Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
歌唱者ダイアライゼーションに向けた 歌唱者識別手法の比較
Search
Kitahara Lab.
February 06, 2023
51
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
歌唱者ダイアライゼーションに向けた 歌唱者識別手法の比較
2022年度卒業研究発表 田中麻衣
Kitahara Lab.
February 06, 2023
More Decks by Kitahara Lab.
See All by Kitahara Lab.
カラーバーの段階的非表示による読譜誘導型ピアノ演奏支援システムの試作
kthrlab
0
41
初学者による演奏音の自動評価を目的としたフルート音の音響分析
kthrlab
1
52
サッカーにおける選手位置とパスコースの可聴化システム
kthrlab
0
35
ハウスミュージックの楽曲構成を決める要因とその法則性の分析
kthrlab
0
220
川原瑞樹
kthrlab
0
100
即興演奏システム JamSketch の社会応用の可能性
kthrlab
0
42
Generating Melodies from Melodic Outlines Towards an Improvisation Support Systems for Non-musicians
kthrlab
0
52
即興演奏支援に向けた旋律生成の一試行
kthrlab
0
18
JamSketch Deep α: A CNN-based Improvisation System in Accordance with User's Melodic Outline Drawing
kthrlab
0
36
Featured
See All Featured
KATA
mclloyd
PRO
35
15k
The agentic SEO stack - context over prompts
schlessera
0
840
Discover your Explorer Soul
emna__ayadi
2
1.2k
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
Information Architects: The Missing Link in Design Systems
soysaucechin
0
1k
Optimizing for Happiness
mojombo
378
71k
The Cost Of JavaScript in 2023
addyosmani
55
10k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
