20-21 >place/grand nikko tokyo Entrance Take card out Tag card Face recognition Entrance Choose Floor Choose Floor Take card back 1. Face recognition replaces authentication 2. 1:1, Verification Elevator
20-21 >place/grand nikko tokyo 1. Face recognition replaces payment 2. 1:N, Recognition Vending Machine Choose product Take cash out Put cash Face recognition Choose product Get Product Get Product Take change back
Take card or change back Face recognition Before recognition After recognition Face recognition After recognition Before recognition Process with physical payment method 1. Simplify UX using face recognition 2. Insert second-verification flow when result is risky Wrap-Up
see keynotes 2. Personal information verification process by e-mail and name Check-in System Online Registration Line Up Check Personal Information Get Goods Watch Session Increased bottlenecks
than 1 second recognition speed 2. Remove process to verify name or personal information Check-in System Online Registration Line Up Face Recognition Get Goods Watch Session Reduced bottlenecks
the probe 3) Recognizing identity via simple thresholding Gallery (A Set of face features) Probe ( A face feature ) 1) Nearest-Neighbor Retrieval It’s face feature, not a face image.!! It’s face feature, not a face image.!!
Speed Deep Learning Framework Face Detection Face Alignment Face Recognition TensorFlow CoreML MLKit iOS Vision Framework iOS Android MacOS Windows Linux 99% Accuracy 0.1 Second Speed
Tracking Pose Estimation Low-Resolution Image Resize High-Resolution Image Post Processing Alignment Recognition Feature Z X Y Human Info Bounding Box Facial Landmark Face Feature Euler Angle
network only ++: Backbone + head Model Latency [ms] Model size[MB] Input Device Pelee [1] 43.86+ ~5.00 320x320 iPhone8 (GPU) Ours 5.74+ 0.14++ 320x320 iPhone7 (CPU) [1] Robert J. Wang et. al, Pelee: A Real-Time Object Detection System on Mobile Devices, NeurIPS, 2018
CPU Real-time Face Detector with High Accuracy, IJCB, 2017 Model mAP+ Latency [ms] Model size [MB] Input Device (engine) FaceBoxes[1] 96.0 21.40 3.83 320x240 Xeon (pytorch) Ours 96.0 22.50 0.29 320x240 Xeon (pytorch) Intel(R) Xeon(R) CPU E5-2630 v3 @ 2.40GHz +: Mean averaged precision is a measure of how accurately the position of the object is detected. (The higher the better) Equal level of mAP 10x reduction in model size‑ FDDB ROC Curve The model located in upper left
Model MSE(Fullset) DSRN[3] 5.21 SBR[1] 4.99 RCN-L+ELT-all[4] 4.90 PCD-CNN[2] 4.44 Ours (Teacher) 3.73 ResNet50+PDB+Wing[5] 3.60 LAB[0] 3.49 Lower is better [0] Look at Boundary: A Boundary-Aware Face Alignment Algorithm, CVPR, 2018 [1] Supervision-by-Registration: An Unsupervised Approach to Improve the Precision of Facial Landmark Detectors, CVPR, 2018 [2] Disentangling 3D Pose in A Dendritic CNN for Unconstrained 2D Face Alignment, CVPR, 2018 [3] Direct Shape Regression Networks for End-to-End Face Alignment, CVPR, 2018 [4] Improving Landmark Localization with Semi-Supervised Learning, CVPR, 2018 [5] Wing Loss for Robust Facial Landmark Localisation with Convolutional Nerual Netowrks, CVPR, 2018 [6] https://ibug.doc.ic.ac.uk/resources/300-W/ Latency(CPU) : 1.2 sec Model size : 93.4MB
Convolution Input channel : 16 Output channel : 16 # of Params : 3 x 3 x 16 x 16 3x3 Depthwise Conv Input channel : 16 Output channel : 16 # of Params : 3 x 3 x 16 1x1 Pointwise Conv # of Params : 1 x 1 x 16 x 16 Total : (3 x 3 x 16) + (1 x 1 x 16 x 16)
: 10 x 10 x 3 Input channel : 3 Output channel : 3 Convolution [ 3 x 3 x 3 x 3] Total parameters : 81 (3x3x3x3) Total multiplications : 24300 (Image x Total Params) Depthwise convolution [ 3 x 3 x 3 x 3] # of Parameters : 27 (3x3x3) # of multiplications : 8100 (Image x Params) Pointwise convolution [ 1 x 1 x 3 x 3 ] # of parameters : 9 (1x1x3x3) # of multiplications : 2700 (Image x Params) Total parameters : 36 Total multiplications : 10800 3 x 3 x c x c > 3 x 3 x c + (c x c)
. K K C Convolution weights: D filters Feature map D x (K"C) (K"C) x N * Matrix multiply = Reshape im2col W H N ≈ (H x W) / (Stride) (Accelerated by optimized GEMM) # of multiplication : D x (%&') x N Memory Usage‐ K K C Convolution weights: D filters Feature map (K"C) cut into the vector size of CPU $ Multiply-and-Add = im2row W H (BLAS Free!) (K"C) cut into the vector size of CPU Repeat (D x N) times! # of multiplication : D x (%&') x N
the Model Was Not Affected. However, Device Galaxy s7 Pixel3 Galaxy note 10+ iPhone7 Geekbench (Singlecore) 341 489 756 744 Model Latency [ms] 159.10 29.71 57.90 13.71 Replace Denormals [ms] 32.97 29.71 11.73 13.71 159.10 ms ➡ 32.97 ms (Up to 5x faster‐) 57.90 ms ➡ 11.73 ms (Up to 5x faster‐) ! !
