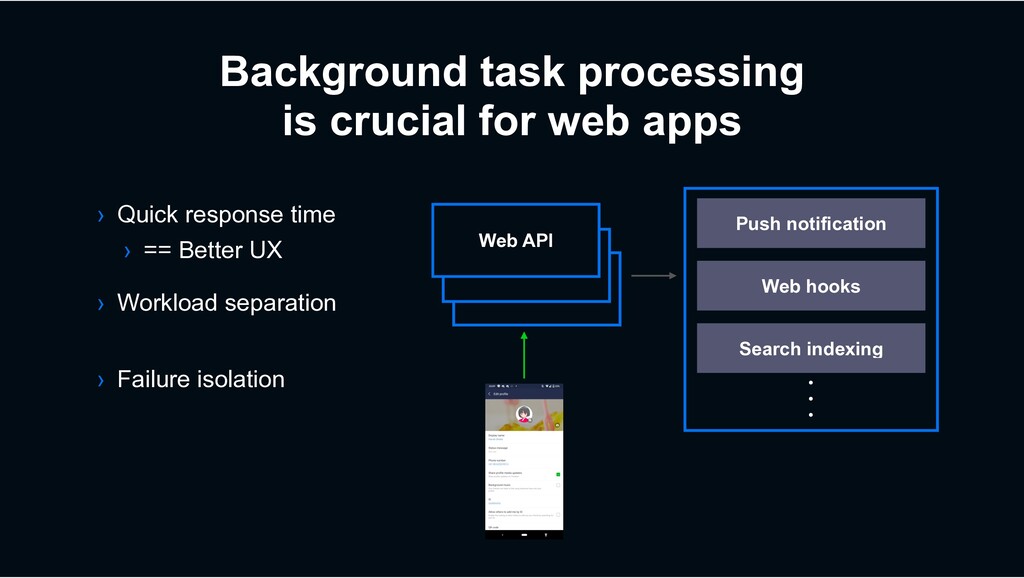
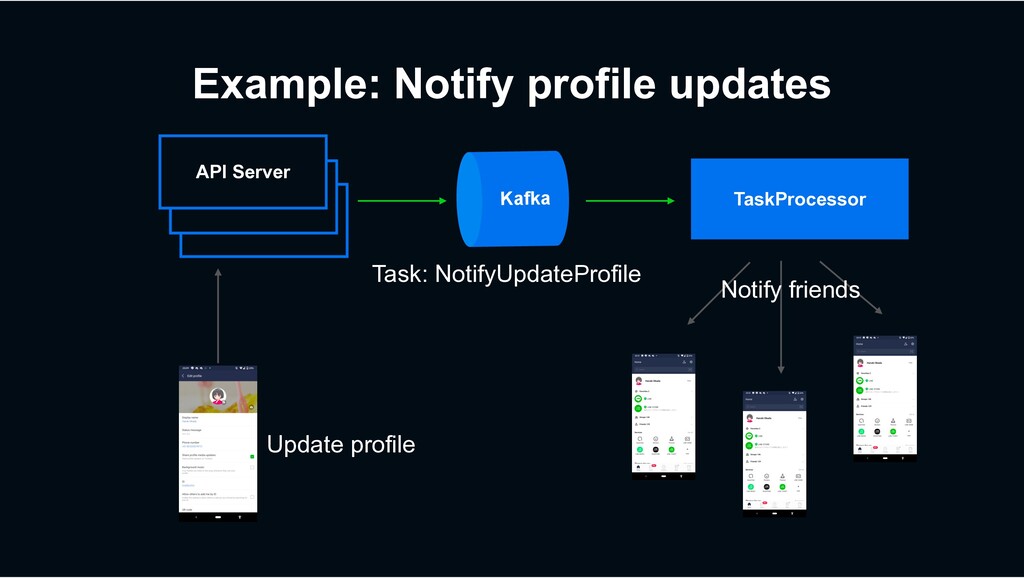
development for years › “High performance” is the most important feature Decaton provides › Kafka consumer framework › Aimed to implement reliable task processing on it
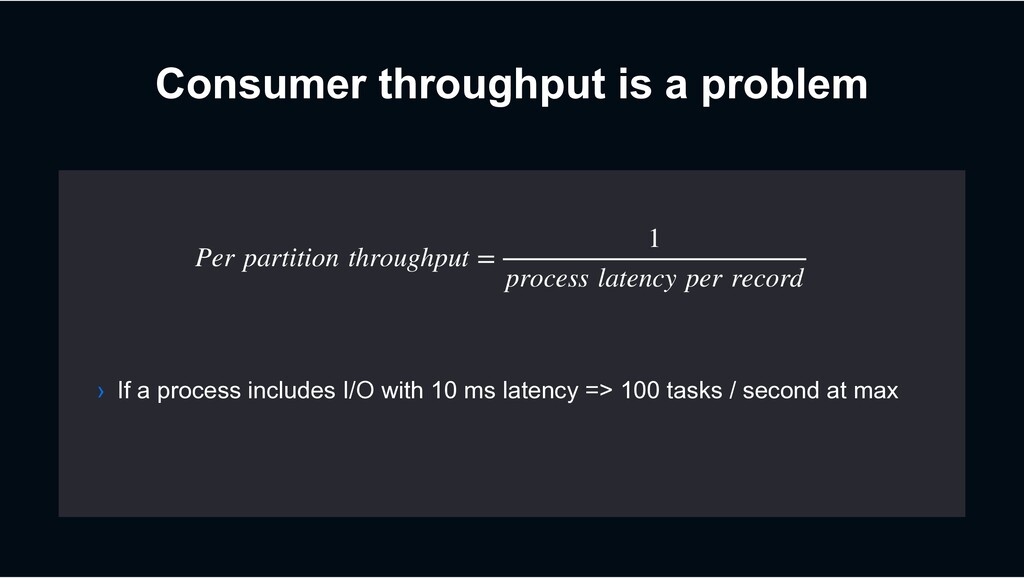
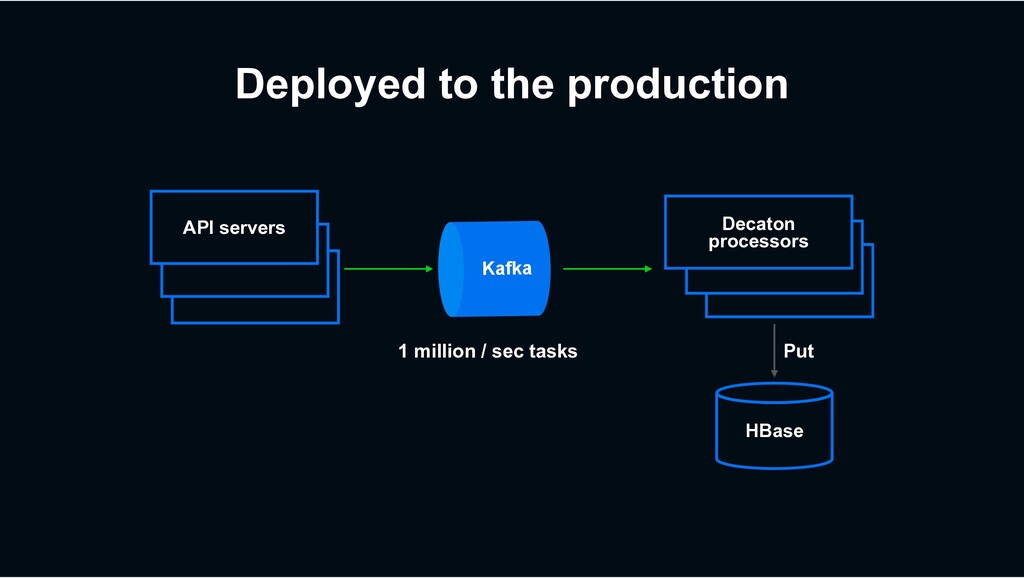
1 million tasks / sec in most high traffic use case › At least once delivery › All produced tasks should be processed without leaking › Usually I/O intensive › DB access, Web API calls, etc
