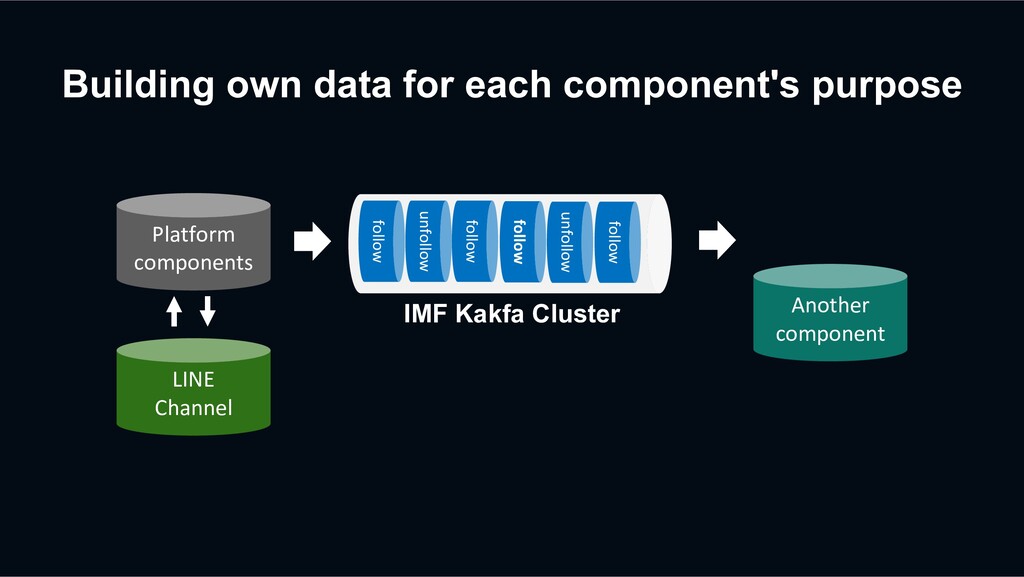
) › Streaming task processing framework built on top of Apache Kafka › Various useful features (retry queueing, concurrent processing, task compaction, …)
without blocking other tasks flow Concurrent processing of records consumed from one partition Dynamic property configuration in runtime using Central Dogma
without blocking other tasks flow Concurrent processing of records consumed from one partition Dynamic property configuration in runtime using Central Dogma
without blocking other tasks flow Concurrent processing of records consumed from one partition Dynamic property configuration in runtime using Central Dogma
without blocking other tasks flow Concurrent processing of records consumed from one partition Dynamic property configuration in runtime using Central Dogma
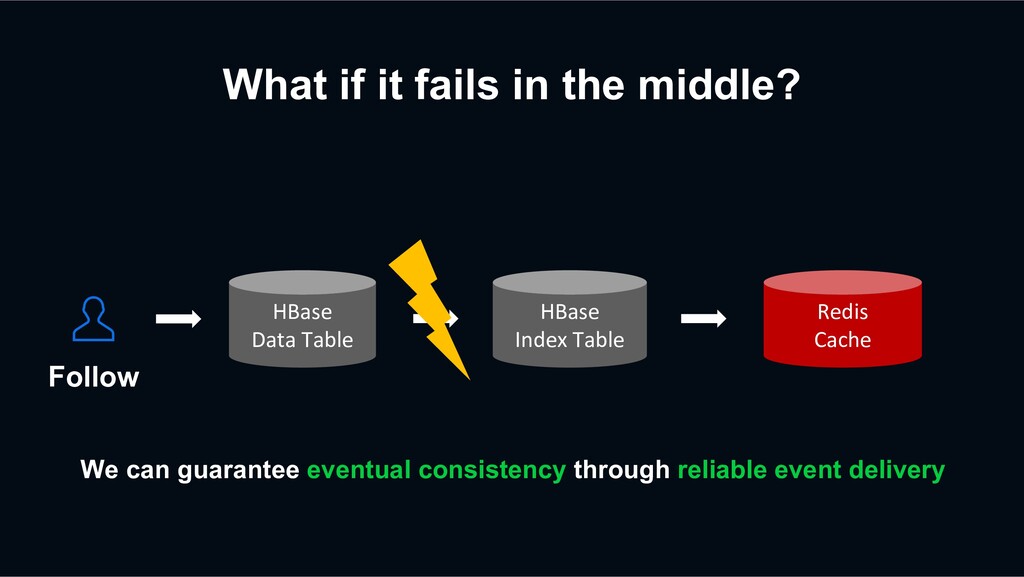
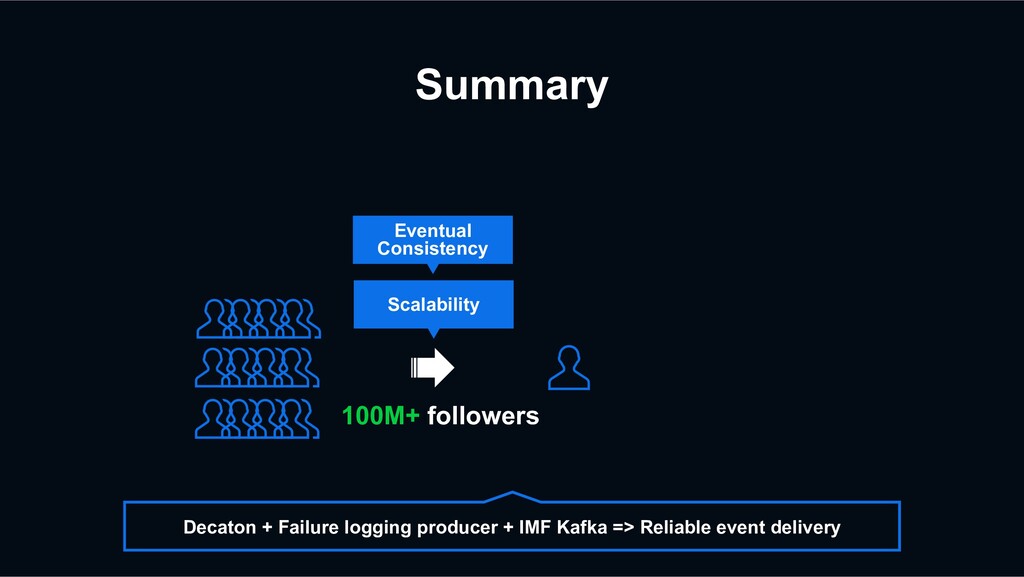
while producing tasks (network issue, temporary increased latency, …) › Even when exhausting Kafka’s default retry attempts, the producer serializes the task to the local file system, and retries with a daemon automatically › Guarantee producing the events eventually
