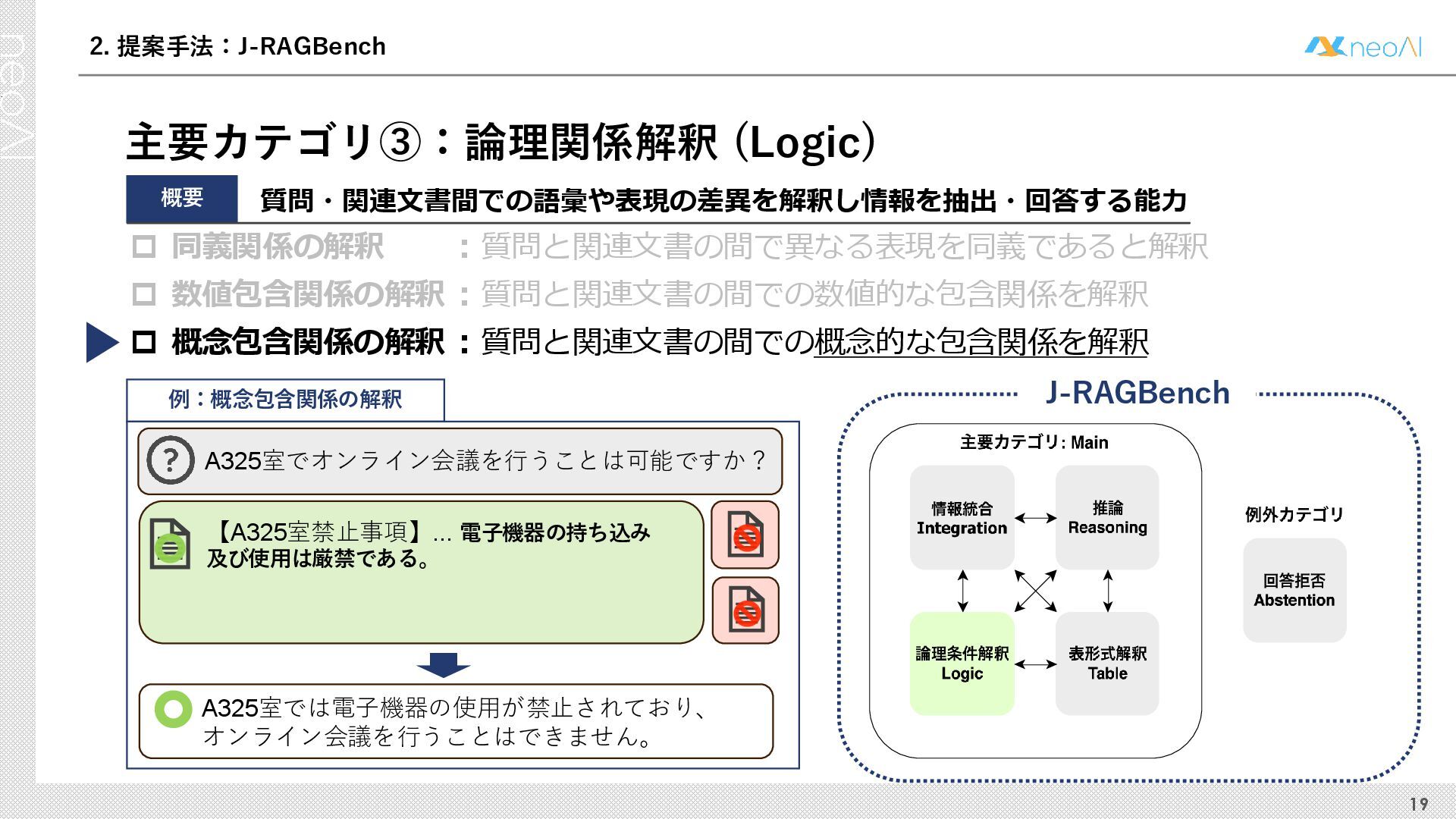
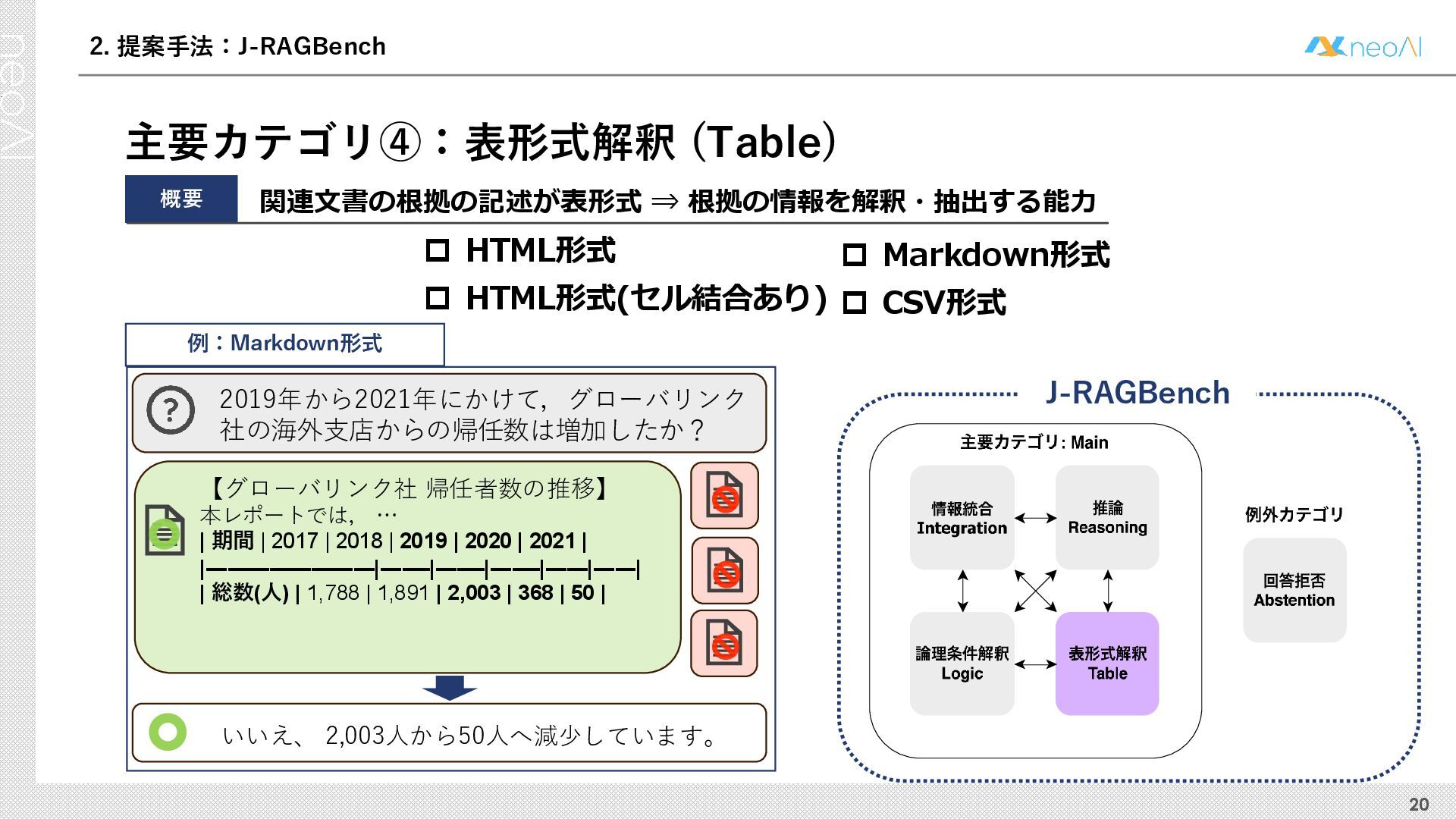
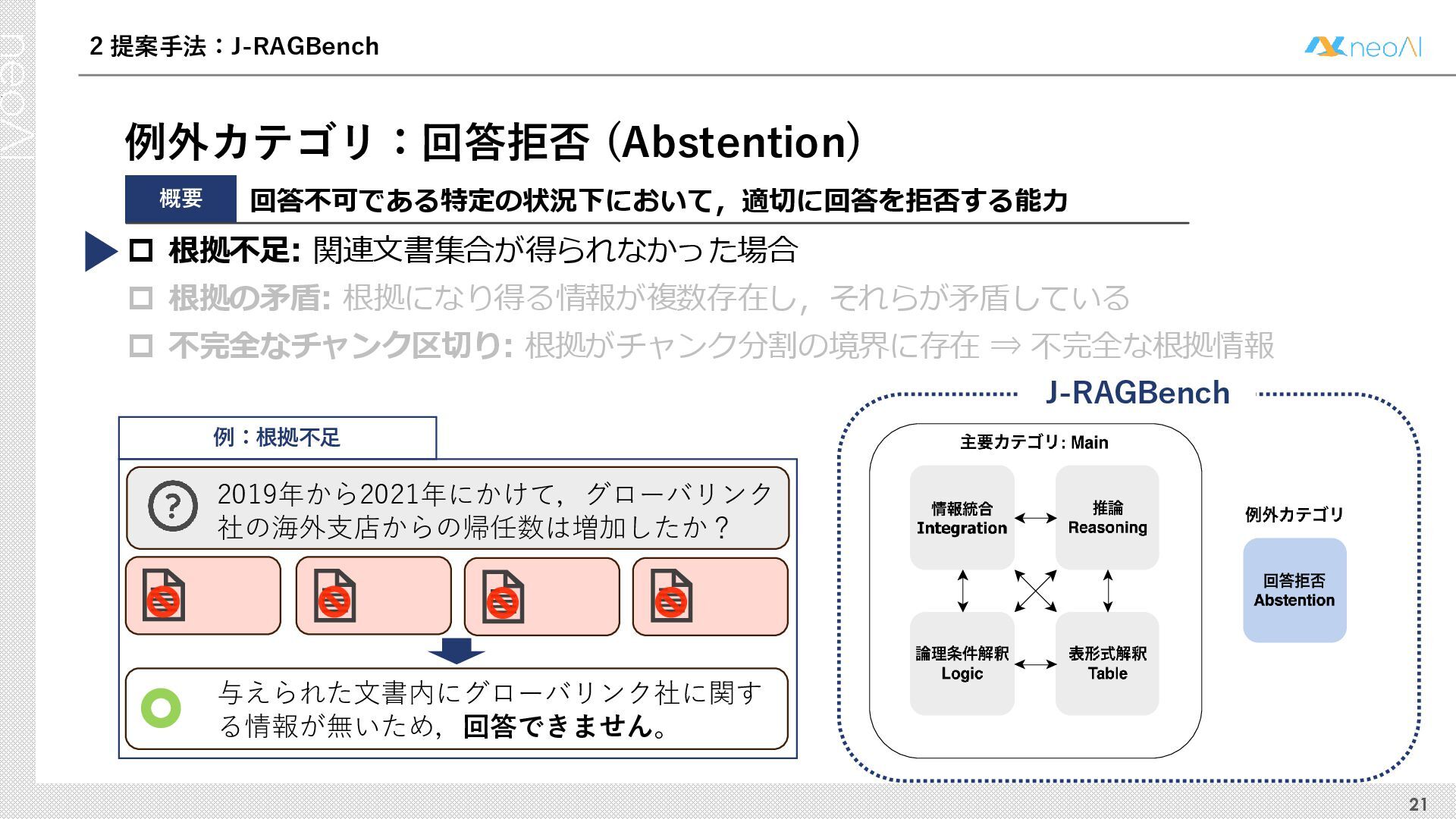
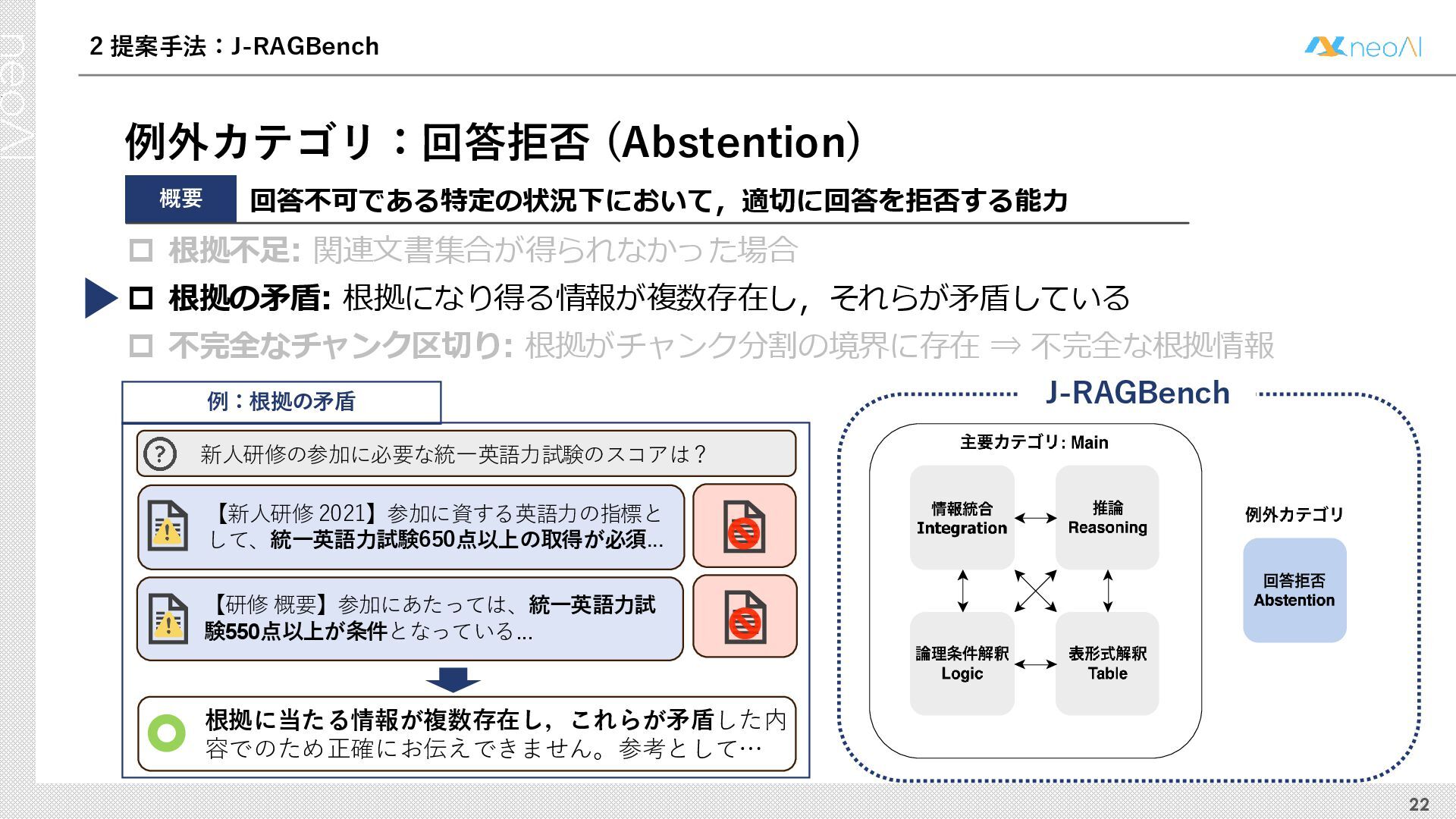
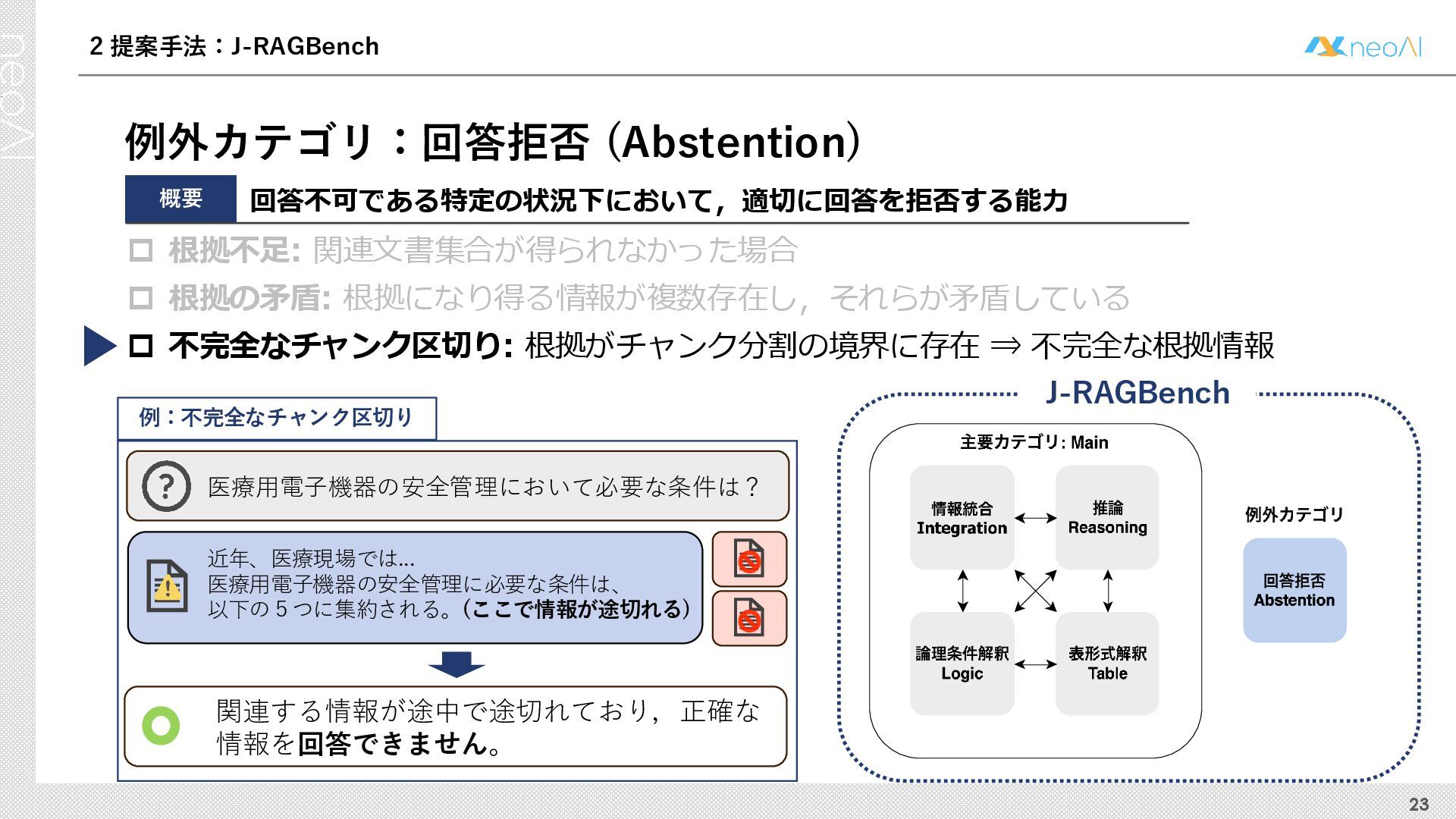
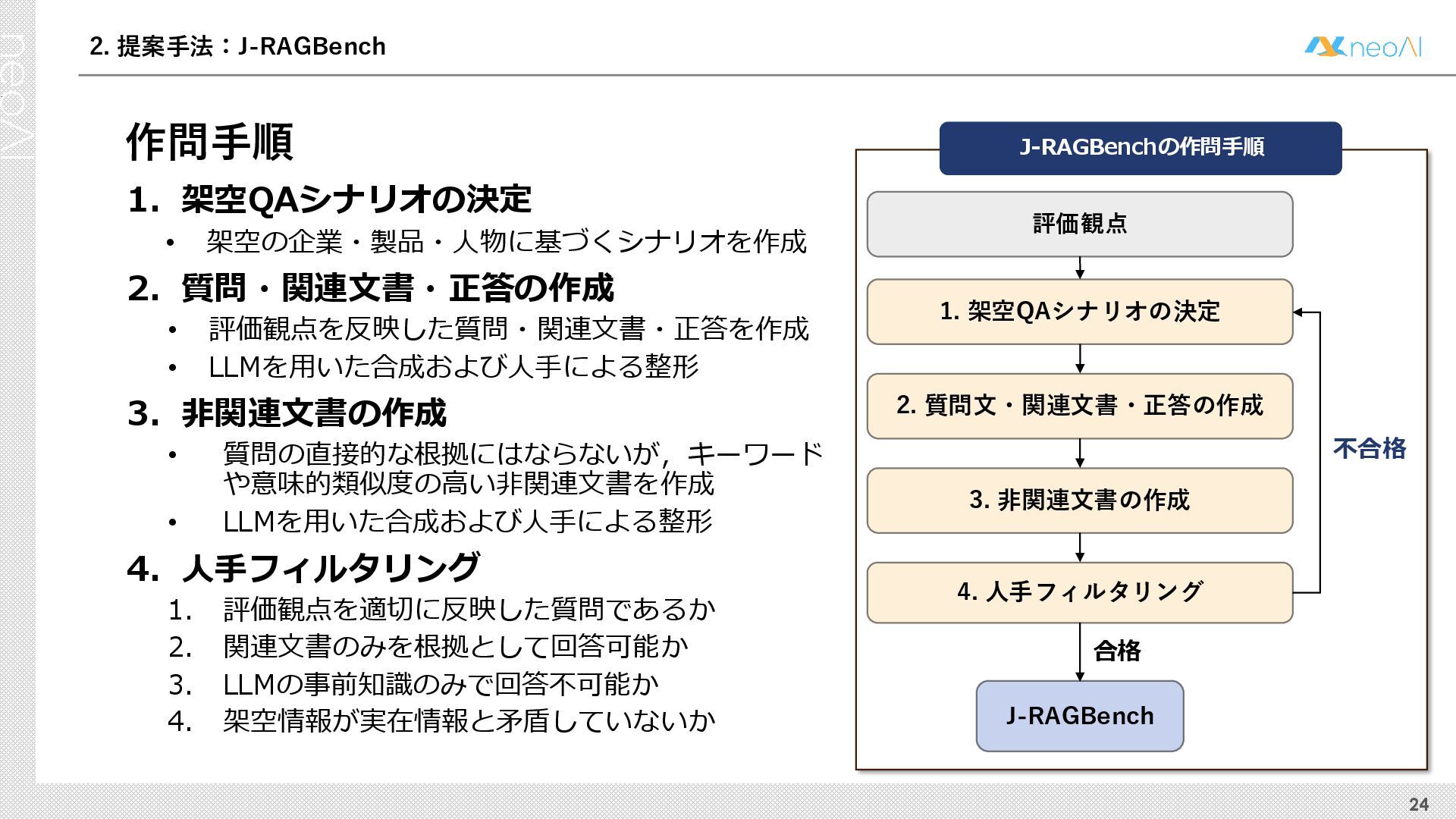