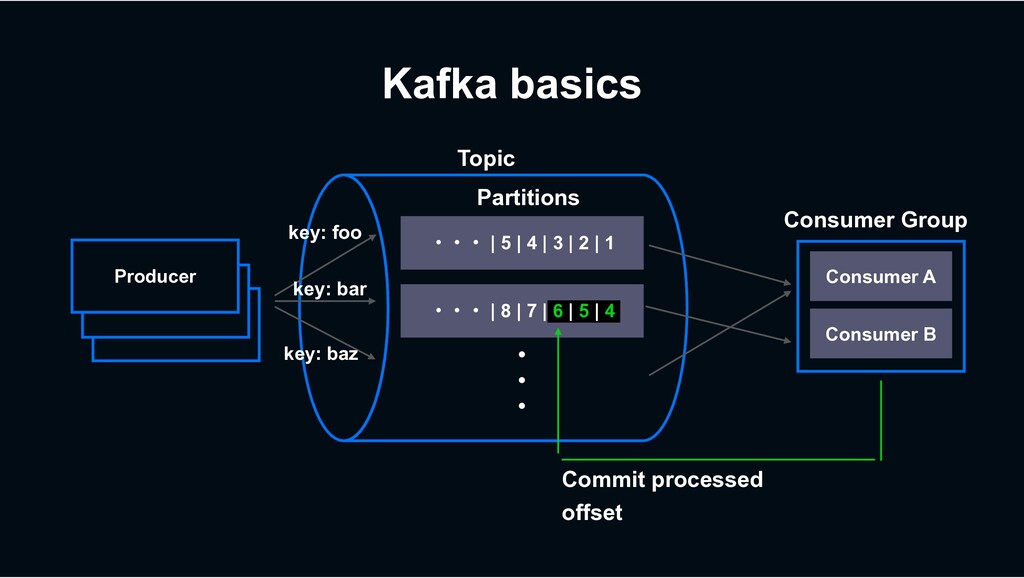
assignment >= 0 partitions › Some consumers could get 0 partition if num consumers > num partitions › => Max consumer concurrency is limited by the number of partitions ɾɾɾ | 5 | 4 | 3 | 2 | 1 Consumer A (assigned: 1) Consumer B (assigned: 1) ɾɾɾ | 8 | 7 | 6 | 5 | 4 Consumer C (assigned: 0) Partitions
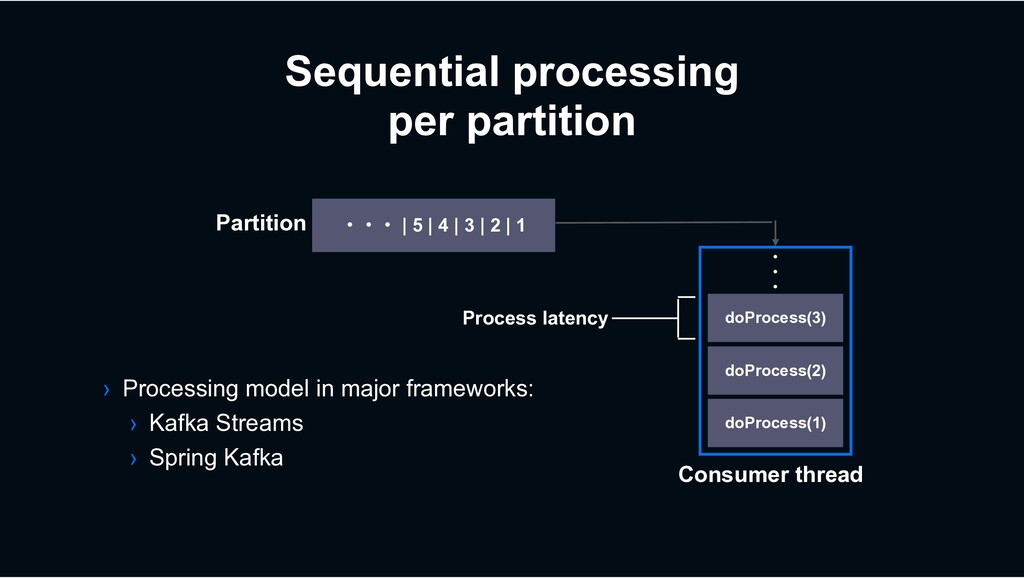
