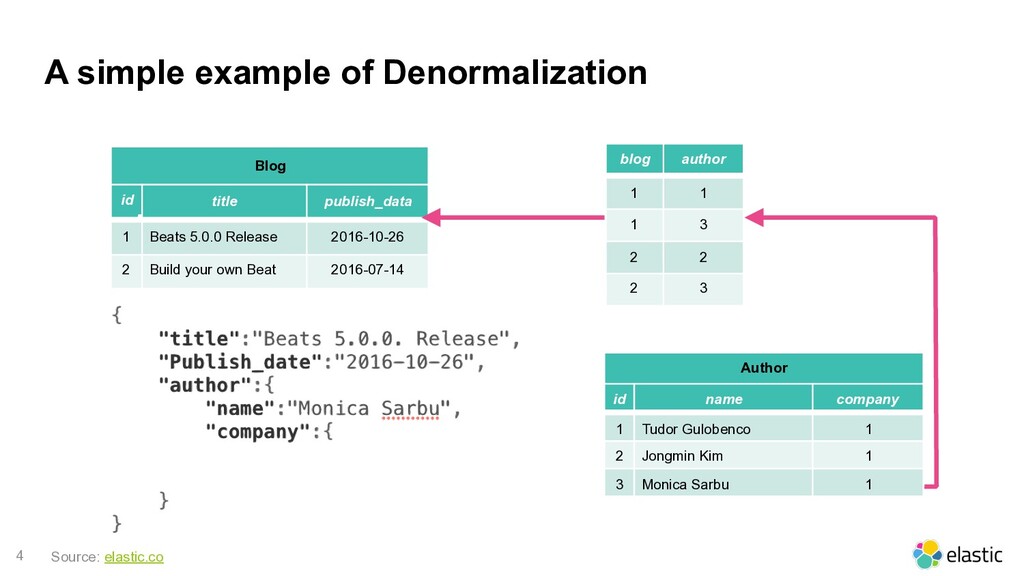
data refers to “flattening” data ‒ storing redundant copies of data in each document, instead of using some type of relationship ‒ _source is compressed which reduces the disk "waste" • Denormalization provides the best performance out of Elasticsearch ‒ That is the standard way to indexing documents in a search engine or in any NoSQL database Source: elastic.co
d title publish_data 1 Beats 5.0.0 Release 2016-10-26 2 Build your own Beat 2016-07-14 blog author 1 1 1 3 2 2 2 3 Author id d name company 1 Tudor Gulobenco 1 2 Jongmin Kim 1 3 Monica Sarbu 1
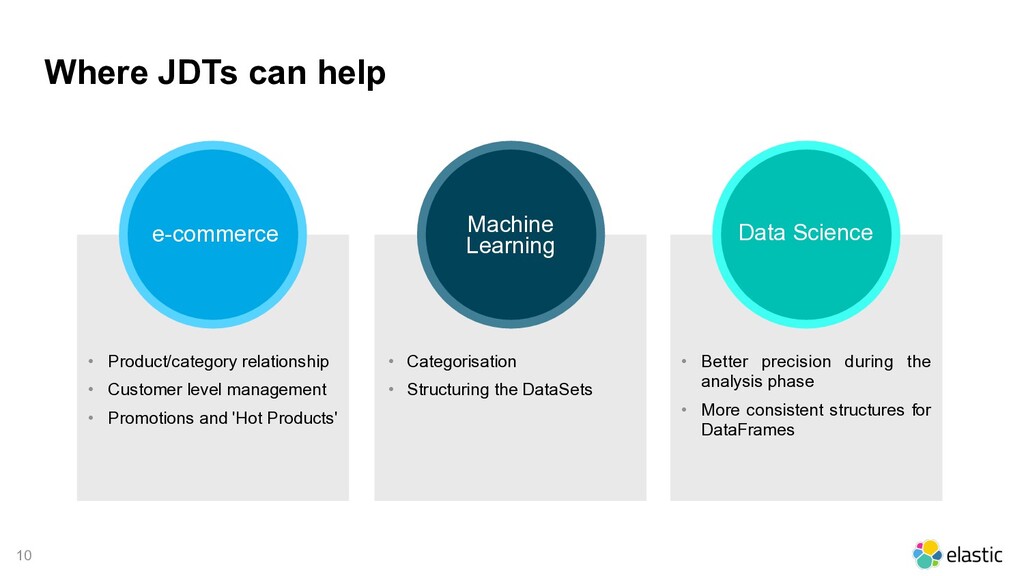
keep relations between documents stored in the same index. Available from version 6, they can be useful in many use cases like classification systems, categorising documents or products, frequent updates, etc... Let's have a look in depth...
