Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
論文紹介 CLIP, LLaVA, Penguin-VL
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
kyad
March 14, 2026
Technology
17
0
Share
論文紹介 CLIP, LLaVA, Penguin-VL
kyad
March 14, 2026
More Decks by kyad
See All by kyad
論文紹介 mHC
kyad
0
26
論文紹介 Attention Residuals
kyad
0
11
Other Decks in Technology
See All in Technology
Diagnosing performance problems without the guesswork
elenatanasoiu
0
130
GitHub Copilot CLIでWebアクセシビリティを改善した話
tomokusaba
0
140
Unlocking the Apps
pimterry
0
140
AI Adaptable なテストを整える工夫 / Ways to Make Your Tests AI-Adaptable
bitkey
PRO
2
190
Platform Engineering as a Product: Criteria for Improvement and Multi-Tenant Design
kumorn5s
0
440
oracle-to-databricks-migration-with-llm-and-dbt
casek
1
390
Javaで学ぶSOLID原則
negima
1
250
Java正規表現エンジン(NFA)の仕組みと パフォーマンスを維持するための最適化手法
takeuchi_132917
0
160
インフラが苦手でも大丈夫! 紙芝居 Kubernetes -WWGT 10周年編-
aoi1
1
310
組織の中で自分を経営する技術
shoota
0
230
Datadog 認定試験の概要と対策
uechishingo
0
210
APIテストとは?
nagix
0
160
Featured
See All Featured
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
2k
Being A Developer After 40
akosma
91
590k
So, you think you're a good person
axbom
PRO
2
2k
Into the Great Unknown - MozCon
thekraken
41
2.5k
Optimising Largest Contentful Paint
csswizardry
37
3.7k
Designing Experiences People Love
moore
143
24k
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
580
Crafting Experiences
bethany
1
160
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