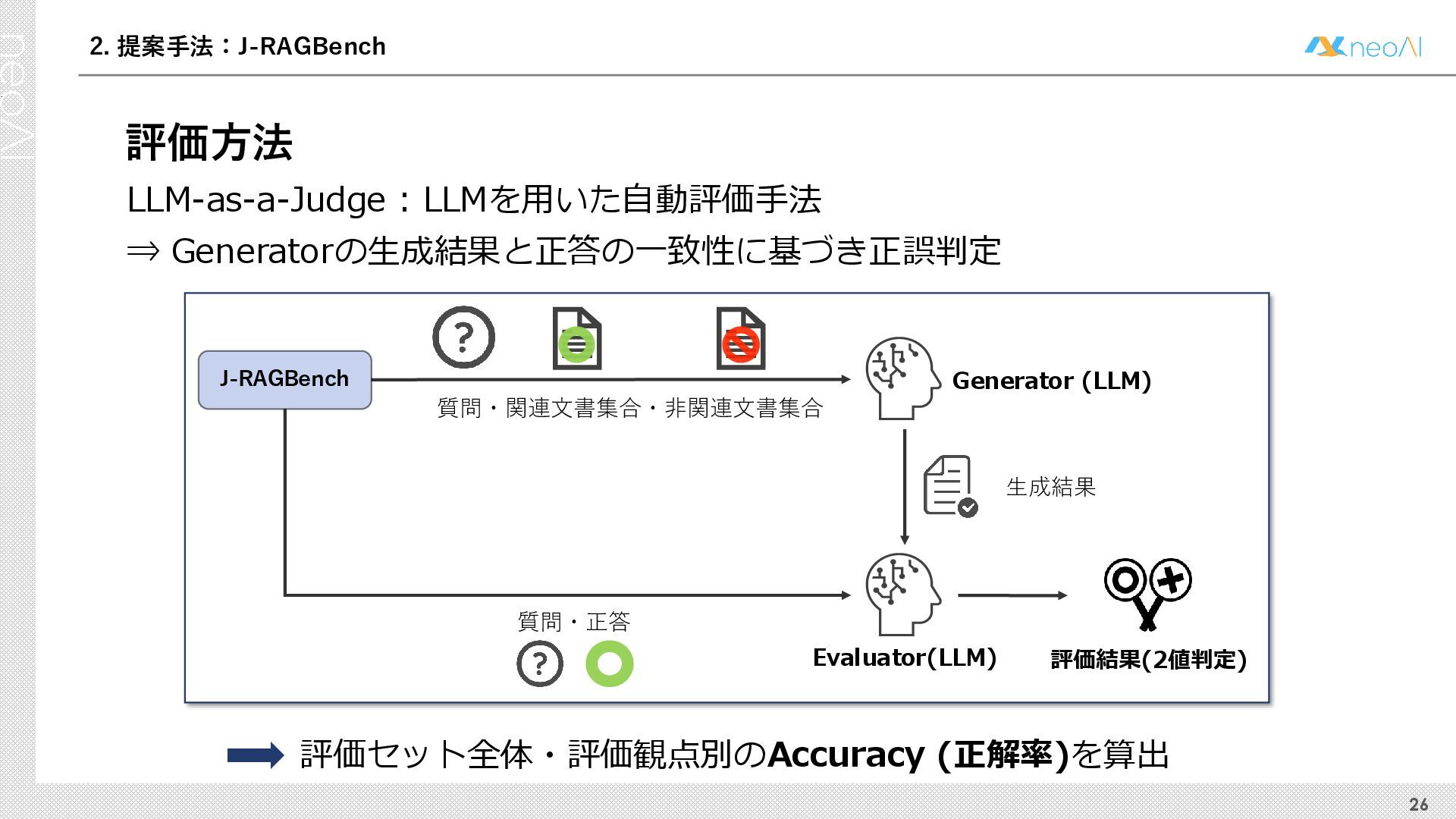
検索拡張生成(RAG)は,入力クエリに対し外部文書集合から検索器(Retriever)により取得した関連文書集合に基づき,大規模言語モデル(LLM)などの生成器(Generator)が回答を作成する手法である.Generator には,長文中からの情報抽出と統合,多段階推論,表形式情報の解釈,関連情報不在時の適切な回答拒否など,複数の能力が求められる.