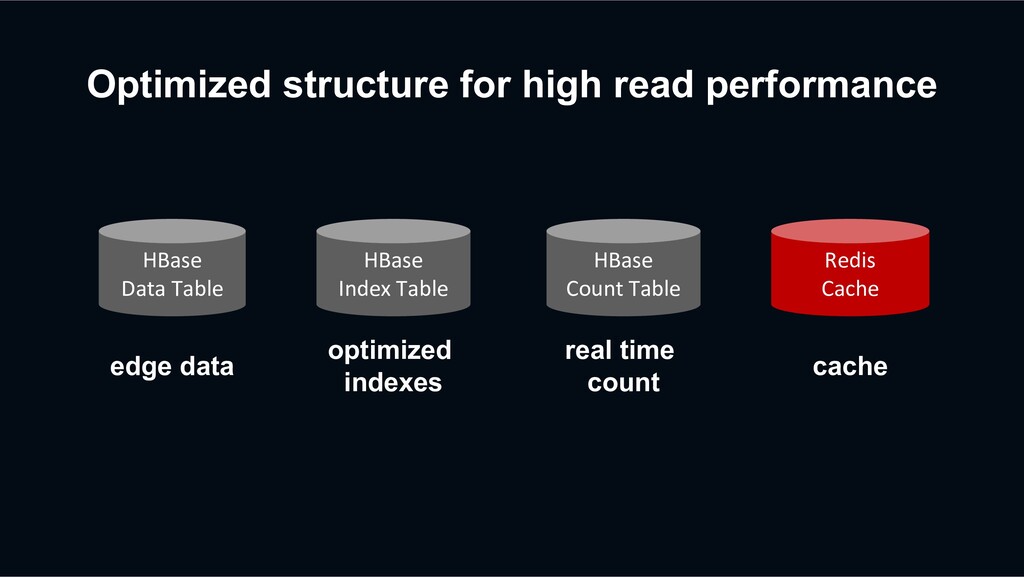
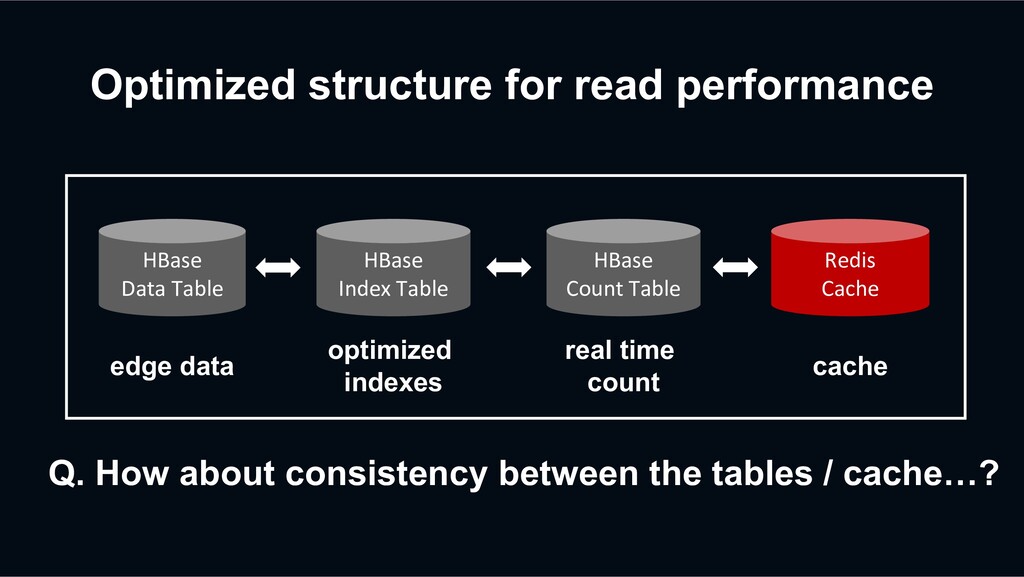
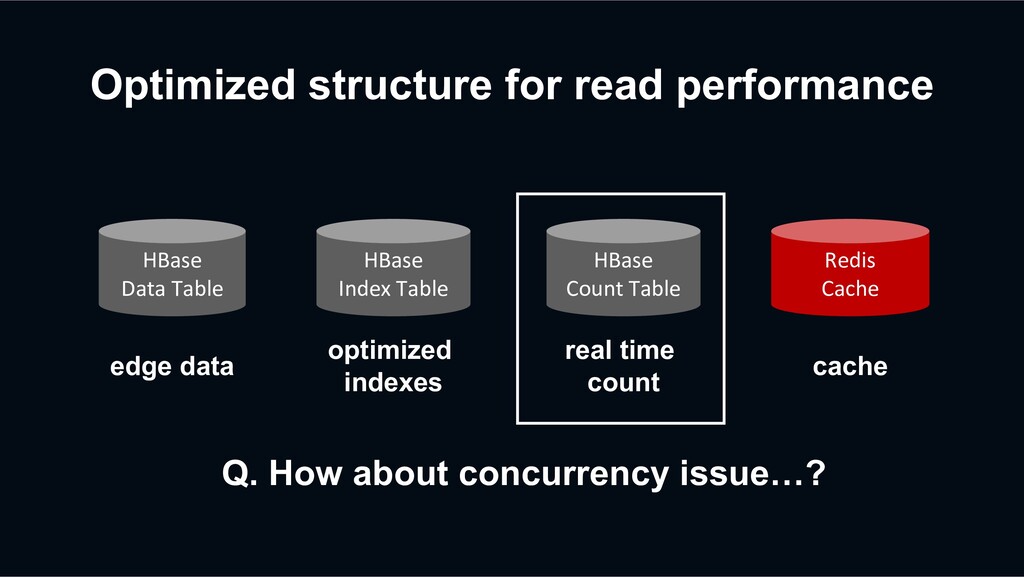
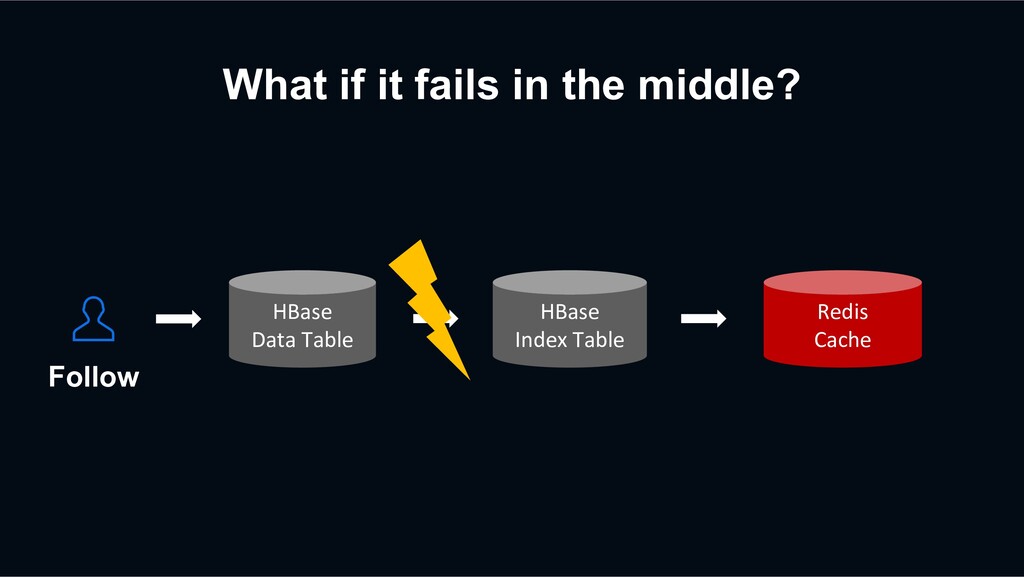
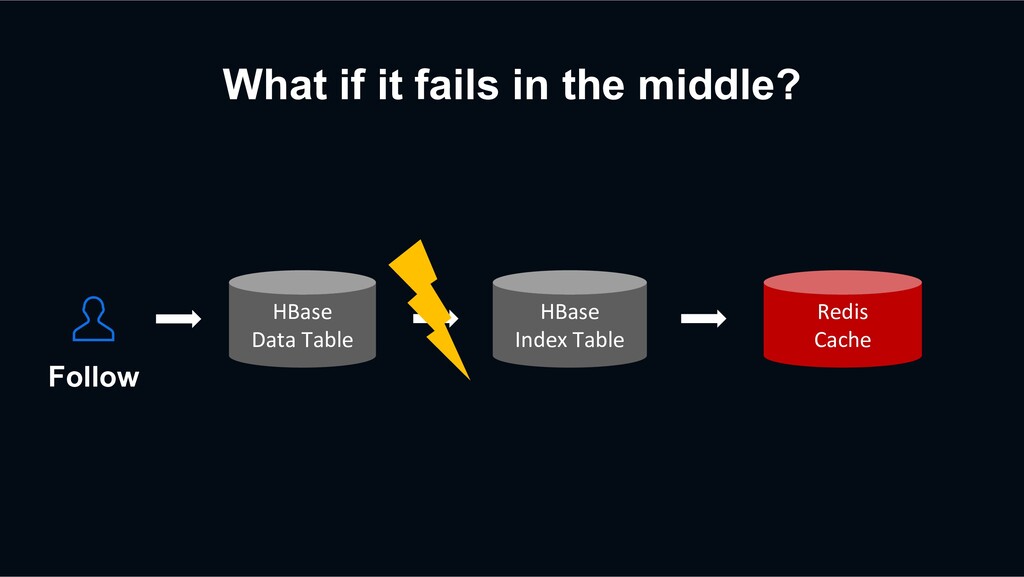
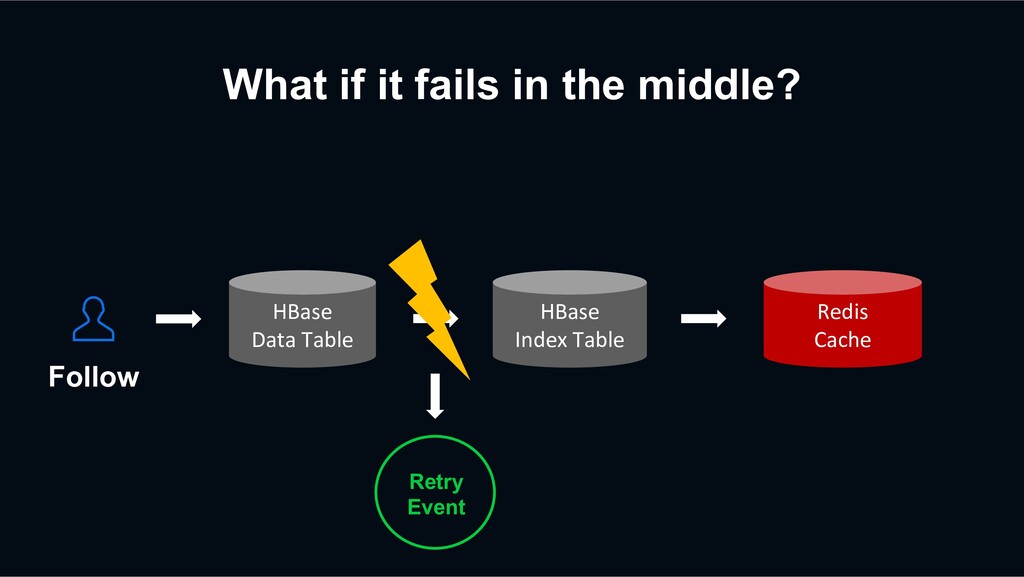
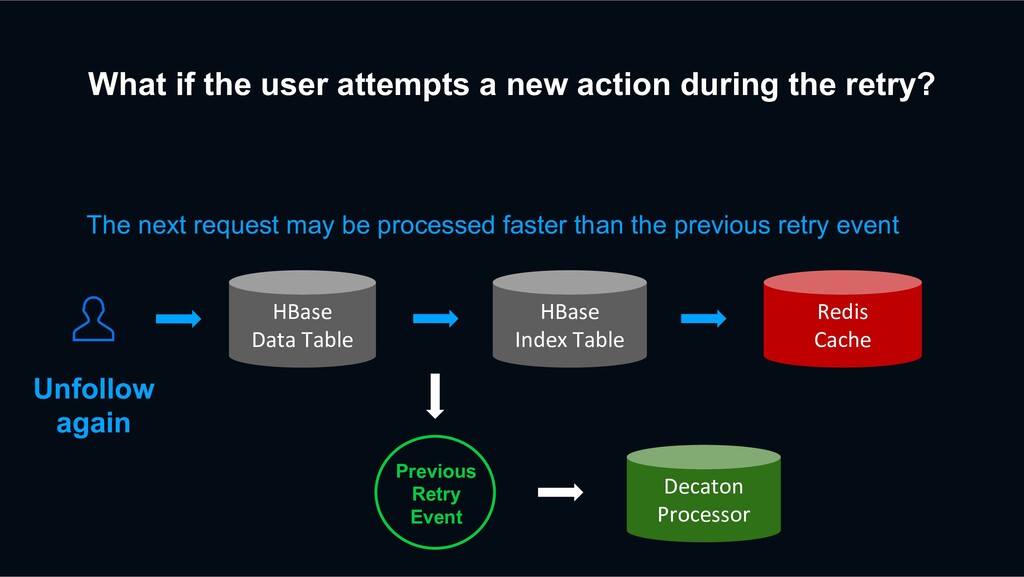
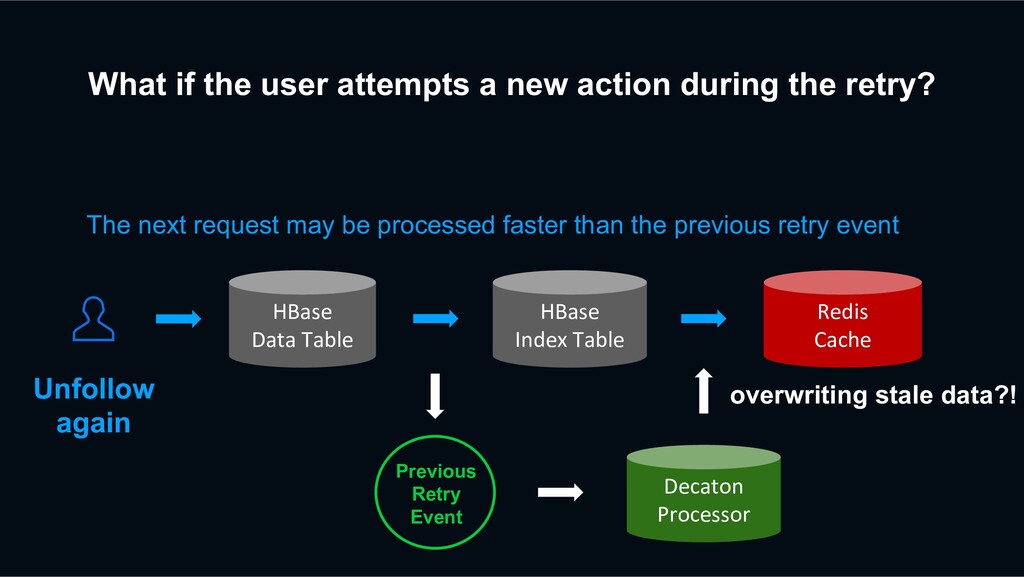
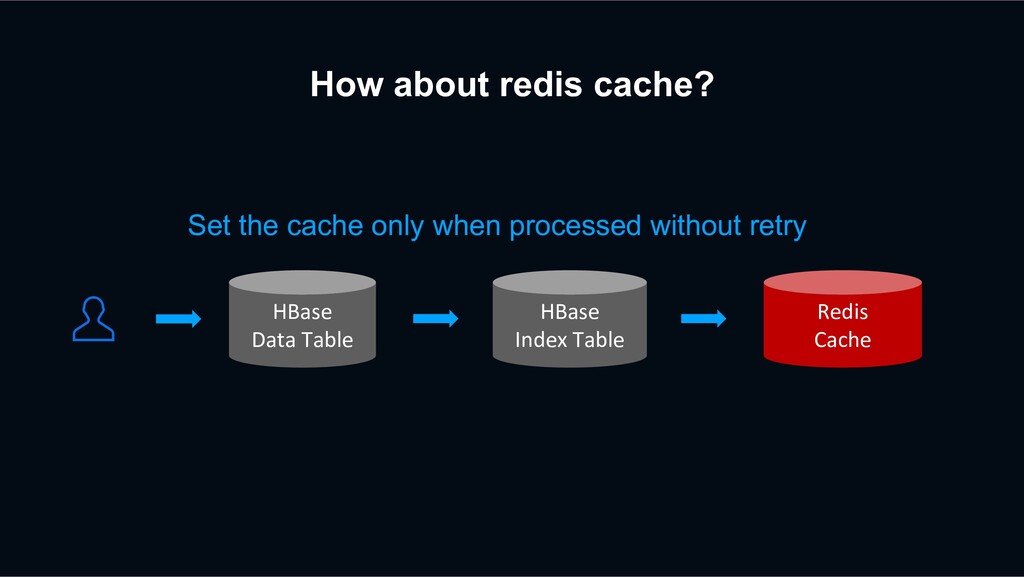
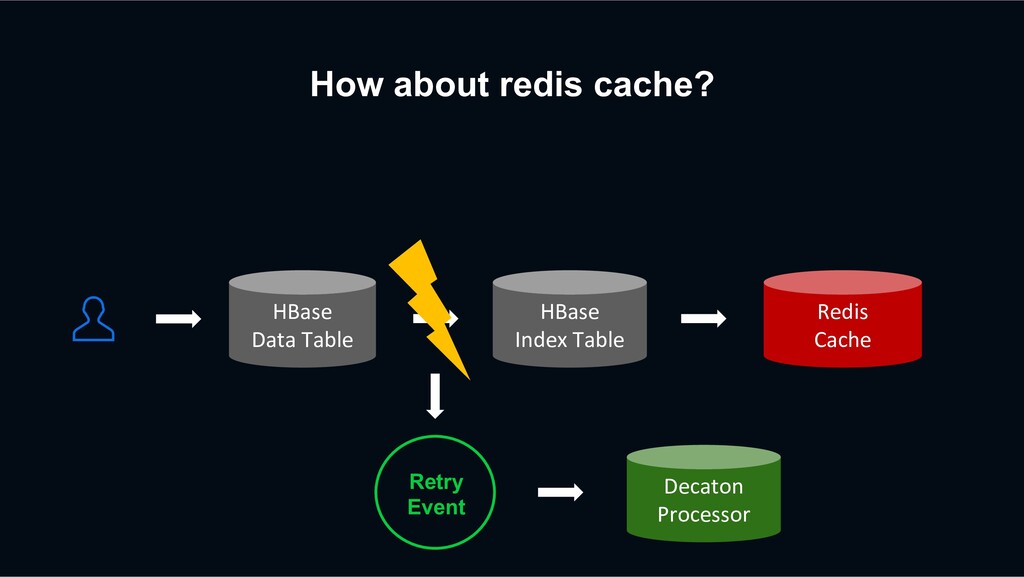
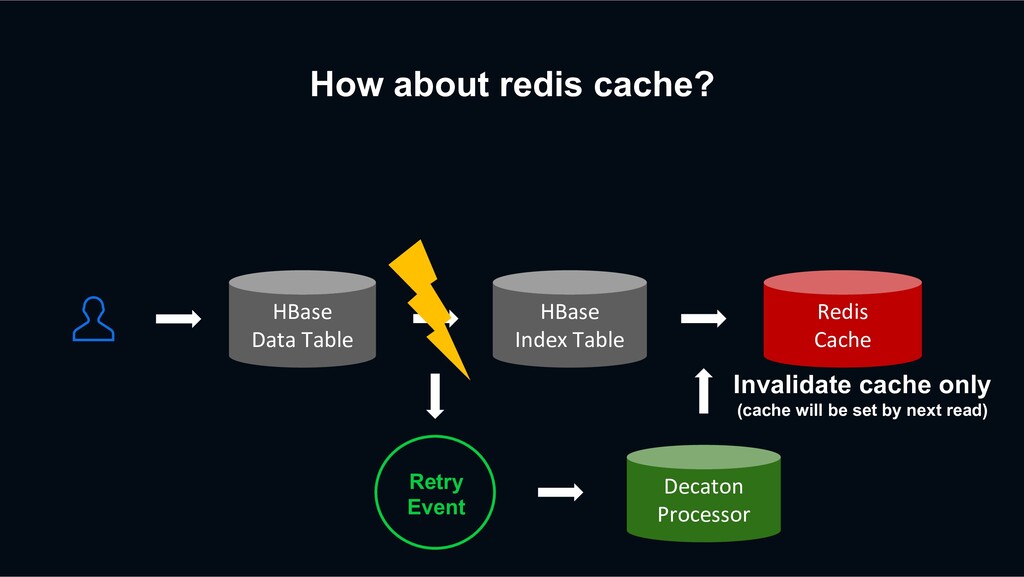
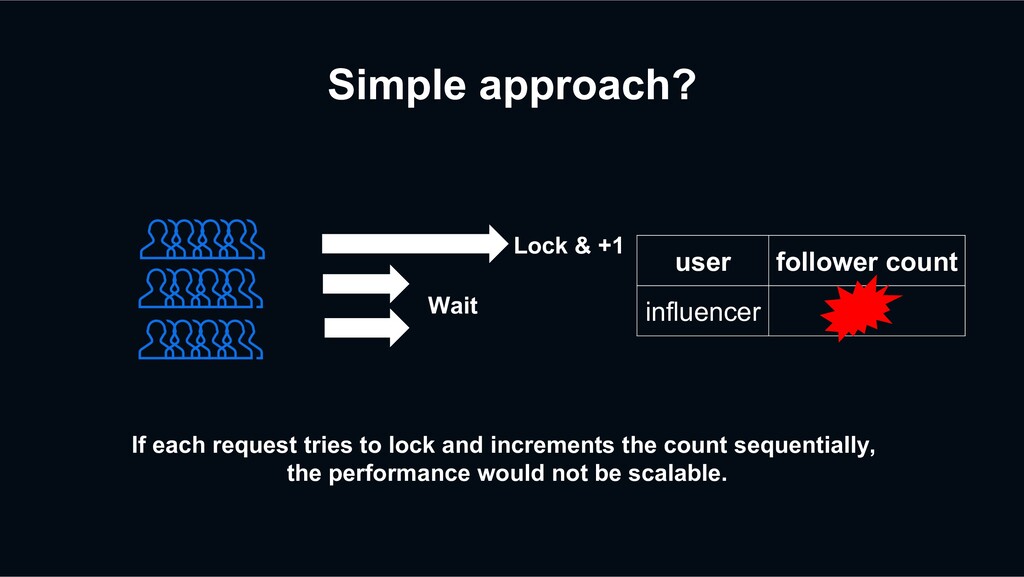
retry? HBase Data Table HBase Index Table Redis Cache Previous Retry Event Decaton Processor Unfollow again The next request may be processed faster than the previous retry event
retry? HBase Data Table HBase Index Table Redis Cache Previous Retry Event Decaton Processor Unfollow again The next request may be processed faster than the previous retry event overwriting stale data?!
retry? action timestamp unfollow 2 HBase sorts the versions of a cell from newest to oldest by sorting the timestamp regardless of the put order. action timestamp unfollow 2 follow 1 Previous retry event has been processed
