This one-hour live webinar will introduce participants to the fundamentals of Privacy Preserving Machine Learning (PPML). The session explores essential PPML concepts including Federated Learning, Differential Privacy, and Homomorphic Encryption, providing participants with a foundational understanding of balancing privacy and transparency in ML model development. Through practical demonstrations, attendees will learn to integrate privacy-preserving techniques into ML workflows using OpenMined. Participants will explore PySyft, a powerful open-source framework for secure and private machine learning, alongside SyftBox—OpenMined's latest project designed to make development with Privacy-Enhancing Technologies more intuitive and developer-friendly.
More info: https://openmined.github.io/intro-to-ppml-workshop/
![Introduction to PPML @leriomaggio [email protected] in/valeriomaggio Valerio Maggio, Ph.D. Education](https://files.speakerdeck.com/presentations/f7f9d5f09edd40699114a6b25d77081f/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Univ. Wisconsin Datasite Data Owner [email protected] Dr. Rachel Science *************](https://files.speakerdeck.com/presentations/f7f9d5f09edd40699114a6b25d77081f/slide_53.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
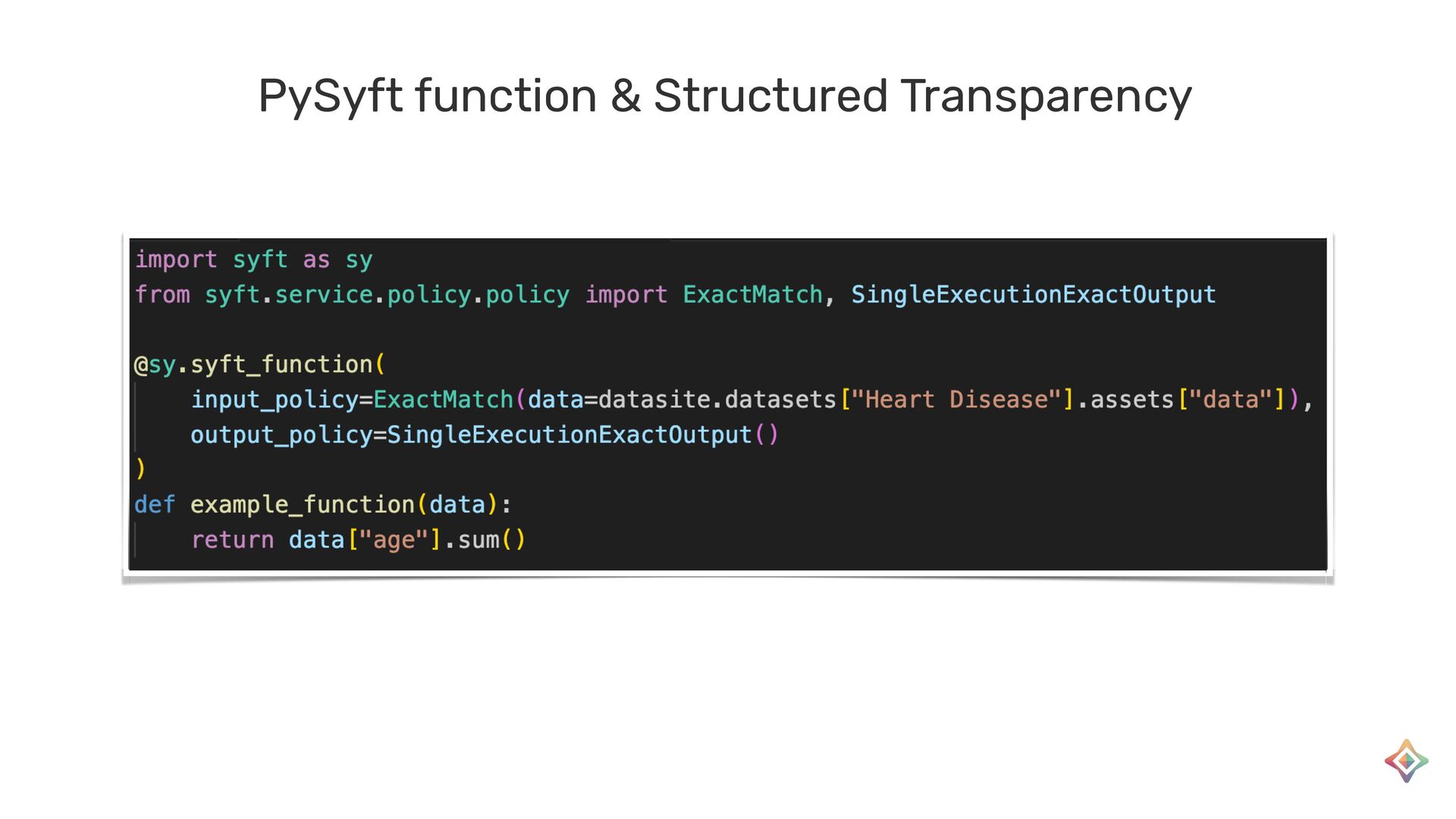{kind=link}
{kind=link}
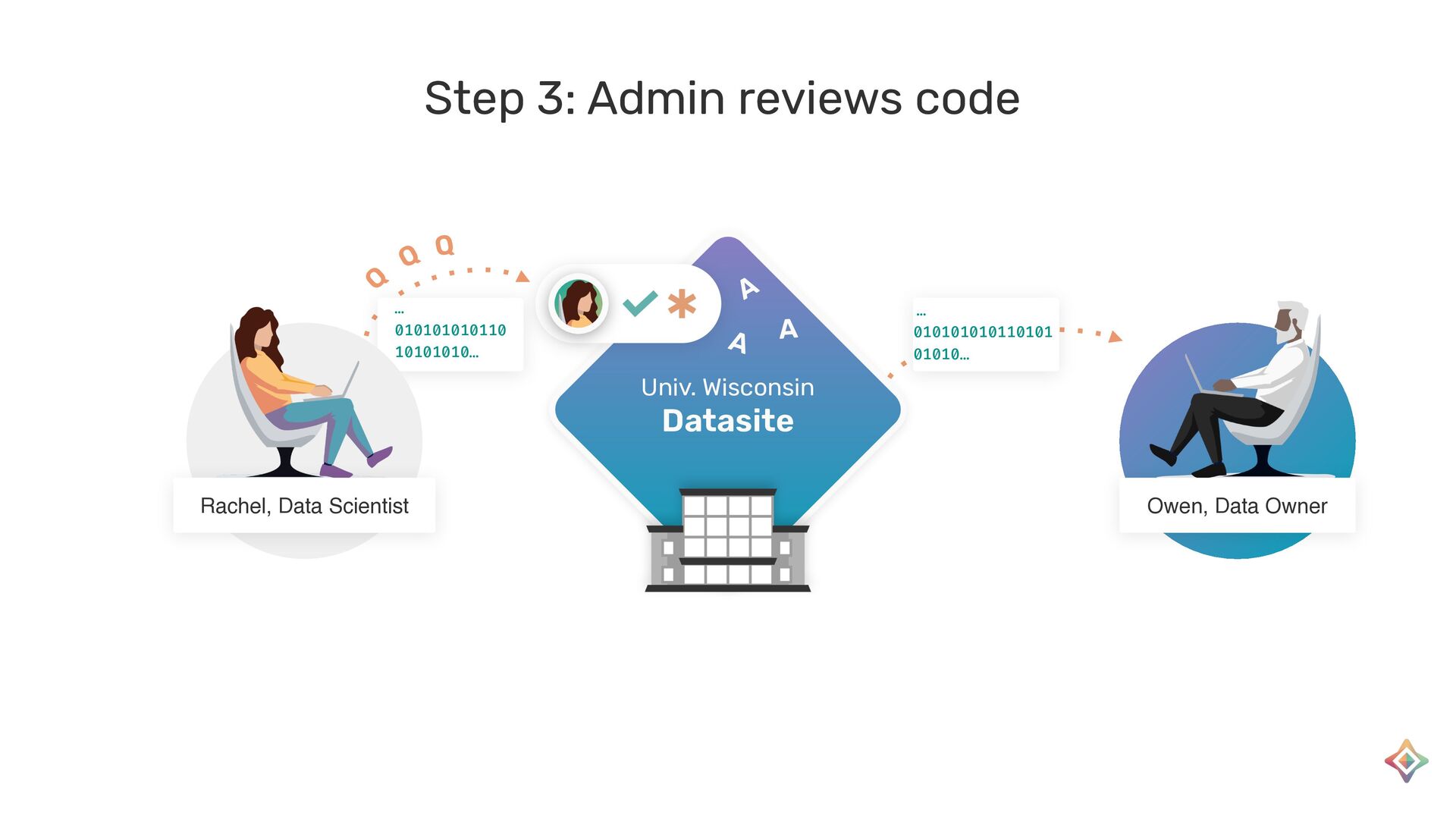{kind=link}
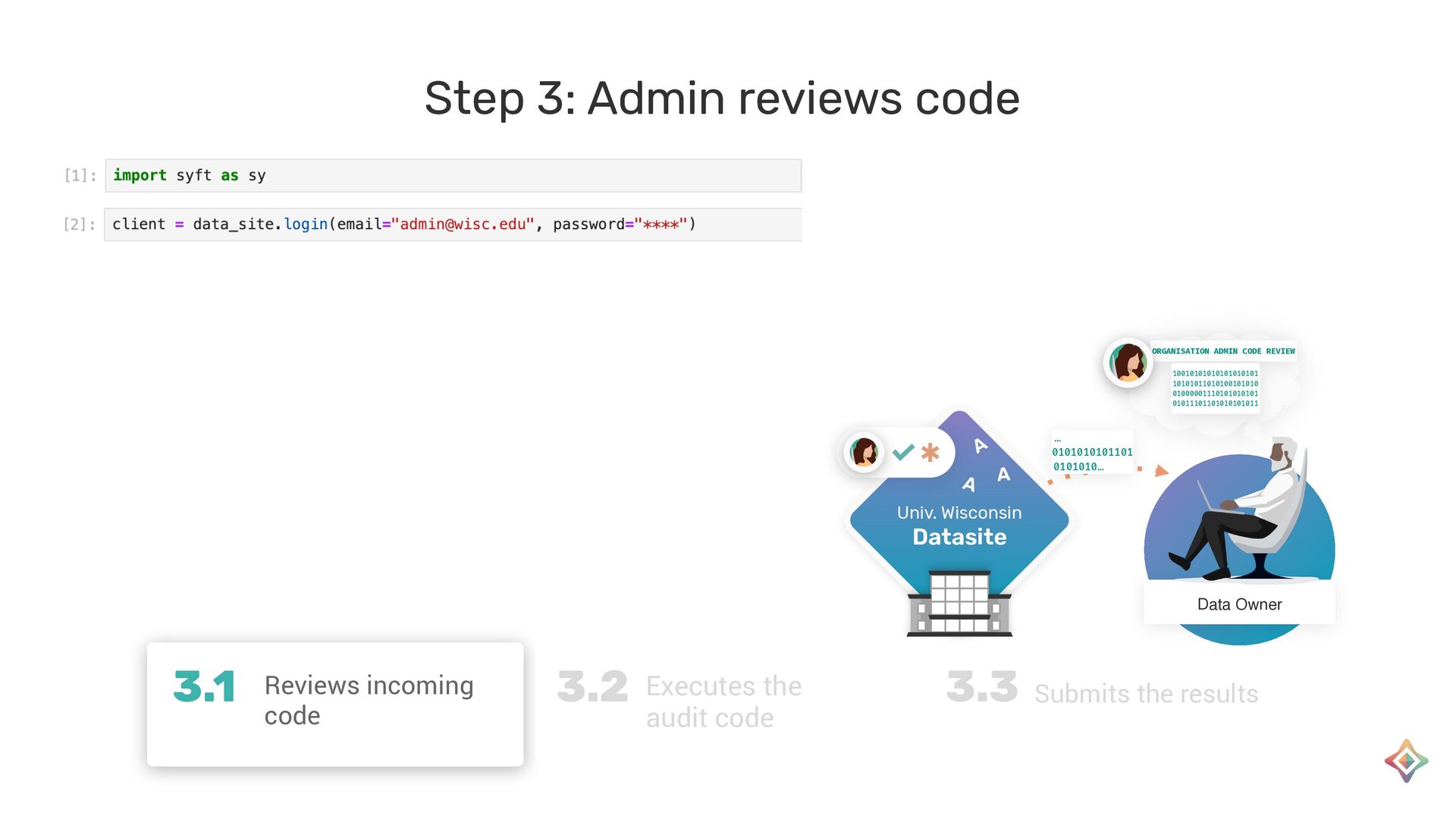{kind=link}
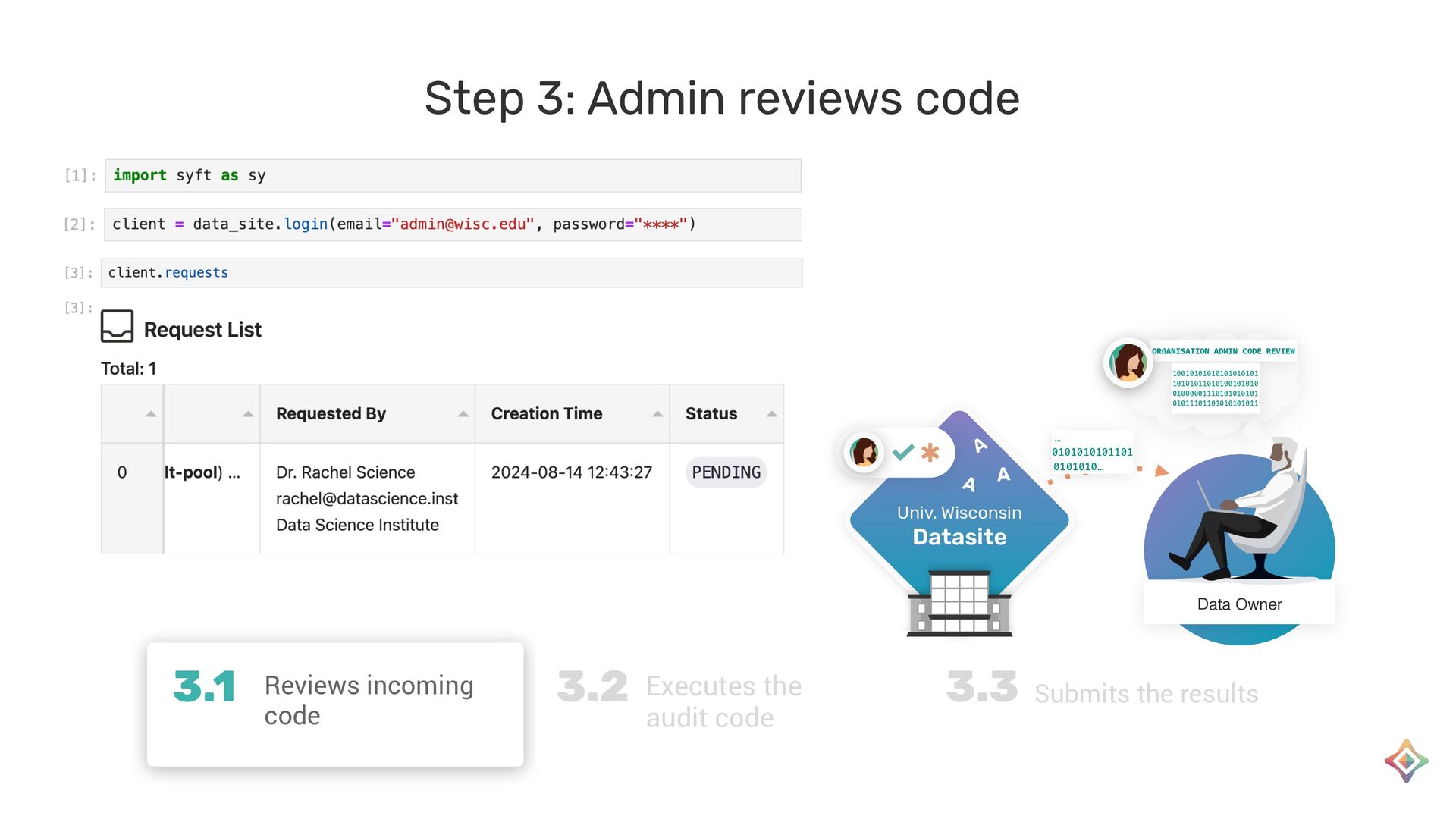{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