Tell your own story through comics
letsgokoyo
1
990
Building AI with AI
inesmontani
PRO
1
1.1k
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
340
Mobile First: as difficult as doing things right
swwweet
225
10k
Transcript
グループ楽曲における 歌唱者識別システム 北原研究室 田中 麻衣
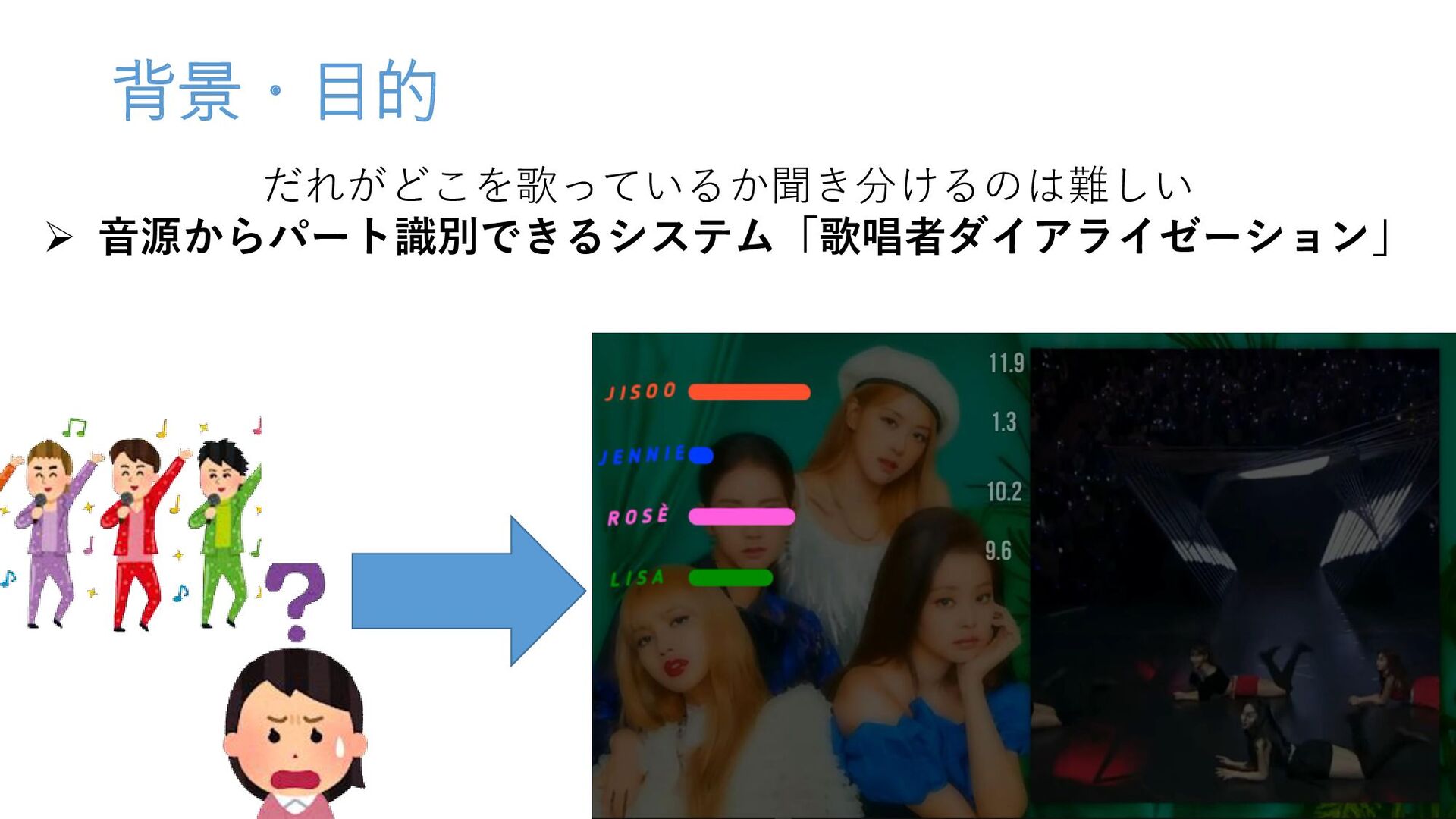
背景・目的 だれがどこを歌っているか聞き分けるのは難しい 音源からパート識別できるシステム「歌唱者ダイアライゼーション」
関連技術 関連研究 話者ダイアライゼーション 誰がどこでしゃべっている かを識別する技術 歌唱者ダイアライゼーション 背景音があると歌声の特徴 量抽出は難しい カラオケ音源を使用した音 源分離手法を用いて実験
