a Machine-Readable Modeling of Phonetic Context Johann-Mattis List¹, Thiago Chacon² ¹Centre des recherches linguistiques sur l’Asie Orientale, Paris ²University of Brasilia, Brasilia 2015-09-04 1 / 20
data, no abstract patterns - comparability: unified human- and machine-readable format - flexibility: no restriction to only one theory or feature system Concrete Challenges - context: How to handle context of sound change patterns in a trans- parent, flexible, and comparable way? - language-specific aspects: How to allow for a modeling of family- or language-specific sound change conditions without sacrificing compara- bility? - quantifiability: How to quantify patterns inside and across languages? - computability: How to formalize the process of modeling in such a way that we can get as much help as possible from computational applicati- ons? 5 / 20
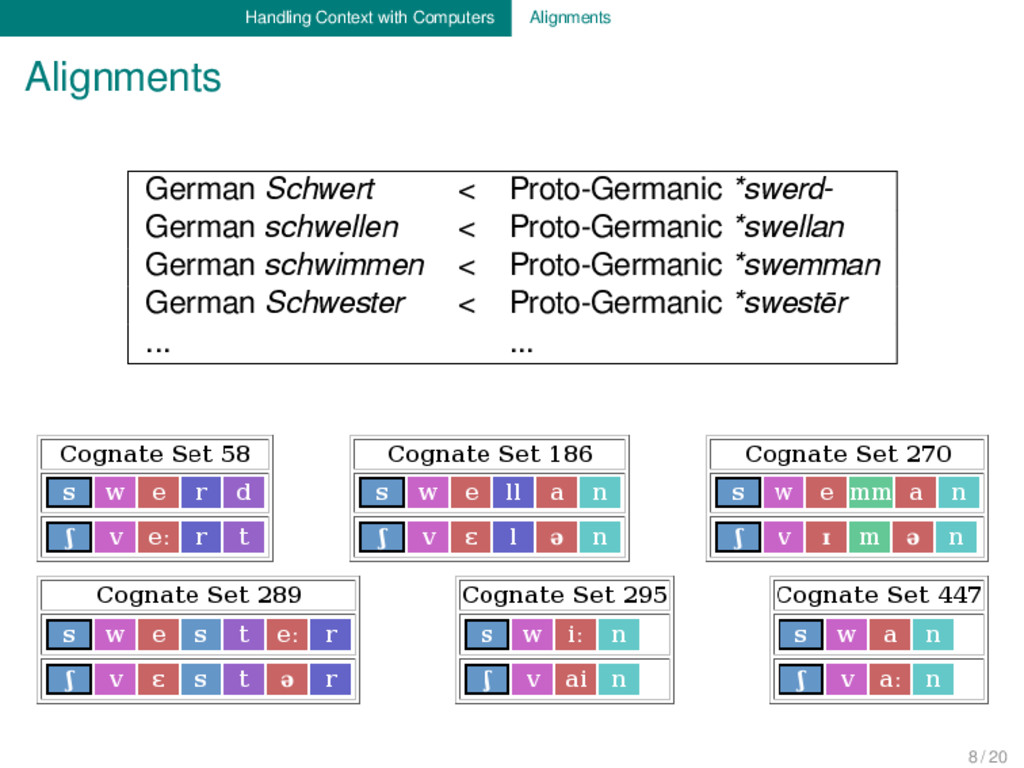
aligning cognate word forms of ancestral (source) and descendant (target) languages. Advantages: - comparability across languages and language families. - concrete, transparent statements regarding relatedness - easy to produce with new interactive software tools - no restrictions to data size Challenges: - handling of supra-segmental aspects of pronunciation - handling of unalignable patterns (morphology) - handling of non-linear patterns (metathesis, mergers) 7 / 20
