user_id = ‘kabata’ Index Scan using user_table_pkey on user_table (cost=0.43..8.46 rows=1 width=70) (actual time=0.031..0.139 rows=115 loops=1) Index Cond: (((company_id)::text = 'sansan'::text) AND ((user_id)::text = 'kabata'::text))
ON (c.oid = s.starelid) JOIN pg_attribute a ON (c.oid = attrelid AND attnum = s.staattnum) LEFT JOIN pg_namespace n ON (n.oid = c.relnamespace) WHERE relname = ‘user_table’ AND attname = ‘user_id’ AND stakind1 = 1;
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![サンプル数を上げてみる 実行時間[ms]](https://files.speakerdeck.com/presentations/740dd7a7ca124dfbb6e0efdacc73093e/slide_6.jpg){kind=link}
![サンプル数を上げてみる 実行時間[ms] っ ょ ぃ。](https://files.speakerdeck.com/presentations/740dd7a7ca124dfbb6e0efdacc73093e/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
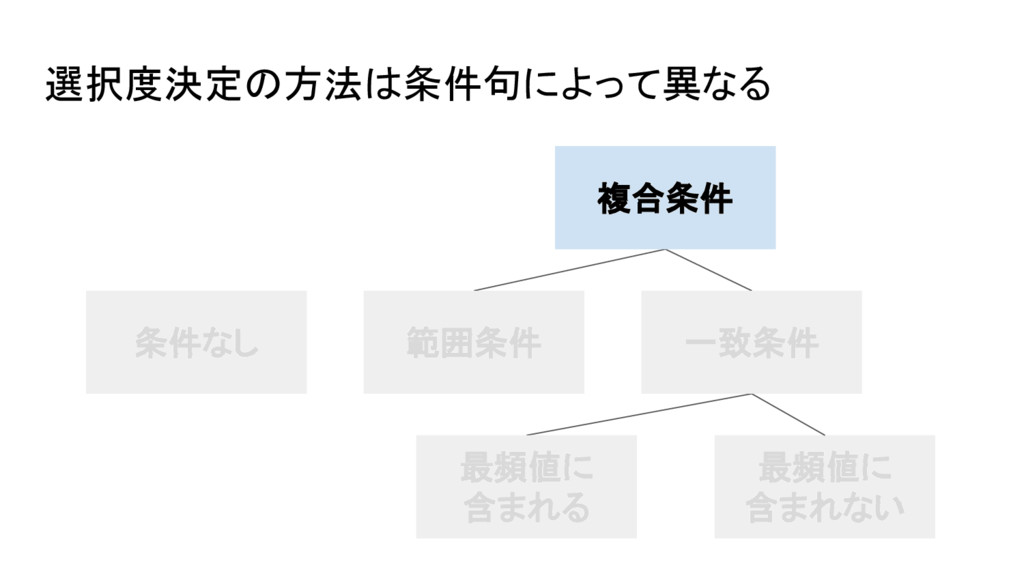{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}