# `%%async_run`: an IPython notebook magic for asynchronous cell execution
The IPython `notebook` project is one the preferred tools of data scientists,
and it is nowadays the bastion for *Reproducible Research*.
In fact, notebooks are now used as in-browser IDE (*Integrated Development Environment*) to implement the whole data analysis process, along with the corresponding documentation.
However, since this kind of processes usually include heavy-weight computations,
it may likely happen that execution results get lost if something wrong happens, e.g. the connection to the
notebook server hangs or an accidental page refresh is issued.
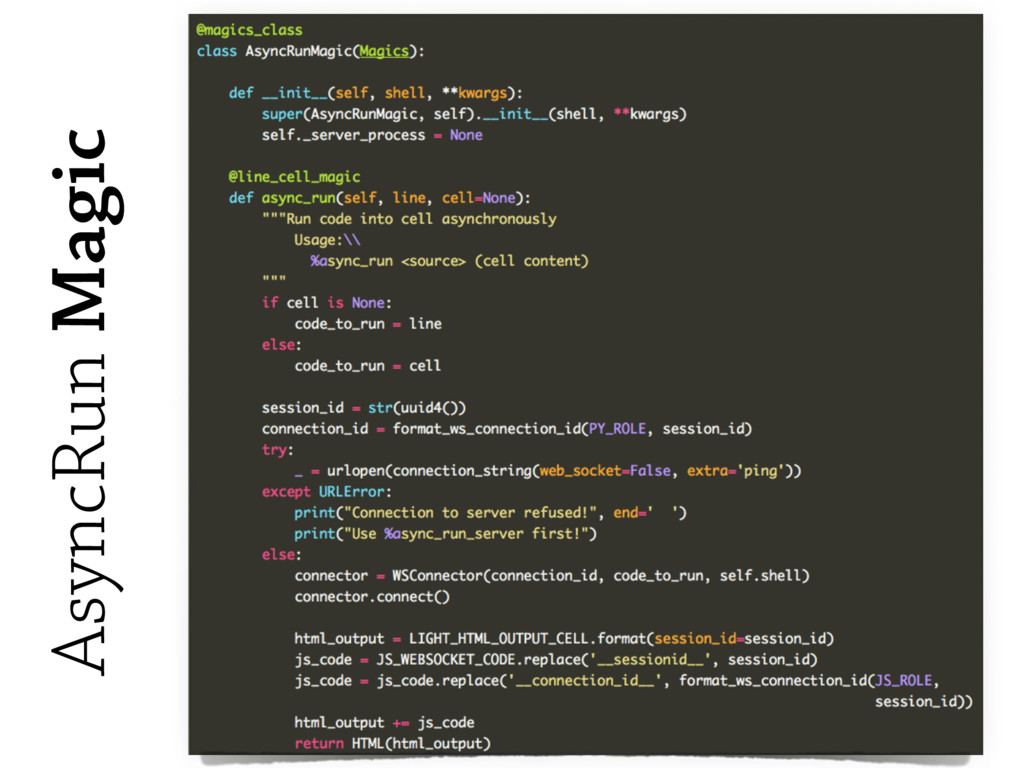
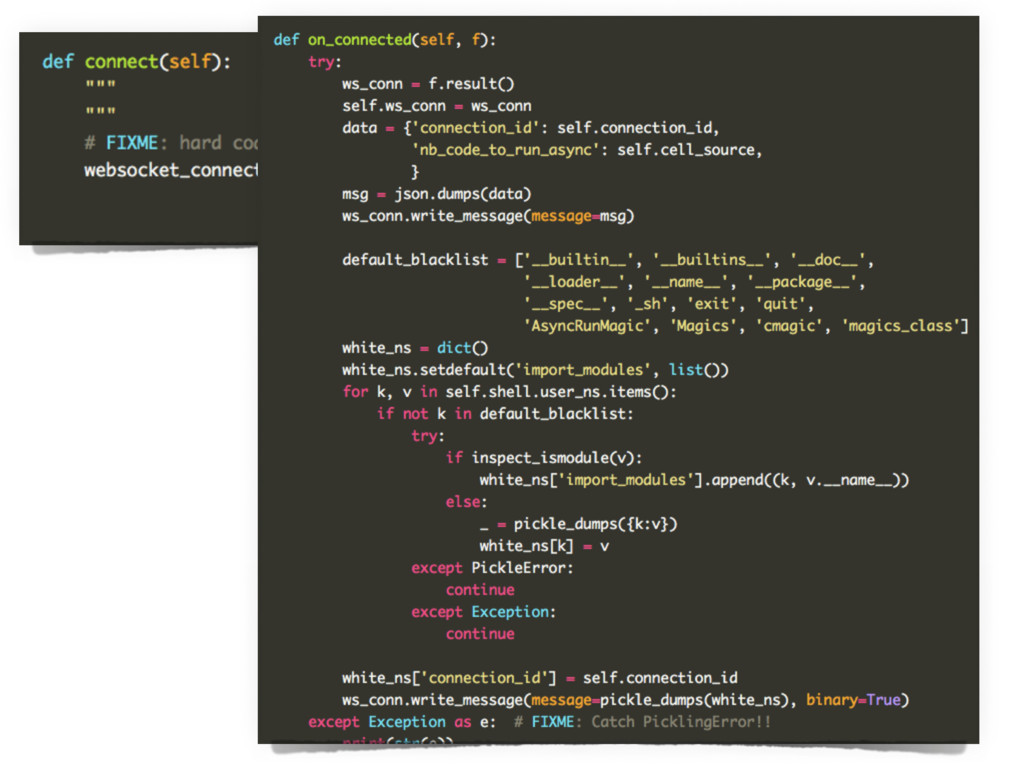