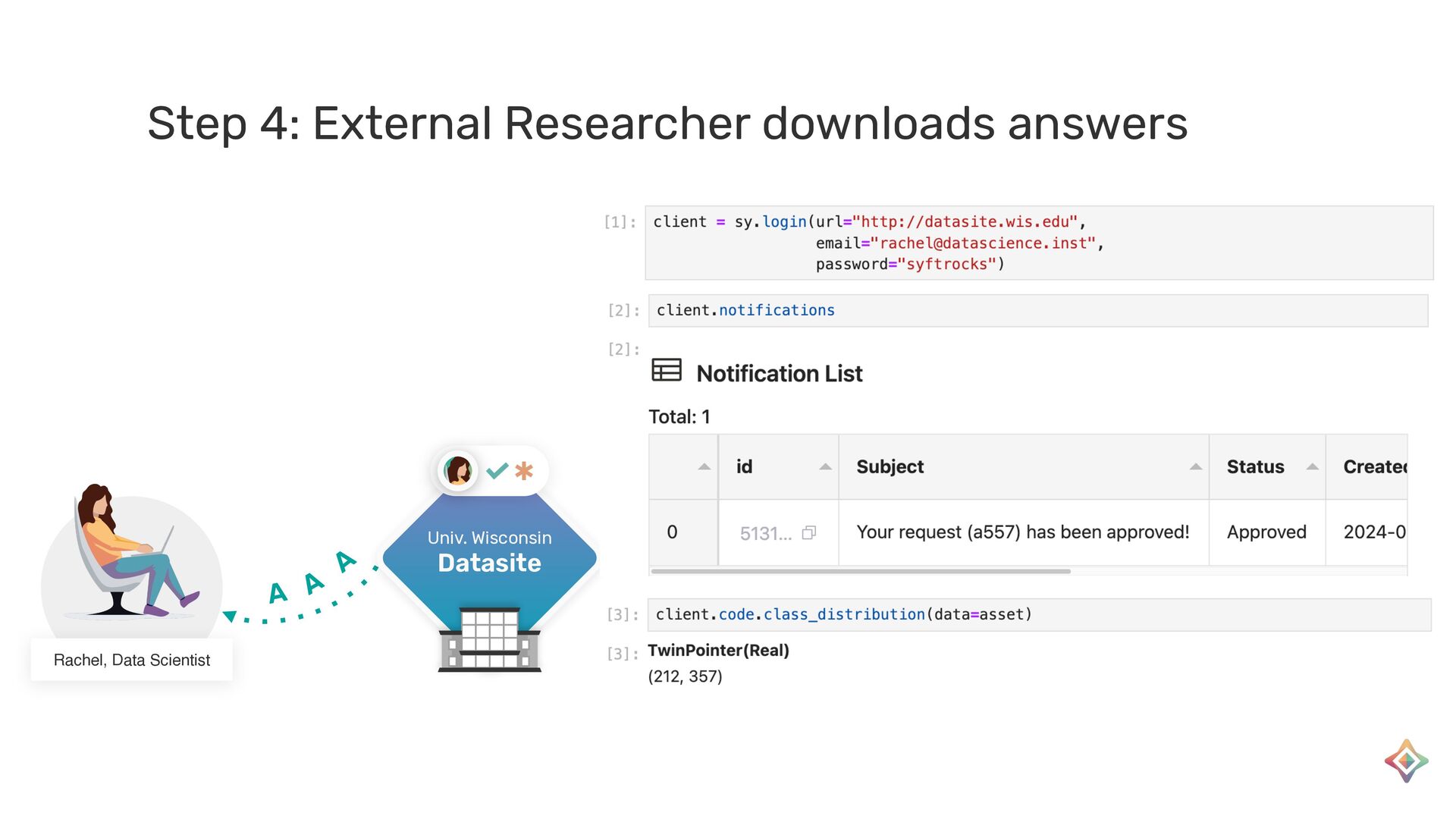{kind=link}
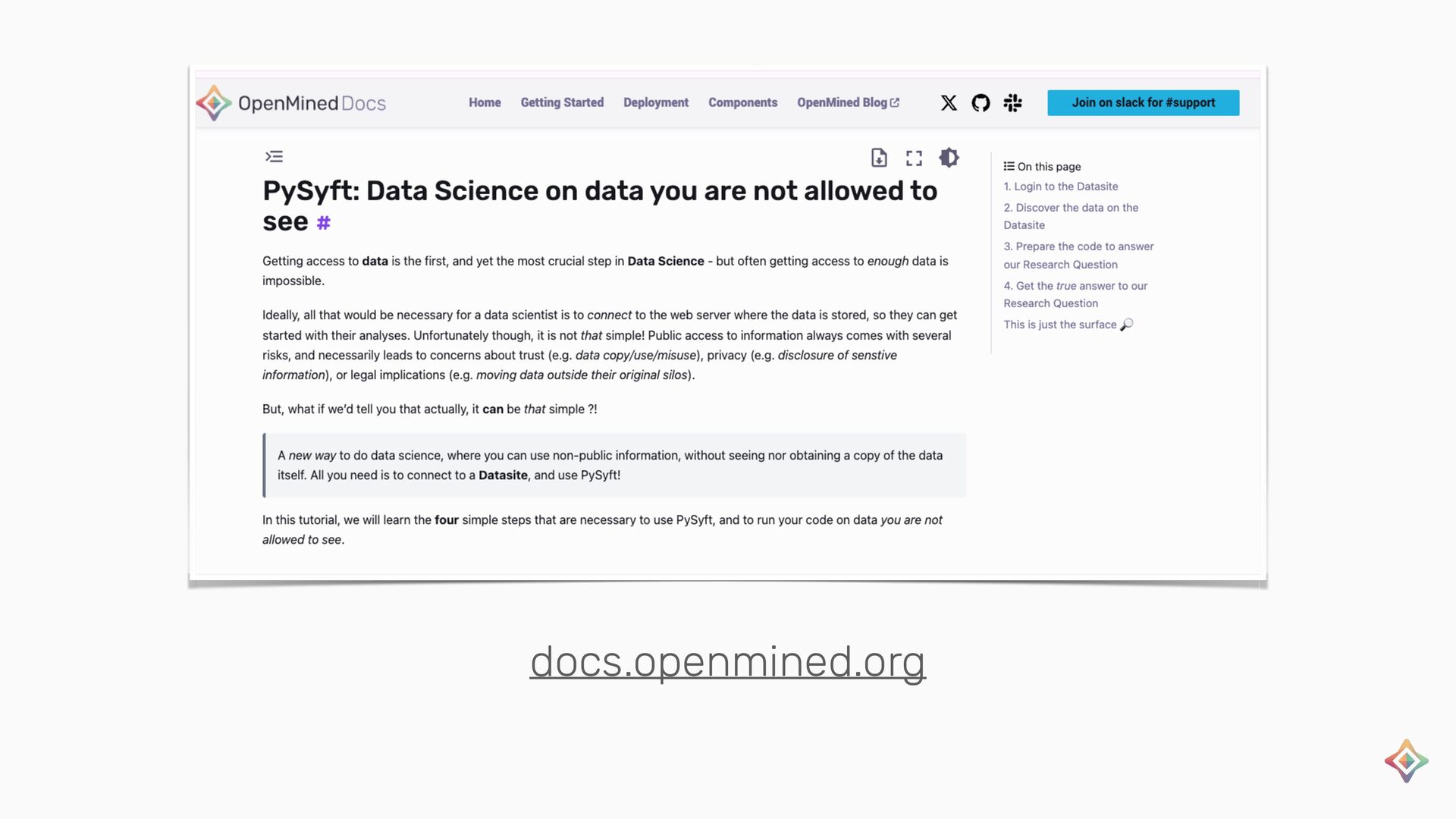{kind=link}
{kind=link}
{kind=link}
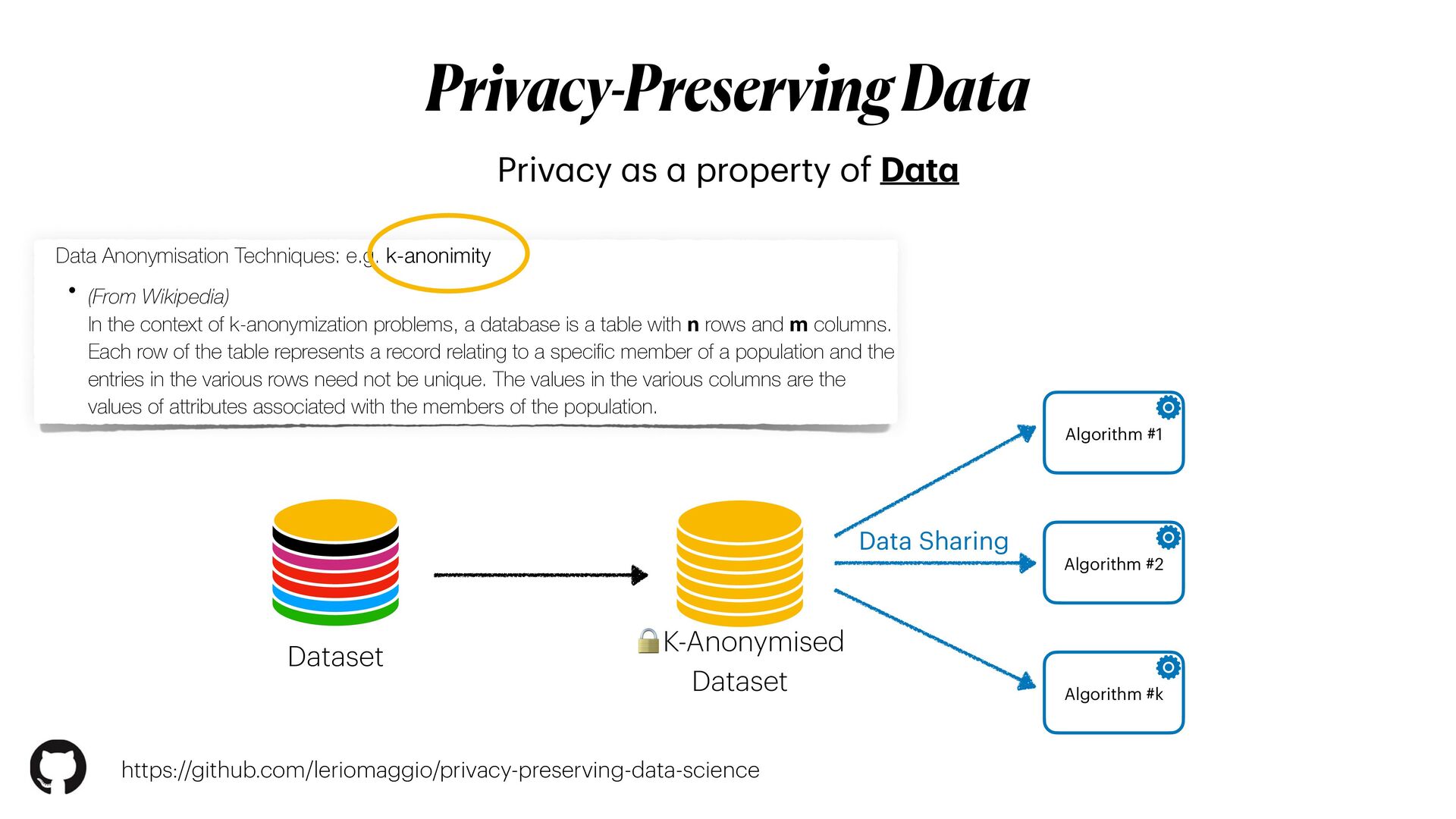{kind=link}
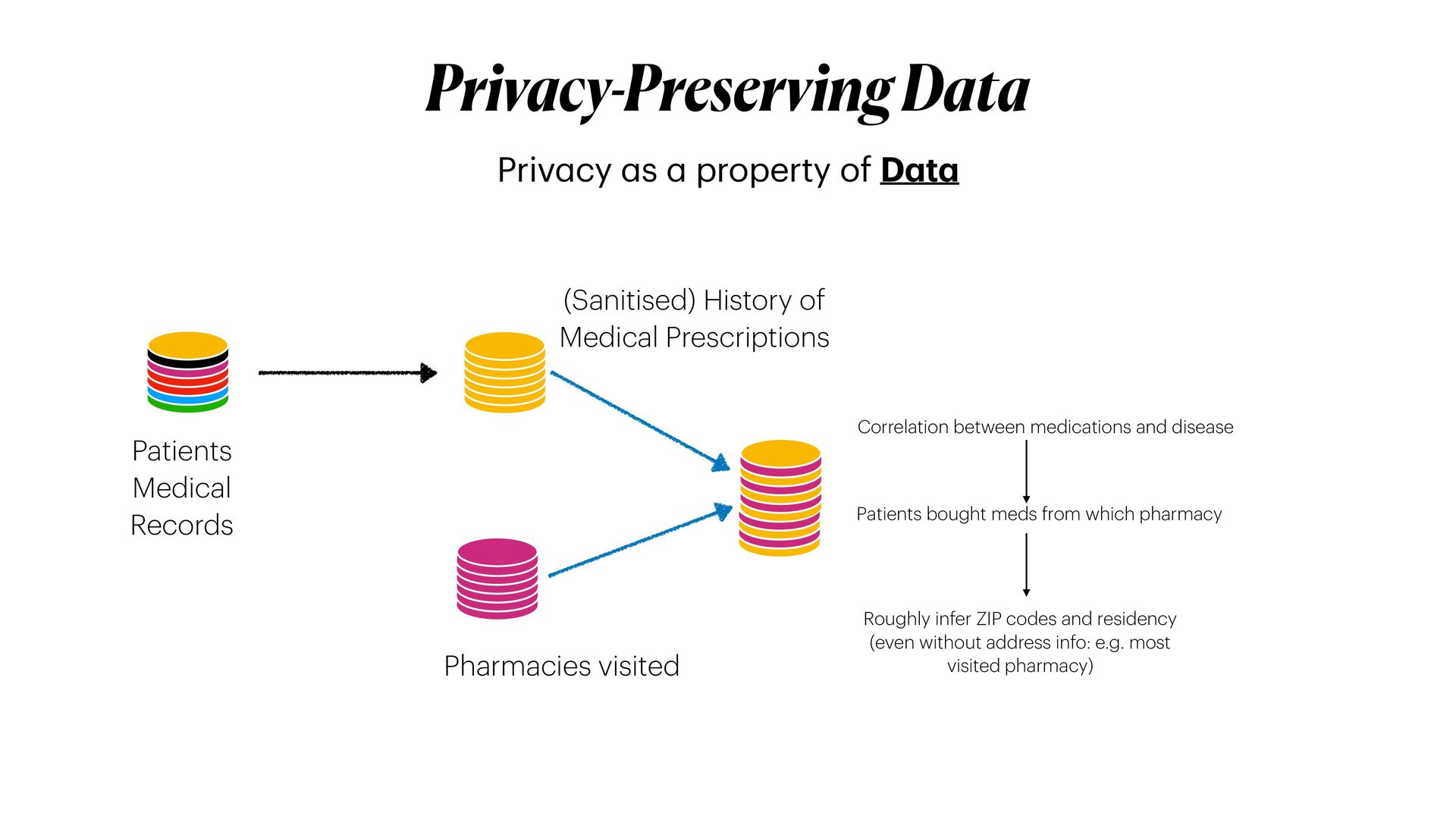{kind=link}
![Data Privacy Issues Source: https://venturebeat.com/2020/04/07/2020-census-data-may-not-be-as-anonymous-as-expected/ […] (we) show how