Talk held at the meeting "Untangling the linguistic past of the Americas: Collaborative efforts and interdisciplinary approaches in an open science framework" (2020-09-23/25, Lima [virtual conference], PUCP).
historical linguistics and linguistic typology present results based on data which are not shared. - Data sharing becomes increasingly important and has been reinforced by some journals (Linguistic Typology, Linguistics, LDNC). - Reviewers ask increasingly for data and code already during review stage and make replicability checks a part of the review procedure.
historical linguistics and linguistic typology present results based on data which are not shared. - Data sharing becomes increasingly important and has been reinforced by some journals (Linguistic Typology, Linguistics, LDNC). - Reviewers ask increasingly for data and code already during review stage and make replicability checks a part of the review procedure.
historical linguistics and linguistic typology present results based on data which are not shared. - Data sharing becomes increasingly important and has been reinforced by some journals (Linguistic Typology, Linguistics, LDNC). - Reviewers ask increasingly for data and code already during review stage and make replicability checks a part of the review procedure.
historical linguistics and linguistic typology present results based on data which are not shared. - Data sharing becomes increasingly important and has been reinforced by some journals (Linguistic Typology, Linguistics, LDNC). - Reviewers ask increasingly for data and code already during review stage and make replicability checks a part of the review procedure.
Sharing data does not mean that the data can be easily processed and reused. - But data processing and data reuse (interoperability and reusability) are essential to - find errors in existing datasets, - enhance existing datasets, and - create new datasets from existing ones. - The discussion should not be about sharing data alone, but about integrating data.
Sharing data does not mean that the data can be easily processed and reused. - But data processing and data reuse (interoperability and reusability) are essential to - find errors in existing datasets, - enhance existing datasets, and - create new datasets from existing ones. - The discussion should not be about sharing data alone, but about integrating data.
Sharing data does not mean that the data can be easily processed and reused. - But data processing and data reuse (interoperability and reusability) are essential to - find errors in existing datasets, - enhance existing datasets, and - create new datasets from existing ones. - The discussion should not be about sharing data alone, but about integrating data.
Sharing data does not mean that the data can be easily processed and reused. - But data processing and data reuse (interoperability and reusability) are essential to - find errors in existing datasets, - enhance existing datasets, and - create new datasets from existing ones. - The discussion should not be about sharing data alone, but about integrating data.
integrated, data needs to be - internally consistent, and - externally comparable. - Internal consistency requires that data are not only human- but also machine-readable. - External comparability requires that data are conforming to general standards. - The Cross-Linguistic Data Formats (CLDF) initiative (https://cldf.clld.org) has presented recommendations for the representation of integrated cross-linguistic data collections.
integrated, data needs to be - internally consistent, and - externally comparable. - Internal consistency requires that data are not only human- but also machine-readable. - External comparability requires that data are conforming to general standards. - The Cross-Linguistic Data Formats (CLDF) initiative (https://cldf.clld.org) has presented recommendations for the representation of integrated cross-linguistic data collections.
integrated, data needs to be - internally consistent, and - externally comparable. - Internal consistency requires that data are not only human- but also machine-readable. - External comparability requires that data are conforming to general standards. - The Cross-Linguistic Data Formats (CLDF) initiative (https://cldf.clld.org) has presented recommendations for the representation of integrated cross-linguistic data collections.
integrated, data needs to be - internally consistent, and - externally comparable. - Internal consistency requires that data are not only human- but also machine-readable. - External comparability requires that data are conforming to general standards. - The Cross-Linguistic Data Formats (CLDF) initiative (https://cldf.clld.org) has presented recommendations for the representation of integrated cross-linguistic data collections.
integrated, data needs to be - internally consistent, and - externally comparable. - Internal consistency requires that data are not only human- but also machine-readable. - External comparability requires that data are conforming to general standards. - The Cross-Linguistic Data Formats (CLDF) initiative (https://cldf.clld.org) has presented recommendations for the representation of integrated cross-linguistic data collections.
language varieties - Concepticon (https://concepticon.clld.org): reference catalog for concepts, linking elicitation glosses used in linguistic literature to Concepticon Concept Sets - Cross-Linguistic Transcription Systems (https://clts.clld.org): identifies more than 8000 possible speech sounds and links transcription systems and transcription dataset to them
and references - Concepticon: offering definitions, and now also extensive norms, ratins, and relations (https://digling.org/norare, frequency, similarity, hierarchies, etc.) - Cross-Linguistic Transcription Systems: offers feature sets for each speech sounds, and similarity metrics based on the features
and references - Concepticon: offering definitions, and now also extensive norms, ratins, and relations (https://digling.org/norare, frequency, similarity, hierarchies, etc.) - Cross-Linguistic Transcription Systems: offers feature sets for each speech sounds, and similarity metrics based on the features Linking your data to Glottolog, mapping your concepts to Concepticon, and converting your transcriptions to CLTS will drastically ENRICH them!