To this end, `[%]%async_run` notebook line/cell magic to the rescue.
In this talk, I would like to talk about some of the technologies I played with since I decided to develop
this extension.
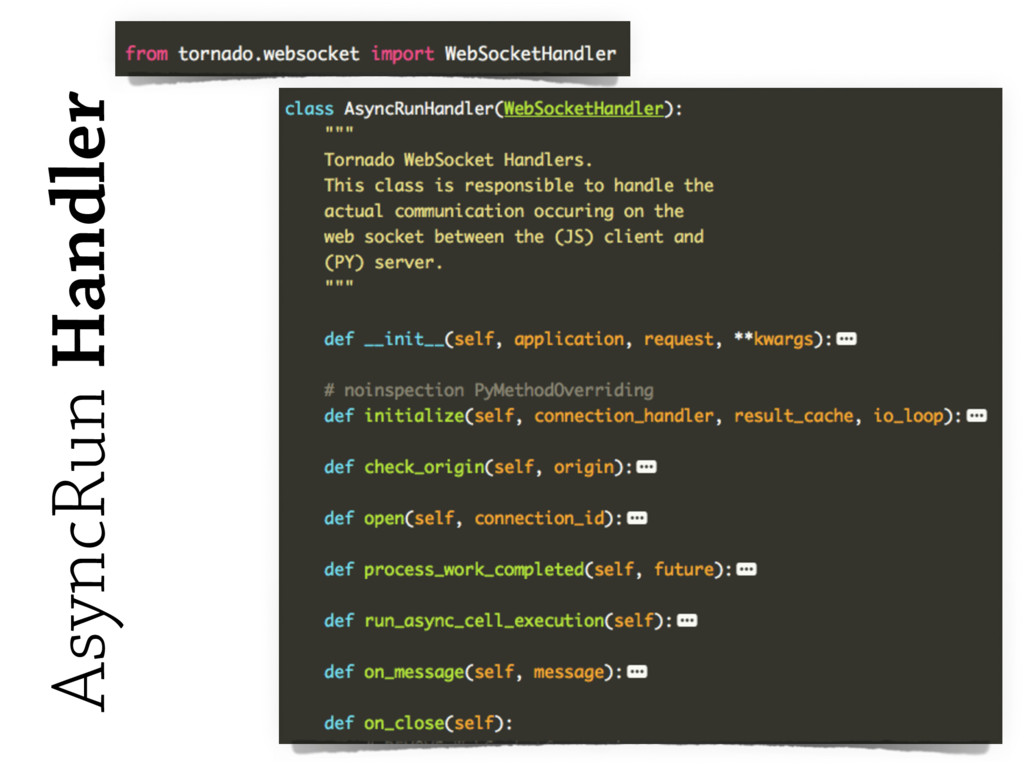
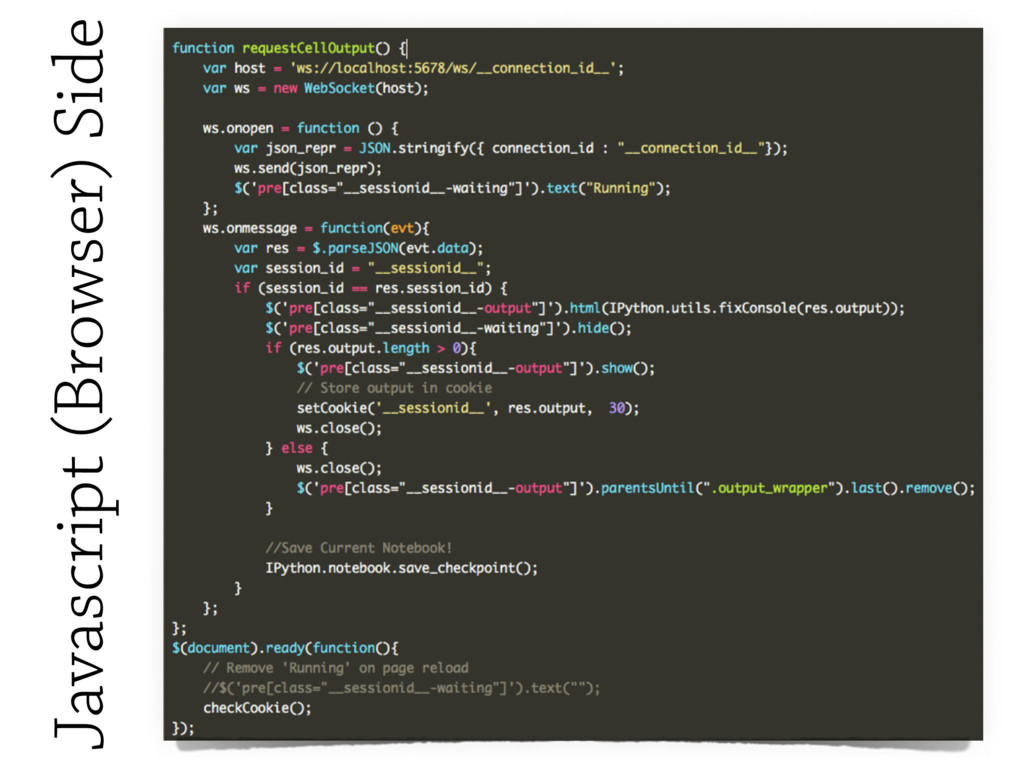
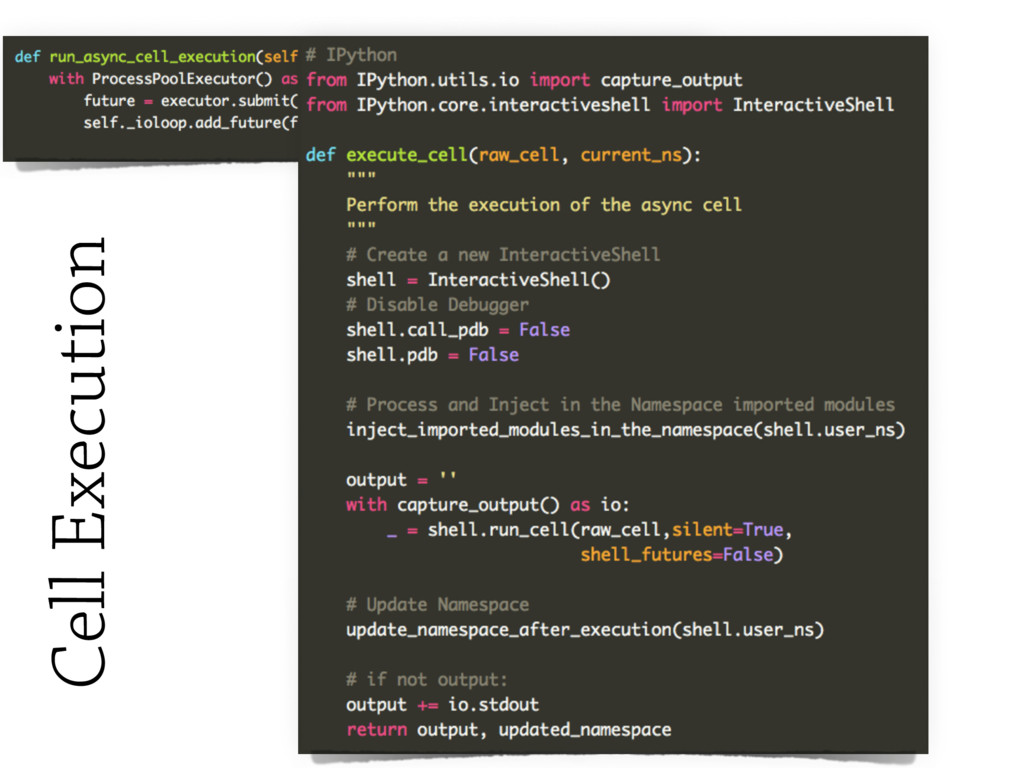
These technologies include **asynchronous I/O** libraries (e.g. `asyncio`, `tornado.websocket`),
