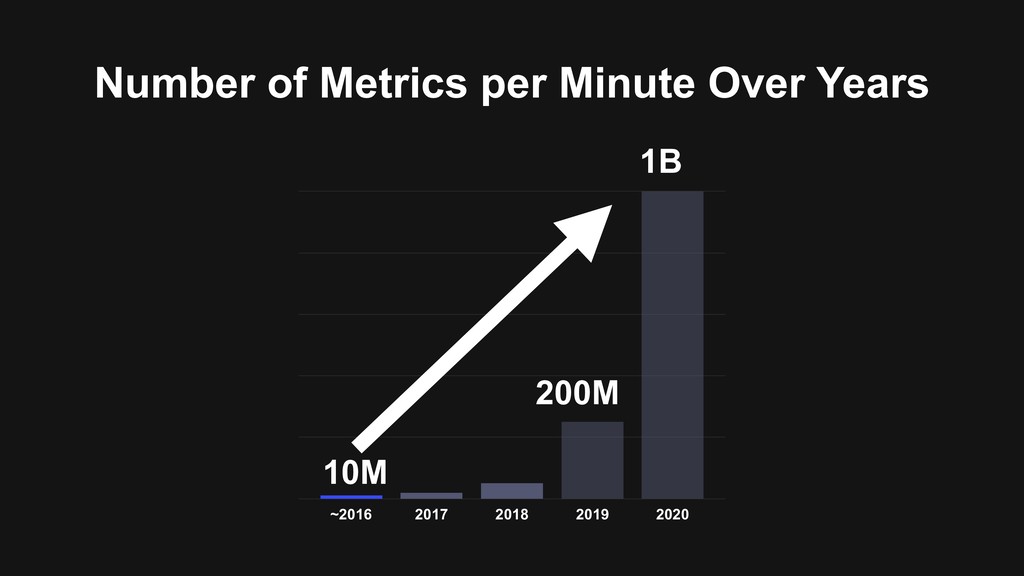
Write Throughput + High Cost Clickhouse Not Satisfy Expected Read Throughput TimeScaleDB Not Satisfy Expected Read Throughput HeroicDB Not Satisfy Expected Write Throughput FB Beringei Only in Memory Module, Not Support Tag Base Query Netflix Atlas Only in Memory Module M3DB Unstable + no Document (1 Year Ago)
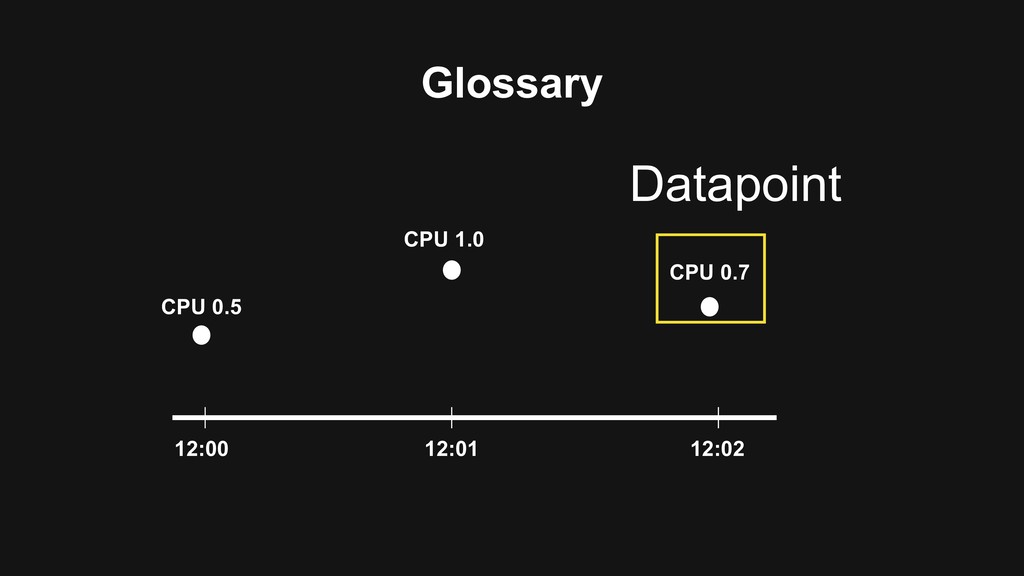
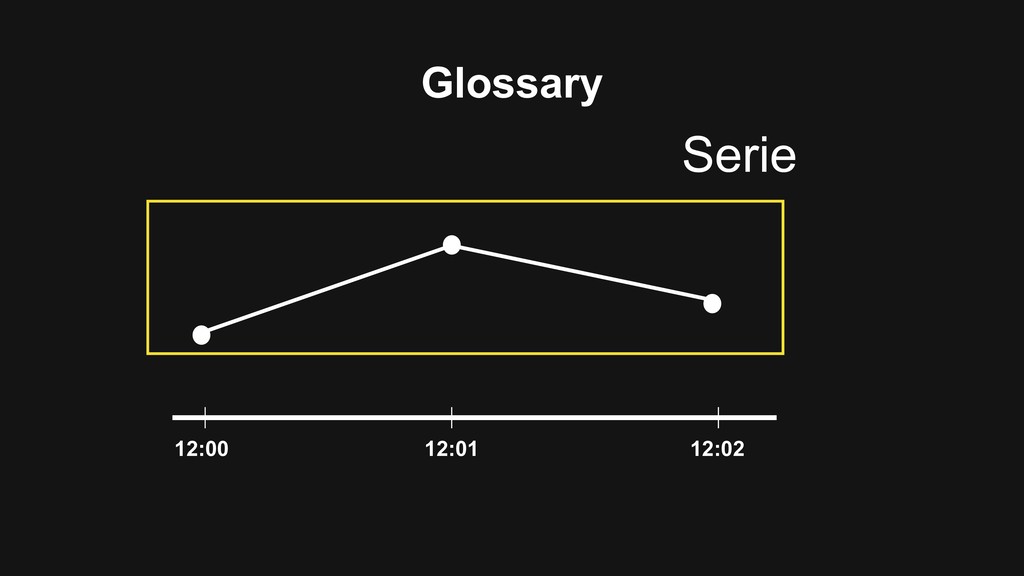