今回 セグメントごとの歌唱者識別 カラオケ音源を使わない音 源分離モデルで背景音を除 去 セグメントの長さによる影 響の検証
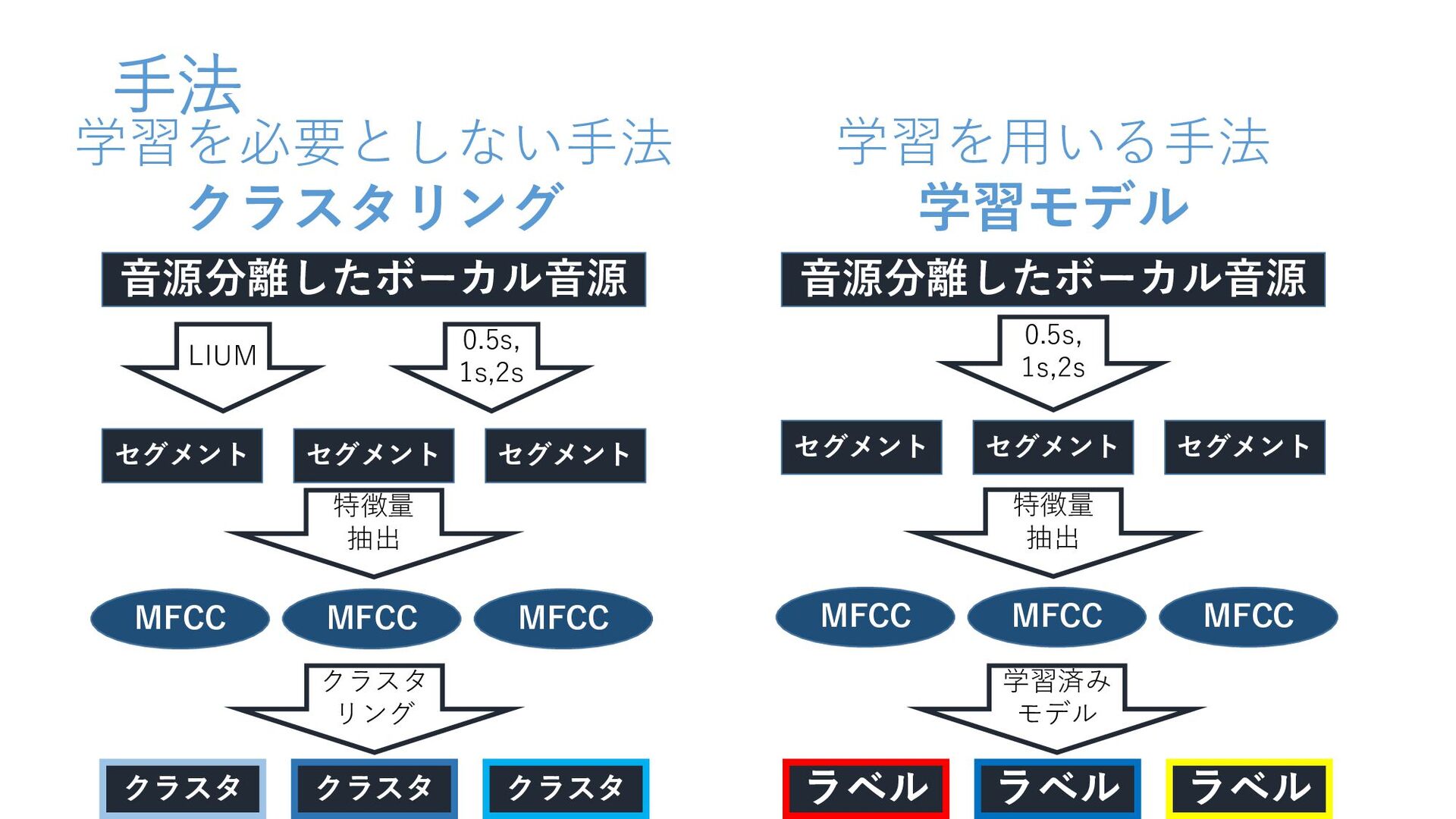
手法 音源分離したボーカル音源 音源分離したボーカル音源 LIUM 0.5s, 1s,2s 0.5s, 1s,2s セグメント セグメント
セグメント セグメント セグメント セグメント クラスタ リング 学習済み モデル クラスタ クラスタ クラスタ 特徴量 抽出 特徴量 抽出 MFCC MFCC MFCC 学習を必要としない手法 クラスタリング 学習を用いる手法 学習モデル MFCC MFCC MFCC ラベル ラベル ラベル
実験条件 使用音源 • 男性ボーカル2人組「ゆず」 の楽曲25曲を使用 • 音源分離モデル「demucs」 でボーカル音源抽出 データセット •
