Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Language Models Are Implicitly Continuous
Search
Sho Yokoi
PRO
September 01, 2025
Research
510
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Language Models Are Implicitly Continuous
第17回最先端NLP勉強会
https://sites.google.com/view/snlp-jp/home/2025
Sho Yokoi
PRO
September 01, 2025
More Decks by Sho Yokoi
See All by Sho Yokoi
言語モデルから言語について語る際に押さえておきたいこと
eumesy
PRO
6
2.5k
言語モデルの内部機序:解析と解釈
eumesy
PRO
94
32k
コーパスを丸呑みしたモデルから言語の何がわかるか
eumesy
PRO
12
4.9k
Zipf 白色化:タイプとトークンの区別がもたらす良質な埋め込み空間と損失関数
eumesy
PRO
10
2.6k
Embers of Autoregression: Understanding Large Language Models Through the Problem They are Trained to Solve
eumesy
PRO
7
2k
「確率的なオウム」にできること、またそれがなぜできるのかについて
eumesy
PRO
8
4.7k
A Theory of Emergent In-Context Learning as Implicit Structure Induction
eumesy
PRO
5
1.8k
ChatGPT と自然言語処理 / 言語の意味の計算と最適輸送
eumesy
PRO
24
19k
Revisiting Over-smoothing in BERT from the Perspective of Graph
eumesy
PRO
0
2k
Other Decks in Research
See All in Research
JICA QUEST 共創×革新プログラム Impact Report(海ノ向こうコーヒー)
ontheslope
0
190
シングルチャネルマルチトーカー音声認識の進展
ryomasumura
0
