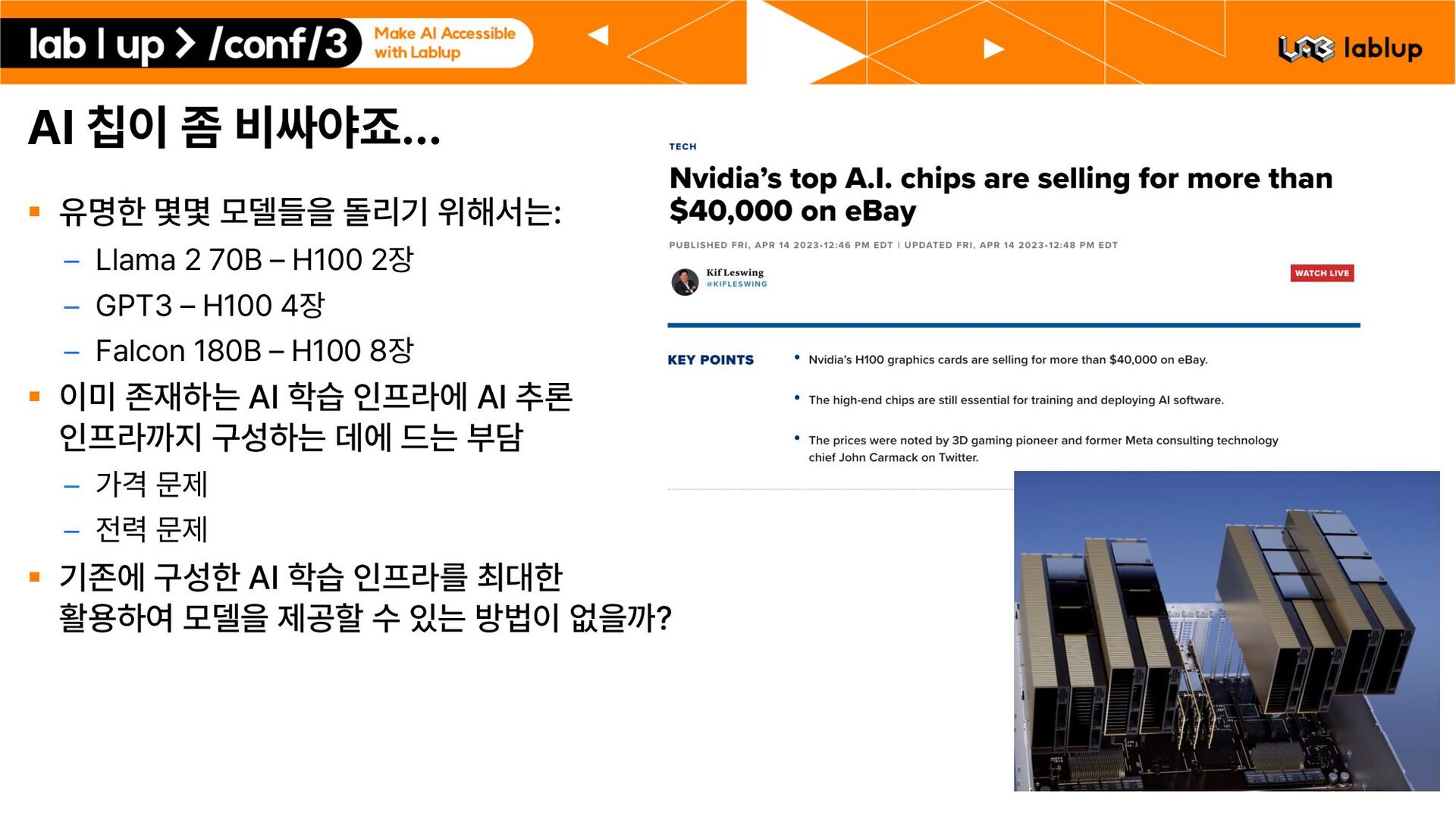
– Llama 2 70B H100 2장 – GPT3 H100 4장 – Falcon 180B H100 8장 § 이미 존재하는 AI 학습 인프라에 AI 추론 인프라까지 구성하는 데에 드는 부담 – 가격 문제 – 전력 문제 § 기존에 구성한 AI 학습 인프라를 최대한 활용하여 모델을 제공할 수 있는 방법이 없을까?