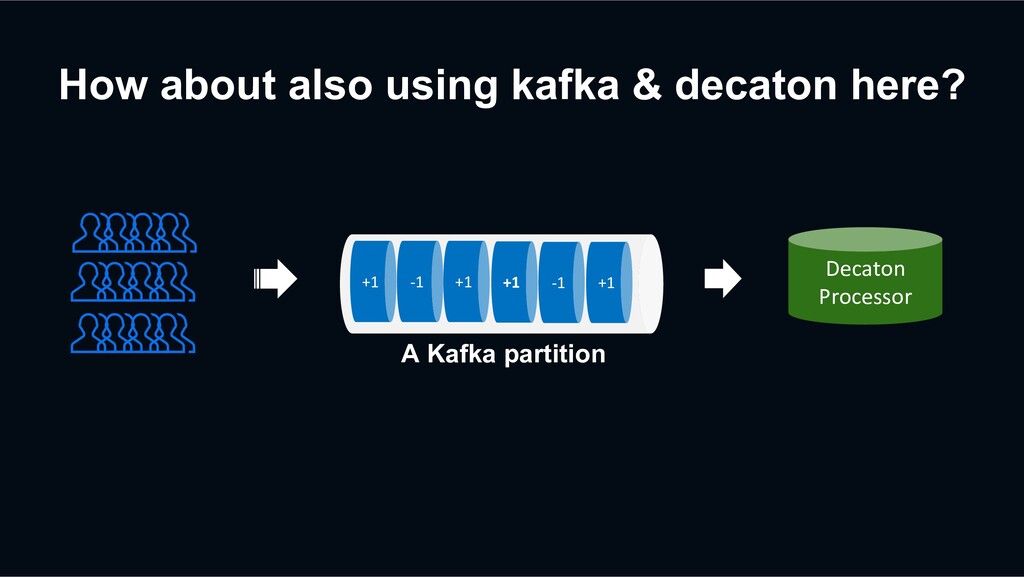
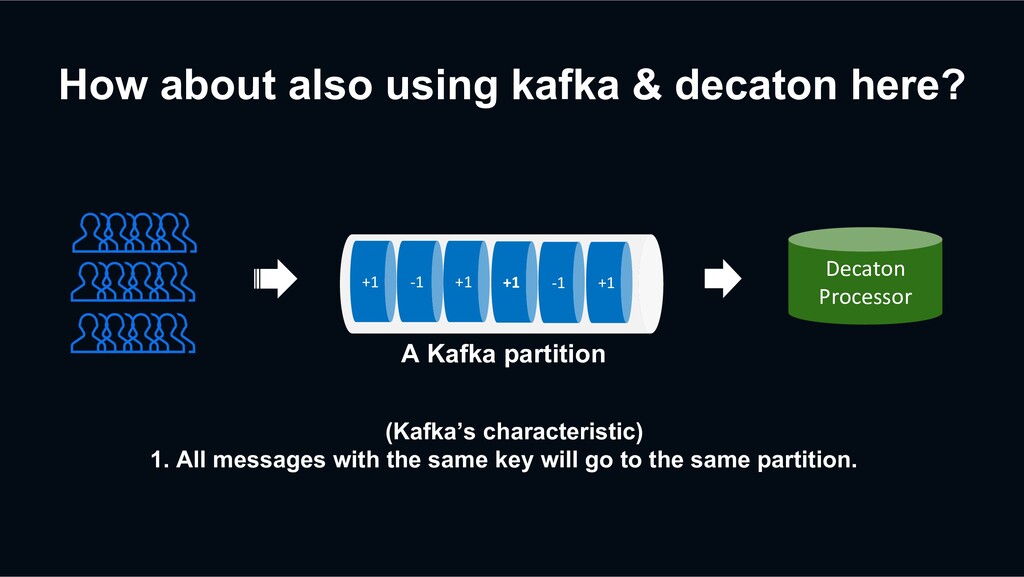
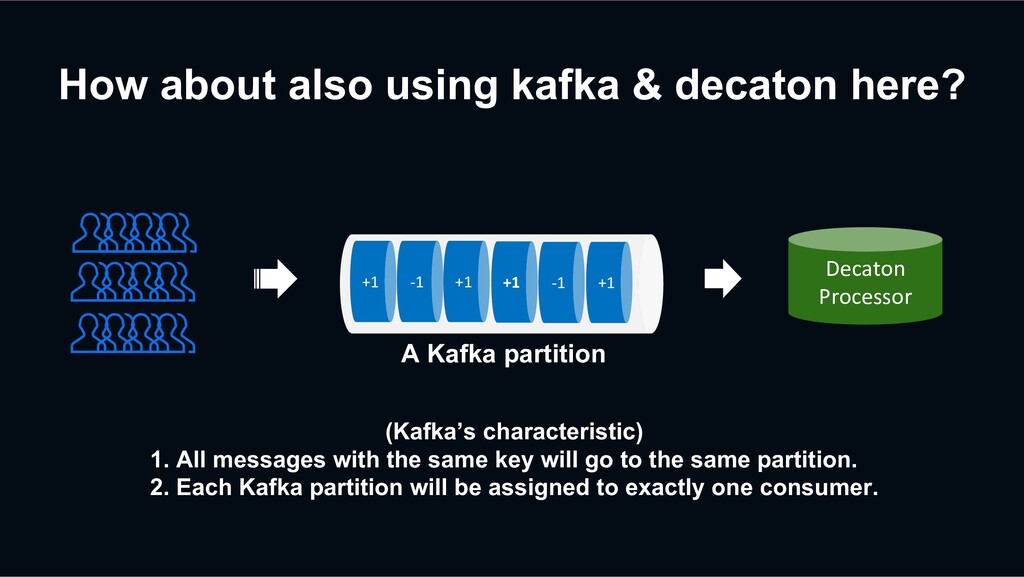
1. All messages with the same key will go to the same partition. 2. Each Kafka partition will be assigned to exactly one consumer. +1 -1 +1 +1 -1 +1 Decaton Processor A Kafka partition
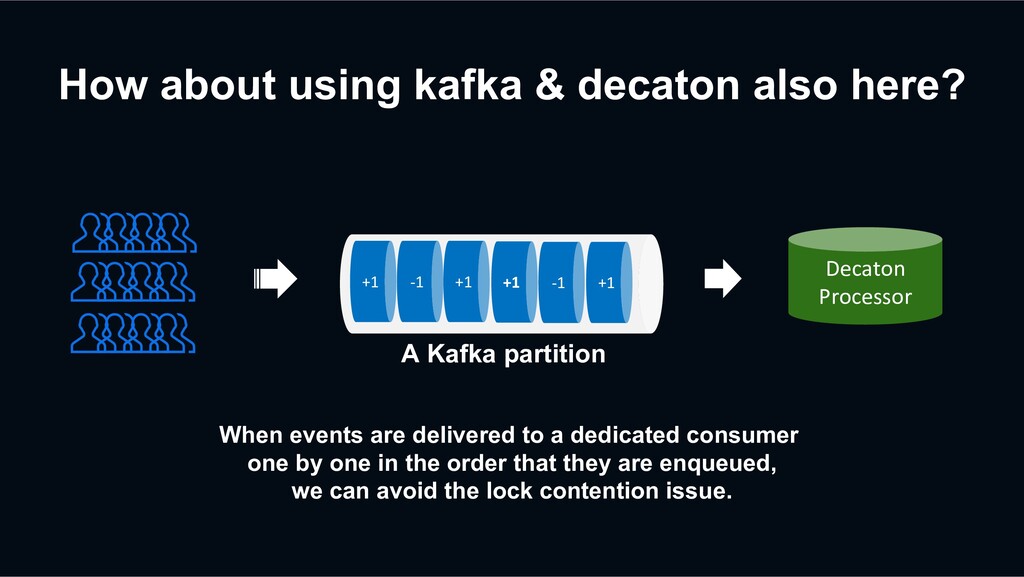
Influencer’s follower count events can be delivered to a dedicated consumer one by one in the order that they are enqueued. +1 -1 +1 +1 -1 +1 Decaton Processor A Kafka partition
are delivered to a dedicated consumer one by one in the order that they are enqueued, we can avoid the lock contention issue. +1 -1 +1 +1 -1 +1 Decaton Processor A Kafka partition
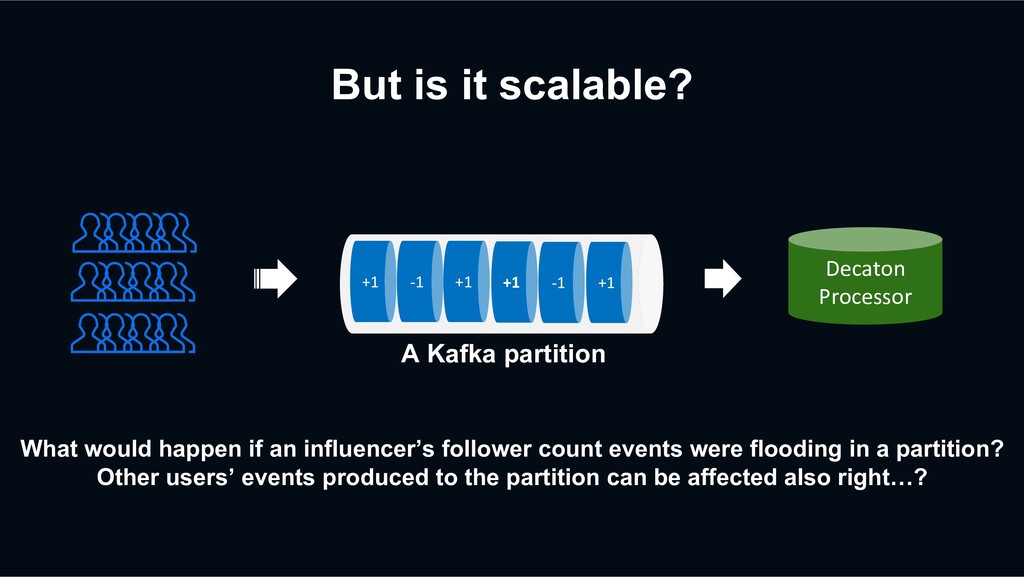
follower count events were flooding in a partition? Other users’ events produced to the partition can be affected also right…? +1 -1 +1 +1 -1 +1 Decaton Processor A Kafka partition
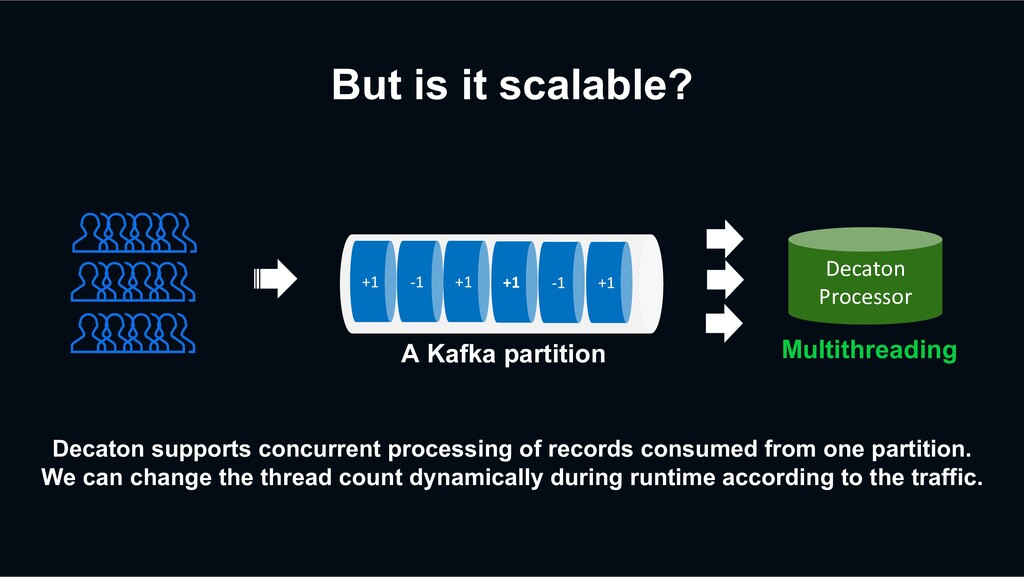