190
計算情報学研究室 (数理情報学第7研究室)2026
tomohirokoana
0
640
機械学習で作った ポケモン対戦bot で 遊ぼう!
fufufukakaka
0
360
PGDM: Physically Guided Diffusion Model for L Downscaling
satai
3
350
非試合日の野球場を楽しむためのARホームランボールキャッチ体験システムの開発 / EC79-miyazaki
yumulab
0
300
さくらインターネット研究所テックトーク2026春、研究開発Gr.25年度成果26年度方針
kikuzo
0
160
AIで最適化を解けるか?
mickey_kubo
0
140
はじまりの クエスチョンブック —余暇と豊かさにあふれた社会とは?
culturaltransition
PRO
0
570
「なんとなく」の顧客理解から脱却する ──顧客の解像度を武器にするインサイトマネジメント
tajima_kaho
11
8.7k
Using our influence and power for patient safety
helenbevan
0
370
LINEヤフー データサイエンス Meetup「三井物産コモディティ予測チャレンジ」の舞台裏-AlpacaTechパート
gamella
1
610
Featured
See All Featured
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
Color Theory Basics | Prateek | Gurzu
gurzu
0
390
Java REST API Framework Comparison - PWX 2021
mraible
34
9.5k
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.4k
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
Navigating Weather and Climate Data
rabernat
0
350
Building an army of robots
kneath
306
46k
WENDY [Excerpt]
tessaabrams
11
38k
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4.1k
Six Lessons from altMBA
