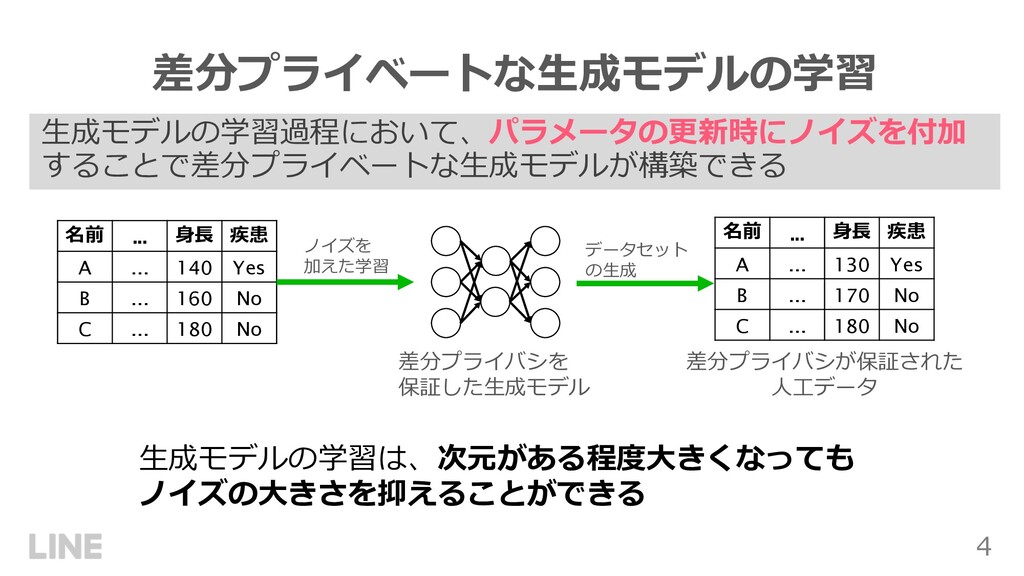
140 Yes B ... 160 No C ... 180 No ノイズを 加えた学習 差分プライバシを 保証した⽣成モデル 名前 ... ⾝⻑ 疾患 A ... 130 Yes B ... 170 No C ... 180 No データセット の⽣成 差分プライバシが保証された ⼈⼯データ ⽣成モデルの学習は、次元がある程度⼤きくなっても ノイズの⼤きさを抑えることができる
bayes." arXiv preprint arXiv:1312.6114 (2013). [2] J. Zhang, et al. "Privbayes: Private data release via bayesian networks." SIGMOD 2014. [3] G. Acs, et al. "Differentially private mixture of generative neural networks." IEEE Transactions on Knowledge and Data Engineering 31.6 (2018): 1109-1121. [4] M. Abadi, et al. "Deep learning with differential privacy." CCS 2016. [5] I. Goodfellow, et al. "Generative adversarial nets." NIPS (2014). [6] Xie, Liyang, et al. "Differentially private generative adversarial network." arXiv preprint arXiv:1802.06739 (2018). [7] J. Jordon, et al. “Generating Synthetic Data with Differential Privacy Guarantees.” ICLR (2019). [8] M. Park, et al. "DP-EM: Differentially private expectation maximization." AISTATS (2017). [9] W. Jiang, et al. "Wishart mechanism for differentially private principal components analysis." AAAI (2016).
