Representing concepts for the purpose of cross-linguistic language comparison
Keynote held at CARLA 2020, the second international workshop on "Concepts in Action: Representation, Learning, and Application" (2020-09-23, virtual conference, Bolzano, University of Osnabrück).
List Research Group “Computer-Assisted Language Comparison” Department of Linguistic and Cultural Evolution Max Planck Institute for the Science of Human History Jena, Germany 2020/09/23 very long title P(A|B)=P(B|A)... 1 / 32
they exist." (August Schleicher 1863) walkman Indo-European Germanic Old English English p f f f ə a æ ɑː t d d ð eː eː e ə r r r r Germanic German English iPod Comparative Linguistics
p f f f ə a æ ɑː t d d ð eː eː e ə r r r r Germanic German English walkman "All languages change, as long as they exist." (August Schleicher 1863) Comparative Linguistics
p f f f ə a æ ɑː t d d ð eː eː e ə r r r r Germanic German English iPod "All languages change, as long as they exist." (August Schleicher 1863) Comparative Linguistics
p f f f ə a æ ɑː t d d ð eː eː e ə r r r r Germanic German English iPod "All languages change, as long as they exist." (August Schleicher 1863) Comparative Linguistics
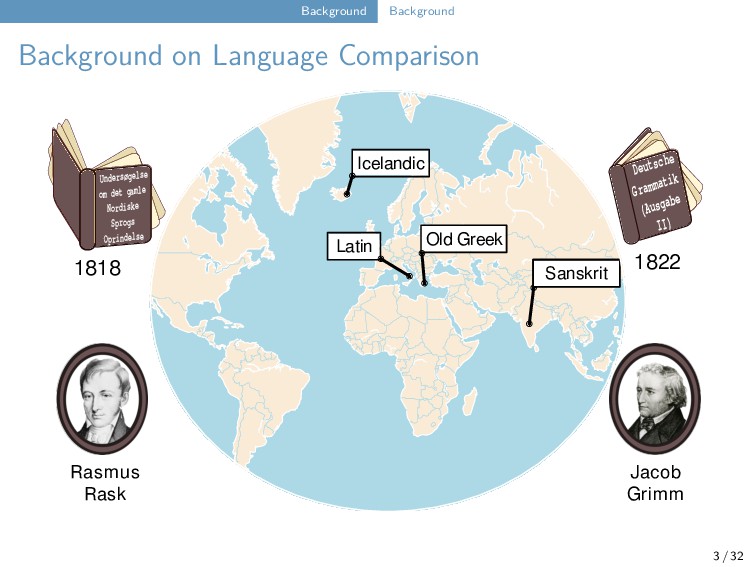
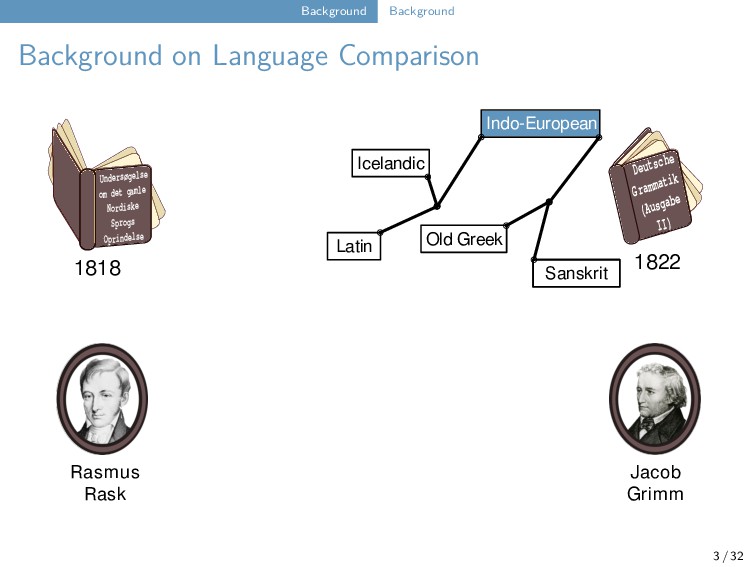
Old Indian Old Greek Latin Sanskrit Jacob Grimm Rasmus Rask Undersøgelse om det gamle Nordiske Sprogs Oprindelse 1818 Deutsche Grammatik (Ausgabe II) 1822
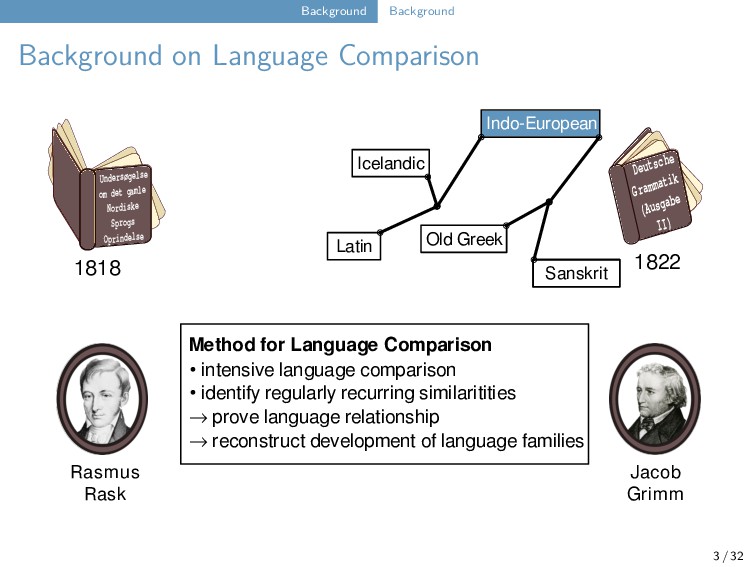
Old Indian Old Greek Latin Sanskrit Indo-European Method for Language Comparison • intensive language comparison • identify regularly recurring similaritities → prove language relationship → reconstruct development of language families Jacob Grimm Rasmus Rask Undersøgelse om det gamle Nordiske Sprogs Oprindelse 1818 Deutsche Grammatik (Ausgabe II) 1822