2.9k
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
231
23k
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.2k
Transcript
論文紹介 CLIP, LLaVA, Penguin-VL @kyad 2026/3/14 本資料中の図は論文から引用しています
CLIP •書誌情報 [2103.00020] Learning Transferable Visual Models From Natural Language
Supervision 研究機関:OpenAI •何をするもの? 画像とテキストを同じ埋め込み空間に対応付けるように学習させる仕組み Contrastive Language-Image Pre-training
CLIP •アーキテクチャ ResNetやViTなど ViT-L/14がベスト GPT-2のデコーダのみのTransformer [EOS]に対する特徴ベクトルが使われる 長さが合うように 重み行列をかける 長さが合うように 重み行列をかける
Nはデータ数 (32768) 1番目のテキストの 特徴ベクトル 1番目の画像の 特徴ベクトル •学習疑似コード T達とI達のそれぞれの内積が 単位行列になるように学習 ⇒ 学習してできたText Encoderや Image Encoderは、 良い特徴量抽出器になっている
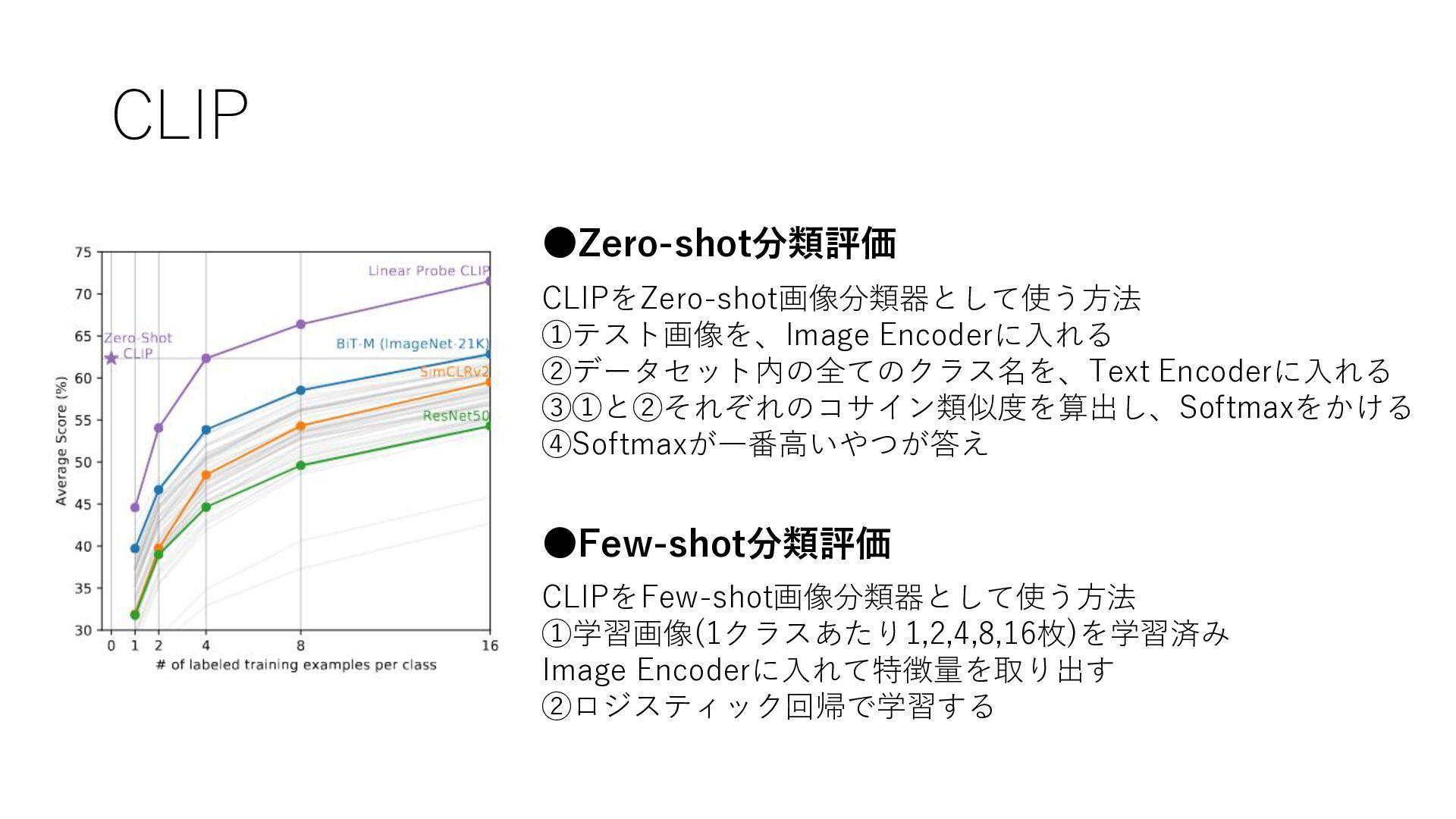