しかし既存のGenerator 評価ベンチマークは,これらの能力の一部に限定される場合が多く,同一条件下で多面的かつ総合的に評価できる枠組みは十分に整備されていない.本研究では,RAG のGenerator の能力評価における観点を体系化し,観点1 種または2 種の全組合せを網羅する評価ベンチマークのJ-RAGBench(Japanese RAG Generator Benchmark) を構築することで,より実用的かつ包括的な評価を可能にすることを目的とする.API 提供モデルとオープンウェイトモデルの主要なLLM を評価した結果,総合正解率が9 割を超えたモデルは存在せず,評価カテゴリごとの正解率に差が確認され,モデル間で能力の得意・不得意が定量的に明らかになった.これらの結果は,本ベンチマークがRAG 実運用でのモデル選定やRAG 特化モデル構築のための有用な指標となることを示す.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
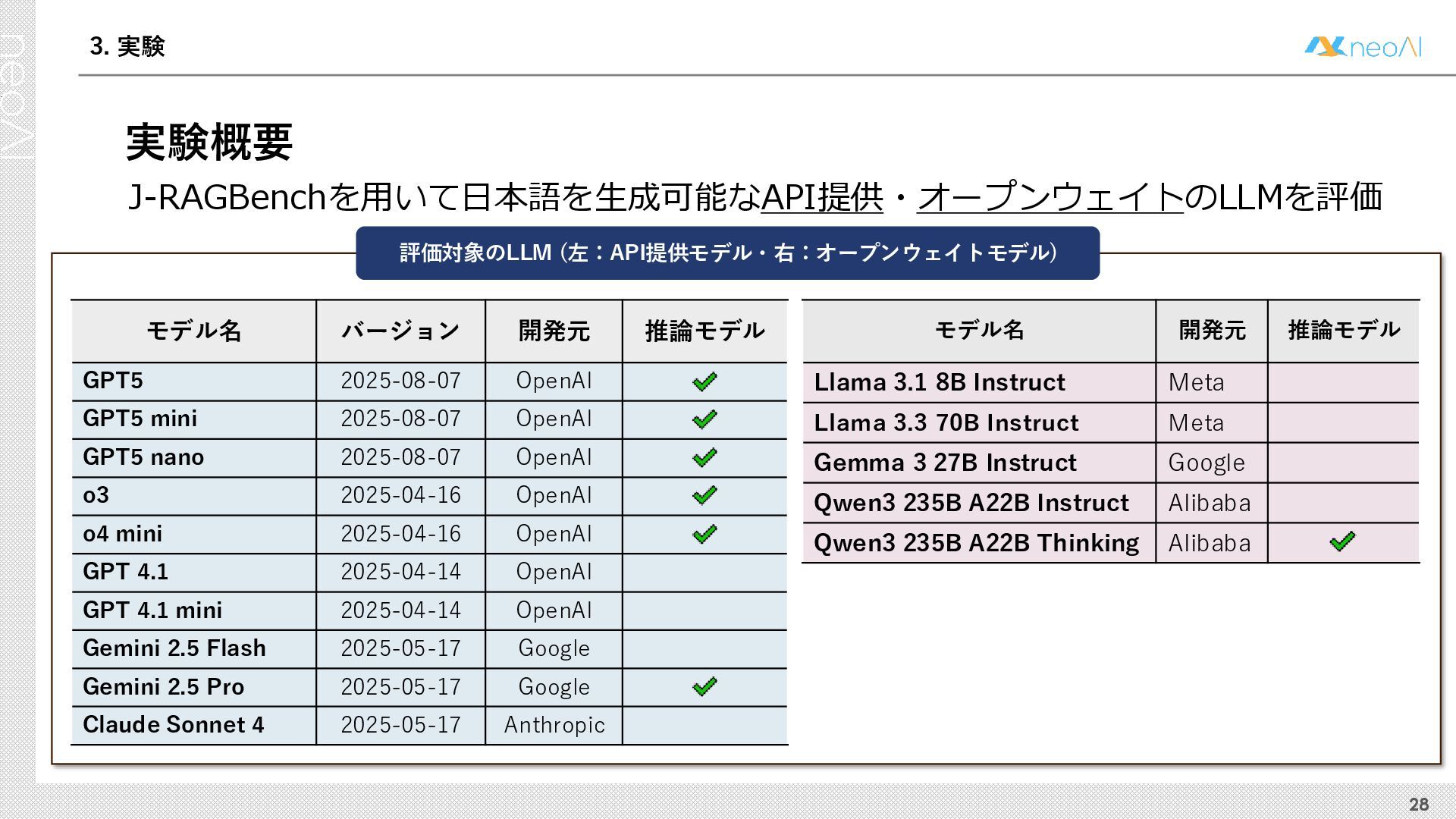{kind=link}
{kind=link}
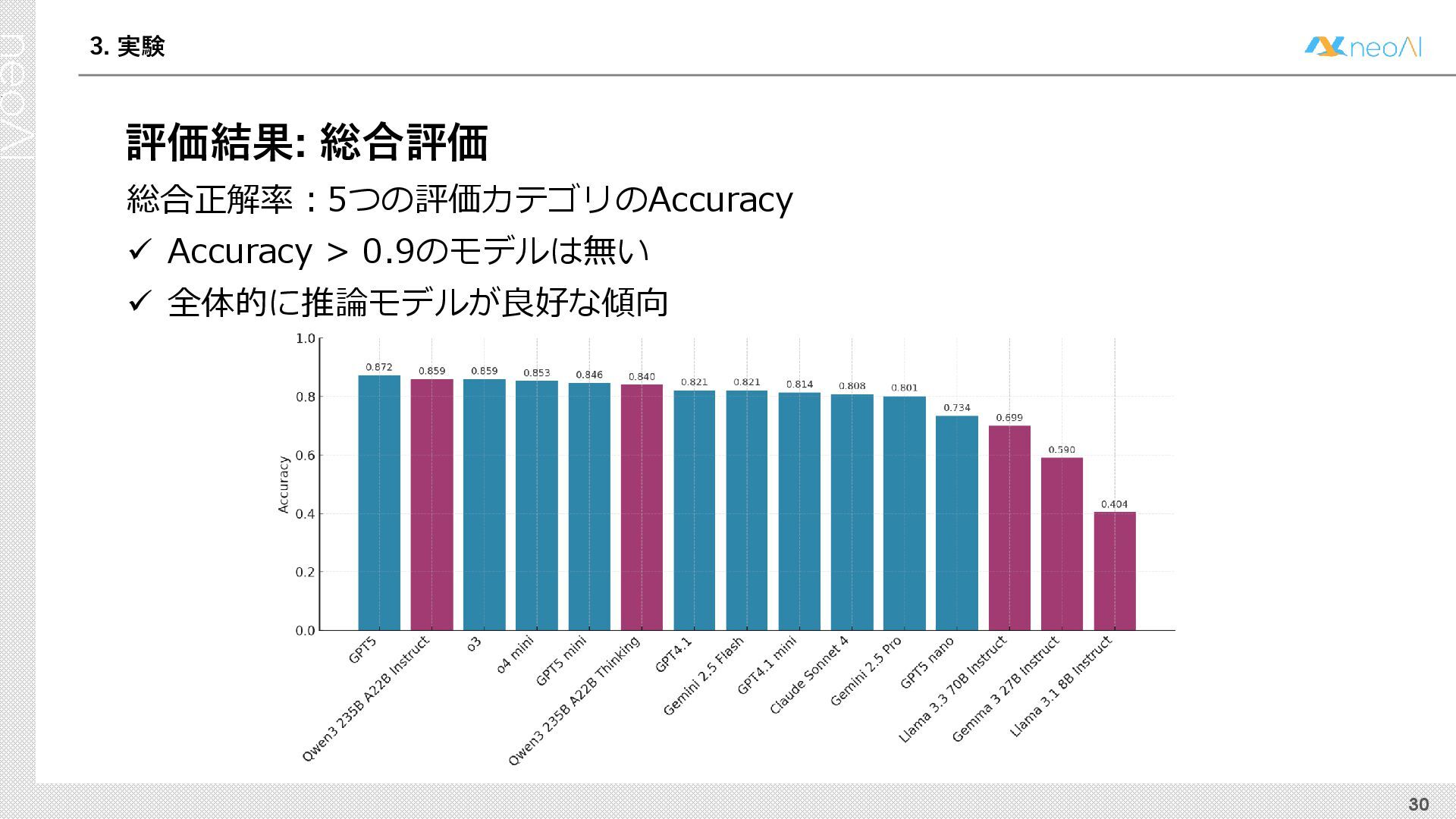{kind=link}
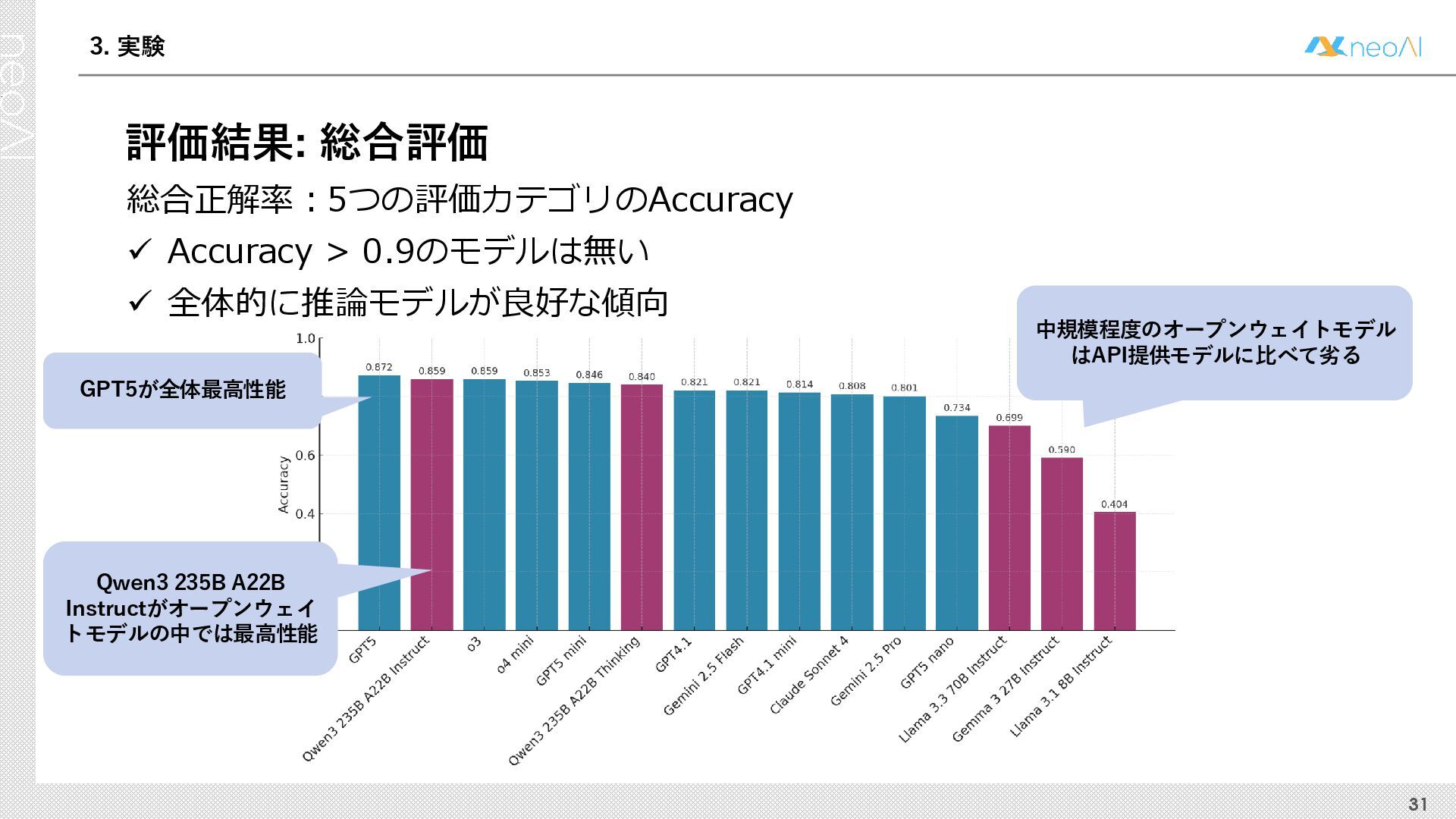{kind=link}
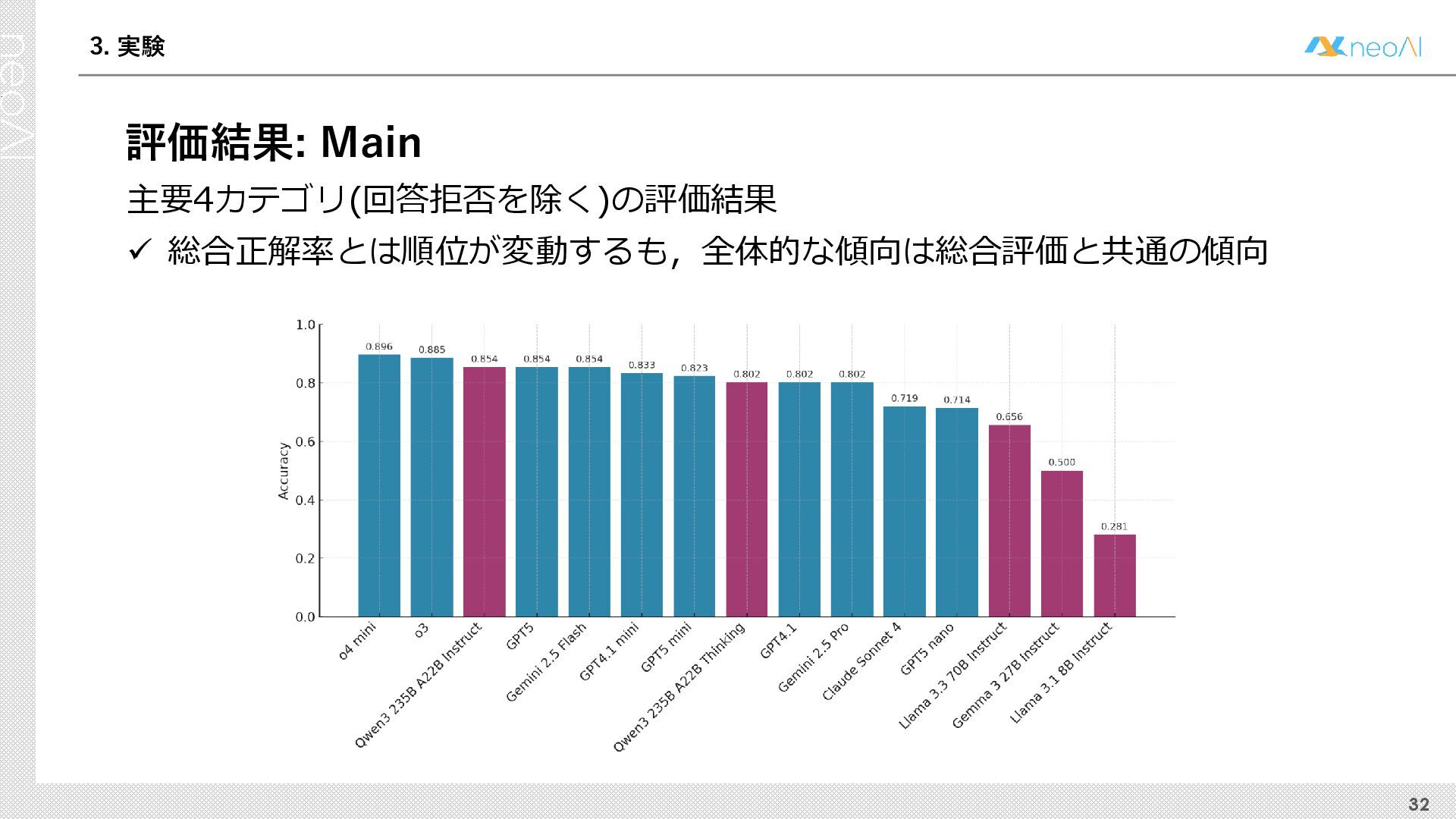{kind=link}
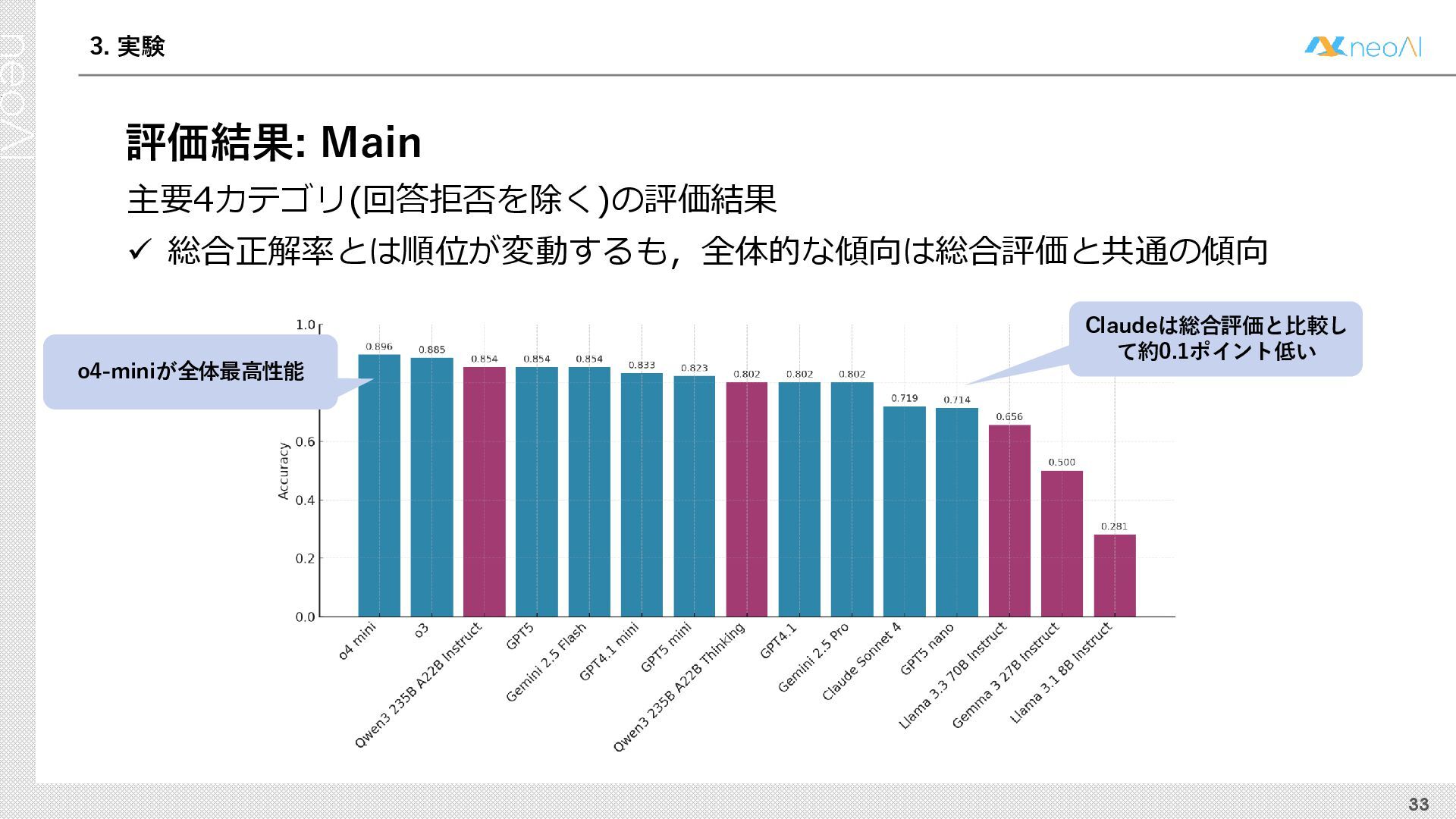{kind=link}