Old Indian Old Greek Latin Sanskrit Indo-European Method for Language Comparison • intensive language comparison • identify regularly recurring similaritities → prove language relationship → reconstruct development of language families Jacob Grimm Rasmus Rask Undersøgelse om det gamle Nordiske Sprogs Oprindelse 1818 Deutsche Grammatik (Ausgabe II) 1822
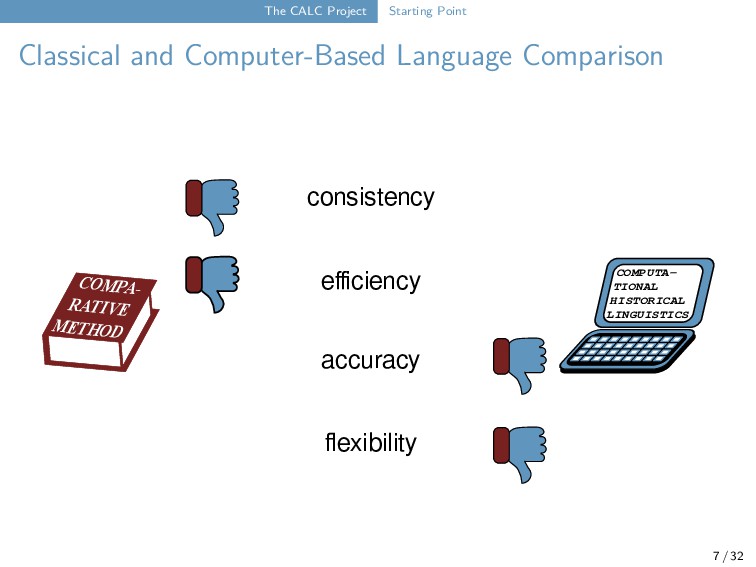
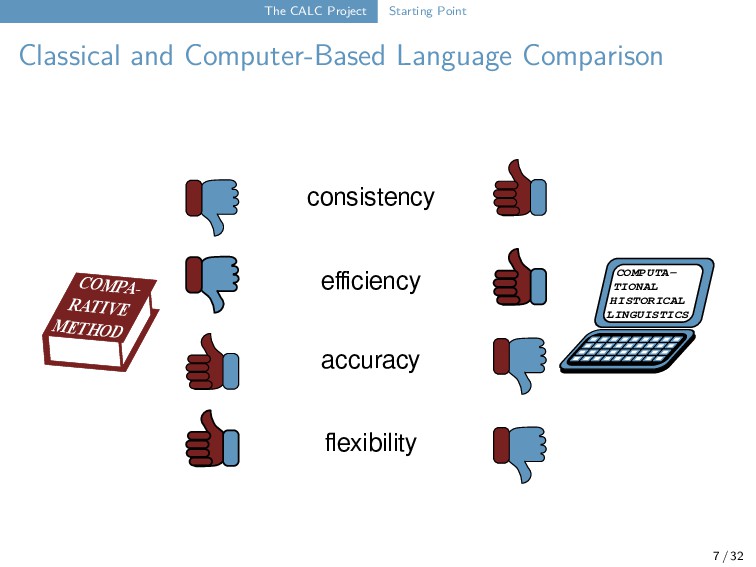
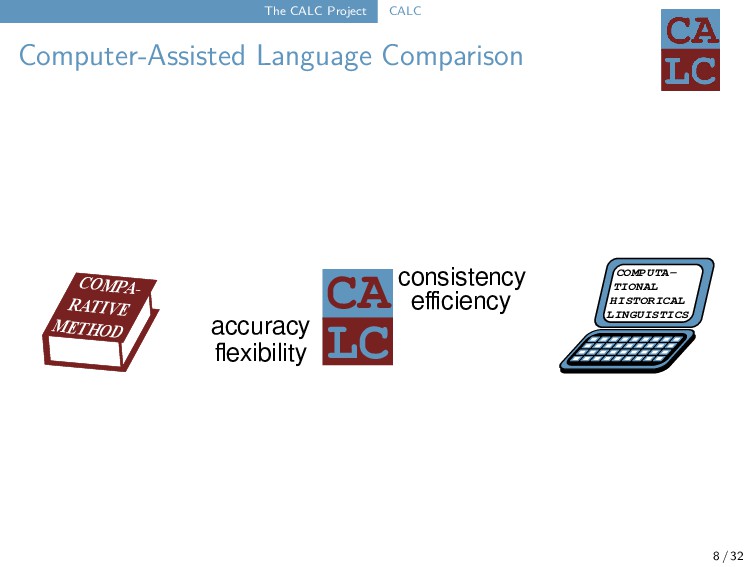
of computational approaches → lack of flexibility → lack of accuracy → often rely on manually annotated data → produce results in a black-box fashion Breton d - ã n t - Danish d̥ʰ - a n - - Dutch t - ɑ n t - English t - uː - θ - French d - ã - - - German t͜s - aː n - - Greek ð - o̞ n d i Italian d - ɛ n t e Portuguese d - ẽ - t ɨ Spanish d j e n t e /-French | | /-Greek_Mod | | ----| /---| /-Portuguese | | | | | | \---| /-Italian | | | /---| | | | | \-Spanish \---| \---| | | /-Breton | \---| | \-Dutch | | /-English \---| | /-Danish \---| \-German phonetic alignment (List 2012, 2014) phylogenetic reconstruction
of computational approaches → lack of flexibility → lack of accuracy → often rely on manually annotated data → produce results in a black-box fashion Breton d - ã n t - Danish d̥ʰ - a n - - Dutch t - ɑ n t - English t - uː - θ - French d - ã - - - German t͜s - aː n - - Greek ð - o̞ n d i Italian d - ɛ n t e Portuguese d - ẽ - t ɨ Spanish d j e n t e /-French | | /-Greek_Mod | | ----| /---| /-Portuguese | | | | | | \---| /-Italian | | | /---| | | | | \-Spanish \---| \---| | | /-Breton | \---| | \-Dutch | | /-English \---| | /-Danish \---| \-German phonetic alignment (List 2012, 2014) phylogenetic reconstruction
of computational approaches → lack of flexibility → lack of accuracy → often rely on manually annotated data → produce results in a black-box fashion Breton d - ã n t - Danish d̥ʰ - a n - - Dutch t - ɑ n t - English t - uː - θ - French d - ã - - - German t͜s - aː n - - Greek ð - o̞ n d i Italian d - ɛ n t e