1 Partition doProcess(1) doProcess(2) doProcess(3) ɾ ɾ ɾ Consumer thread Process latency › Processing model in major frameworks: › Kafka Streams › Spring Kafka Sequential processing per partition
required concurrency from the beginning › However, › Adding partitions often requires contacting cluster administrator › Adding partitions has side-effects › Message ordering breaks temporarily
of consumer concurrency. At the same time: › The unit of producer batches => tends to generate smaller batches › Affects number of open file descriptors & mmapped files etc › Not preferable in LINE circumstance › Single, multi-tenant shared Kafka cluster
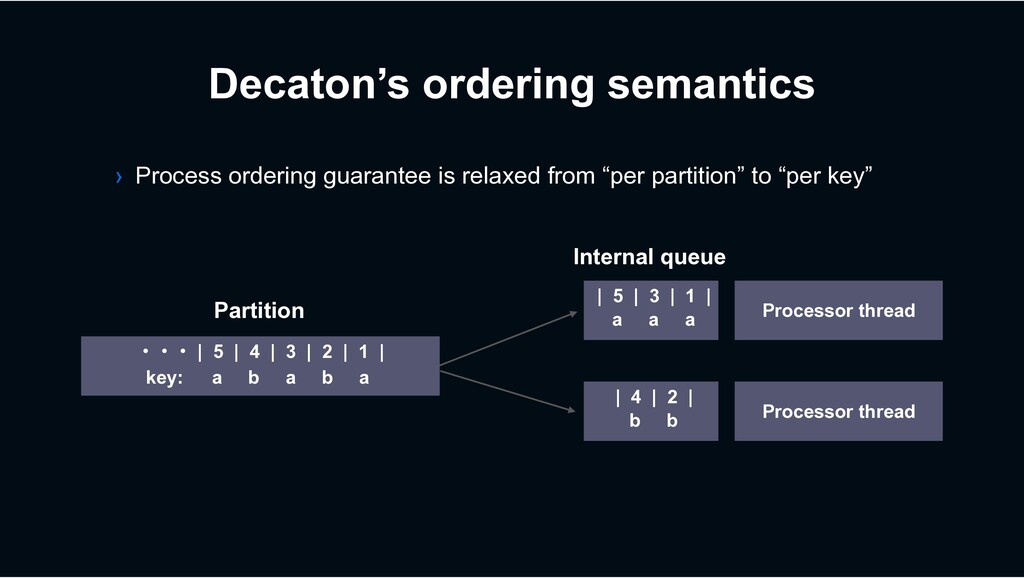
| 4 | 3 | 2 | 1 | a b a b a key: Partition | 5 | 3 | 1 | a a a Internal queue | 4 | 2 | b b › Process ordering guarantee is relaxed from “per partition” to “per key”
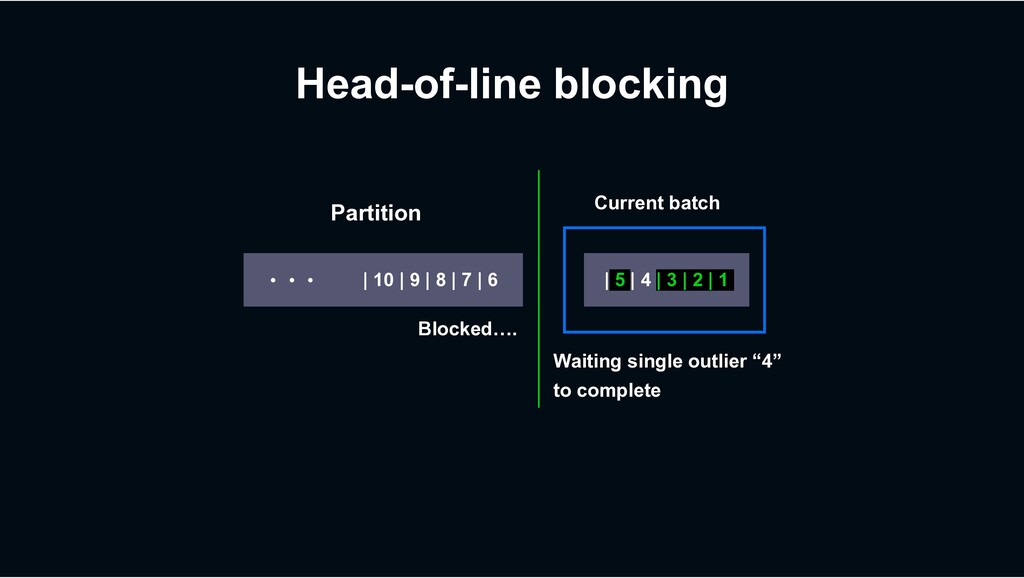
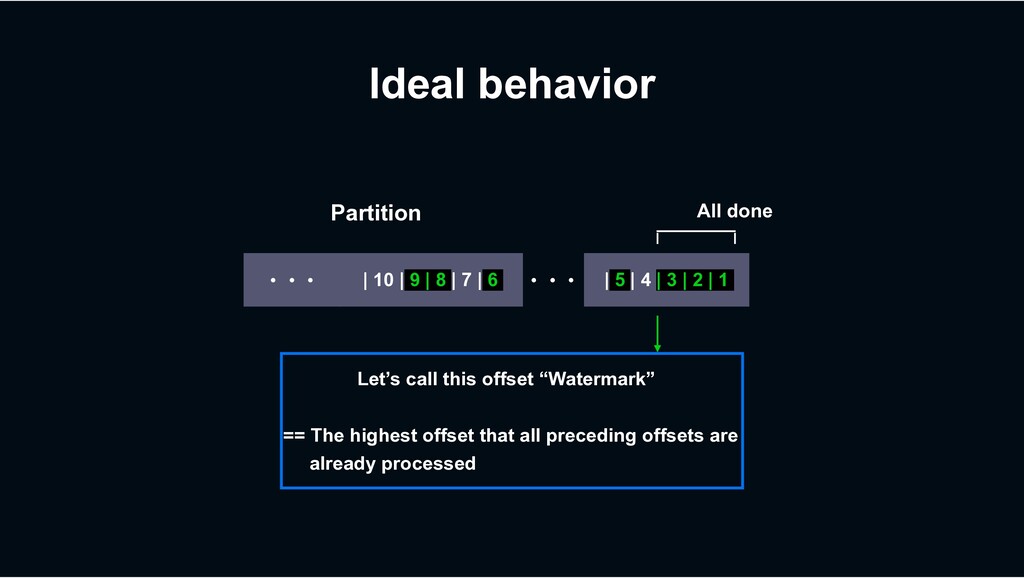
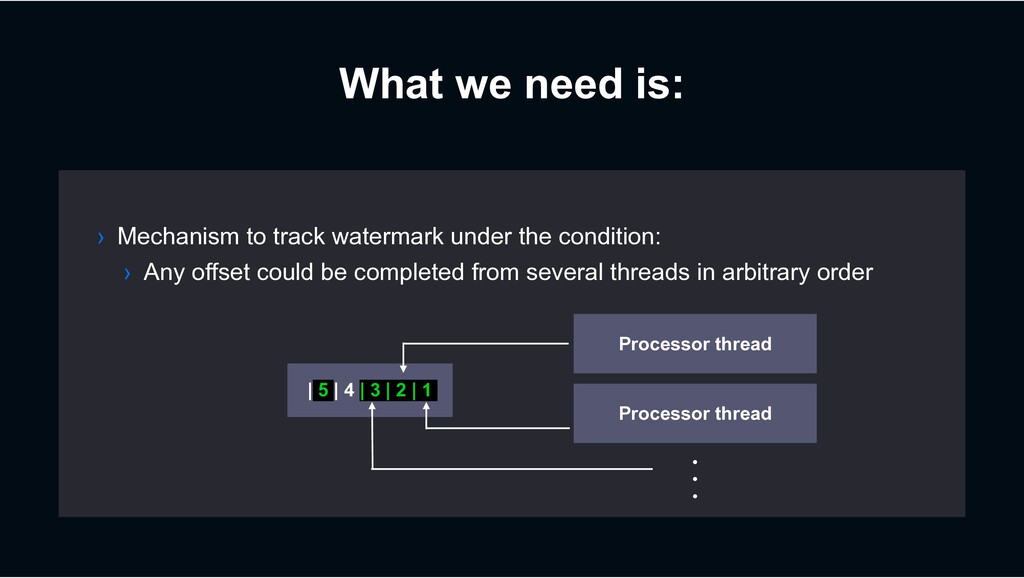
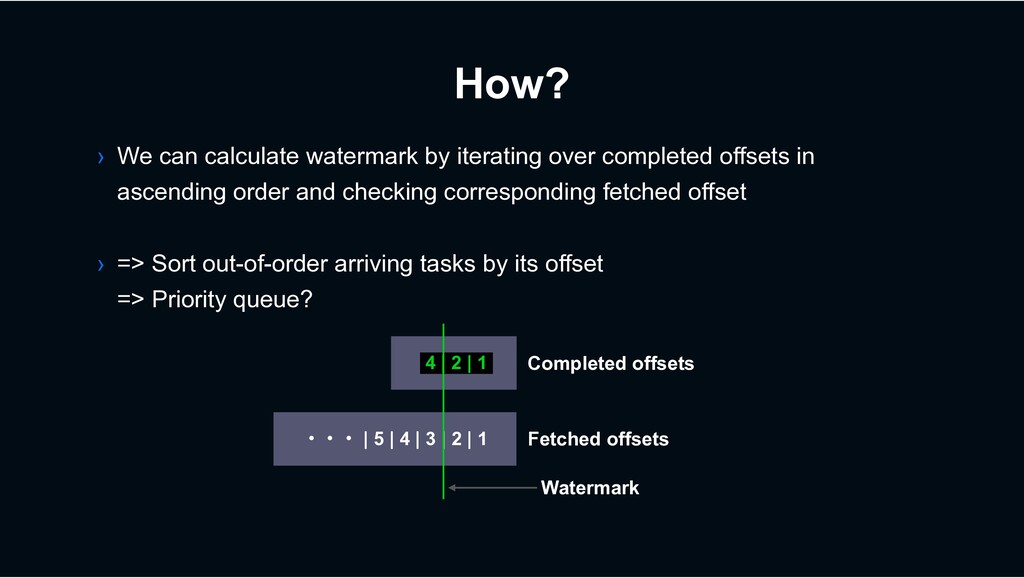