skipperchong
29
4.3k
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
Transcript
Language Models Are Implicitly Continuous Samuele Marro, Davide Evangelista, X.
Angelo Huang, Emanuele La Malfa, Michele Lombardi, Michael Wooldridge (Oxford, U. Bologna, ETH) ICLR 2025 https://arxiv.org/abs/2504.03933 読む⼈︓横井 祥(国語研・統数研・理研・JST創発) 2025-09-01, 第17回最先端NLP勉強会 ※ とくに注釈がない限り,図や数式は, 論⽂に掲載されているものを紹介者が適宜加筆・修正したものです ※ 引⽤が⽢いスライドで済みません
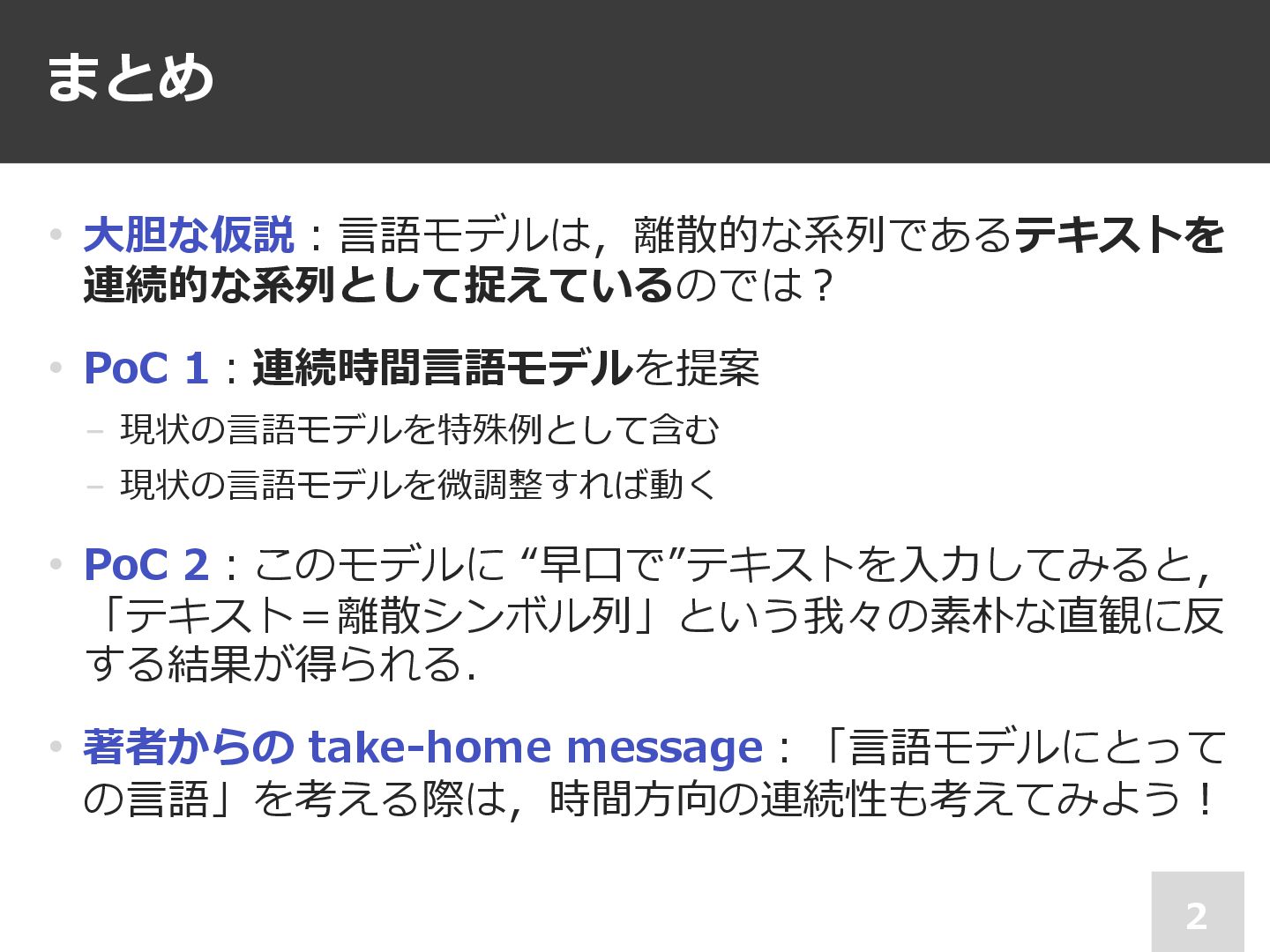
まとめ 2 • ⼤胆な仮説︓⾔語モデルは,離散的な系列であるテキストを 連続的な系列として捉えているのでは︖ • PoC 1︓連続時間⾔語モデルを提案 − 現状の⾔語モデルを特殊例として含む
− 現状の⾔語モデルを微調整すれば動く • PoC 2︓このモデルに “早⼝で”テキストを⼊⼒してみると, 「テキスト=離散シンボル列」という我々の素朴な直観に反 する結果が得られる. • 著者からの take-home message︓「⾔語モデルにとって の⾔語」を考える際は,時間⽅向の連続性も考えてみよう︕
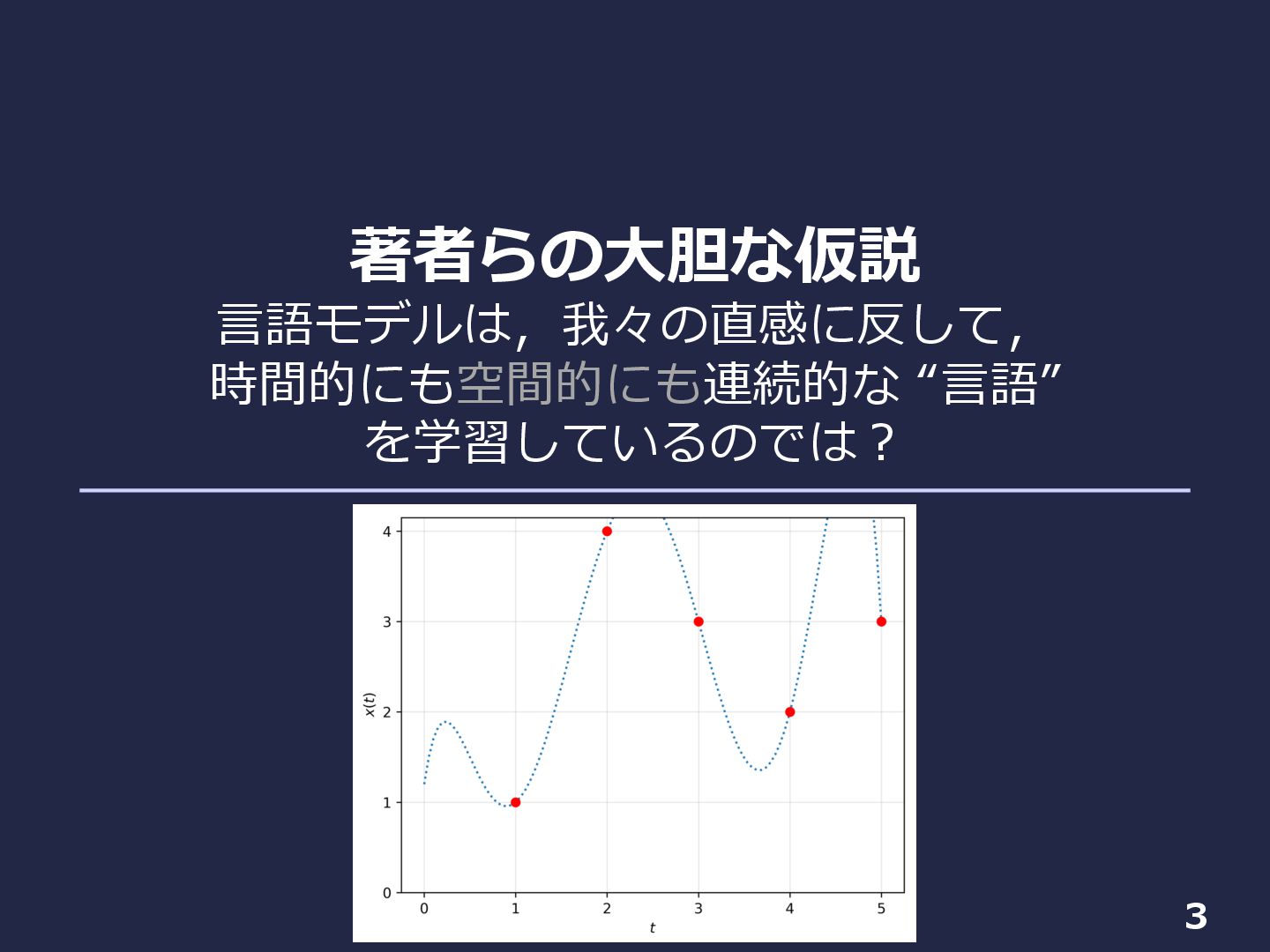
著者らの⼤胆な仮説 ⾔語モデルは,我々の直感に反して, 時間的にも空間的にも連続的な “⾔語” を学習しているのでは︖ 3
テキストデータ 4 • テキストデータ︓離散シンボルの離散列 ‘エピグラフ’ ‘と’ ‘エビピラフ’ ‘の’ ‘共通点’ ……
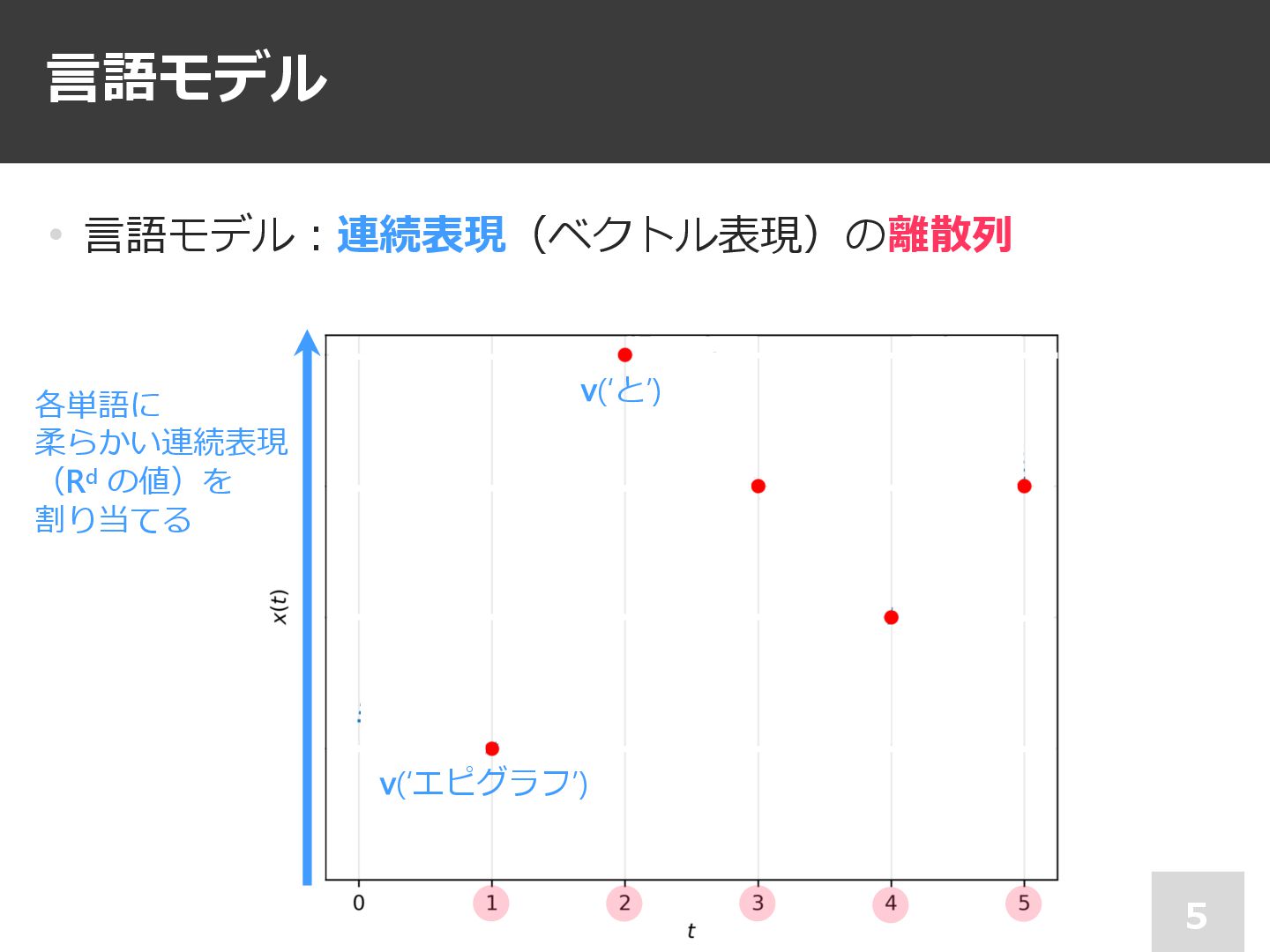
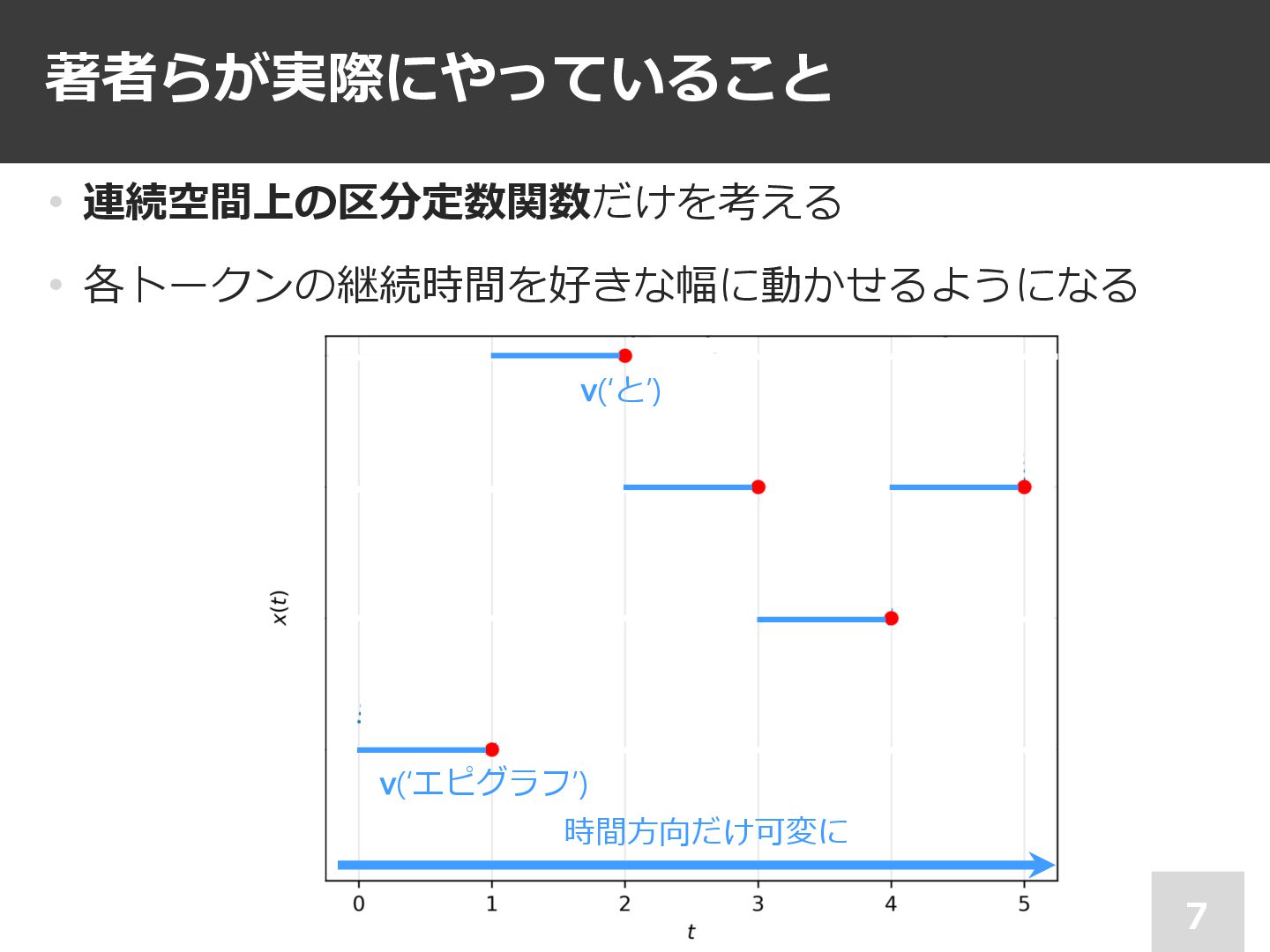
⾔語モデル 5 • ⾔語モデル︓連続表現(ベクトル表現)の離散列 各単語に 柔らかい連続表現 (Rd の値)を 割り当てる v(‘エピグラフ’)
v(‘と’)
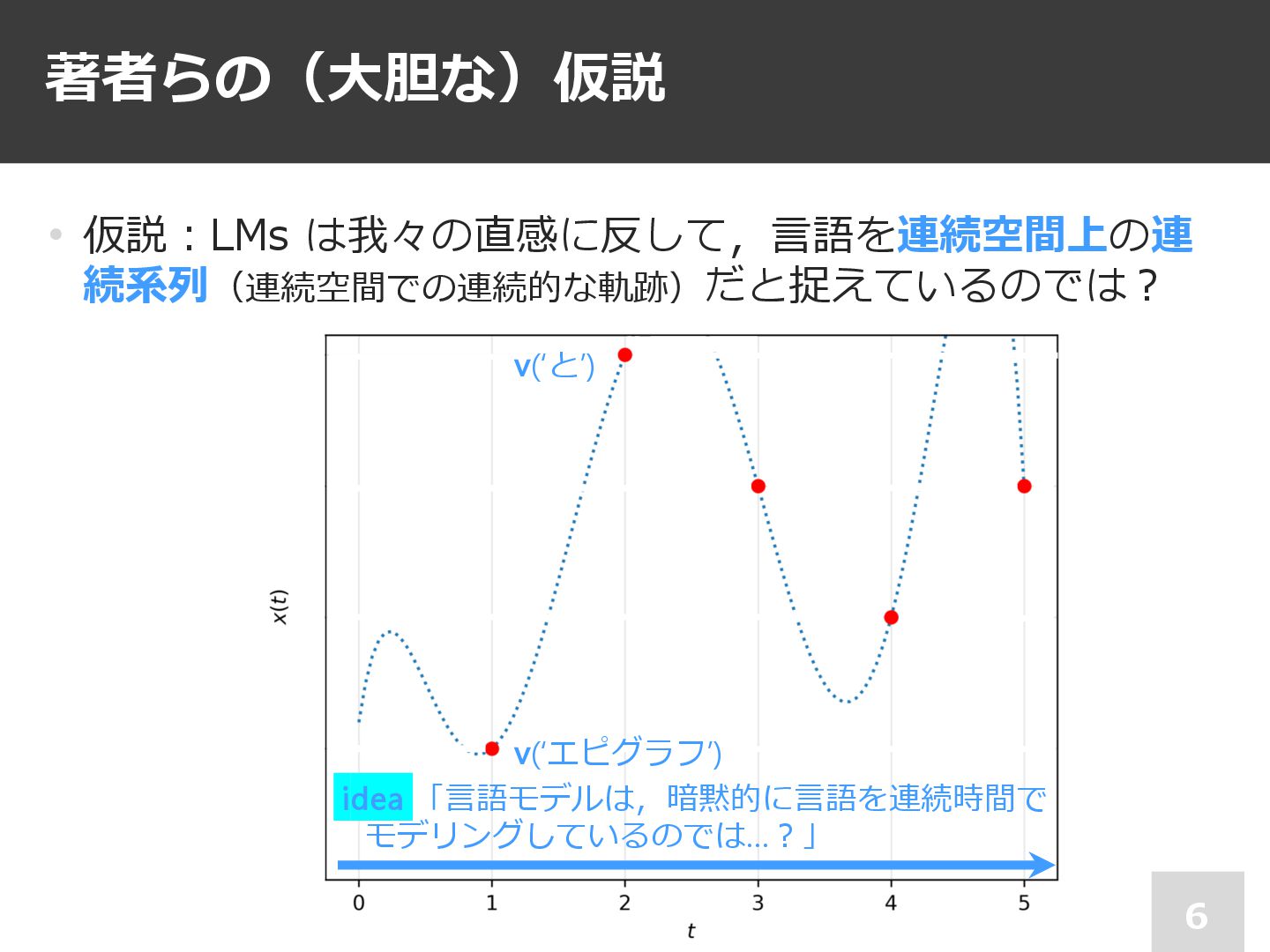