Portuguese d - ẽ - t ɨ Spanish d j e n t e /-French | | /-Greek_Mod | | ----| /---| /-Portuguese | | | | | | \---| /-Italian | | | /---| | | | | \-Spanish \---| \---| | | /-Breton | \---| | \-Dutch | | /-English \---| | /-Danish \---| \-German phonetic alignment (List 2012, 2014) phylogenetic reconstruction
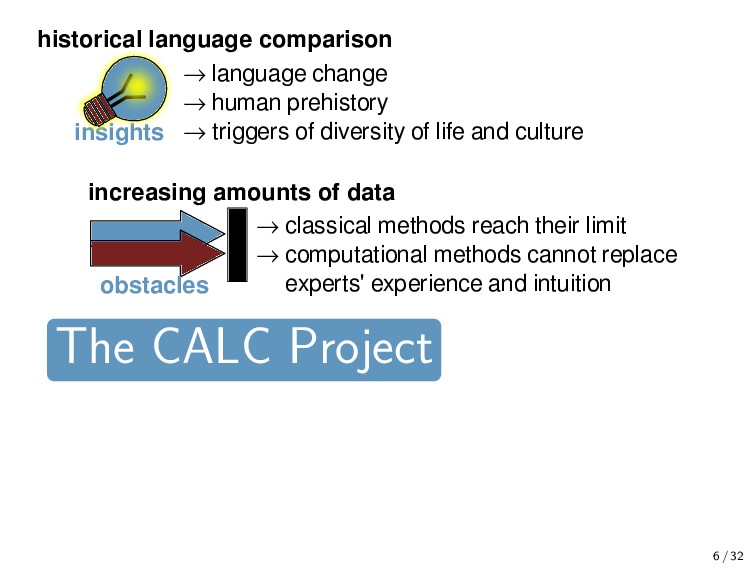
obstacles". (Antoine Meillet 1925) insights → language change → human prehistory → triggers of diversity of life and culture → classical methods reach their limit → computational methods cannot replace experts' experience and intuition obstacles increasing amounts of data historical language comparison large and diverse language families challenges The CALC Project
obstacles". (Antoine Meillet 1925) insights → language change → human prehistory → triggers of diversity of life and culture → classical methods reach their limit → computational methods cannot replace experts' experience and intuition obstacles increasing amounts of data historical language comparison large and diverse language families challenges The CALC Project
obstacles". (Antoine Meillet 1925) insights → language change → human prehistory → triggers of diversity of life and culture → classical methods reach their limit → computational methods cannot replace experts' experience and intuition obstacles increasing amounts of data historical language comparison large and diverse language families challenges The CALC Project
very long title P(A|B)=P(B|A)... Funding: ERC Starting Grant (2017-2022) Host Institution: MPI-SHH (Jena) Team: 2 Post-Docs, 4 Docs (2 financed by project, 2 financed externally), PI Goal: establish a framework for CALC and show how to apply it to the Sino-Tibetan language family. https://digling.org/calc/
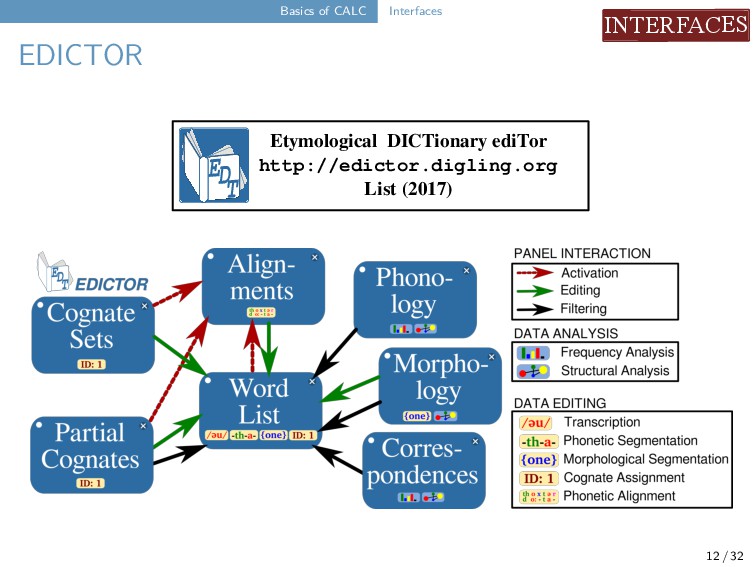