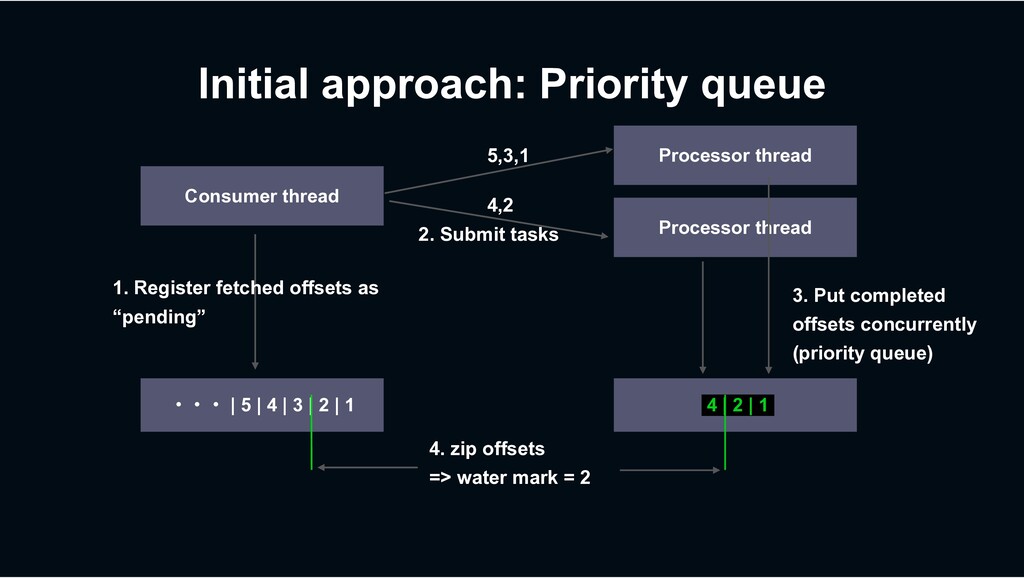
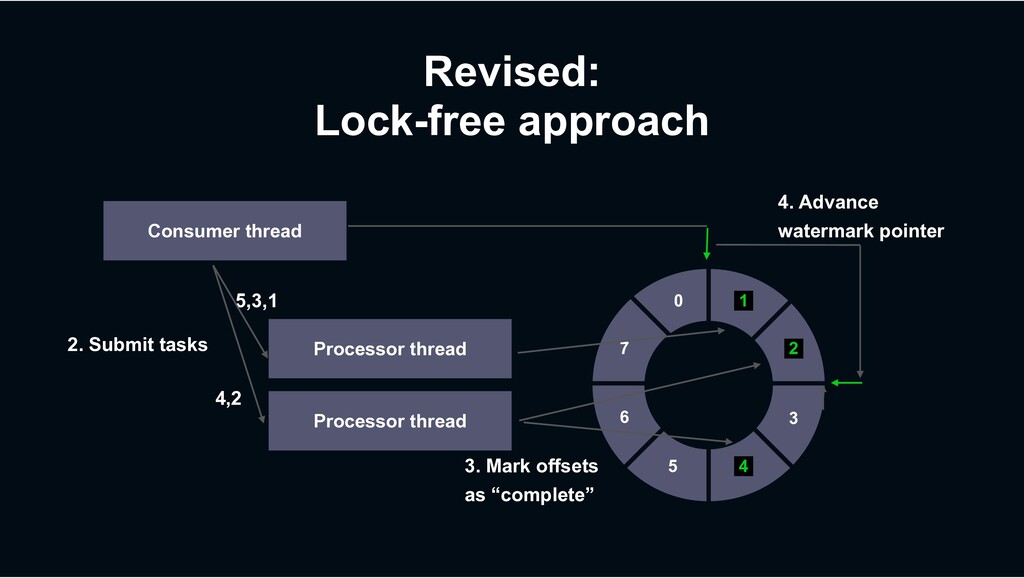
multiple threads › Which isn’t possible in many other consumer frameworks › With preserving at-least-once processing semantics › At stable delivery latency › Because it’s not a “batching” model › Per-key process ordering guarantee
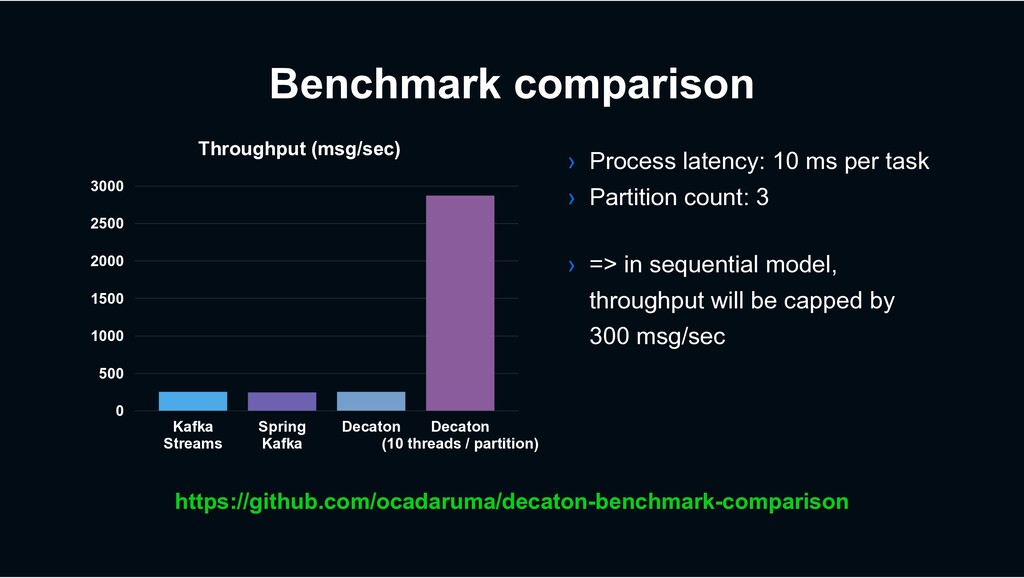
Streams Spring Kafka Decaton Decaton (10 threads / partition) › Process latency: 10 ms per task › Partition count: 3 