- Consistent, code-based, test-driven conversion of data to CLDF - integration with Orthography Profiles for conversion to CLTS - straightforward con- version of CLDF data- sets into a CLLDF database
appear, 2474 languages) CLICS¹ (List et al. 2014, 300 languages) CLICS² (List et al. 2018, 1200 languages) Increasing coverage in the CLICS database over the past four years.
with cross-linguistic data: - lexical data lifted for more than 2000 language varieties - automated methods for the creation of colexification networks - colexification networks can help to answer various question on human cognition
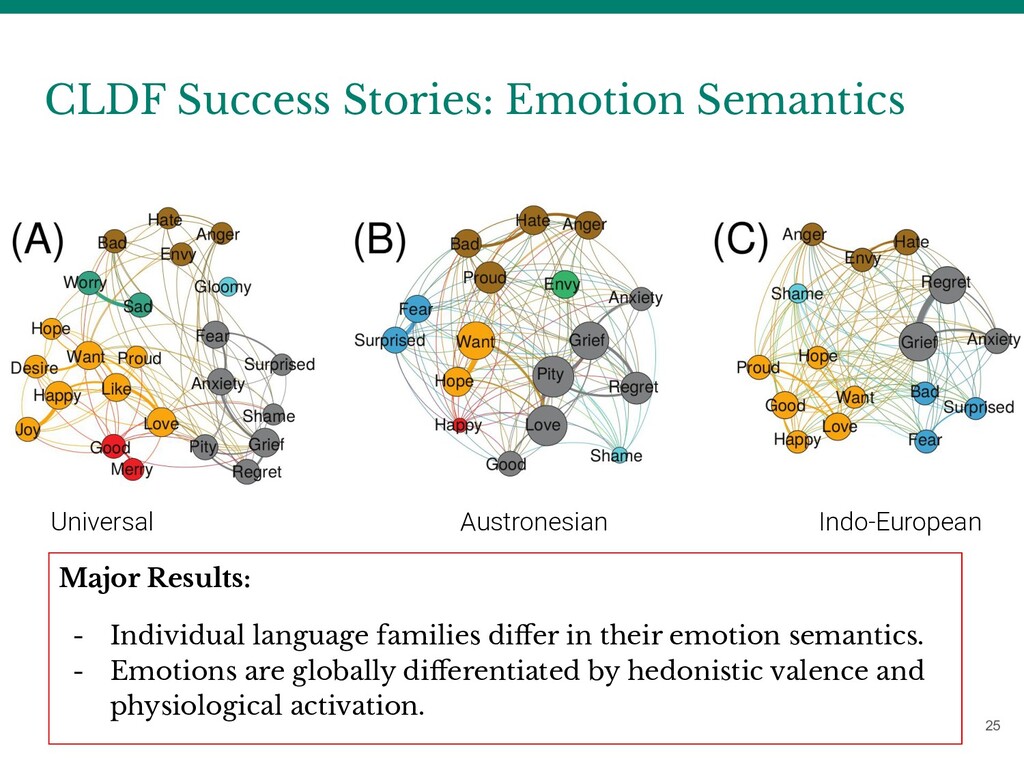
Results: - Individual language families differ in their emotion semantics. - Emotions are globally differentiated by hedonistic valence and physiological activation.
your lexical and structural data is largely facilitated. - Based on our experience with helping colleagues to convert their data to CLDF, we can say: converting your dataset to CLDF will help you to improve it! - If you convert your data accompanying publications to CLDF, you help not only yourself, but also others to build on your work. - Our CLDF team at the DLCE in of the MPI-SHH in Jena/Leipzig is always ready to help with questions.
your lexical and structural data is largely facilitated. - Based on our experience with helping colleagues to convert their data to CLDF, we can say: converting your dataset to CLDF will help you to improve it! - If you convert your data accompanying publications to CLDF, you help not only yourself, but also others to build on your work. - Our CLDF team at the DLCE in of the MPI-SHH in Jena/Leipzig is always ready to help with questions.
your lexical and structural data is largely facilitated. - Based on our experience with helping colleagues to convert their data to CLDF, we can say: converting your dataset to CLDF will help you to improve it! - If you convert your data accompanying publications to CLDF, you help not only yourself, but also others to build on your work. - Our CLDF team at the DLCE in of the MPI-SHH in Jena/Leipzig is always ready to help with questions.
your lexical and structural data is largely facilitated. - Based on our experience with helping colleagues to convert their data to CLDF, we can say: converting your dataset to CLDF will help you to improve it! - If you convert your data accompanying publications to CLDF, you help not only yourself, but also others to build on your work. - Our CLDF team at the DLCE in of the MPI-SHH in Jena/Leipzig is always ready to help with questions.
your lexical and structural data is largely facilitated. - Based on our experience with helping colleagues to convert their data to CLDF, we can say: converting your dataset to CLDF will help you to improve it! - If you convert your data accompanying publications to CLDF, you help not only yourself, but also others to build on your work. - Our CLDF team at the DLCE in of the MPI-SHH in Jena/Leipzig is always ready to help with questions.
