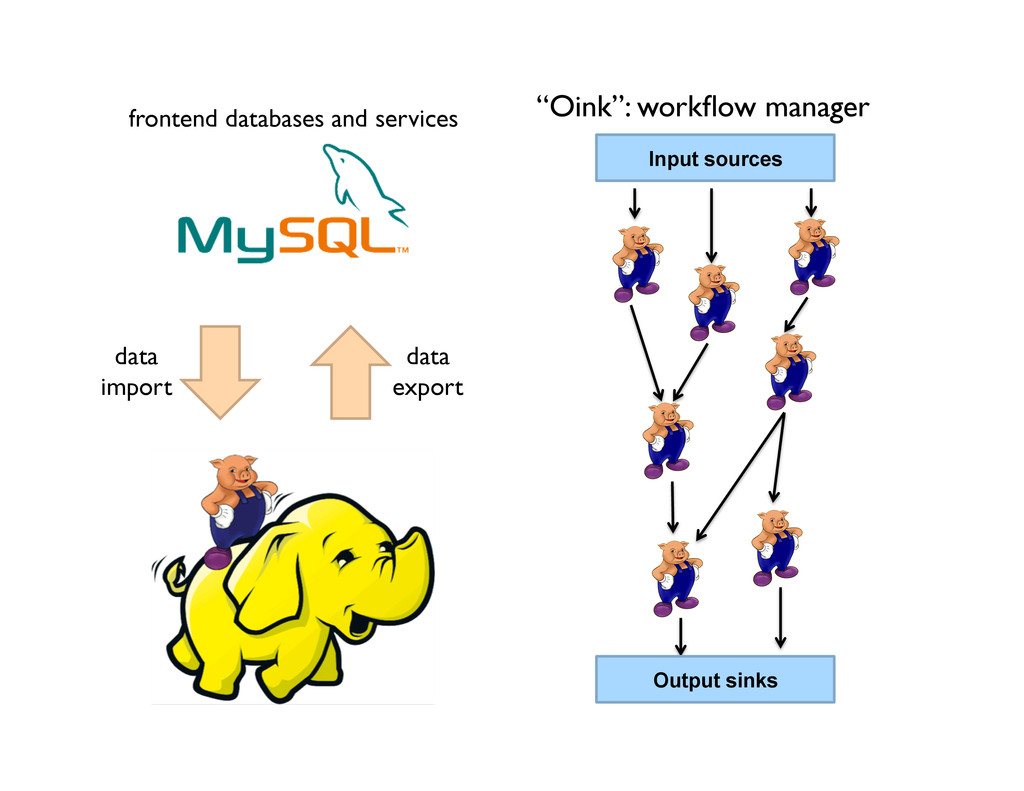
Defeats the whole point of big data! 2. Ad hoc productionizing Disconnected from rest of production Oink workflow None of the benefits of Oink So, we redesigned it… with two goals:
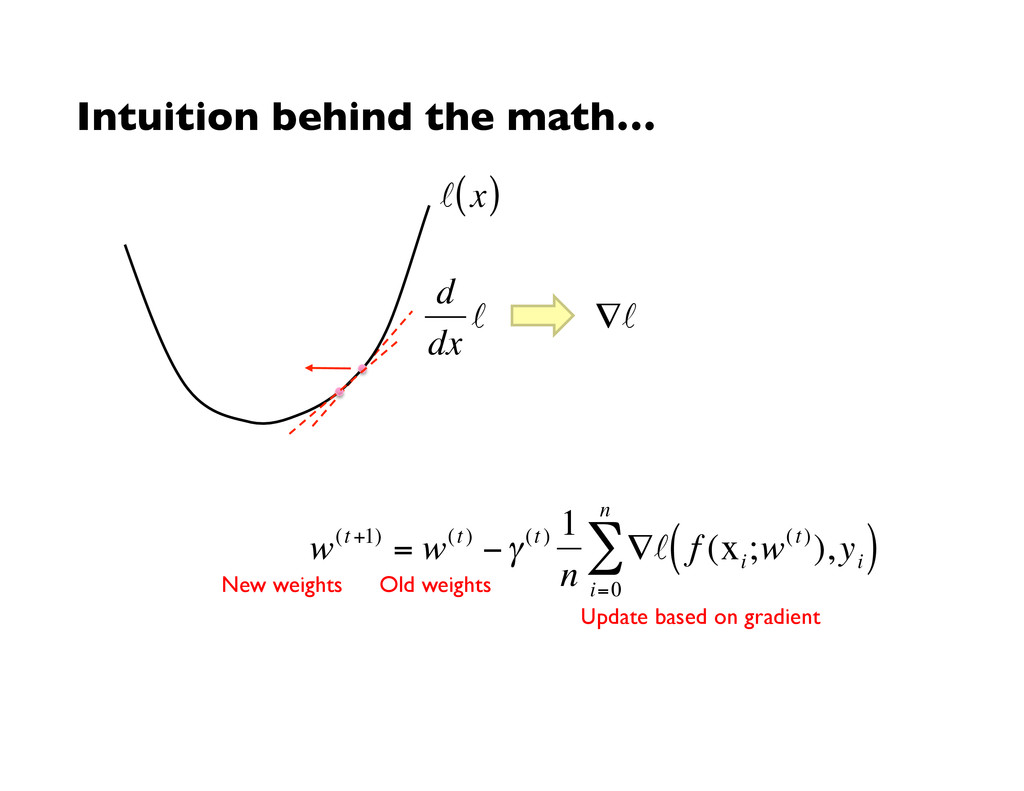
minimized € argmin θ 1 n f (x i ;w),y i ( ) i=0 n ∑ Consider functions of a parametric form: Key insight: machine learning as an optimization problem! empirical loss = (closed form solutions generally not possible) loss function model parameters (weights) (sparse) feature vector label
∇ f (x i ;w(t)),y ( ) i=0 n ∑ mapper mapper mapper mapper reducer compute partial gradient single reducer mappers update model iterate until convergence
job startup costs Awkward to retain state across iterations High sensitivity to skew Iteration speed bounded by slowest task Potentially poor cluster utilization Must shuffle all data to a single reducer