if just a small part of it must be frequently updated. • Allows you to split data into multiple documents while maintaining a relationship between them. FREQUENT UPDATES
n c r e a s e p r e c i s i o n o n aggregations and full-text queries. • particularly suitable for a n a l y s i n g s c i e n t i f i c o r research documents. ANALYSIS
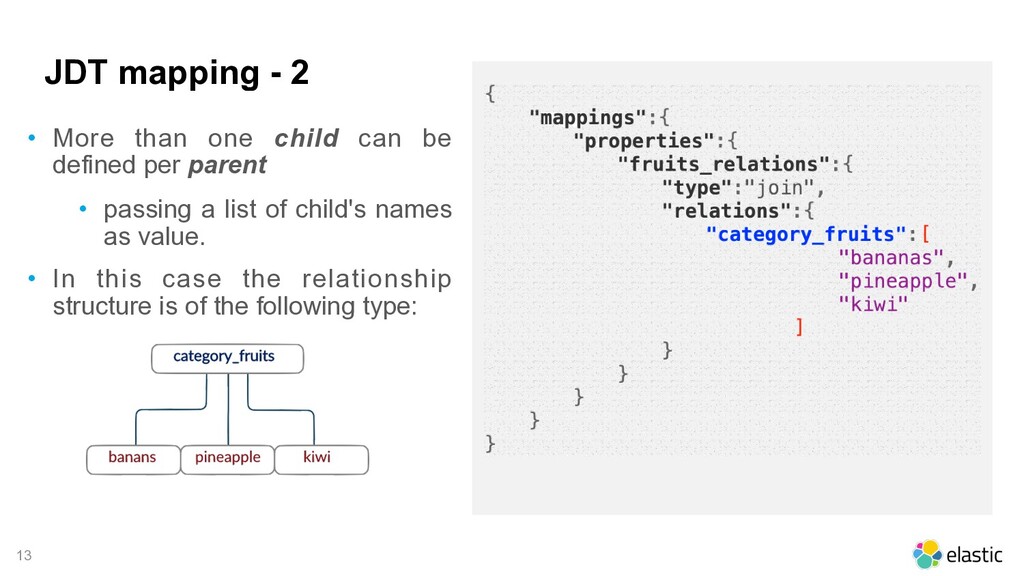
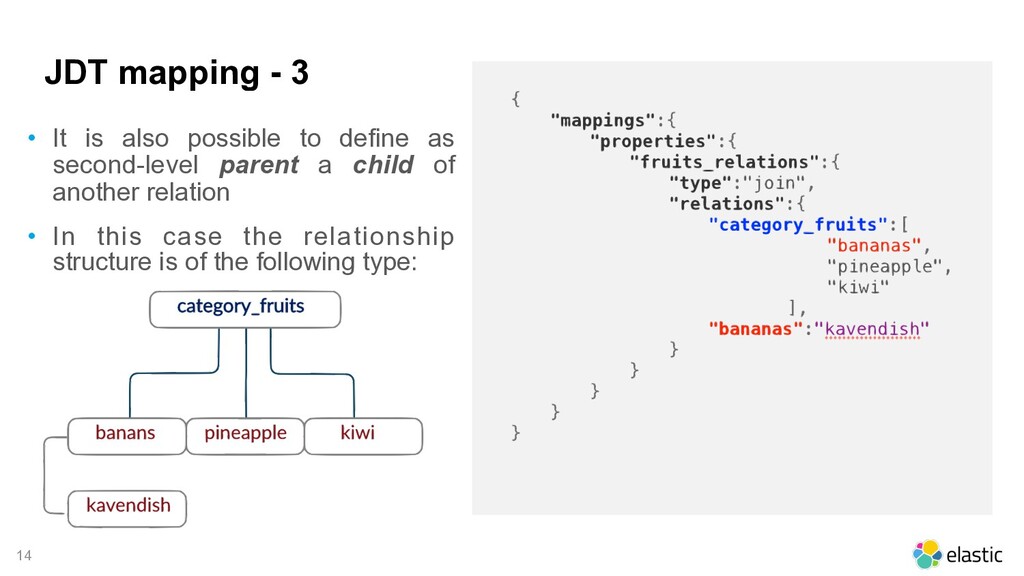
Definition must be done at mapping level • just custom mapping, they can't be mapped dynamically 2. More relations per join field allowed • List all parent:child that are needed 3. Can have hierarchical relationships • a child can also be declared as parent 4. More than one parent document can be created per relationship. • parents documents can be created independently and they will be at the same level Source: elastic.co
the join field • in this example 'fruits_relations' ... (ok it's definitely not the best name in the world, but we have a demo later!) • Then define the type as 'type: join' • The join type requires at least one parent/ child relationship. • in our example we have two parent: • category_fruits • category_citrus • and two child: • fruits • citrus
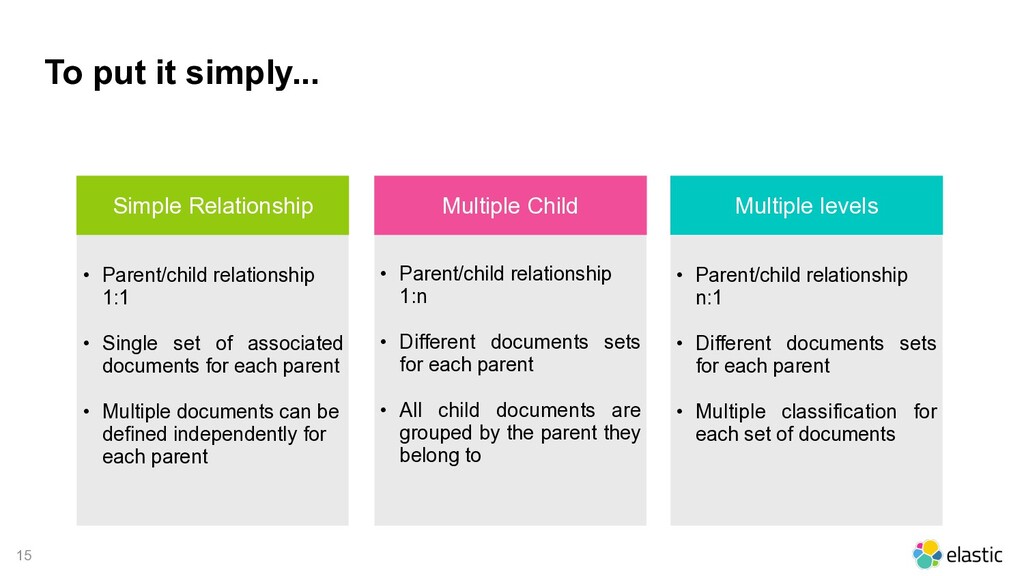