DOCULECT CONCEPT SEGMENTS N U O ? wOld yuE_5_1liaN_1 moon moon moon moon Běijīng Guǎngzhōu Měixiàn Fúzhōu 1 2 3 4 Conversion and Segmentation Highlighting of Unrecognized Phonetic Symbols yuE_5_1liaN_1 yɛ⁵¹liɑŋ¹ y ɛ ⁵¹ l i ɑ ŋ ¹ annotate data analyze data edit alignments Etymological DICTionary ediTor http://edictor.digling.org List (2017) E D T
centuries, scholars have been producing a large amount of concept lists. A concept list is in its simples form a list of concepts (e.g., I, you, he/she, dog, cat) which scholars find interesting for some linguistic, anthropological, or cognitive study. Starting with the work by Morris Swadesh, who proposed basic vocabulary as a concept important for historical linguistics, the compilation of concept lists has increased even more. For a very long time, scholars would just ignore the abundance of different concept lists produced in different fields and never try to systematically compare them. 15 / 32
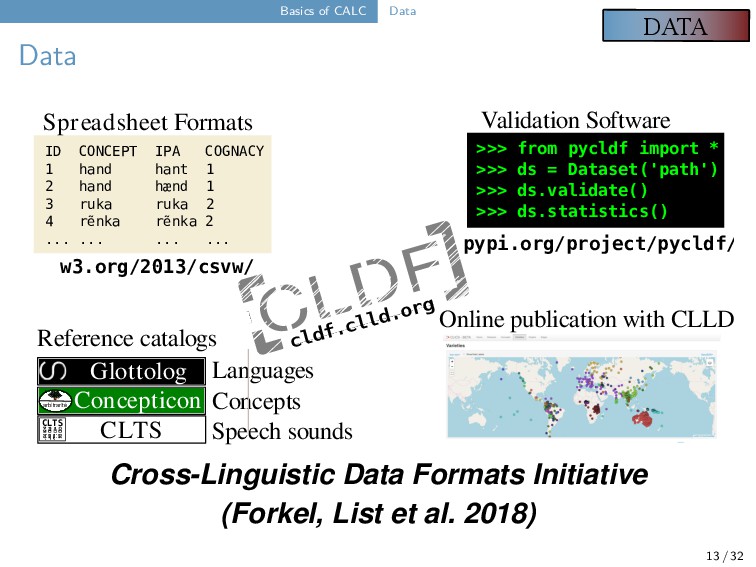
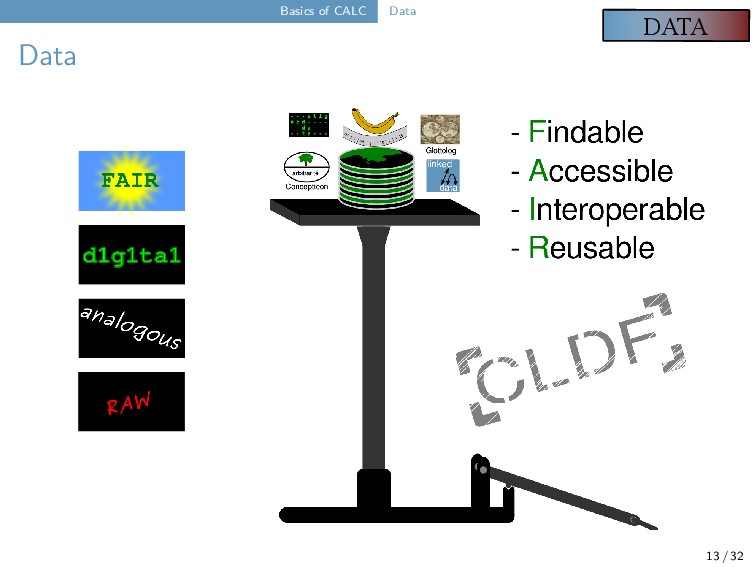
we published the first version of the Concepticon project (List et al. 2016, https://concepticon.clld.org), the first attempt to link the numerous concept lists which have been compiled so far. We link concept lists by defining Concept Sets, that is, abstract concepts which are given a unique ID and a gloss (to ease elicitation) along with a definition and (potentially) additional metadata. All items of a given concept list are linked to the Concepticon Concept Sets where possible. By now, Concepticon has 3755 Concept Sets and links to 310 different concept lists. 16 / 32
regularly maintained and updated the Concepticon since 2016. By now, we have a team of about 8-10 regular contributors. All concept lists that are added to the project are rigorously checked in a code-based review procedure along with computational checks for internal consistency. New lists can be automatically linked to the Concepticon and later manually refined (this works in up to 10 different languages). Concepticon is the basic reference catalog for concepts and elicitation glosses as underlying the Cross-Linguistic Data Formats initiative (Forkel et al. 2018, https://cldf.clld.org). 17 / 32