**`multiprocessing`**, along with IPython `kernels` and `notebooks`.
During the talk, I would like to discuss pitfalls, failures, and adopted solutions (e.g. *namespace management
among processes*) , aiming at getting as many feedbacks as possible from the community.
A general introduction to the actual state-of-the-art of the **Jupyter** projects (an libraries) will be
presented as well, in order to help those who are willing to know some more details about the internals of
IPython.
![[%]%async_run an IPython notebook* magic for asynchronous (code) cell execution](https://files.speakerdeck.com/presentations/08f01922660c43868c47c41009f54917/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
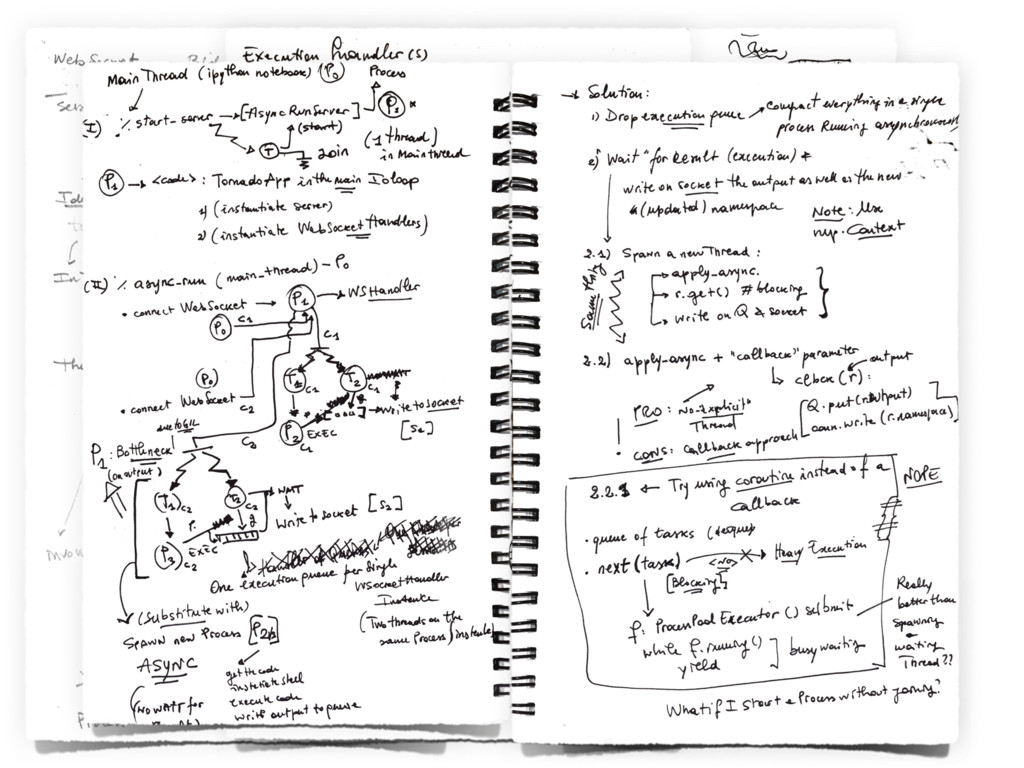{kind=link}
![[%]%async_run an IPython notebook* magic for asynchronous (code) cell execution](https://files.speakerdeck.com/presentations/08f01922660c43868c47c41009f54917/slide_7.jpg){kind=link}
{kind=link}
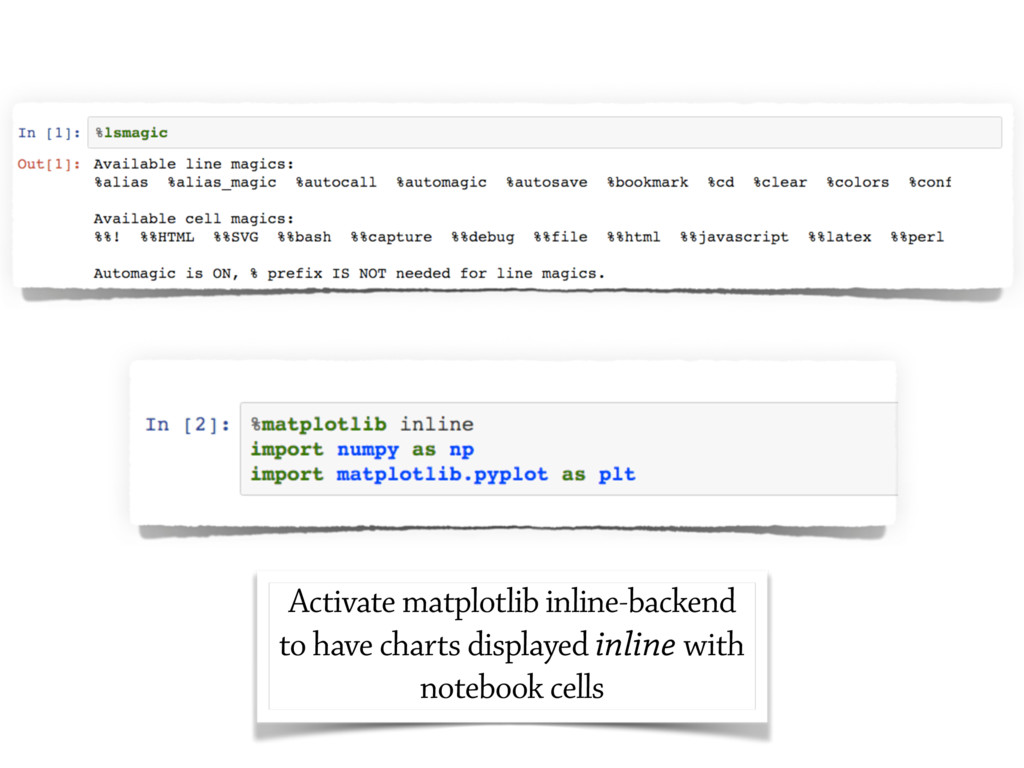{kind=link}
![[%]%timeit Line Magic Cell Magic](https://files.speakerdeck.com/presentations/08f01922660c43868c47c41009f54917/slide_10.jpg){kind=link}
