lattice-free maximum mutual information-based acoustic models with sequence-level Kullback-Leibler divergence” (*2) S. Karita, et al., “A COMPARATIVE STUDY ON TRANSFORMER VS RNN IN SPEECH APPLICATIONS” End-to-End型により誤りが半減 0 2 4 6 8 10 E1 E2 E3 ⽇本語話し⾔葉コーパス(CSJ)に対する認識誤り率 (%) DNN-HMM End-to-End
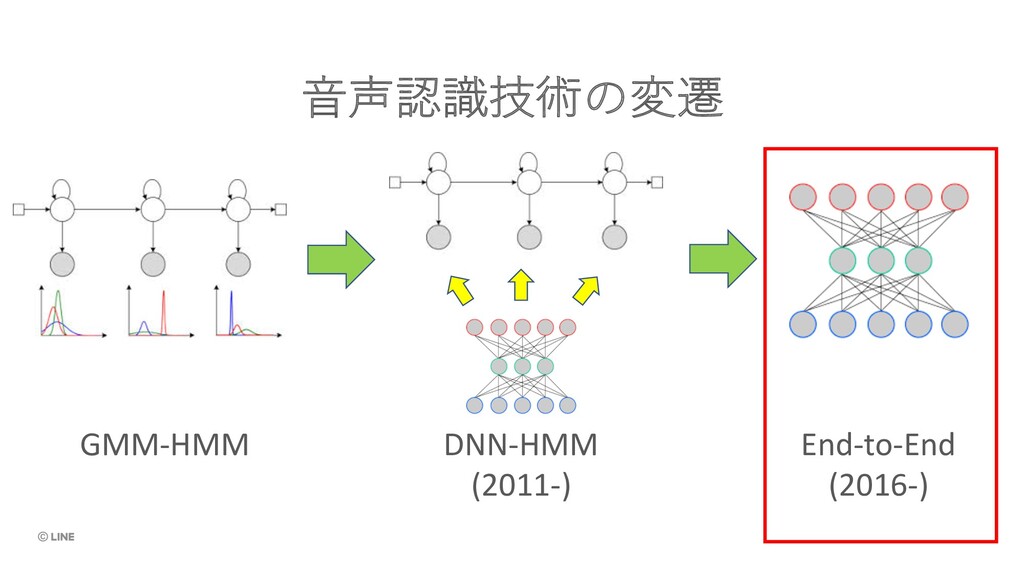
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
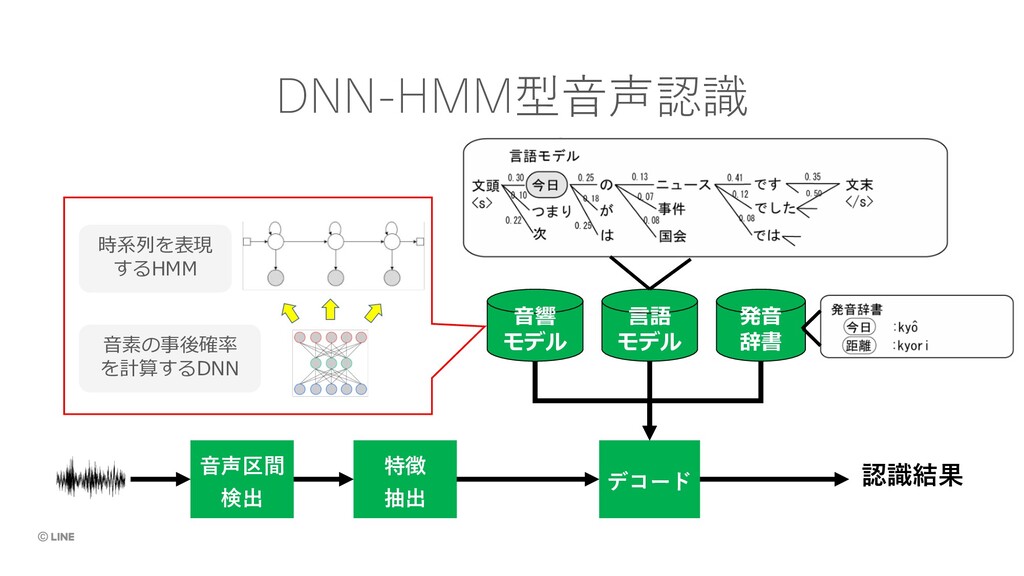
{kind=link}
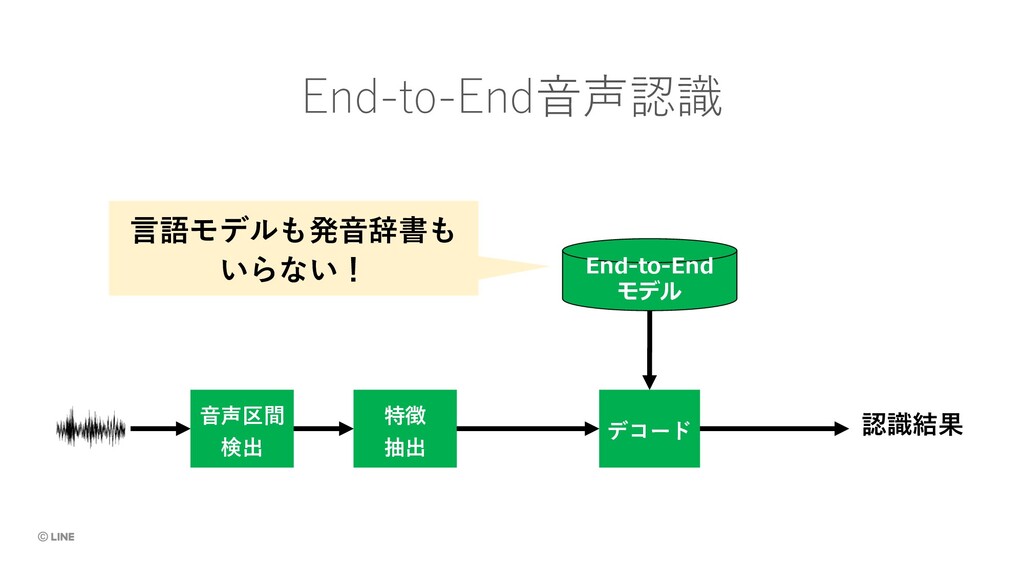
{kind=link}
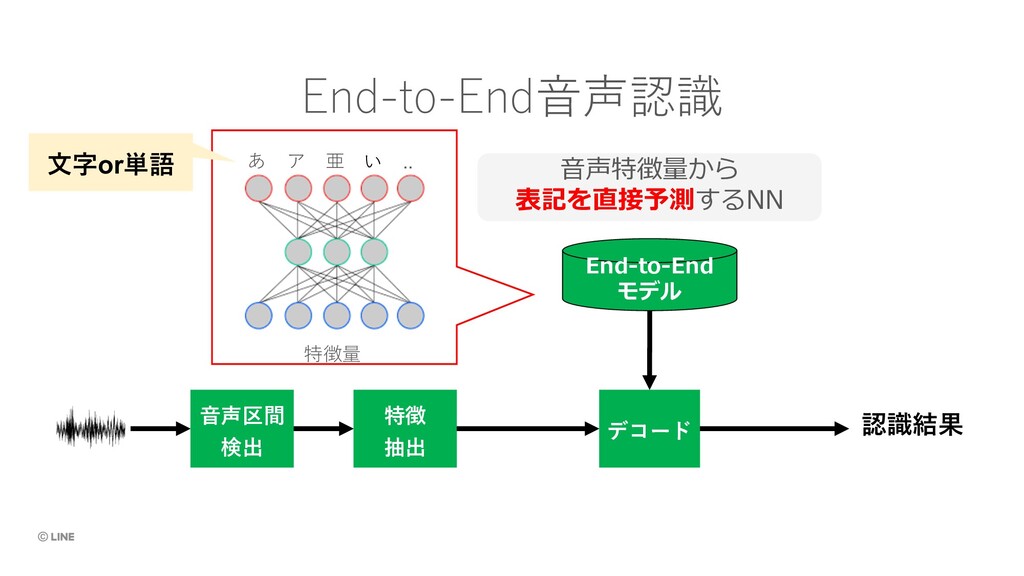