by scholars who want to establish their own questionnaires or surveys for lexical data of the languages of the world. Concepticon is the core component that allowed for the relaunch of the CLICS database (see Semantic Networks, next example). The data is growing at a steady paste and the procedures for error-checking and evaluation are constantly being refined. Our code-based data curation approach has shown to be very efficient for projects with a long-term goal. Individual issues of defining concepts in the way in which we do this in Concepticon have been disseminated in form of discussions in Blog posts (e.g., List 2018). 18 / 32
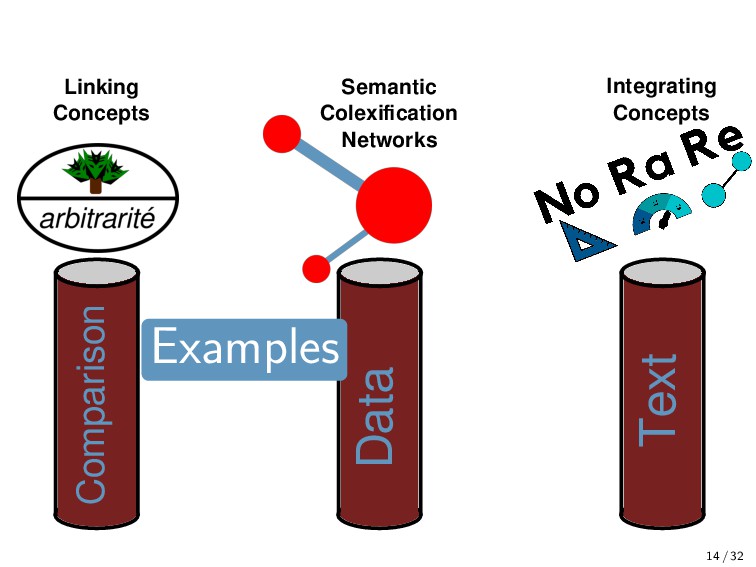
to bring another larger extension of the Concepticon project by even more concept lists. We work on an integration of Concepticon with the NoRaRe database (last example in this talk). We pursue initial experiments that enhance our automated mapping algorithm (also considering the use of machine learning technologies), which is needed to provide access to Concepticon data for those projects that work with a lot of data (e.g., NLP projects). 19 / 32
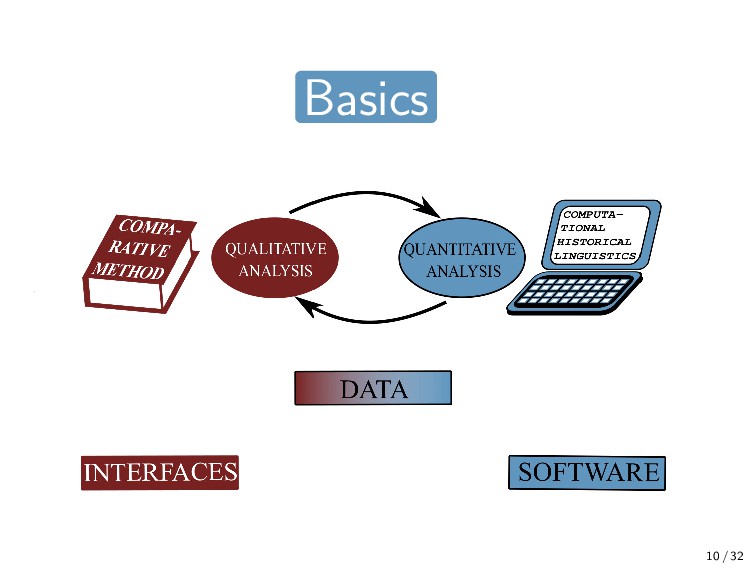
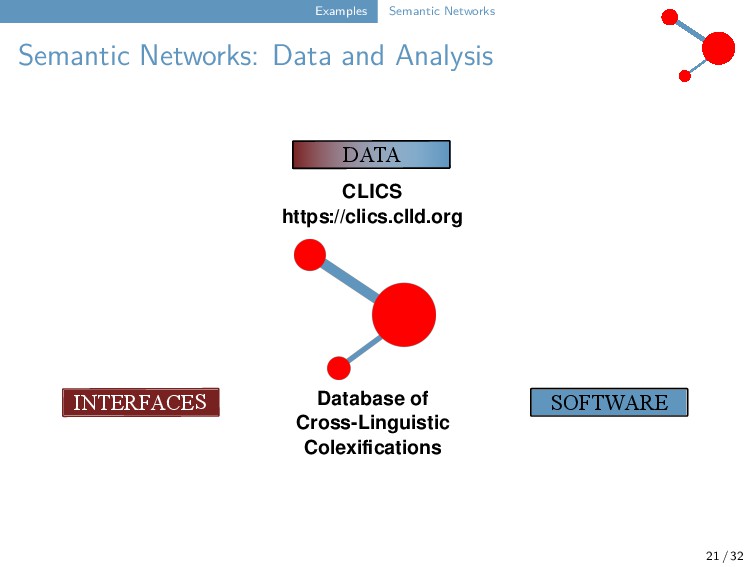
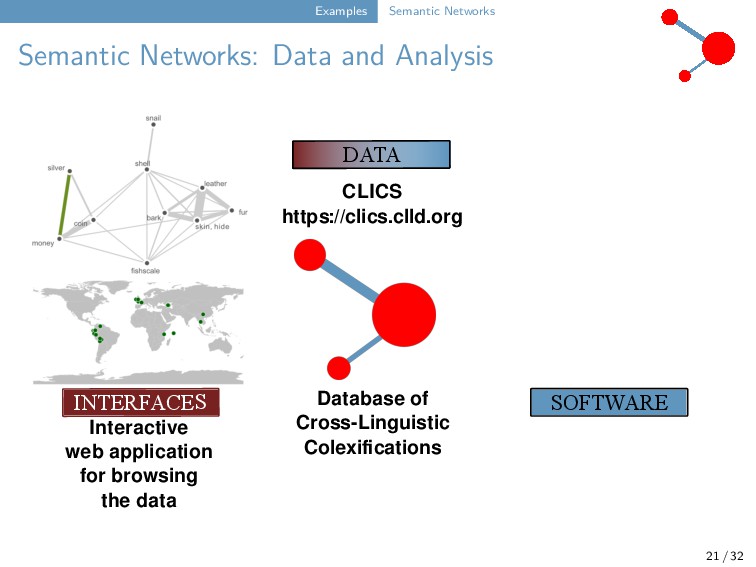
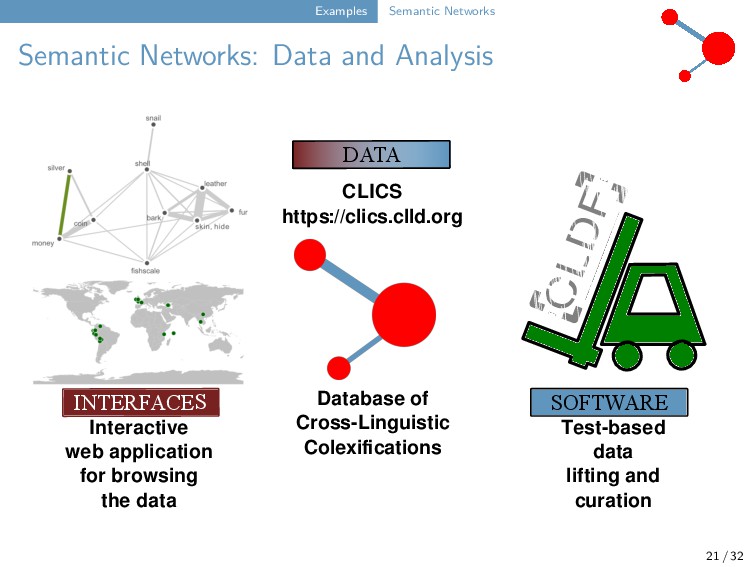
32 INTERFACES SOFTWARE DATA Database of Cross-Linguistic Colexifications CLICS https://clics.clld.org Interactive web application for browsing the data Test-based data lifting and curation CLDF
J.-M., A. Terhalle, and M. Urban (2013): Using network approaches to enhance the analysis of cross-linguistic polysemies. In: Proceedings of the 10th International Conference on Computational Semantics -- Short Papers. Association for Computational Linguistics 347-353.