著者らの(⼤胆な)仮説 6 • 仮説︓LMs は我々の直感に反して,⾔語を連続空間上の連 続系列(連続空間での連続的な軌跡)だと捉えているのでは︖ idea 「⾔語モデルは,暗黙的に⾔語を連続時間で モデリングしているのでは…︖」 v(‘エピグラフ’)
v(‘と’)
著者らが実際にやっていること 7 • 連続空間上の区分定数関数だけを考える • 各トークンの継続時間を好きな幅に動かせるようになる v(‘エピグラフ’) v(‘と’) 時間⽅向だけ可変に
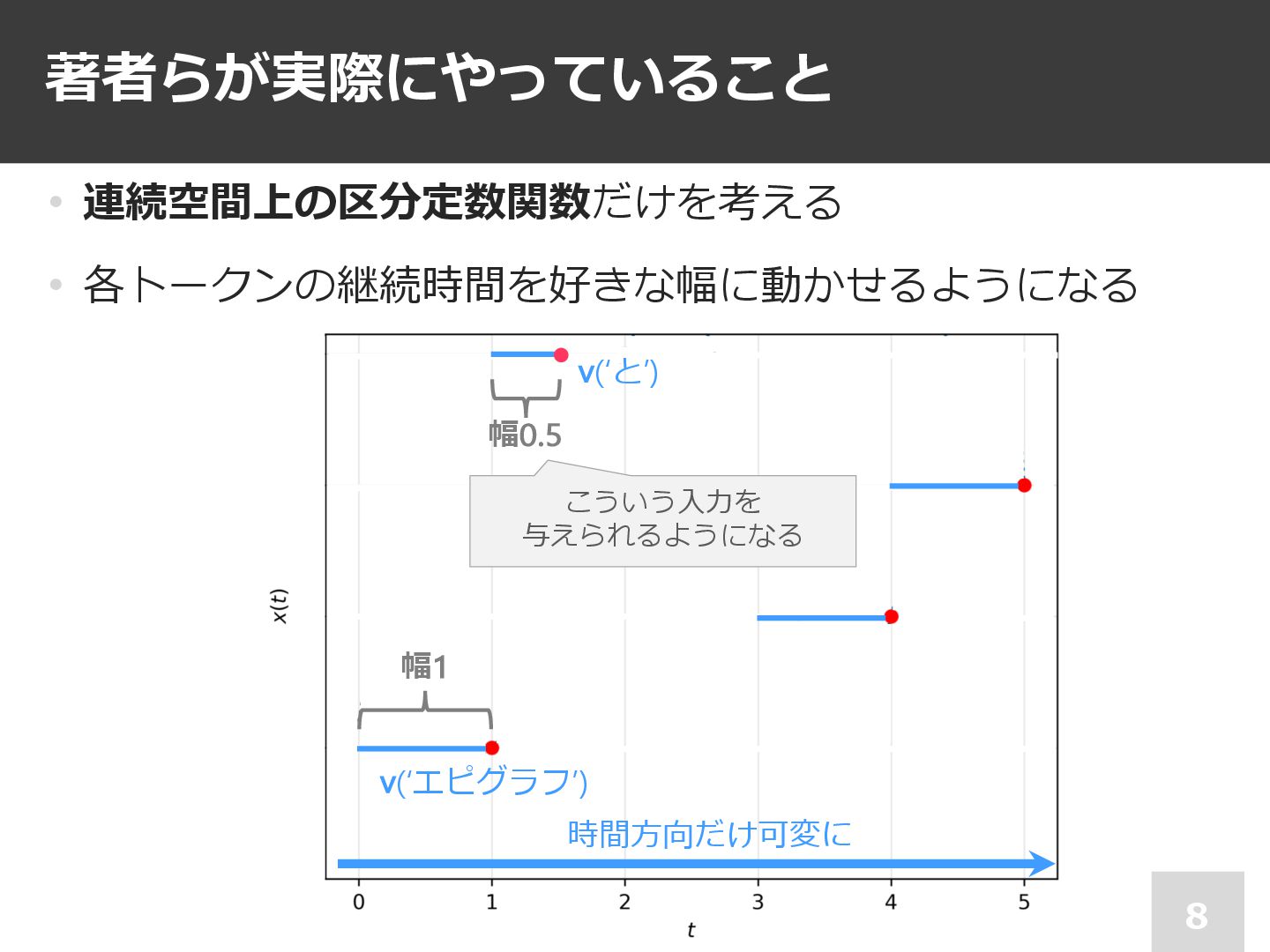
著者らが実際にやっていること 8 • 連続空間上の区分定数関数だけを考える • 各トークンの継続時間を好きな幅に動かせるようになる v(‘エピグラフ’) 幅1 幅0.5 v(‘と’)
こういう⼊⼒を 与えられるようになる 時間⽅向だけ可変に
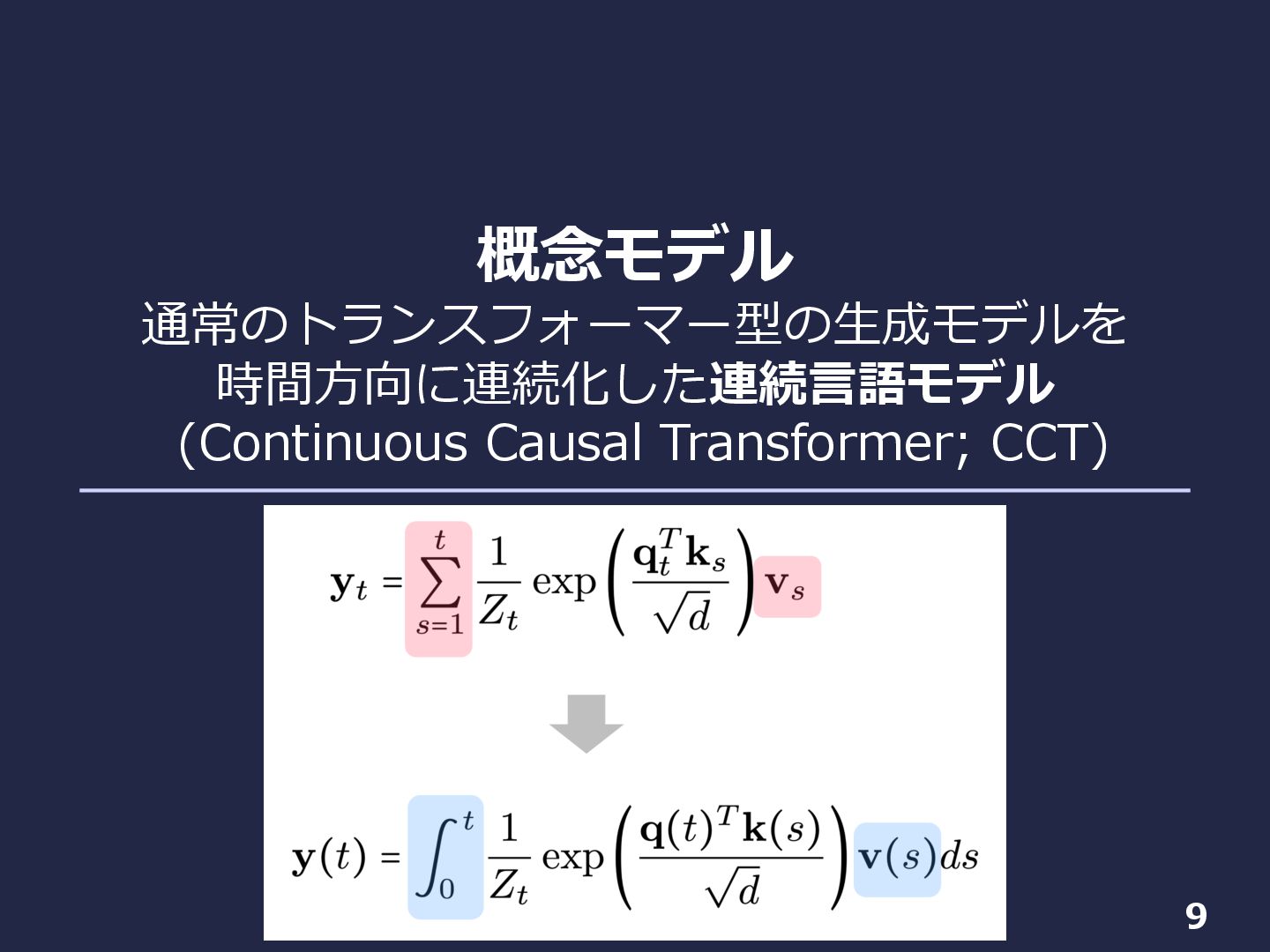
概念モデル 通常のトランスフォーマー型の⽣成モデルを 時間⽅向に連続化した連続⾔語モデル (Continuous Causal Transformer; CCT) 9
注意機構の時間⽅向の連続化 10 • 離散時間トランスフォーマー(普通のやつ)における注意機構 − 注意機構︓トークン間の(=時刻が異なるイベント同⼠の)相互作⽤ が明⽰的に⽣じる唯⼀のモジュール − Value vectors
を⾜し合わせることで次の層の表現を作る
注意機構の時間⽅向の連続化 11 • 離散時間トランスフォーマー(普通のやつ)における注意機構 − 注意機構︓トークン間の(=時刻が異なるイベント同⼠の)相互作⽤ が明⽰的に⽣じる唯⼀のモジュール − Value vectors
を⾜し合わせることで次の層の表現を作る • → 注意機構の連続化 − 連続時間で変化しうる value vector で積分して次の層の表現を作る
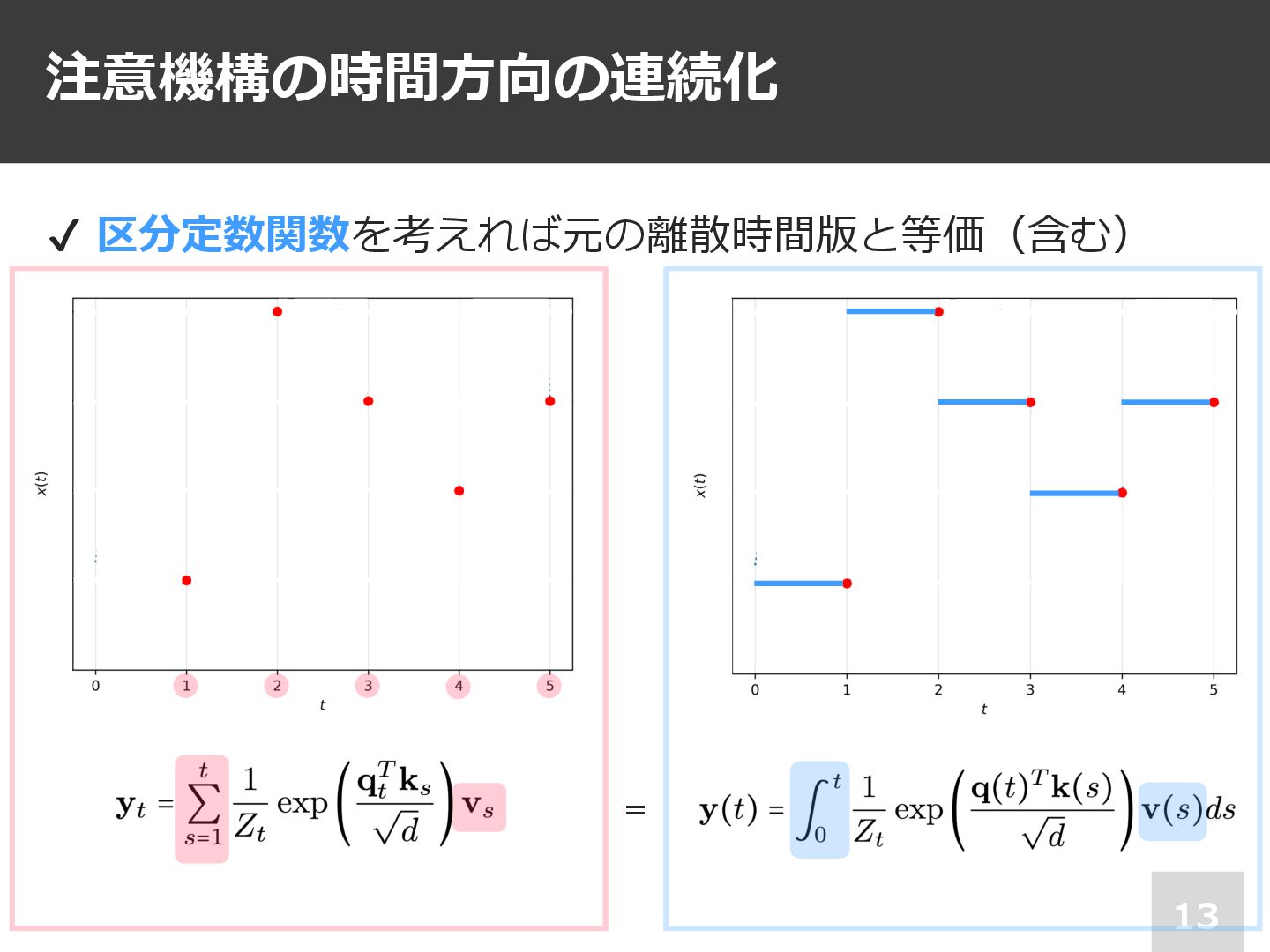
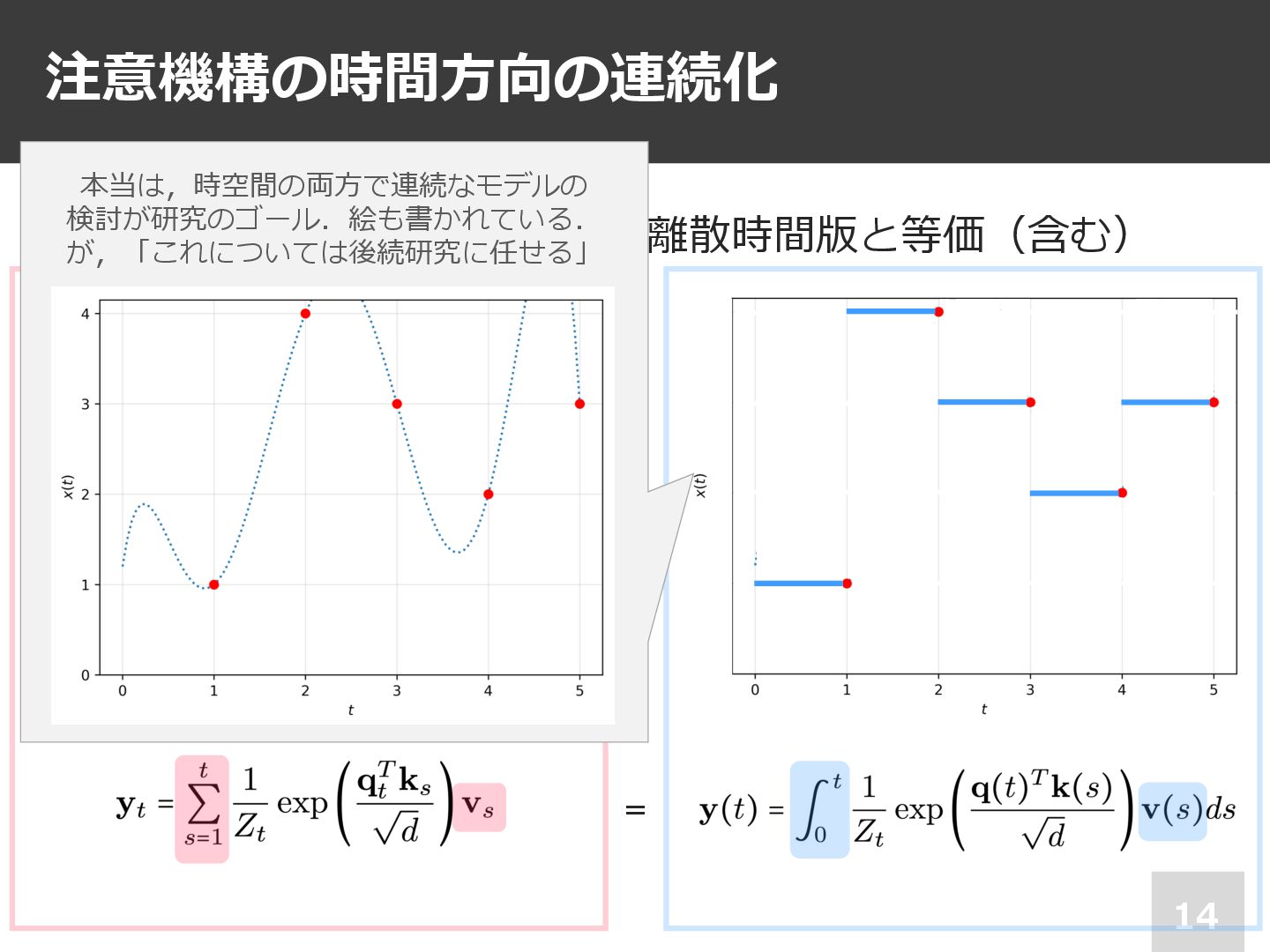
注意機構の時間⽅向の連続化 13 ✔ 区分定数関数を考えれば元の離散時間版と等価(含む) =
注意機構の時間⽅向の連続化 14 ✔ 区分定数関数を考えれば元の離散時間版と等価(含む) = 本当は,時空間の両⽅で連続なモデルの 検討が研究のゴール.絵も書かれている. が,「これについては後続研究に任せる」
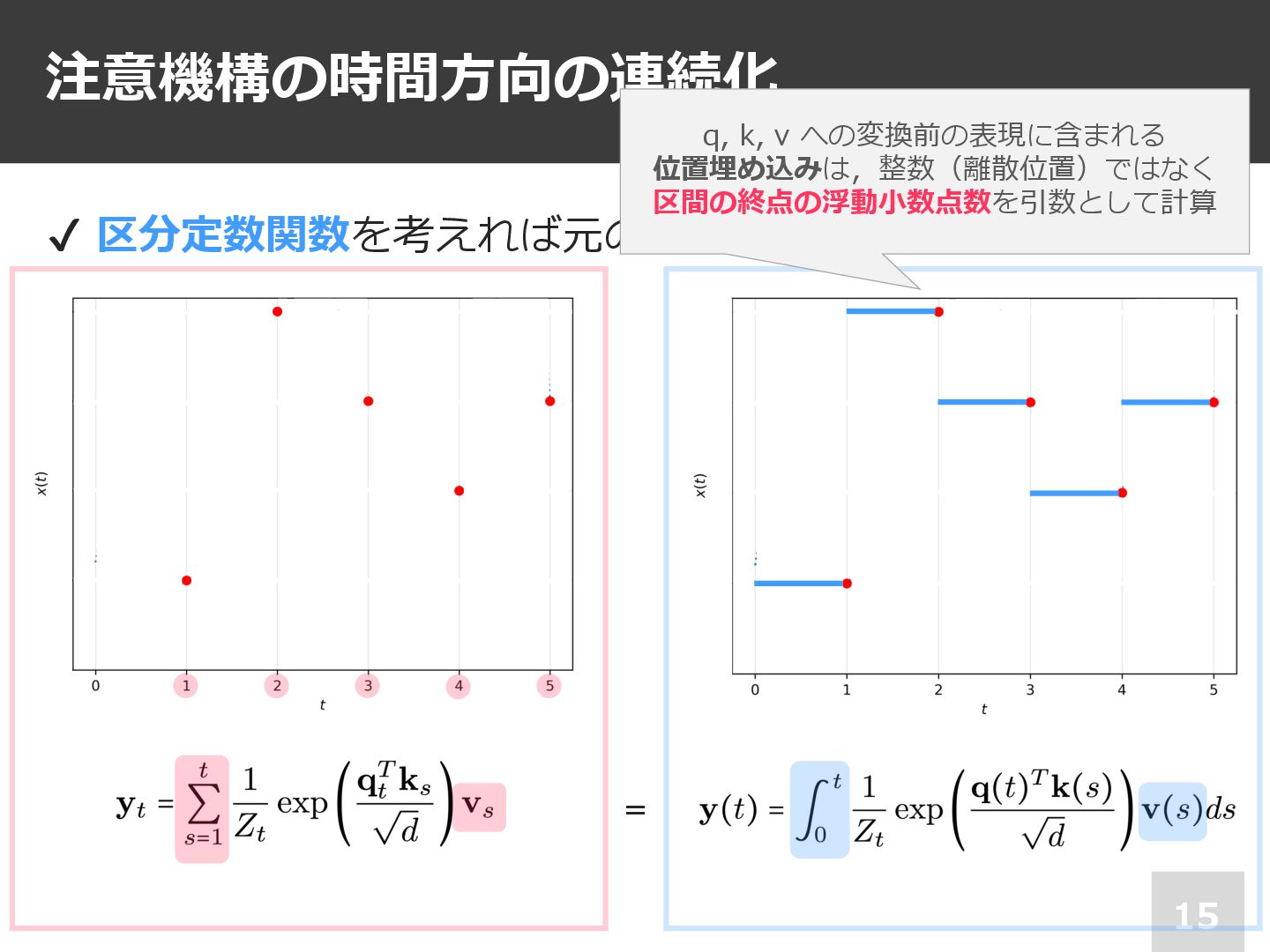