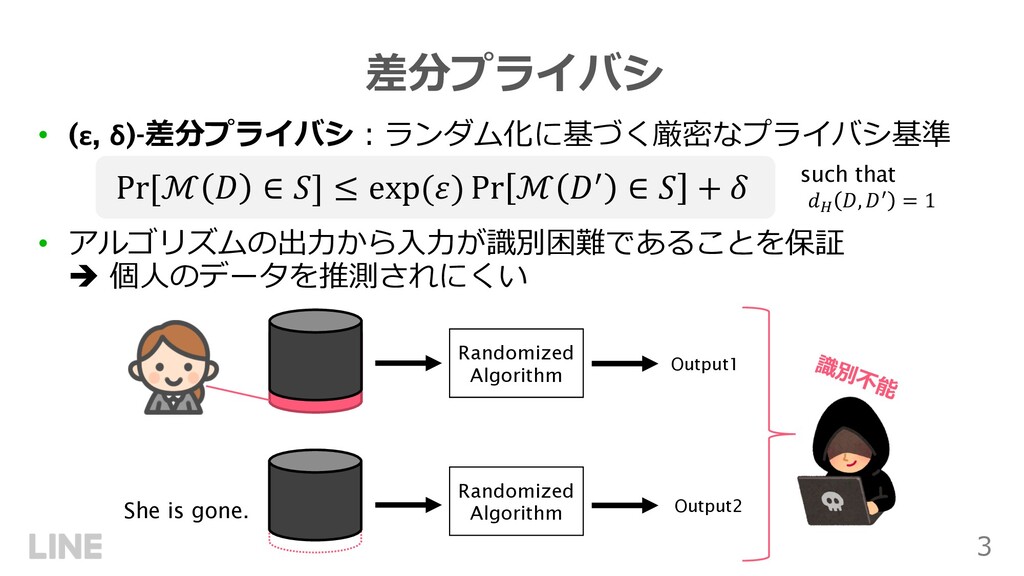
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![5 ⾼次元データに対して、元のデータらしさを保持することが困難 課題 元データ PrivBayes[2] ⽣成モデル ナイーブな⼿法[4] DP-GM[3] 深層⽣成モデル(VAE[1])](https://files.speakerdeck.com/presentations/3884062be9df482baebade699a290683/slide_4.jpg){kind=link}
![6 ⾼次元データに対しても、元のデータらしさを保持した⽣成モデルを 差分プライバシの制約下で実現 本研究の貢献 元データ PrivBayes[2] ⽣成モデル ナイーブな⼿法[4] DP-GM[3] 深層⽣成モデル(VAE[1])](https://files.speakerdeck.com/presentations/3884062be9df482baebade699a290683/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