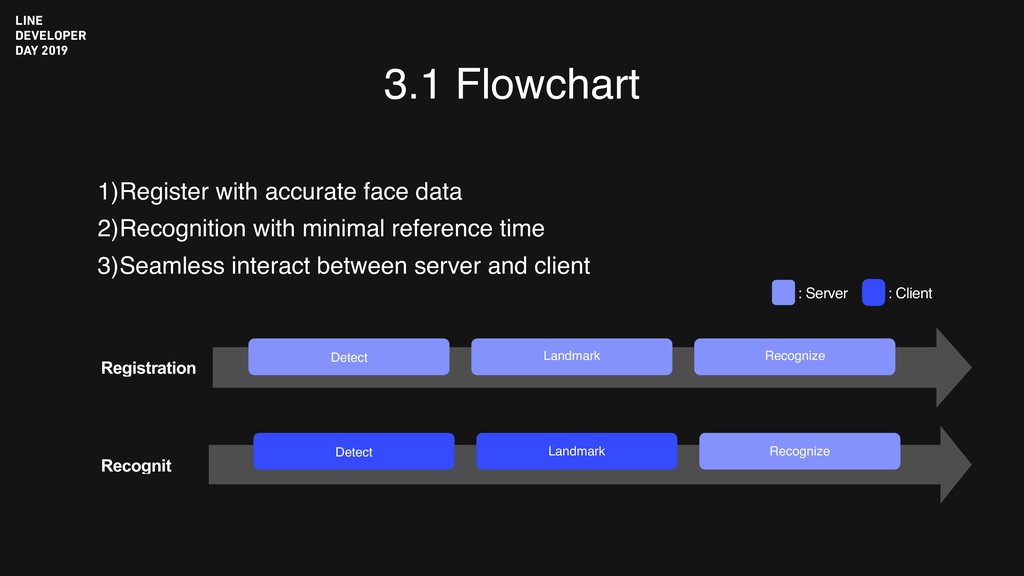
reference time 3)Seamless interact between server and client Registration Recognit : Client : Server Detect Landmark Recognize Detect Landmark Recognize
size Face Alignment Network Frame Processing Postprocess, UX Design and Development Preprocess, UX Design and Development Frame Processing Device type Device tilt
Status # compute the center of mass for each eye leftEyeCenter = leftEyePts.mean(axis=0).astype("int") rightEyeCenter = rightEyePts.mean(axis=0).astype("int") # compute the angle between the eye centroids dY = rightEyeCenter[1] - leftEyeCenter[1] dX = rightEyeCenter[0] - leftEyeCenter[0] angle = np.degrees(np.arctan2(dY, dX)) - 180 https://www.pyimagesearch.com/2017/05/22/face-alignment-with-opencv-and-python/ ▲ ▲ ✓ ✓
Threshold Value? Is the Detected Result Encrypted? Is the Recognized Person Same? Network 1. Consideration for encryption 2. Find optimal results in multi-requests Encrypt Recognized Face Encrypt Features Encrypt Network Encrypt Result
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![2.1.2 Face Detector [1] S. Zhang et. al, FaceBoxes: A](https://files.speakerdeck.com/presentations/39af092d2db64ddeb1cd8b69ca9e9685/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
![2.1.4 Face Recognizer Baseline model : MobileFaceNet [1] Model mAP](https://files.speakerdeck.com/presentations/39af092d2db64ddeb1cd8b69ca9e9685/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}