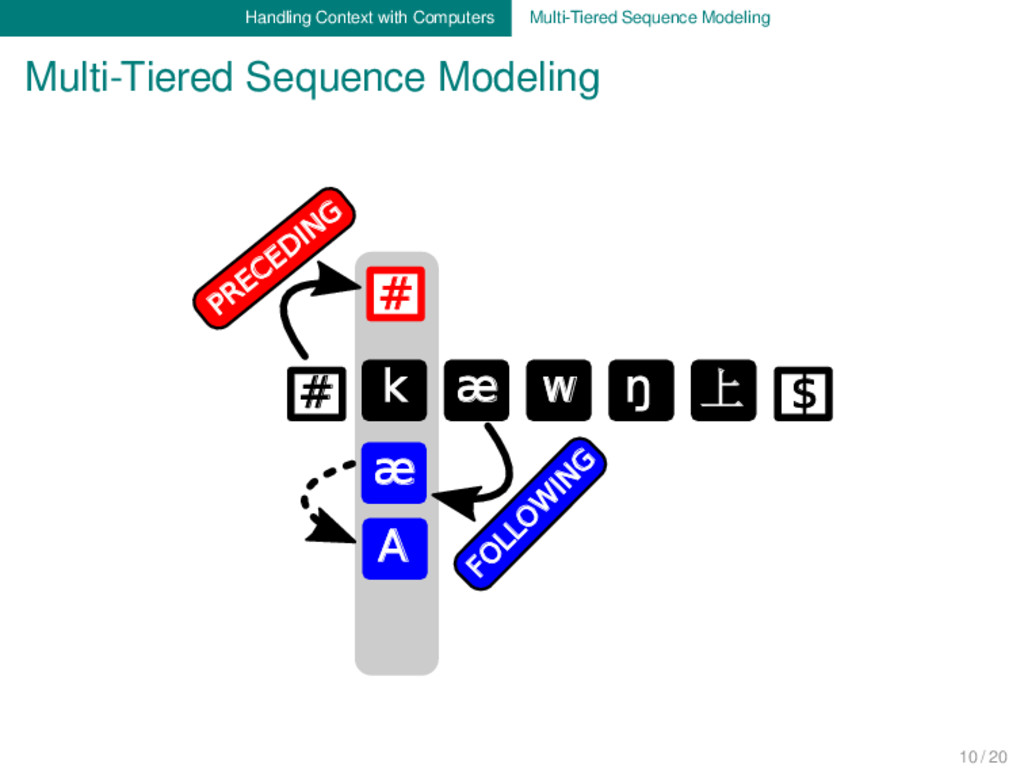
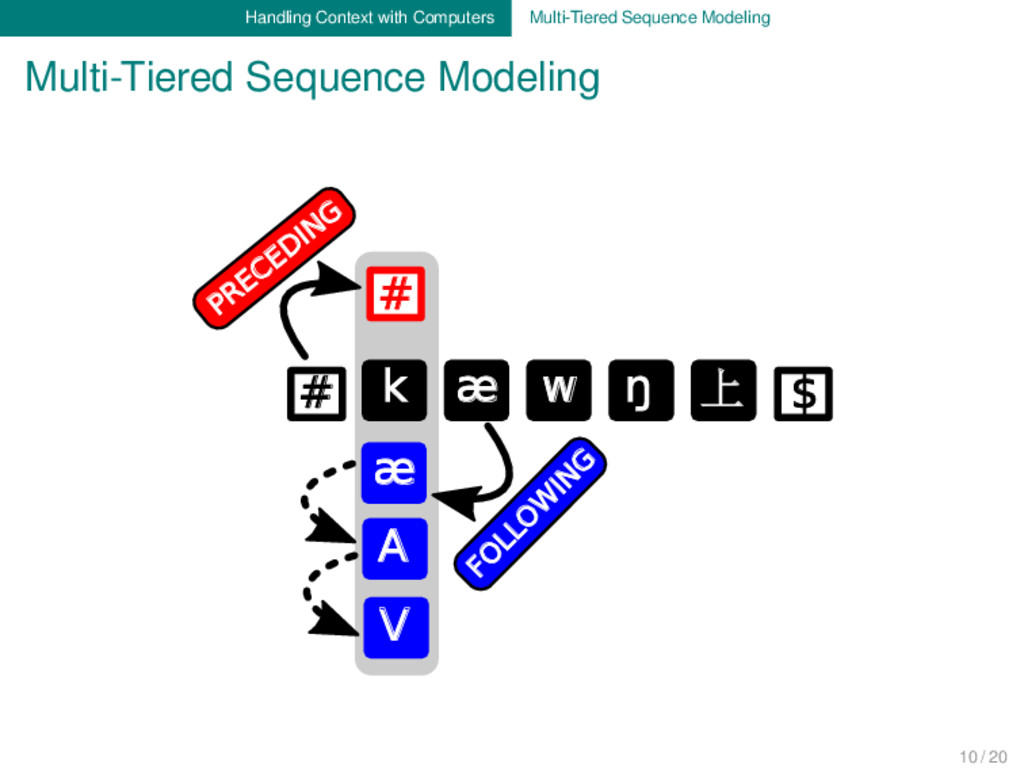
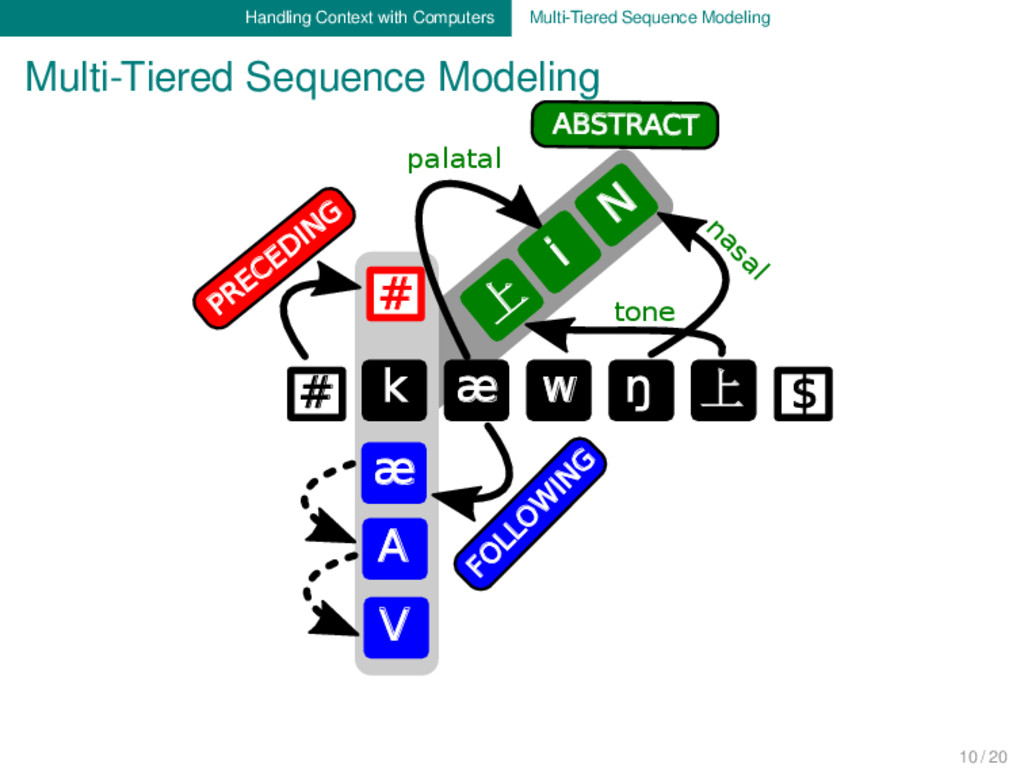
Main Idea: We add context to alignments by defining different types of context to each segment of the ancestral word form. Each alignment of ancestral and descendant form is then additionally represented by multiple context tiers. Three Technical Types of Context: - preceding: the element is preceded by one or more other elements - following: the element is followed by one or more other elements - abstract: the element’s context is specified otherwise Advantages: - multi-tiers can handle suprasegmental aspects (stress, tone) - multi-tiers are extremely flexible, but also comparable across languages - multi-tiers are human- and machine-readable - multi-tiers are easy to compute automatically - multi-tiers are an excellent heuristic for initial language comparison 9 / 20
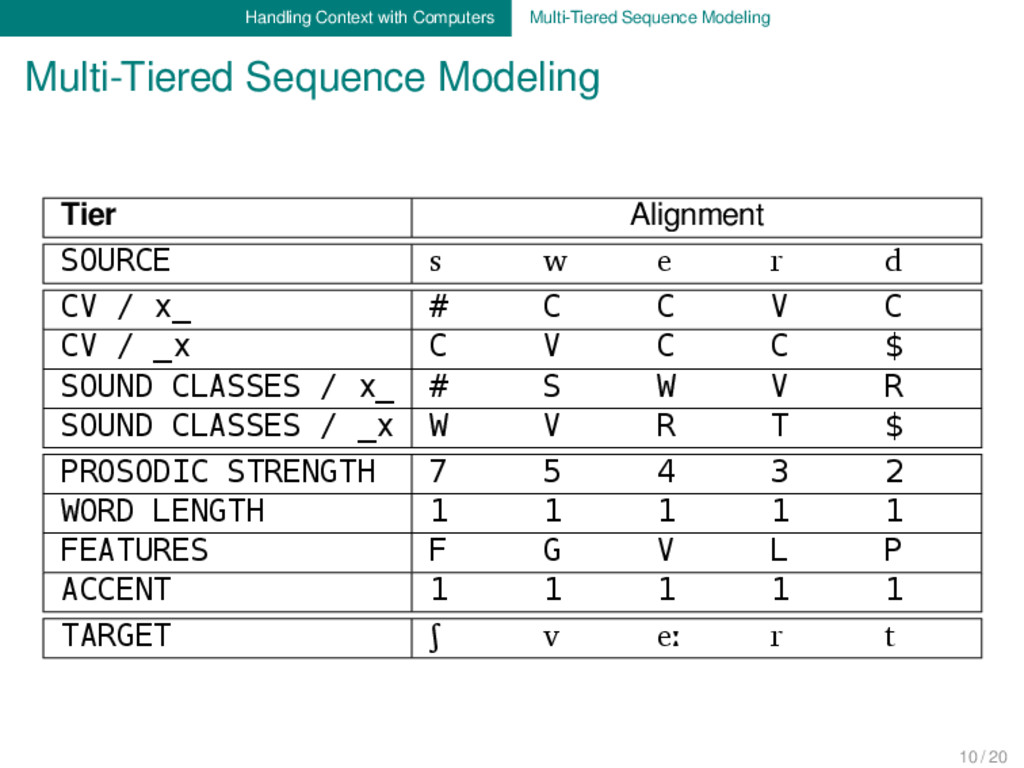
Tier Alignment SOURCE s w e r d CV / x_ # C C V C CV / _x C V C C $ SOUND CLASSES / x_ # S W V R SOUND CLASSES / _x W V R T $ PROSODIC STRENGTH 7 5 4 3 2 WORD LENGTH 1 1 1 1 1 FEATURES F G V L P ACCENT 1 1 1 1 1 TARGET ʃ v eː r t 10 / 20