注意機構の時間⽅向の連続化 15 ✔ 区分定数関数を考えれば元の離散時間版と等価(含む) q, k, v への変換前の表現に含まれる 位置埋め込みは,整数(離散位置)ではなく 区間の終点の浮動⼩数点数を引数として計算
=
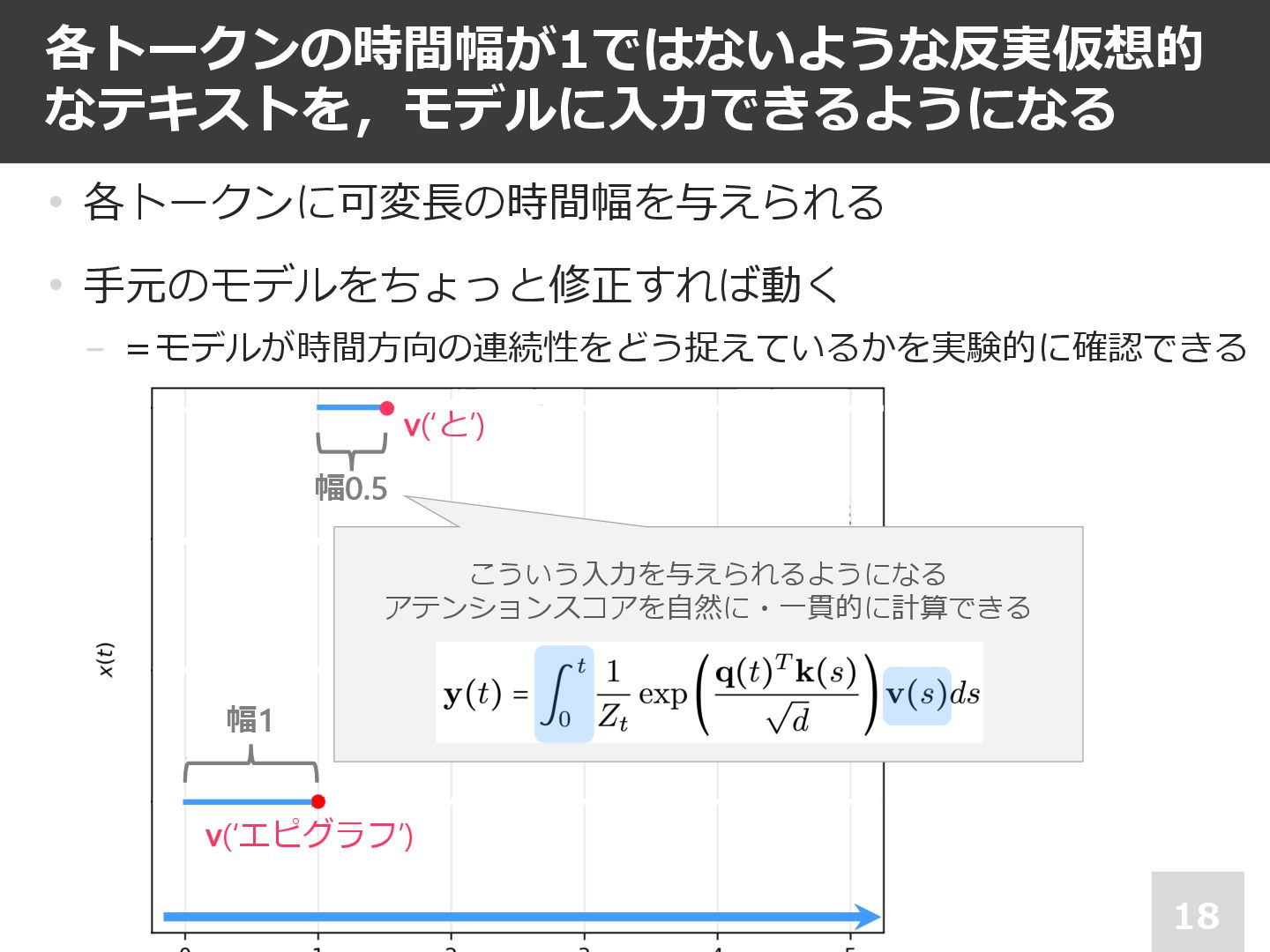
各トークンの時間幅が1ではないような反実仮想的 なテキストを,モデルに⼊⼒できるようになる 18 • 各トークンに可変⻑の時間幅を与えられる • ⼿元のモデルをちょっと修正すれば動く − =モデルが時間⽅向の連続性をどう捉えているかを実験的に確認できる v(‘エピグラフ’)
幅1 幅0.5 v(‘と’) こういう⼊⼒を与えられるようになる アテンションスコアを⾃然に・⼀貫的に計算できる
実験 連続⾔語モデルに “早⼝” でテキストを⼊⼒し, 「⾔語モデルは我々の直観に反する形で (=時間⽅向に連続に)⾔語を捉えている説」 を確認してみる 19
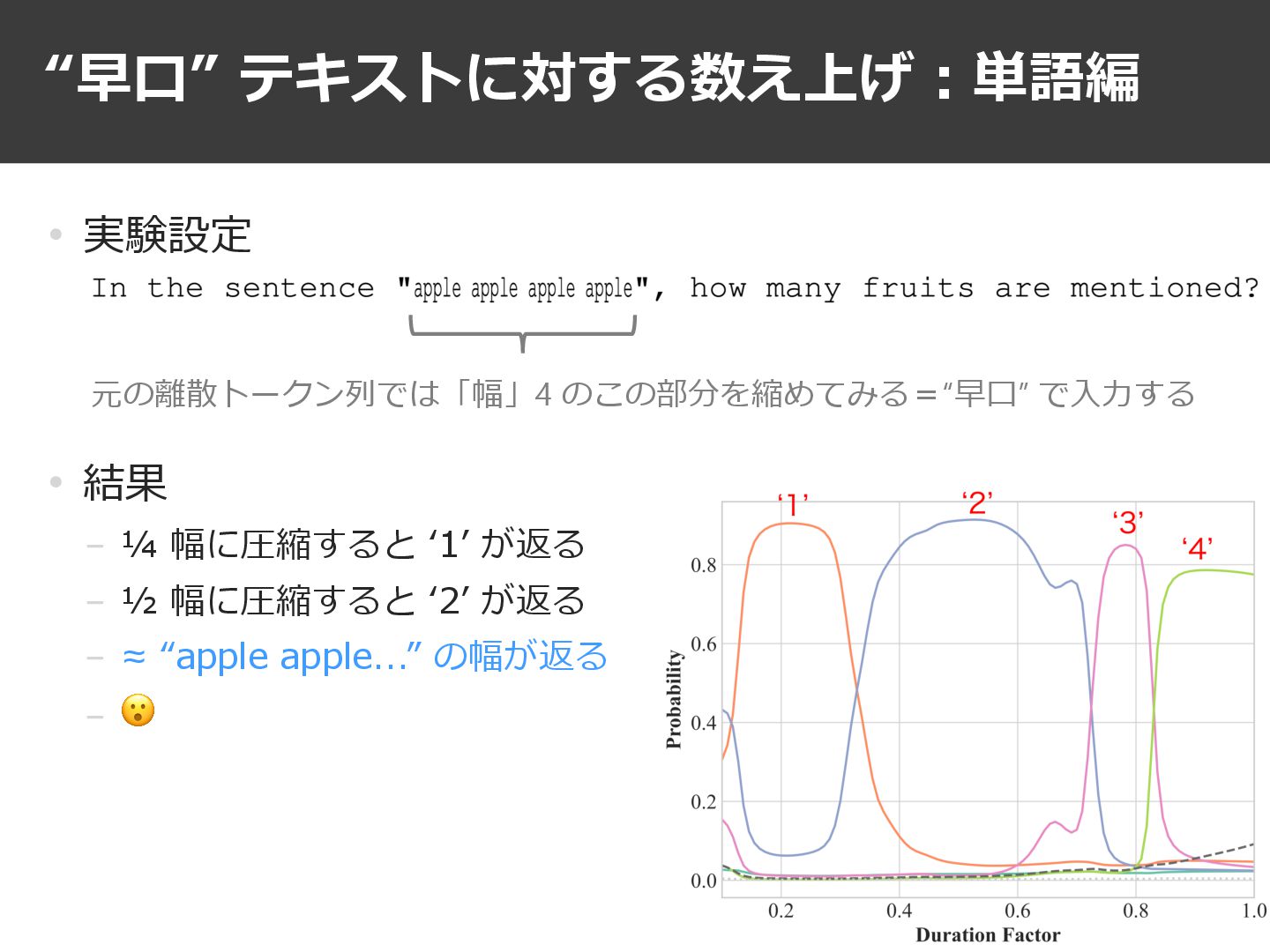
“早⼝” テキストに対する数え上げ︓単語編 20 • 実験設定 • 予想 − ⼈間のように⾔語を扱っているのであれば, どんなに早⼝で⾔おうが4が返ってきそう︖
− 学習時に含まれないような設定なので, 壊れた回答が返ってきたとしてもそれはそれでわかる 元の離散トークン列では「幅」4 のこの部分を縮めてみる=“早⼝” で⼊⼒する
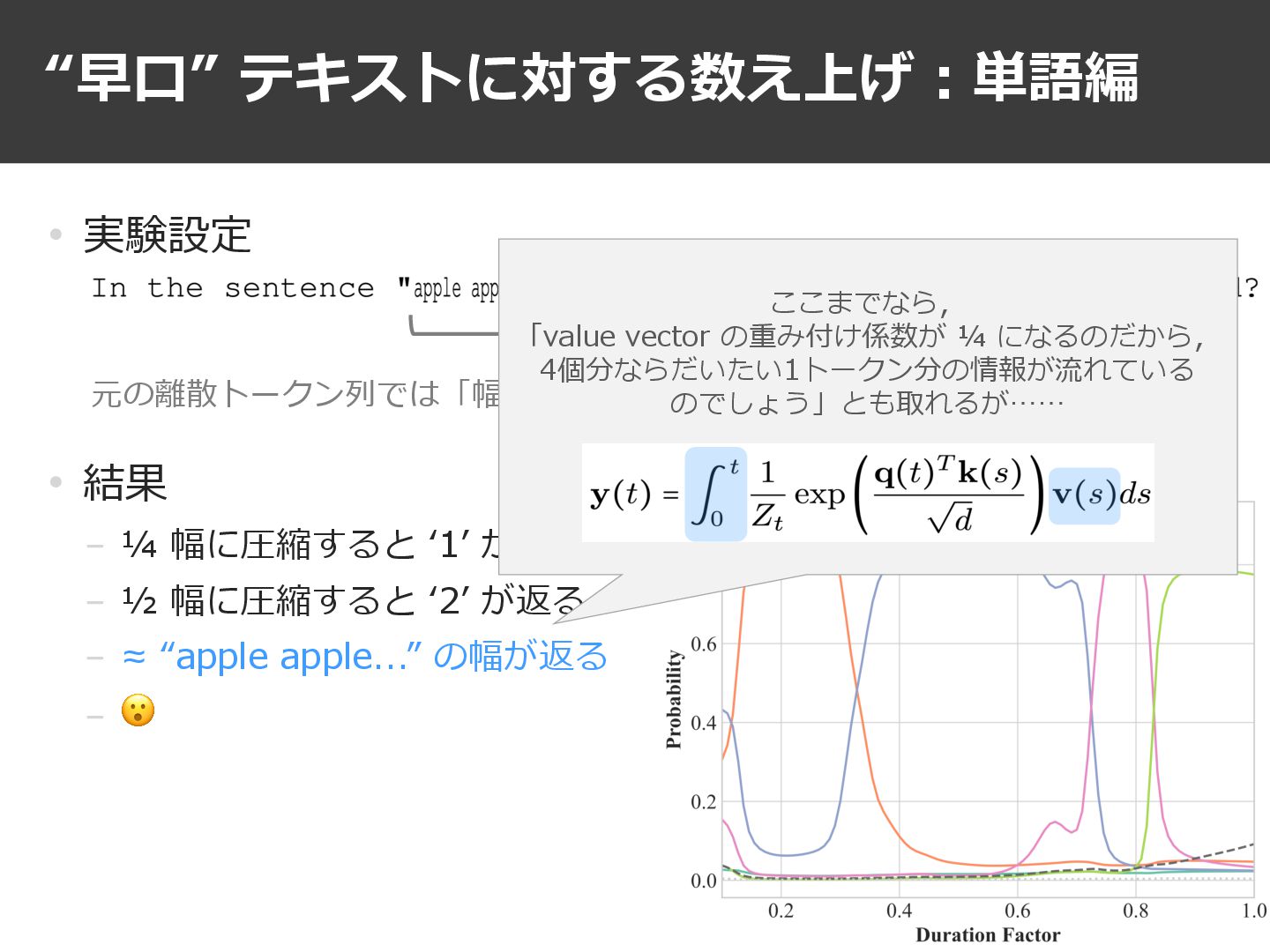
“早⼝” テキストに対する数え上げ︓単語編 21 • 実験設定 • 結果 − ¼ 幅に圧縮すると
ʻ1ʼ が返る − ½ 幅に圧縮すると ʻ2ʼ が返る − ≈ “apple apple...” の幅が返る − 😮 元の離散トークン列では「幅」4 のこの部分を縮めてみる=“早⼝” で⼊⼒する
“早⼝” テキストに対する数え上げ︓単語編 22 • 実験設定 • 結果 − ¼ 幅に圧縮すると
ʻ1ʼ が返る − ½ 幅に圧縮すると ʻ2ʼ が返る − ≈ “apple apple...” の幅が返る − 😮 元の離散トークン列では「幅」4 のこの部分を縮めてみる=“早⼝” で⼊⼒する ここまでなら, 「value vector の重み付け係数が ¼ になるのだから, 4個分ならだいたい1トークン分の情報が流れている のでしょう」とも取れるが……
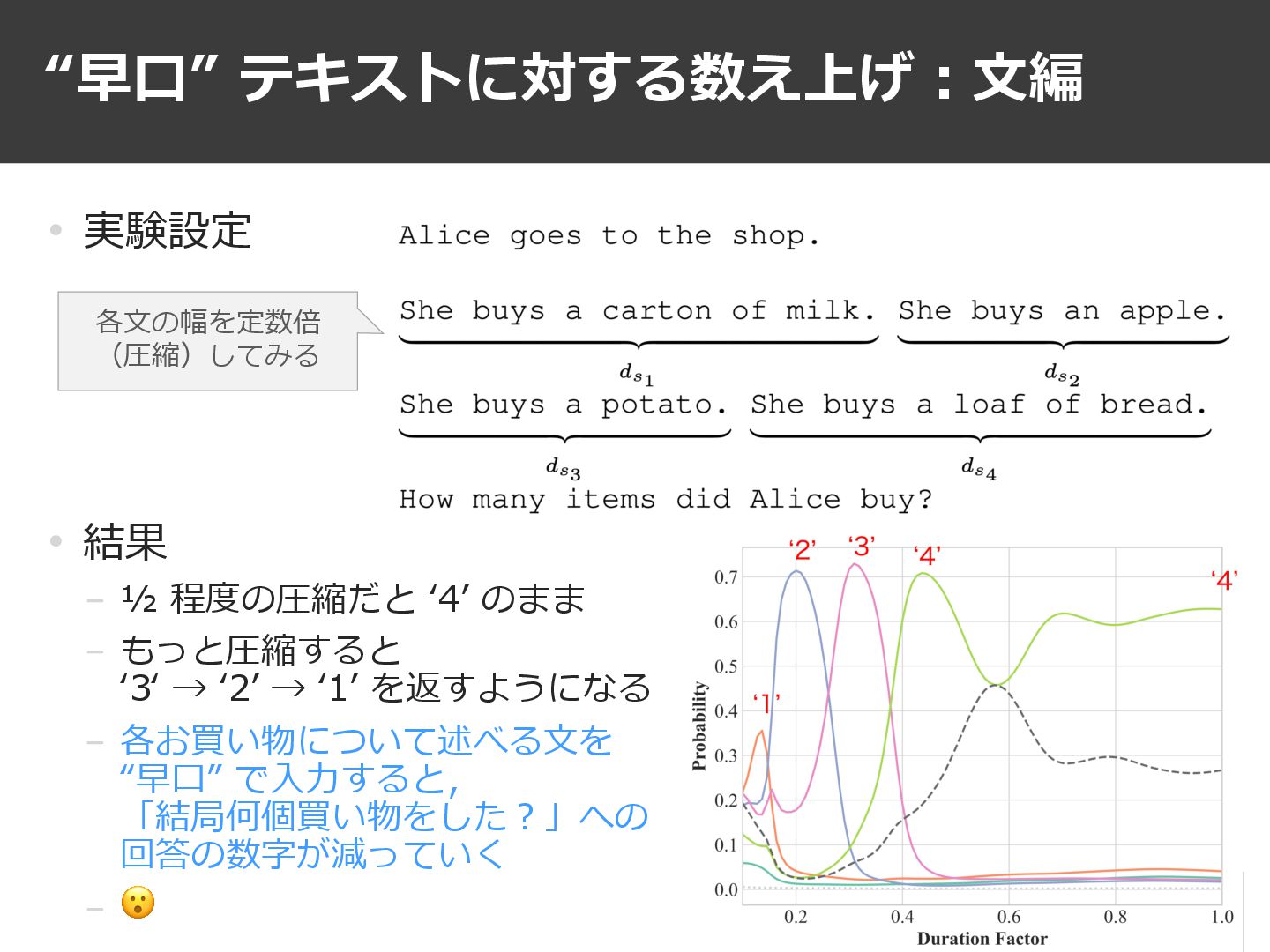
“早⼝” テキストに対する数え上げ︓⽂編 23 • 実験設定 各⽂の幅を定数倍 (圧縮)してみる