documents for each parent • Multiple documents can be defined independently for each parent • Parent/child relationship 1:n • Different documents sets for each parent • All child documents are grouped by the parent they belong to • Parent/child relationship n:1 • Different documents sets for each parent • Multiple classification for each set of documents To put it simply... Simple Relationship Multiple Child Multiple levels
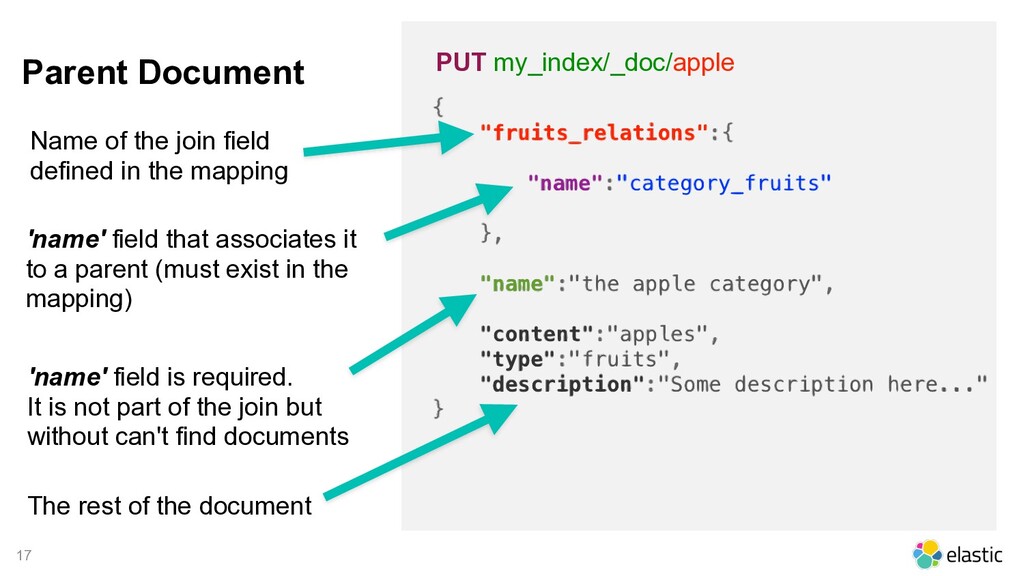
the mapping 'name' field is required. It is not part of the join but without can't find documents The rest of the document 'name' field that associates it to a parent (must exist in the mapping) PUT my_index/_doc/apple
the mapping The 'name' field is required as it was in the parent's document The rest of the document Field 'name' associates it with a child. The 'parent' field associates it with the _id of the parent
quantities of documents. To work with JDTs, the effort that elasticsearch makes for query or aggregation is greater than usual. • An index that maps a join field can also contain documents that have no relationship but, all those that use the relationship, must be indexed in the same shard. This means that the use of the _routing parameter is mandatory. (Which makes mandatory the use of _routing parameter for any operation). • Only a join field is allowed per index. • A parent can have an indefinite number of child, but a child can refer to only one parent Source: elastic.co
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}