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MoChA (Monotonic Chunkwise Attention) [Chui+17] こ ん に ち は](https://files.speakerdeck.com/presentations/01e92392b72847b384ca1bf253071fa4/slide_21.jpg){kind=link}
{kind=link}
![NAT (Non-Autoregressive Transformer) [Chen+19] • 学習 ランダムにマスクした 正解系列を与えて マスクした⽂字を予測 ランダムにマスクした](https://files.speakerdeck.com/presentations/01e92392b72847b384ca1bf253071fa4/slide_23.jpg){kind=link}
![NAT (Non-Autoregressive Transformer) [Chen+19] • 認識 1 iter 2 iter](https://files.speakerdeck.com/presentations/01e92392b72847b384ca1bf253071fa4/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
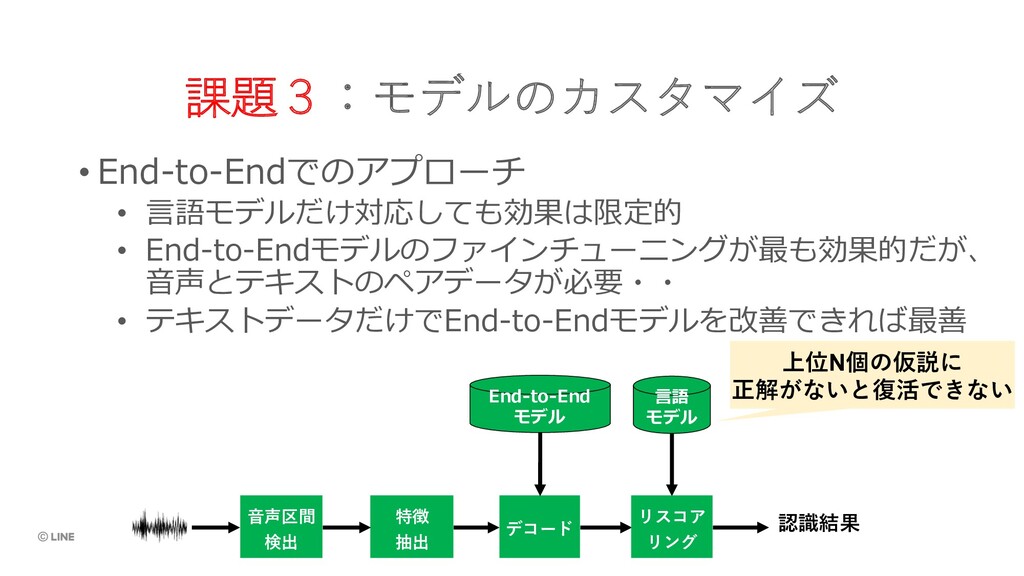{kind=link}
![⾳声合成を利⽤したアプローチ • ⾳声合成を利⽤したデータ増強 • ⼀定の効果はあるが、認識に不必要な⾮⾔語情報を含む • Back-Translation-Style Data Augmentation [Hayashi+17]](https://files.speakerdeck.com/presentations/01e92392b72847b384ca1bf253071fa4/slide_29.jpg){kind=link}
![Back-Translation-Style Data Augmentation [Hayashi+17] ①ペアデータで E2Eモデルを学習 ②テキストと対応する ⾳声のEncode特徴を算出 ③テキストから Encode特徴を](https://files.speakerdeck.com/presentations/01e92392b72847b384ca1bf253071fa4/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}