“早⼝” テキストに対する数え上げ︓⽂編 24 • 実験設定 • 結果 − ½ 程度の圧縮だと
ʻ4ʼ のまま − もっと圧縮すると ʻ3ʻ → ʻ2ʼ → ʻ1ʼ を返すようになる − 各お買い物について述べる⽂を “早⼝” で⼊⼒すると, 「結局何個買い物をした︖」への 回答の数字が減っていく − 😮 各⽂の幅を定数倍 (圧縮)してみる
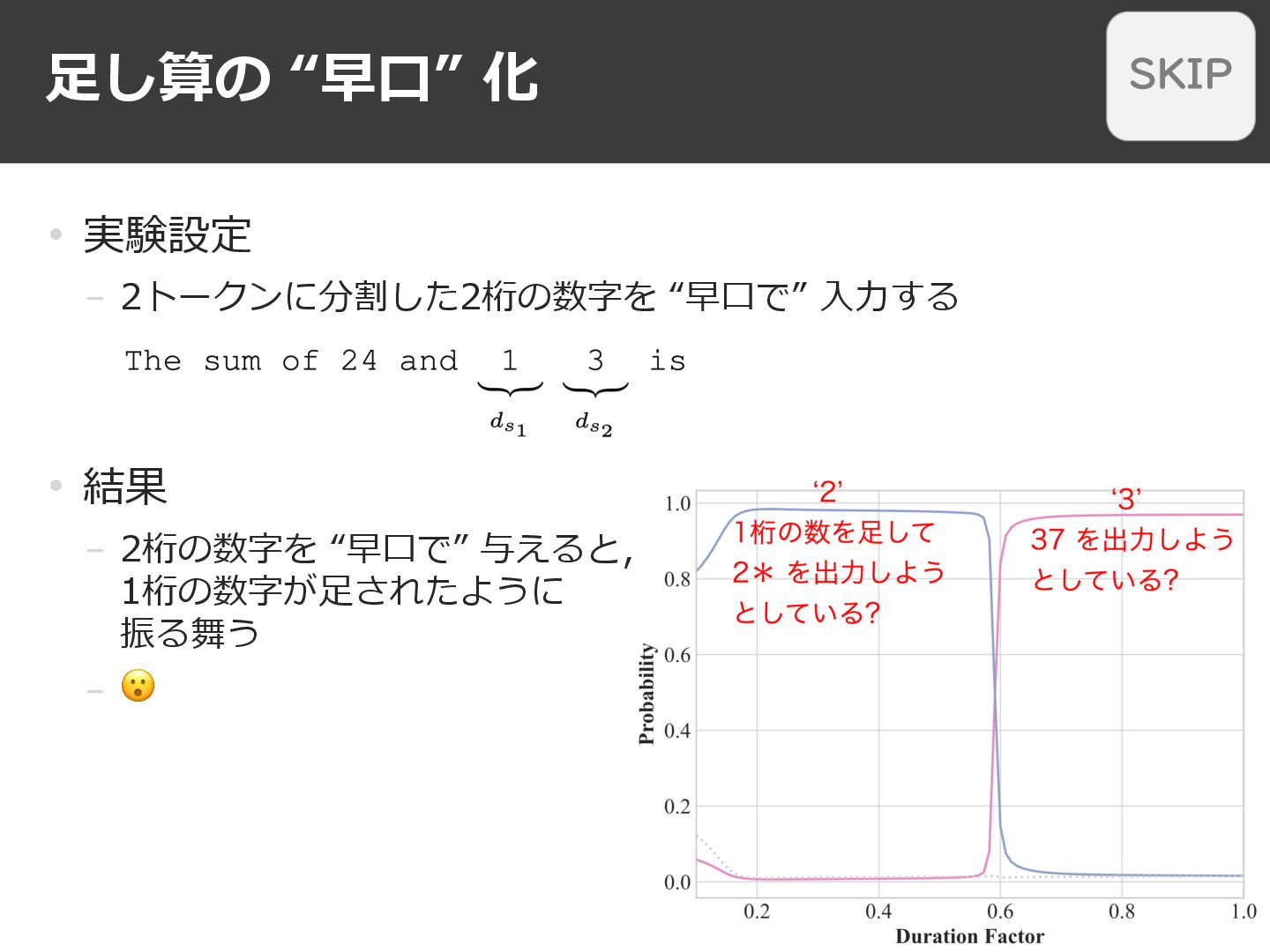
⾜し算の “早⼝” 化 25 • 実験設定 − 2トークンに分割した2桁の数字を “早⼝で” ⼊⼒する
• 結果 − 2桁の数字を “早⼝で” 与えると, 1桁の数字が⾜されたように 振る舞う − 😮 SKIP
まとめ・議論 26
まとめ 27 • 新しい仮説を検討するポジションペーパー 「⾔語モデルは,我々の直観に反して, ⾔語を時間的にも空間的にも連続的に捉えているのでは︖」 • 注意機構を時間⽅向(語順⽅向)に連続化(積分化) − トークン列=区分定数関数
だと思えば,元の⾔語モデルを含む − ⼿元のモデルをちょっと修正すれば動く − =モデルが時間⽅向の連続性をどう捉えているかを実験的に確認できる • ⼊⼒の “早⼝化” 実験 − テキストを “早⼝で” ⼊⼒すると⼊⼒した事象数が少なく⾒積もられる − 少なくとも,離散トークン列としてのテキストに対する⾃然な直感 とは異なる結果が得られる • 著者らの take-home message︓「⾔語モデルにとっての⾔語」 を考える際は,時間⽅向の連続性について思いを馳せてみよう︕
選んだ理由・お気持ち 28 • ⾔語(科, 哲, ……)学の諸分野が議論の前提としている⾔語観 や,拠って⽴っている形⽽上学的コミットメントについて, ⾔語モデル (とかいう異常な何か) の成功が再検討を促して
いる ……ように⾒える − 「⾔語 (推論, 知識, ……) って⼀旦なんなん︖」と考えたくなる • ⾔語学と親和性の⾼い従来の⾃然⾔語処理 − パイプライン︓形態素解析 → 構⽂解析 → 意味解析 → …… − 離散シンボル (e.g. 単語) 間の離散構造 (e.g. ⽊) を取り扱う • → 現在のニューラルネットベースの⾃然⾔語処理 − End2end︓中間問題を解かず⽣データを丸呑み − ⾼次元の連続空間で処理 気になる (1) 経験主義的な 学習フレームワーク 気になる (2) 離散データに対する 連続的なモデリング 私見
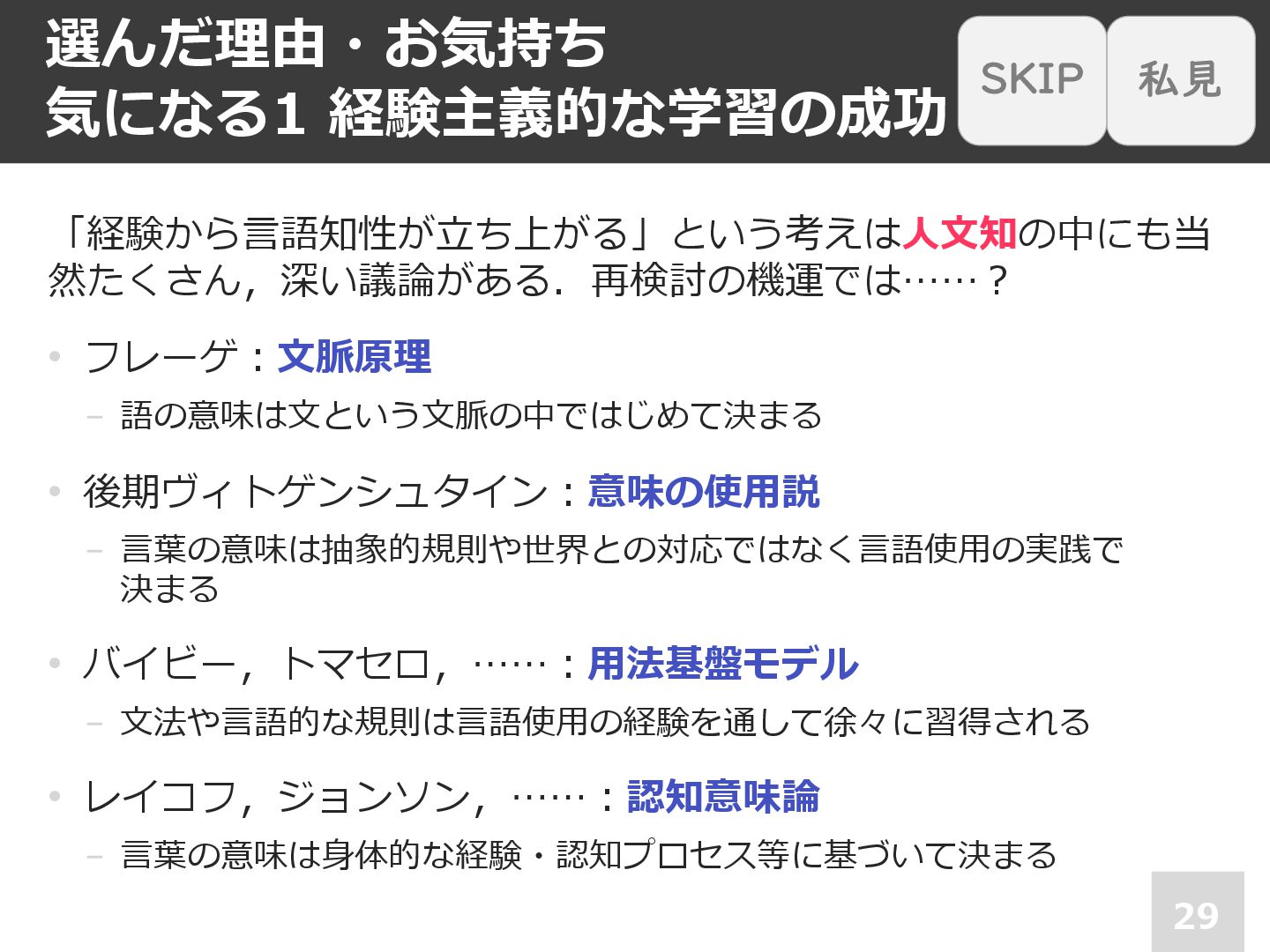