T., J.-M. List, A. Terhalle, and M. Urban (2014): An interactive visualization of cross-linguistic colexification patterns. In: Visualization as added value in the development, use and evaluation of Linguistic Resources. Workshop organized as part of the International Conference on Language Resources and Evaluation. 1-8.
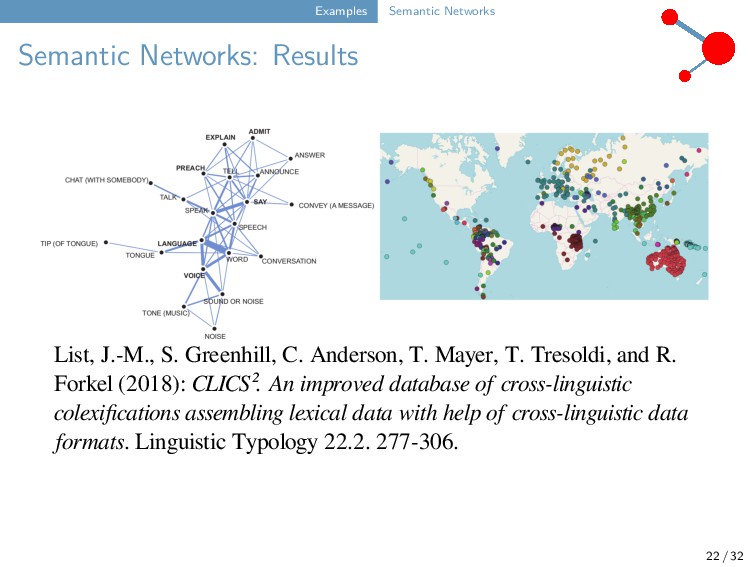
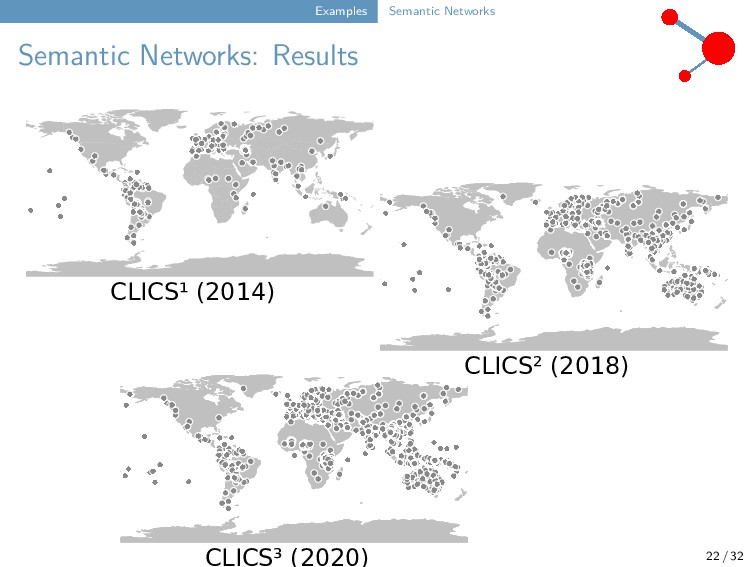
J.-M., S. Greenhill, C. Anderson, T. Mayer, T. Tresoldi, and R. Forkel (2018): CLICS². An improved database of cross-linguistic colexifications assembling lexical data with help of cross-linguistic data formats. Linguistic Typology 22.2. 277-306.
C., T. Tresoldi, S. Greenhill, M. Wu, N. Schweikhard, M. Koptjevskaja-Tamm, V. Gast, T. Bodt, A. Hantgan, G. Kaiping, S. Chang, Y. Lai, N. Morozova, H. Arjava, N. Hübler, E. Koile, S. Pepper, M. Proos, B. Epps, I. Blanco, C. Hundt, S. Monakhov, K. Pianykh, S. Ramesh, R. Gray, R. Forkel, and J.-M. List (2020): The Database of Cross-Linguistic Colexifications, reproducible analysis of cross- linguistic polysemies. Scientific Data 7.13. 1-12.
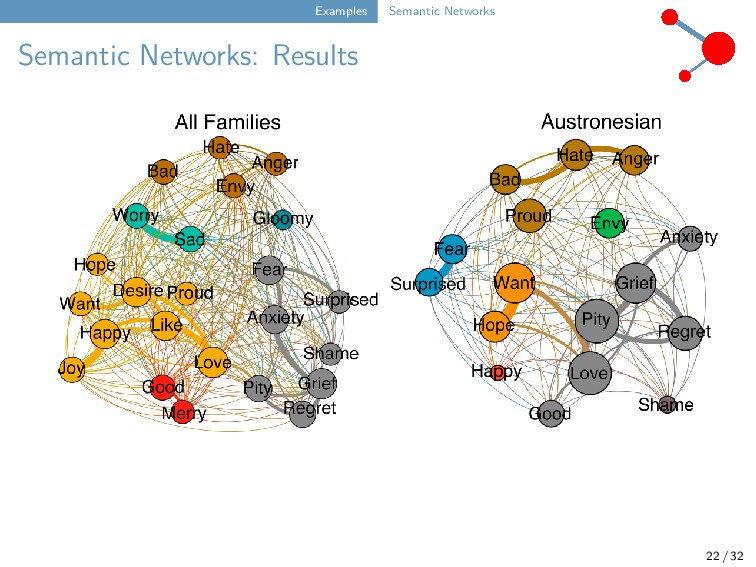
J., J. Watts, T. Henry, J.-M. List, P. Mucha, R. Forkel, S. Greenhill, and K. Lindquist (2019): Emotion semantics show both cultural variation and universal structure. Science 366.6472. 1517-1522.