) −γ(t ) 1 n ∇ f (x i ;w(t)),y i ( ) i=0 n ∑ € w(t +1) = w(t ) −γ(t )∇ f (x;w(t)),y ( ) “batch” learning: update model after considering all training instances “online” learning: update model after considering each (randomly-selected) training instance Solves the iteration problem! What about the single reducer problem? In practice… just as good!
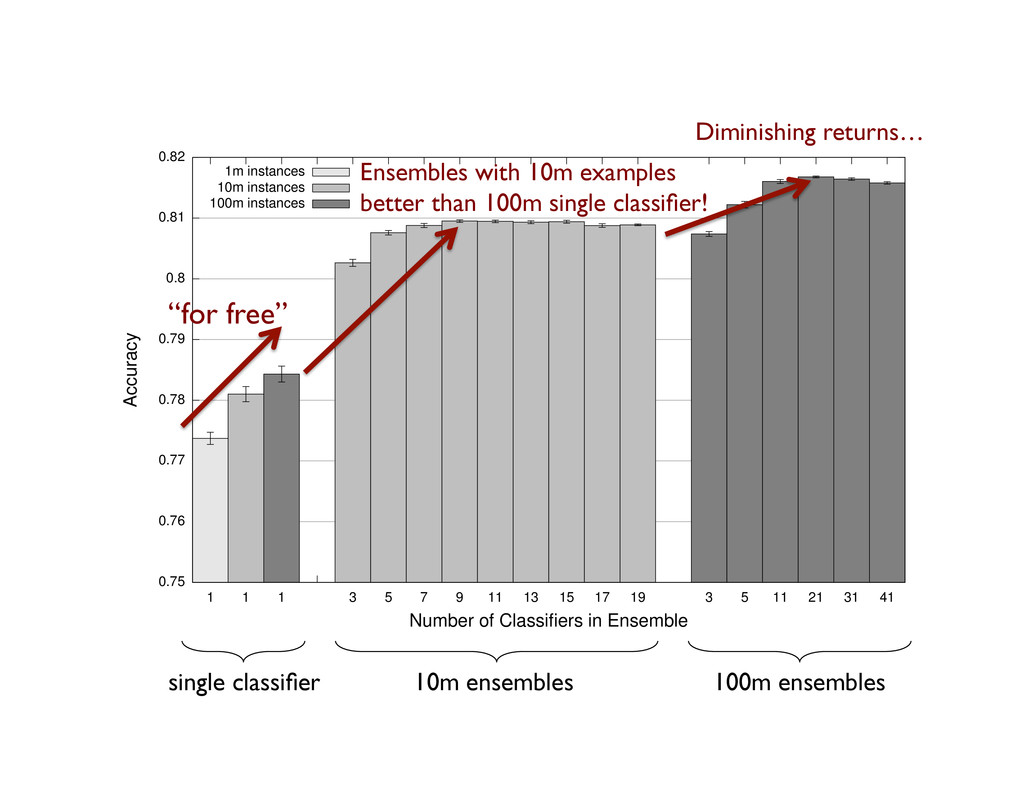
majority voting Simple weighted voting: Why does it work? If errors uncorrelated, multiple classifiers being wrong is less likely Reduces the variance component of error Embarassingly parallel ensemble learning: Train each classifier on partitioned input Contrast with boosting: more difficult to parallelize
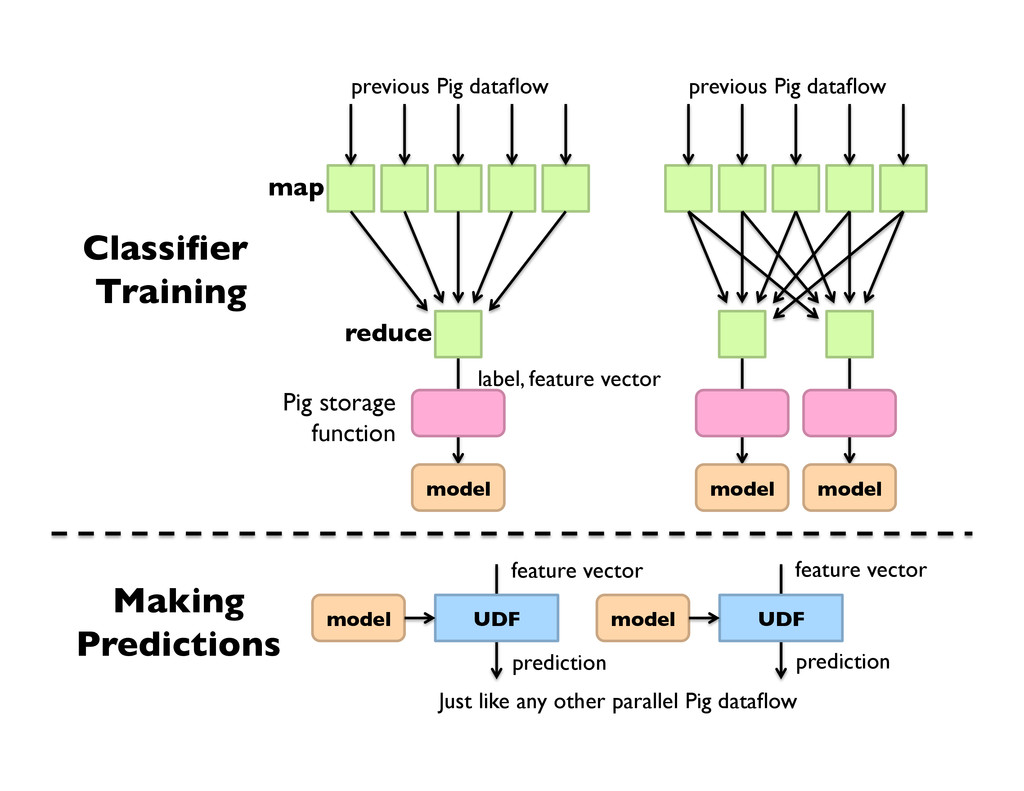
