日本ロボット学会 ロボット工学セミナー 第119回 原理から学ぶロボットのための画像処理技術での以下の講演スライドのうち,初学者向け内容を取り出したものです
---
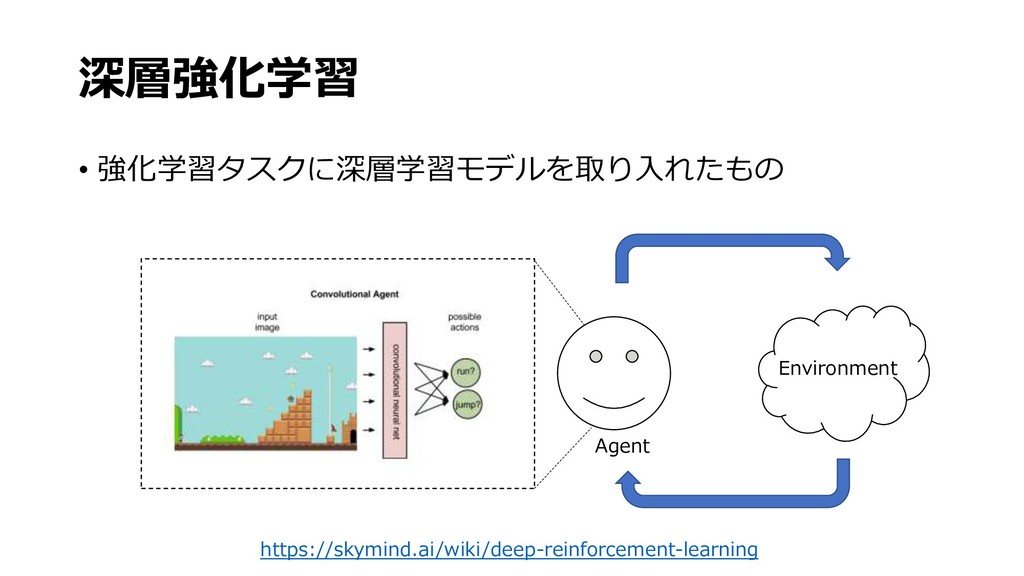
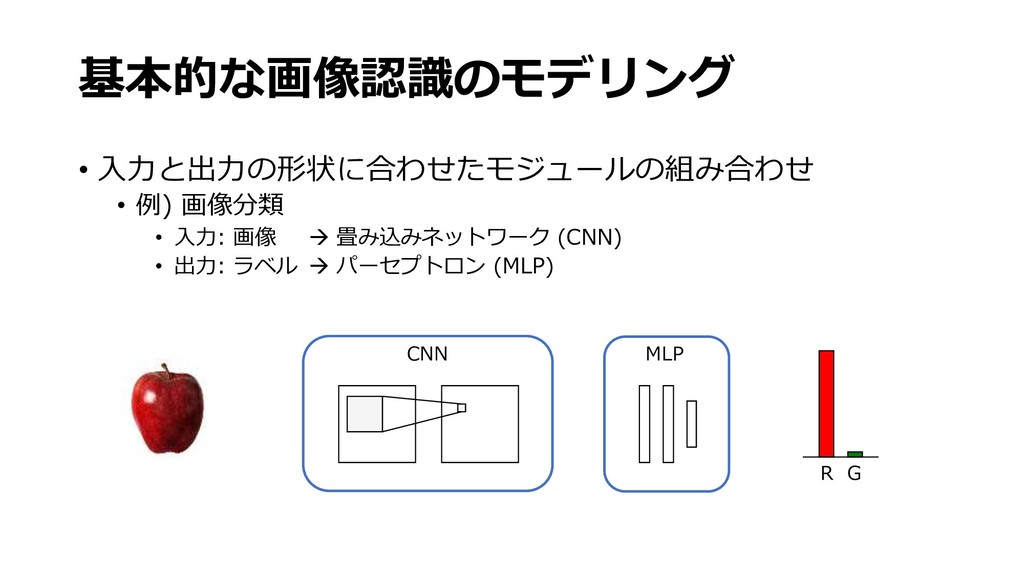
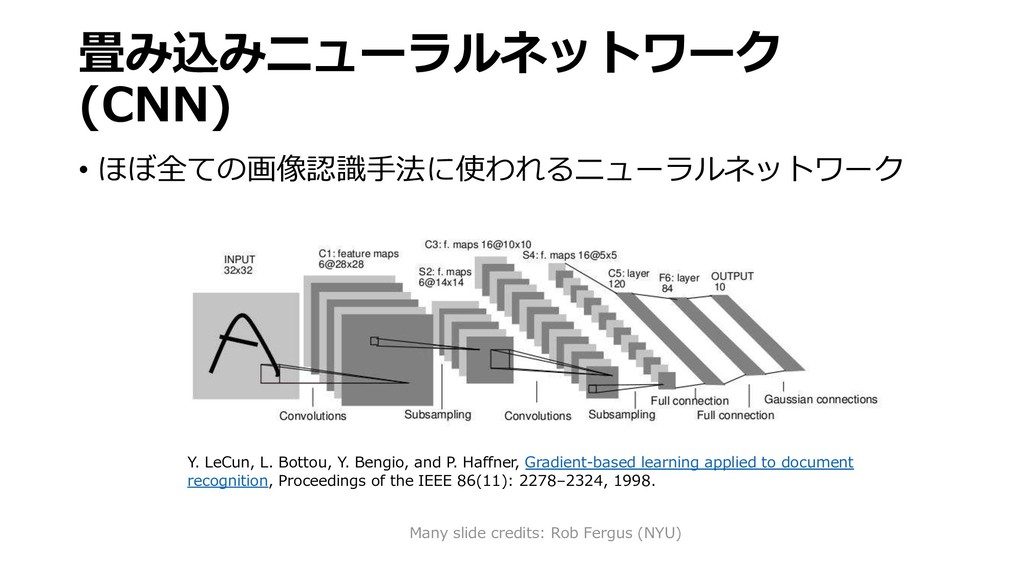
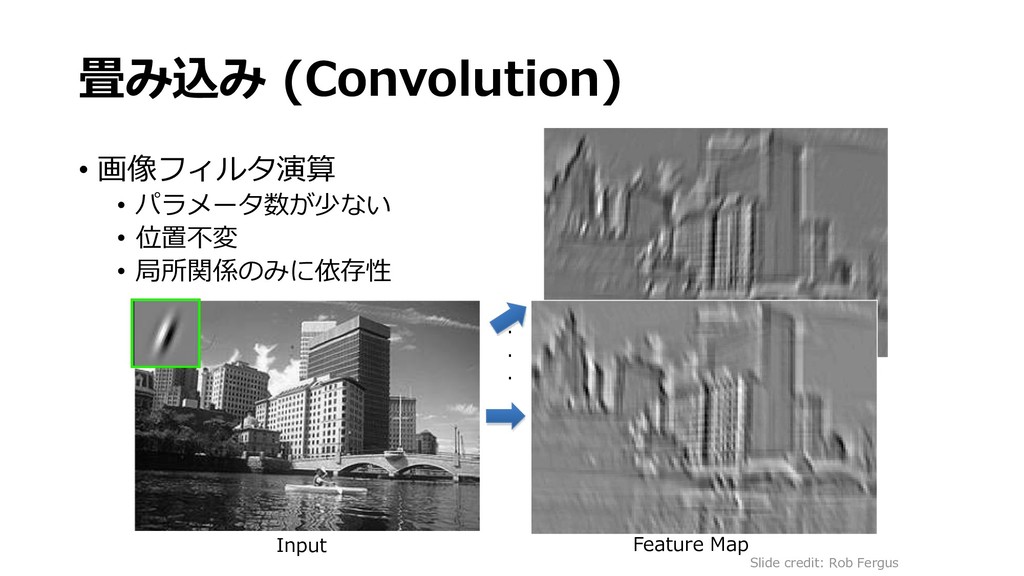
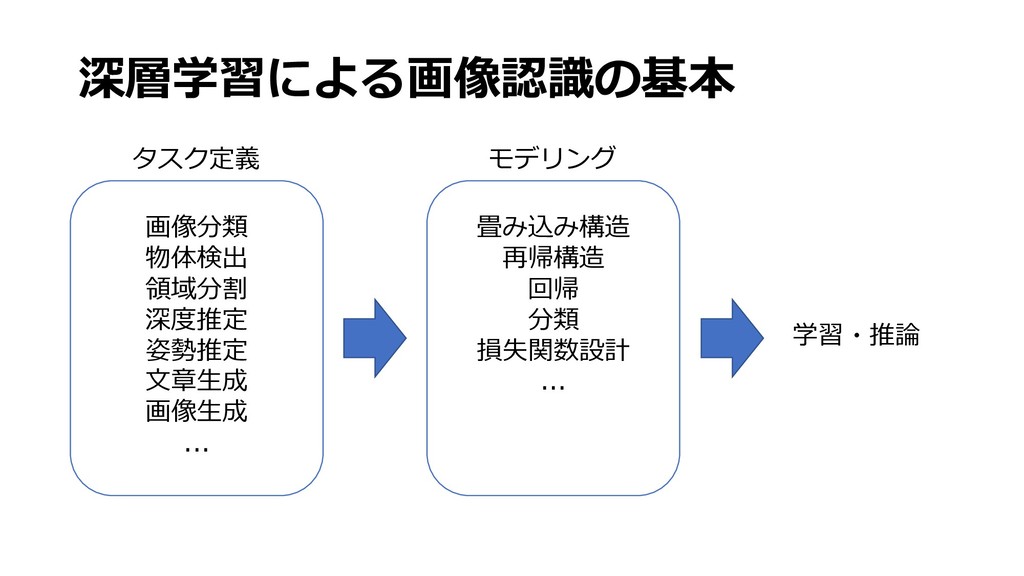
深層学習による画像認識の基礎と実践
https://www.rsj.or.jp/seminar/s119/
