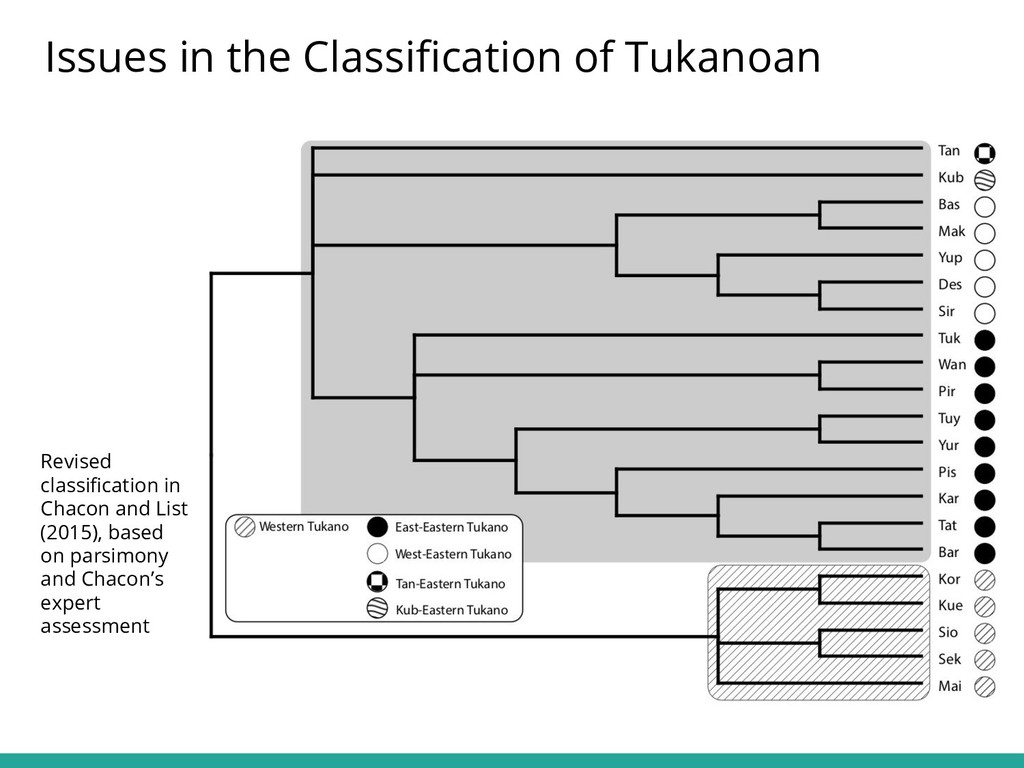
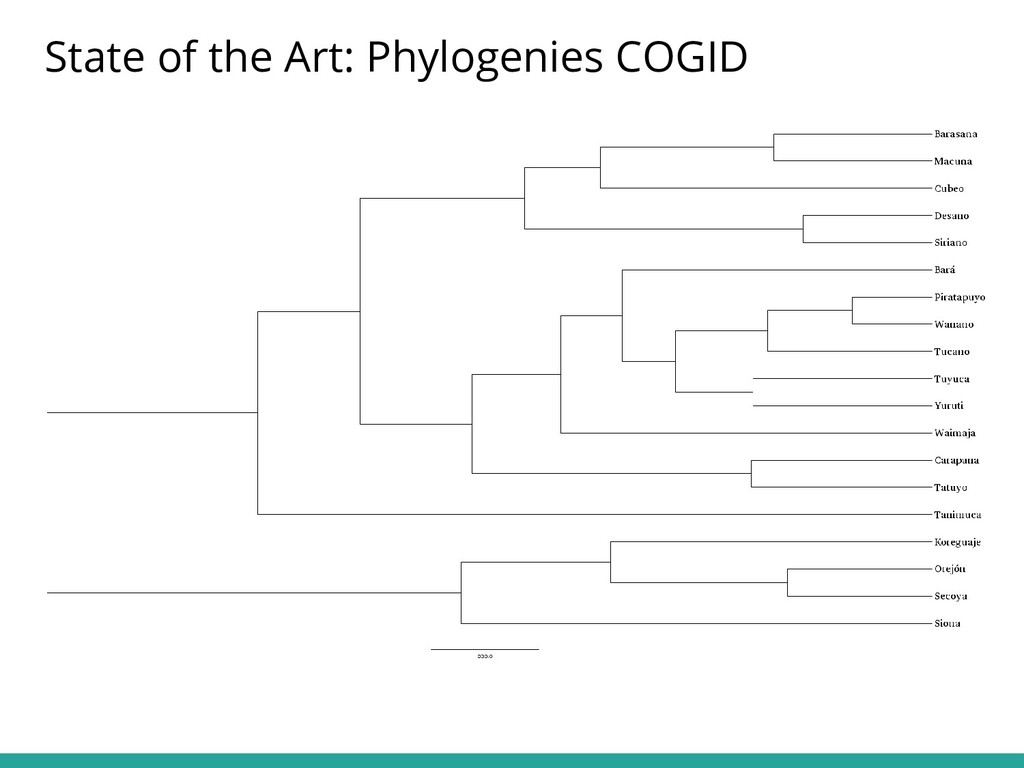
Talk (by Thiago Costa Chacon, Tiago Tresoldi, and Johann-Mattis List), held as part of the Workshop "Computer-assisted approaches to historical and typological language comparison", organized as part of the Annual Meeting of the Societas Linguistica Europea (2019-08-21/24, Leipzig, University of Leipzig).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
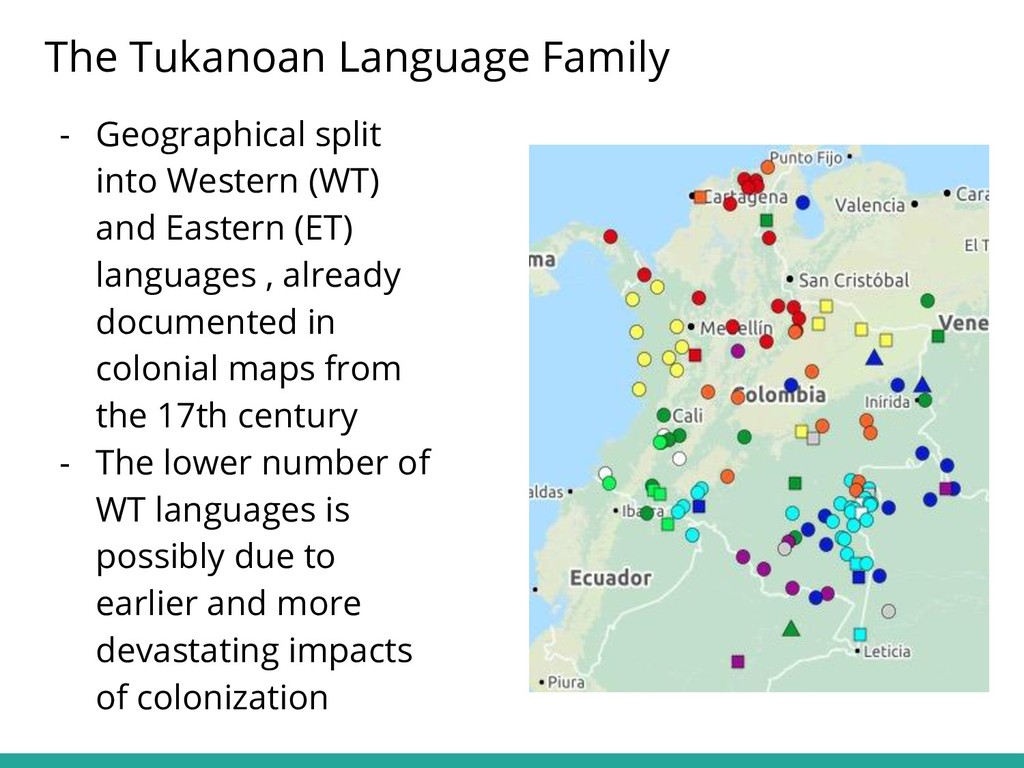{kind=link}
{kind=link}
{kind=link}
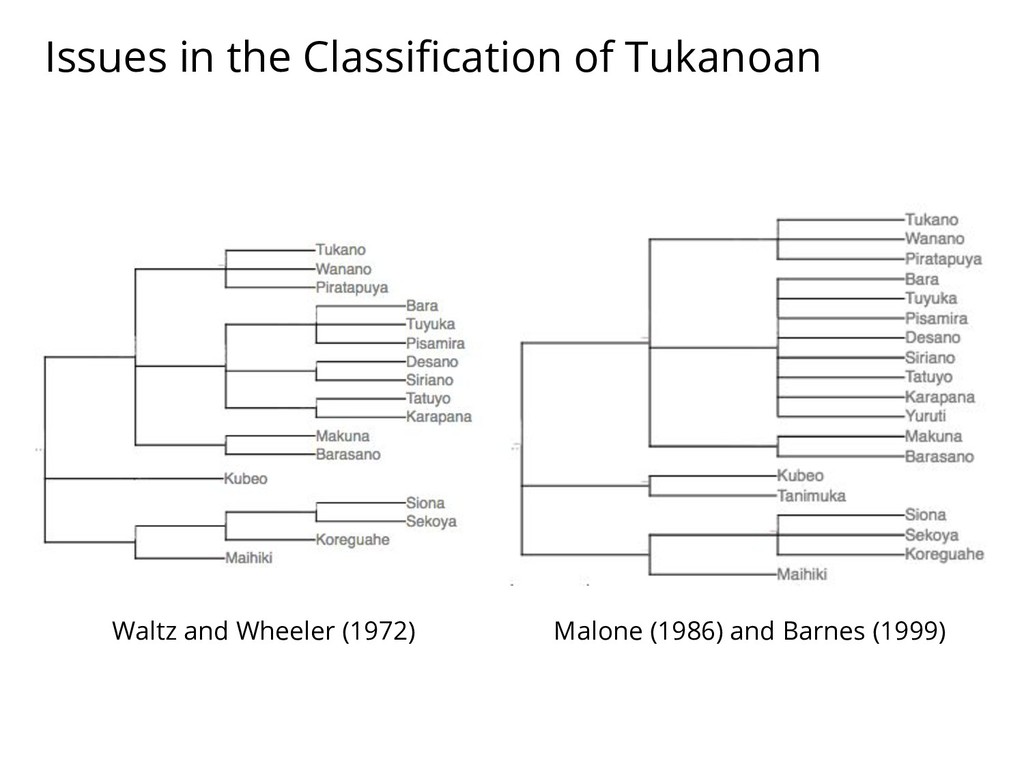{kind=link}
