戸上 真人(LINE株式会社 AI開発室 室長)
第20回情報科学技術フォーラム(FIT2021)での登壇資料です。
https://www.ipsj.or.jp/event/fit/fit2021/splist-IndustrialSession.html
「LINEにおける人工知能分野の取り組みのご紹介」
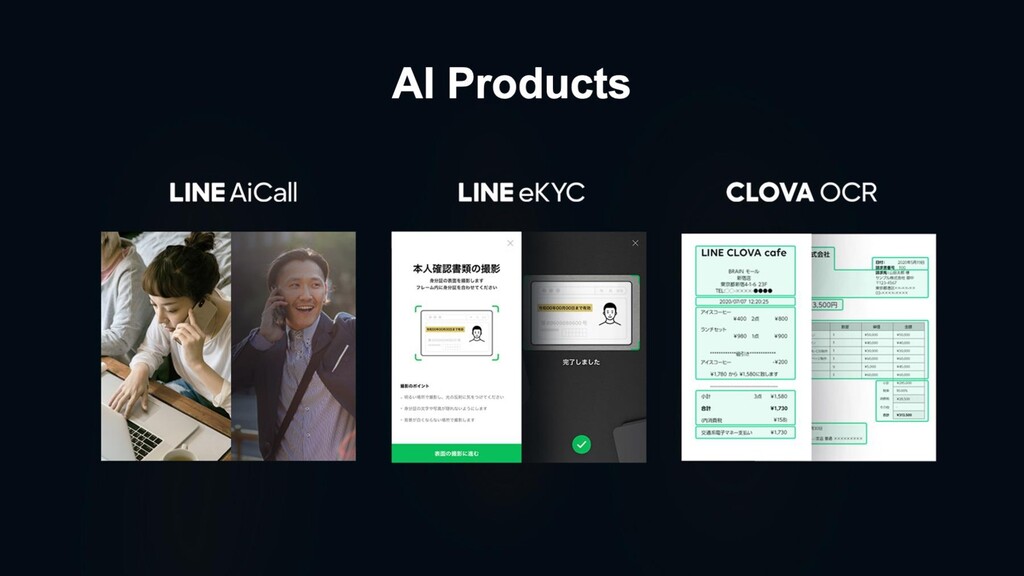
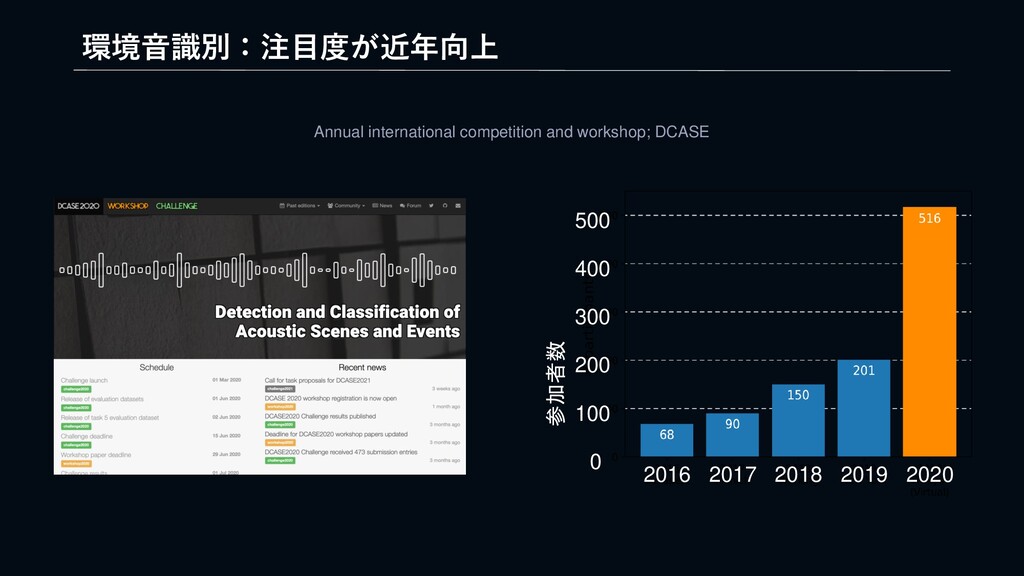
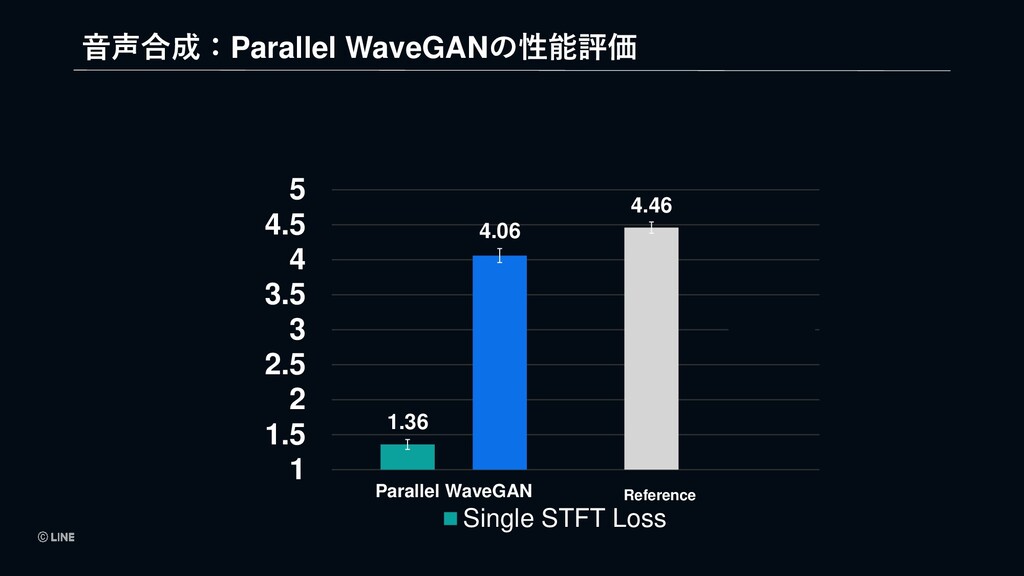
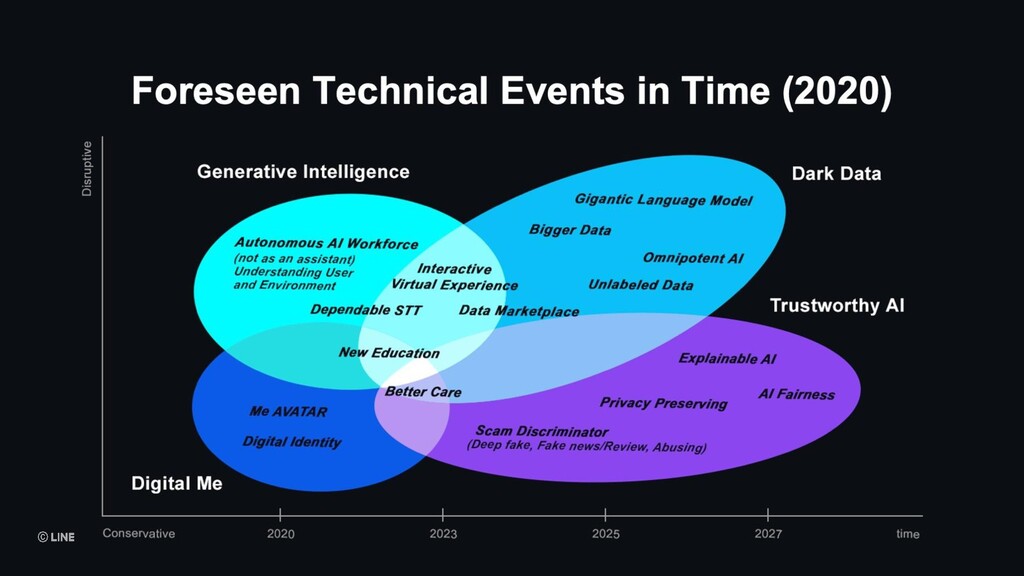
LINEではAI事業を「戦略事業」として位置づけており、アジアNo.1のAIテックリードカンパニーを目指し、積極的に事業展開しています。AIテクノロジーブランド「LINE CLOVA」として、音声認識、顔画像認識、文字認識、自然言語処理、セキュリティなど自社で技術開発し、コールセンターのAI化や、デジタル本人確認(eKYC)、RPA/OCRなど、マーケットニーズ・ペインポイントが明確な領域を定め、急速に事業拡大を続けています。また、新規事業分野事業としてGPT-XをはじめとしたBig Model、本人確認を発展したDigital認証基盤の構築、それらを"公正"に実現するためのTrustworhy AI(信頼できるAI)の研究開発に取り組んでいます。「より自然なユーザー体験をLife on LINEにもたらすことで、これからの当たり前を作り出す」をビジョンに、生活やビジネスに潜む煩わしさを解消し、AI技術が生活やビジネスの一部に溶け込んだサービス創出を目指しています。このセッションでは、そのサービス開発の組織的取り組みについての概要をご紹介いたします。
【略歴】日立製作所、Stanford大学客員研究員を経て2018年LINE入社。音声認識の研究開発チームであるSpeechチームのマネージャを経て、2021年よりAI開発室室長。2020年「Pythonで学ぶ音源分離」執筆。2011年東京大学工学系研究科航空宇宙工学専攻博士後期課程修了。博士(工学)。IEEE Senior Member。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}