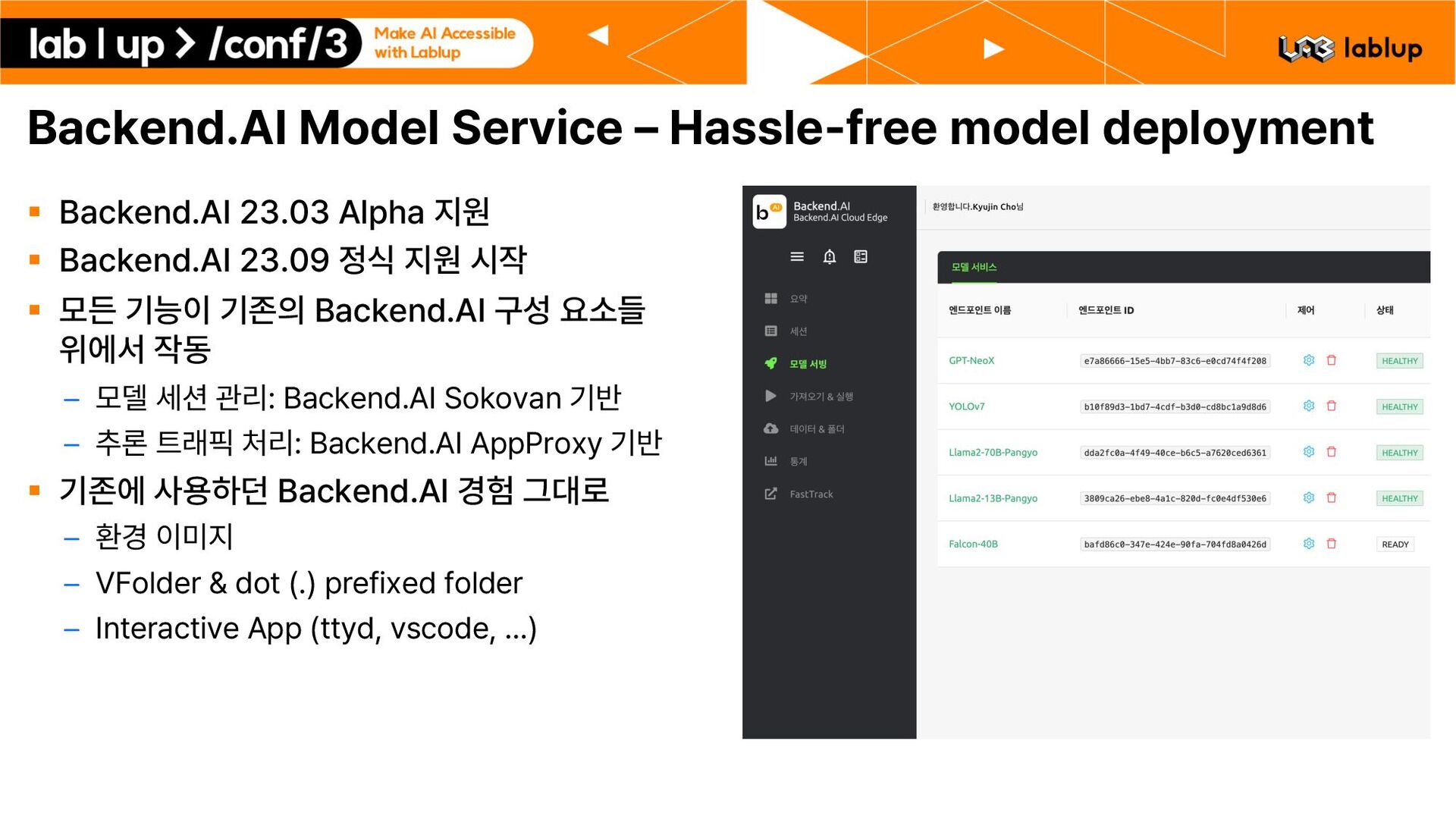
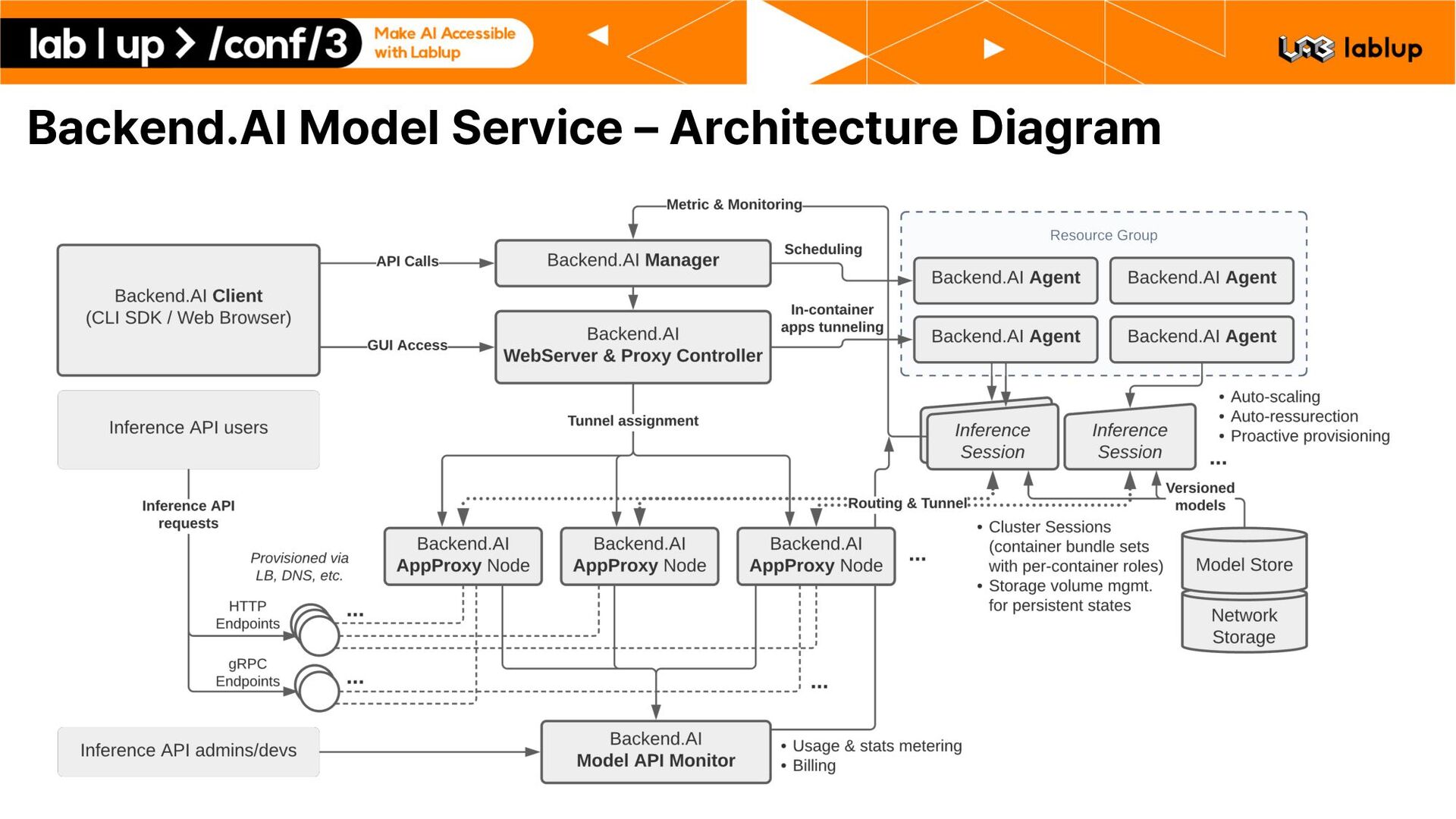
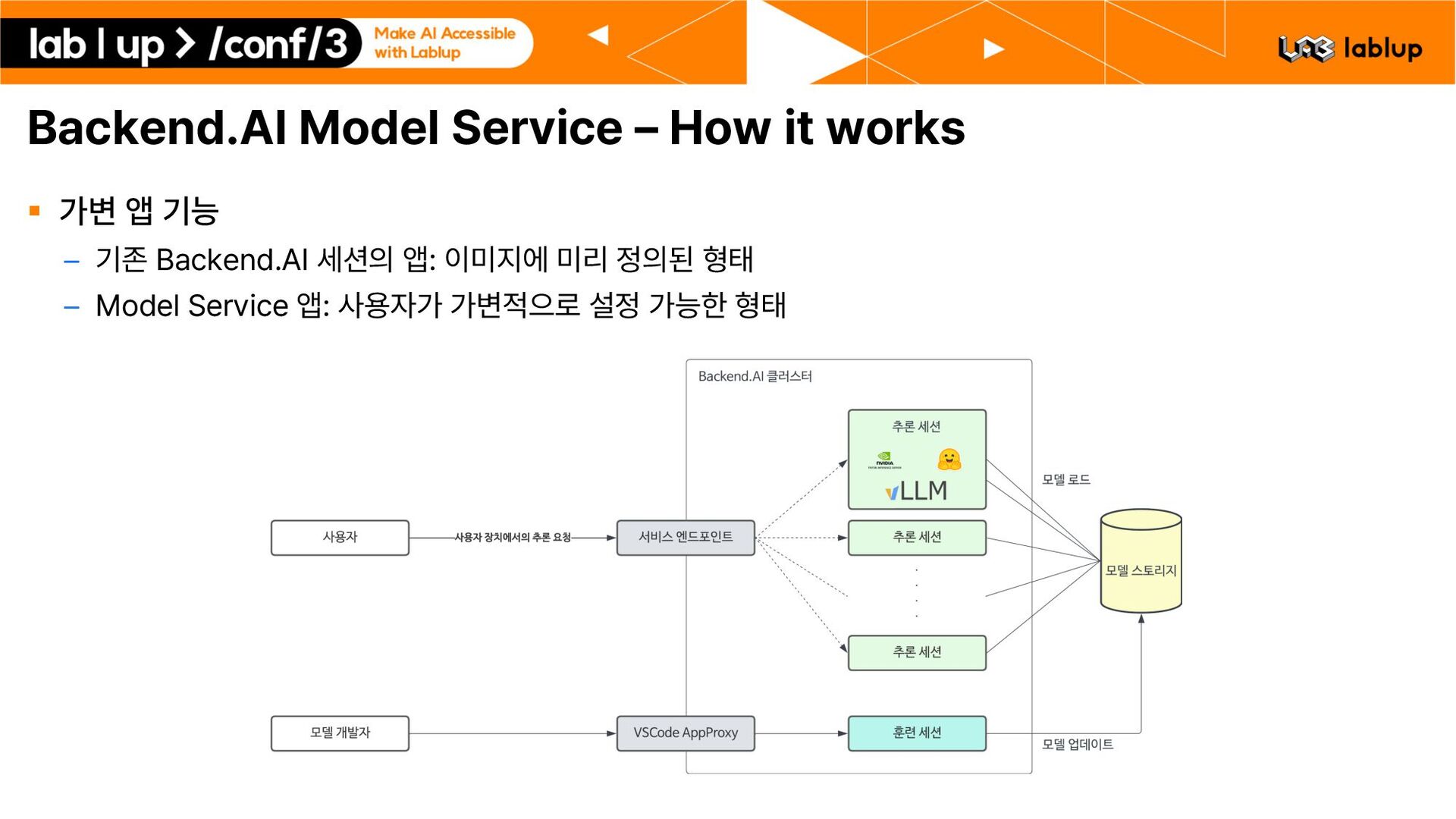
Alpha 지원 § Backend.AI 23.09 정식 지원 시작 § 모든 기능이 기존의 Backend.AI 구성 요소들 위에서 작동 – 모델 세션 관리: Backend.AI Sokovan 기반 – 추론 트래픽 처리: Backend.AI AppProxy 기반 § 기존에 사용하던 Backend.AI 경험 그대로 – 