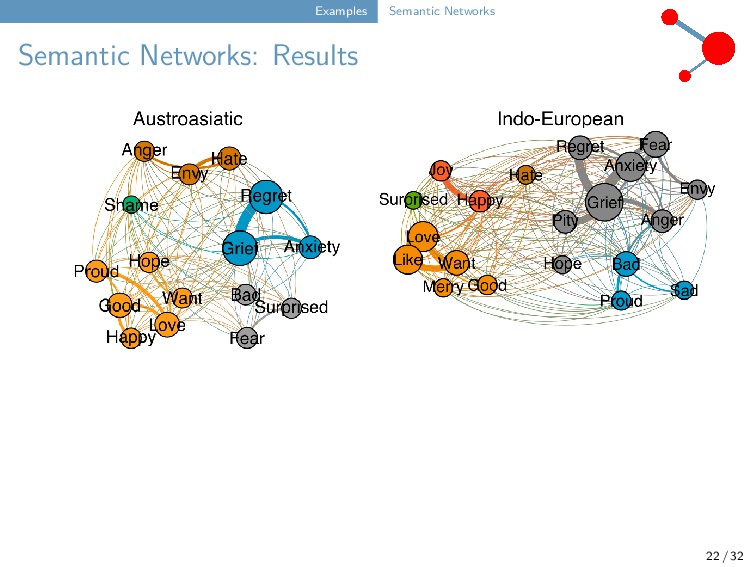
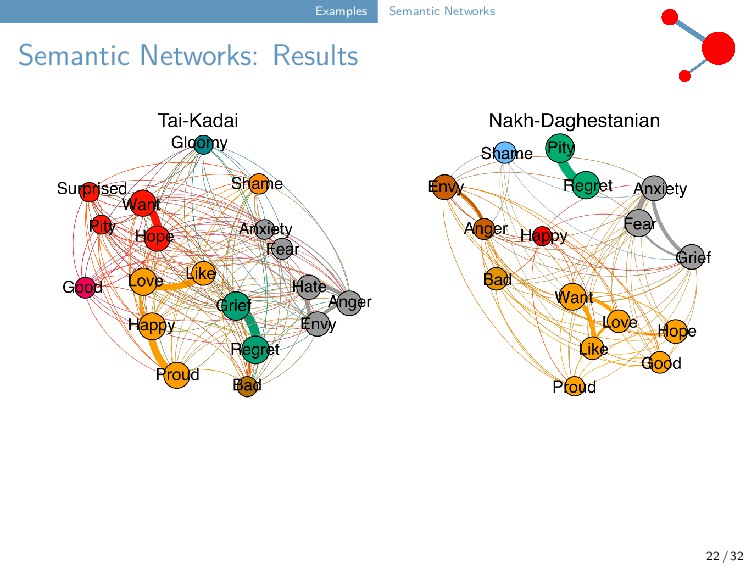
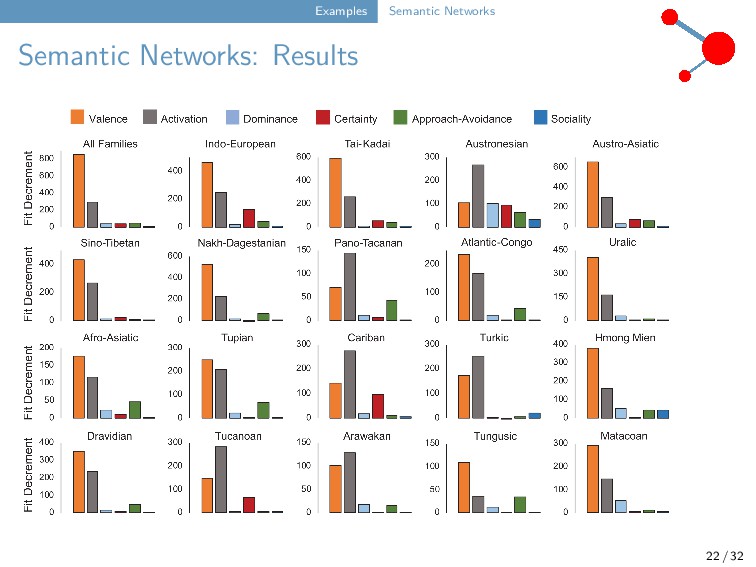
include partial colexifications and directed networks. Creating partial colexification data for testing and training. Conducting targeted colexification studies. 23 / 32
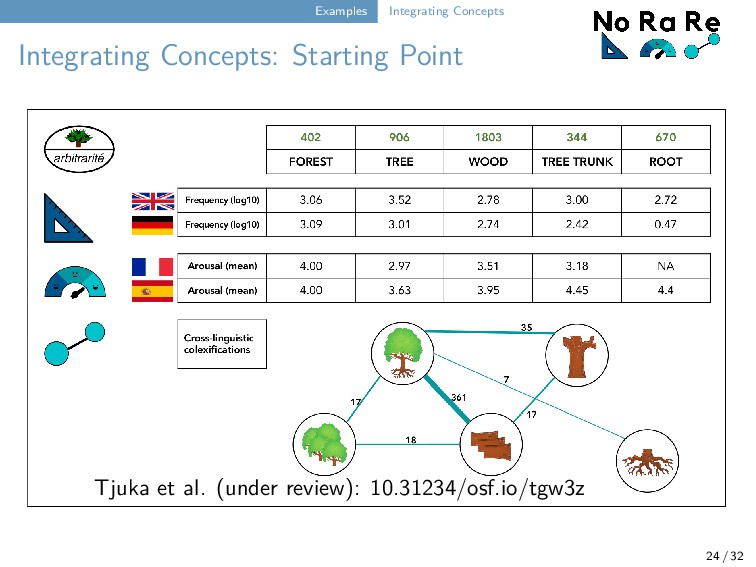
wealth of data about concepts produced by historical linguists, corpus linguistics, computational linguistics, and psycholinguists. These data are rarely properly integrated. But if they were integrated with resources like the Concepticon, this would be fantastic, since it would offer us a large amount of new possibilities for our research. 24 / 32
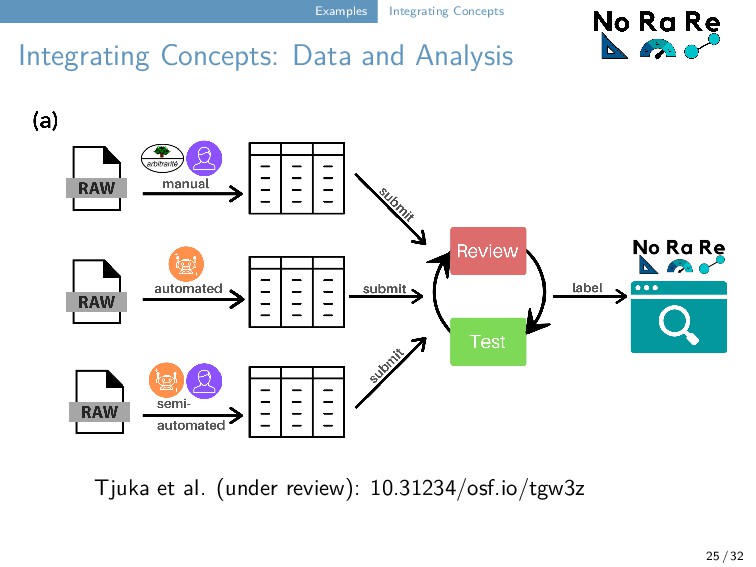
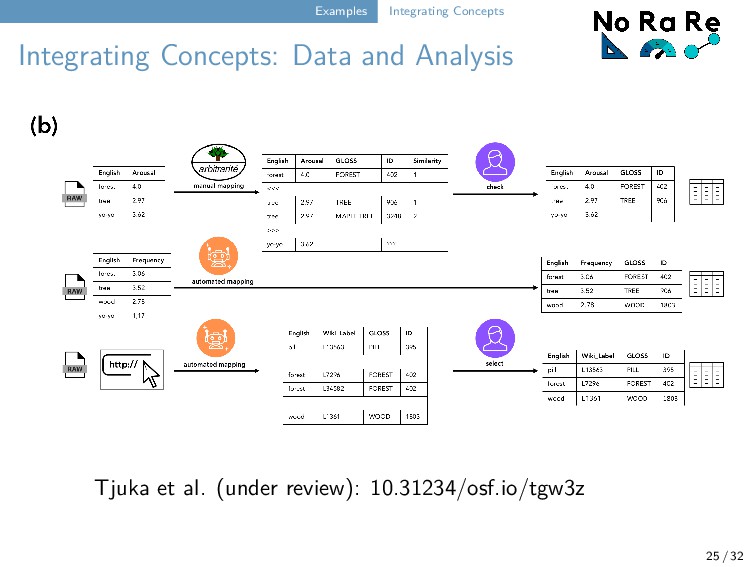
our workflow for test-driven data curation to publicly available datasets which provide norms, ratings, or relations for concepts and words. We distinguish manually, semi-automatically, and automatically mapped resources (based on structure and size). We normalize the original data by tagging the columns and making them comparable across the different source datasets. 25 / 32
released (Tjuka, Forkel, and List, under review, https://digling.org/norare/). 71 datasets from which 415 word and concept properties could be derived. Data curation workflow could be successfully evaluated (building also on our experience with Concepticon). Data applicability is largely enhanced thanks to the pynorare software API that allows for a quick comparison, but the data can also be easily analyzed with the help of R. 26 / 32
of the NoRaRe database) started to carry out different tests of the norms, ratings, and relations in NoRaRe and will pursue doing this. Expanding the database by adding specifically corpus data (e.g., for parallel bible corpus studies) and data from NLP studies (word embeddings). Enhancing the concept mapping algorithms (experiments with Christoph Rzymski). Integrating NoRaRe with the Concepticon web presentation (with Robert Forkel). 27 / 32