uint64 Label map[string]string Datapoints [] Datapoint } type Datapoint struct { Value float64 Timestamp int64 } type Storage interface { Put(Series []Serie) QueryRange(Label map[string]string, fromTs int64, toTs int64) []Datapoint } 4.000.000 Serie Per Sec 1000 Query Range per Sec
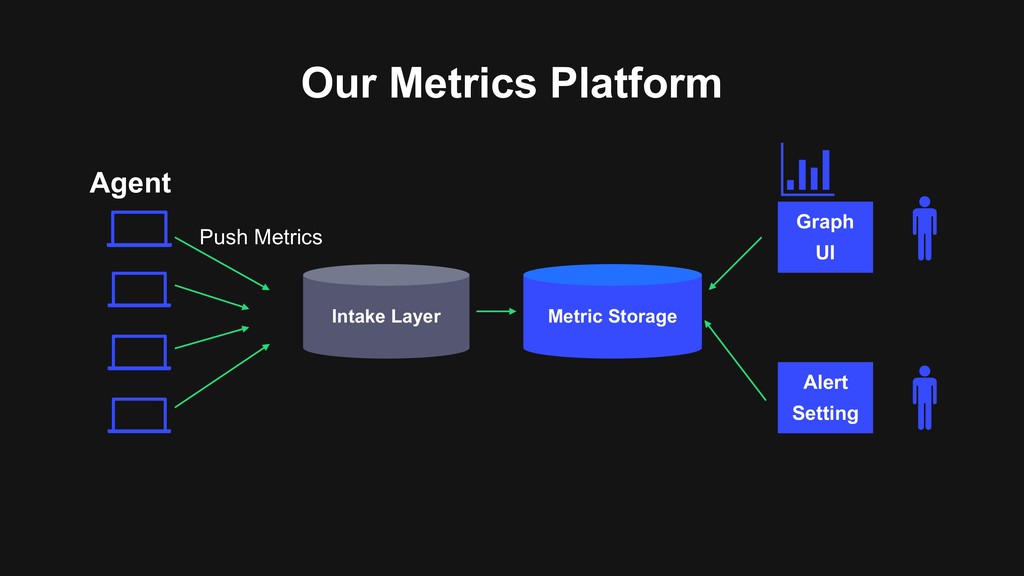
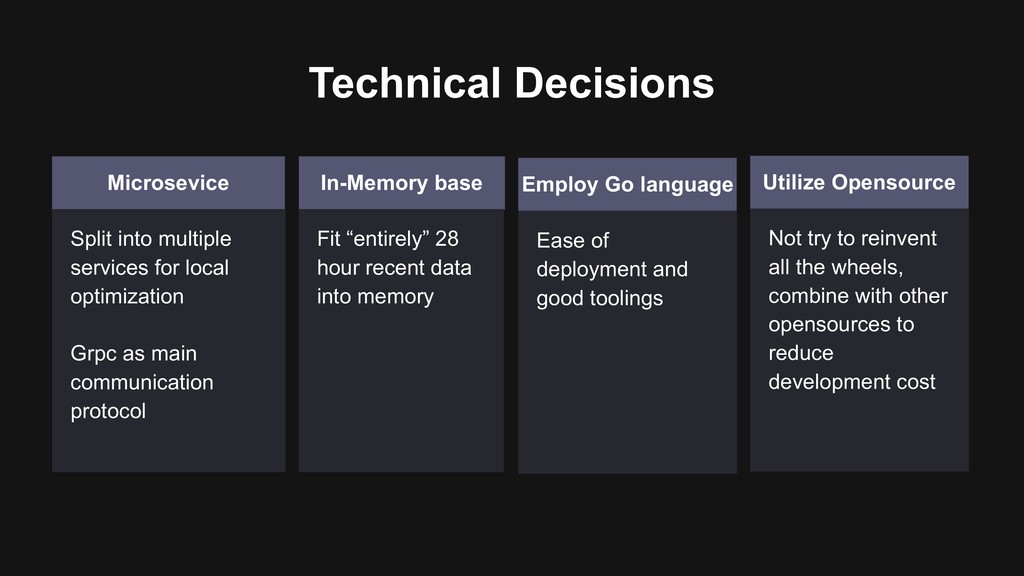
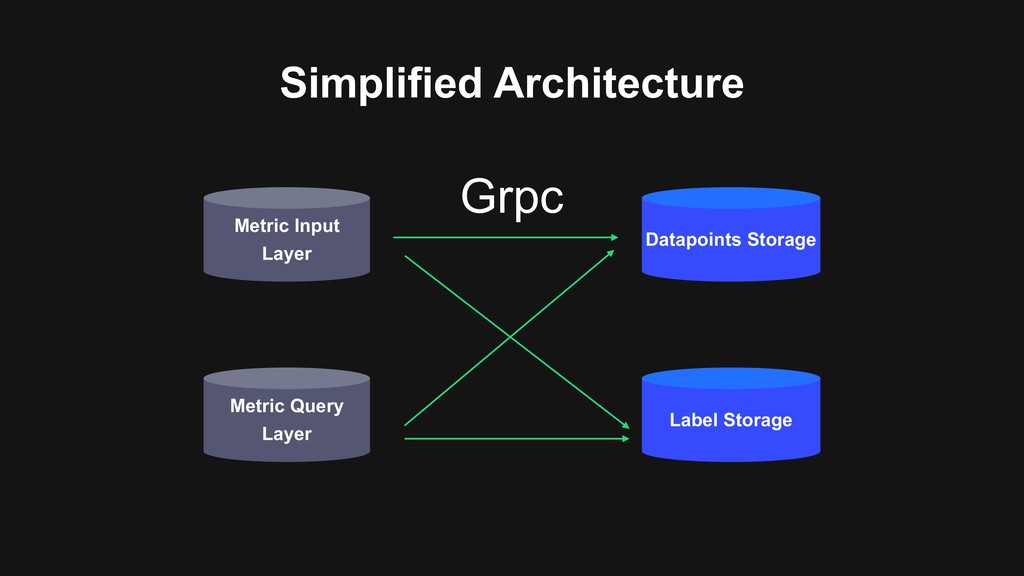
into memory Microsevice Split into multiple services for local optimization Grpc as main communication protocol Employ Go