https://github.com/ocadaruma/decaton-benchmark-comparison Throughput (msg/sec) › => in sequential model, throughput will be capped by 300 msg/sec
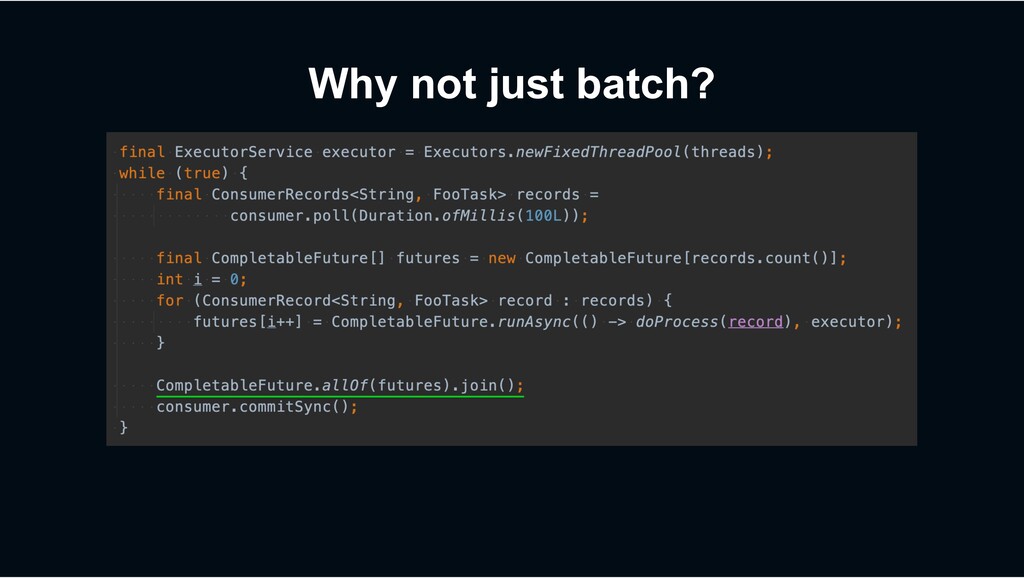
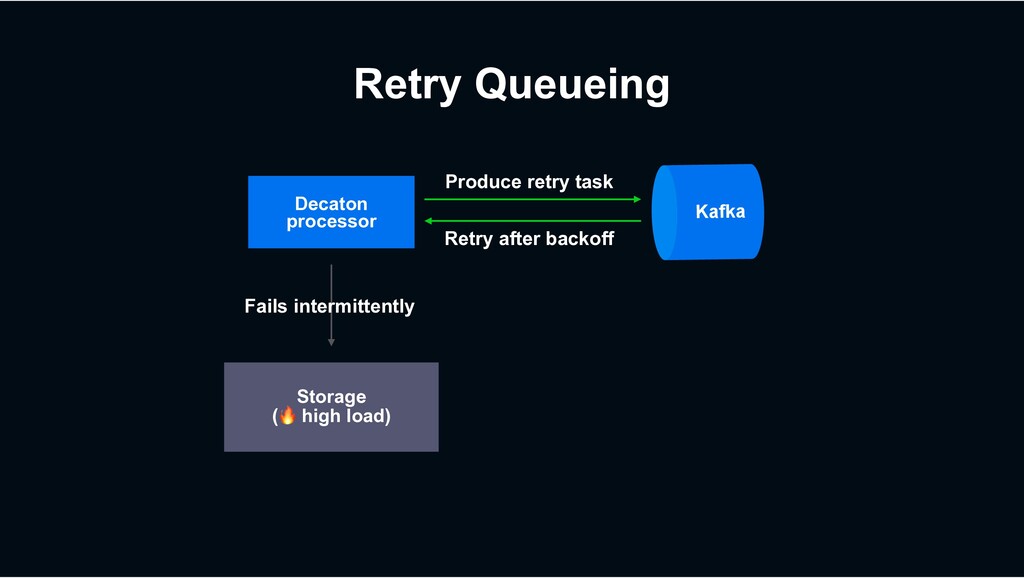
› Retry until succeeds? › => Can block subsequent tasks (Though Decaton’s processing model mitigates the impact) › Just give up the task? › => Not preferable
only supports JVM based language › If Decaton can support WebAssembly binary as a DecatonProcessor