2021 • The CTO and co-founder of Komodor, a startup building the first k8s-native troubleshooting platform. • A big believer in dev empowerment and moving fast. • Worked at eBay|Forter| Rookout (first developer), A lot backend and infra developer experience (“DevOps”) • K8S fan 😃 Who am I?
2021 Agenda 1. Why should you care what changed 2. What is a change 3. Why is it so hard to find what changed 4. The future of changes tracking 5. What can you do???
what changed • Issues happen on an hourly basis • They derive from complete system downtime to a small bug in staging • 85% of incidents can be traced to system changes!!! • Most troubleshooting time is focused around identifying the issue
Any action that altered the system state. For example: • Code deployment • Infra changes (Cloud/on prem) • Config change • Feature flag • Job’s changes • DB migrations • 3 party changes • Customer usage or data*
3parties (cloud/ api’s etc’) 2. Includes dozens of microservices 3. Changes rapidly (the more the better) 4. Everyone can make a change (shift left) TL;DR Modern systems are basically a super complex puzzle that changes rapidly. Modern Haystack
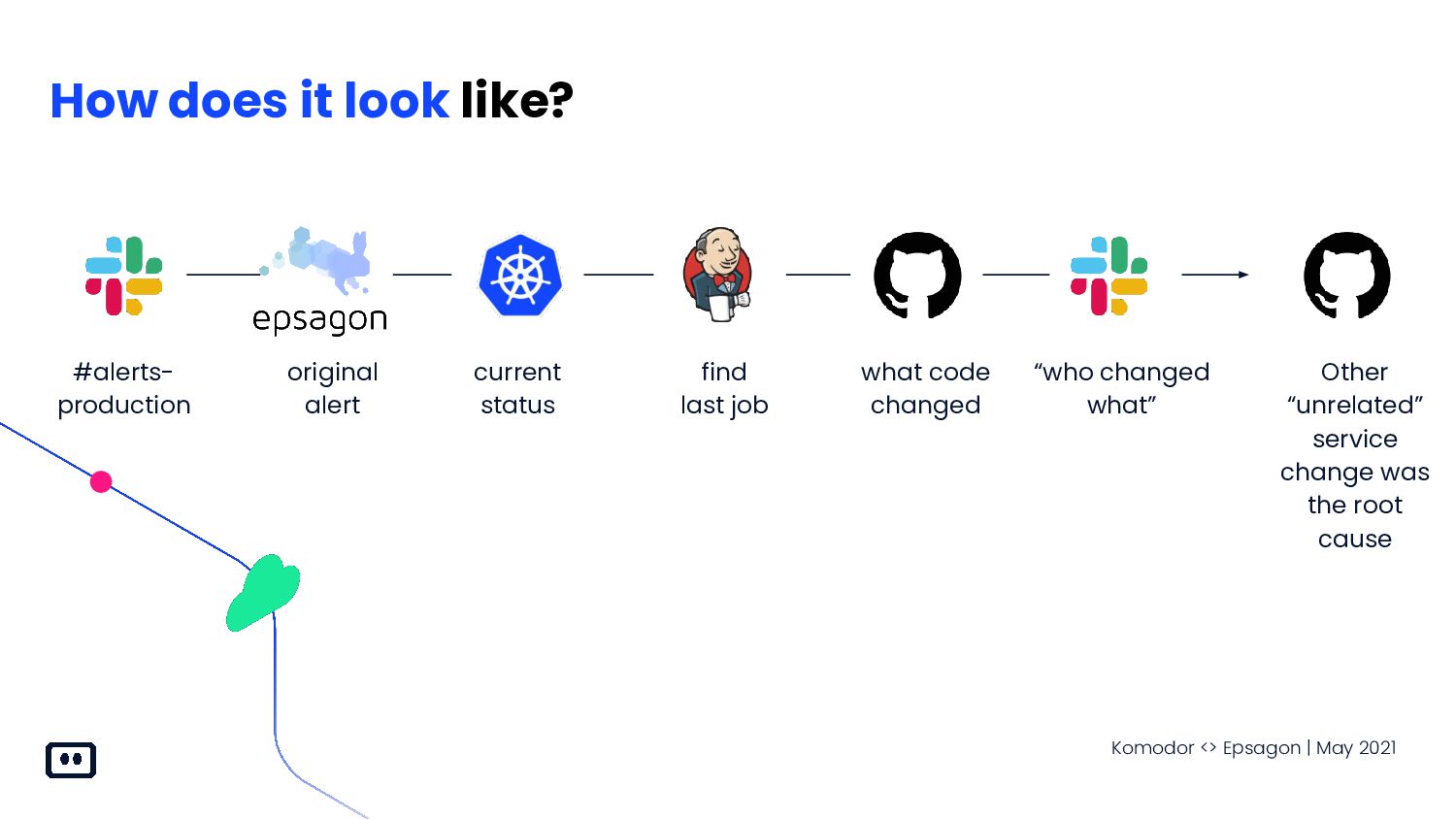
hard? 1. Everything is connected - Ripple effect can cause “unrelated change” to crash the system 2. Dark data - Unaudited changes are happening all day long! (cloud changes/deploy to production/3 parties changes etc.) 3. Scattered data - Tracking changes efficnetly require opening up different systems and query each individually
do? 1. Admitting you have a problem 2. Automate change Notification to slack (or monitoring tools) 3. Use IAC as much as possible 4. Create a changes process (even if just for reporting) 5. Improve cross team communication while troubleshooting 6. Eliminate unaudited change: use process or tool 7. Use distributed tracing to better understand system topology 8. Use tags/ annotation and metadata with relevant version 9. Gitops can eliminate some of the issues 10. Create playbooks with links to relevant tools changes 10 quick tips
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}