consumed from one partition. We can change the thread count dynamically during runtime according to the traffic. +1 -1 +1 +1 -1 +1 Decaton Processor A Kafka partition Multithreading
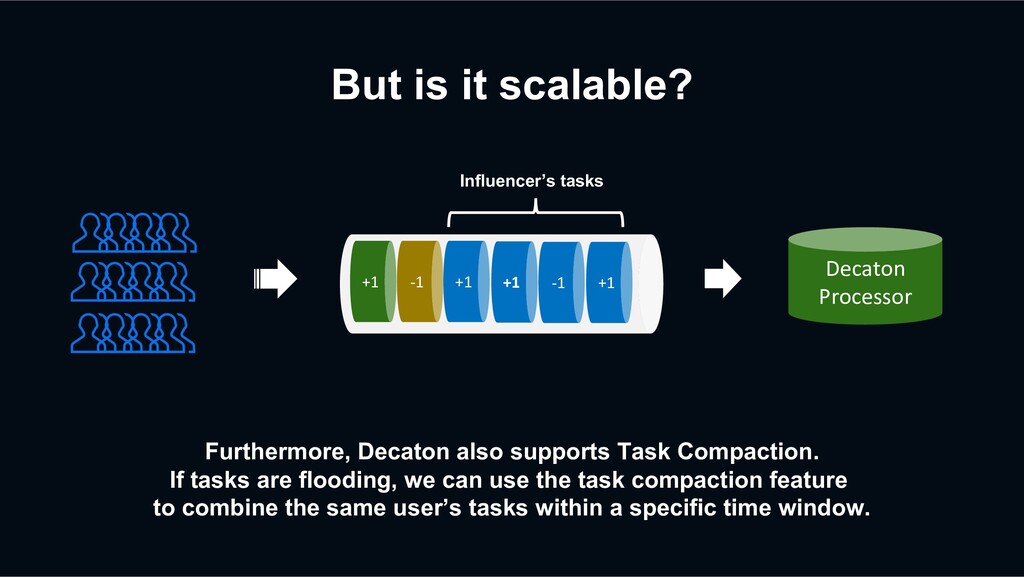
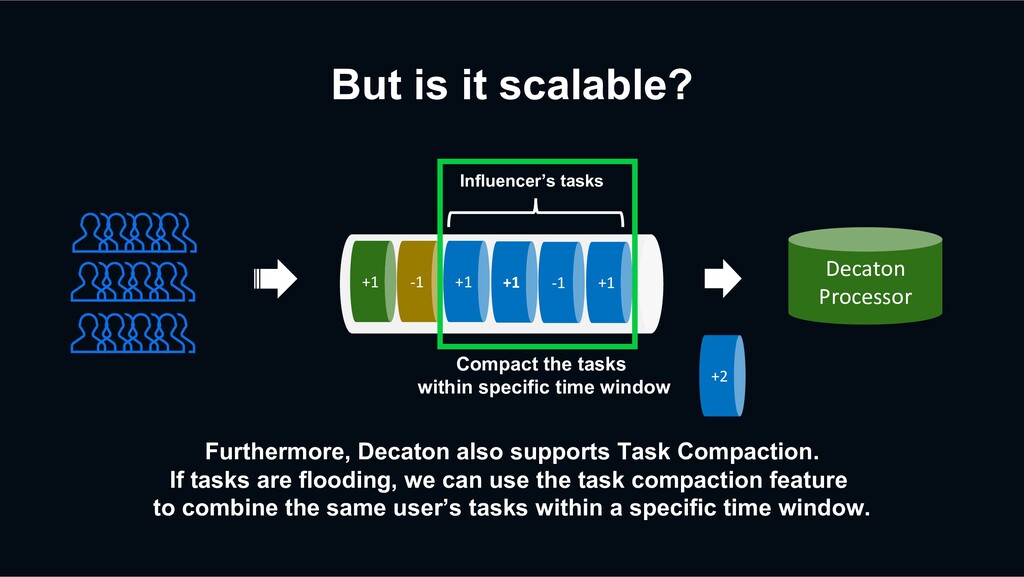
If tasks are flooding, we can use the task compaction feature to combine the same user’s tasks within a specific time window. +1 -1 +1 +1 -1 +1 Decaton Processor Influencer’s tasks
If tasks are flooding, we can use the task compaction feature to combine the same user’s tasks within a specific time window. +1 -1 +1 +1 -1 +1 Decaton Processor +2 Compact the tasks within specific time window Influencer’s tasks
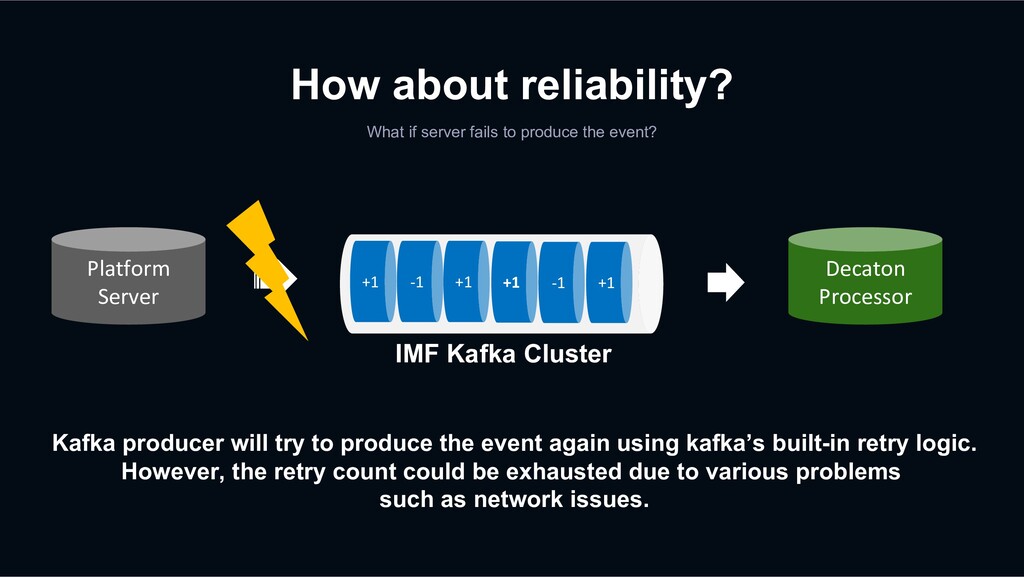
event? Kafka producer will try to produce the event again using kafka’s built-in retry logic. However, the retry count could be exhausted due to various problems such as network issues. +1 -1 +1 +1 -1 +1 Decaton Processor IMF Kafka Cluster Platform Server
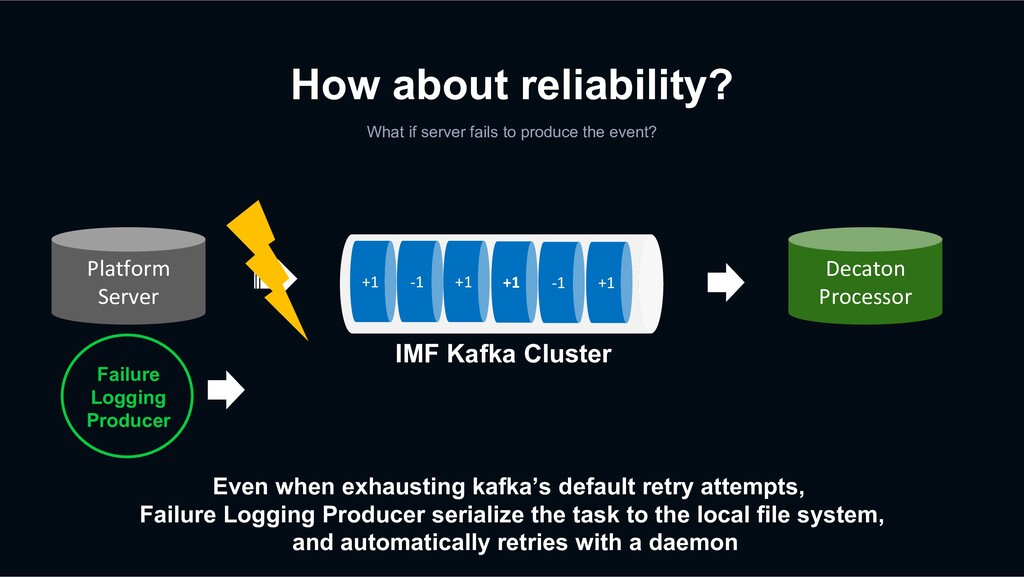