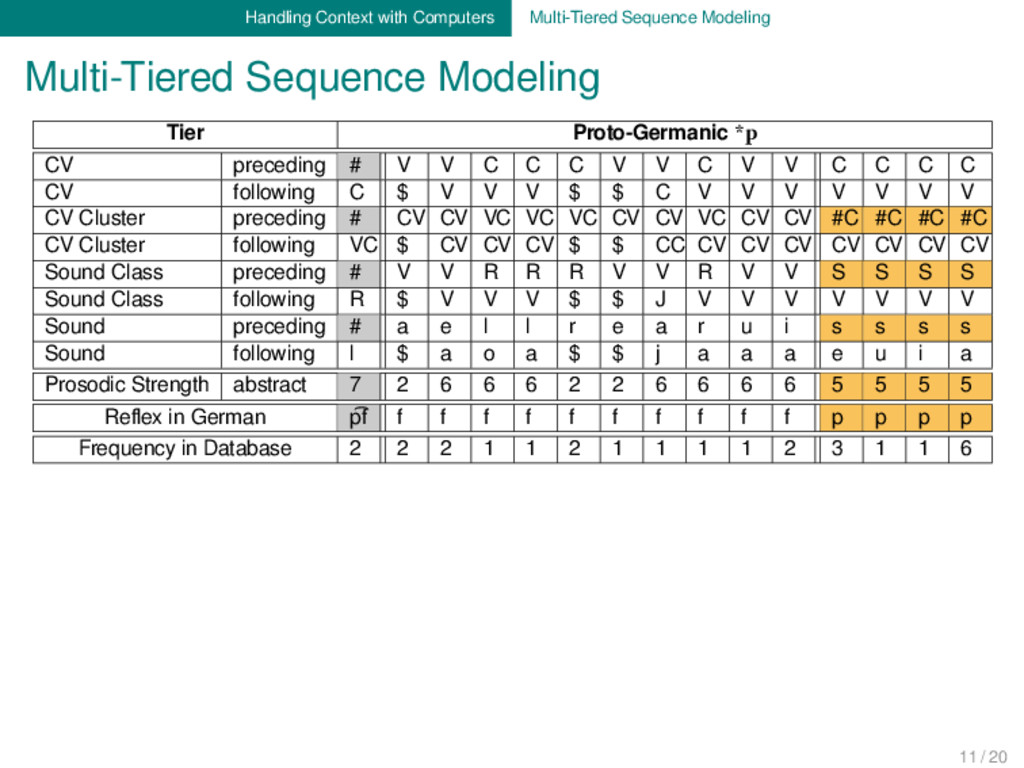
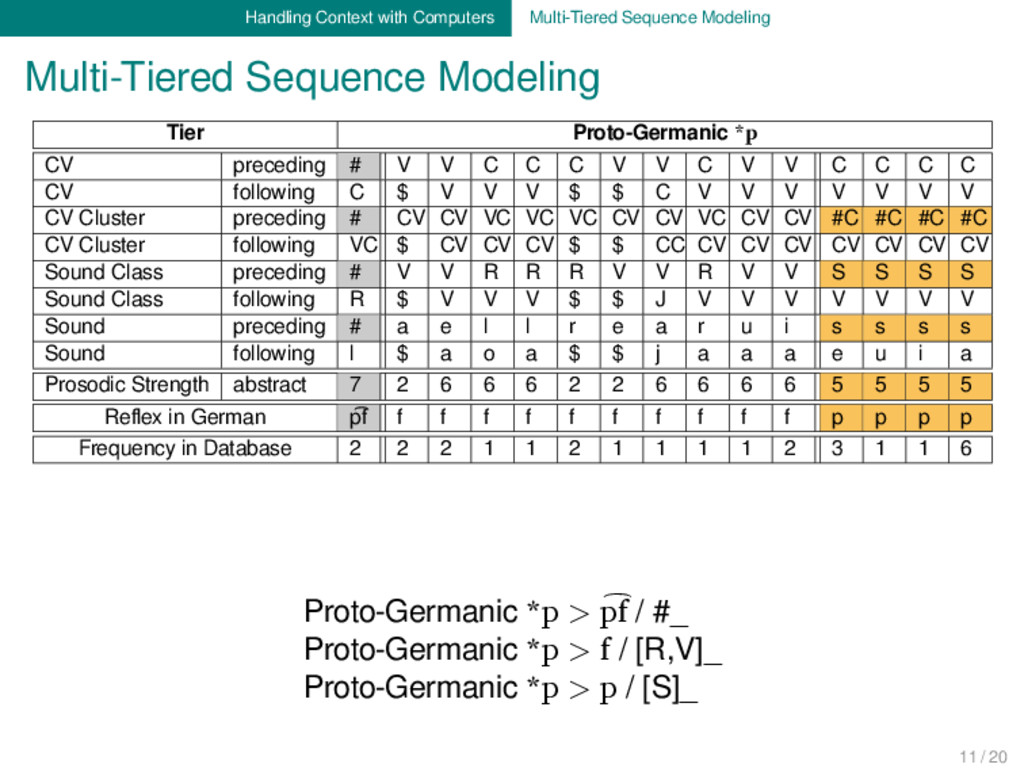
Tier Proto-Germanic *p CV preceding # V V C C C V V C V V C C C C CV following C $ V V V $ $ C V V V V V V V CV Cluster preceding # CV CV VC VC VC CV CV VC CV CV #C #C #C #C CV Cluster following VC $ CV CV CV $ $ CC CV CV CV CV CV CV CV Sound Class preceding # V V R R R V V R V V S S S S Sound Class following R $ V V V $ $ J V V V V V V V Sound preceding # a e l l r e a r u i s s s s Sound following l $ a o a $ $ j a a a e u i a Prosodic Strength abstract 7 2 6 6 6 2 2 6 6 6 6 5 5 5 5 Reflex in German p͡f f f f f f f f f f f p p p p Frequency in Database 2 2 2 1 1 2 1 1 1 1 2 3 1 1 6 Proto-Germanic *p > p͡f / #_ Proto-Germanic *p > f / [R,V]_ Proto-Germanic *p > p / [S]_ 11 / 20
Tier Proto-Germanic *p CV preceding # V V C C C V V C V V C C C C CV following C $ V V V $ $ C V V V V V V V CV Cluster preceding # CV CV VC VC VC CV CV VC CV CV #C #C #C #C CV Cluster following VC $ CV CV CV $ $ CC CV CV CV CV CV CV CV Sound Class preceding # V V R R R V V R V V S S S S Sound Class following R $ V V V $ $ J V V V V V V V Sound preceding # a e l l r e a r u i s s s s Sound following l $ a o a $ $ j a a a e u i a Prosodic Strength abstract 7 2 6 6 6 2 2 6 6 6 6 5 5 5 5 Reflex in German p͡f f f f f f f f f f f p p p p Frequency in Database 2 2 2 1 1 2 1 1 1 1 2 3 1 1 6 Proto-Germanic *p > p͡f / #_ Proto-Germanic *p > f / [R,V]_ Proto-Germanic *p > p / [S]_ 11 / 20