CLIP •Few-shot分類評価 CLIPをFew-shot画像分類器として使う方法 ①学習画像(1クラスあたり1,2,4,8,16枚)を学習済み Image Encoderに入れて特徴量を取り出す ②ロジスティック回帰で学習する •Zero-shot分類評価 CLIPをZero-shot画像分類器として使う方法 ①テスト画像を、Image
Encoderに入れる ②データセット内の全てのクラス名を、Text Encoderに入れる ③①と②それぞれのコサイン類似度を算出し、Softmaxをかける ④Softmaxが一番高いやつが答え
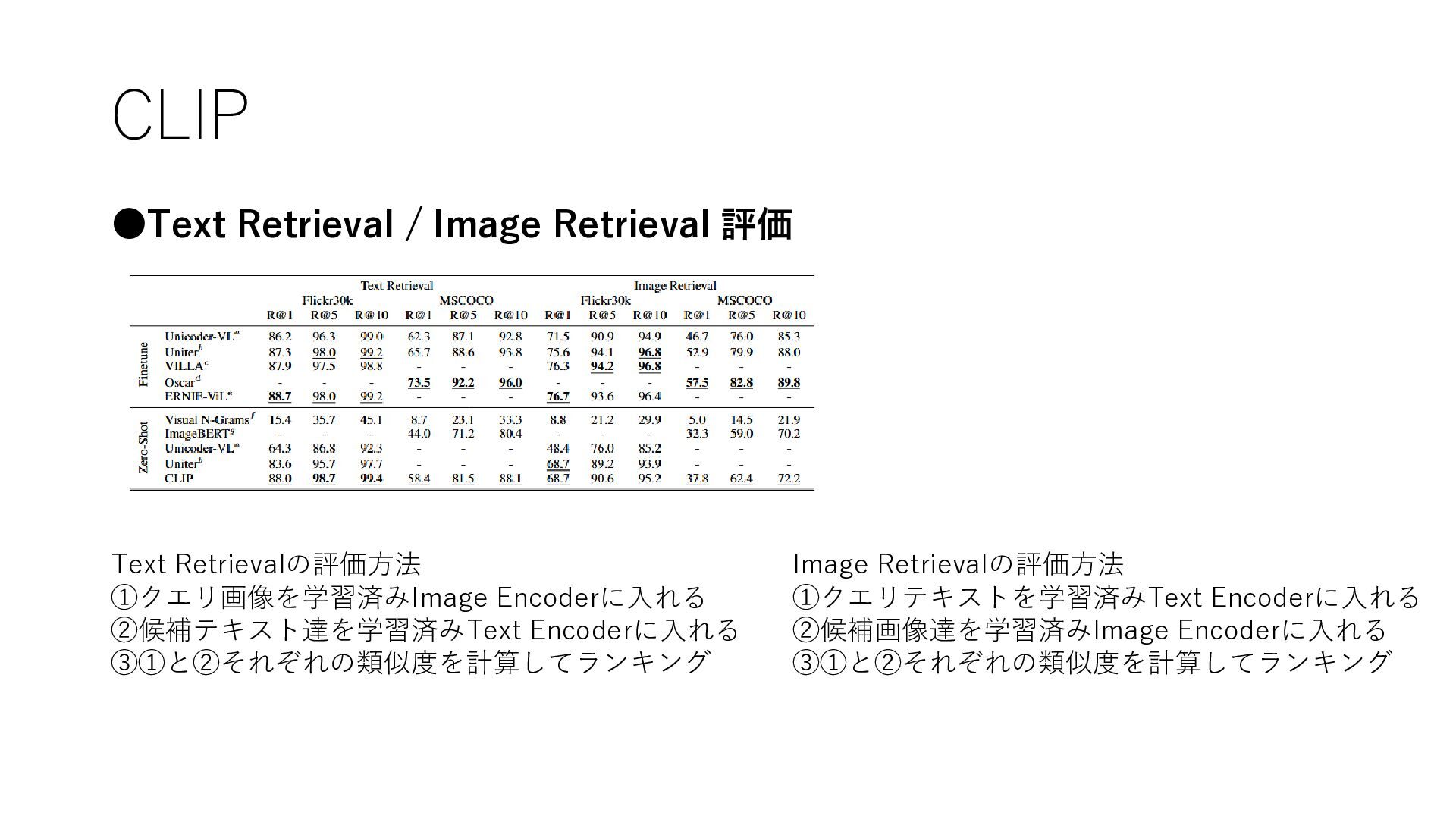
CLIP •Text Retrieval / Image Retrieval 評価 Text Retrievalの評価方法 ①クエリ画像を学習済みImage
Encoderに入れる ②候補テキスト達を学習済みText Encoderに入れる ③①と②それぞれの類似度を計算してランキング Image Retrievalの評価方法 ①クエリテキストを学習済みText Encoderに入れる ②候補画像達を学習済みImage Encoderに入れる ③①と②それぞれの類似度を計算してランキング
LLaVA •書誌情報 [2304.08485] Visual Instruction Tuning 研究機関:Microsoft •何をするもの? LLMで画像とテキストのマルチモーダル学習するシンプルな方法 強力なマルチモーダルチャット機能を実現
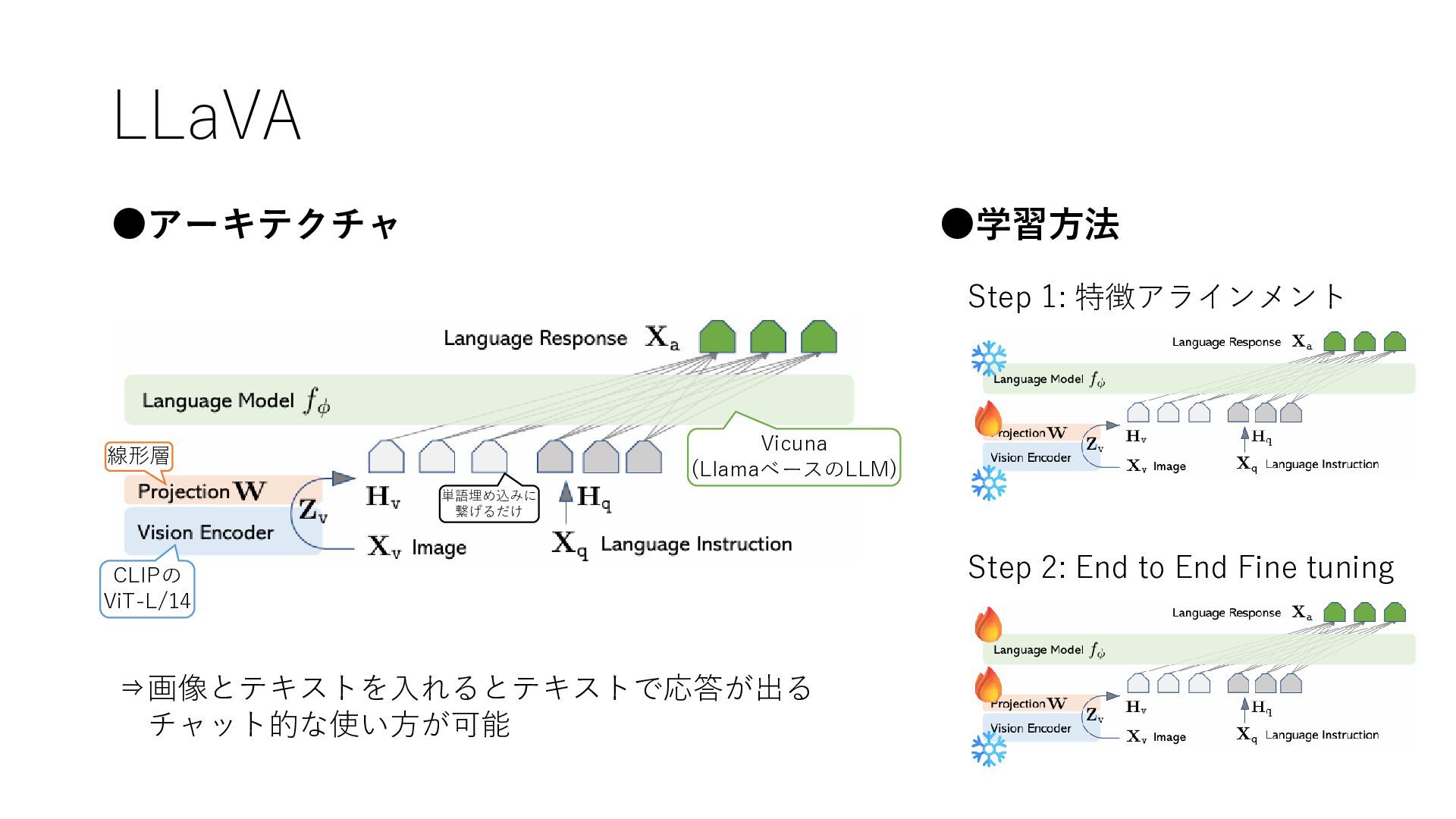
LLaVA •アーキテクチャ CLIPの ViT-L/14 Vicuna (LlamaベースのLLM) 線形層 単語埋め込みに 繋げるだけ •学習方法