年代順割当データセット • ランダム割当データセット 入出力データ • 入力:特徴量MFCC • 出力:4クラス
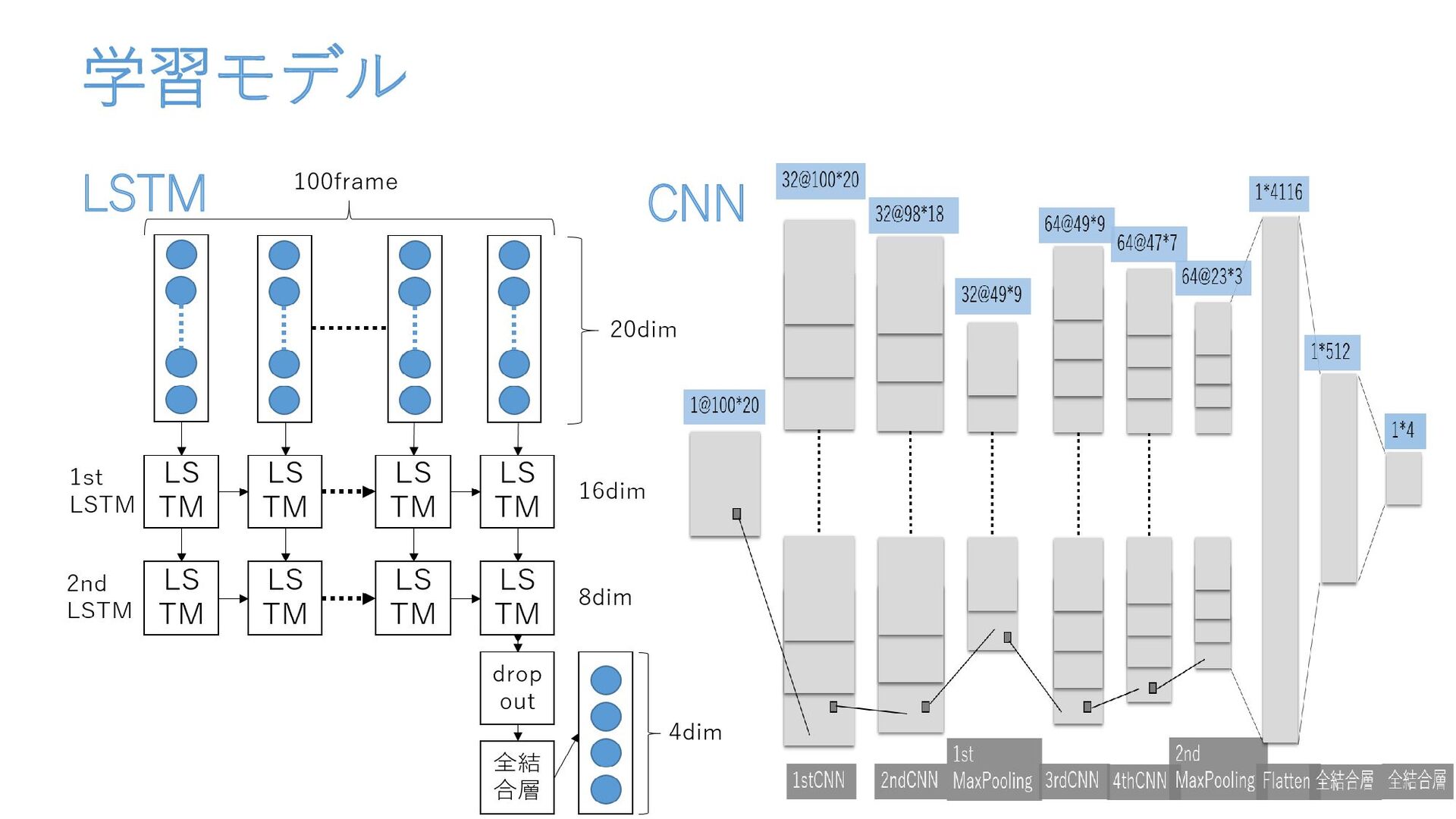
学習モデル LSTM CNN
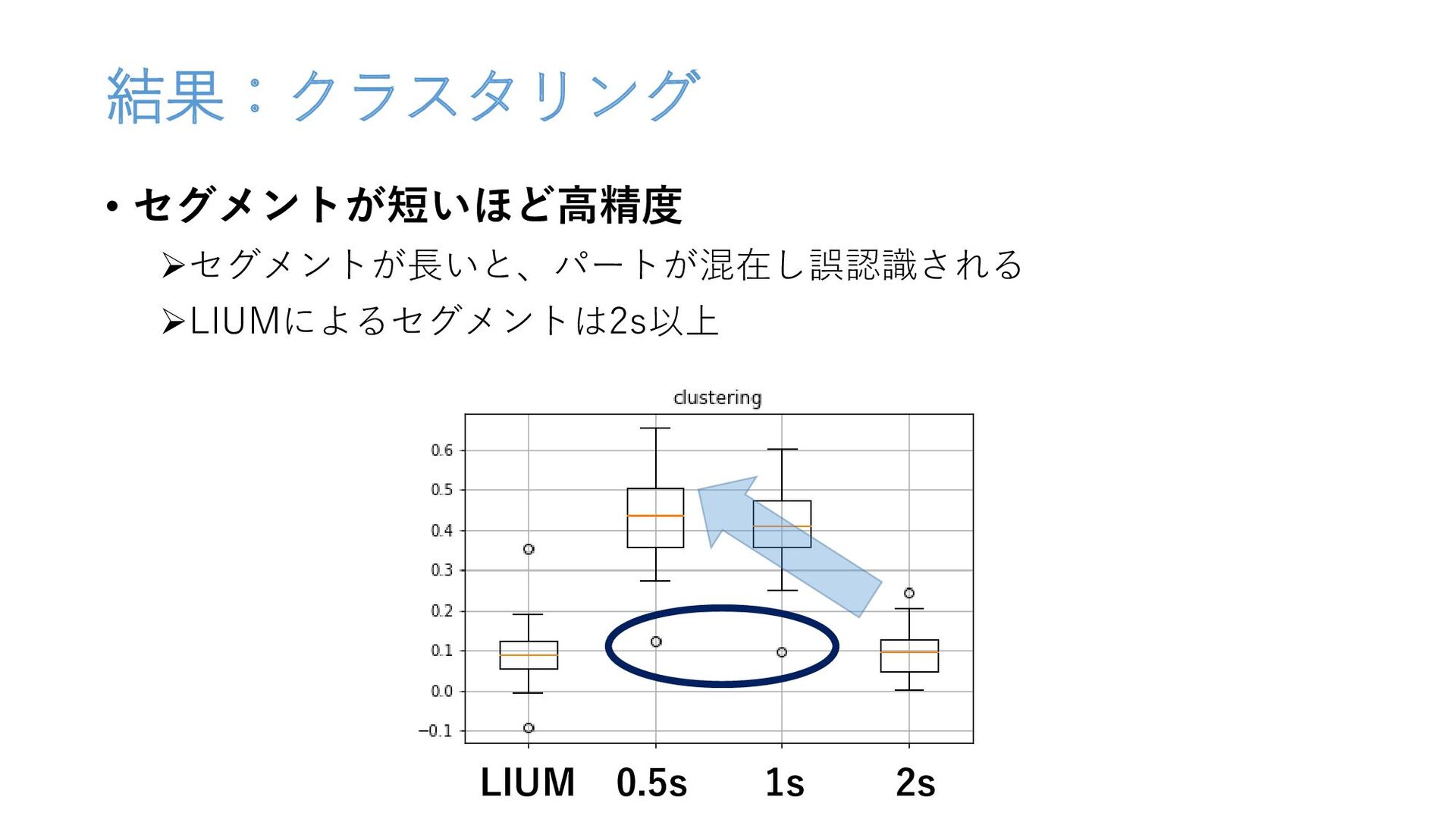
結果:クラスタリング • セグメントが短いほど高精度 セグメントが長いと、パートが混在し誤認識される LIUMによるセグメントは2s以上 LIUM 0.5s 1s 2s
ラ ベ ル r ラ ベ ル r 時間(10ms) 時間(10ms)
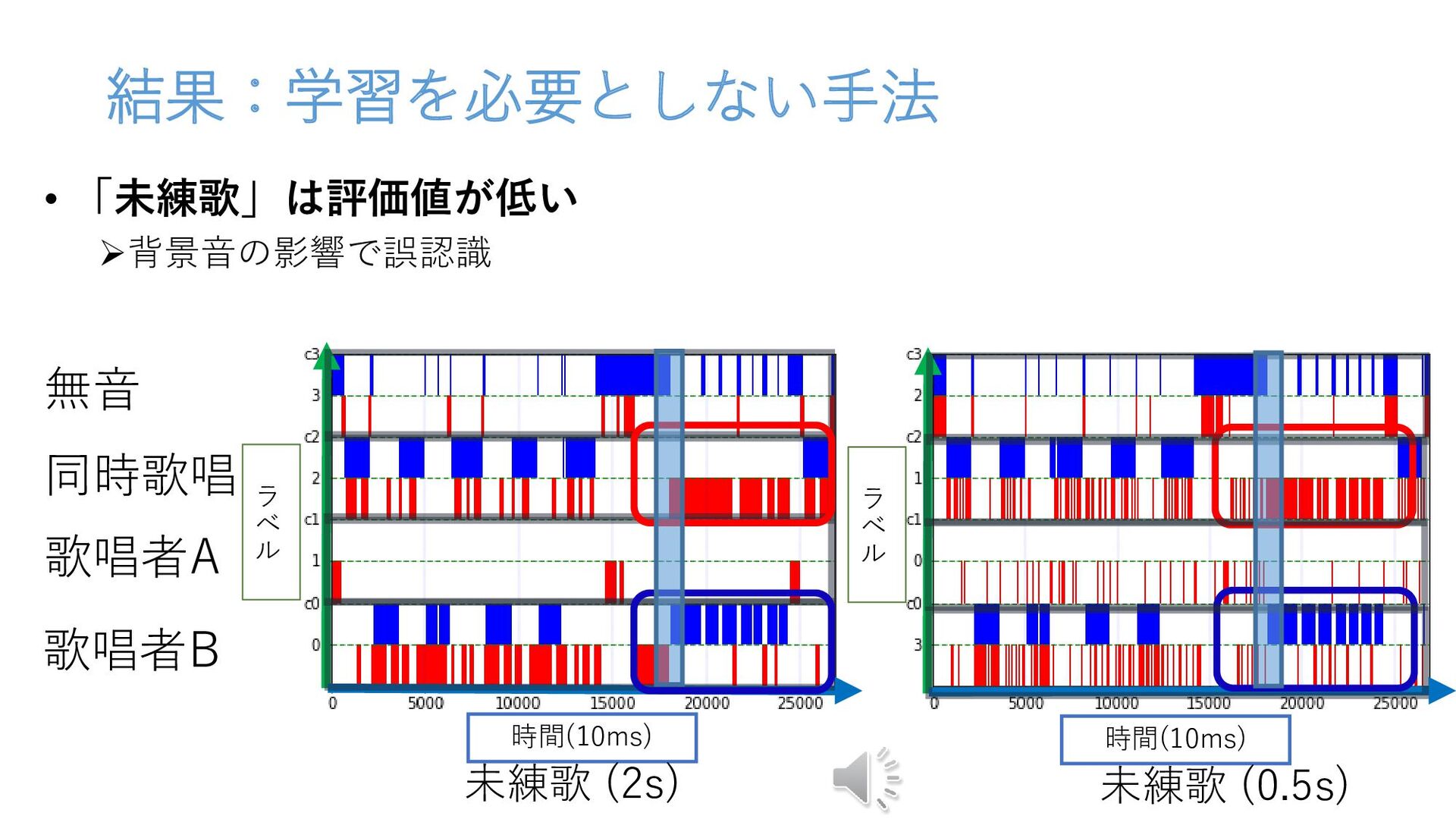
結果:学習を必要としない手法 • 「未練歌」は評価値が低い 背景音の影響で誤認識 未練歌 (0.5s) 未練歌 (2s) 無音 同時歌唱 歌唱者A 歌唱者B
