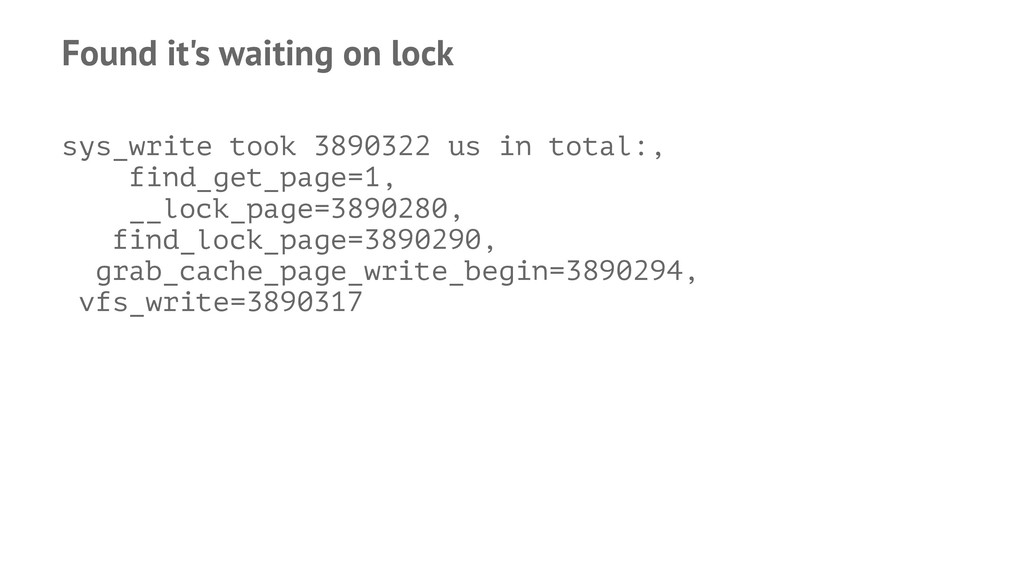
o_write,__generic_file_aio_write,file_update_time,generic_file_buffered_write,ext4_write_begin' ./ddown..py ... 'vfs_write,do_sync_write,ext4/ext4_file_write,generic_file_ai o_write,__generic_file_aio_write,file_update_time,generic_file_buffered_write,ext4/ext4_write_begin' (snip) ./ddown..py ... 'vfs_write,do_sync_write,ext4/ext4_file_write,generic_file_ai o_write,__generic_file_aio_write,file_update_time,generic_file_buffered_write,ext4/ext4_da_write_beg in,iov_iter_copy_from_user_atomic,ext4/ext4_da_write_end,ext4/ext4_journal_start_sb,grab_cache_page_ write_begin,block_write_begin,ext4/__ext4_journal_stop,jbd2/jbd2_journal_start,jbd2/start_this_handl e,find_lock_page,find_get_page' ./ddown..py ... 