This tutorial will demonstrate ways to approach the design and implementation of concurrent data structures. In the process, it will clarify that there is no one size fits it all solution and different designs – such as shared variables and locks or communicating sequential processes – can make sense. It is not always obvious which approach is preferable but depending on the context, one solution can be simpler or more expressive to the specific problem domain than the other one.
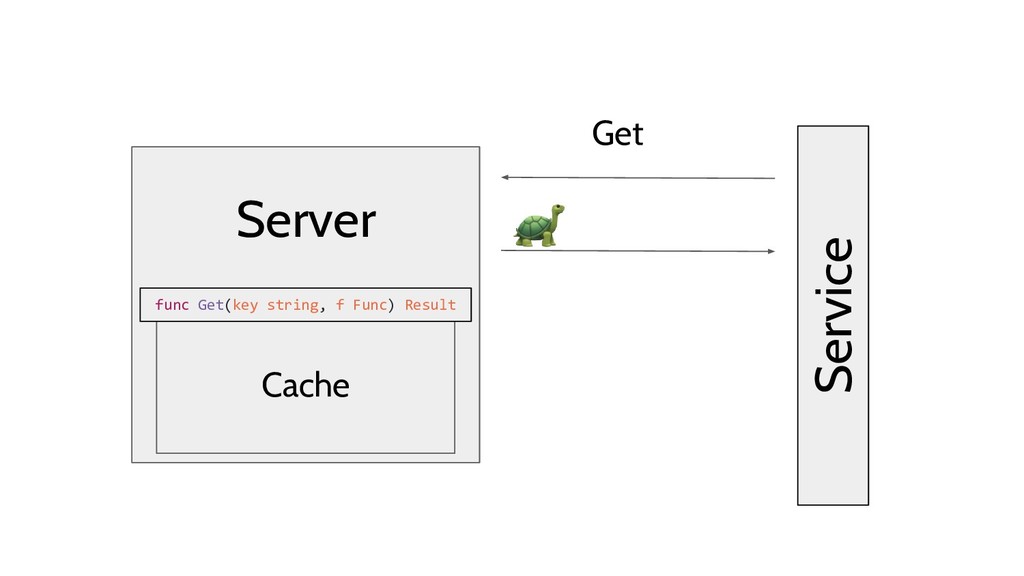
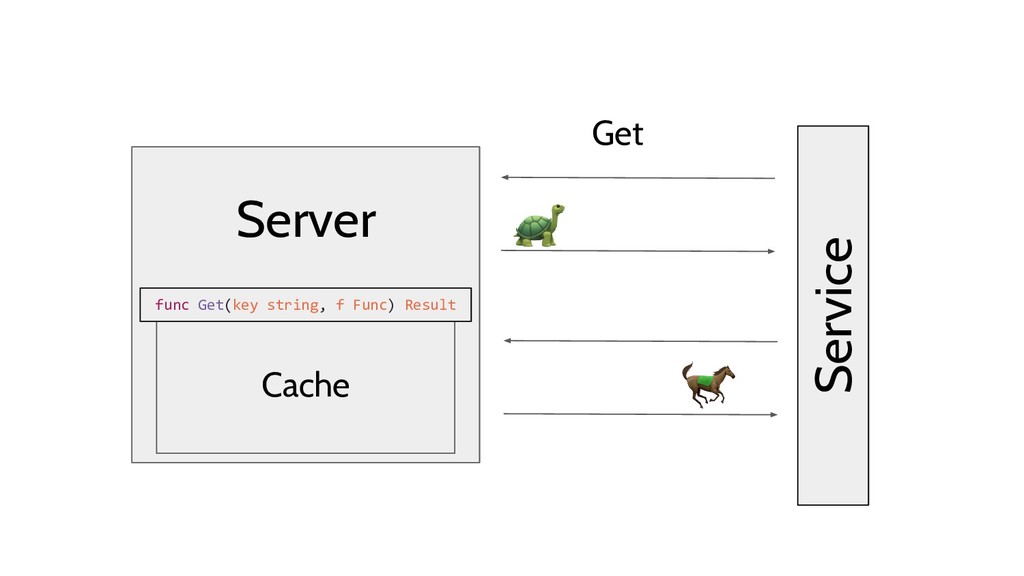
The demo will use a cache as the sample project. It will fetch a handle which serves HTTP requests for computing a playlist dynamically based on existing media segments in a database. Calls to this endpoint are relatively expensive which makes it a reasonable use case for a cache.
Video: https://www.youtube.com/32gCDXoN1NU?start=1787
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks Ping me [email protected] Follow me @konradreiche](https://files.speakerdeck.com/presentations/0120e77638c94cfe90b8e57cec3b092e/slide_13.jpg){kind=link}