event? Even when exhausting kafka’s default retry attempts, Failure Logging Producer serialize the task to the local file system, and automatically retries with a daemon +1 -1 +1 +1 -1 +1 Decaton Processor IMF Kafka Cluster Platform Server Failure Logging Producer
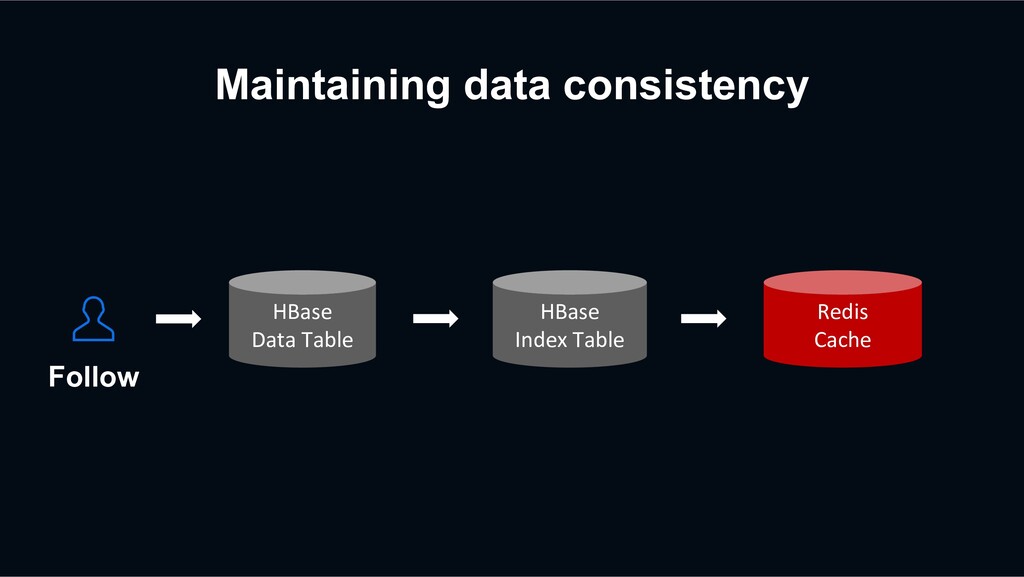
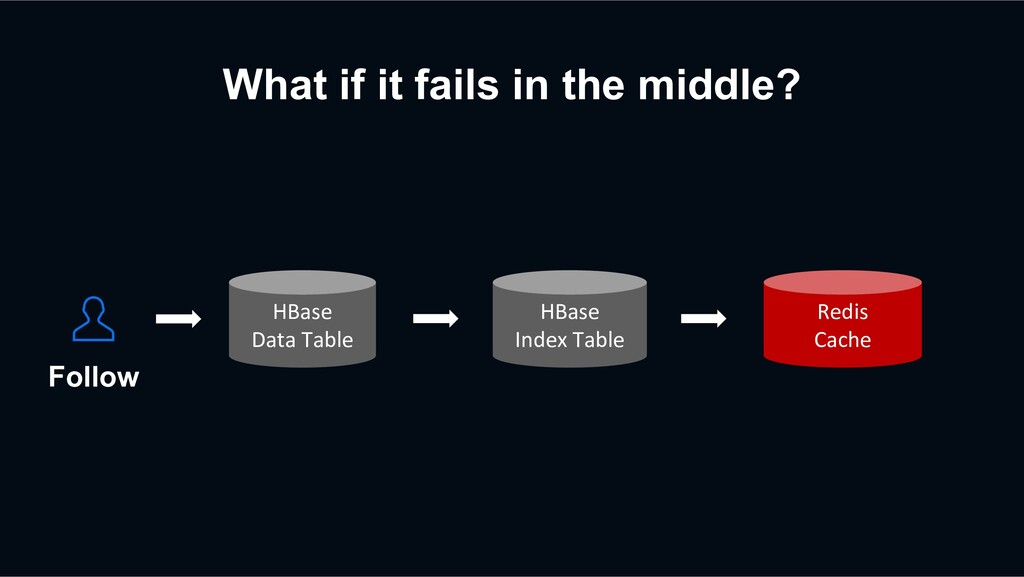
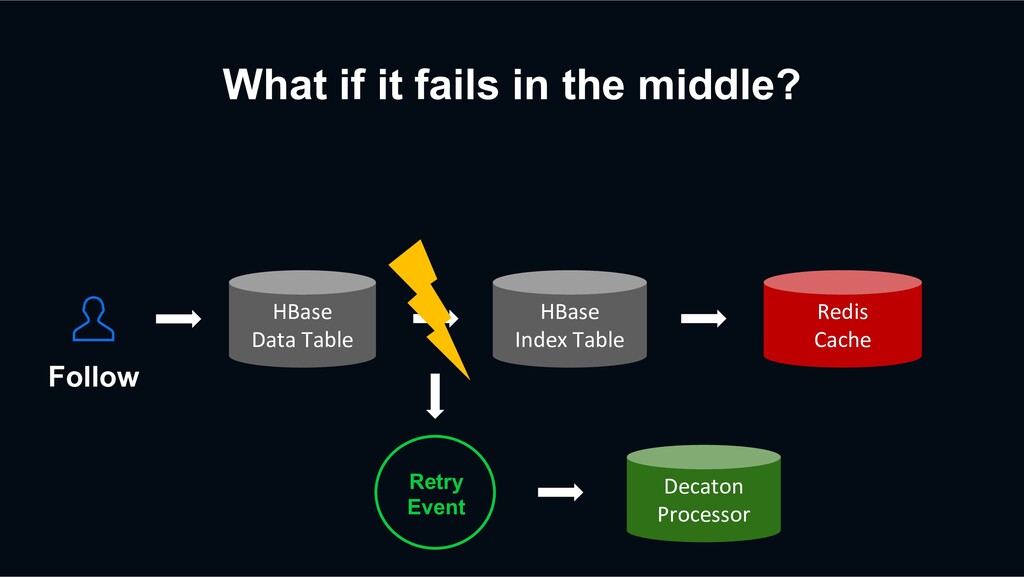
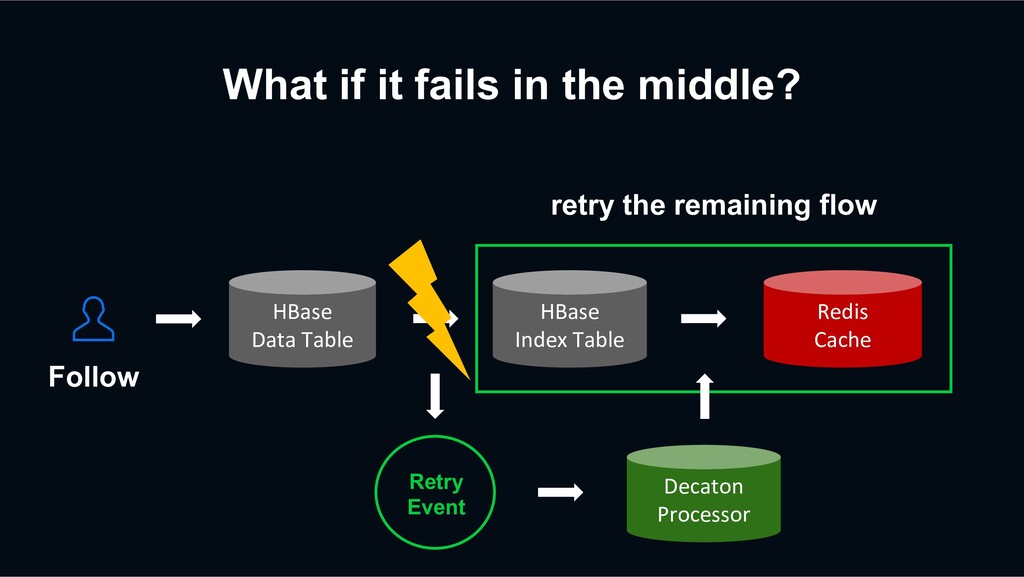
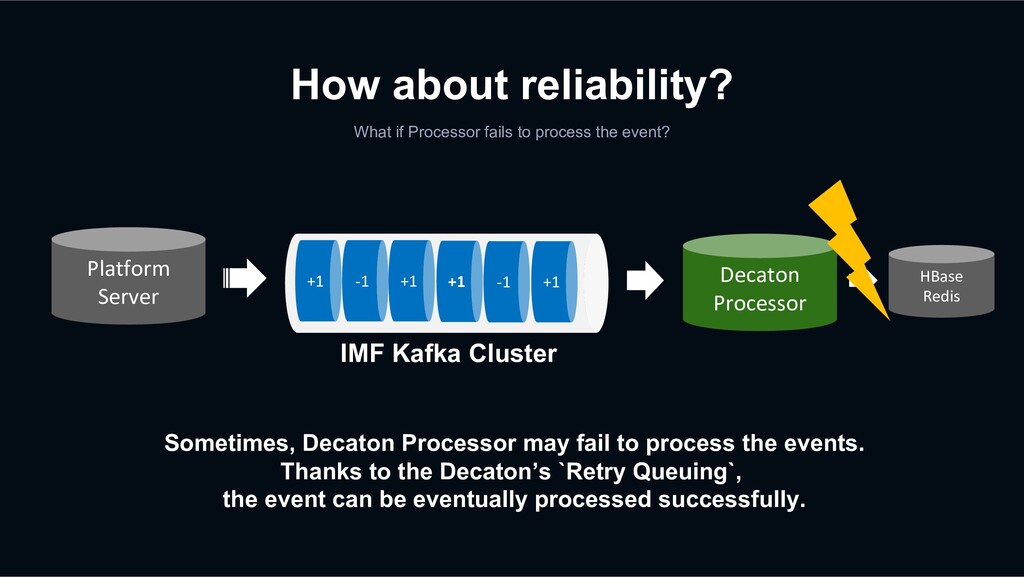
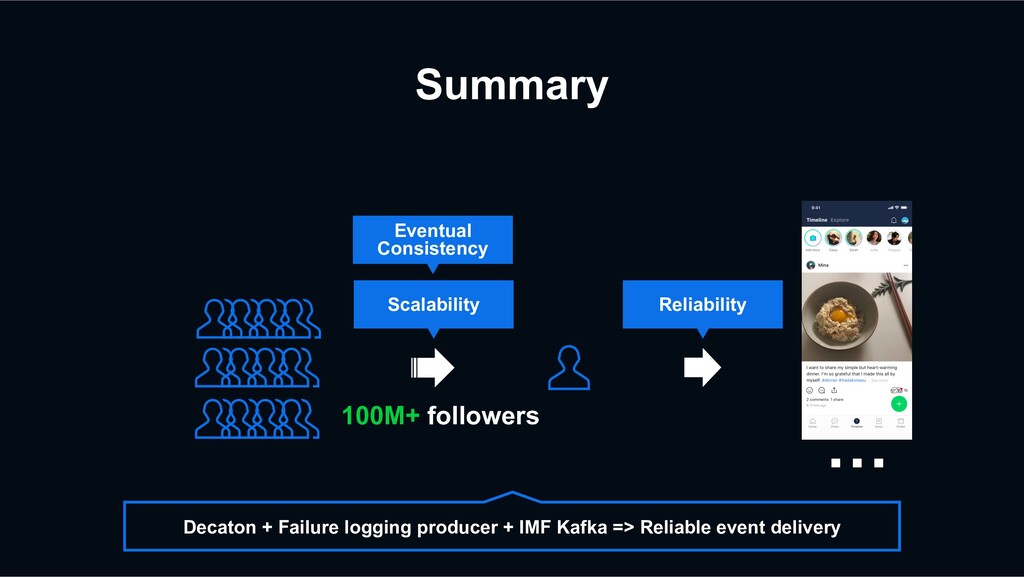
event? Sometimes, Decaton Processor may fail to process the events. Thanks to the Decaton’s `Retry Queuing`, the event can be eventually processed successfully. +1 -1 +1 +1 -1 +1 Decaton Processor IMF Kafka Cluster Platform Server HBase Redis
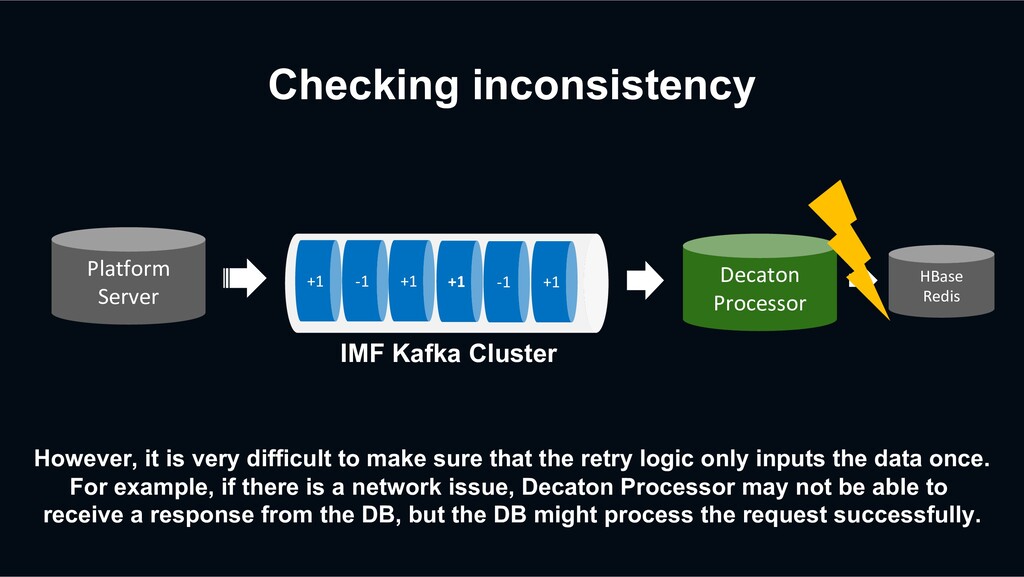
that the retry logic only inputs the data once. For example, if there is a network issue, Decaton Processor may not be able to receive a response from the DB, but the DB might process the request successfully. +1 -1 +1 +1 -1 +1 Decaton Processor IMF Kafka Cluster Platform Server HBase Redis
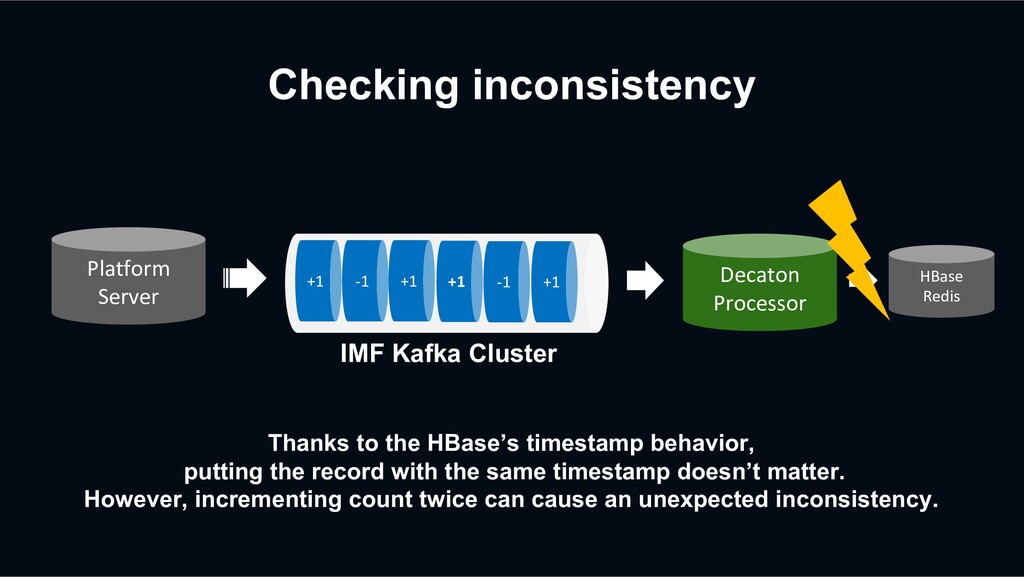