'vfs_write,grab_cache_page_write_begin,find_lock_page,find_ge t_page,lock_page' ./ddown..py ... 'vfs_write,grab_cache_page_write_begin,find_lock_page,find_ge t_page,__lock_page' ... 14 lines in total.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
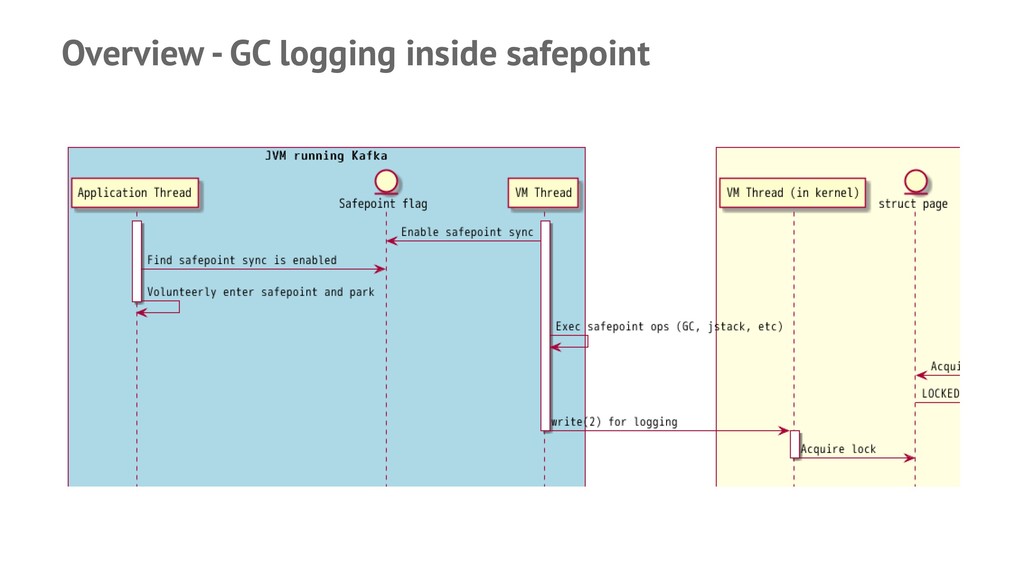
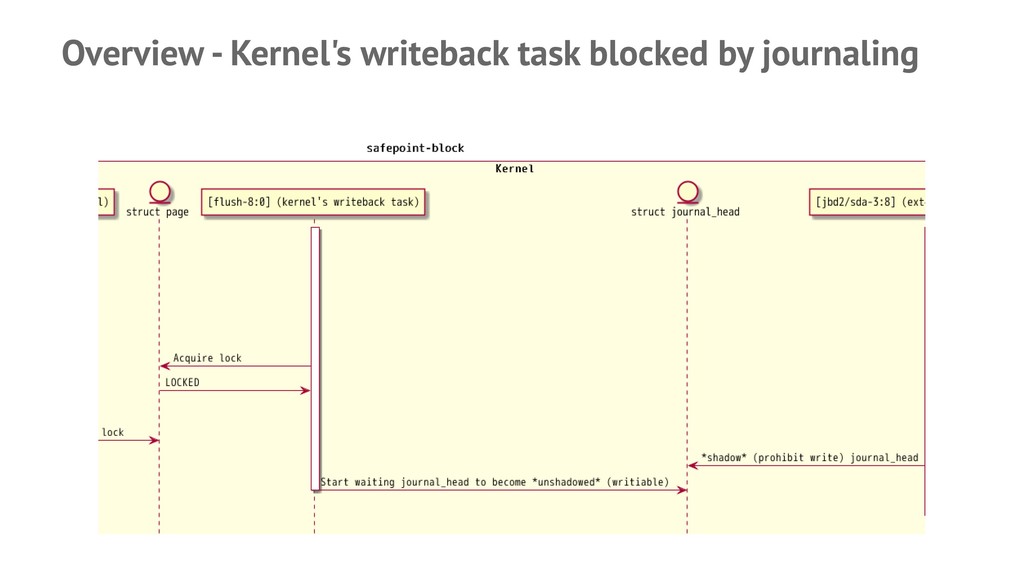
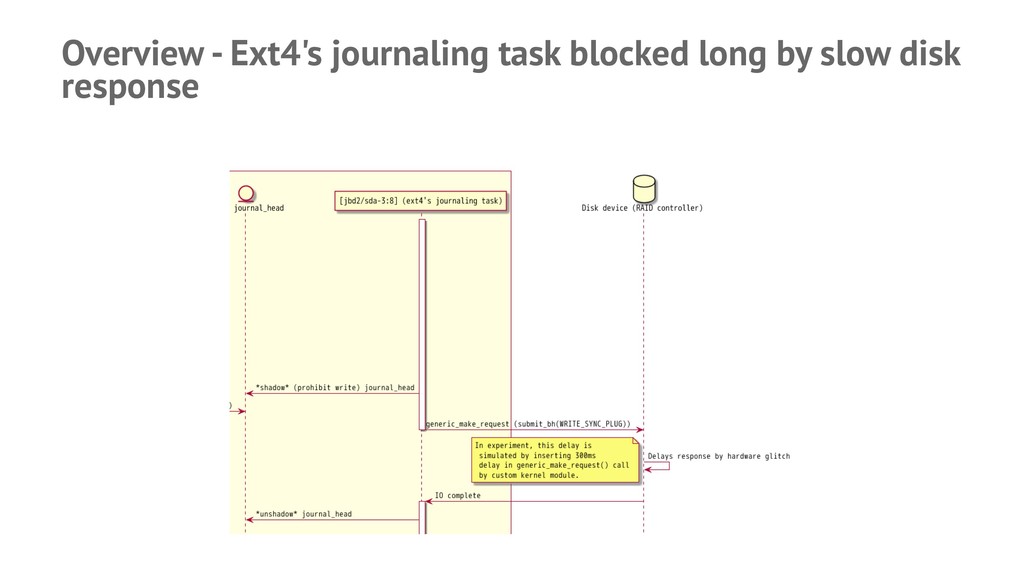
![Successfully reproduced and gotcha! — Found that [jbd2/sda3-8] kernel task](https://files.speakerdeck.com/presentations/cd44ef30415f4ac3bbf1446b473b5121/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}