Computer-assisted approaches in historical and typological language comparison
Talk, held at the workshop "Computer-Assisted Approaches in Historical and Typological Language Comparison", organized as part of the Annual Meeting of the Societas Linguistica Europea (2019-08/21-24, Leipzig, University of Leipzig).
for a long time based on data collection and analysis, the classical approaches, pre-dating the era of computers, have been challenged recently, as reflected in the quantitative turn in diversity linguistics, which started around the second millennium. • The challenge has created a gap between the classical (or traditional) and the computational (quantitative) approaches, since classical linguists are often skeptical of the new approaches, while the defenders of the new approaches complain about a lack of acceptance among classical linguists.
of the world’s largest language families - initial classification of the world’s languages into 300-400 language families - accumulation of comparative data for many of the world’s languages linguistic typology - insights into language universals and cross-linguistic tendencies - large surveys on grammatical categories in prose - accumulation of structural data for many of the world’s languages
history of the world’s largest language families - initial classification of the world’s languages into 300-400 language families - accumulation of comparative data for many of the world’s languages computational typology - imputation of features in structural data - accumulation of structural data for many of the world’s languages
large amount of data that has been assembled so far. - Accuracy: Computational approaches cannot compete with the fine-grained analyses that trained experts can deliver in historical and typological language comparison. - Consistency: Classical approaches are hard to learn, hard to apply, and scholars may drastically differ in their respective interpretation of the classical canon of methods. - Flexibility: Computational approaches have serious problems to deal with new problems that have not been addressed by means of computational methods before.
can easily cope with large amounts of data. - Accuracy: Classical approaches are not error-free but they show a high accuracy, as also witnessed by the success story of the historical language comparison. - Consistency: Computational approaches are straightforward in their application, clear-cut with respect to the tasks they fulfill, and minimally biased with respect to the data they are applied to. - Flexibility: Classical approaches can take all different kinds of evidence into account, thus reflecting the old idea of consilience in the historical sciences, where one searches different kinds of evidence to receive a unique picture.