record with the same timestamp doesn’t matter. However, incrementing count twice can cause an unexpected inconsistency. +1 -1 +1 +1 -1 +1 Decaton Processor IMF Kafka Cluster Platform Server HBase Redis
api is getting the list data. When the follow list is fetched from HBase, inconsistencies are checked while minimizing additional storage I/O for the sampled targets. Another component Platform Server Query follow list by api HBase Redis follow list Checking inconsistency
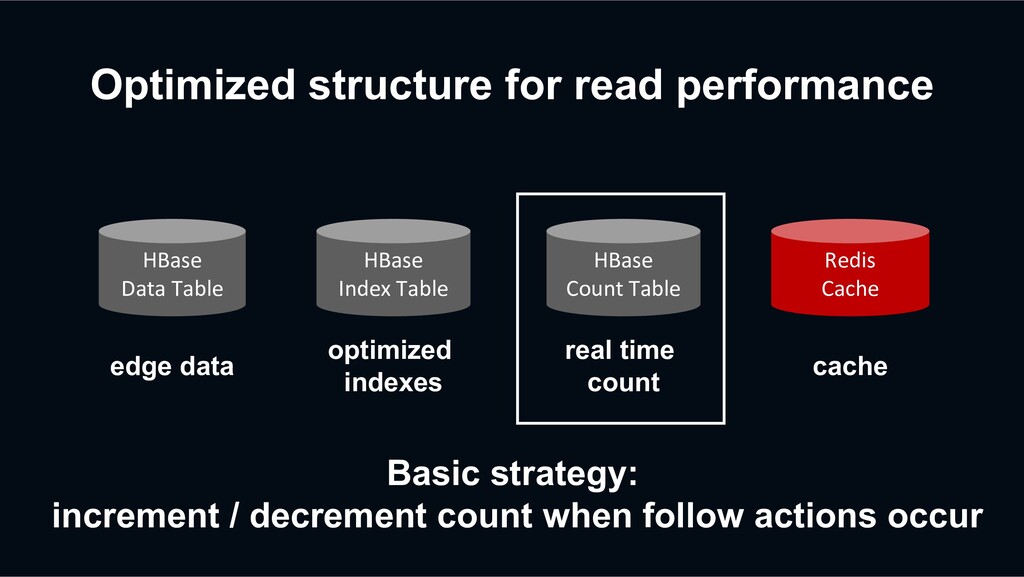
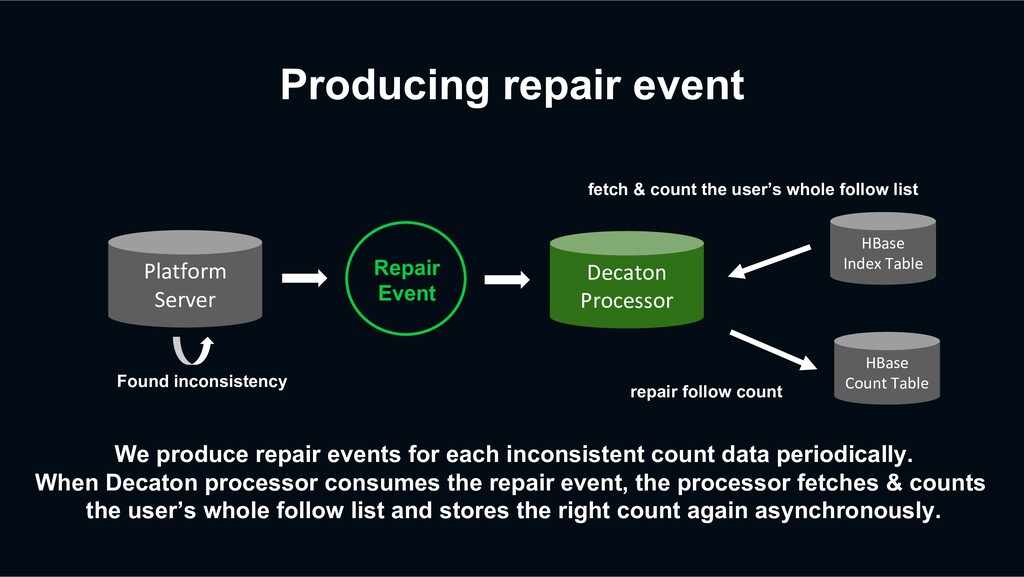
count data periodically. When Decaton processor consumes the repair event, the processor fetches & counts the user’s whole follow list and stores the right count again asynchronously. Platform Server HBase Index Table fetch & count the user’s whole follow list Found inconsistency Repair Event Decaton Processor HBase Count Table repair follow count
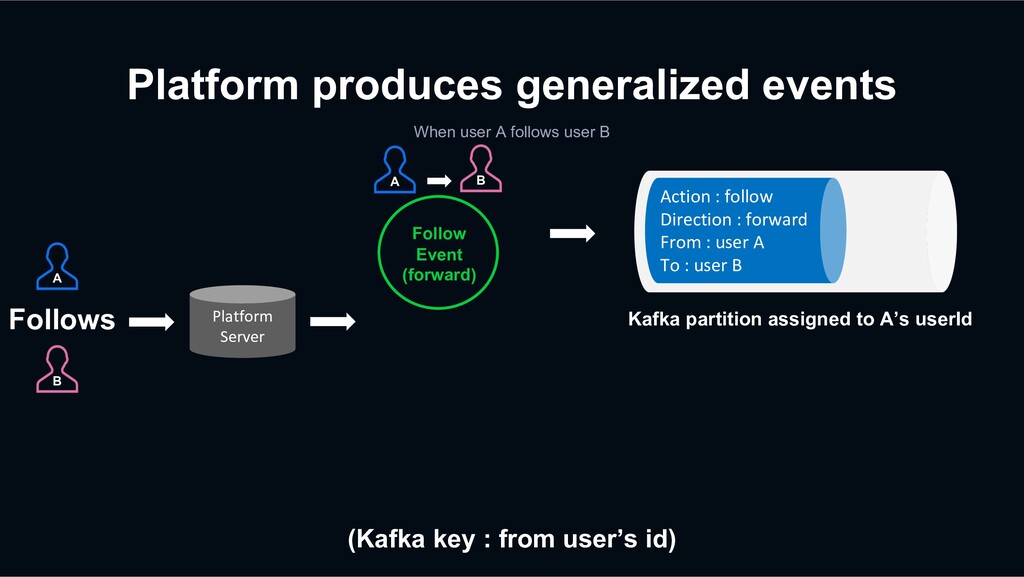
Platform Server Follows (Kafka key : from user’s id) A B Follow Event (forward) Action : follow Direction : forward From : user A To : user B Kafka partition assigned to A’s userId A B