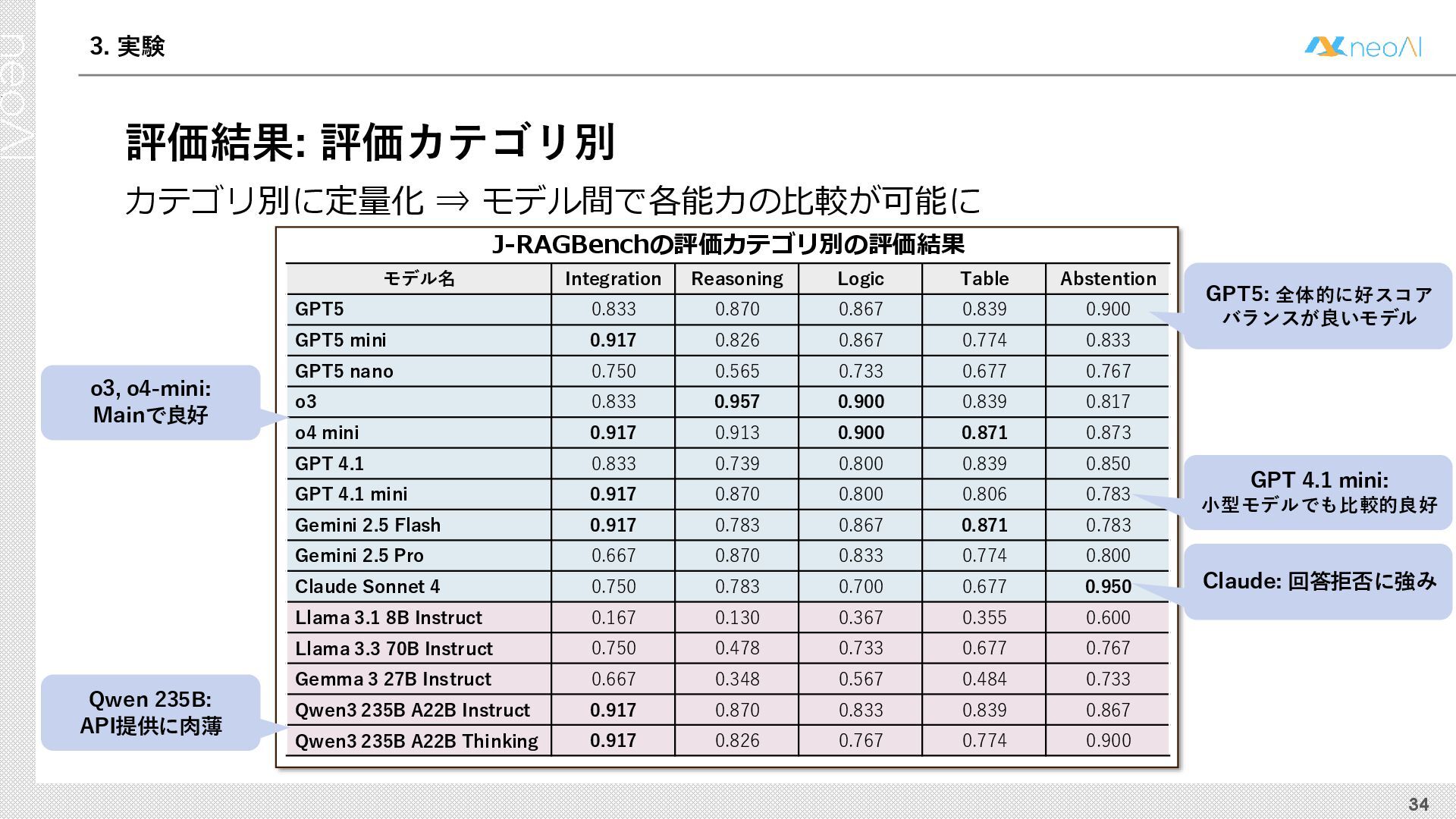{kind=link}
{kind=link}
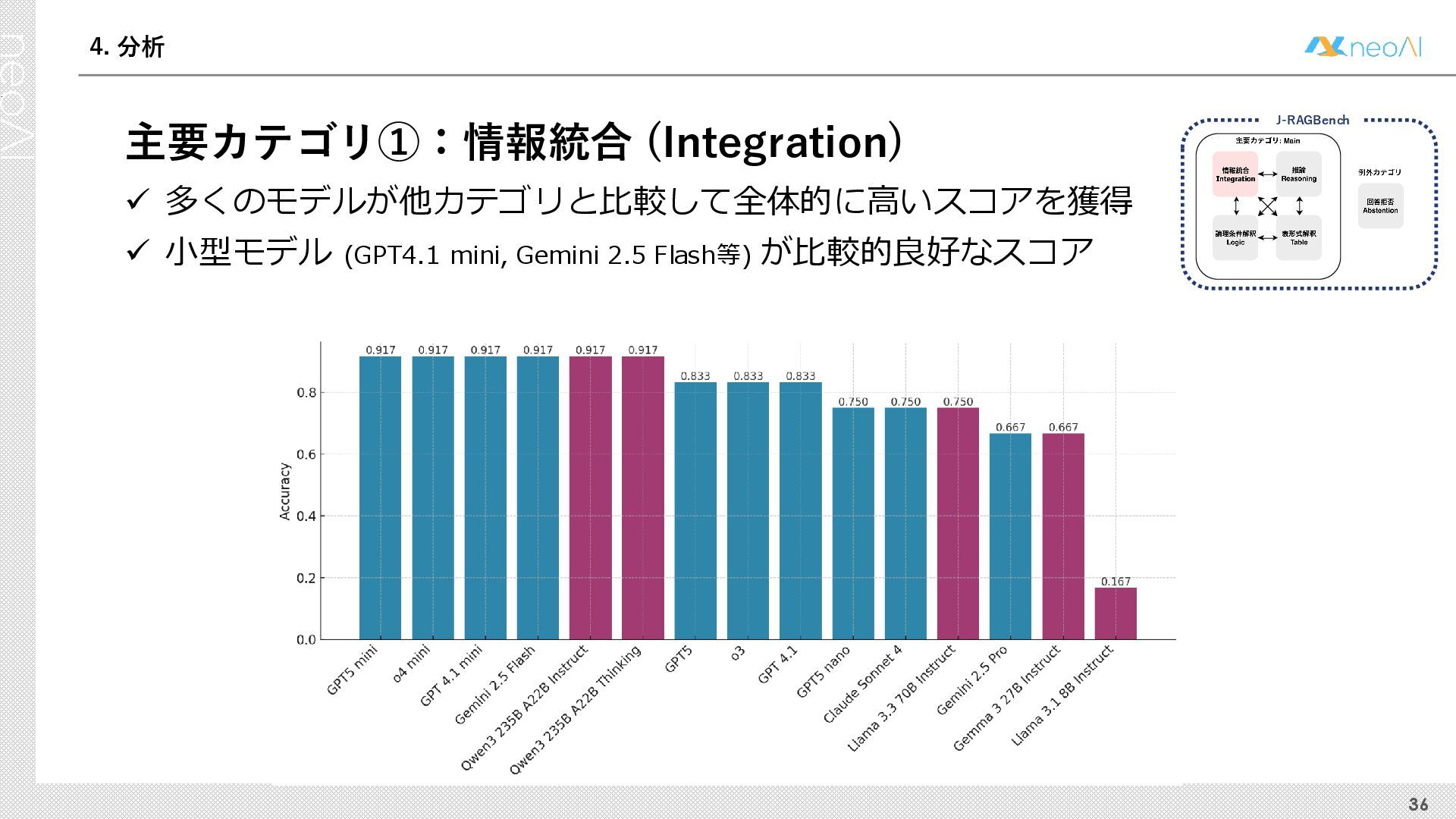{kind=link}
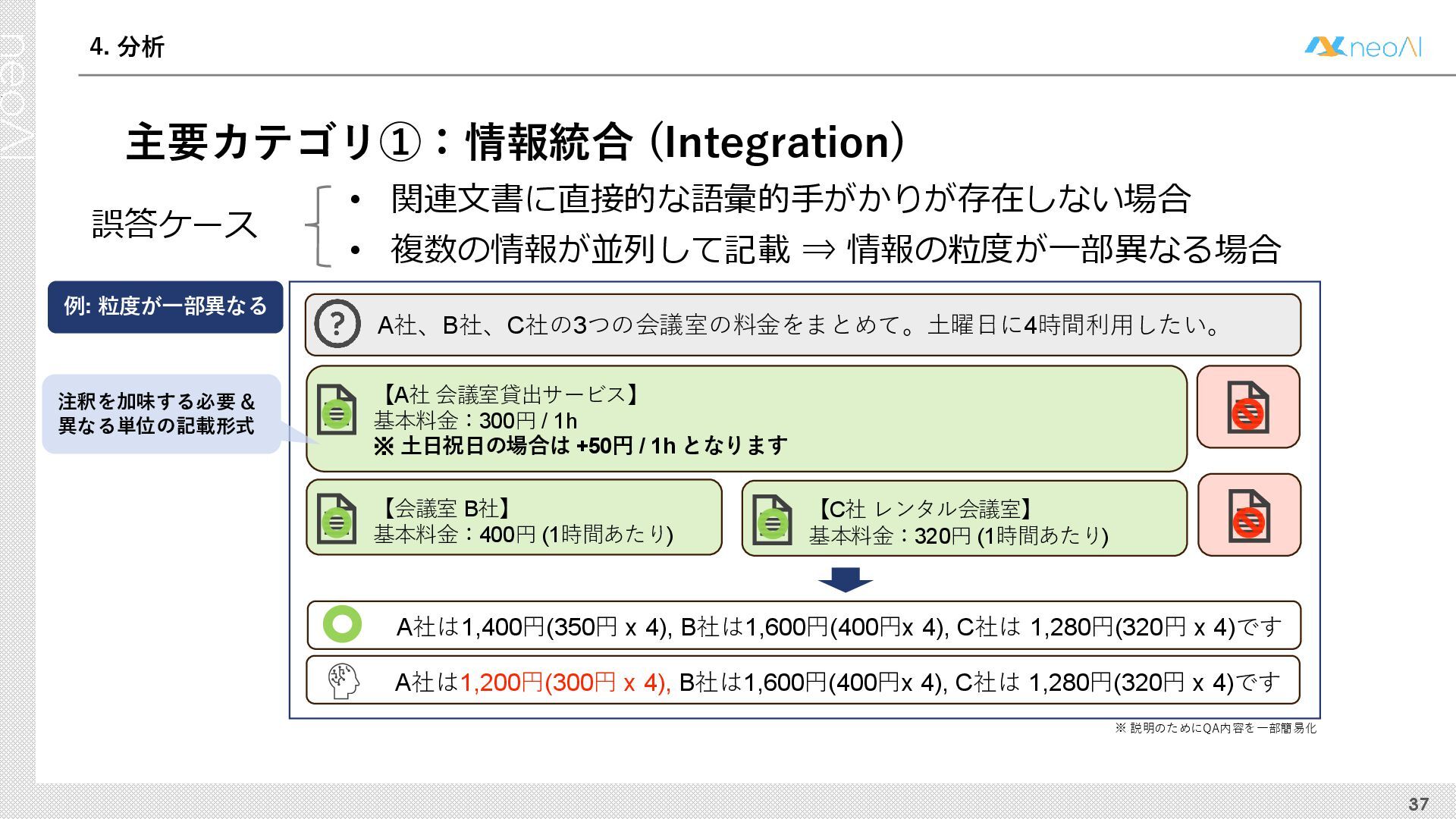{kind=link}
{kind=link}
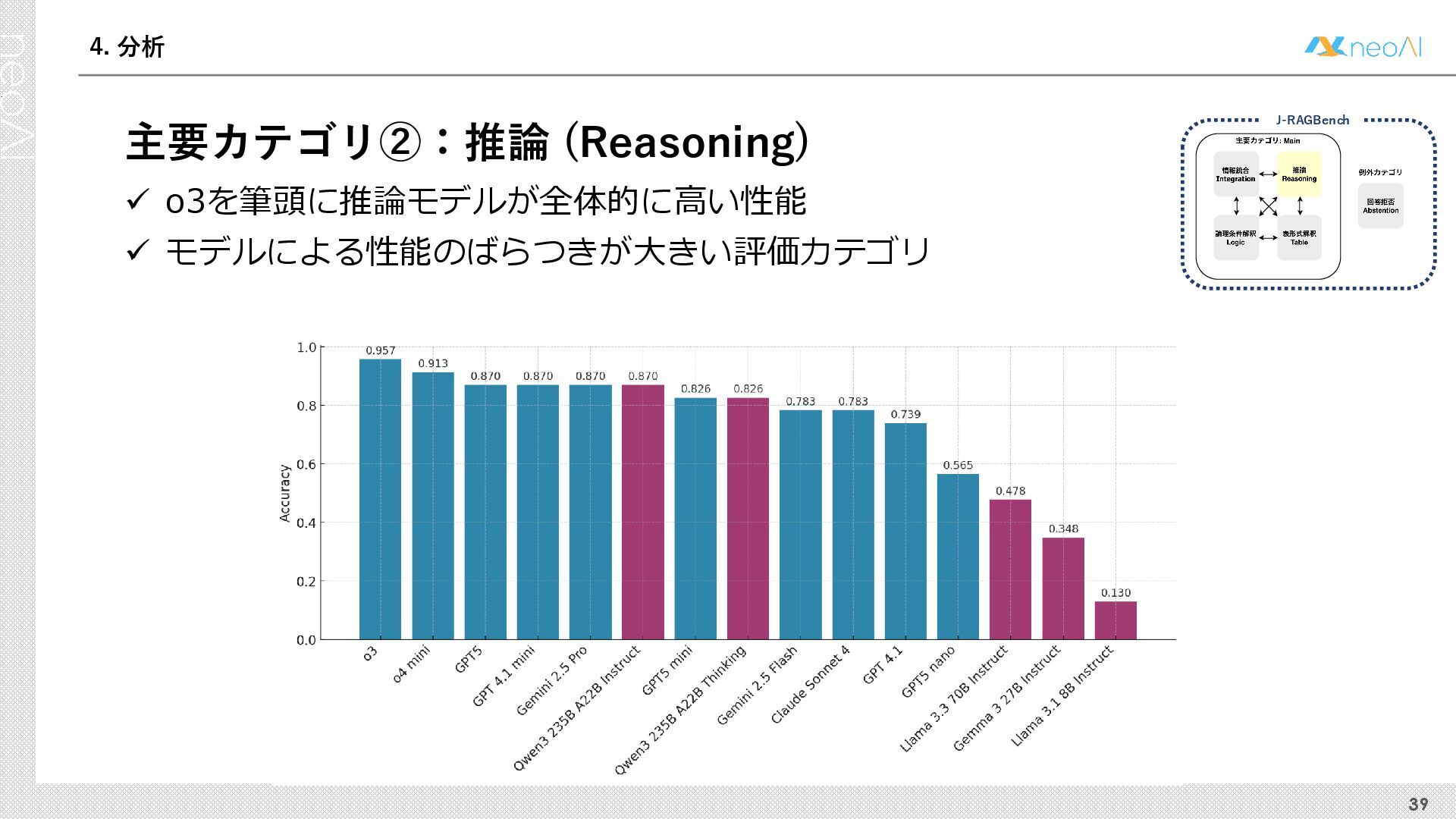{kind=link}