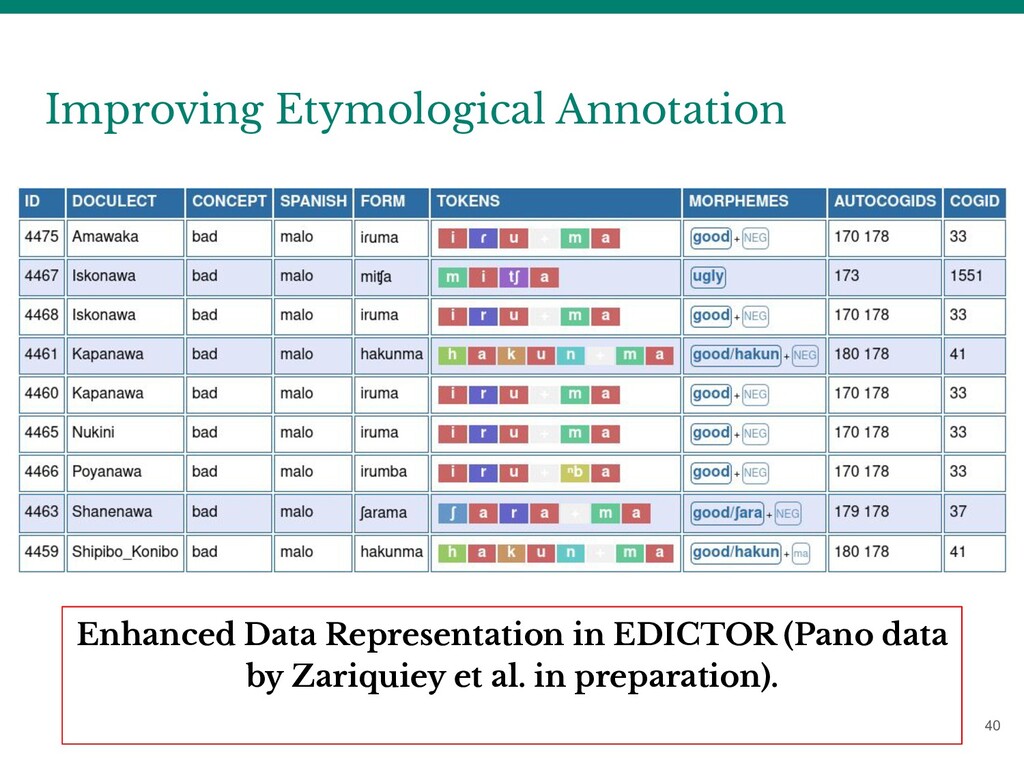
- binary in the light of partial cognates, - “horizontal” in the light of language-internal word families, - implying regular sound change and alignability in the light of non-concatenative derivation - flat, but rather hierarchical, depending on the purpose of the analysis.
frameworks for annotation of etymologies. - Develop interfaces which support the annotation. - Develop software for preprocessing, which can be used to automatically annotate data in a computer-assisted setting.
forms should be represented as lists of sound segments. - not [tʰantsʰən] but [tʰ a n t ͡ sʰ ə n] - Word forms should conform to CLTS: - not [tʰ a n t ͡ sʰ ə n] but [tʰ a n tsʰ ə n] - Word forms should be further segmented into morphemes. - not [tʰ a n tsʰ ə n] but [tʰ a n tsʰ + ə n]
meanings should be linked to Concepticon (if available). - “apple (noun)” -> 1320 APPLE - Individual meanings of morphemes per word should be glossed, distinguishing lexical (autosemantic) from grammatical (synsemantic) meanings. - [a pf ə l + b au m] -> APPLE TREE - [tʰ a n tsʰ + ə n] -> DANCE _infinitive
cognate words receive the same ID (independent of their meaning slot), called COGID in LingPy/EDICTOR. - Partial cognate words receive an ID for each of their morphemes. - Alignments should only be provided for partial cognates.
Bodt, Thiago Chacon, Ilya Chechuro, Doug Cooper, Robert Forkel, Volker Gast, Russell Gray, Simon J. Greenhill, Guido Grimm, Teague Henry, Nathan W. Hill, Joshua Jackson, Guillaume Jacques, Maria Koptjevskaja Tamm, Yunfan Lai, Kristen Lindquist, Kristina Pianykh, Justin Power, Robin Ryder, Christoph Rzymski, Laurent Sagart, Nathanael E. Schweikhard, Valentin Thouzeau, Annika Tjuka, Tiago Tresoldi, Mary E. Walworth, Joseph Watts, Mei-Shin Wu, Roberto Zariquiey, and many more...
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}