{kind=link}
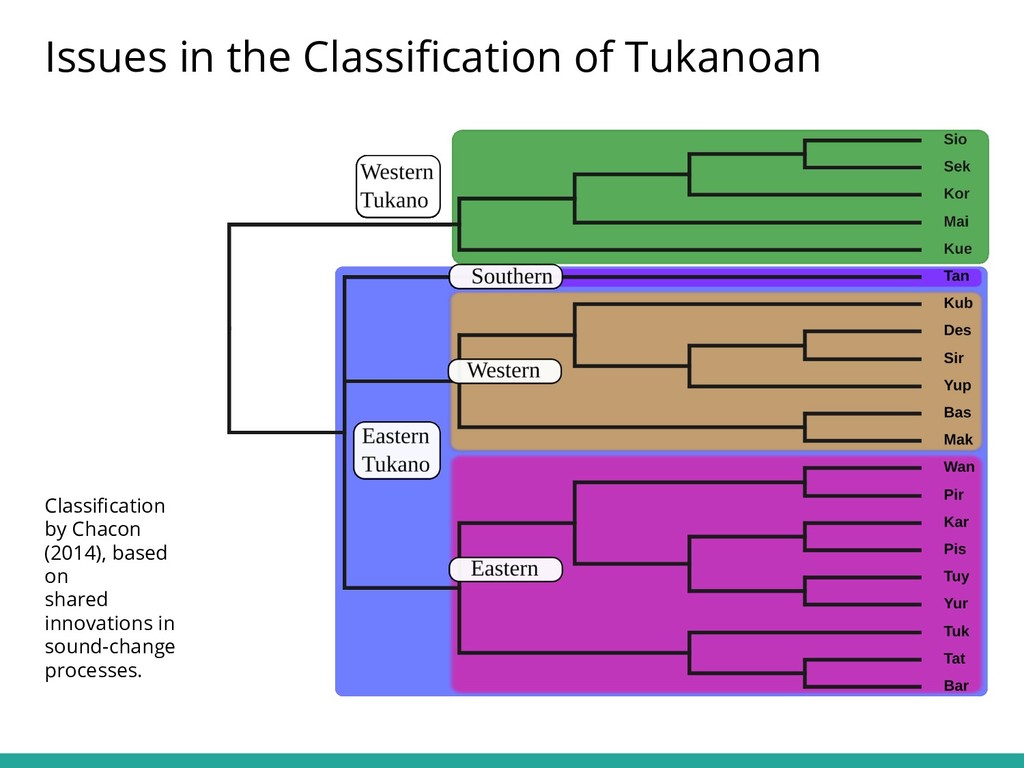{kind=link}
{kind=link}
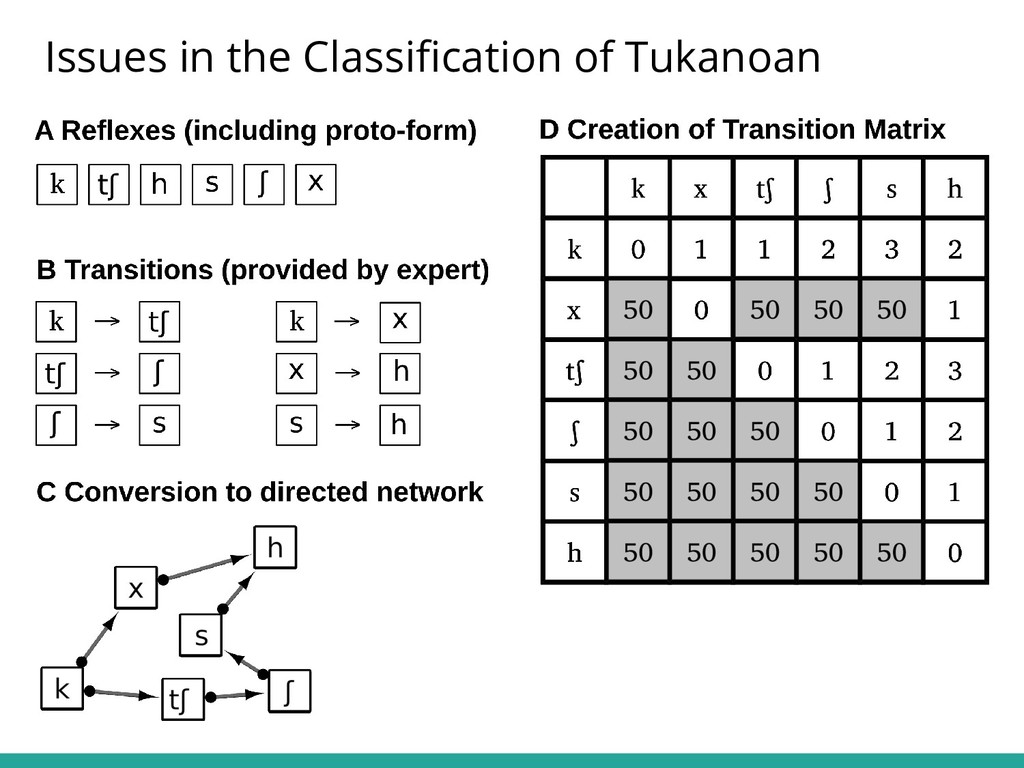{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}