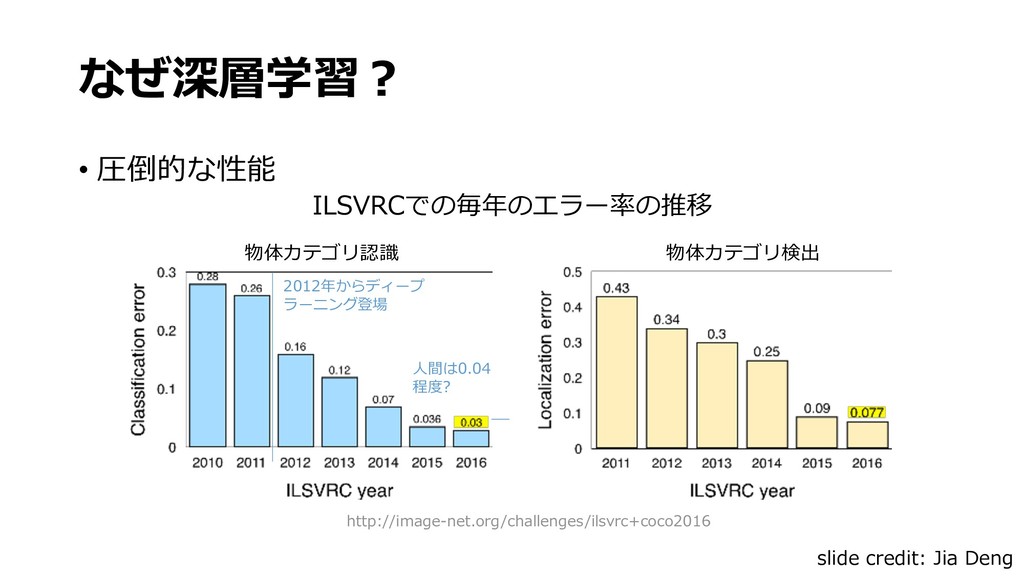
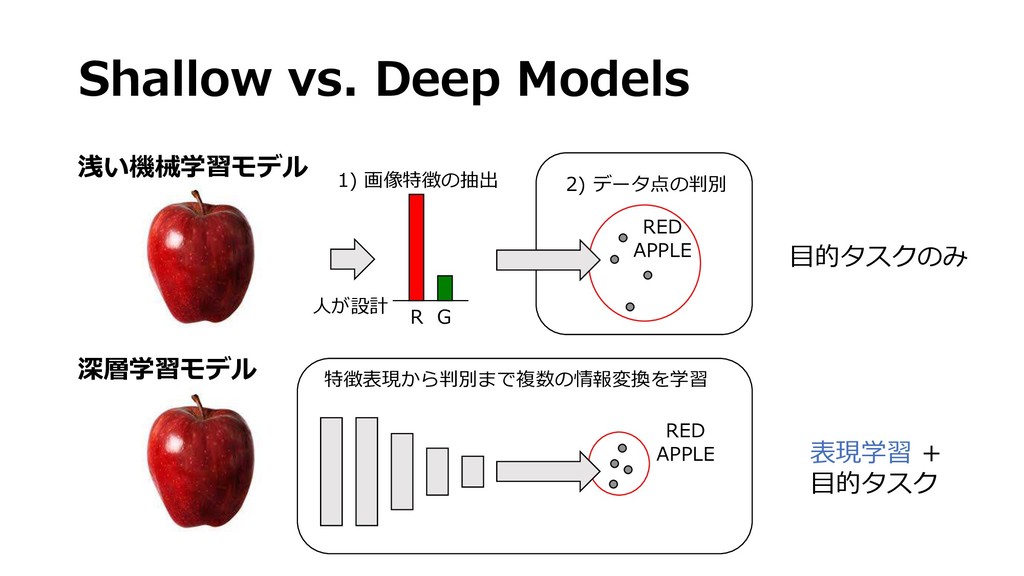
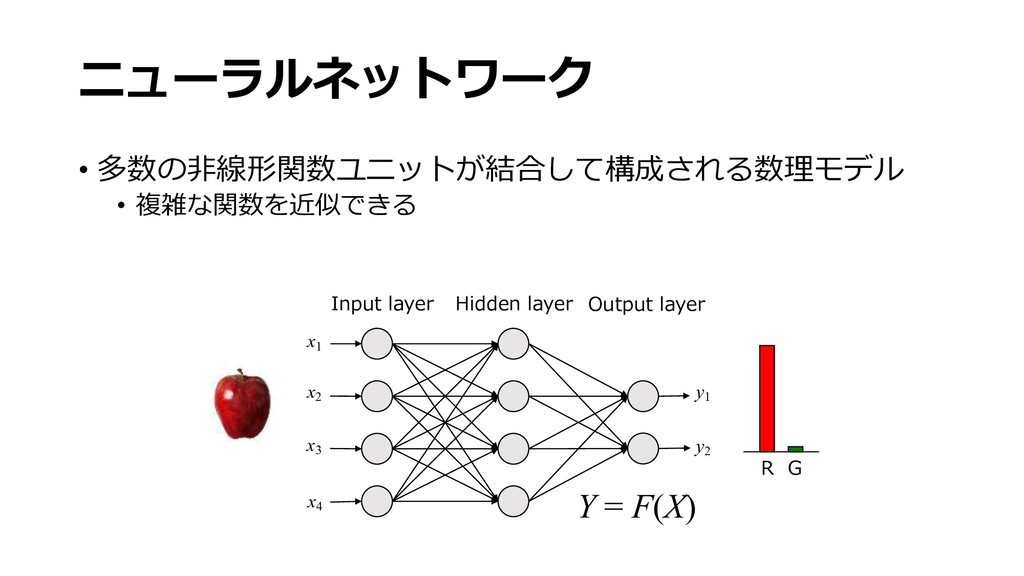
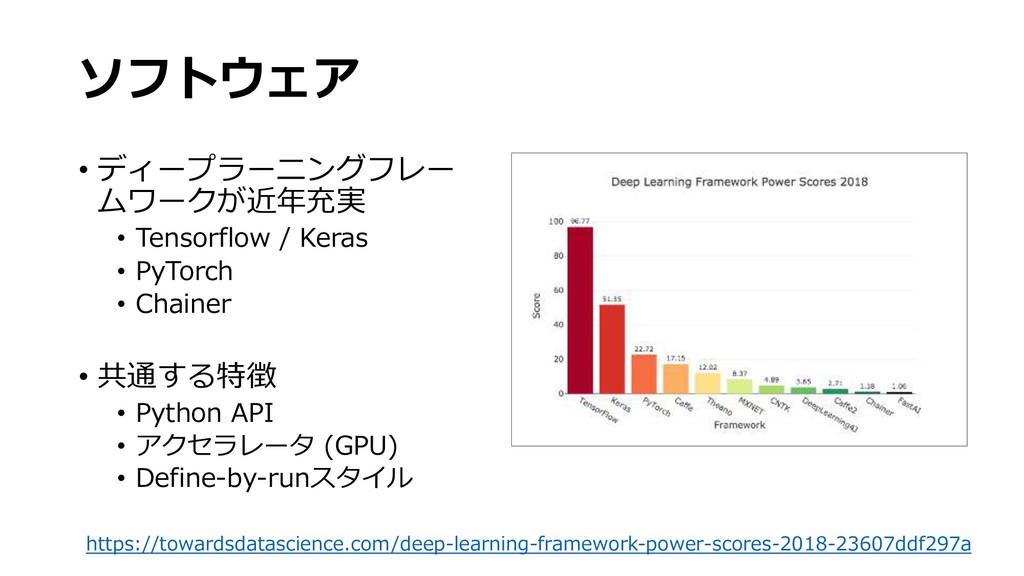
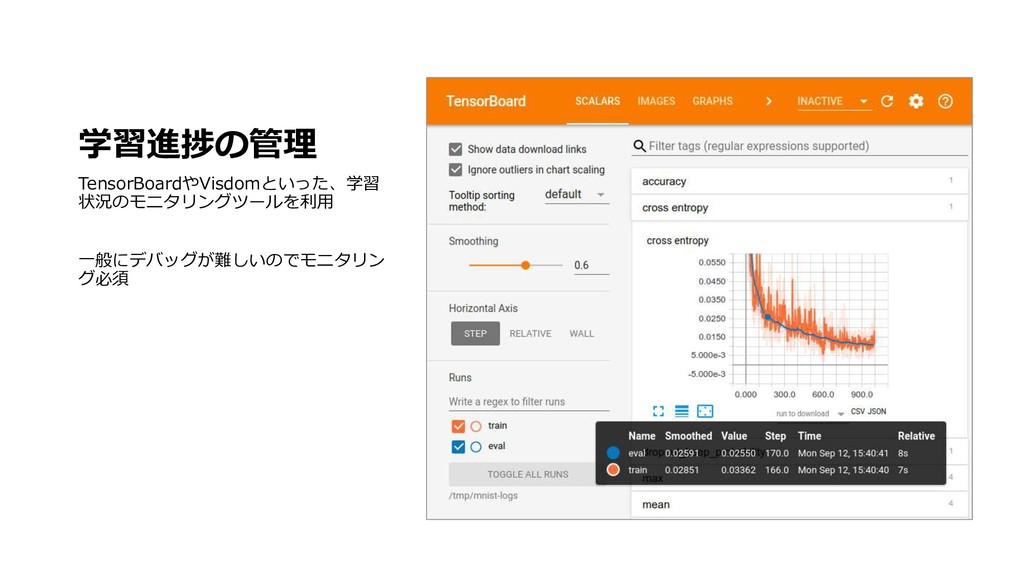
深層学習用のソフトウェアフレームワークとそれを高速に実行するハードウェアが一般的になるにつれ,高性能な画像認識アプリケーションを手軽に実装することが可能となってきました.ツールの使い方は洗練されてきたものの,深層学習モデルは中身を解釈することが難しく,初心者が実際に使うにはいくつもの落とし穴があります.