Step 1: 特徴アラインメント Step 2: End to End Fine tuning ⇒画像とテキストを入れるとテキストで応答が出る チャット的な使い方が可能
LLaVA •データ CLIP: 画像とキャプションを学習するのみ LLaVa: ①会話②詳細説明③複雑な推論を 学習させる 学習データは、COCOの①キャプションと ②Bounding boxのみからGPT-4で生成(画
像はGPT-4に入れていない)
LLaVA LLaVAは、画像の説明をするのみならず、理由も 含めて説明できている点が従来の方法と異なる •マルチモーダルチャット評価
Penguin-VL •書誌情報 [2603.06569] Penguin-VL: Exploring the Efficiency Limits of VLM
with LLM-based Vision Encoders 研究機関:Tencent プロジェクトページ:Penguin-VL •何をするもの? CLIPベースの画像エンコーダを使わないVLM
Penguin-VL •課題 従来のVLMは、CLIP等のcontrastive learning事前学習モデルベースのものが多かった しかし、これらは分類ベースの事前学習のため、細かい粒度の情報を欠落させるように学習 してしまう課題がある また、VLMモデルは一般的に重く、軽量モデルが無い課題がある ⇒ Penguin-VLでは、 contrastive
learningベースの モデルを使わずに、LLMに入 れるVision Encoderを学習する
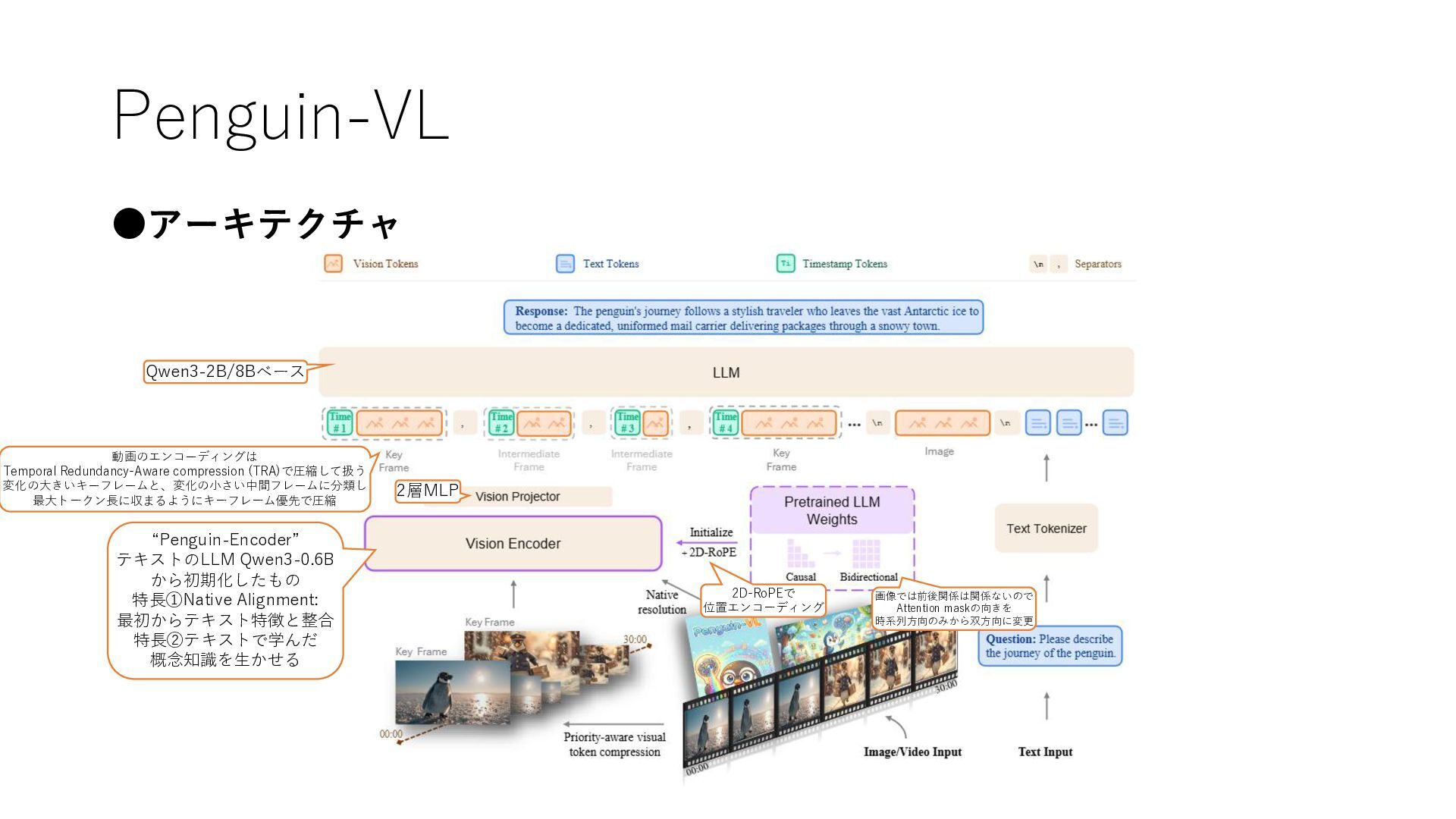