our lexibank initiative to lift and retro-standardize lexical data for the purpose of cross-linguistic comparison (see, among others, Forkel and List 2020: CLDFBench). Discussing further integration with psychological approaches by pushing language analysis (Jackson et al. under review). Enhanced approaches to the annotation of colexifications in lexical datasets (with Roberto Zariquiey, based on work presented in Schweikhard and List 2020). 29 / 32
semantics of body parts from the perspective of linguistic diversity (work with Annika Tjuka and Damián Blasi). Semantics underlying terms for body and mind (work led by MacCormack and Jackson in collaboration with Watts, and Henry). Creating enhanced, manually annotated datasets for the study of partial colexifications (work with Nathanael Schweikhard). 30 / 32
can design an approach to detect partial colexifications in a cross-linguistic collection of lexical datasets. Unlike Urban’s claim, these networks reflect both metonymic and metaphorical relations among concepts across multiple languages. Pilot studies show promising results with respect to network structures. 31 / 32
our group and shared ideas, code, and data with us in the past: Cormac Anderson, Timotheus Bodt, Doug Cooper, Simon J. Greenhill, Russell D. Gray, Robert Forkel, Yunfan Lai, Nathan W. Hill, Jessica K. Ivani, Yunfan Lai, Christoph Rzymski, Nathanael E. Schweikhard, Tiago Tresoldi, and Mei-Shin Wu. Many thanks to the European Research Council for supporting the project "Computer-Assisted Language Comparison" as part of the H2020 Funding Schema in the form of an ERC Starting Grant (2017-2022). Thank You for Listening LC CA COMPUTA- TIONAL HISTORICAL LINGUISTICS COMPA- RATIVE METHOD
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}