these](https://files.speakerdeck.com/presentations/f7f9d5f09edd40699114a6b25d77081f/slide_82.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
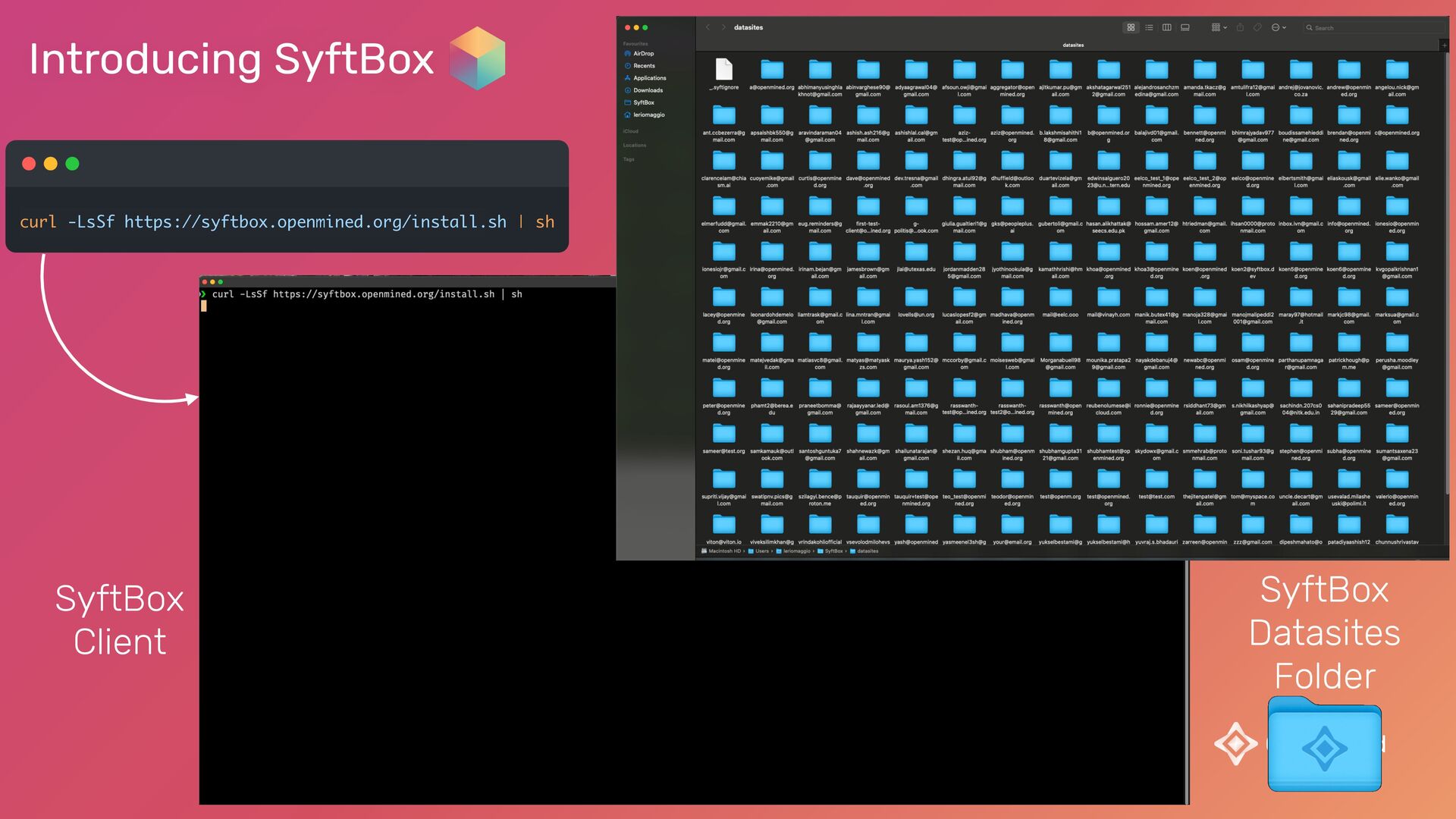{kind=link}
![syftbox.openmined.org/datasites/[email protected]/syft_stats.html](https://files.speakerdeck.com/presentations/f7f9d5f09edd40699114a6b25d77081f/slide_105.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