Tier Proto-Germanic *p CV preceding # V V C C C V V C V V C C C C CV following C $ V V V $ $ C V V V V V V V CV Cluster preceding # CV CV VC VC VC CV CV VC CV CV #C #C #C #C CV Cluster following VC $ CV CV CV $ $ CC CV CV CV CV CV CV CV Sound Class preceding # V V R R R V V R V V S S S S Sound Class following R $ V V V $ $ J V V V V V V V Sound preceding # a e l l r e a r u i s s s s Sound following l $ a o a $ $ j a a a e u i a Prosodic Strength abstract 7 2 6 6 6 2 2 6 6 6 6 5 5 5 5 Reflex in German p͡f f f f f f f f f f f p p p p Frequency in Database 2 2 2 1 1 2 1 1 1 1 2 3 1 1 6 Proto-Germanic *p > p͡f / #_ Proto-Germanic *p > f / [R,V]_ Proto-Germanic *p > p / [S]_ 11 / 20
Tier Proto-Germanic *p CV preceding # V V C C C V V C V V C C C C CV following C $ V V V $ $ C V V V V V V V CV Cluster preceding # CV CV VC VC VC CV CV VC CV CV #C #C #C #C CV Cluster following VC $ CV CV CV $ $ CC CV CV CV CV CV CV CV Sound Class preceding # V V R R R V V R V V S S S S Sound Class following R $ V V V $ $ J V V V V V V V Sound preceding # a e l l r e a r u i s s s s Sound following l $ a o a $ $ j a a a e u i a Prosodic Strength abstract 7 2 6 6 6 2 2 6 6 6 6 5 5 5 5 Reflex in German p͡f f f f f f f f f f f p p p p Frequency in Database 2 2 2 1 1 2 1 1 1 1 2 3 1 1 6 Proto-Germanic *p > p͡f / #_ Proto-Germanic *p > f / [R,V]_ Proto-Germanic *p > p / [S]_ 11 / 20
Multi-tiers are only a representation! Mult-tiered alignments alone won’t give us the sound-change conditio- ning context. In order to infer the patterns relevant to condition sound change processes, a careful inspection of relevant contexts is needed. Multi-tier-Systems can be automatically optimized Automated procedures can provide a great help here, since they can be used to seek the optimal tier-system which is needed in order to explain a given datasets as having evolved from regular sound change processes. Multi-tiers also provide great help in identifying erroneous cognate sets, undetected borrowings, or wrong alignments in a given dataset. 12 / 20
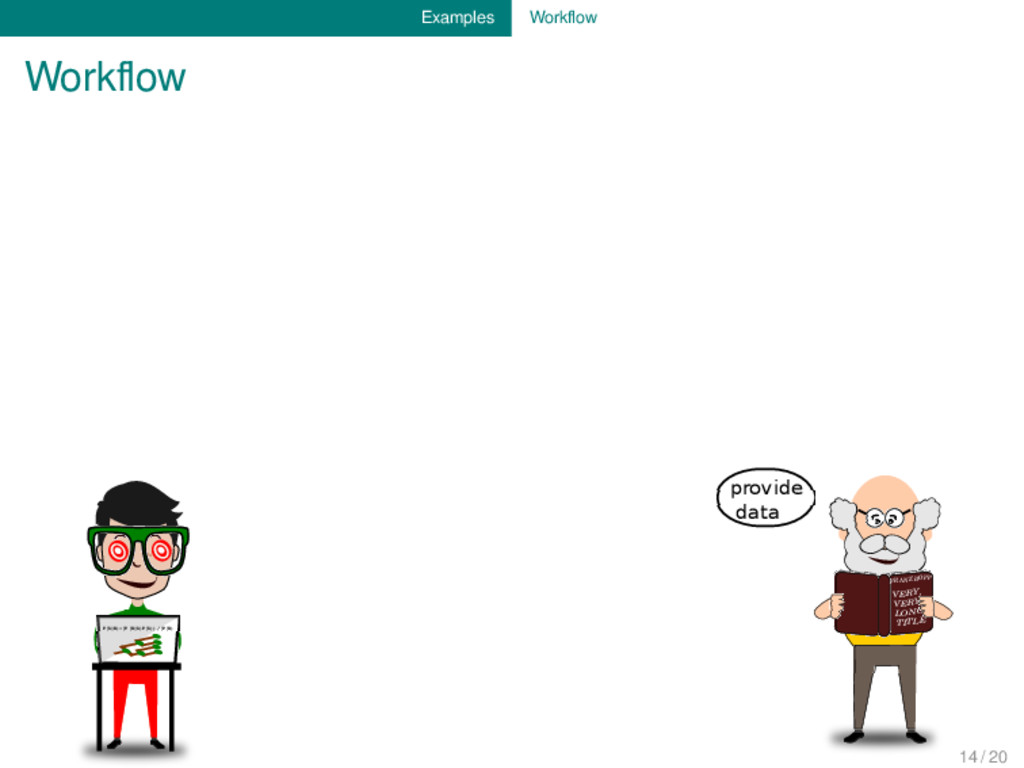
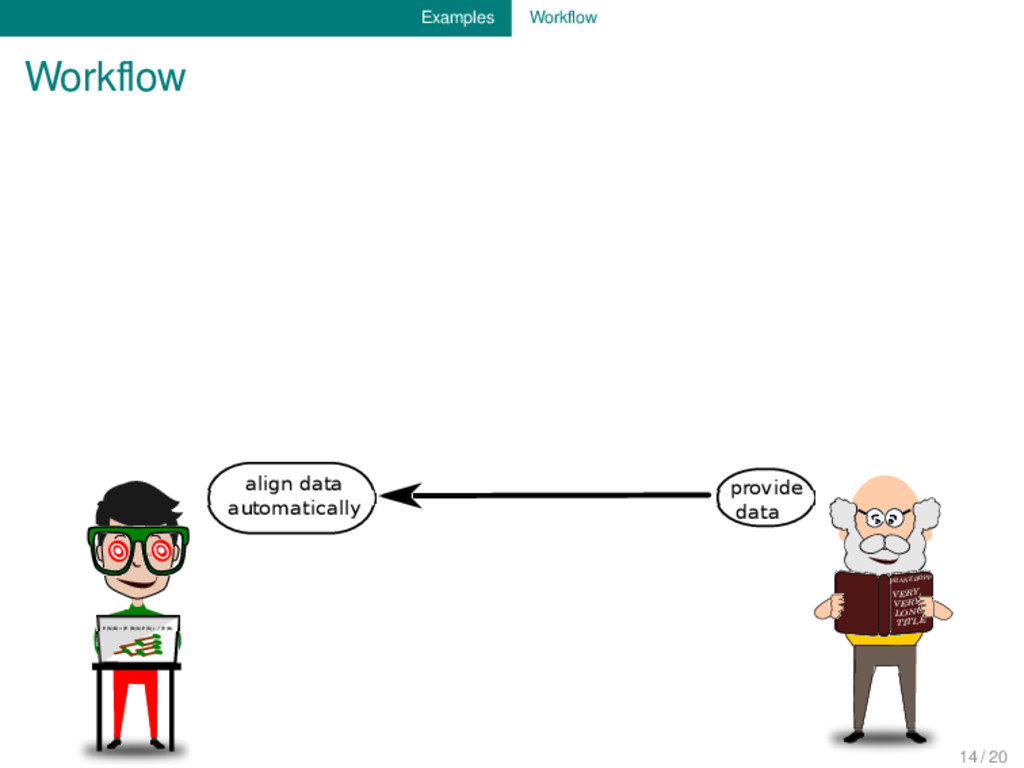
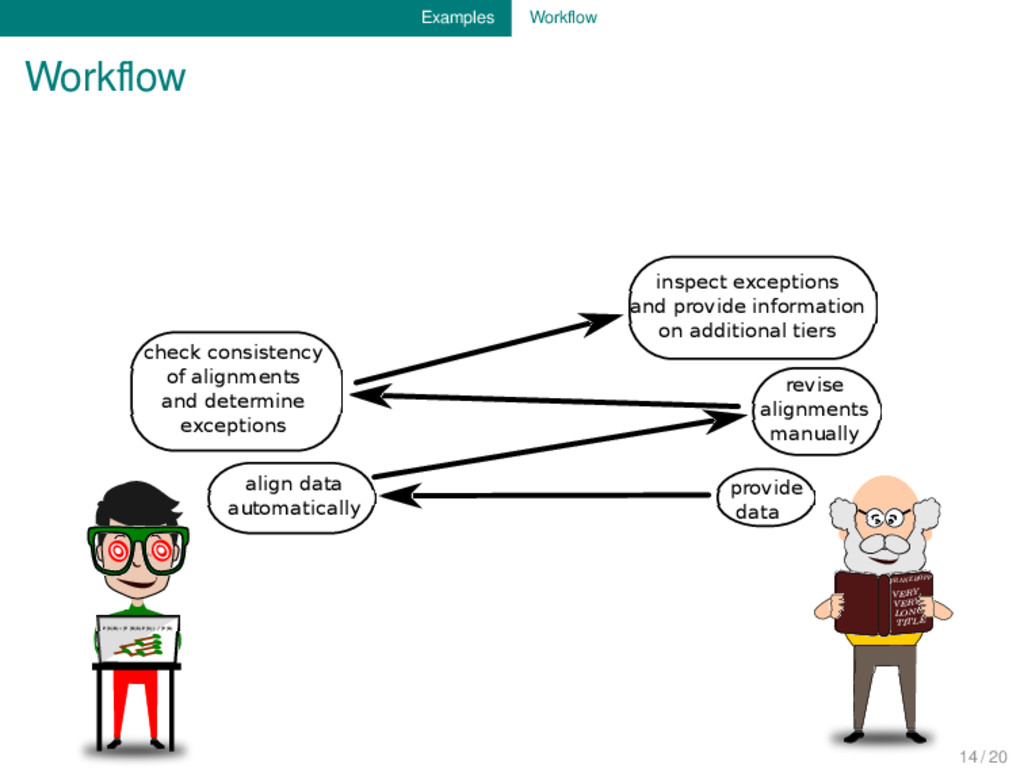
provide data align data automatically revise alignments manually check consistency of alignments and determine exceptions inspect exceptions and provide information on additional tiers 14 / 20
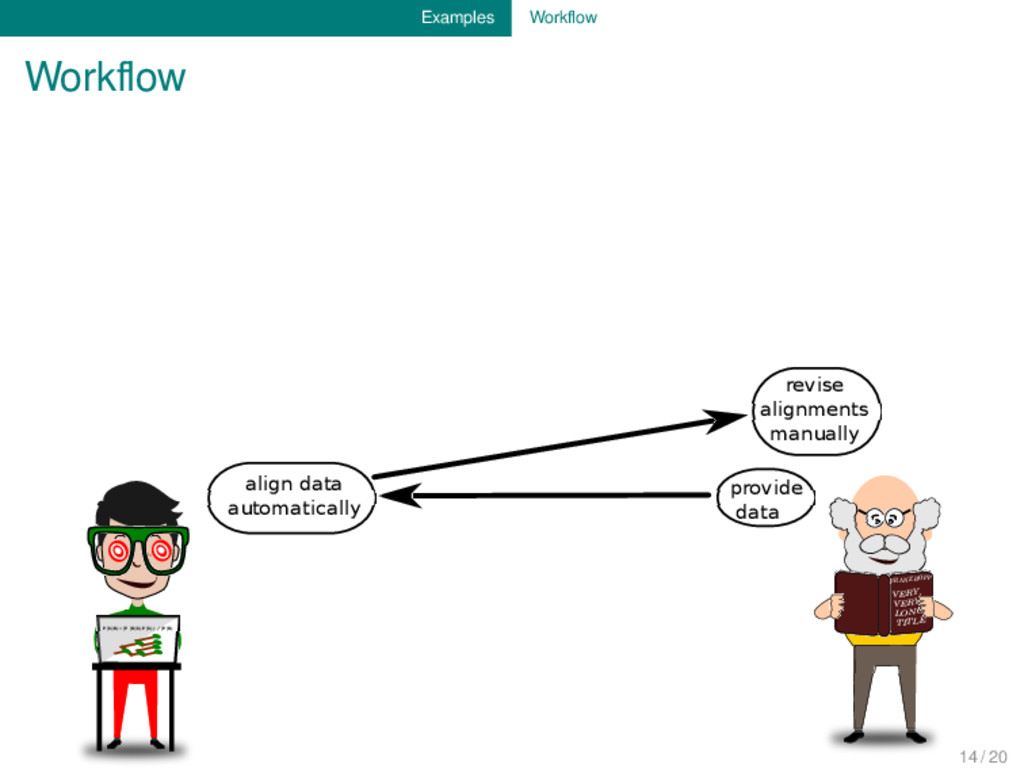