{kind=link}
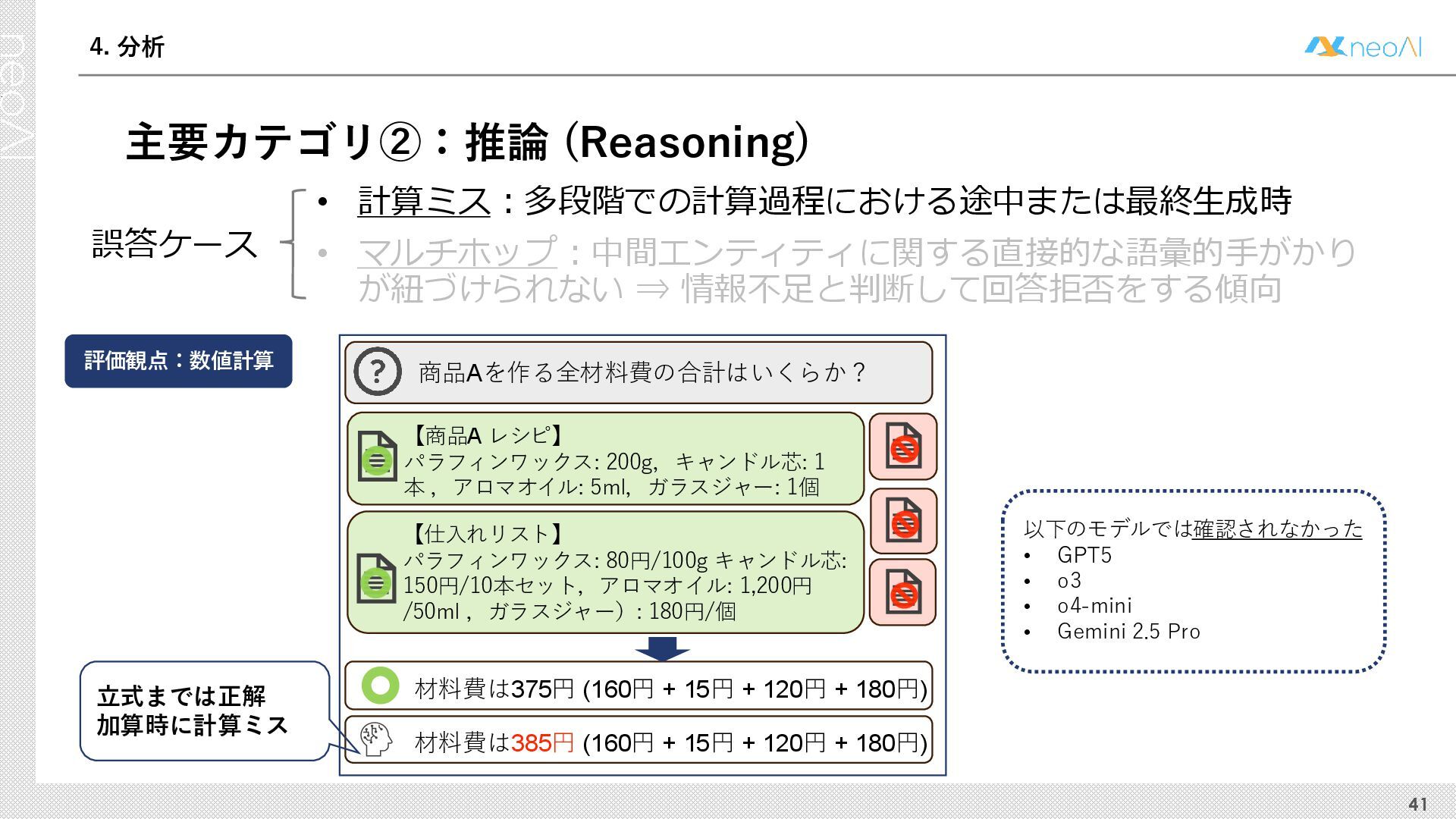{kind=link}
{kind=link}
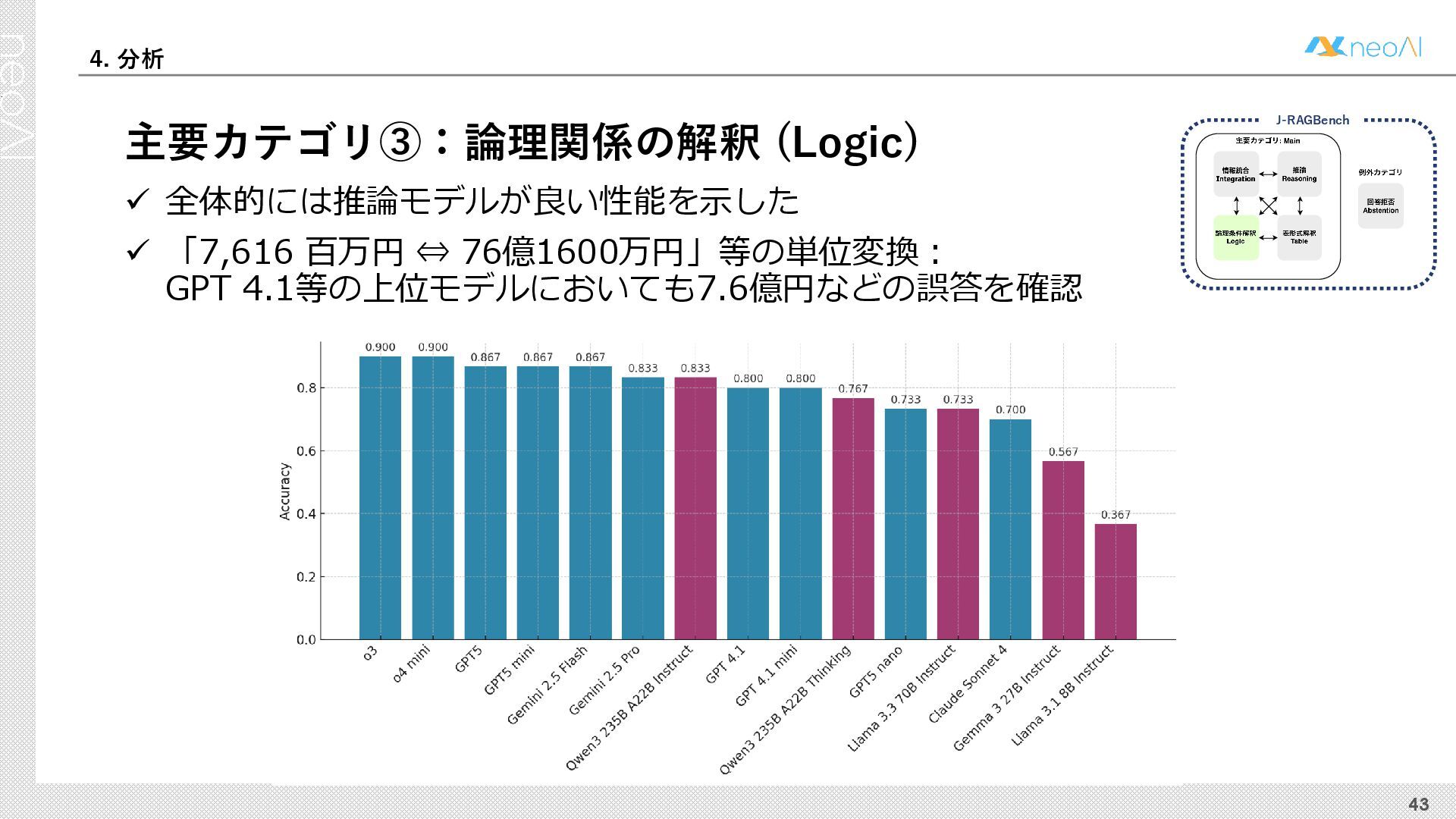{kind=link}
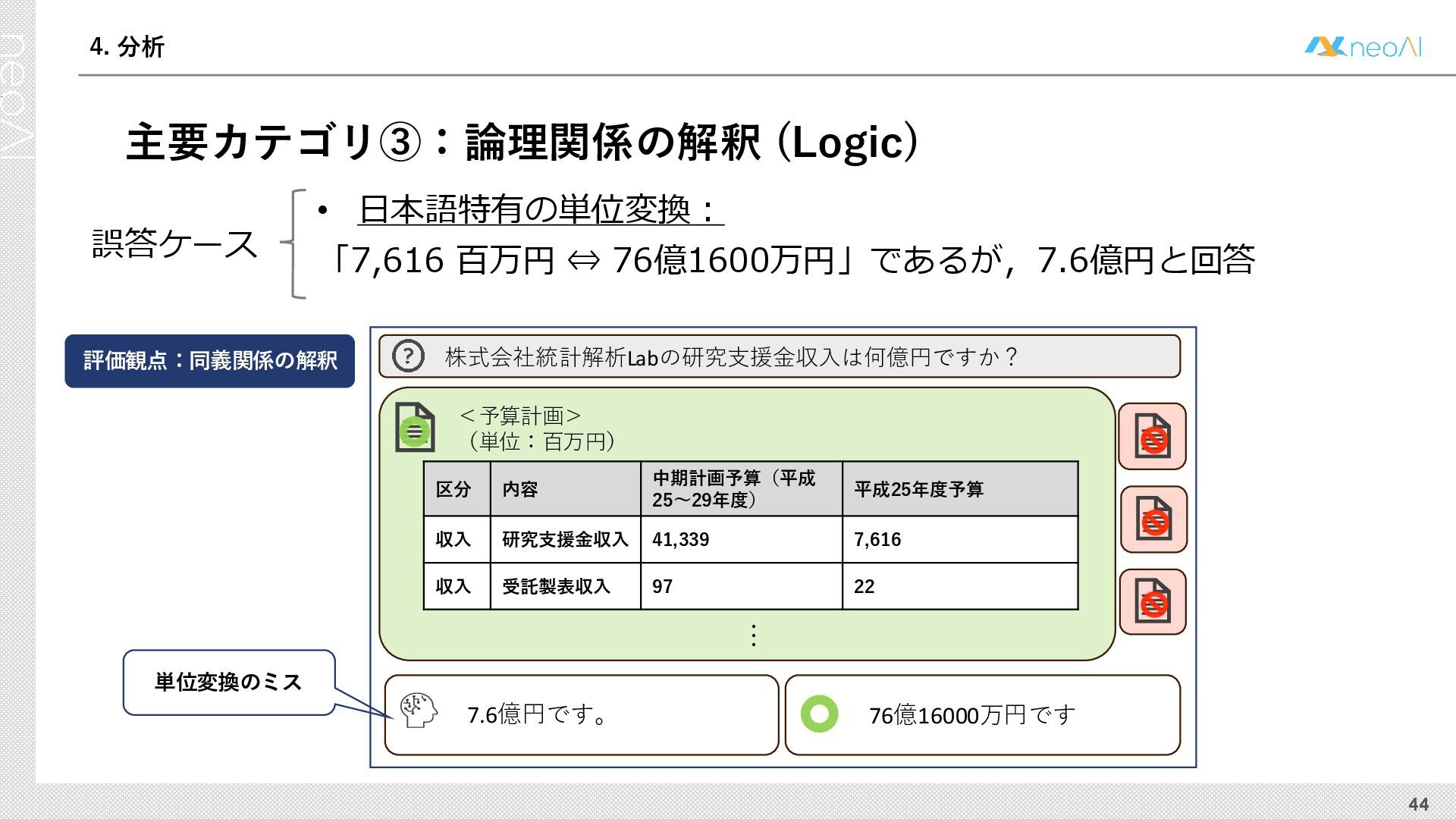{kind=link}
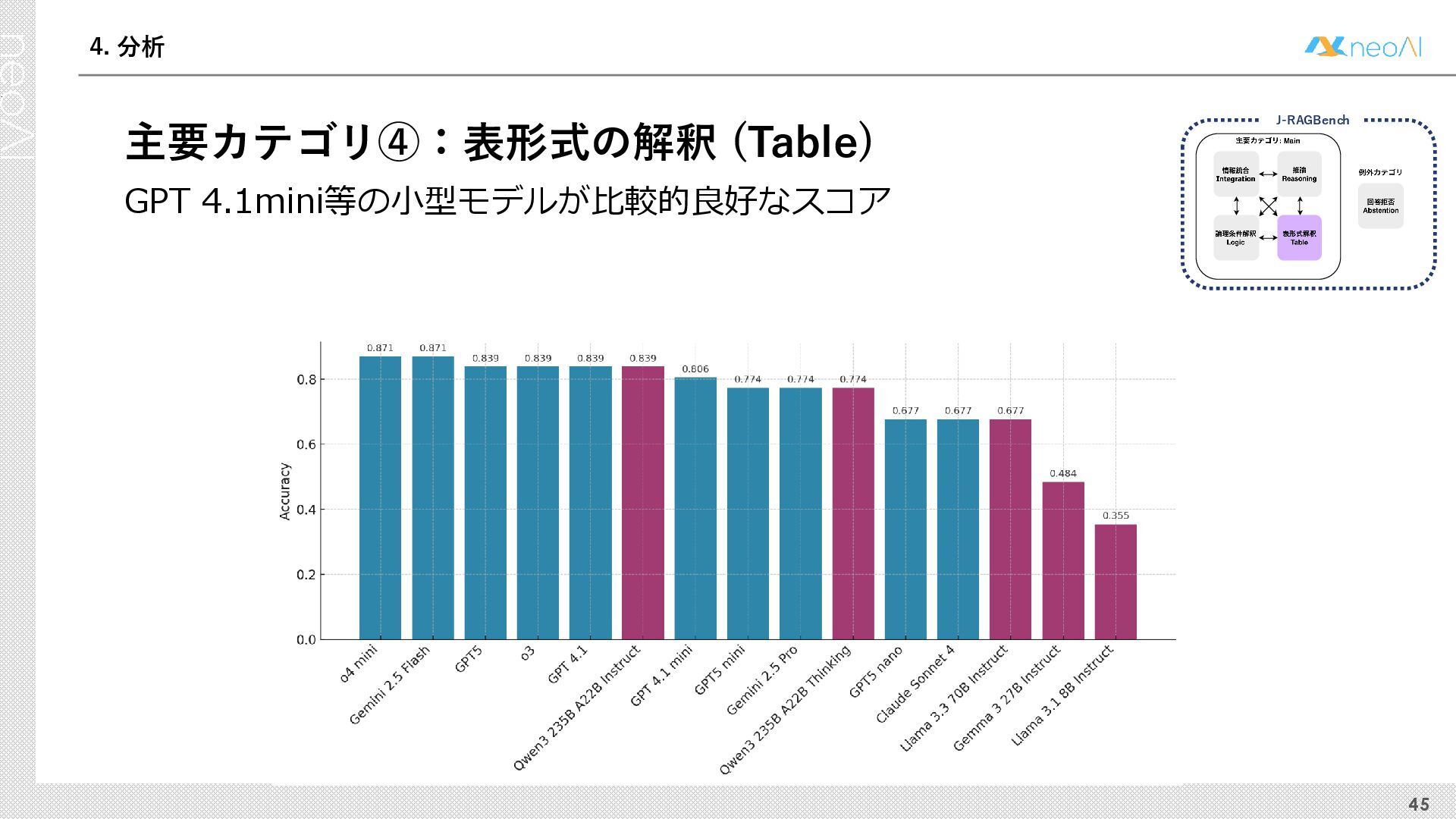{kind=link}