この講演では初心者を対象として,深層学習の基礎となるニューラルネットワークの動作原理や学習手法,画像認識でよく使われるアーキテクチャについて一通り解説し,基礎知識の習得を目指します.また,クラス分類や回帰のような簡単な問題設定から,物体検出,セグメンテーションのように様々な画像認識の課題設定についても整理します.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
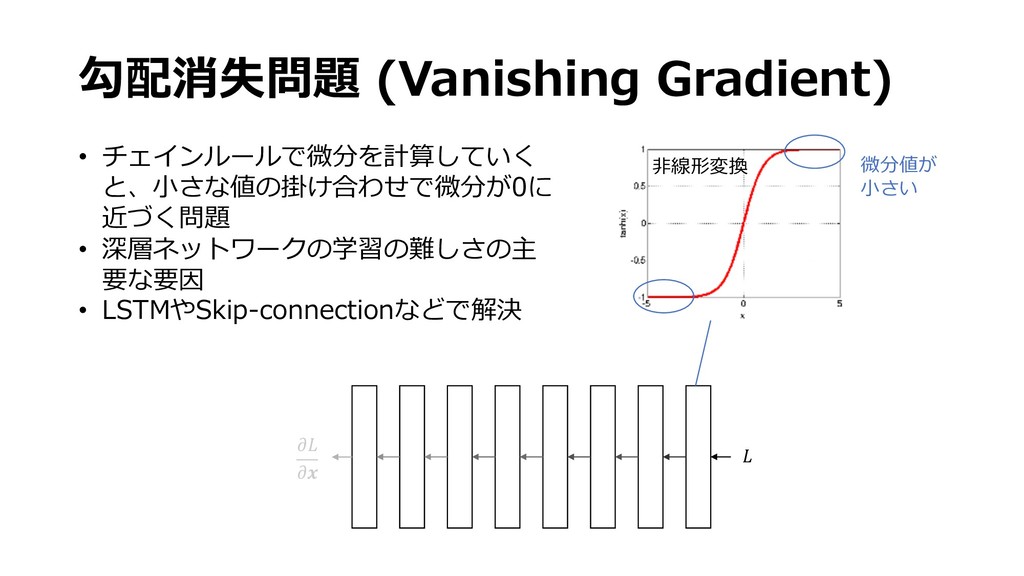{kind=link}
{kind=link}