환경 이미지 – VFolder dot . prefixed folder – Interactive App ttyd, vscode, …
다양한 이기종 AI 칩 지원 Traditional GPU: CUDA, ROCm Graphcore IPU/BOW NPU: Furiosa Warboy, Rebellions ATOM … – ARM64 기반 시스템과의 호환 GPU 서버의 숙명과도 같은 문제인 높은 전력 소모 해결에 도움
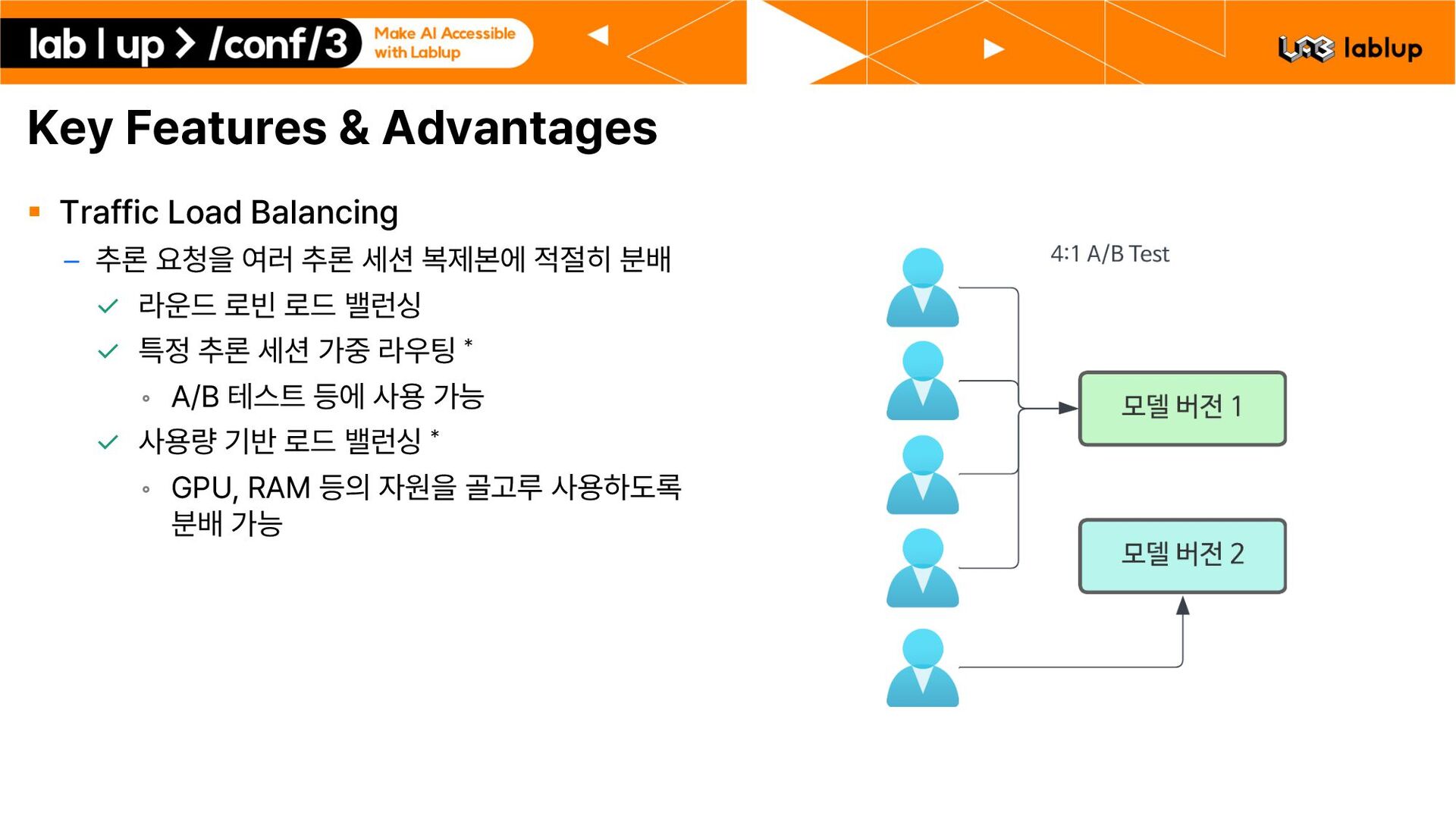
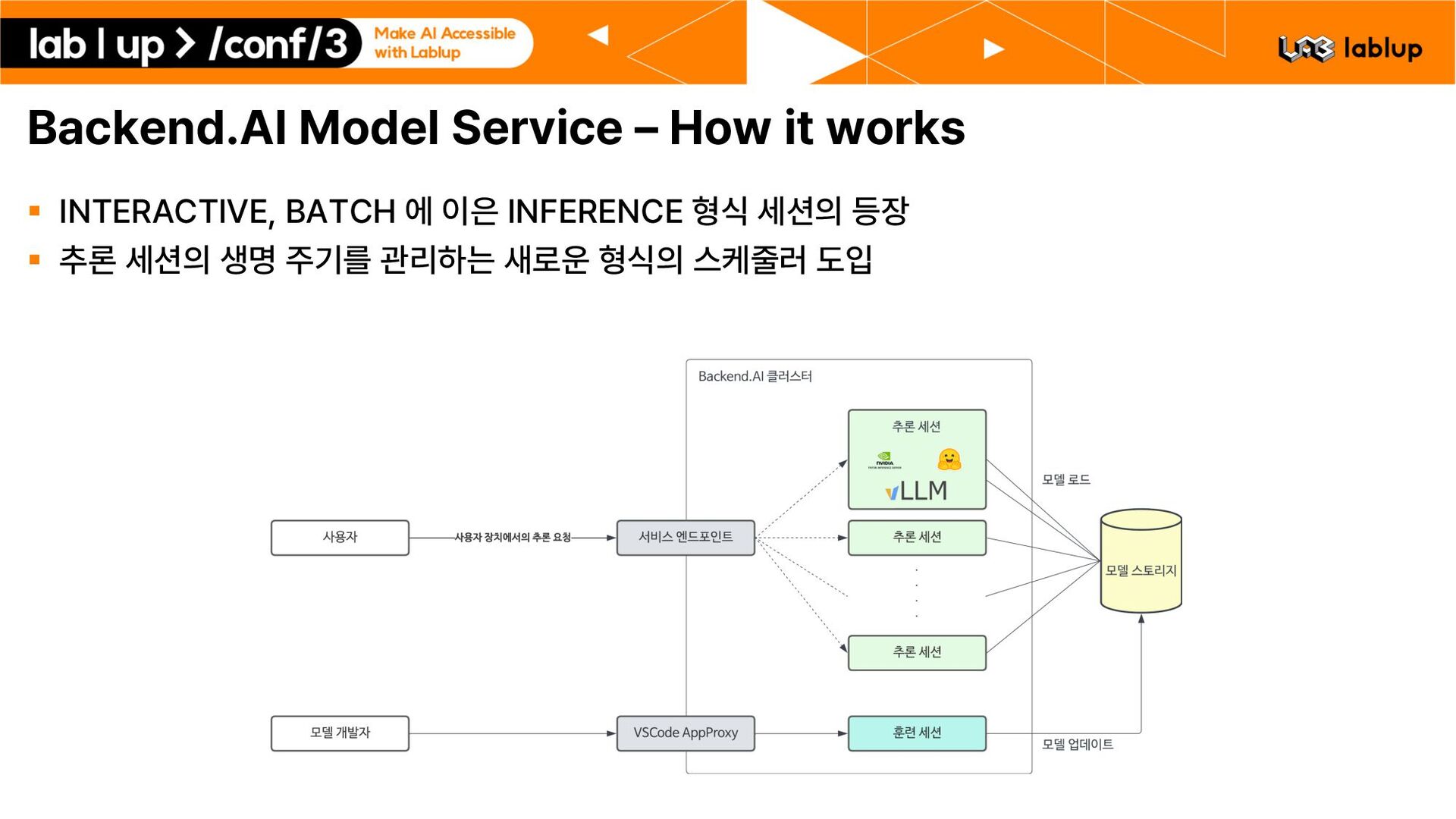