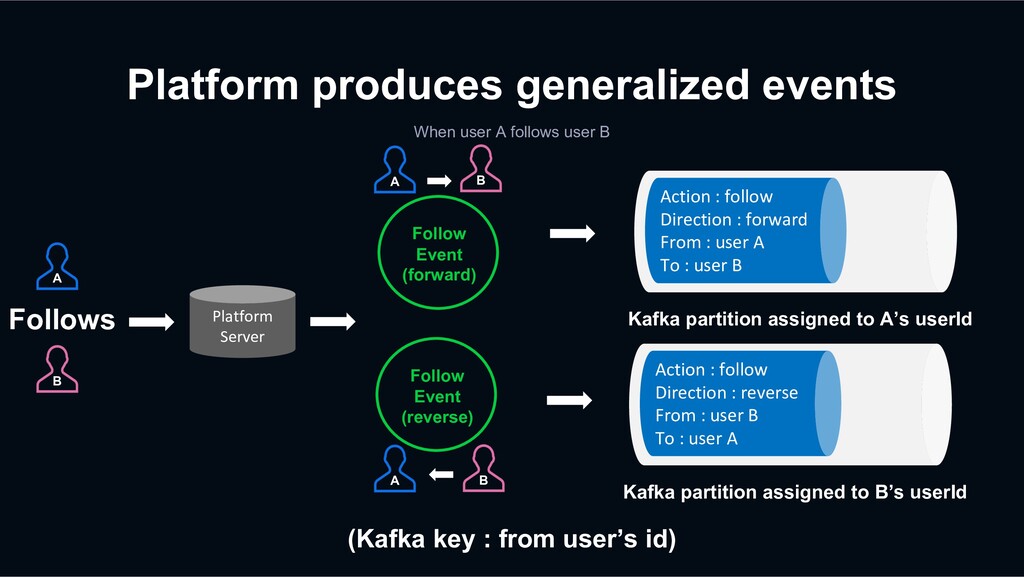
Platform Server Follows (Kafka key : from user’s id) A B Follow Event (forward) Action : follow Direction : forward From : user A To : user B Kafka partition assigned to A’s userId A B Follow Event (reverse) Action : follow Direction : reverse From : user B To : user A Kafka partition assigned to B’s userId A B
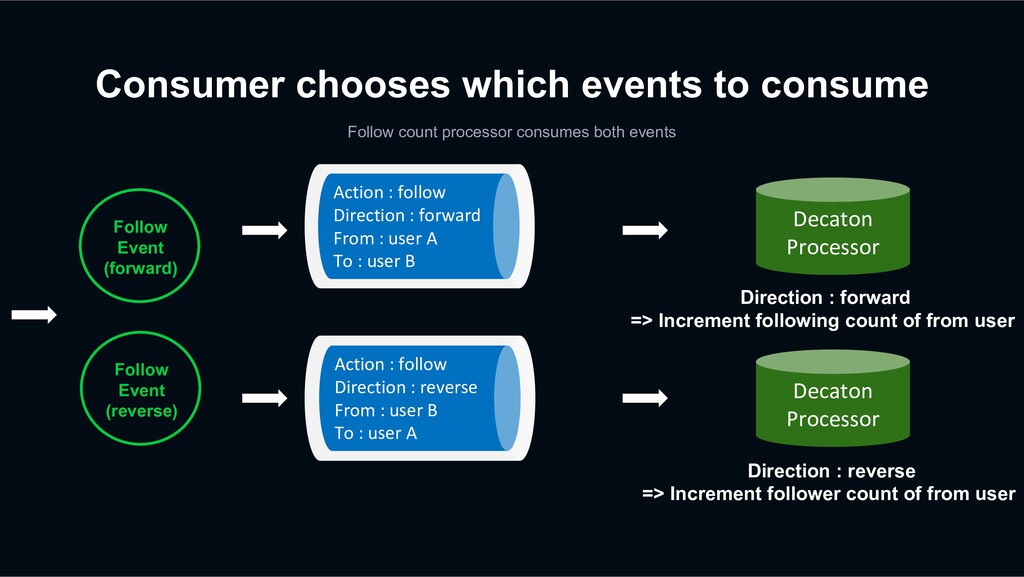
both events Follow Event (forward) Action : follow Direction : forward From : user A To : user B Follow Event (reverse) Action : follow Direction : reverse From : user B To : user A Decaton Processor Decaton Processor Direction : forward => Increment following count of from user Direction : reverse => Increment follower count of from user
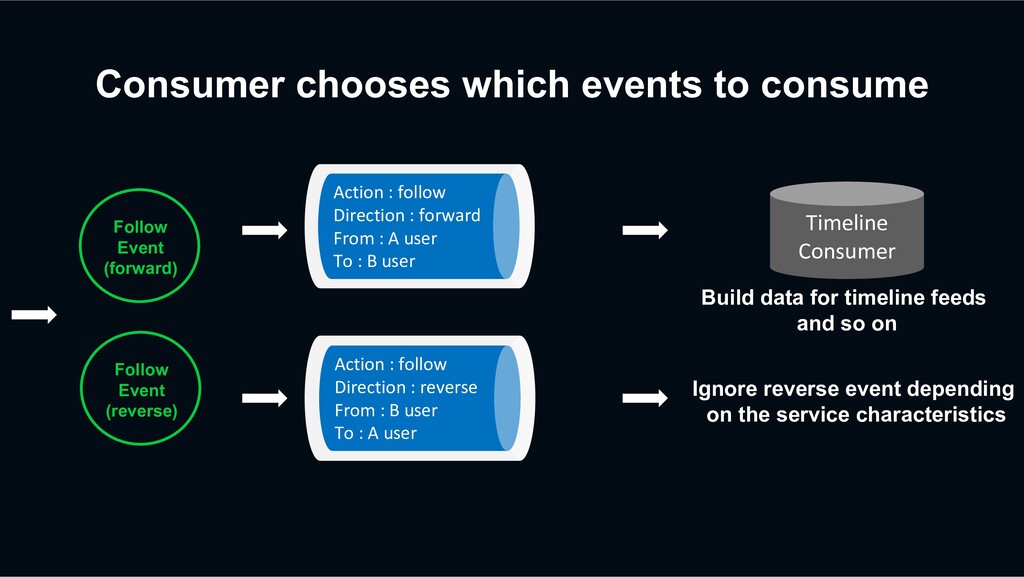
: follow Direction : forward From : A user To : B user Follow Event (reverse) Action : follow Direction : reverse From : B user To : A user Timeline Consumer Build data for timeline feeds and so on Ignore reverse event depending on the service characteristics
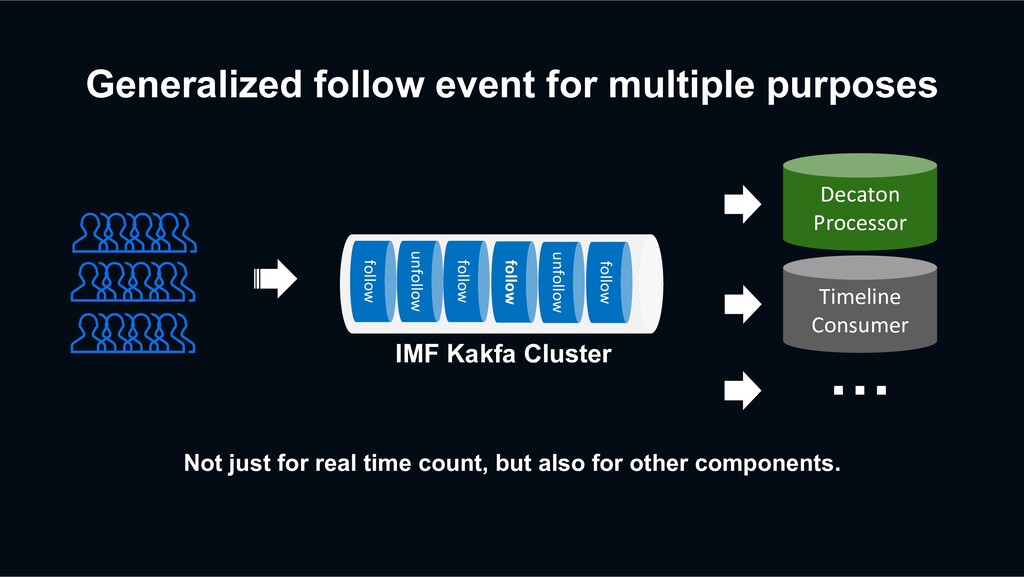