language Ease of deployment and good toolings Utilize Opensource Not try to reinvent all the wheels, combine with other opensources to reduce development cost
into memory Microsevice Split into multiple services for local optimization Grpc as main communication protocol Employ Go language Ease of deployment and good toolings Utilize Opensource Not try to reinvent all the wheels, combine with other opensources to reduce development cost
into memory Microsevice Split into multiple services for local optimization Grpc as main communication protocol Employ Go language Ease of deployment and good toolings Utilize Opensource Not try to reinvent all the wheels, combine with other opensources to reduce development cost
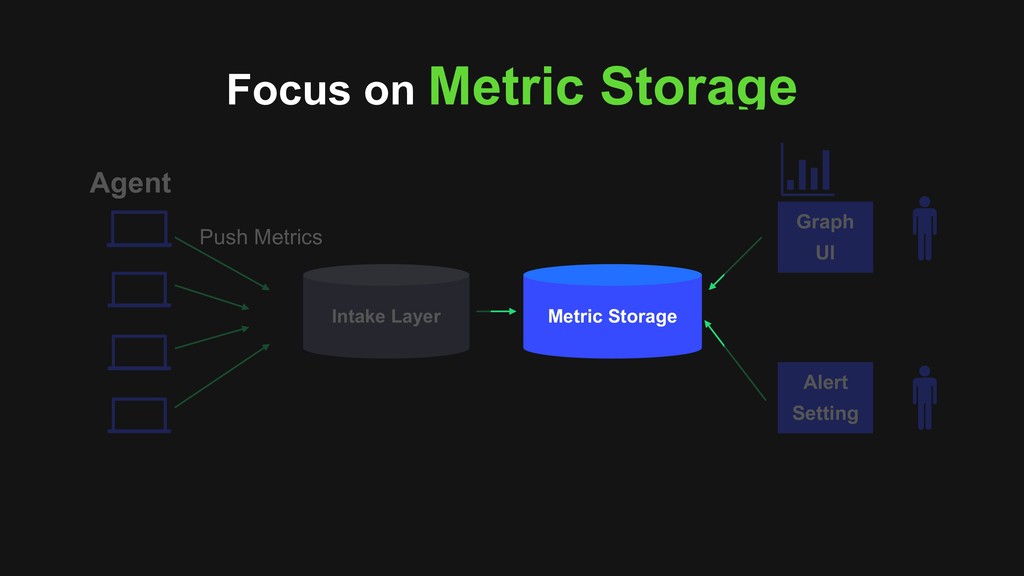
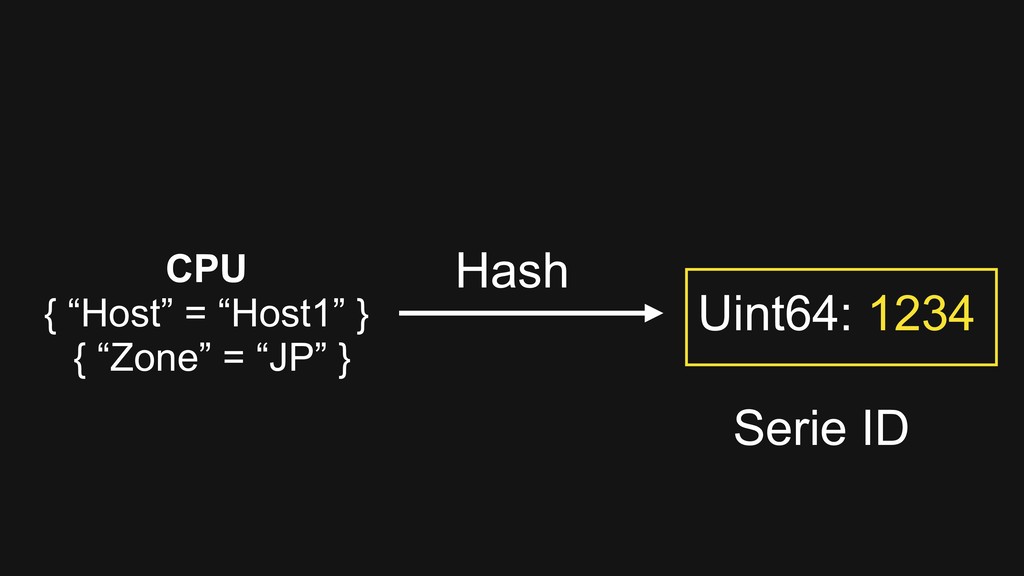
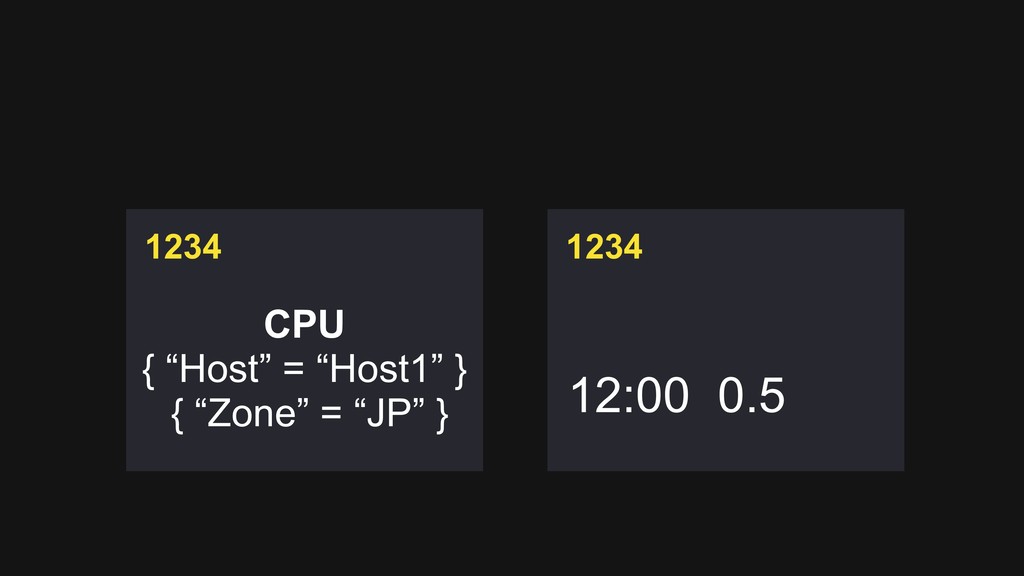
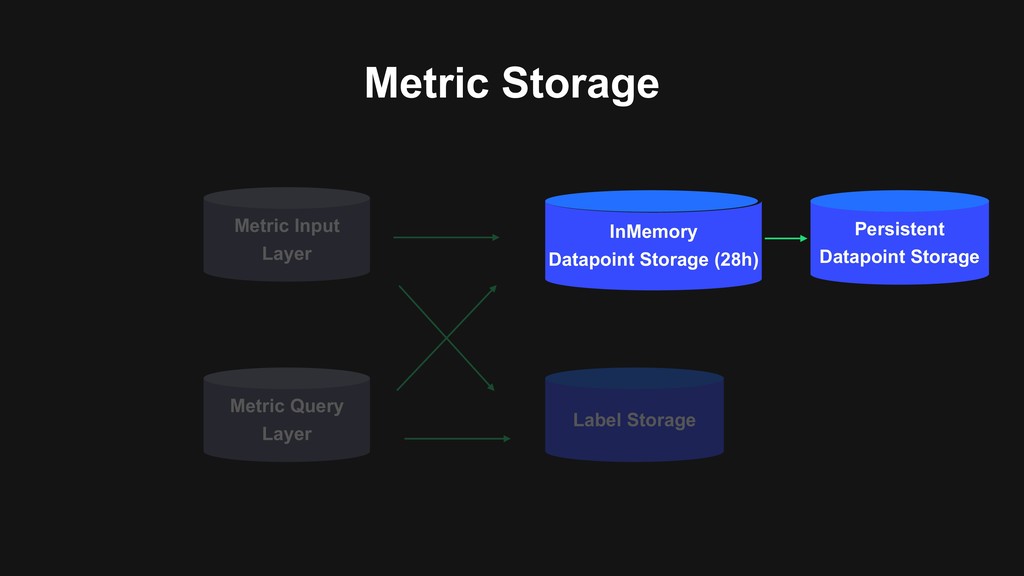
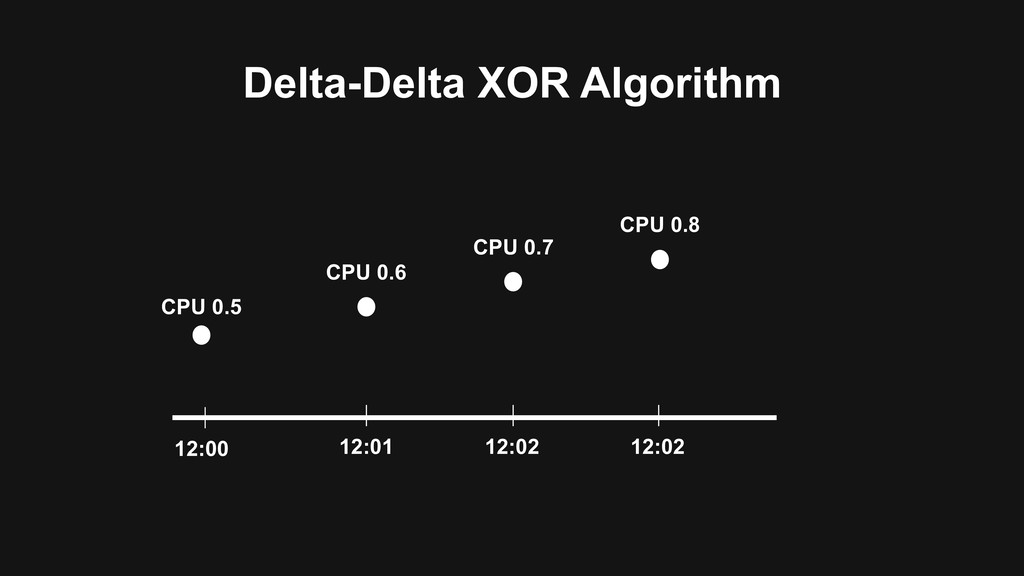
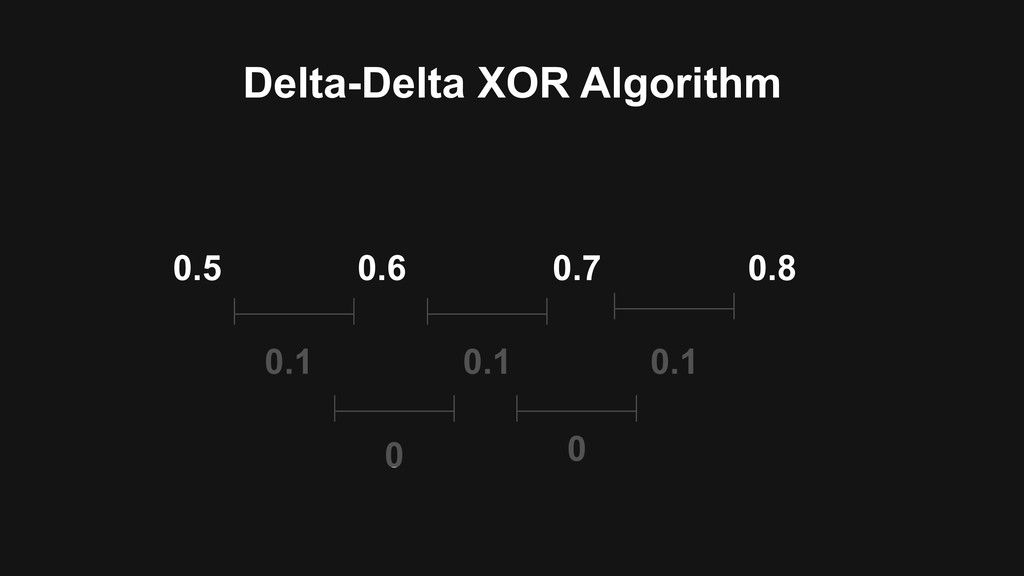