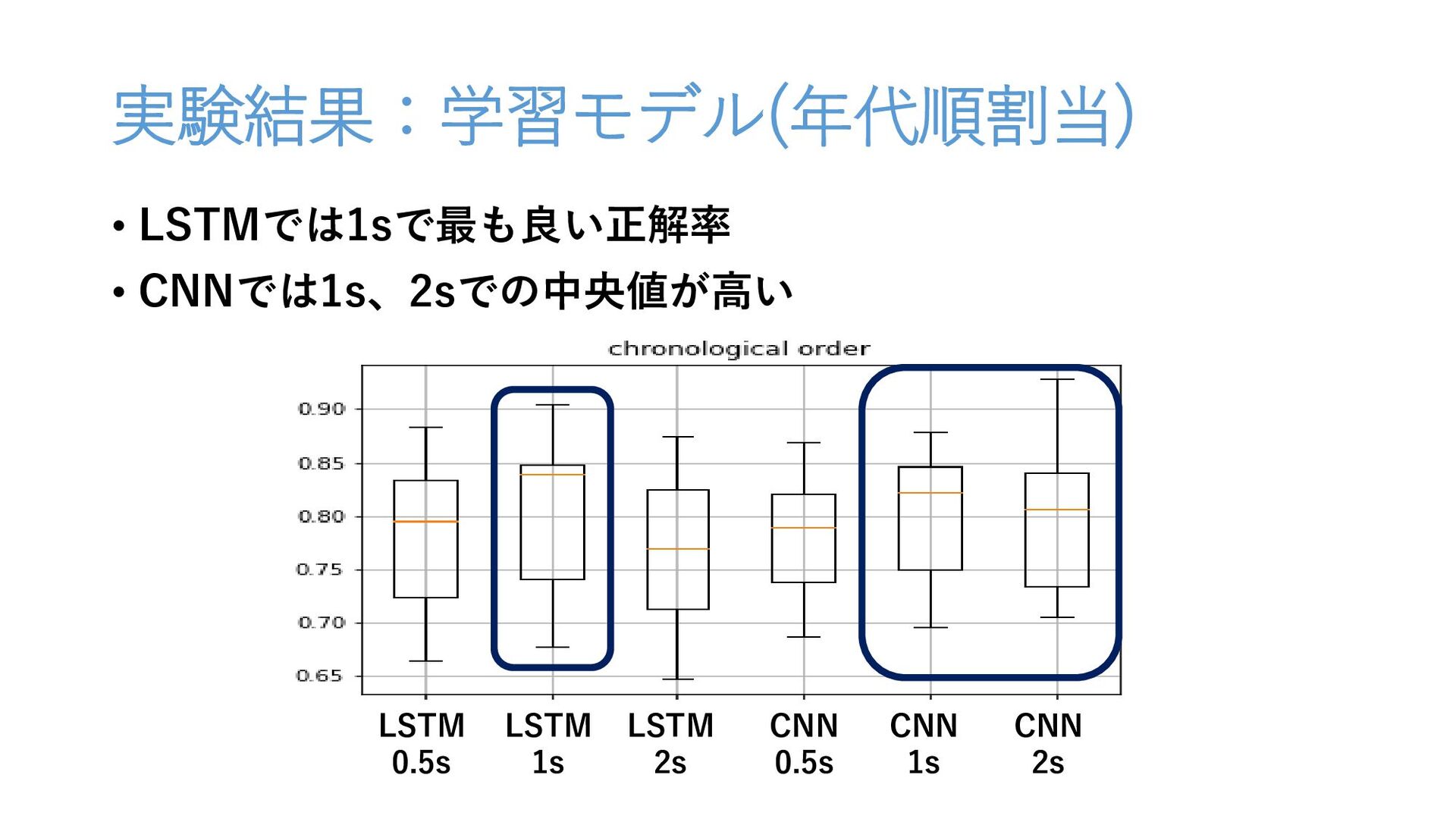
実験結果:学習モデル(年代順割当) • LSTMでは1sで最も良い正解率 • CNNでは1s、2sでの中央値が高い LSTM 0.5s LSTM 1s LSTM
2s CNN 0.5s CNN 1s CNN 2s
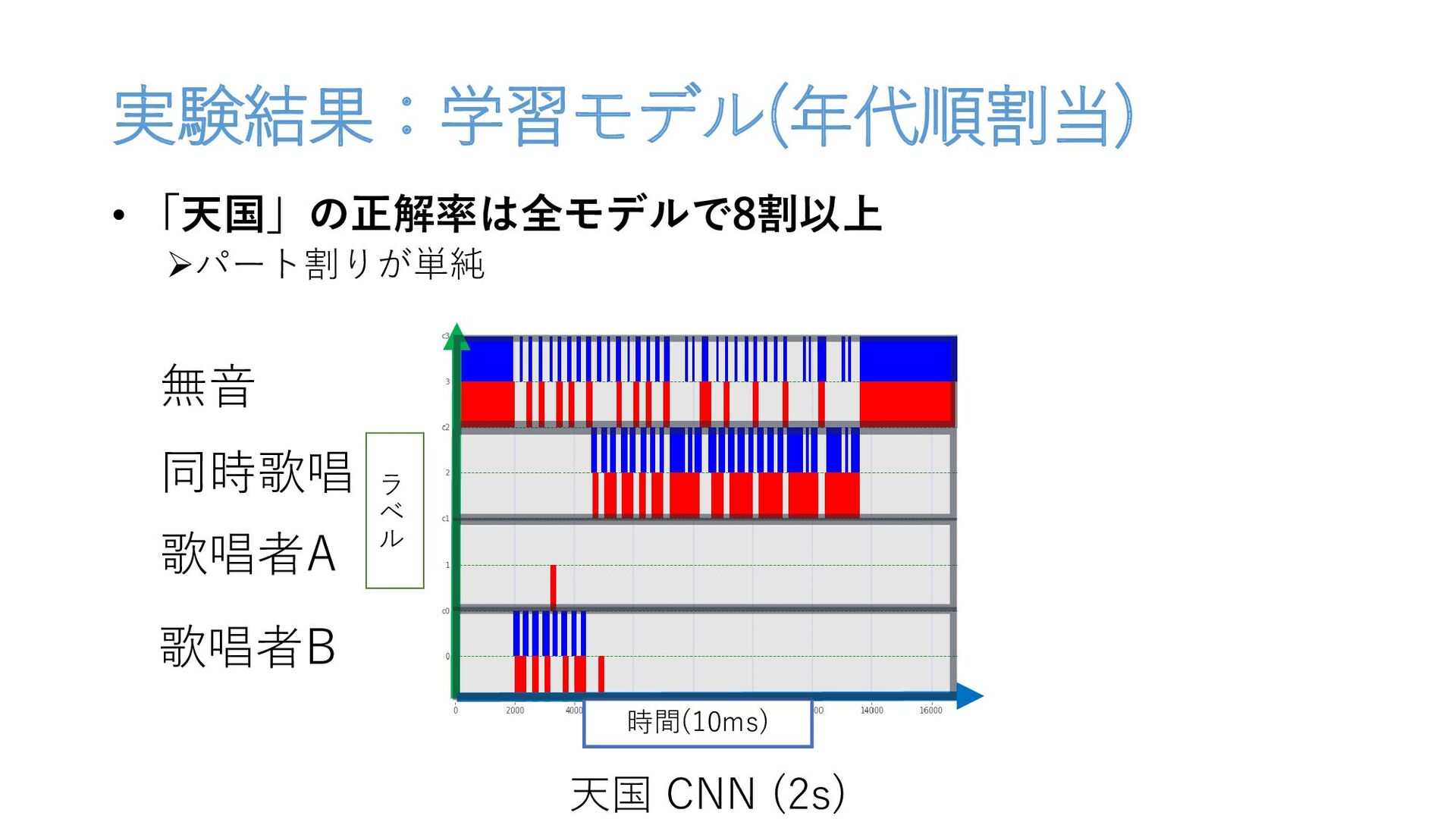
実験結果:学習モデル(年代順割当) • 「天国」の正解率は全モデルで8割以上 パート割りが単純 天国 CNN (2s) 時間(10ms) ラ ベ
ル r 無音 同時歌唱 歌唱者A 歌唱者B
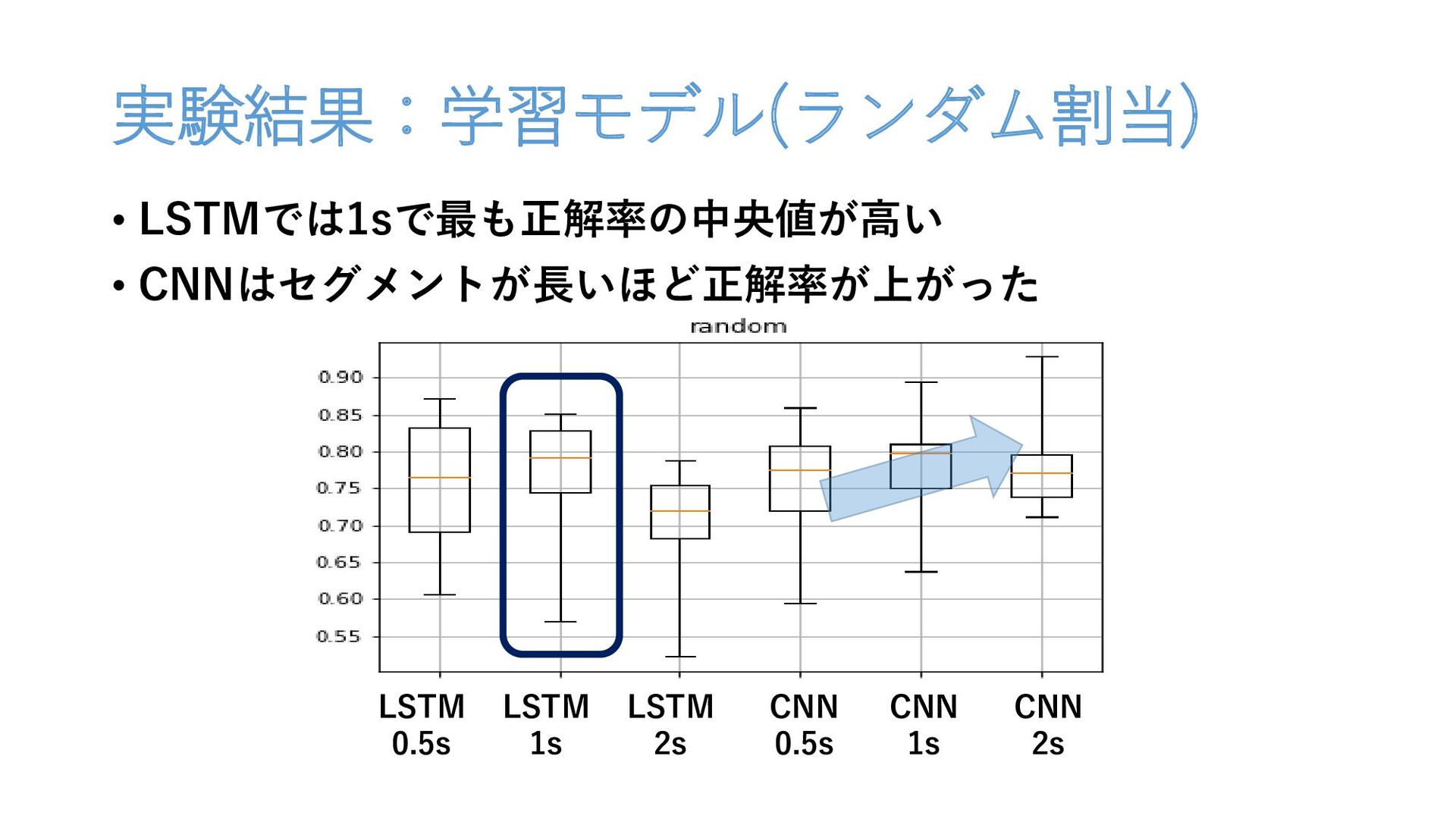
実験結果:学習モデル(ランダム割当) • LSTMでは1sで最も正解率の中央値が高い • CNNはセグメントが長いほど正解率が上がった LSTM 0.5s LSTM 1s LSTM
