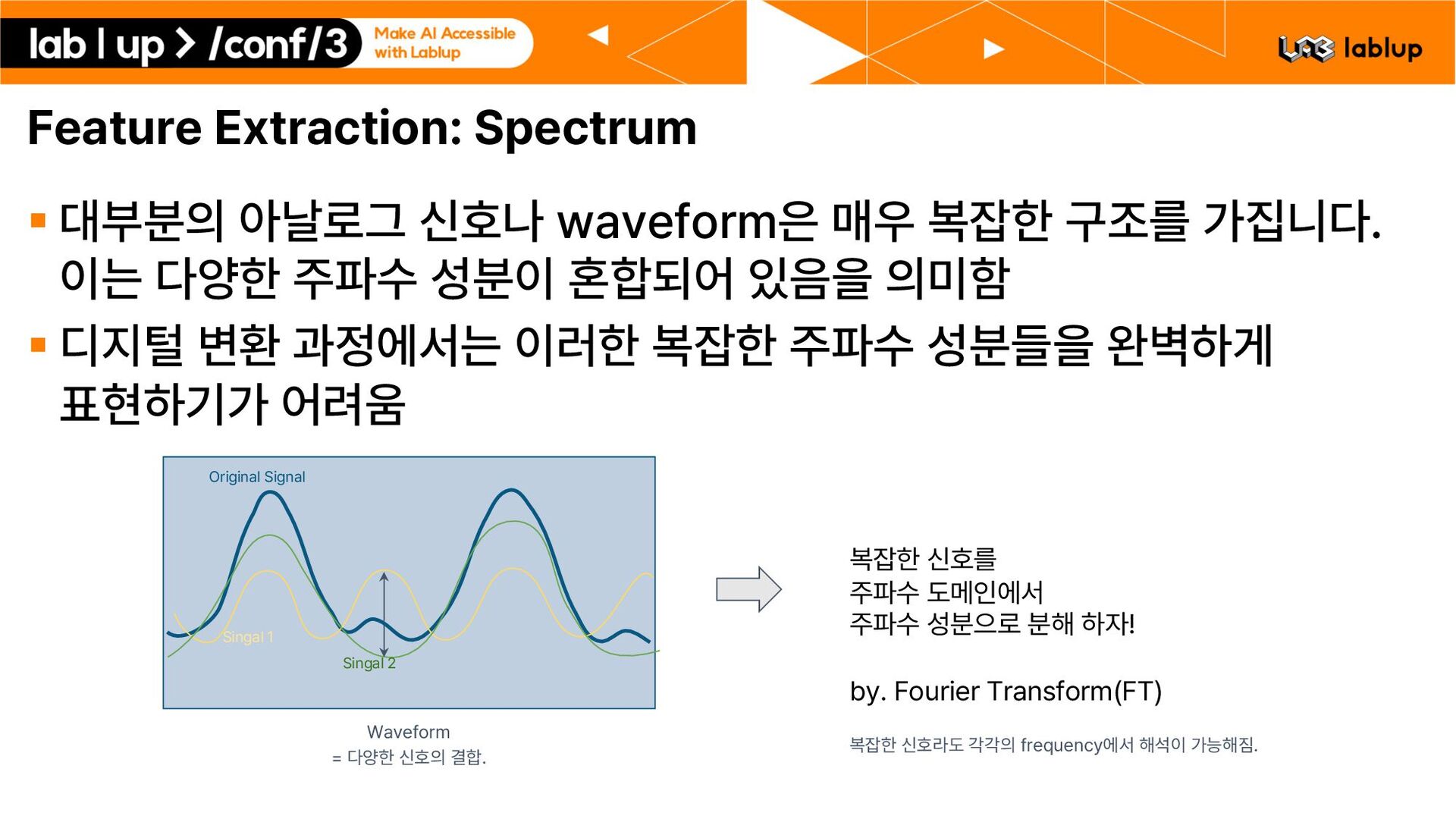
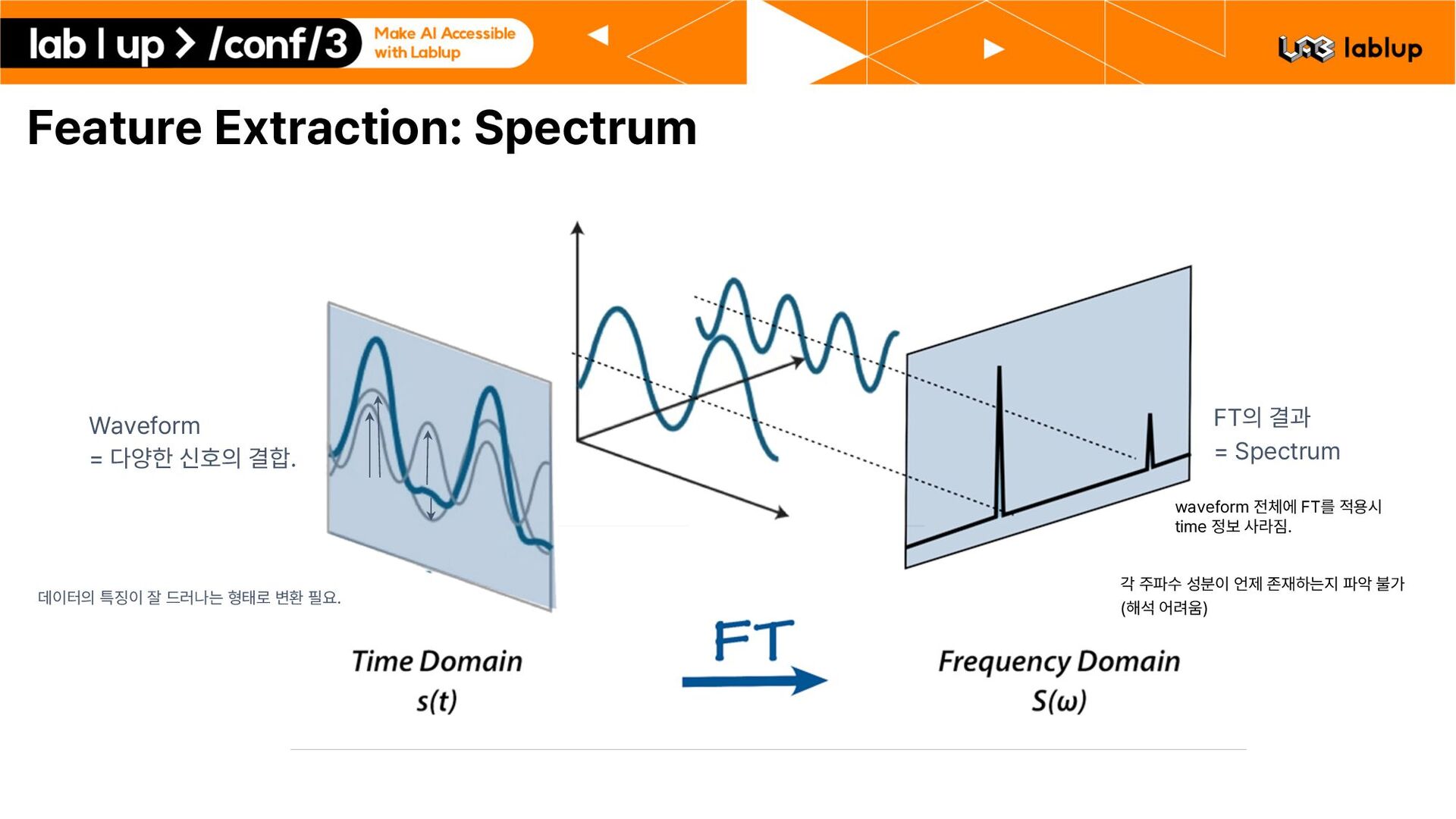
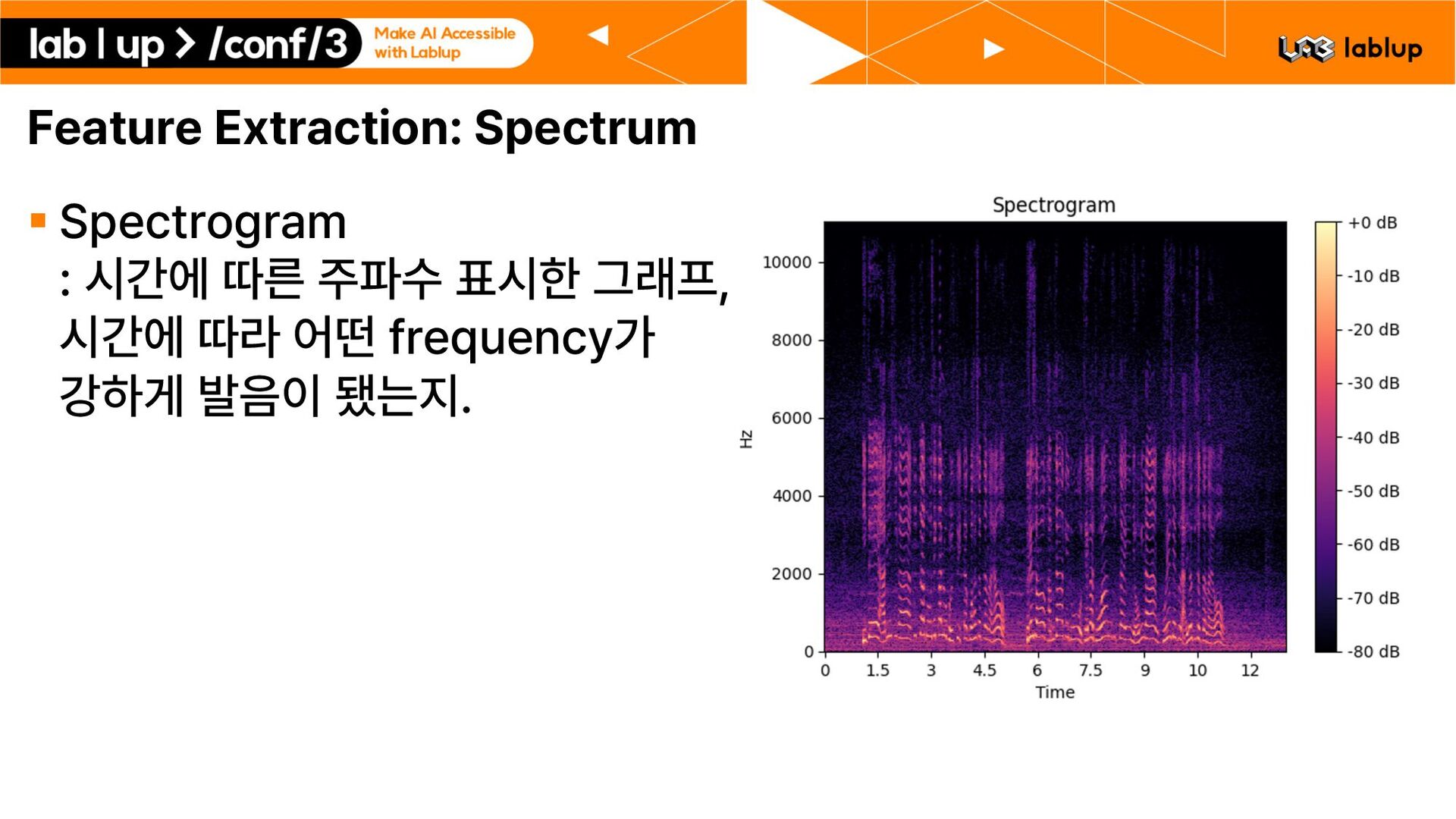
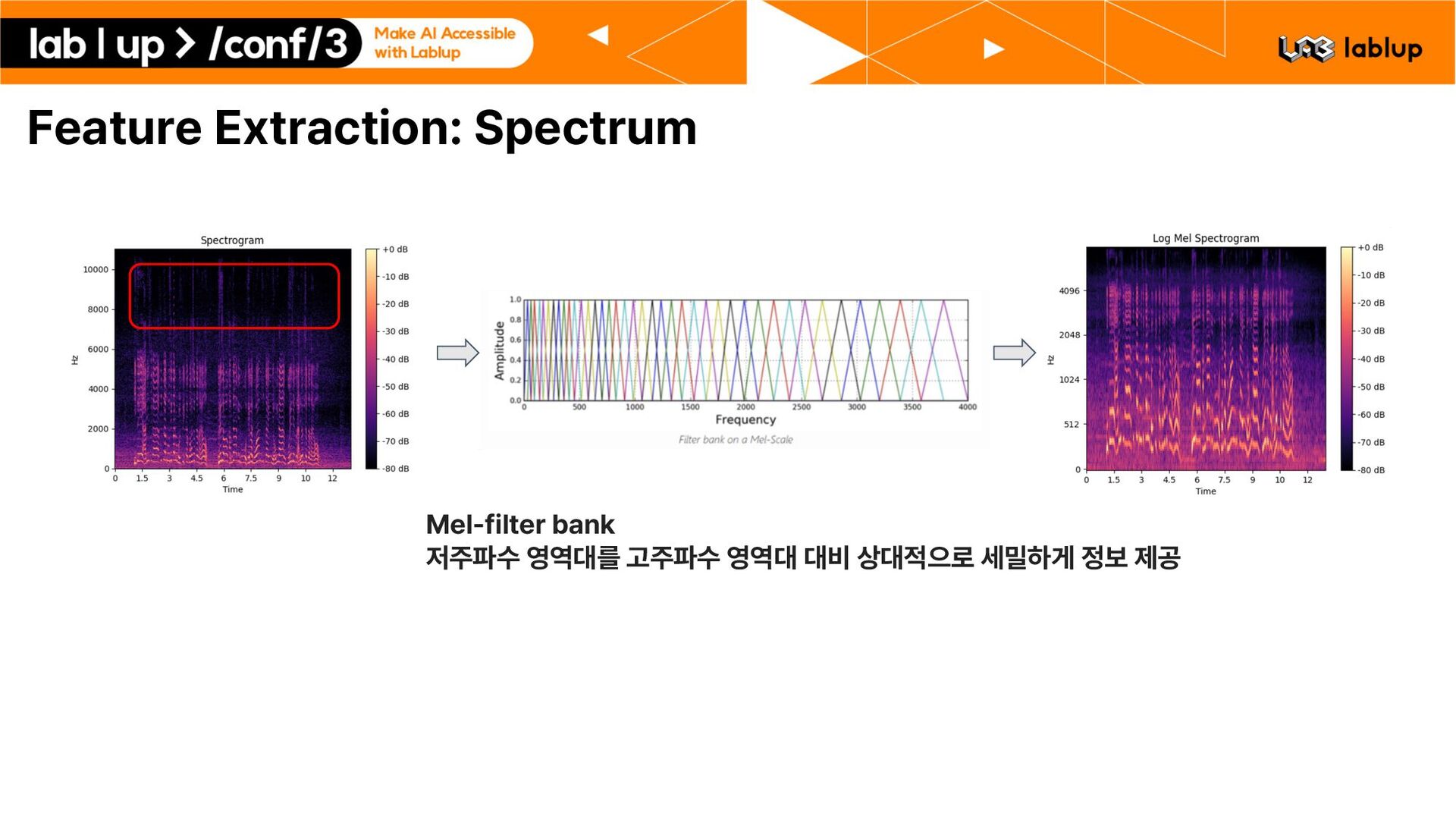