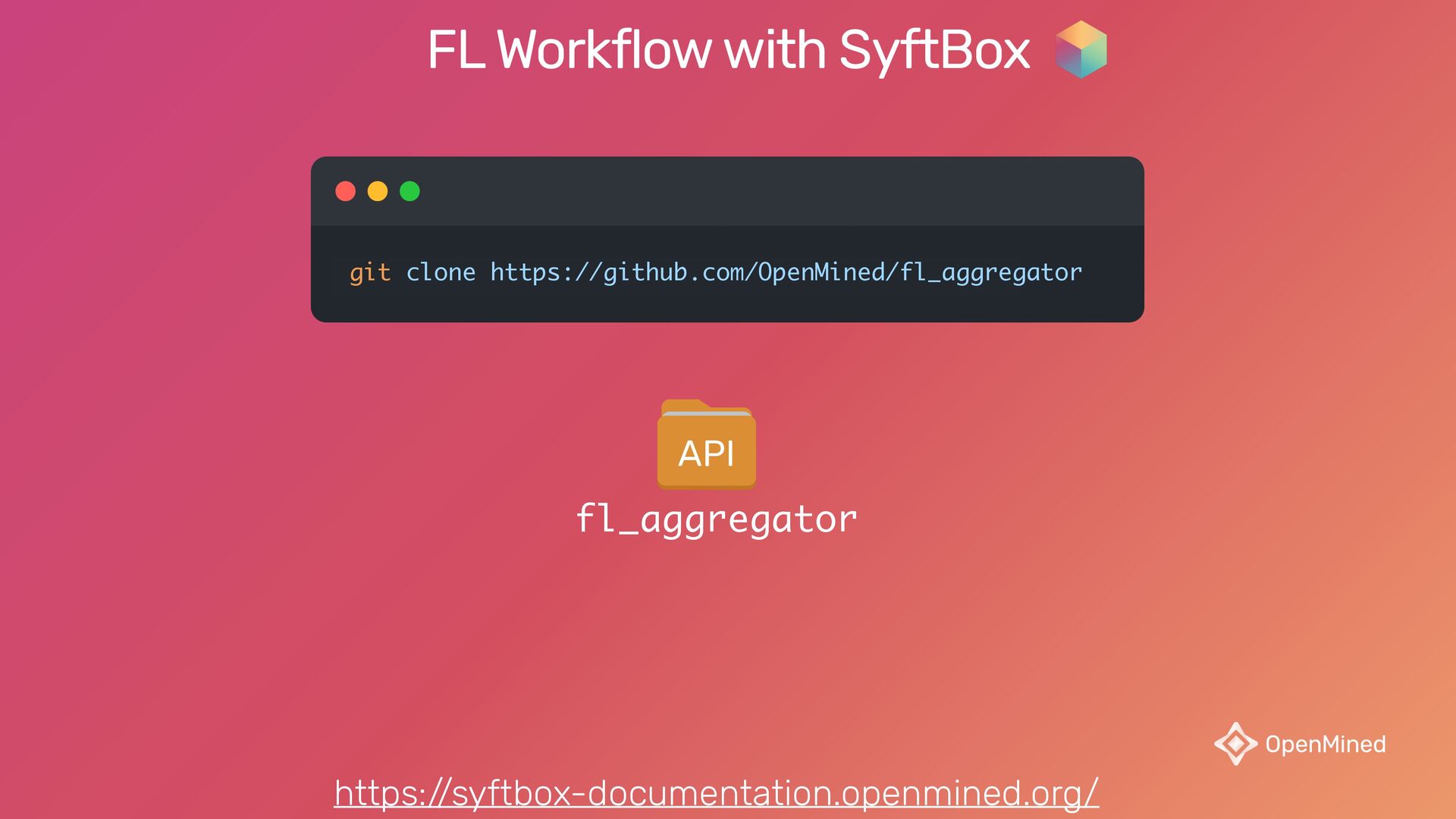{kind=link}
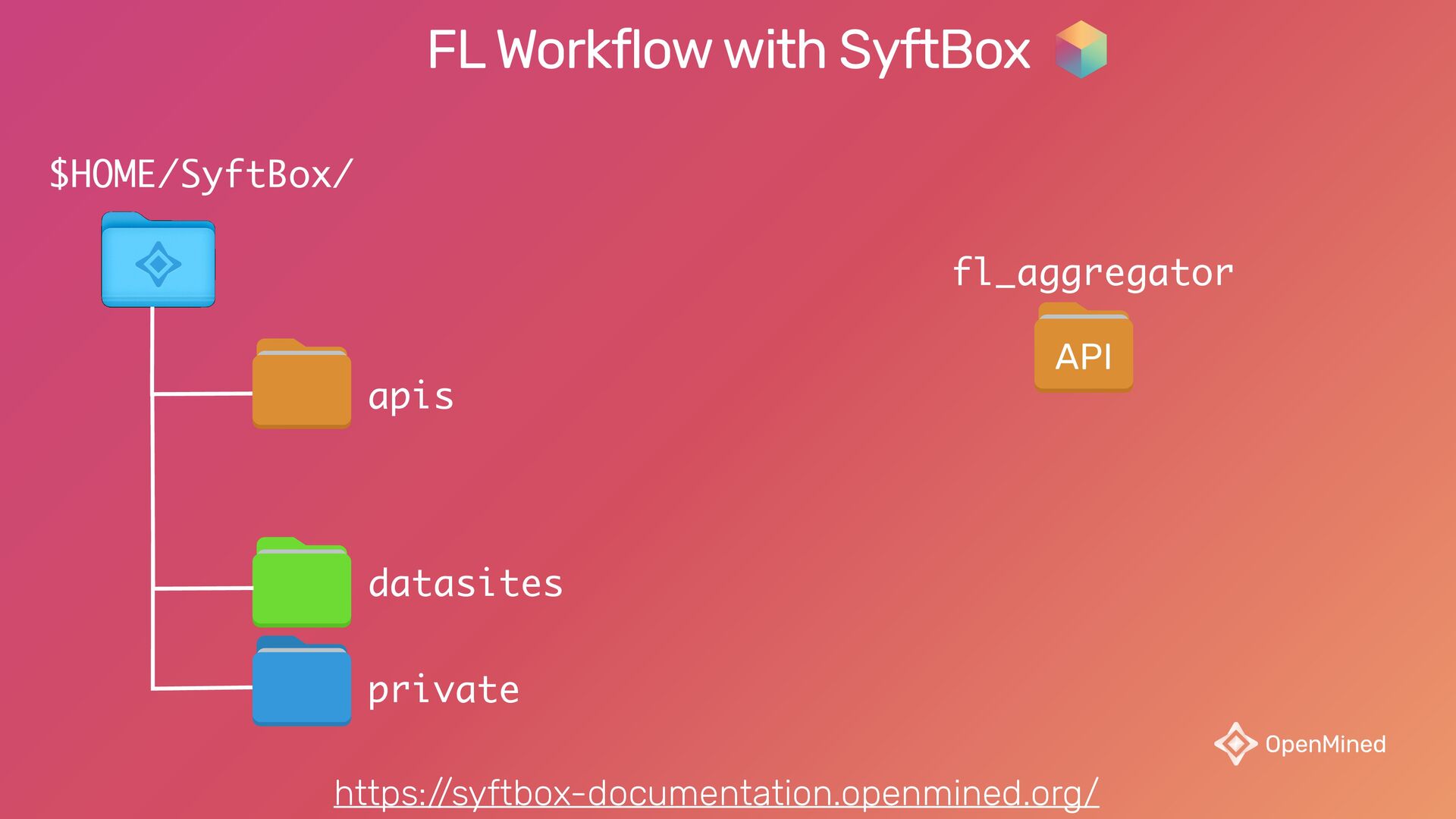{kind=link}
{kind=link}
{kind=link}
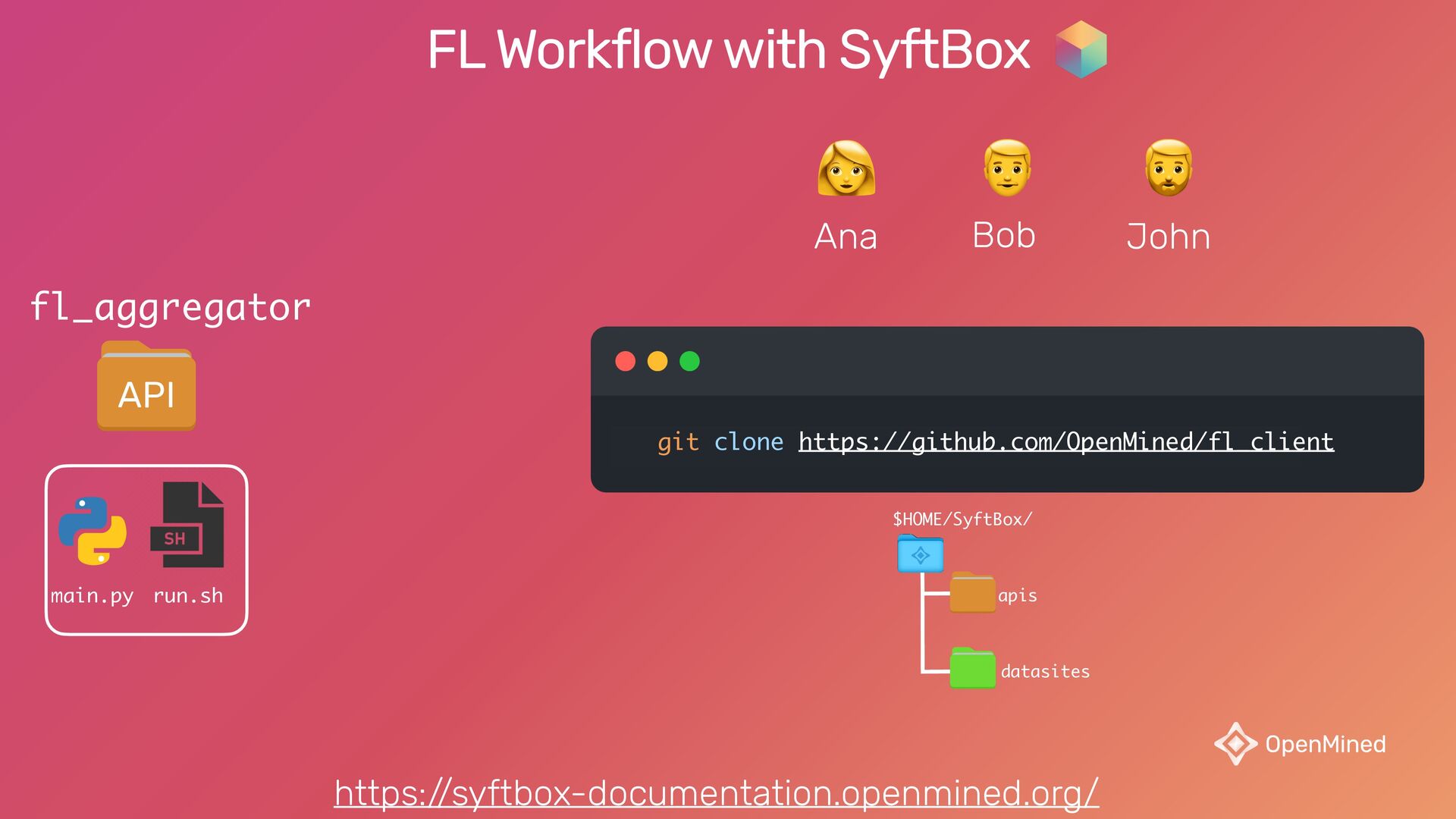{kind=link}
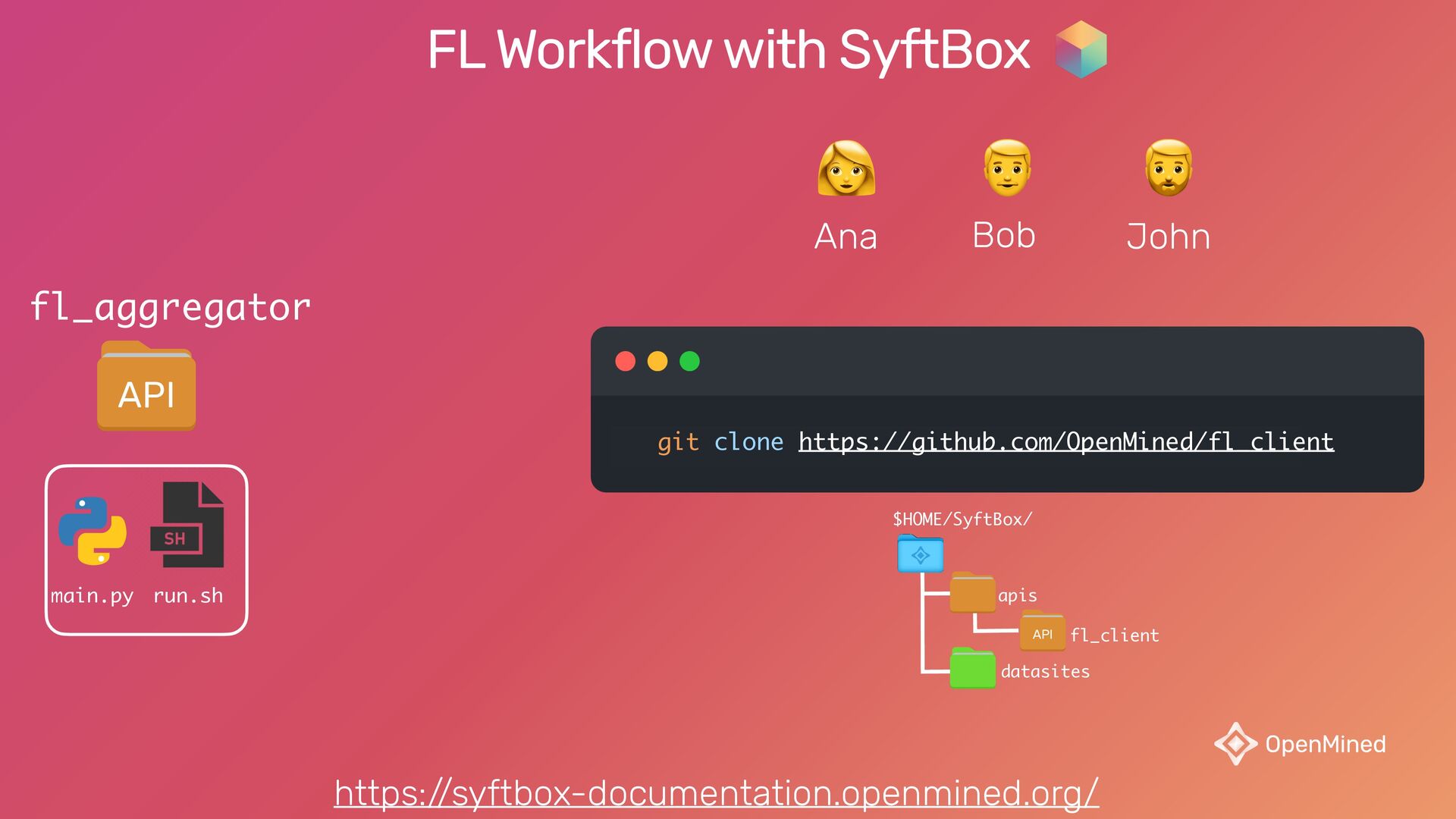{kind=link}
{kind=link}
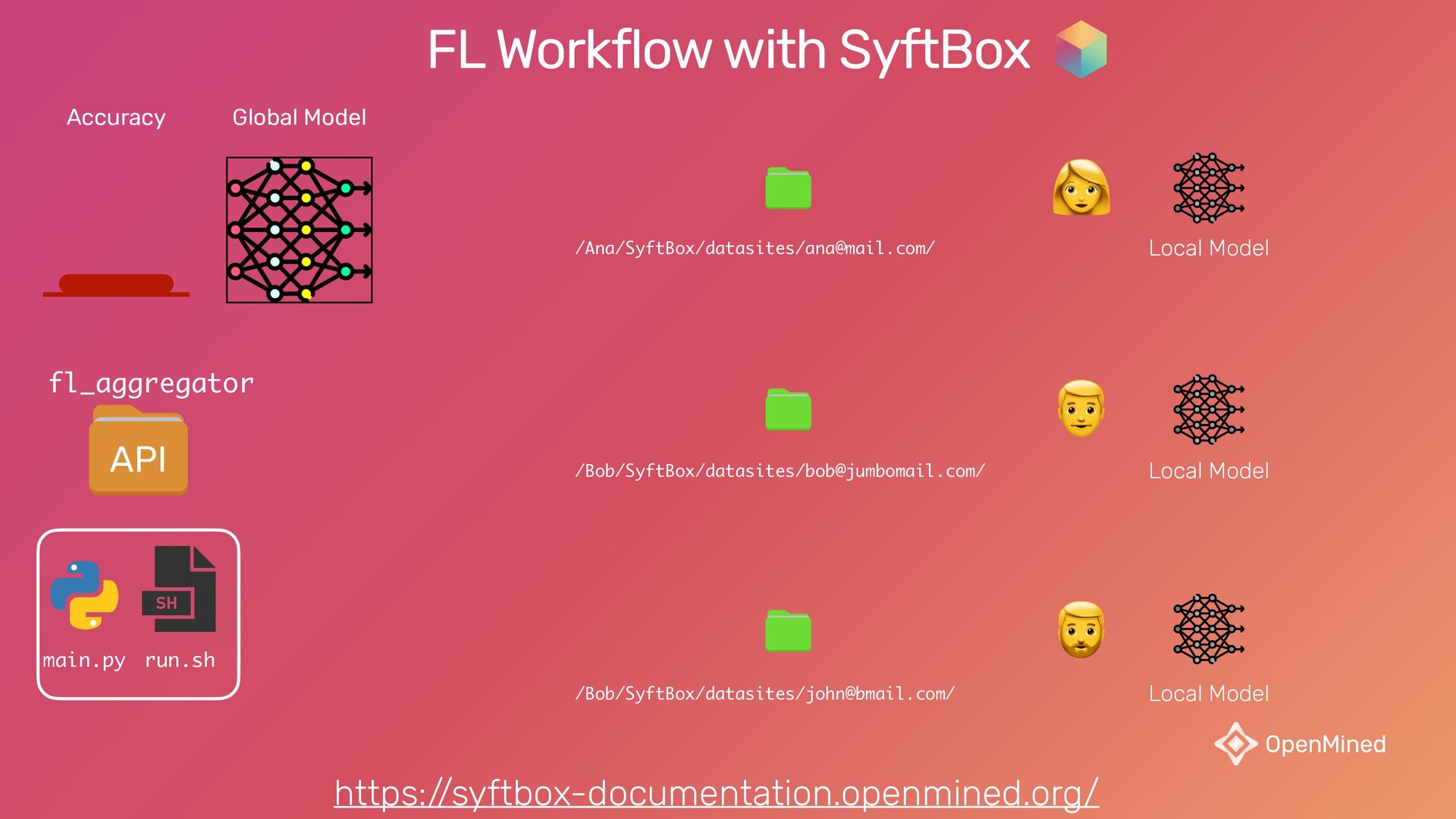{kind=link}
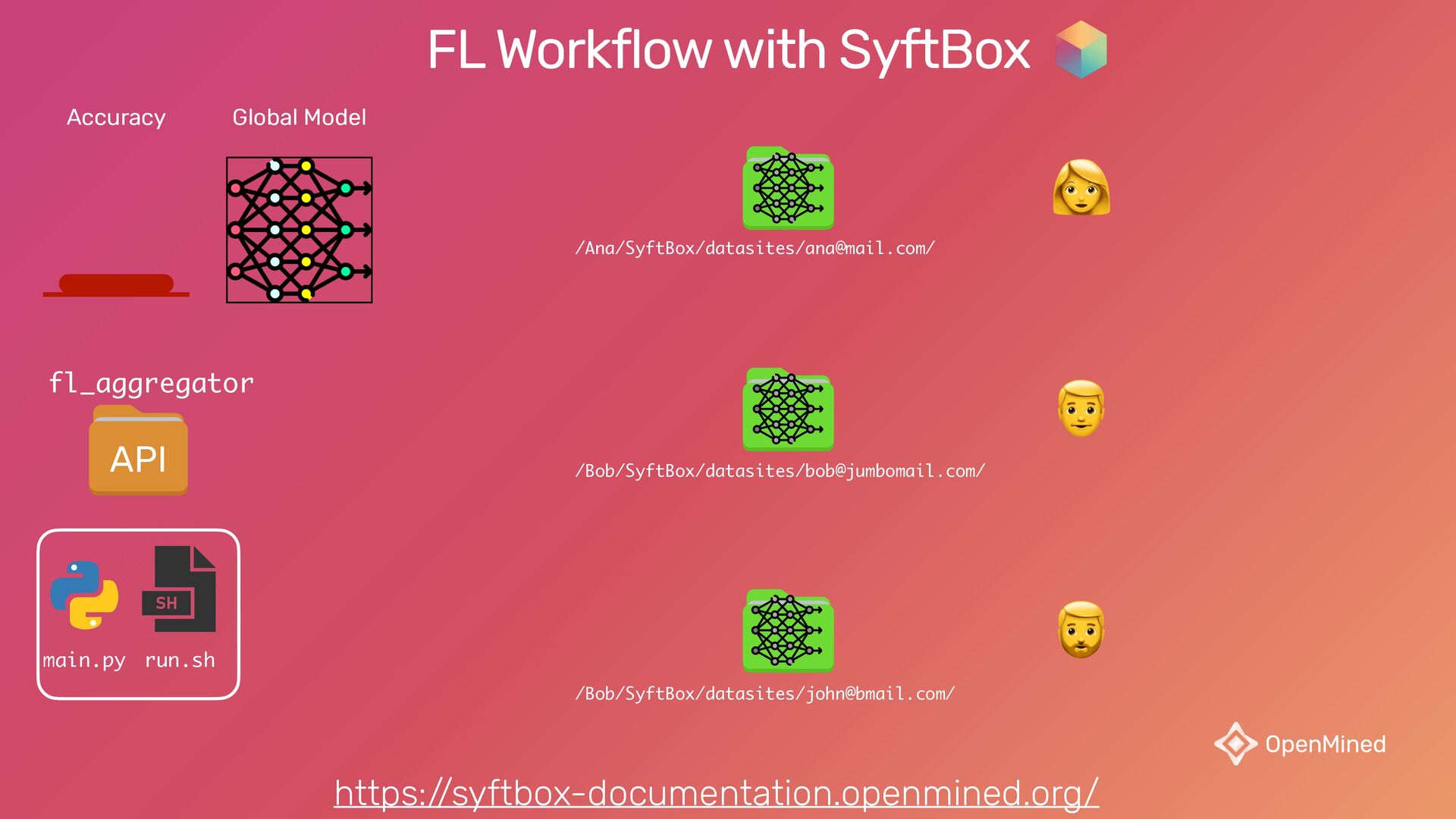{kind=link}