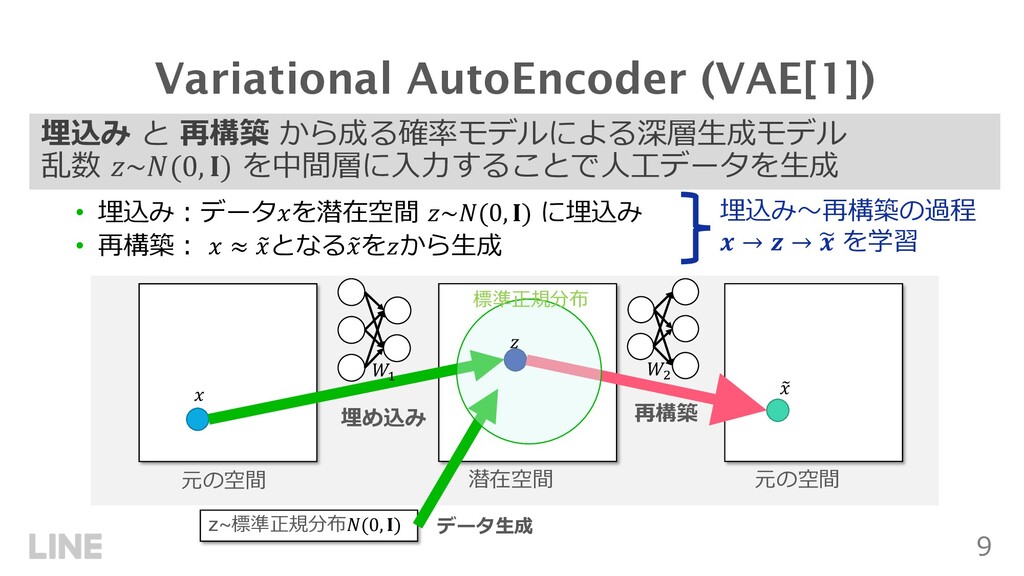{kind=link}
![10 確率的勾配降下法 (SGD) において、重み!の更新Δにノイズ"を加える ことで、学習されたモデルに差分プライバシーを保証 DP-SGD[4]: 深層モデルの差分プライベートな学習 #$ #% 名前](https://files.speakerdeck.com/presentations/3884062be9df482baebade699a290683/slide_9.jpg){kind=link}
![11 VAE を DP-SGD で訓練することで、差分プライバシを保証可能 ただし、ノイズによってうまく収束しない VAE[1] + DP-SGD[4] 潜在空間](https://files.speakerdeck.com/presentations/3884062be9df482baebade699a290683/slide_10.jpg){kind=link}
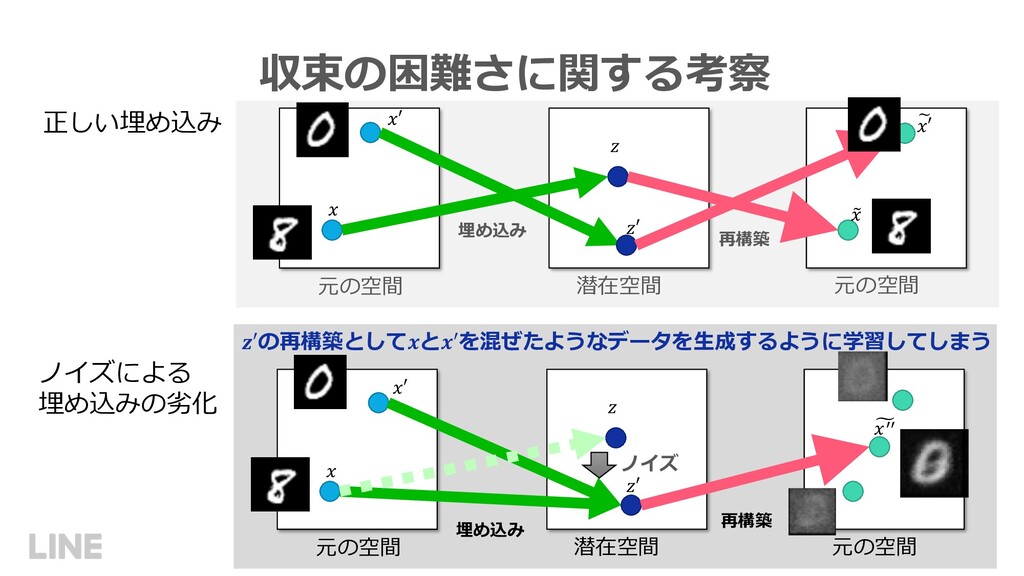{kind=link}