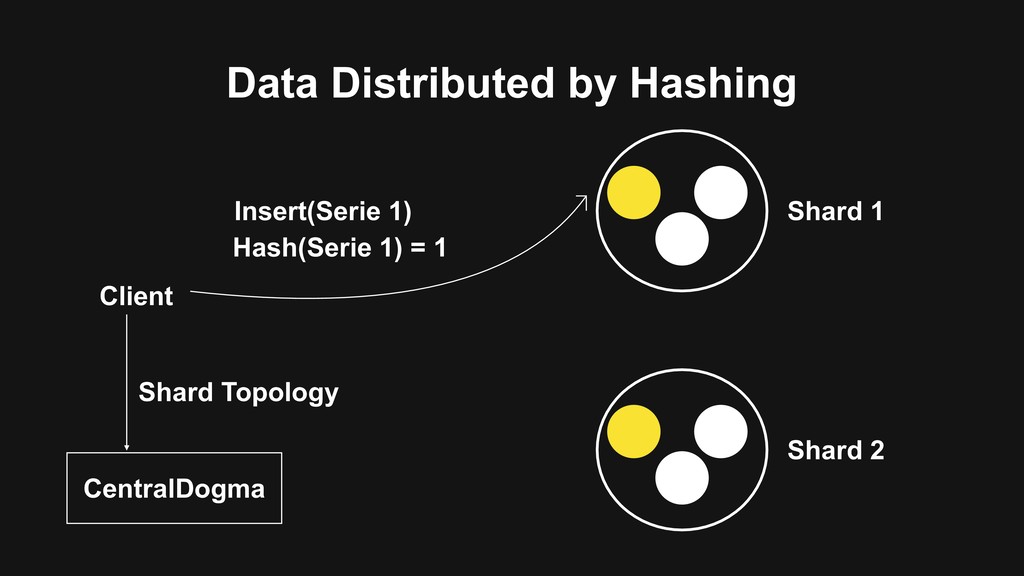
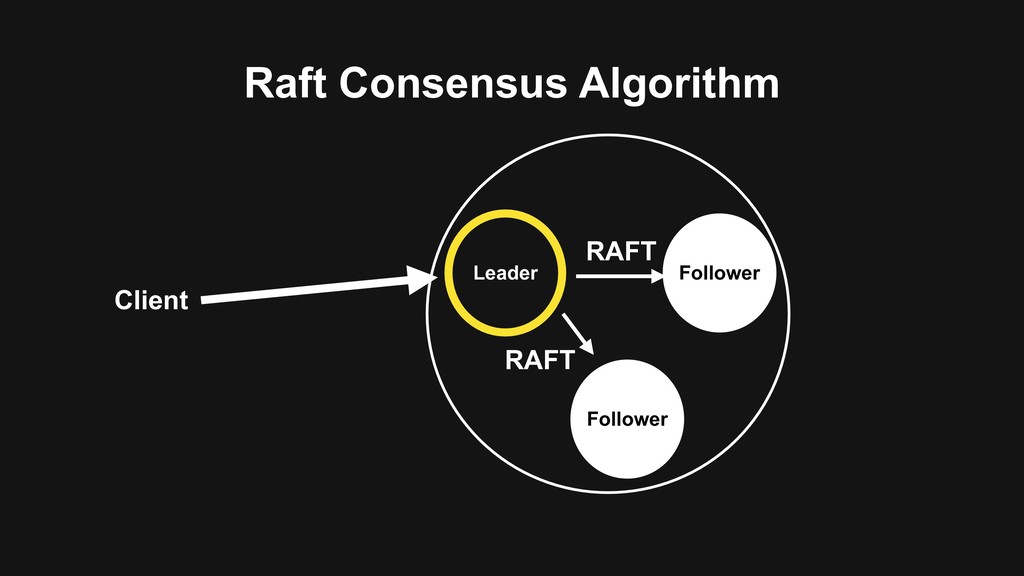
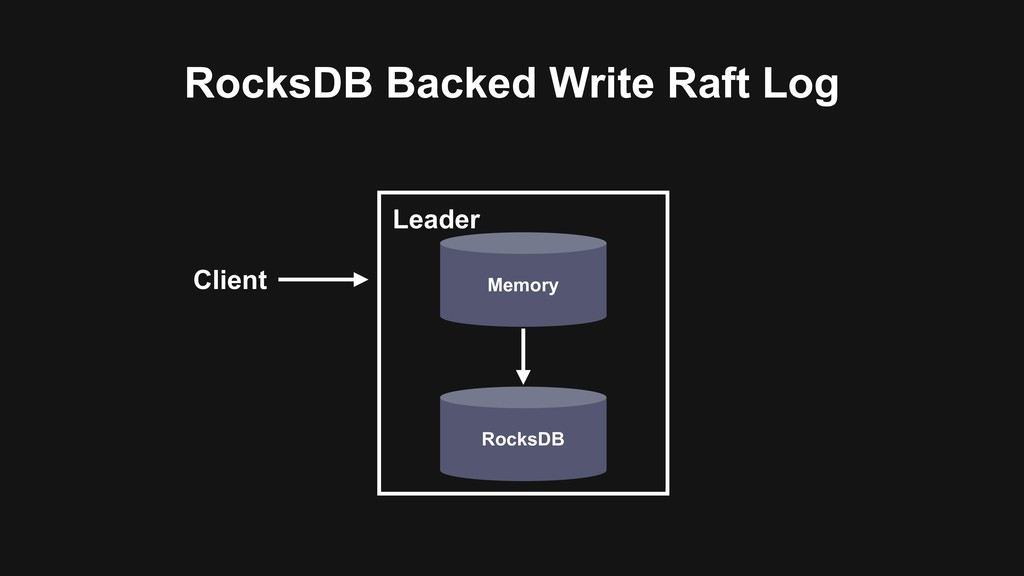
memory • Use Delta-Delta XOR algorithm to compress data points > Vertical scale by hash-base serie id distribution > High-Availability with rocksdb as log backend and Raft concensus protocol for replication
memory > Use Delta-Delta XOR algorithm to compress data points > Vertical scale by hash-base serie id distribution • High-Availability with rocksdb as log backend and Raft concensus protocol for replication