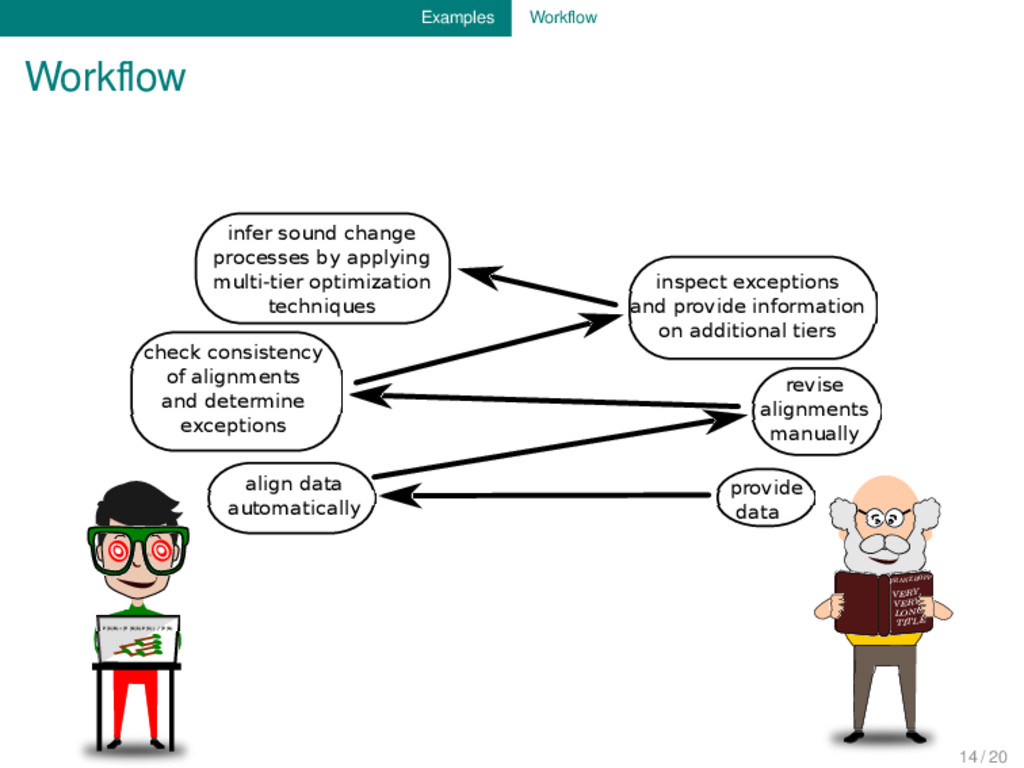
provide data align data automatically revise alignments manually check consistency of alignments and determine exceptions inspect exceptions and provide information on additional tiers infer sound change processes by applying multi-tier optimization techniques 14 / 20
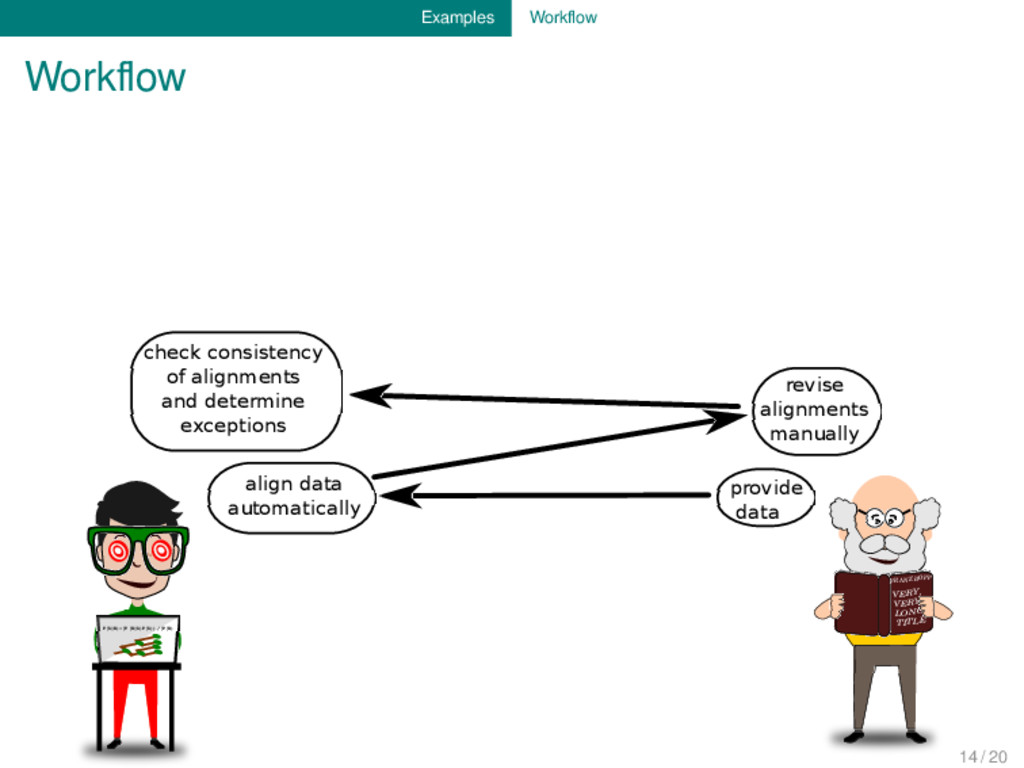
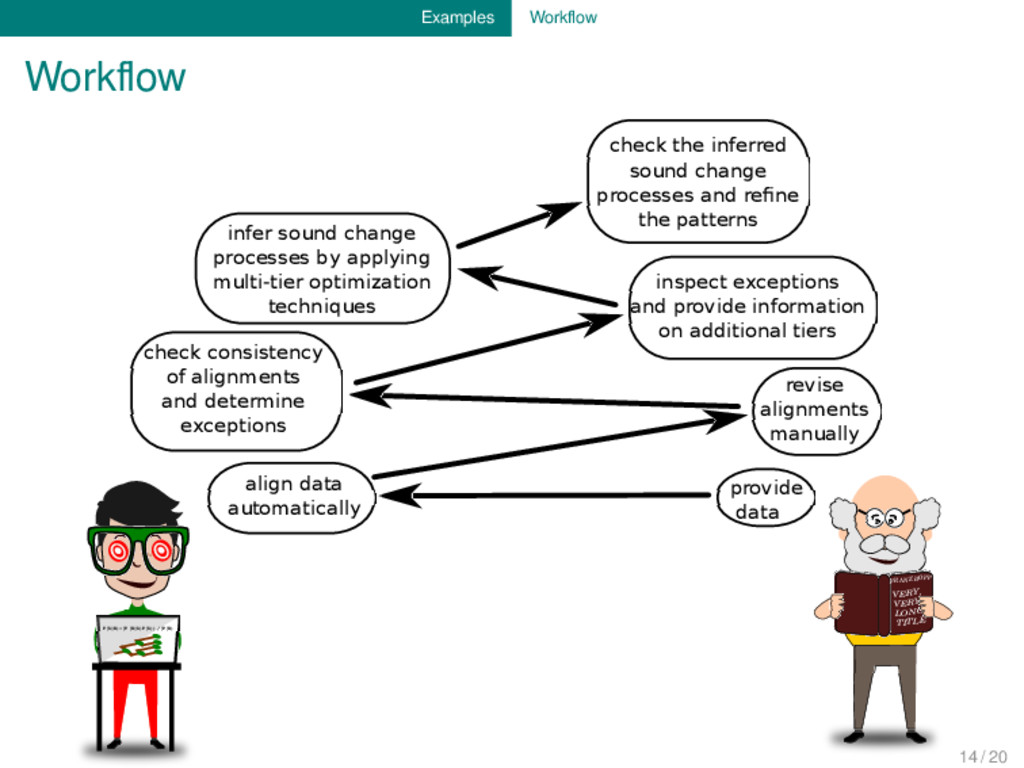
provide data align data automatically revise alignments manually check consistency of alignments and determine exceptions inspect exceptions and provide information on additional tiers check the inferred sound change processes and refine the patterns infer sound change processes by applying multi-tier optimization techniques 14 / 20
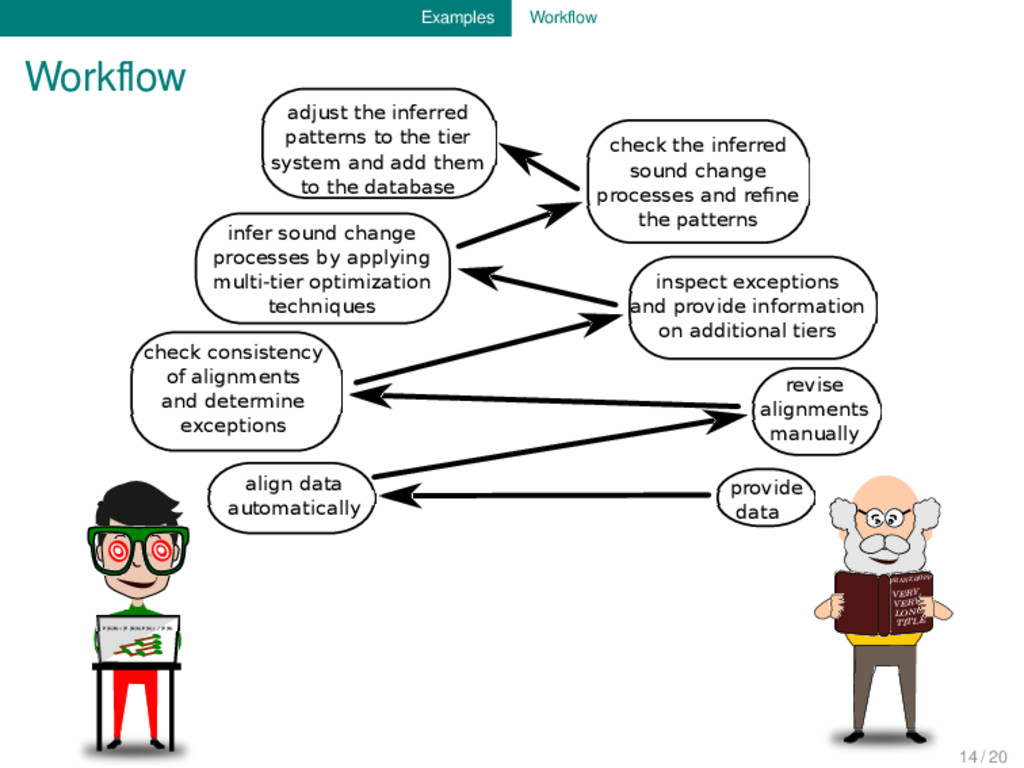
provide data align data automatically revise alignments manually check consistency of alignments and determine exceptions inspect exceptions and provide information on additional tiers check the inferred sound change processes and refine the patterns infer sound change processes by applying multi-tier optimization techniques adjust the inferred patterns to the tier system and add them to the database 14 / 20
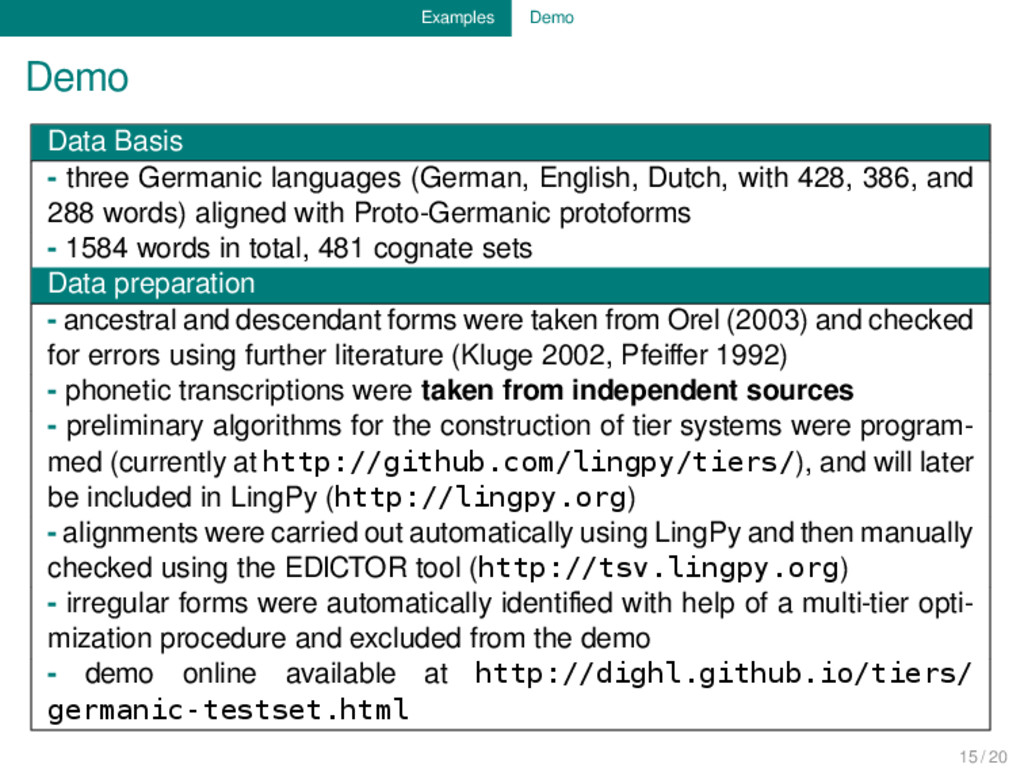