![AlexNet • ImageNet 2012最⾼性能 • 畳み込み5層+全結合層3層 • サイズが⽐較的⼩さく、基準⼿法としてよく使われるCNN [Krizhevsky 2012]](https://files.speakerdeck.com/presentations/a8217f1ed6234f219f60d54ed22a2d02/slide_23.jpg){kind=link}
![ResNet [He 2015] http://felixlaumon.github.io/ https://culurciello.github.io/tech/2016/06/04/nets.html • ImageNet 2015最⾼性能 • Residual](https://files.speakerdeck.com/presentations/a8217f1ed6234f219f60d54ed22a2d02/slide_24.jpg){kind=link}
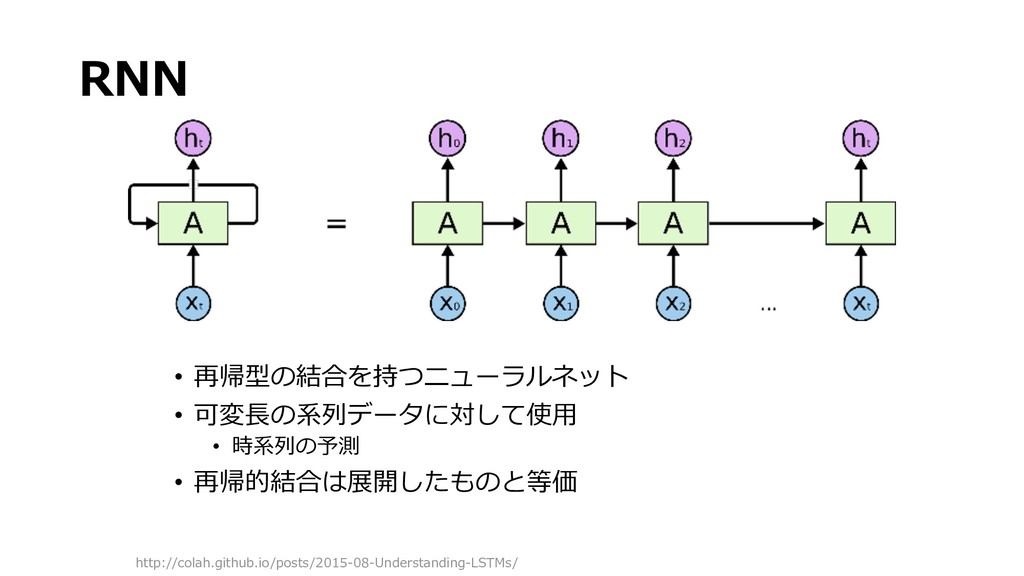{kind=link}
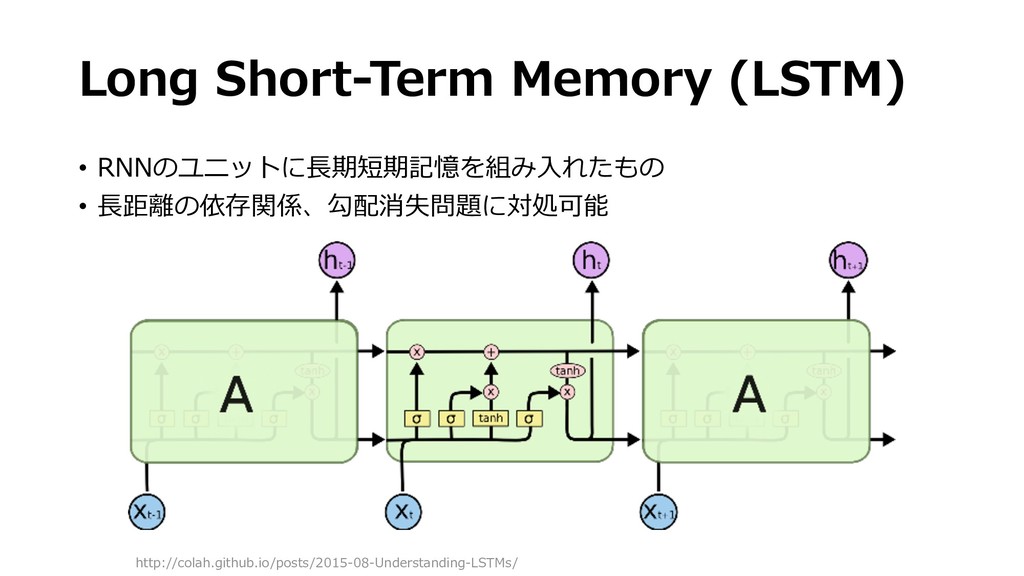{kind=link}
{kind=link}
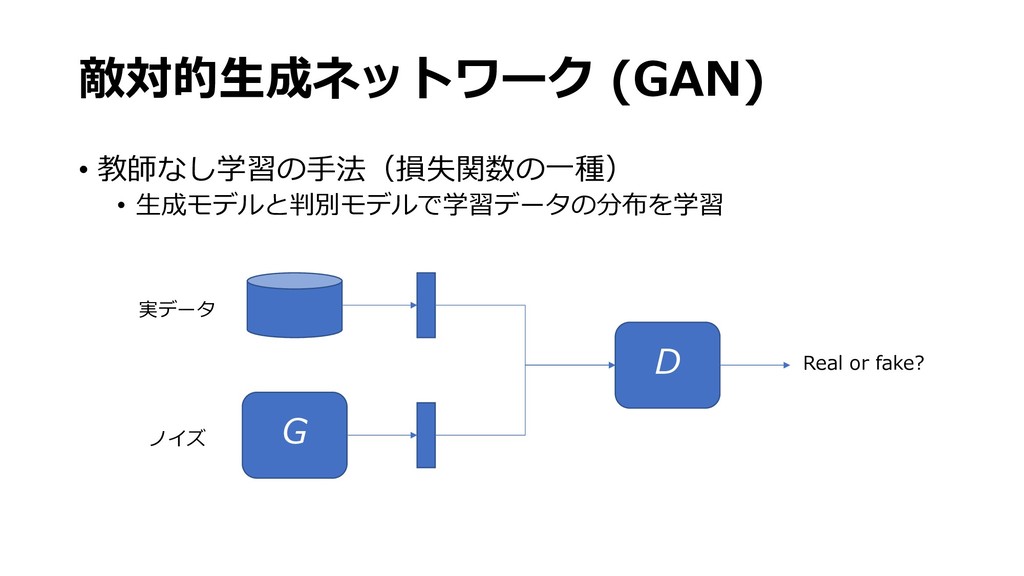{kind=link}
{kind=link}
{kind=link}
{kind=link}
![画像認識 DensePose [Gueler, 2018] skin hair bag dress jacket/blazer