정도에 따라서 유동적으로 점유 자원량을 조절 가능 – 추론 세션 갯수 수동 조절 기능 모델 서비스 관리자가 직접 추론 세션의 복제본을 생성 또는 삭제할 수 있음 – 오토 스케일링 기능 * 특정 시각에 추론 세션을 생성 또는 제거 미리 정해진 사용량 임계점을 지나면 Backend.AI Sokovan이 자동으로 추론 세션 생성 또는 제거
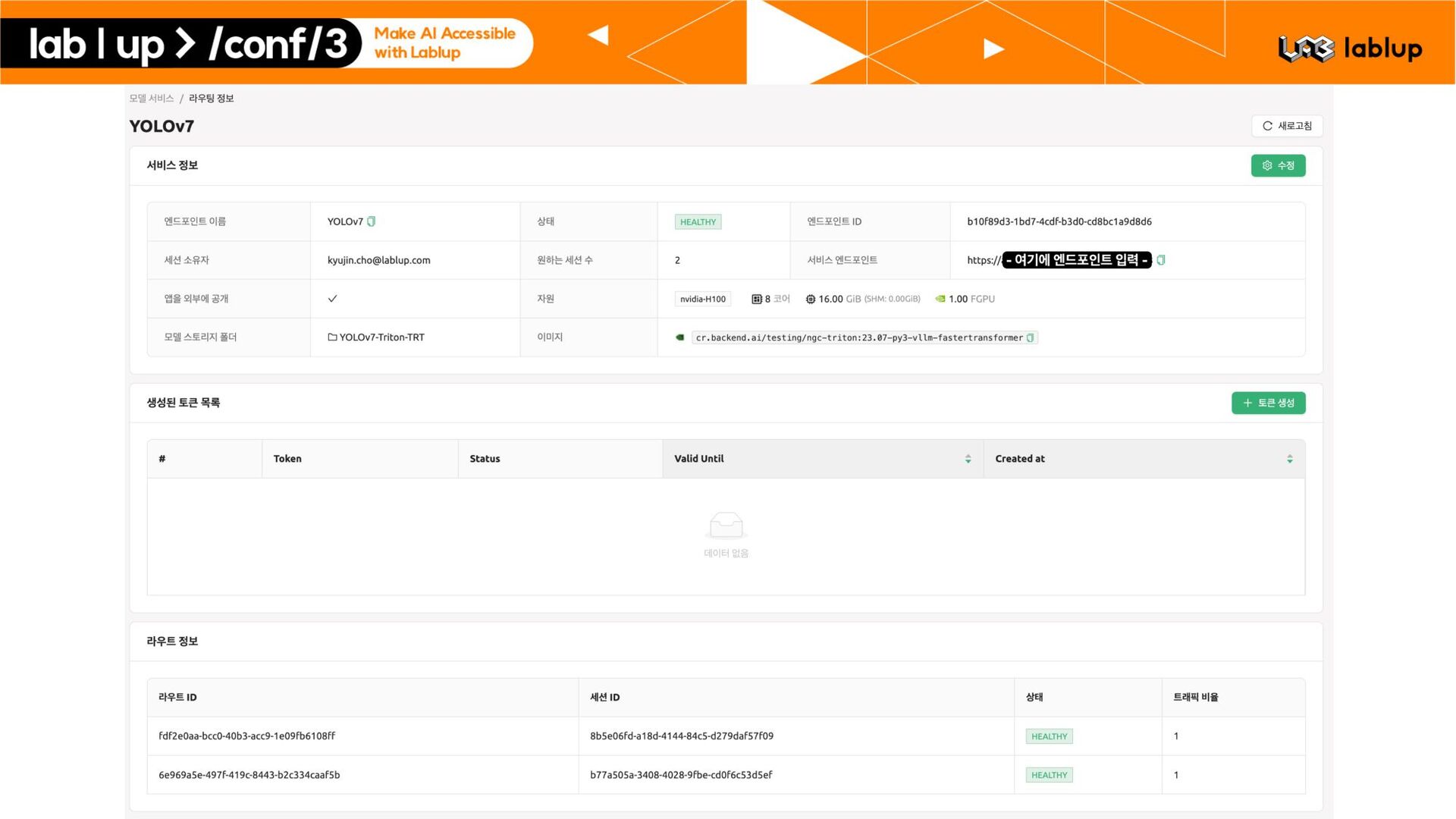
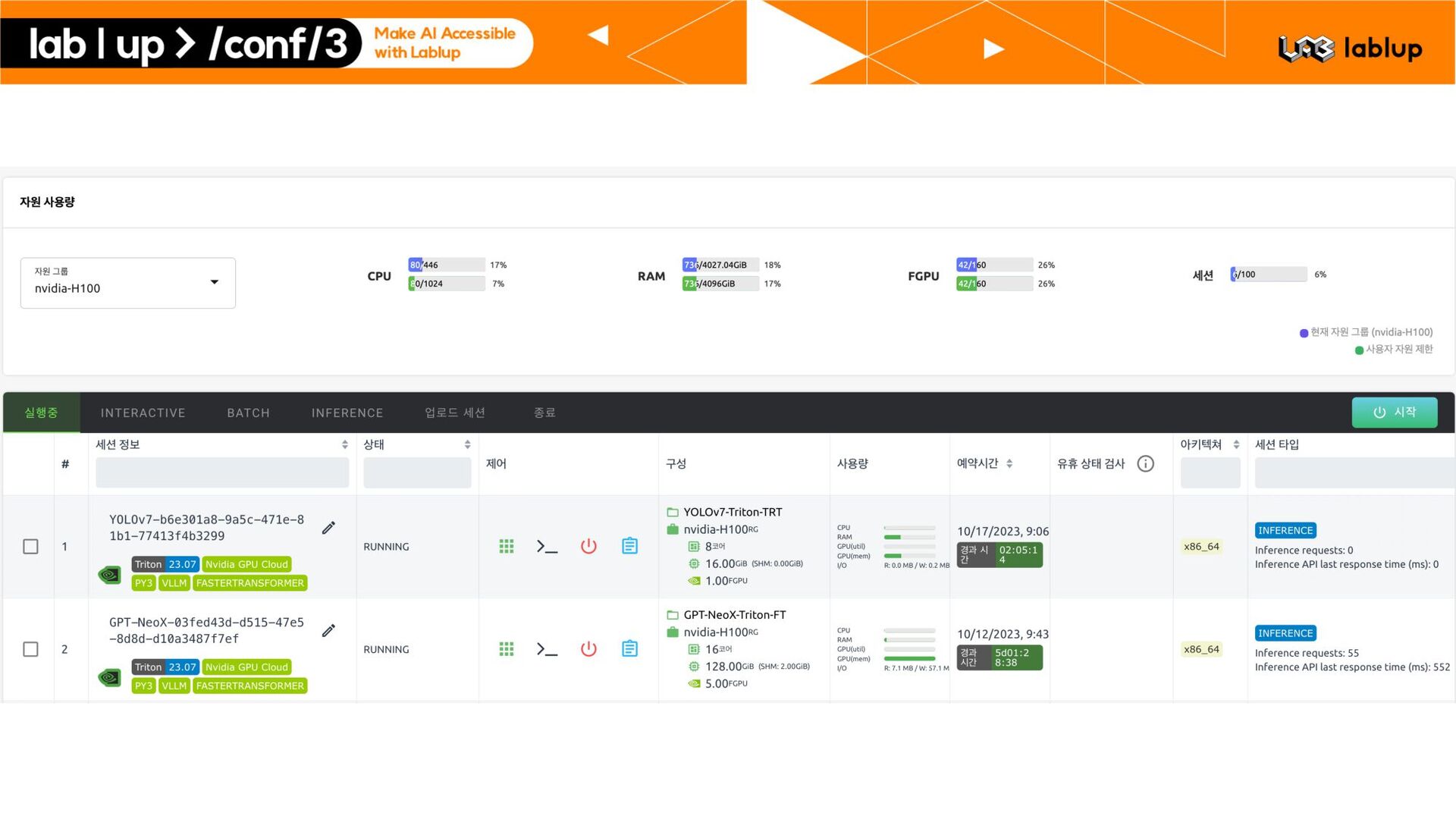