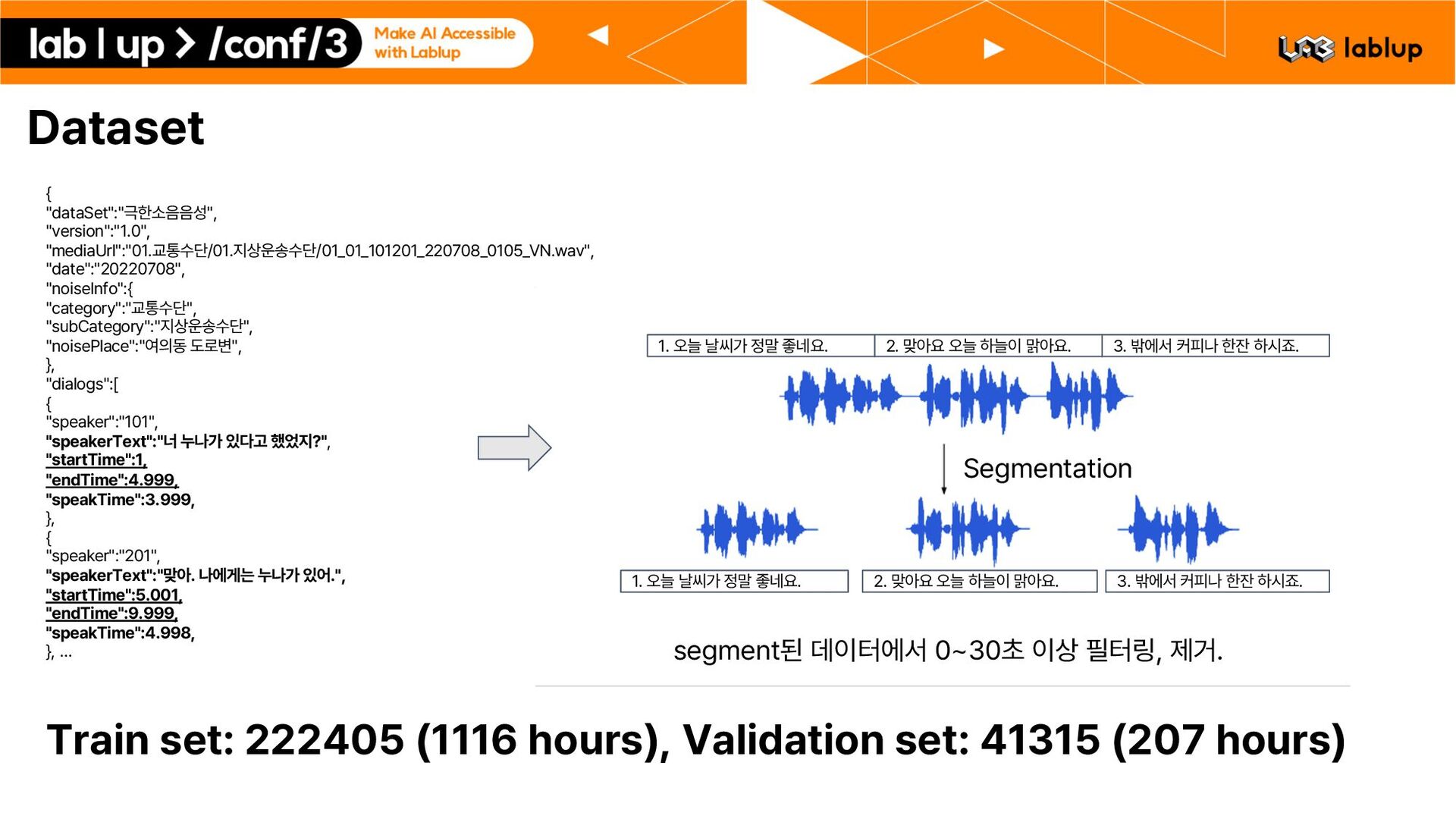
: 01.교통수단/01.지상운송수단/01 01 101201 220708 0105 VN.wav , date : 20220708 , noiseInfo : category : 교통수단 , subCategory : 지상운송수단 , noisePlace : 여의동 도로변 , , dialogs : speaker : 101 , speakerText : 너 누나가 있다고 했었지? , startTime :1, endTime :4.999, speakTime :3.999, , speaker : 201 , speakerText : 맞아. 나에게는 누나가 있어. , startTime :5.001, endTime :9.999, speakTime :4.998, , … 1. 오늘 날씨가 정말 좋네요. 2. 맞아요 오늘 하늘이 맑아요. 3. 밖에서 커피나 한잔 하시죠. Segmentation 1. 오늘 날씨가 정말 좋네요. 2. 맞아요 오늘 하늘이 맑아요. 3. 밖에서 커피나 한잔 하시죠. segment된 데이터에서 0 30초 이상 필터링, 제거. Train set: 222405 1116 hours , Validation set: 41315 207 hours
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
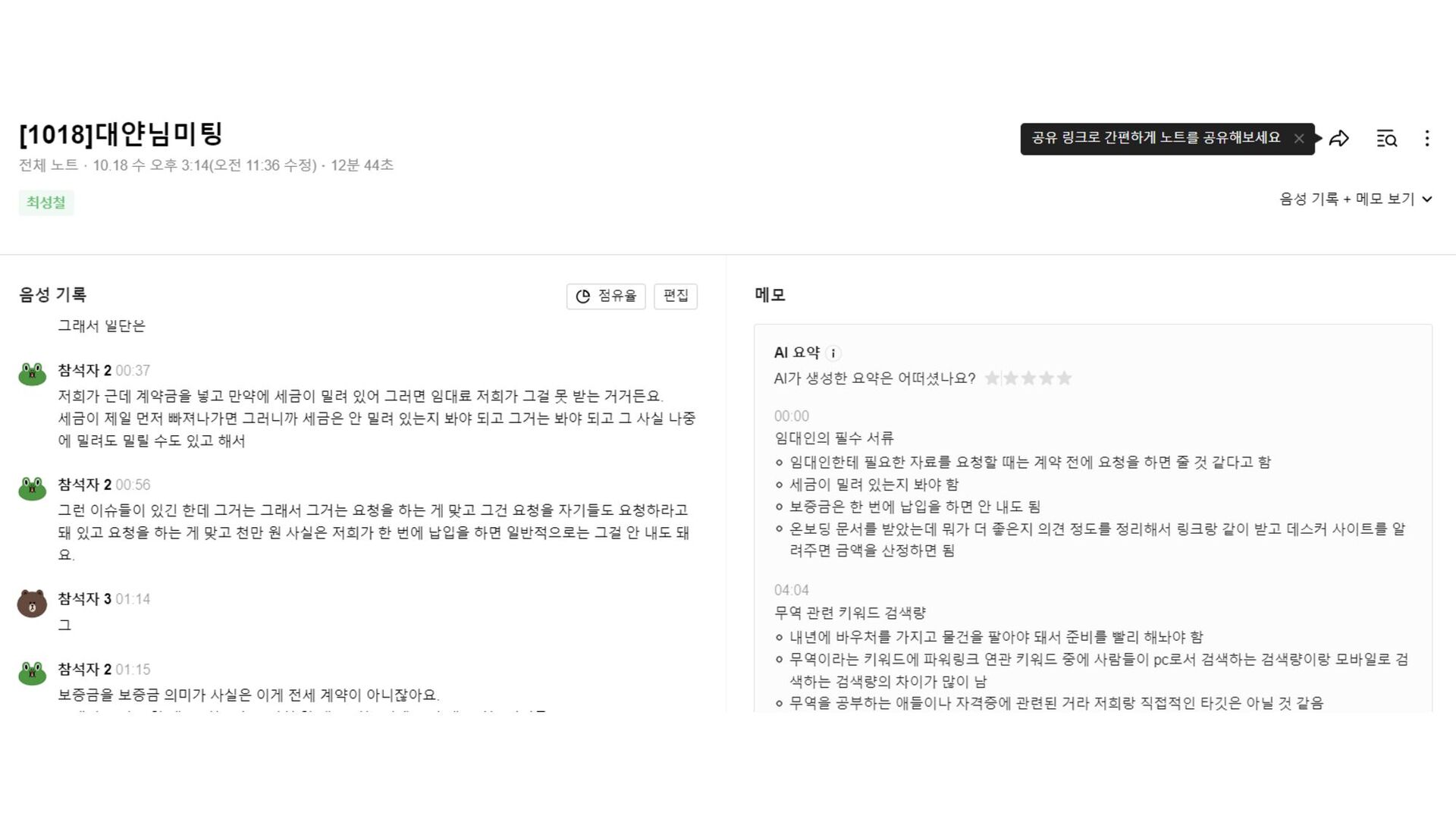{kind=link}
{kind=link}
![5월 11일 회의록 [주요 토론 포인트] - 예창패의 돈은 다음](https://files.speakerdeck.com/presentations/4ec27c81ab7c40fbb79f730c7bb7daec/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
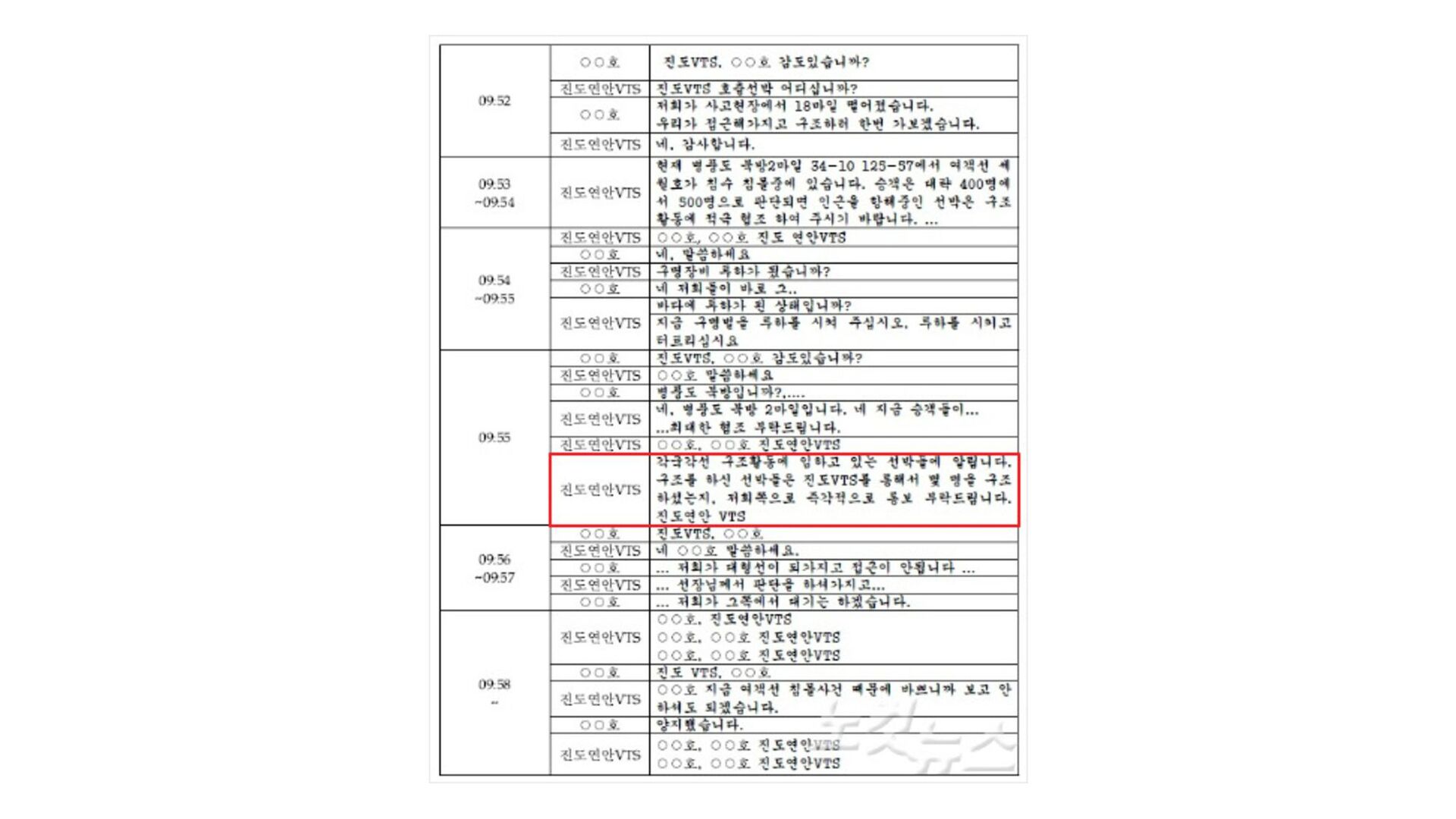{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}