int, features: map[]); store training into ‘model/’ using FeaturesLRClassifierBuilder(); Want an ensemble? training = foreach training generate label, features, RANDOM() as random; training = order training by random parallel 5; Logistic regression + SGD (L2 regularization) Pegasos variant (fully SGD or sub-gradient)
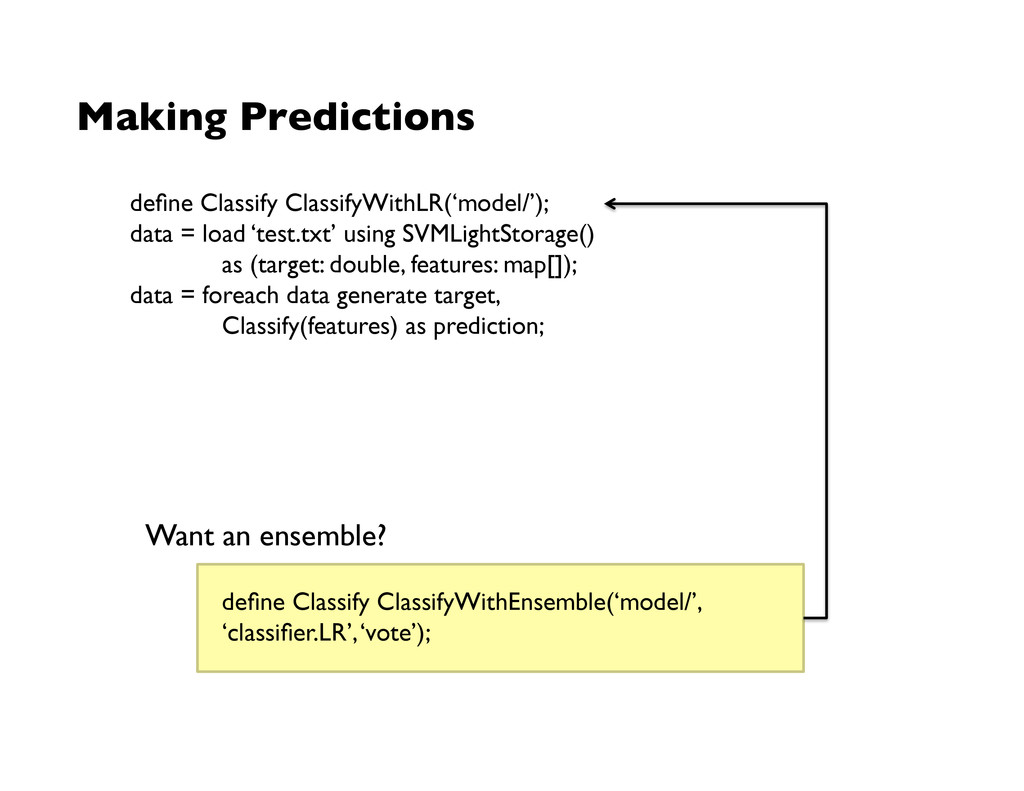
(target: double, features: map[]); data = foreach data generate target, Classify(features) as prediction; Making Predictions Want an ensemble? define Classify ClassifyWithEnsemble(‘model/’, ‘classifier.LR’, ‘vote’);
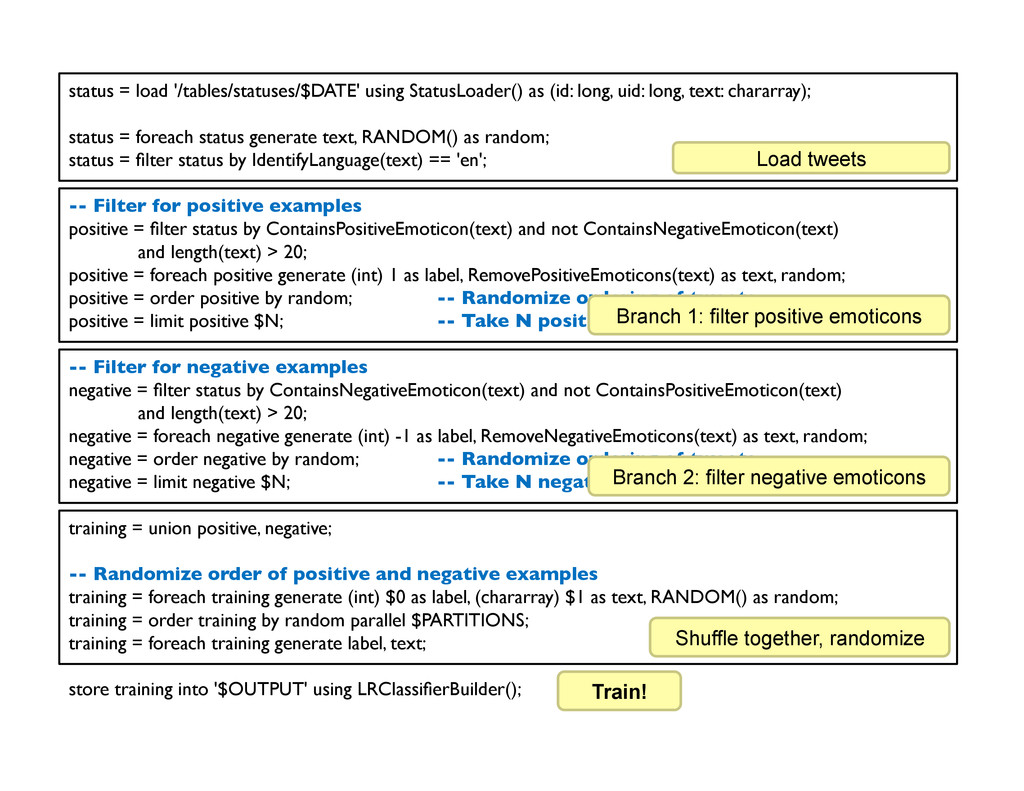
long, text: chararray); status = foreach status generate text, RANDOM() as random; status = filter status by IdentifyLanguage(text) == 'en'; -- Filter for positive examples positive = filter status by ContainsPositiveEmoticon(text) and not ContainsNegativeEmoticon(text) and