English, Dutch, with 428, 386, and 288 words) aligned with Proto-Germanic protoforms - 1584 words in total, 481 cognate sets Data preparation - ancestral and descendant forms were taken from Orel (2003) and checked for errors using further literature (Kluge 2002, Pfeiffer 1992) - phonetic transcriptions were taken from independent sources - preliminary algorithms for the construction of tier systems were program- med (currently at http://github.com/lingpy/tiers/), and will later be included in LingPy (http://lingpy.org) - alignments were carried out automatically using LingPy and then manually checked using the EDICTOR tool (http://tsv.lingpy.org) - irregular forms were automatically identified with help of a multi-tier opti- mization procedure and excluded from the demo - demo online available at http://dighl.github.io/tiers/ germanic-testset.html 15 / 20
datasets (Tukano, Indo-European, Chinese) work out and test ways to model sound sequences beyond their IPA types (gestural mechanics, features systems, etc.) explore and adjust the multi-tier-systems based on discussions with computer scientists and experts on diachronic phonology (can we classify tier systems in a less technical way?) seek solutions for problems which multi-tiers cannot answer so far (non-linear sound change patterns, secondary changes) try to find methods and models to further structure the inferred sound change patterns and reconcile them with existing theories of language change find solutions to get the time dimension into the sound change modeling process (using trees or networks) seek collaborations with scholars willing to share their data and with scholars willing to share and test their theories 16 / 20
Concluding Remarks Collecting cross-linguistic data on regu- lar sound change patterns is very chal- lenging.The way towards a cross-linguistic database for historical phonology is long and stony. But we are making progress, and with combined efforts involving the collaboration of historical linguists and computer scientists within a computer- assisted framework of language collabo- ration, we may succeed. 19 / 20
Concluding Remarks So far, computational approaches only use the data, not the theories, and lin- guistic theories are often only developed on small amounts of data. Putting the construction of the database in a frame- work of computer-assisted – as opposed to computer-based – language compari- son could reconcile the achievements of historical linguistics with the most recent developments in computer sciences. 19 / 20
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}