necklace](https://files.speakerdeck.com/presentations/a8217f1ed6234f219f60d54ed22a2d02/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![代表的なCNNアーキテクチャ • LeNet [LeCun 1998] • AlexNet [Krizhevsky 2012] •](https://files.speakerdeck.com/presentations/a8217f1ed6234f219f60d54ed22a2d02/slide_36.jpg){kind=link}
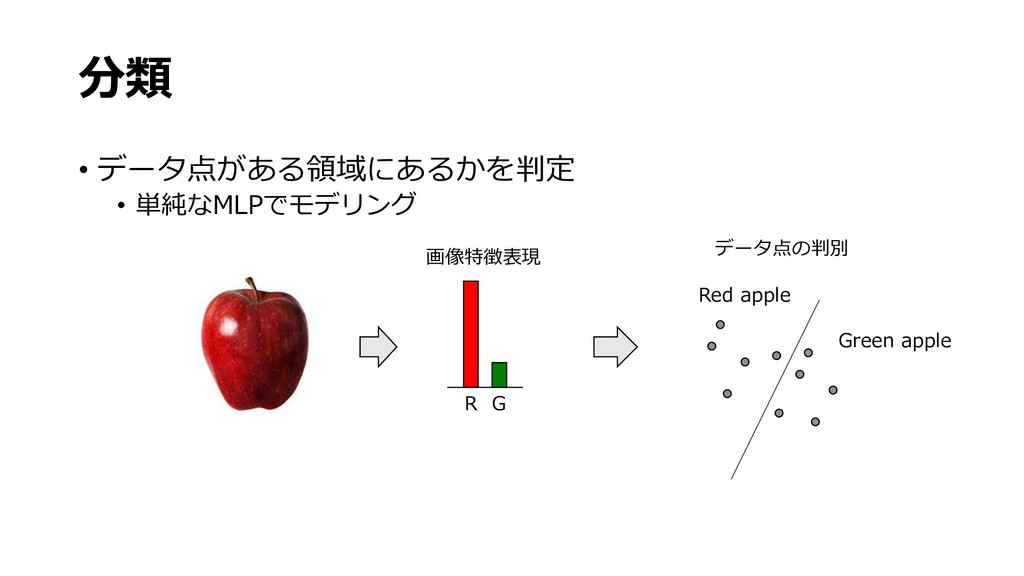{kind=link}