– Backend.AI AppProxy 단에서의 자체적인 인증 기능 지원 – JWT 기반 인증 – 세션 기반 인증 * 특정 사용자에게 발급된 인증 키를 임의 회수할 수 있음 § Metric Collection – 모델 서비스에 특화된 다양한 수치 수집 기능 모델 세션 별 API 요청 처리 횟수 사용자 토큰 별 API 요청 횟수 및 Billable Time Duration *
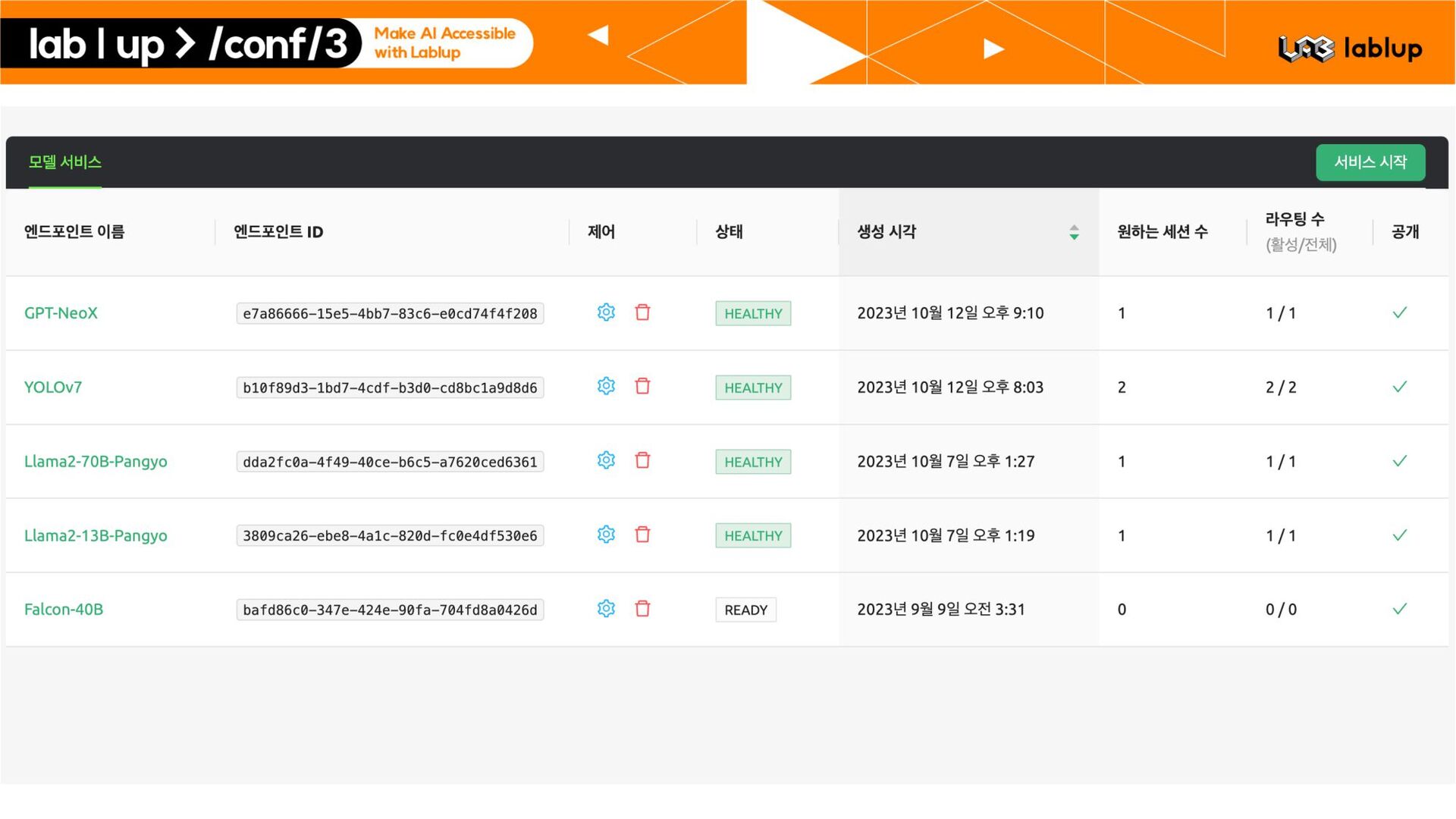
서버 프로세스의 상태를 검사 – 응답하지 않는 모델 서버 프로세스로 트래픽이 향하지 않도록 자동 조치 § Customizable API Endpoint Subdomain * – 모델 서비스의 이름을 API 엔드포인트에 포함시킬 수 있음 llama2 2d8a0f84.app.backend.ai kogpt 1p0908xf.app.backend.ai
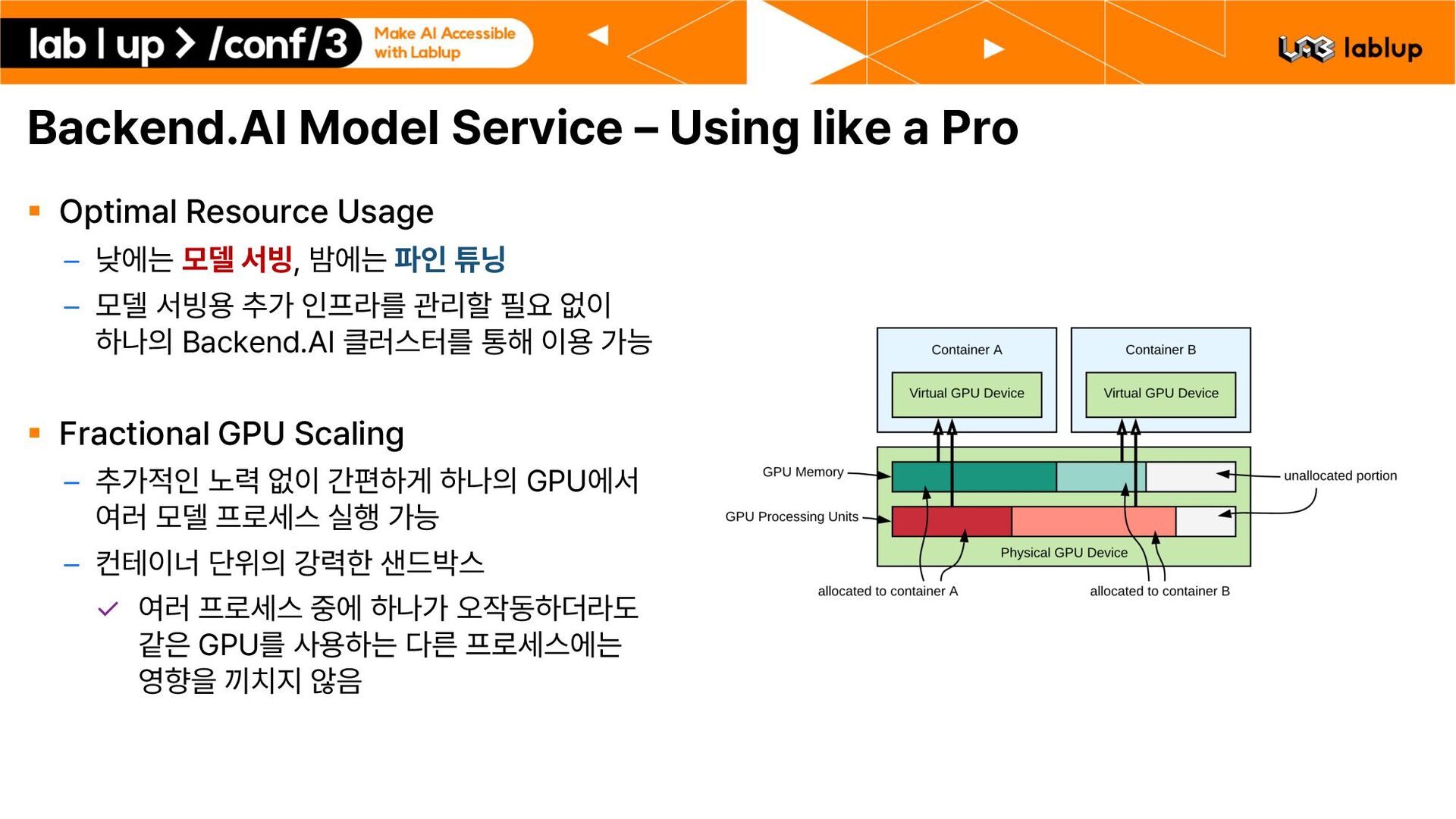
Usage – 낮에는 모델 서빙, 밤에는 파인 튜닝 – 모델 서빙용 추가 인프라를 관리할 필요 없이 하나의 Backend.AI 클러스터를 통해 이용 가능 § Fractional GPU Scaling – 추가적인 노력 없이 간편하게 