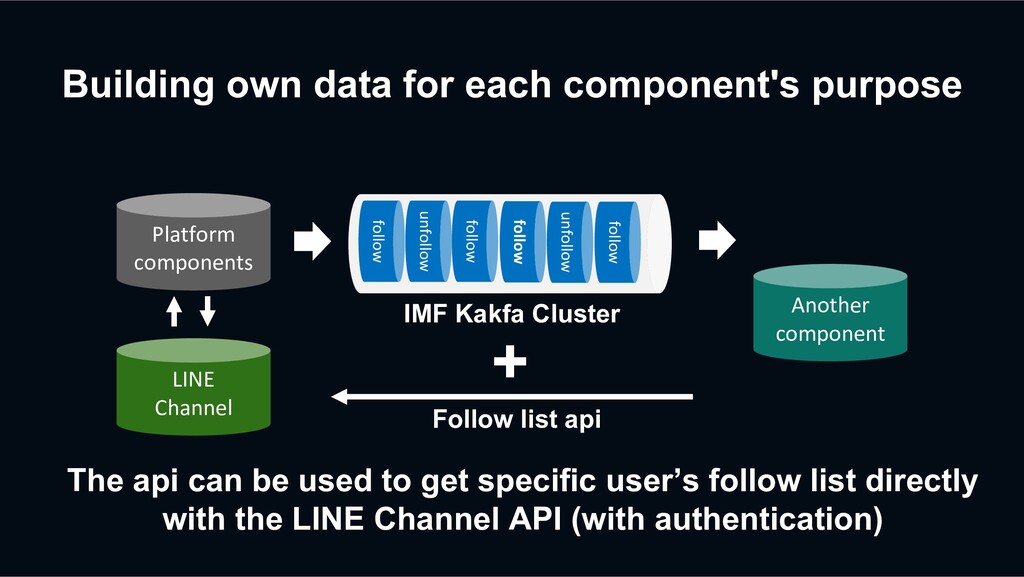
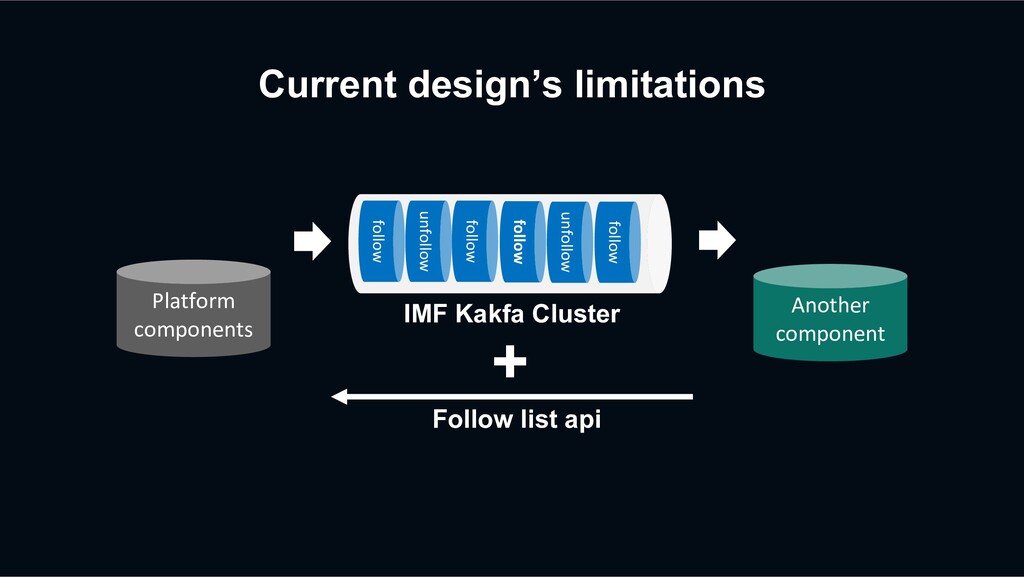
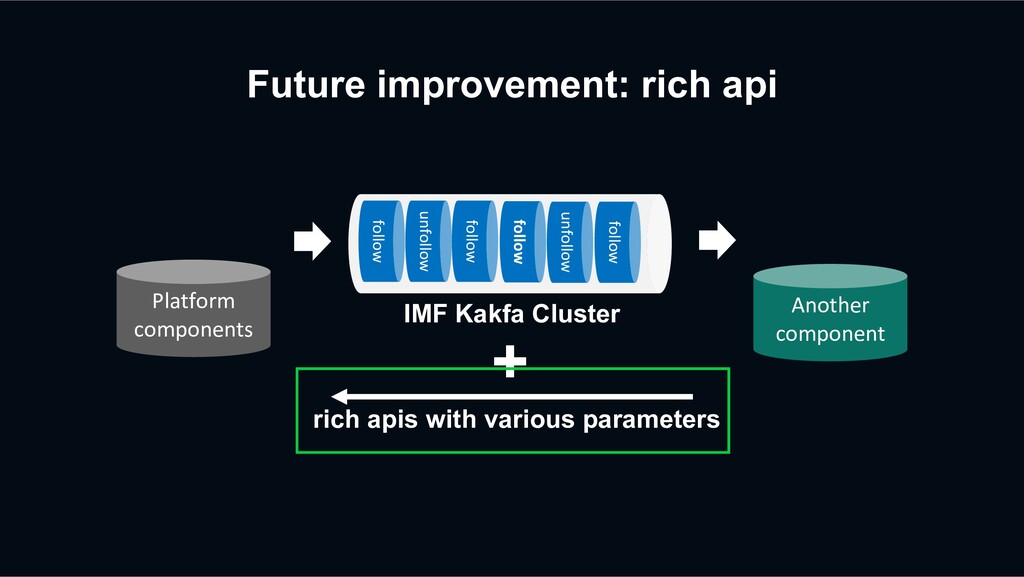
unfollow follow follow unfollow follow IMF Kakfa Cluster Platform components The api can be used to get specific user’s follow list directly with the LINE Channel API (with authentication) + Follow list api LINE Channel
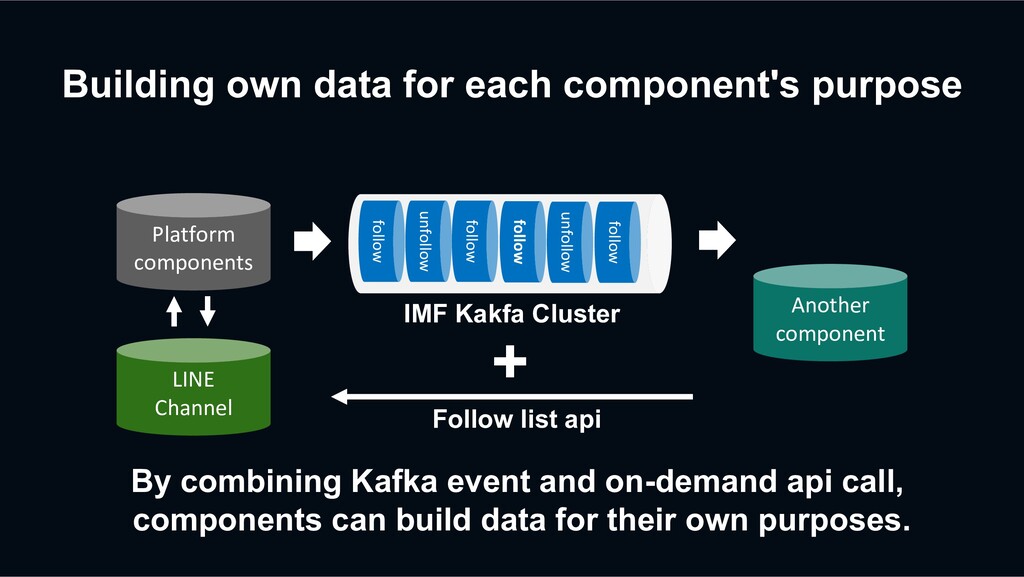
unfollow follow follow unfollow follow IMF Kakfa Cluster By combining Kafka event and on-demand api call, components can build data for their own purposes. + Follow list api Platform components LINE Channel
various requirements › Enhanced inconsistency checker for the whole data (Currently, we are checking inconsistencies only for the sampled targets during runtime) › Improvements for the future hotspots related to the influencers › More features for the users (block unwanted follow requests, search, …) › Recommending accounts to follow based on user interests › Anti-abuse › and any improvements or challenges that arise in the future…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}