into memory Microsevice Split into multiple services for local optimization Grpc as main communication protocol Employ Go language Ease of deployment and good toolings Utilize Opensource Not try to reinvent all the wheels, combine with other opensources to reduce development cost
(binary) > Very good tooling for profiling (CPU/memory..) • Very helpful for building memory intensive application > Has GC but still able to control memory layout
into memory Microsevice Split into multiple services for local optimization Grpc as main communication protocol Employ Go language Ease of deployment and good toolings Utilize Opensource Not try to reinvent all the wheels, combine with other opensources to reduce development cost
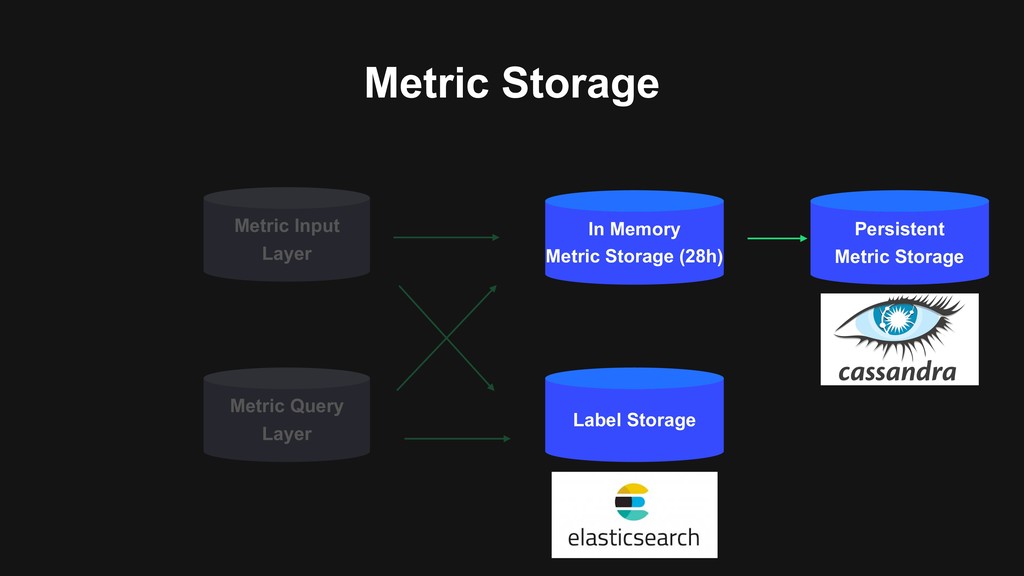
for label index layer > More perfomance, more reliablility, better cost optimization > Multi-Region deployment for disaster discovery > New storage base ecosystem (Alert, On-Call…)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![TSDB Storage type Serie struct { Id uint64 Label map[string]string](https://files.speakerdeck.com/presentations/3194419ac6e74d45bd73c5fd63a6343a/slide_37.jpg){kind=link}
![TSDB Storage type Serie struct { Id uint64 Label map[string]string](https://files.speakerdeck.com/presentations/3194419ac6e74d45bd73c5fd63a6343a/slide_38.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}