implementation, it unlocks supports for many programming languages ! › Adding experimental WebAssembly support to Decaton – Part 1, 2
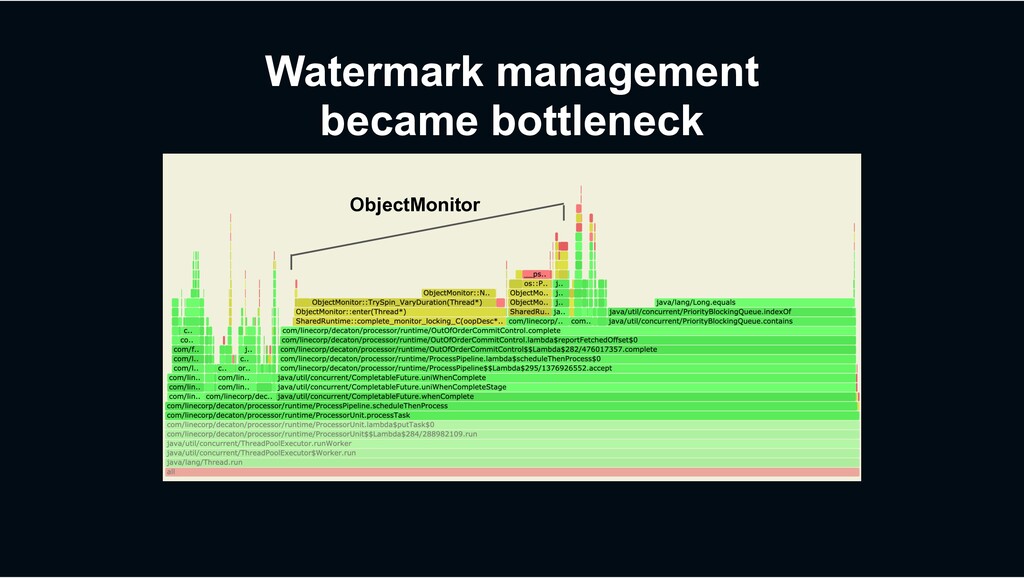
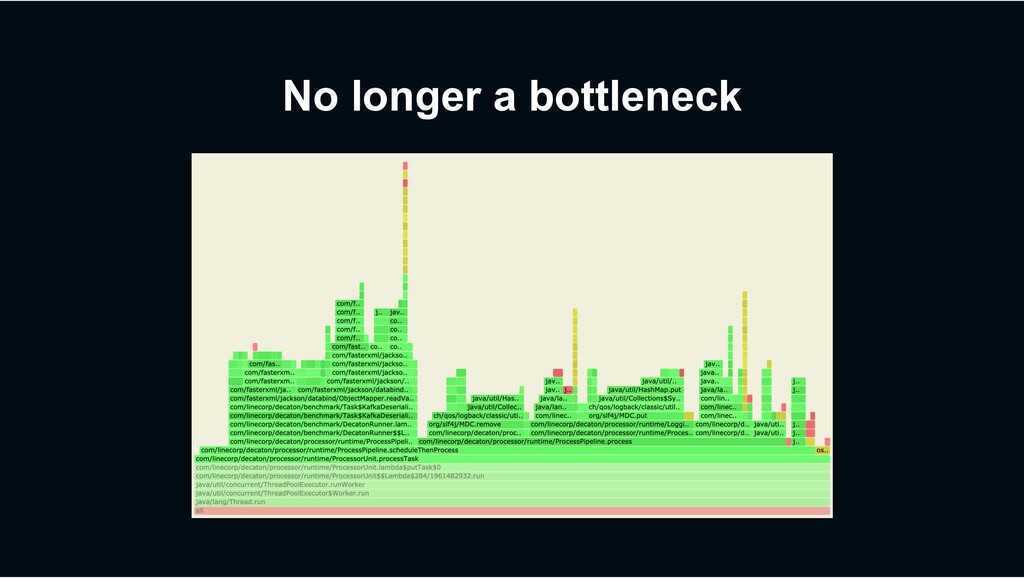
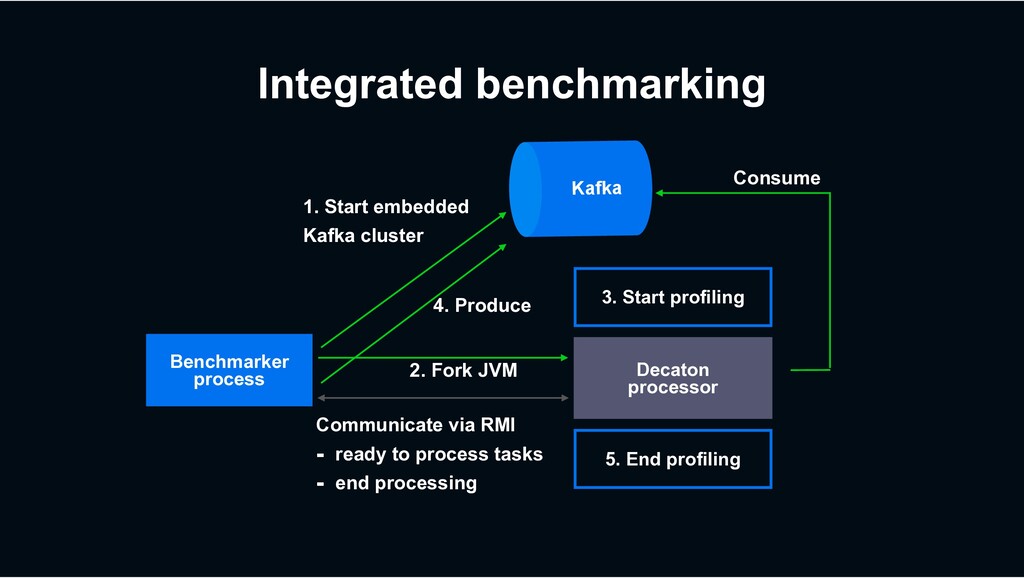
end-to-end processing performance › Rather than micro-benchmark for small portion of the code › Along with profiles to investigate bottleneck › Async-profiler › Linux taskstats › Measure performance transition per code changes