![13 事前に集めた類似するデータ群を対象に⽣成モデルを学習 DP-GM [3] • 利点︓埋め込みが不正確でもそれらしいデータを⽣成できる • 問題点 • “類似するデータ”をどうやって集める︖](https://files.speakerdeck.com/presentations/3884062be9df482baebade699a290683/slide_12.jpg){kind=link}
{kind=link}
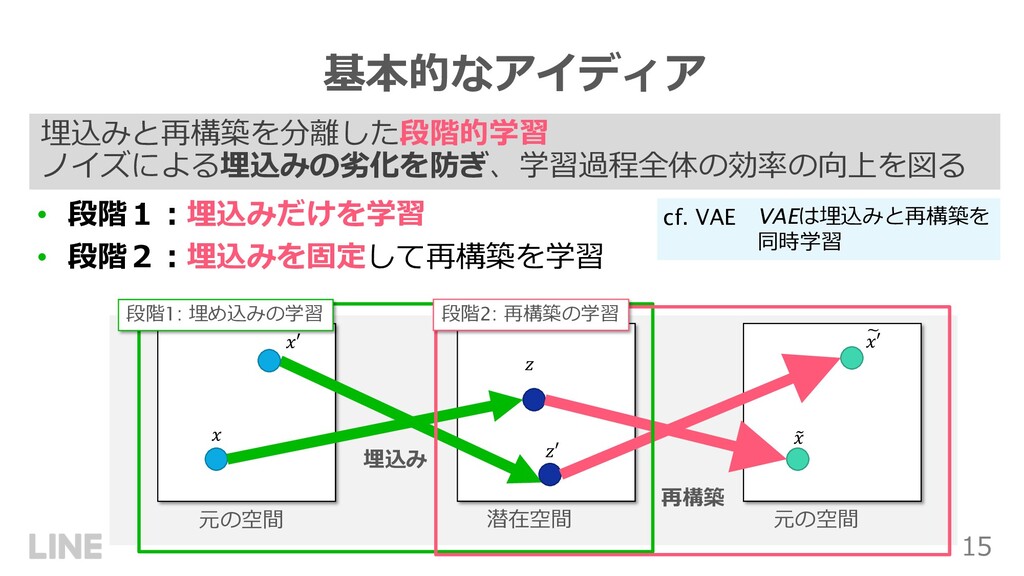{kind=link}
{kind=link}
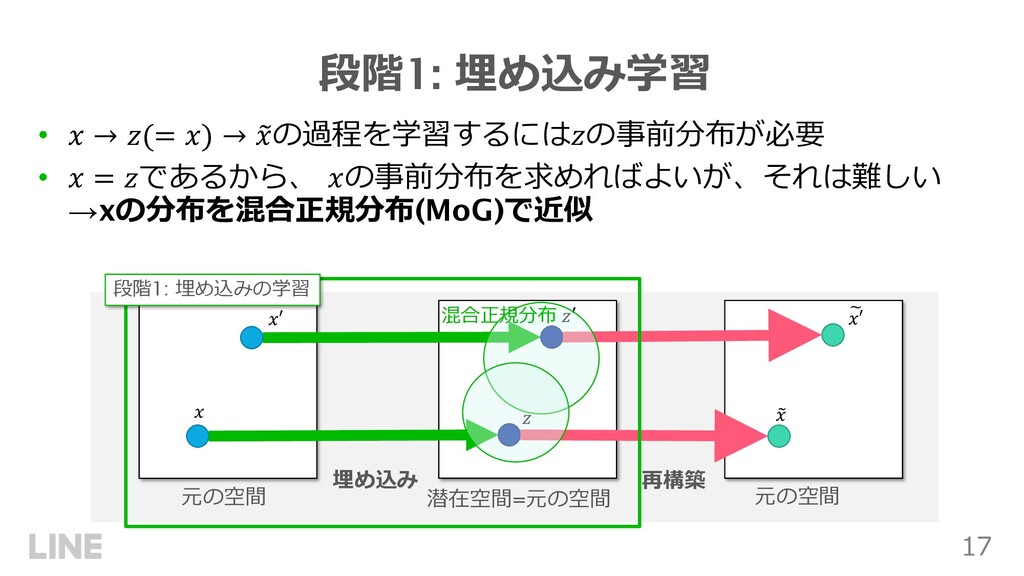{kind=link}
![18 段階1: 埋め込み学習 • データ!の従うMoGのパラメータをEMアルゴリズムで推定 • ⾼次元データはEMアルゴリズムがうまく機能しないため、PCAで次元圧縮 • 差分プライベートなEM、PCAとしてDP-EM [8]、DP-PCA](https://files.speakerdeck.com/presentations/3884062be9df482baebade699a290683/slide_17.jpg){kind=link}