{kind=link}
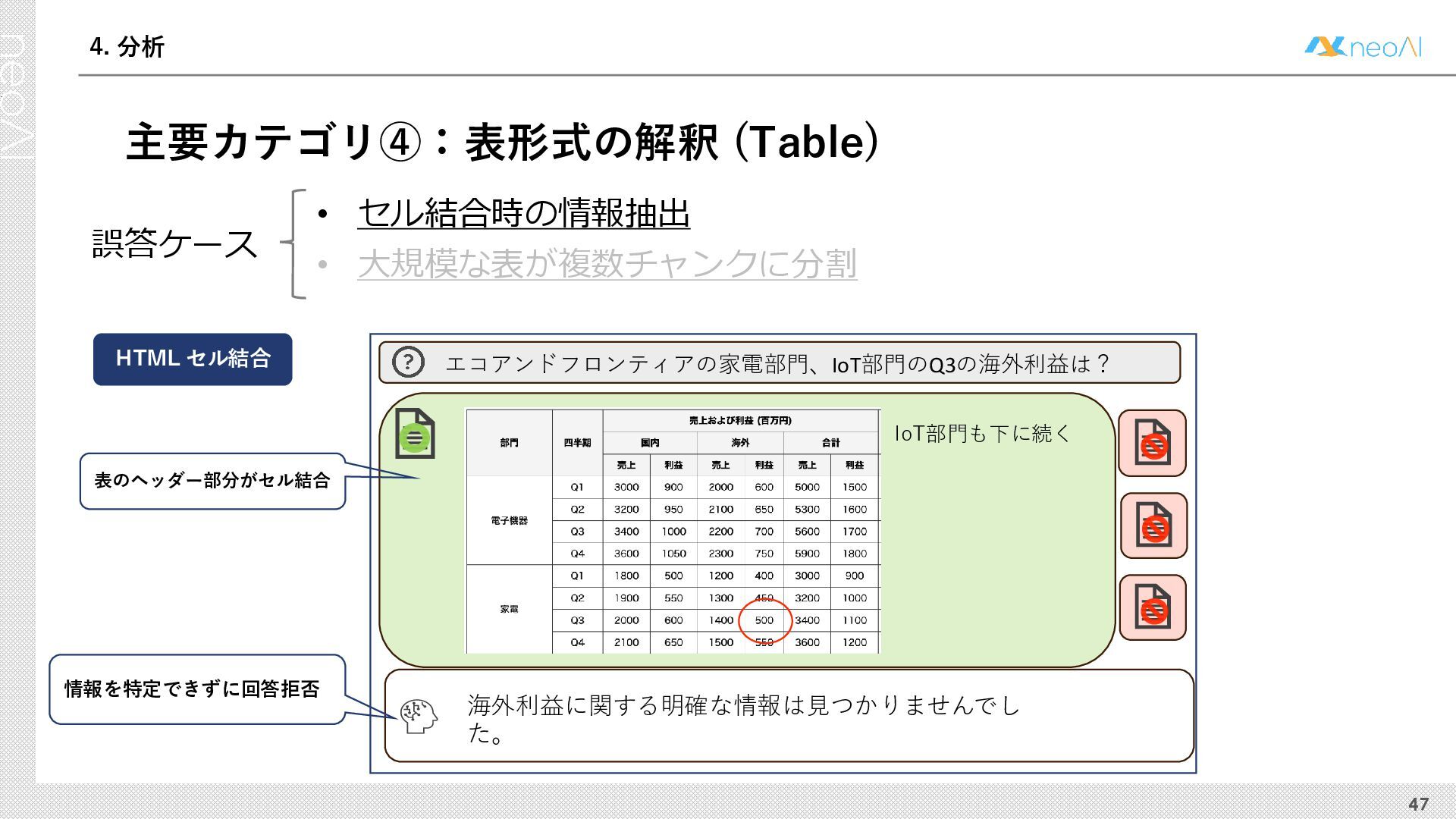{kind=link}
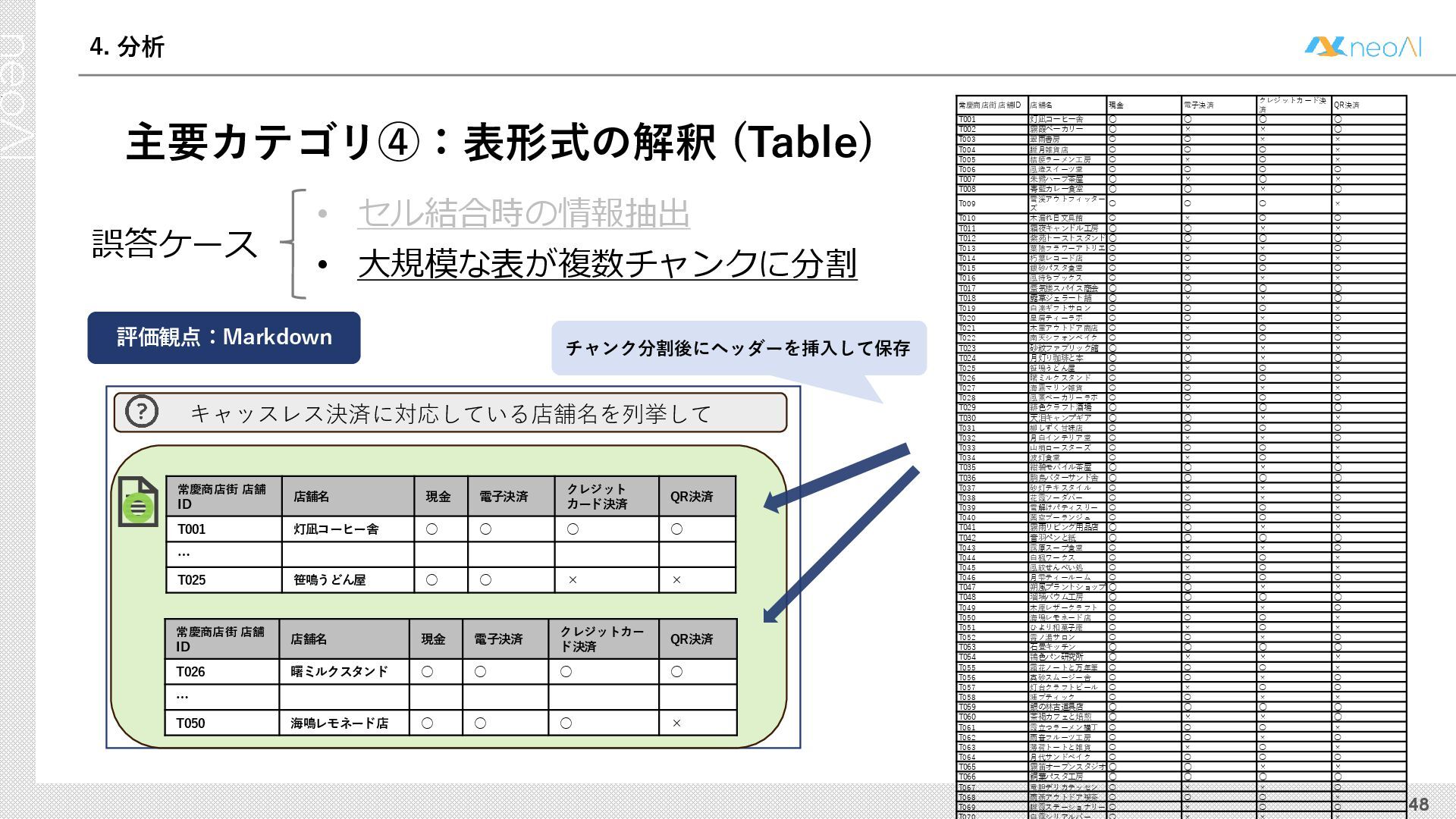{kind=link}
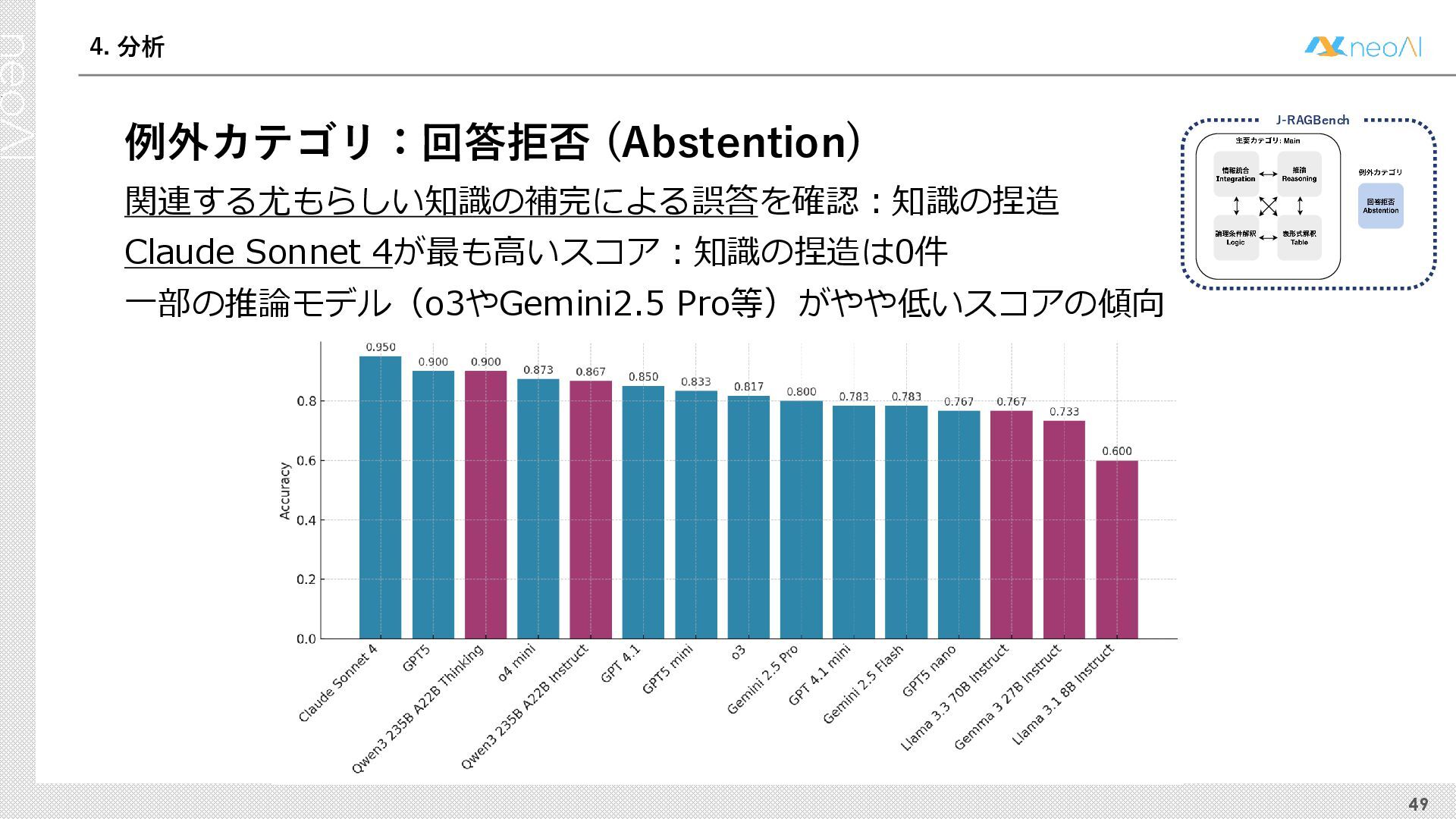{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}