2s CNN 0.5s CNN 1s CNN 2s
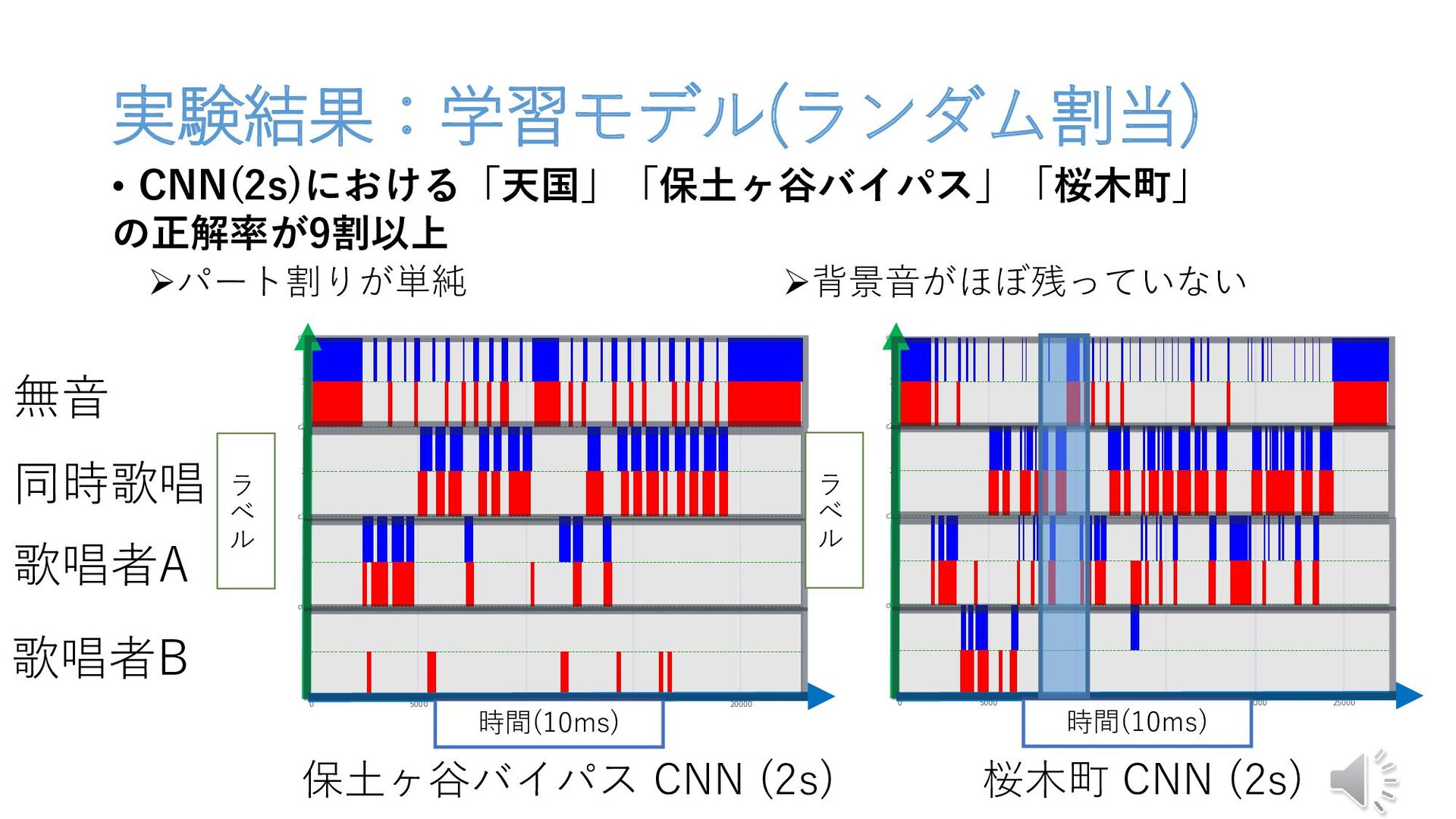
実験結果:学習モデル(ランダム割当) • CNN(2s)における「天国」「保土ヶ谷バイパス」「桜木町」 の正解率が9割以上 桜木町 CNN (2s) 保土ヶ谷バイパス CNN (2s)
時間(10ms) ラ ベ ル r 無音 同時歌唱 歌唱者A 歌唱者B パート割りが単純 背景音がほぼ残っていない 時間(10ms) ラ ベ ル r
結論 • 背景音除去の精度が識別精度にかかわっている • 使用モデルによって精度の上がるセグメント長が異なる これから • 識別結果の平滑化 • 推定されたパート割を見ながら楽曲鑑賞するアプリの開発
ご清聴 ありがとうございました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}