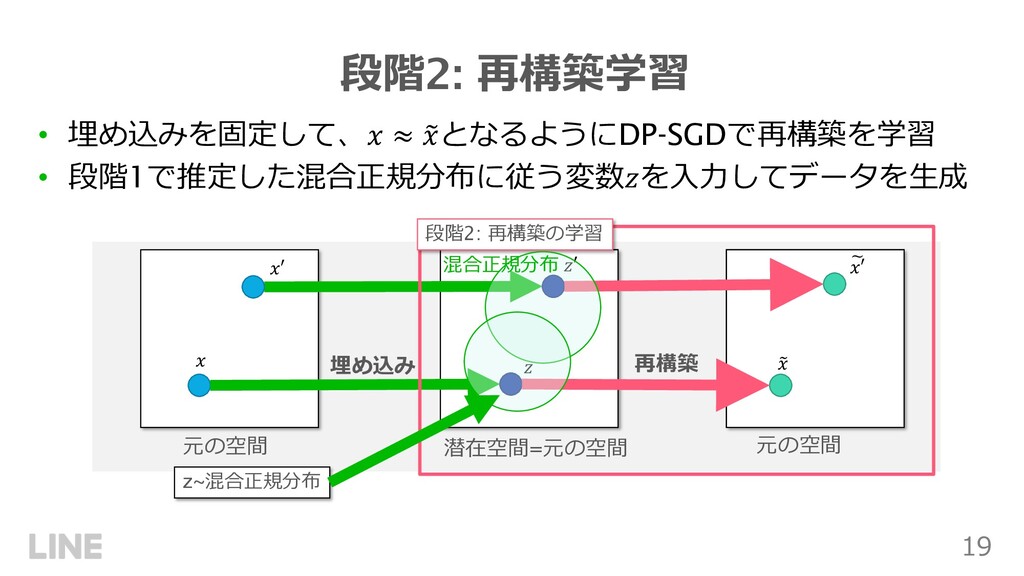{kind=link}
{kind=link}
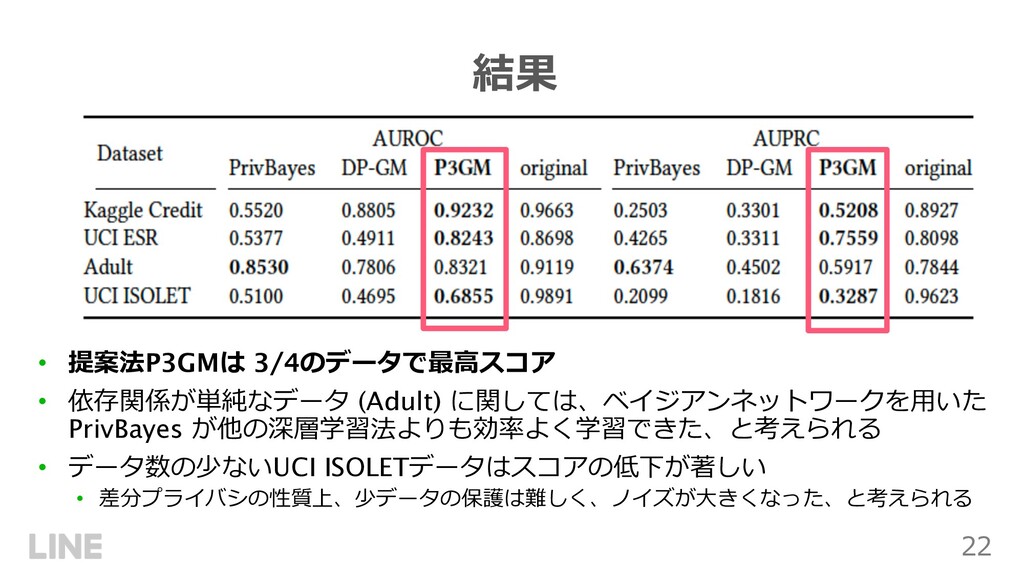
{kind=link}
{kind=link}
![23 まとめ • 差分プライバシーの制約下、⾼次元データであっても、元のデータ らしさを保持可能な⽣成モデルP3GMを提案 • 実験により提案法の有⽤性を確認 元データ PrivBayes[2] ⽣成モデル](https://files.speakerdeck.com/presentations/3884062be9df482baebade699a290683/slide_22.jpg){kind=link}
![24 参考⽂献 [1] DP Kingma and Max Welling. "Auto-encoding variational](https://files.speakerdeck.com/presentations/3884062be9df482baebade699a290683/slide_23.jpg){kind=link}