Papers from 2018 until now - Reflex prediction (with T. A. Bodt, Western Kho-Bwa, Bodt and List 2019) - Borrowing detection (with A. Hantgan, Dogon, Bangime, Hantgan and List forthcoming) - Annotation of rhyme judgments (with N. W. Hill and C. Forster, List et al. 2019) - Fast cognate detection algorithms (with T. Rama, Rama and List 2019) - Sino-Tibetan subgrouping (with L. Sagart, G. Jacques, R. Ryder, V. Thouzeau, S. Greenhill, and Y. Lai, Sagart et al. 2019) - Inference of sound correspondence patterns (List 2019) - Cross-linguistic transcription systems (with C. Anderson, R. Forkel, T. Tresoldi, Anderson et al. 2019) - Cross-linguistic data formats (with R. Forkel, C. Rzymski, S. Greenhill, Forkel et al. 2019) - CLICS² (with S. Greenhill, T. Tresoldi, R. Forkel, List et al. 2018)
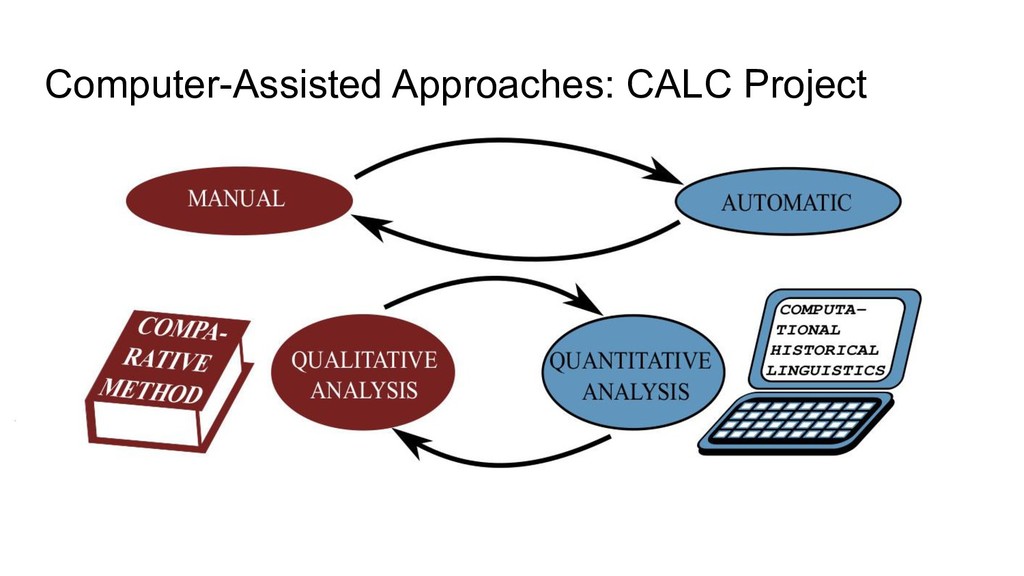
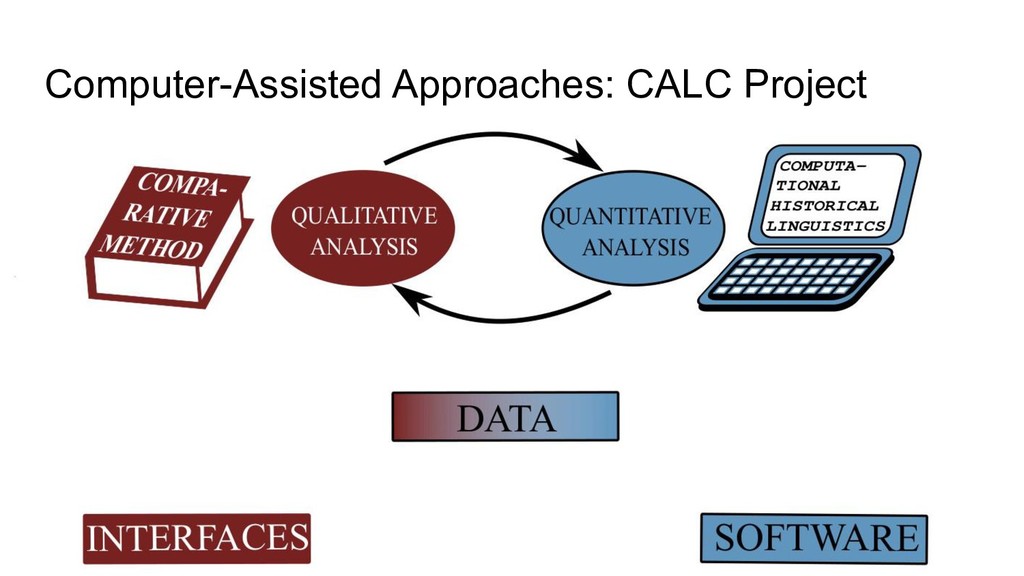
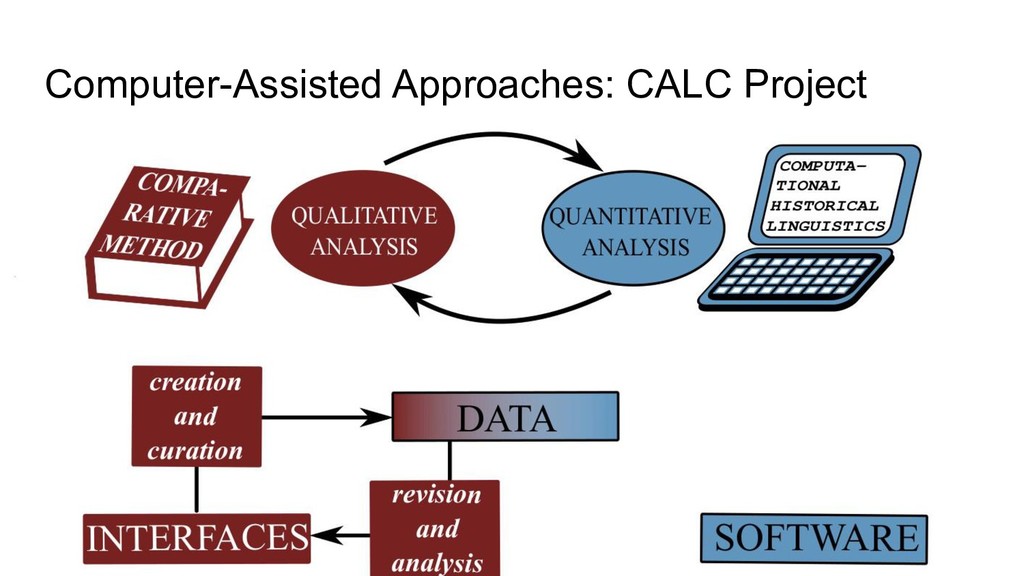
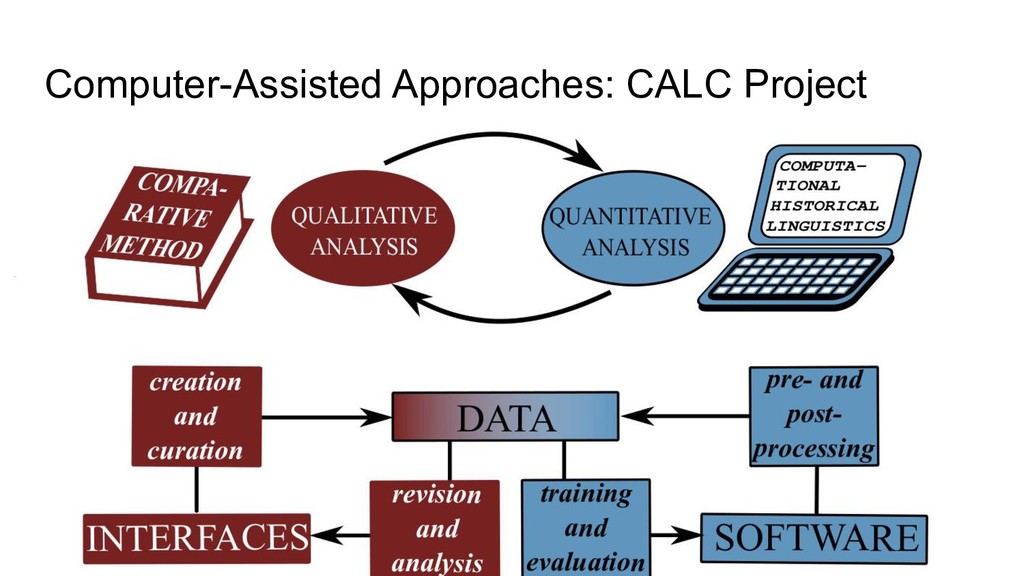
Databases and Standards - Cross-linguistic data formats (with R. Forkel, C. Rzymski, S. Greenhill, et al., https://cldf.clld.org, since 2018) - Cross-linguistic transcription systems (with C. Anderson, R. Forkel, T. Tresoldi, et al., https://clts.clld.org, since 2018) - Database of Cross-Linguistic Colexifications (with R. Forkel, T. Tresoldi, C. Rzymski, et al., https://clics.clld.org, since 2014) - Concepticon (with N. Schweikhard, R. Forkel, S. Greenhill, T. Tresoldi, et al., https://concepticon.clld.org, since 2016) - EvoBib: Bibliographic database and quote collection (http://calc.digling.org/evobib, since 2014)
Software and Interfaces - LingPy: Python library for quantitative tasks in historical linguistics (with R. Forkel, et al., http://lingpy.org, since 2014) - PoePy: Python library for handling annotated rhymes (https://github.com/lingpy/poepy/, since 2019) - SinoPy: Python library for quantitative tasks in Chinese historical linguistics (https://github.com/lingpy/sinopy/ since 2018) - LingRex: Linguistic reconstruction with LingPy (https://github.com/lingpy/lingrex/, since 2018) - EDICTOR: Web-based tool for the curation of etymological data (http://edictor.digling.org, since 2017)
project: - Subgrouping of sign languages (with J. Power and G. Grimm, Power et al. under review) - Large-scale inference of borrowings - Workflows for computer-assisted language comparison (with M.-S. Wu) - Subgrouping of Tukano (with T. Tresoldi and T. Chacon) - Subgrouping of Pano (with R. Zariquiey et al.) - Standards for inter-linear-glossed texts (with N. Sims) - Reconstruction of Proto-Burmish (with N. W. Hill) - Open problems in computational diversity linguistics (series of blogposts, addressing 10 problems to be discussed throughout 2019) - Morpheme-segmented database (with N. Schweikhard and potentially also A. Tjuka)
Modeling is the first step of all scientific endeavor, since we cannot understand no matter what phenomenon without models. • Inference helps us to use the models to accumulate more data. • Analysis is the step in which we use the inferences to test the original models.