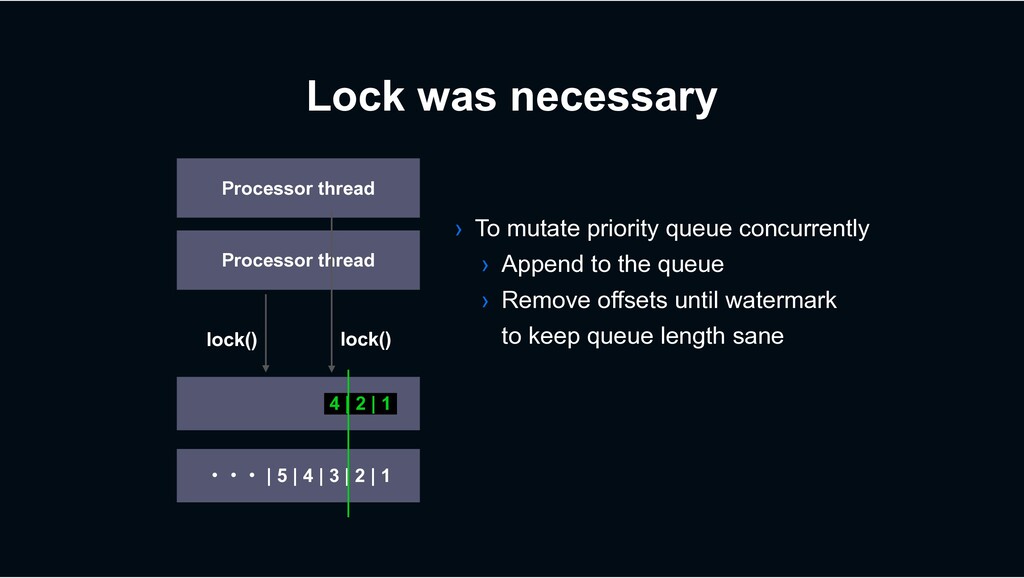
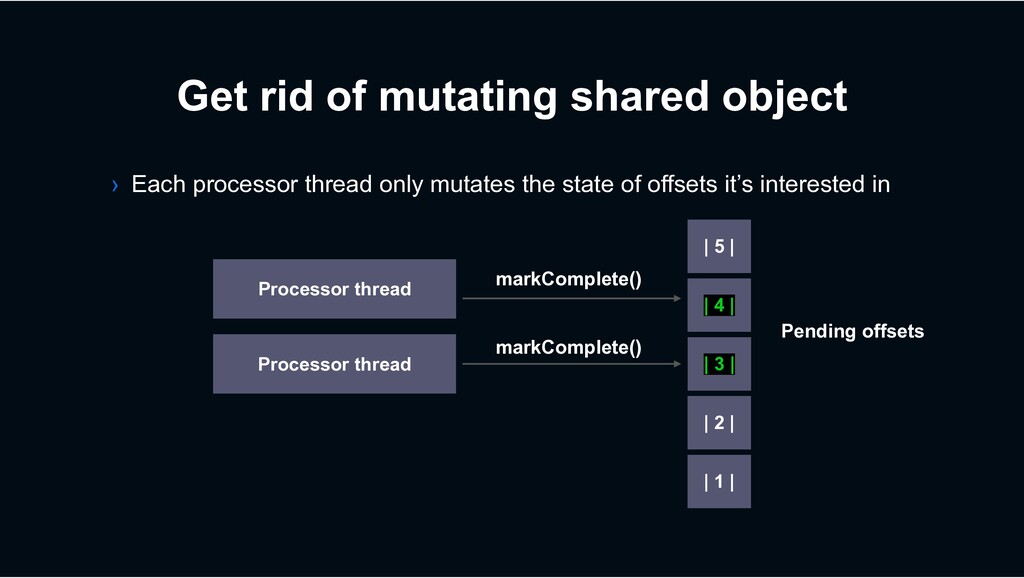
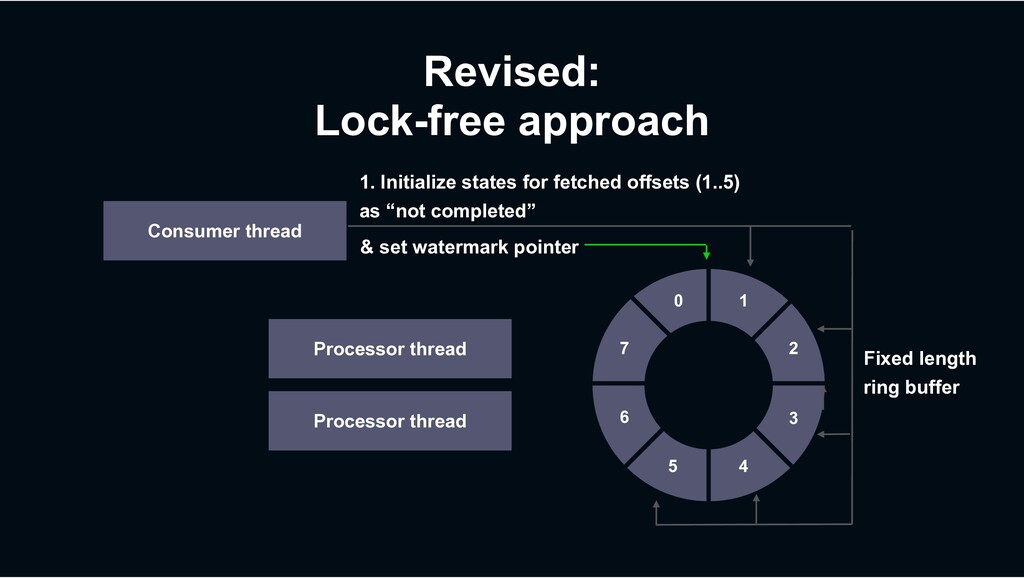
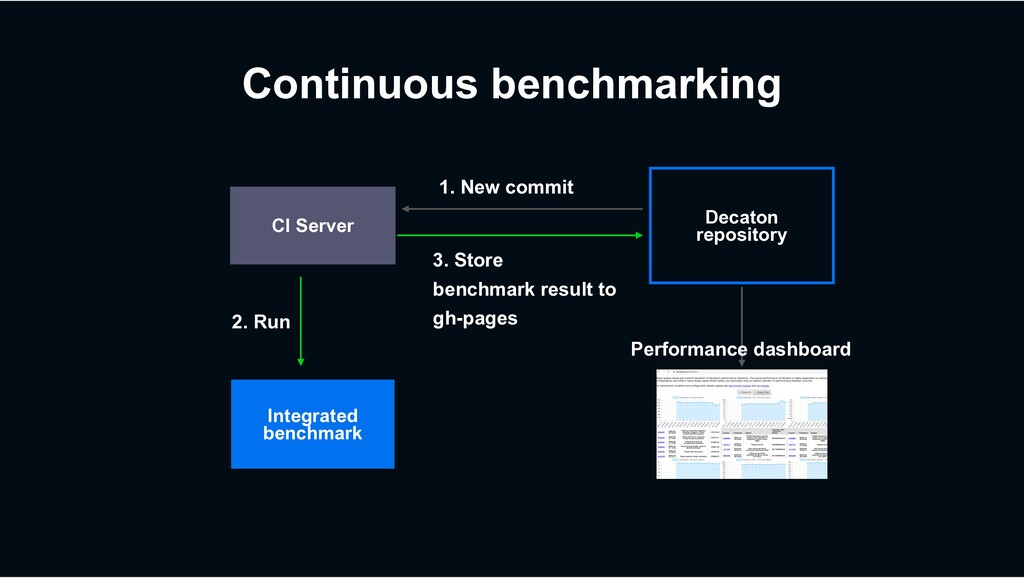
› Suites for I/O intensive workload the most › Made various efforts to make it high performant › Highly optimized commit management › Continuous integrated benchmarking › Decaton has been open-sourced https://github.com/line/decaton › Try it and give us your feedbacks!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}