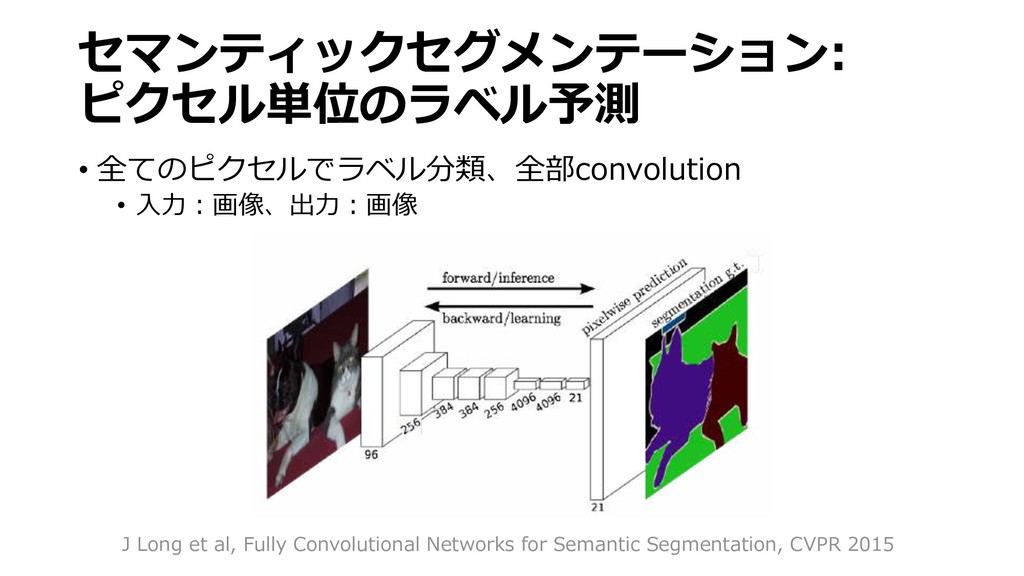{kind=link}
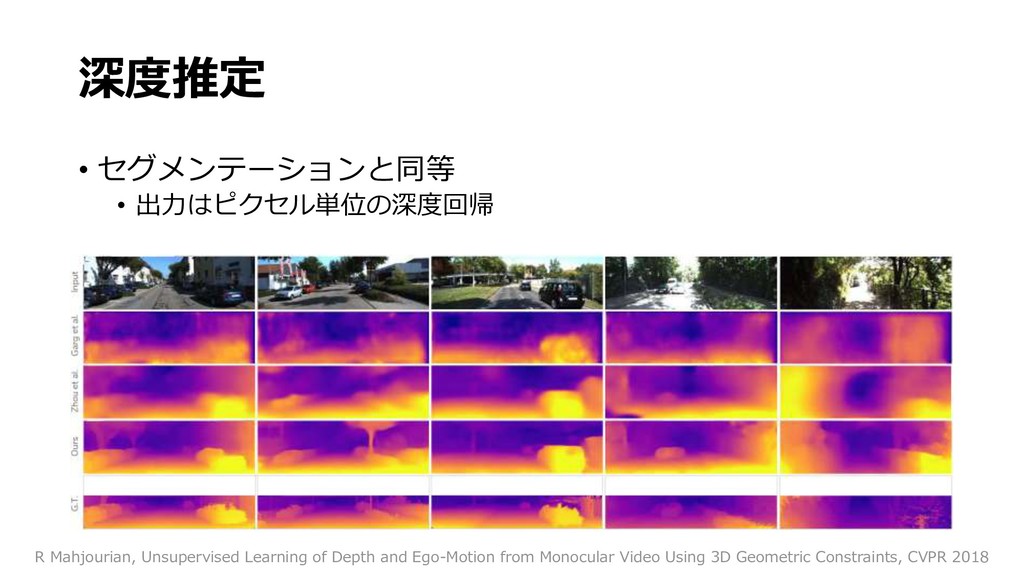{kind=link}
{kind=link}
{kind=link}
![物体検出 Mask R-CNN https://medium.com/@jonathan_hui/ebe6d793272 [He 2017] • インスタンンスセグメンテーション • RPNによる物体候補領域の検出](https://files.speakerdeck.com/presentations/a8217f1ed6234f219f60d54ed22a2d02/slide_42.jpg){kind=link}