選んだ理由・お気持ち 気になる1 経験主義的な学習の成功 29 「経験から⾔語知性が⽴ち上がる」という考えは⼈⽂知の中にも当 然たくさん,深い議論がある.再検討の機運では……︖ • フレーゲ︓⽂脈原理 − 語の意味は⽂という⽂脈の中ではじめて決まる
• 後期ヴィトゲンシュタイン︓意味の使⽤説 − ⾔葉の意味は抽象的規則や世界との対応ではなく⾔語使⽤の実践で 決まる • バイビー,トマセロ,……︓⽤法基盤モデル − ⽂法や⾔語的な規則は⾔語使⽤の経験を通して徐々に習得される • レイコフ,ジョンソン,……︓認知意味論 − ⾔葉の意味は⾝体的な経験・認知プロセス等に基づいて決まる 私見 SKIP
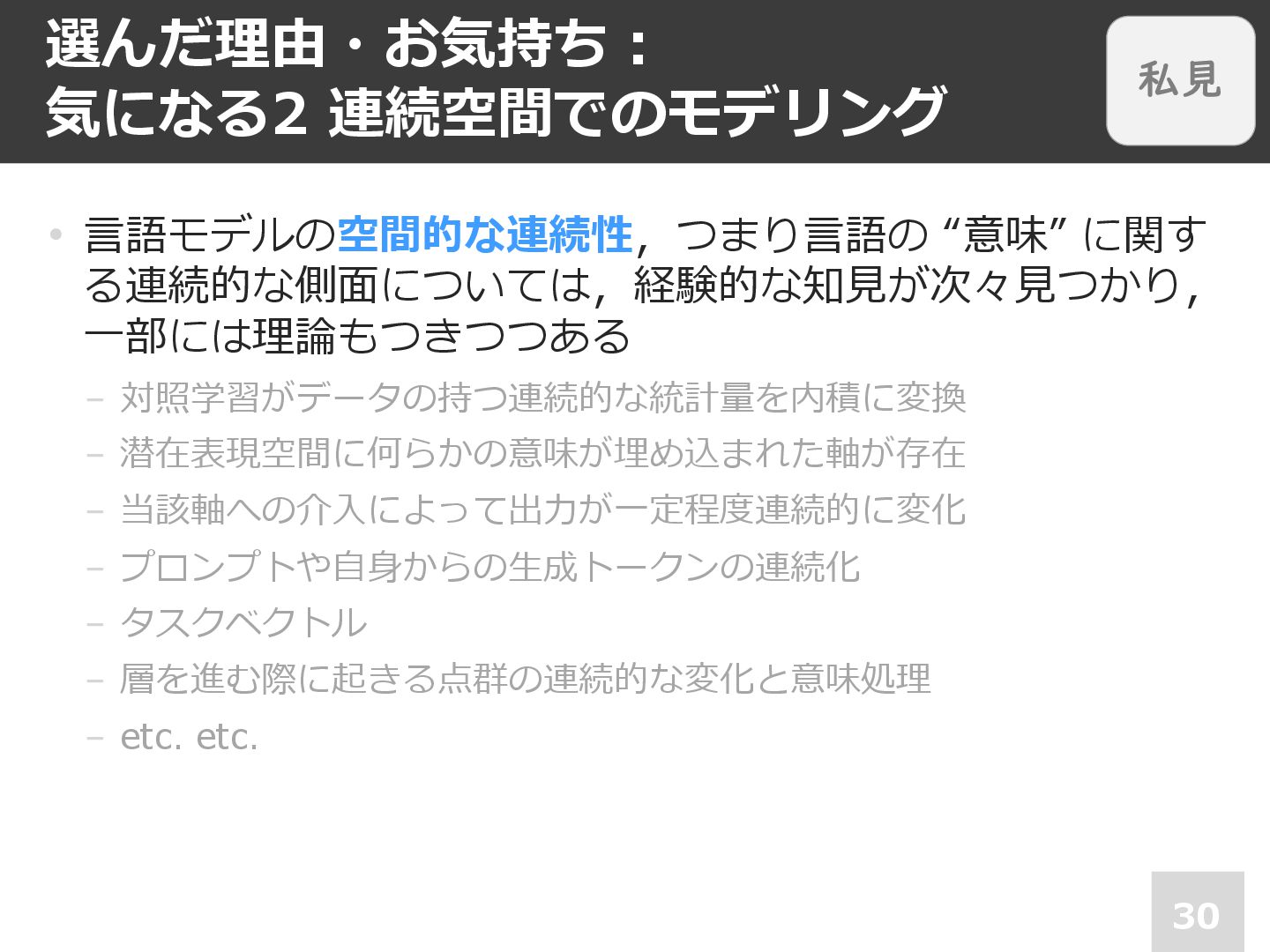
選んだ理由・お気持ち︓ 気になる2 連続空間でのモデリング 30 • ⾔語モデルの空間的な連続性,つまり⾔語の “意味” に関す る連続的な側⾯については,経験的な知⾒が次々⾒つかり, ⼀部には理論もつきつつある
− 対照学習がデータの持つ連続的な統計量を内積に変換 − 潜在表現空間に何らかの意味が埋め込まれた軸が存在 − 当該軸への介⼊によって出⼒が⼀定程度連続的に変化 − プロンプトや⾃⾝からの⽣成トークンの連続化 − タスクベクトル − 層を進む際に起きる点群の連続的な変化と意味処理 − etc. etc. 私見
選んだ理由・お気持ち︓ 気になる2 連続空間でのモデリング 31 • ⾔語は「ちょっと動かす」ができない − ⾔語データは「ちょっと動かせ」ない – 画像の場合︓明るさを少し変える,位置を少し動かす,……などが可
– ⾔語の場合︓「単語を加える」「変える」など⼤きく変えるしかない − 「ちょっと動かす」に依存した (空間の連続性に強く依存した) 機械 学習モデルは,⾔語データでは相対的にうまく動かなかった – VAE (変分オートエンコーダ) – GAN (敵対的⽣成ネットワーク) – 拡散モデル ※ 最近成功し始めた • ……それなのに,テキストを “単語ベクトル集合・列” だと 思って処理するトランスフォーマーはうまく動いている • Q. なぜ︖ − 意味のどの側⾯が “連続的” で,どういう機序で埋め込まれる︖ 私見 SKIP
選んだ理由・お気持ち︓ 気になる3 連続時間でのモデリング 32 • ⾔語モデルの時間的な連続性という側⾯はオープンに⾒える − 「テキストデータ=トークン列」は現在のNLPの⼯学的な強い前提 − ⾔語モデルを離散時間で組むことも⾃然