Penguin-VL •アーキテクチャ “Penguin-Encoder” テキストのLLM Qwen3-0.6B から初期化したもの 特長①Native Alignment: 最初からテキスト特徴と整合 特長②テキストで学んだ
概念知識を生かせる 画像では前後関係は関係ないので Attention maskの向きを 時系列方向のみから双方向に変更 2D-RoPEで 位置エンコーディング 動画のエンコーディングは Temporal Redundancy-Aware compression (TRA)で圧縮して扱う 変化の大きいキーフレームと、変化の小さい中間フレームに分類し 最大トークン長に収まるようにキーフレーム優先で圧縮 Qwen3-2B/8Bベース 2層MLP
Penguin-VL •2D-RoPE 1次元RoPE [2104.09864] RoFormer: Enhanced Transformer with Rotary Position
Embedding 苏剑林. (May. 10, 2021). 《Transformer升级之路:4、二维位置的旋转式位置编码 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/8397 2次元RoPE
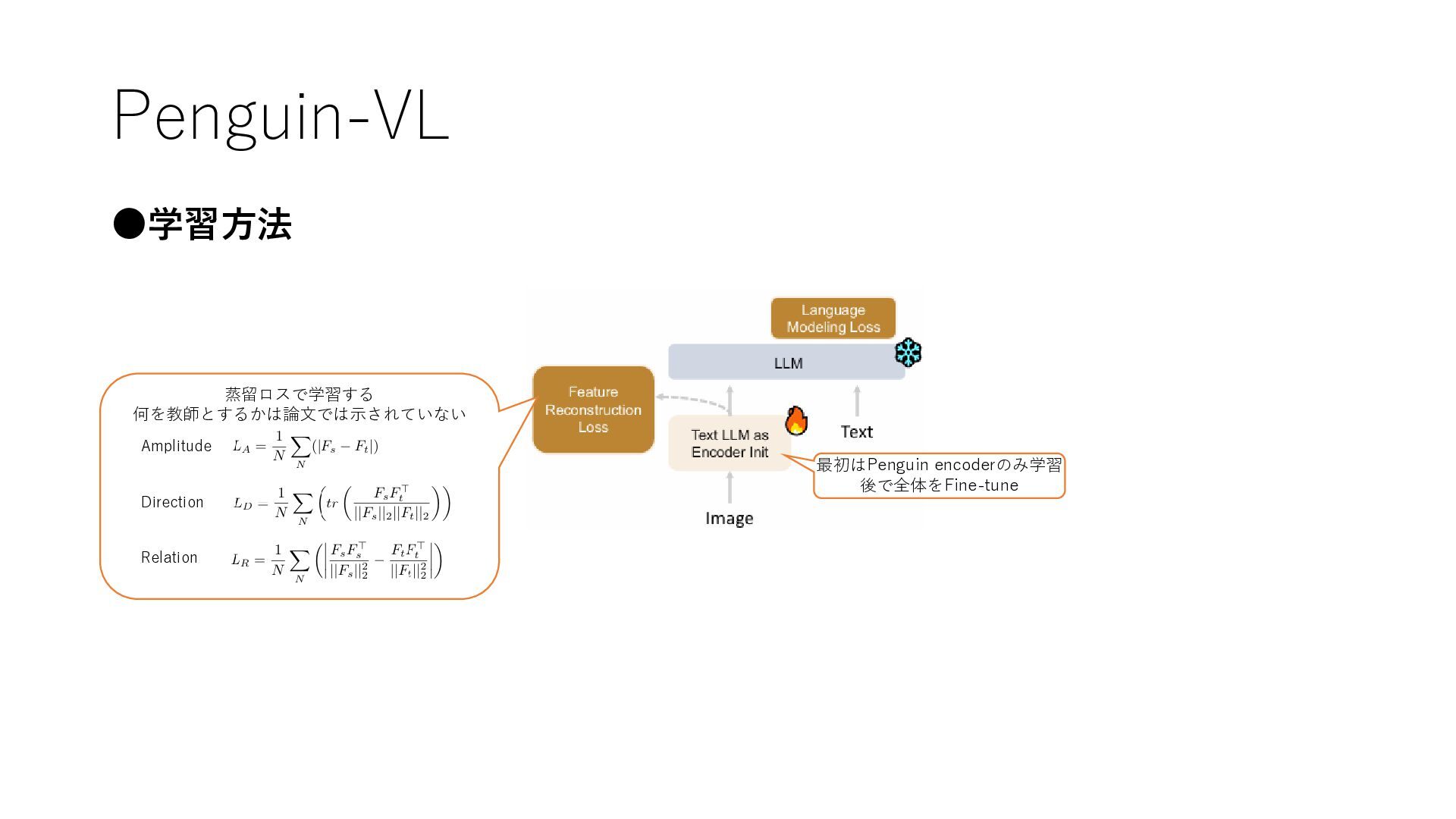
Penguin-VL •学習方法 最初はPenguin encoderのみ学習 後で全体をFine-tune 蒸留ロスで学習する 何を教師とするかは論文では示されていない Amplitude Direction Relation