length(text) > 20; positive = foreach positive generate (int) 1 as label, RemovePositiveEmoticons(text) as text, random; positive = order positive by random; -- Randomize ordering of tweets. positive = limit positive $N; -- Take N positive examples. -- Filter for negative examples negative = filter status by ContainsNegativeEmoticon(text) and not ContainsPositiveEmoticon(text) and length(text) > 20; negative = foreach negative generate (int) -1 as label, RemoveNegativeEmoticons(text) as text, random; negative = order negative by random; -- Randomize ordering of tweets negative = limit negative $N; -- Take N negative examples training = union positive, negative; -- Randomize order of positive and negative examples training = foreach training generate (int) $0 as label, (chararray) $1 as text, RANDOM() as random; training = order training by random parallel $PARTITIONS; training = foreach training generate label, text; store training into '$OUTPUT' using LRClassifierBuilder(); Load tweets Branch 1: filter positive emoticons Branch 2: filter negative emoticons Shuffle together, randomize Train!
into DB? MADLibs, Bismark Integration into custom DSL? Spark Integration into existing package? MATLAB, R Faster iterative algorithms in MapReduce HaLoop, Twister, PrIter: Requires a different programming model Why not just use Mahout? Our core ML libraries pre-date Mahout Tighter integration with our internal workflows Mahout + Pig can be integrated in exactly the same way!
Machine Learning at Twitter. Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data (SIGMOD 2012), May 2012, Scottsdale, Arizona.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}