− このペーパーも,離散的な⾔語モデルの「暗黙的な」連続性を議論 • ⾔語・テキストデータ・LMs の時間的の連続性は重要そう − ⾔語学の中⼼課題のひとつは,⾳声(時間⽅向に連続的な信号)と意 味の対応関係の解明 − 離散トークン列だとしても…… – トークン毎の情報量(等,信号の強さ)は連続的 – 「時間的にも意味的にもひとかたまり」の部分が分割されまくる – こうした情報が時間幅として暗黙的に埋め込まれていたりする︖ − RNN系など,より時系列データの処理を重視したモデルへの含意︖ − etc. 私見
選んだ理由・お気持ち 33 • ⾔語(科, 哲, ……)学の諸分野が議論の前提としている⾔語観 や,拠って⽴っている形⽽上学的コミットメントについて, ⾔語モデル (とかいう異常な何か) の成功が再検討を促して
いる ……ように⾒える − 「⾔語 (推論, 知識, ……) って⼀旦なんなん︖」と考えたくなる • ⾔語学と親和性の⾼い従来の⾃然⾔語処理 − パイプライン︓形態素解析 → 構⽂解析 → 意味解析 → …… − 離散シンボル (e.g. 単語) 間の離散構造 (e.g. ⽊) を取り扱う • → 現在のニューラルネットベースの⾃然⾔語処理 − End2end︓中間問題を解かず⽣データを丸呑み − ⾼次元の連続空間で処理 気になる (1) 経験主義的な 学習フレームワーク 気になる (2) 離散データに対する 連続的なモデリング 私見 この論⽂「トランスフォーマーLMは 時空間の両⽅で連続的なのでは︖」
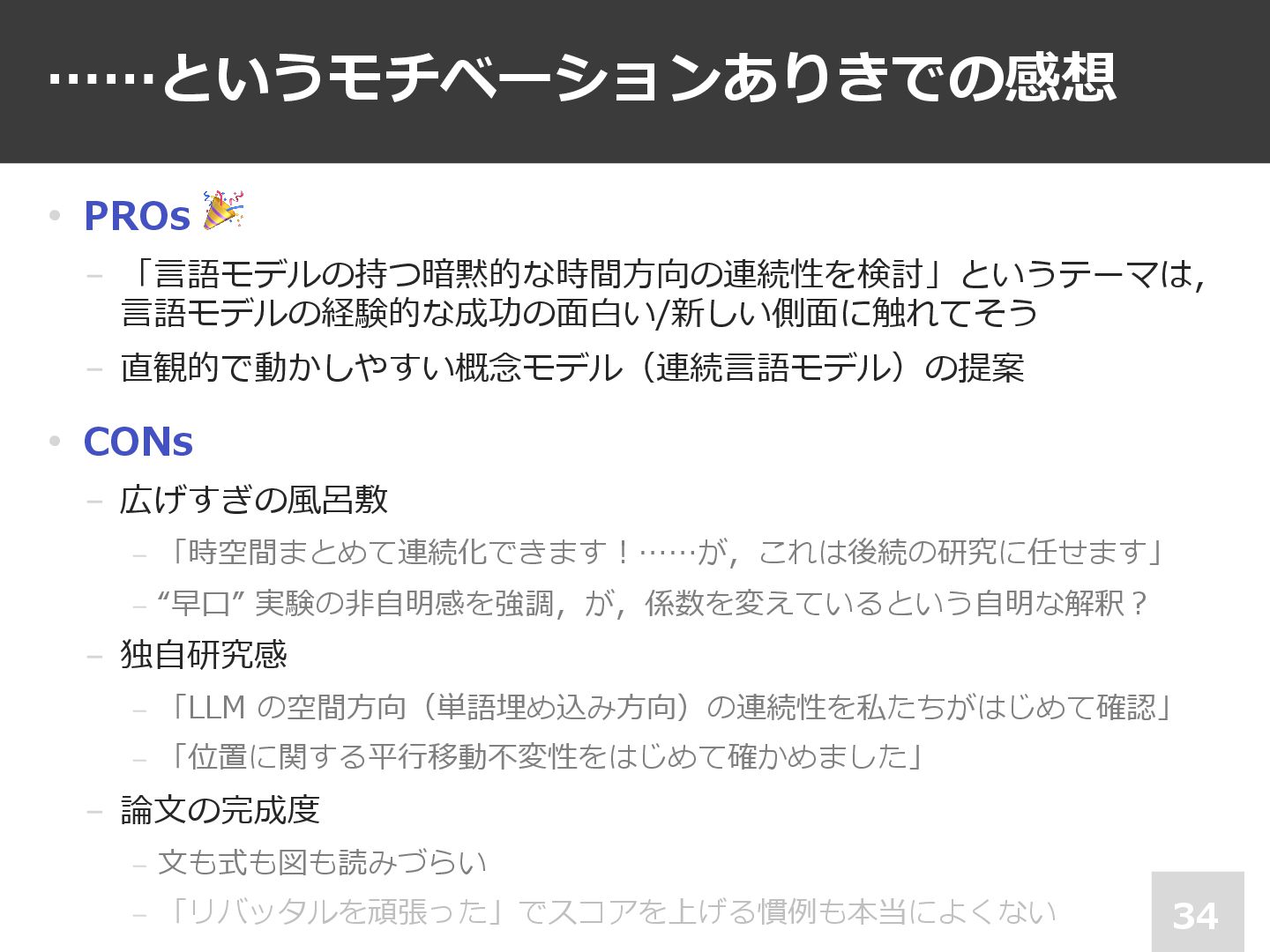
……というモチベーションありきでの感想 34 • PROs 🎉 − 「⾔語モデルの持つ暗黙的な時間⽅向の連続性を検討」というテーマは, ⾔語モデルの経験的な成功の⾯⽩い/新しい側⾯に触れてそう − 直観的で動かしやすい概念モデル(連続⾔語モデル)の提案
• CONs − 広げすぎの⾵呂敷 – 「時空間まとめて連続化できます︕……が,これは後続の研究に任せます」 – “早⼝” 実験の⾮⾃明感を強調,が,係数を変えているという⾃明な解釈︖ − 独⾃研究感 – 「LLM の空間⽅向(単語埋め込み⽅向)の連続性を私たちがはじめて確認」 – 「位置に関する平⾏移動不変性をはじめて確かめました」 − 論⽂の完成度 – ⽂も式も図も読みづらい – 「リバッタルを頑張った」でスコアを上げる慣例も本当によくない
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}