Penguin-VL •データセット(画像とテキスト) まず、画像に対して項目ごとに アノテーション付与する その後、視覚的特徴、空間的関係、 OCRで認識可能なテキストを含む 長文のアノテーションを付与する
Penguin-VL •データセット(動画とテキスト) 動画に対しては、複数の時間粒度で 説明文を付与 さらに、複数の画像から正しい順序を 推定させる問題と、特定の行動から タイムスタンプを答えさせるQAデータ を作成
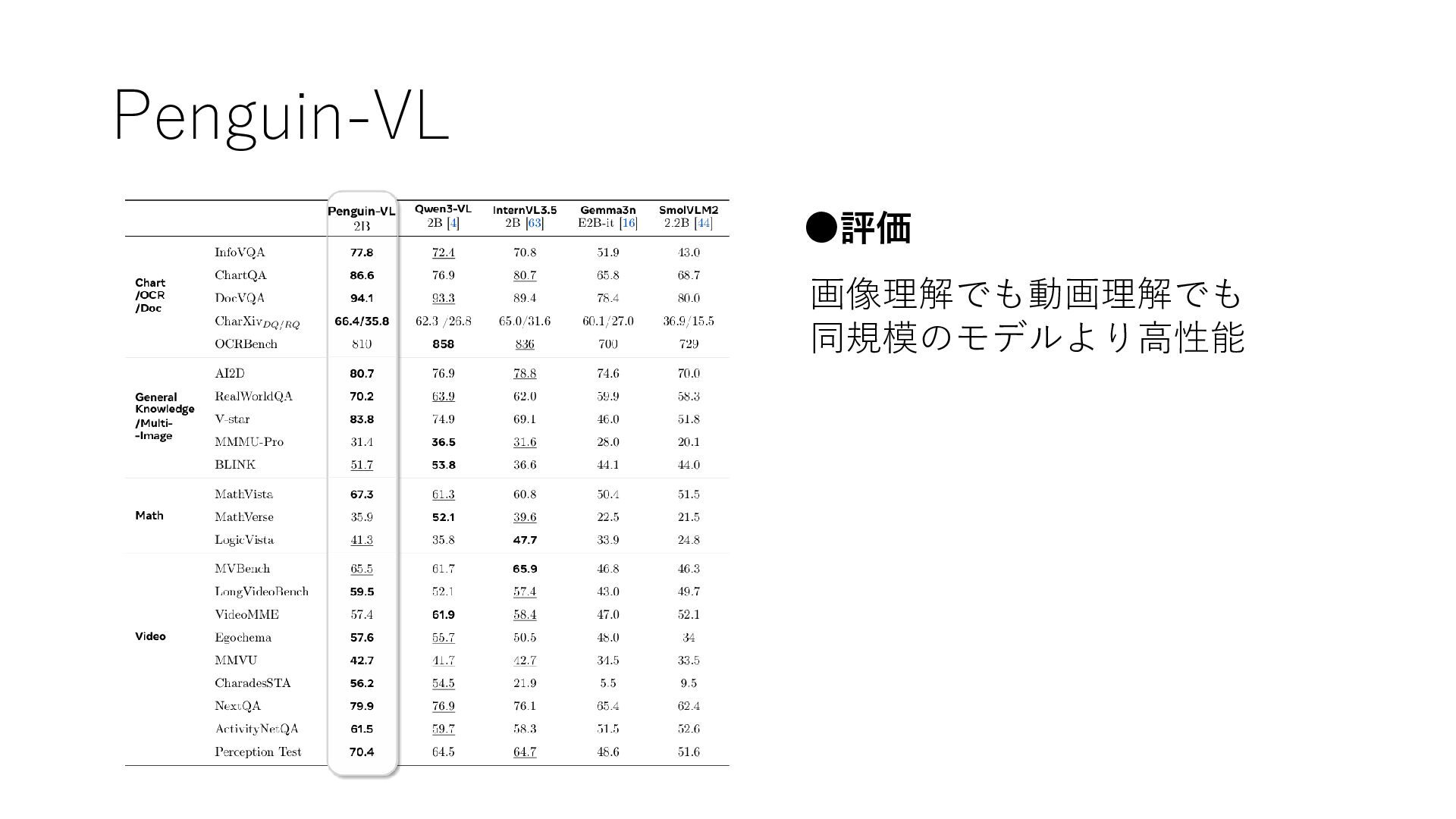
Penguin-VL •評価 画像理解でも動画理解でも 同規模のモデルより高性能
参考文献 • VLM視覚言語モデルの歴史整理(2025年9月まで) • alphaXiv
{kind=link}
![CLIP •書誌情報 [2103.00020] Learning Transferable Visual Models From Natural Language](https://files.speakerdeck.com/presentations/09730b32502e473e8da28a0e58642c37/slide_1.jpg){kind=link}
![CLIP •アーキテクチャ ResNetやViTなど ViT-L/14がベスト GPT-2のデコーダのみのTransformer [EOS]に対する特徴ベクトルが使われる 長さが合うように 重み行列をかける 長さが合うように 重み行列をかける](https://files.speakerdeck.com/presentations/09730b32502e473e8da28a0e58642c37/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
![LLaVA •書誌情報 [2304.08485] Visual Instruction Tuning 研究機関:Microsoft •何をするもの? LLMで画像とテキストのマルチモーダル学習するシンプルな方法 強力なマルチモーダルチャット機能を実現](https://files.speakerdeck.com/presentations/09730b32502e473e8da28a0e58642c37/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Penguin-VL •書誌情報 [2603.06569] Penguin-VL: Exploring the Efficiency Limits of VLM](https://files.speakerdeck.com/presentations/09730b32502e473e8da28a0e58642c37/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
![Penguin-VL •2D-RoPE 1次元RoPE [2104.09864] RoFormer: Enhanced Transformer with Rotary Position](https://files.speakerdeck.com/presentations/09730b32502e473e8da28a0e58642c37/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}