(based on ideas presented by M. Haspelmath) • Particular language comparison does not claim to solve anything about all languages of the world, or the language faculty in an abstract sense, but addresses instead a particular language or language family, its history, or its typological characteristics. • General language comparison should aim at addressing cross-linguistic trends, patterns, but also methods that can be applied to all human languages, regardless of where they come from.
to today many open problems in the field of computational and computer-assisted diversity linguistics. In order to solve them, it is useful to actually write them down once in a while, trying to formalize them. In this way, one can get a better understanding of the problem, also share it with colleagues, and determine, why the problem actually counts as difficult.
Data and Code Sharing With great data comes great responsibility! Unfortunately, it is still the exception rather than the rule when scholars share data and code in a FAIR (Wilkinson et al. 2016) form: findable, accessible, interoperable, and reproducible. At times, scholars even do not share their data at all. It should be obvious that this does not reflect good scientific practice, specifically since most scholars profit from the generosity of their colleagues who share their data. Ideally, diversity linguists would sit together in the future and establish guidelines and recommendations for author, reviewers, and publishers, to help those who work with data and code, to share them correctly.
standards, and annotation play an increasingly important role for data curation. The most successful and largest projects which have been launched during the last decades (Reflex, STEDT, Tower of Babel, WOLD, WALS, GLD) all make use of specifically designed interfaces that help scholars to curate and analyze their data. For the future, we should think of ways to unify the exchange of data between these interfaces, and also try to work towards general and free interfaces that can be used platform-independently by all scholars, as well as community-wide standards of annotation, that guarantee that the data are still analyzable, even if one does not have access to certain interfaces.
replace them, they will replace everybody, and nobody will know it, from inside the matrix). • Computational approaches, combined with the power of expertise and intuition can make a huge difference in our field. • The degree to which historical linguistics and linguistic typology is already making active use of computational and computer-assisted approaches shows the importance of these fields in comparison to general linguistics, but also may qualify computer-assisted approaches to historical and typological language comparison as role models for data-driven research in the humanities.
T. Tresoldi, Y. Lai, N. E. Schweikhard, M.-S. Wu Associates (DLCE): R. Forkel, S. J. Greenhill, R. D. Gray, C. Rzymski, and many others Collaborators (external): A. Hantgan, J. Power, R. Zariquiey, N. W. Hill, L. Sagart, G. Jacques, T. Rama, G. Jäger, and many others
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}