하나의 GPU에서 여러 모델 프로세스 실행 가능 – 컨테이너 단위의 강력한 샌드박스 여러 프로세스 중에 하나가 오작동하더라도 같은 GPU를 사용하는 다른 프로세스에는 영향을 끼치지 않음
pipeline – Backend.AI FastTrack과 연계하여 파인튜닝 모델 실시간 배포 § Backend.AI FastTrack – Backend.AI를 기반으로 작동하는 Hyperscale MLOps 솔루션 – DAG 관리 및 멀티 파이프라인 기능 – YAML 기반 재사용 가능 파이프라인 – 예약, 큐잉, 반복 실행 및 모니터링 – 데이터부터 서비스 배포 자동화까지 한번에 가능
– 동일 하드웨어 자원으로 다양한 용도 활용 § GenAI 서비스 고도화를 위한 서빙 기능 – 자원량 사전 예약 및 사용자 부하에 따른 오토스케일링 – 사용자 지정 모델 저장소 및 임포트 기능 – 모델 저장소에서 원클릭 모델 서빙 § 파이프라인을 통한 파인 튜닝 / 디플로이 완전 자동화 – 사용 패턴에 따른 스케쥴링 기반 인퍼런스 파인튜닝 워크로드 전환 – 파인튠 모델 주기적 배포 편한 인생
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}