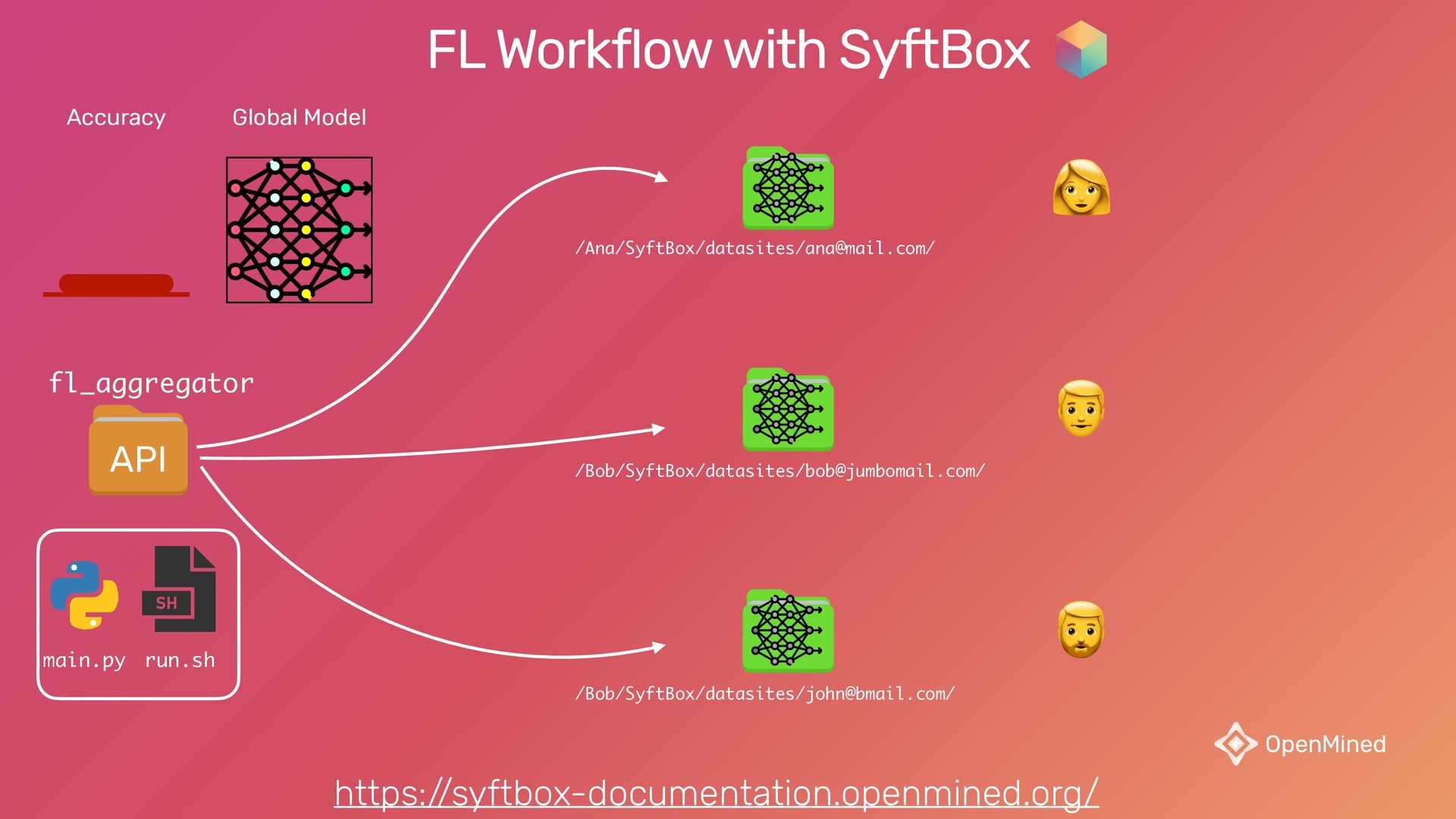{kind=link}
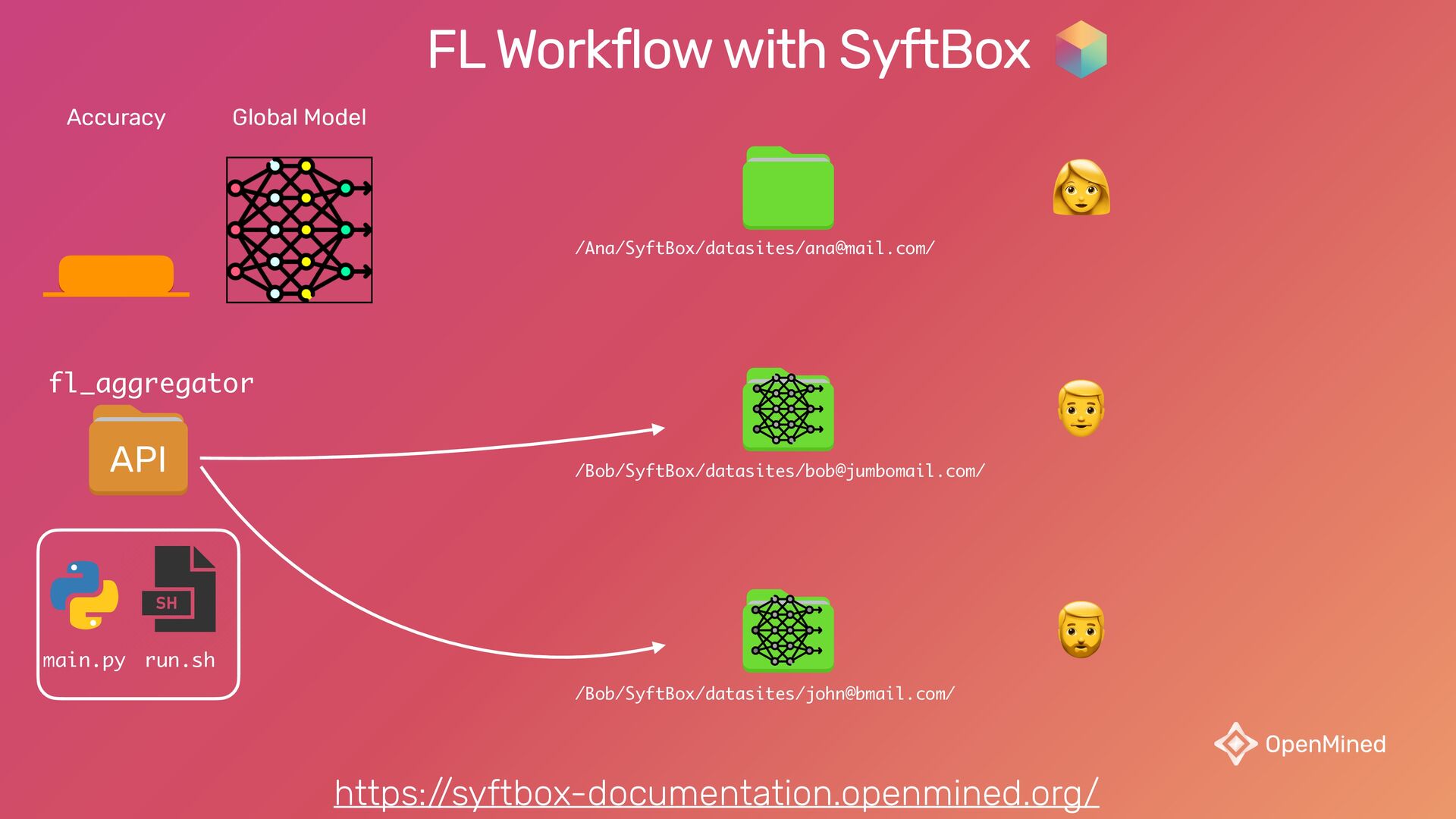{kind=link}
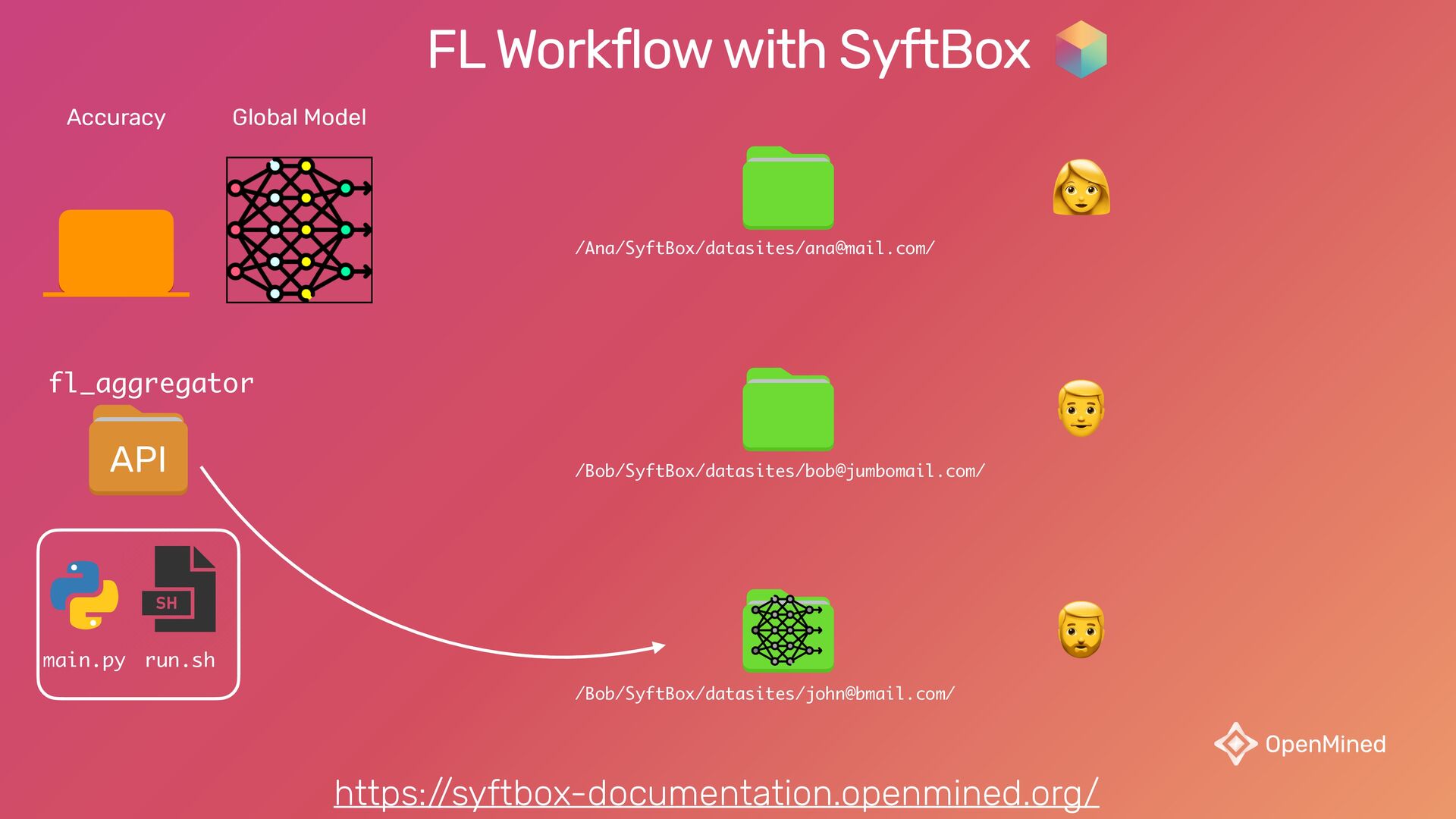{kind=link}
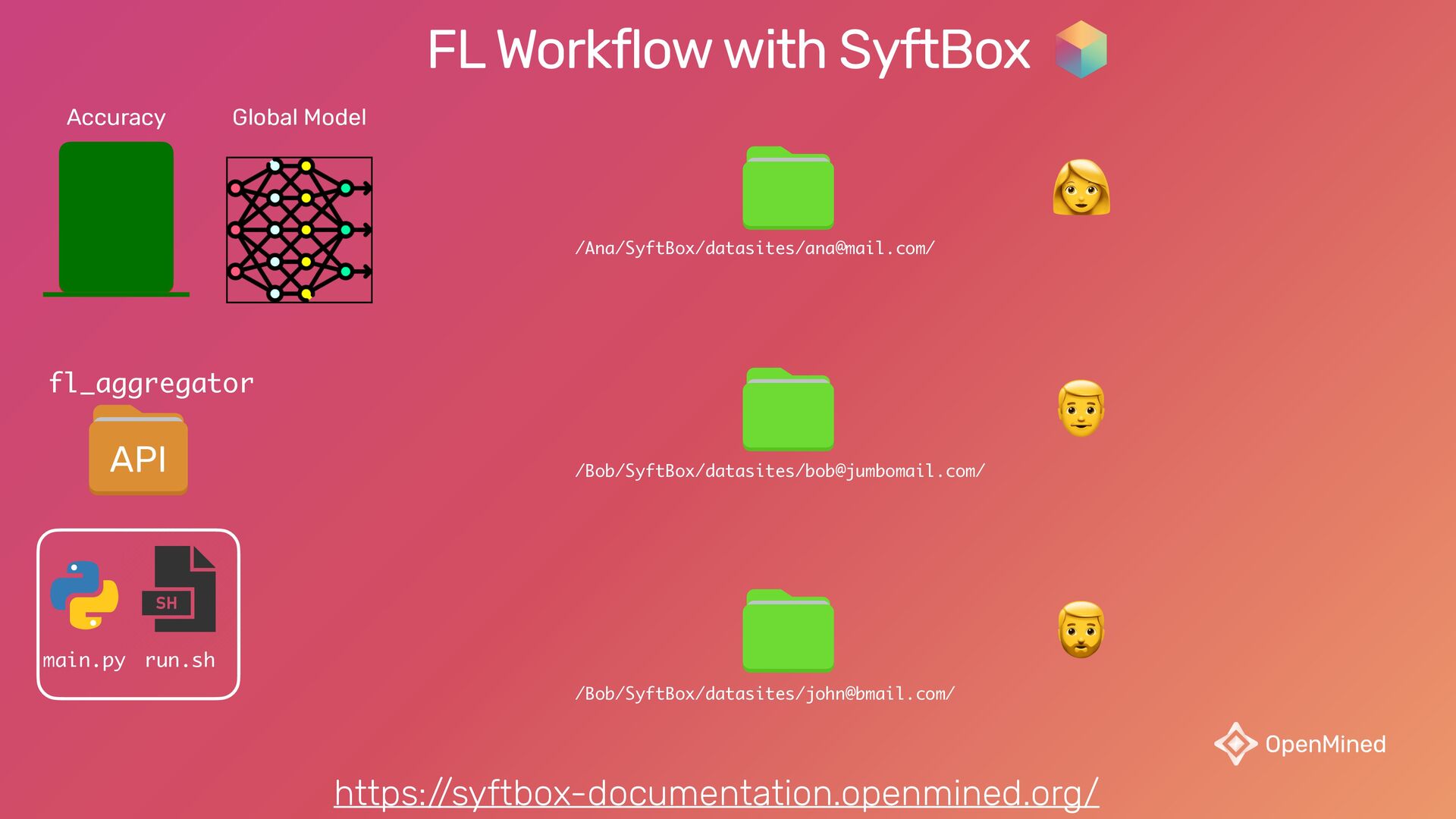{kind=link}
![Thank You! Valerio Maggio @leriomaggio [email protected] in/valeriomaggio Join the Community](https://files.speakerdeck.com/presentations/f7f9d5f09edd40699114a6b25d77081f/slide_122.jpg){kind=link}