{kind=link}
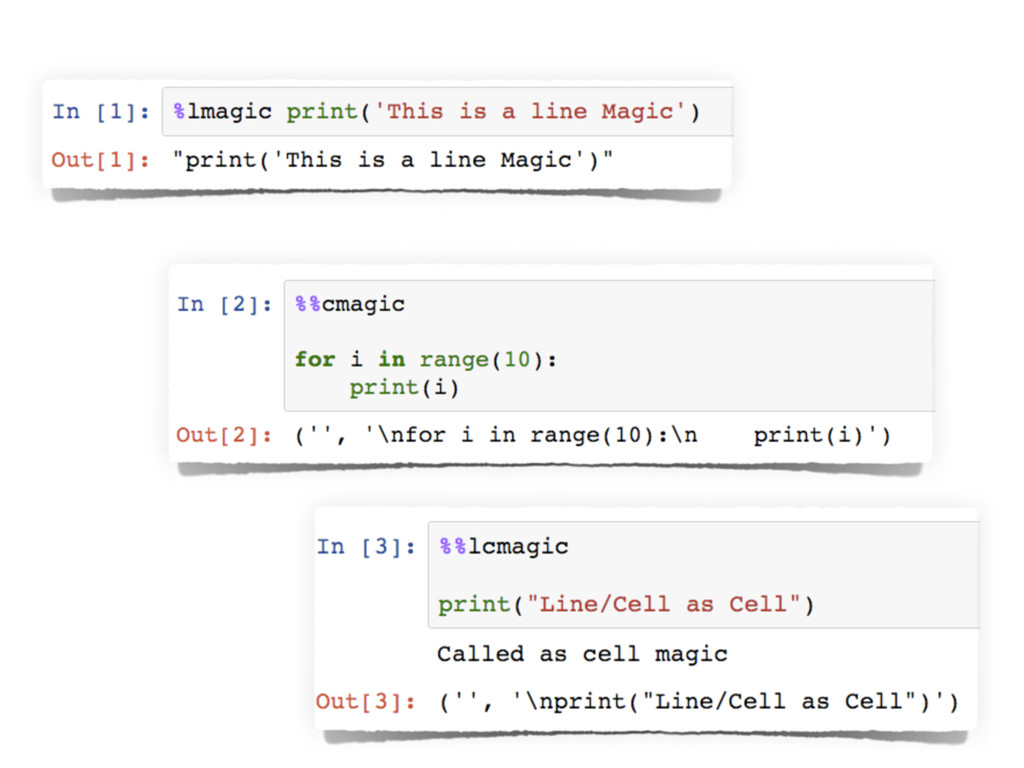{kind=link}
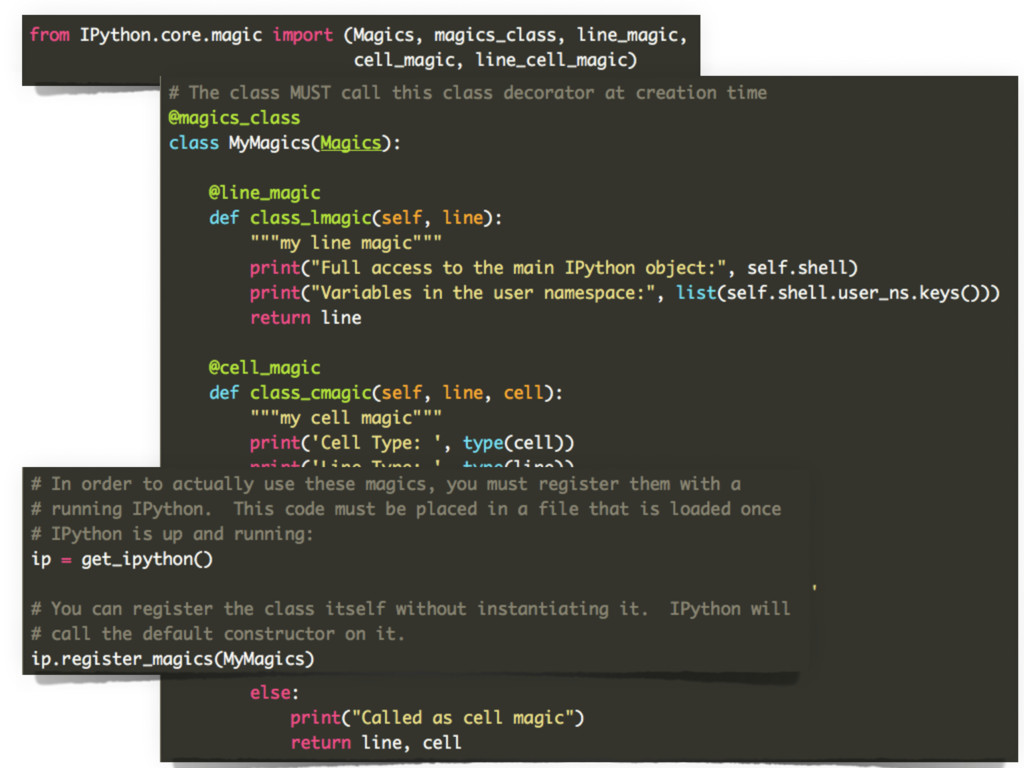{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[%]%async_run an IPython notebook* magic for asynchronous (code) cell execution](https://files.speakerdeck.com/presentations/08f01922660c43868c47c41009f54917/slide_37.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks a lot for your kind attention +ValerioMaggio [email protected] it.linkedin.com/in/valeriomaggio](https://files.speakerdeck.com/presentations/08f01922660c43868c47c41009f54917/slide_53.jpg){kind=link}