![DensePose [Gueler 2018] http://densepose.org/ • Mask R-CNNで⾝体表⾯を対象に検出 • ピクセル単位でどの⾝体部位に属するか認識 •](https://files.speakerdeck.com/presentations/a8217f1ed6234f219f60d54ed22a2d02/slide_43.jpg){kind=link}
{kind=link}
{kind=link}
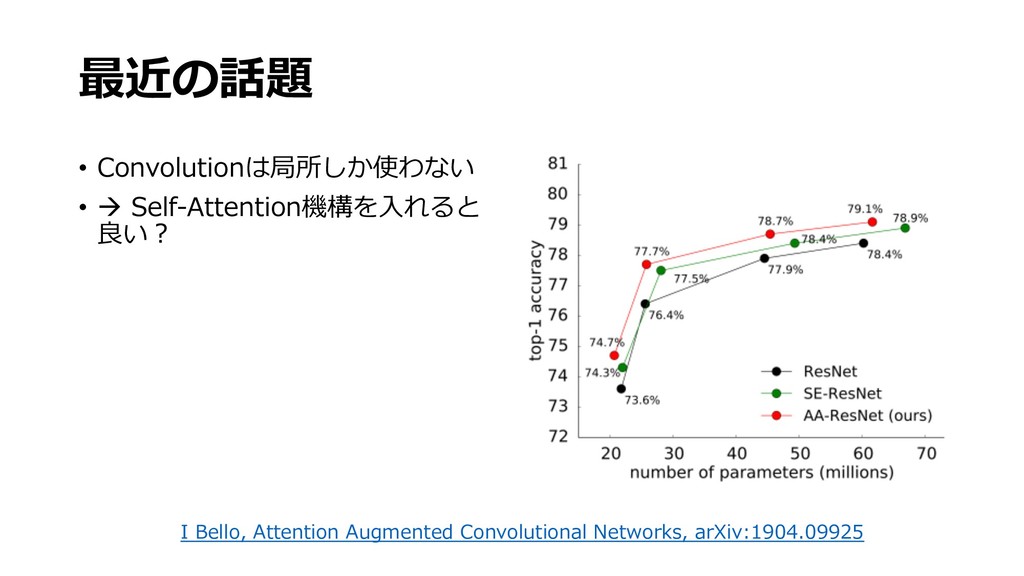{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}