Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
統計学:予測 と ベイジアン統計: 要するに確率→エネルギー #TechLunch
Search
Livesense Inc.
PRO
April 21, 2014
Technology
110
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
統計学:予測 と ベイジアン統計: 要するに確率→エネルギー #TechLunch
統計学:予測 と ベイジアン統計: 要するに確率→エネルギー
2012/08/01 (水) @ Livesense TechLunch
発表者:徳江 勇樹
Livesense Inc.
PRO
April 21, 2014
More Decks by Livesense Inc.
See All by Livesense Inc.
Rubyはただの⾔語に⾮ず
livesense
PRO
0
430
28新卒_Webエンジニア職採用_会社説明資料
livesense
PRO
0
110
27新卒_総合職採用_会社説明資料
livesense
PRO
0
6k
27新卒_Webエンジニア職採用_会社説明資料
livesense
PRO
0
11k
株式会社リブセンス・転職会議 採用候補者様向け資料
livesense
PRO
0
510
株式会社リブセンス 会社説明資料(報道関係者様向け)
livesense
PRO
1
1.7k
データ基盤の負債解消のためのリプレイス
livesense
PRO
0
640
26新卒_総合職採用_会社説明資料
livesense
PRO
0
13k
株式会社リブセンス会社紹介資料 / Invent the next common.
livesense
PRO
2
69k
Other Decks in Technology
See All in Technology
勉強会企画をアプリで構造化してみた 〜そこで見えた、AIとの付き合い方〜 / I've structured a study group plan using an app.
pauli
0
330
オブザーバビリティ、本当に活用できてる? 〜API連携×生成AIで成熟度を自動評価〜
dmmsre
0
2k
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
1.5k
環境凍結という Toil を倒す -セルフサービス型 Ephemeral テスト環境の 設計と実践
shirouz
1
1.5k
cccccc
moznion
0
1.8k
Docker Desktop不要の時代が来る? WSL標準の「wslc」で Linuxコンテナを動かしてみた.
ueponx
0
800
SRE歴2ヶ月でも開発6年の知見を活かして、チームで止まっていた環境改善を前に進めた話
a_ono
1
220
Baseline対応のDOMの型定義を作った
uhyo
3
720
そのタスクオンスケですか?
poropinai1966
0
140
Amazon EVS で VCF 9.0 / 9.1 のサポート開始まとめ
mtoyoda
0
280
デジタル・デザイン構想 by Sayaka Ishizuka
y150saya
0
200
Zoom2Youtube.Claude
kawaguti
PRO
2
460
Featured
See All Featured
Thoughts on Productivity
jonyablonski
76
5.2k
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Future Trends and Review - Lecture 12 - Web Technologies (1019888BNR)
signer
PRO
0
3.6k
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
170
Noah Learner - AI + Me: how we built a GSC Bulk Export data pipeline
techseoconnect
PRO
0
210
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
My Coaching Mixtape
mlcsv
0
170
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.8k
Designing for Performance
lara
611
70k
sira's awesome portfolio website redesign presentation
elsirapls
0
300
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
The agentic SEO stack - context over prompts
schlessera
0
840
Transcript
1 統計 基礎 予測 と ベイジアン
2 Agenda 統計って? 予測って? ベイジアン再考 次回に向けて
3 ... 本論の前に、経歴抜粋 ? ▪氏名 徳江勇樹 ▪2006 年 東京工業大学大学院 生命理工学研究科生体システム選考 卒業 太田研究室 所属 ▪2004-2006
生物物理学会 こんぴゅてーしょなる な 統計解析 が強い学会 遺伝子データベースからの配列解析 生化学物質の構造・挙動・移動シミュレーション 分子進化速度からのクラスタリング→ 進化系統樹生成 ▪研究課題 タンパク質主鎖の局所構造 - 配列相関 : 1 部位構造コードおよび統 計的ポテンシャルによる解析 ???
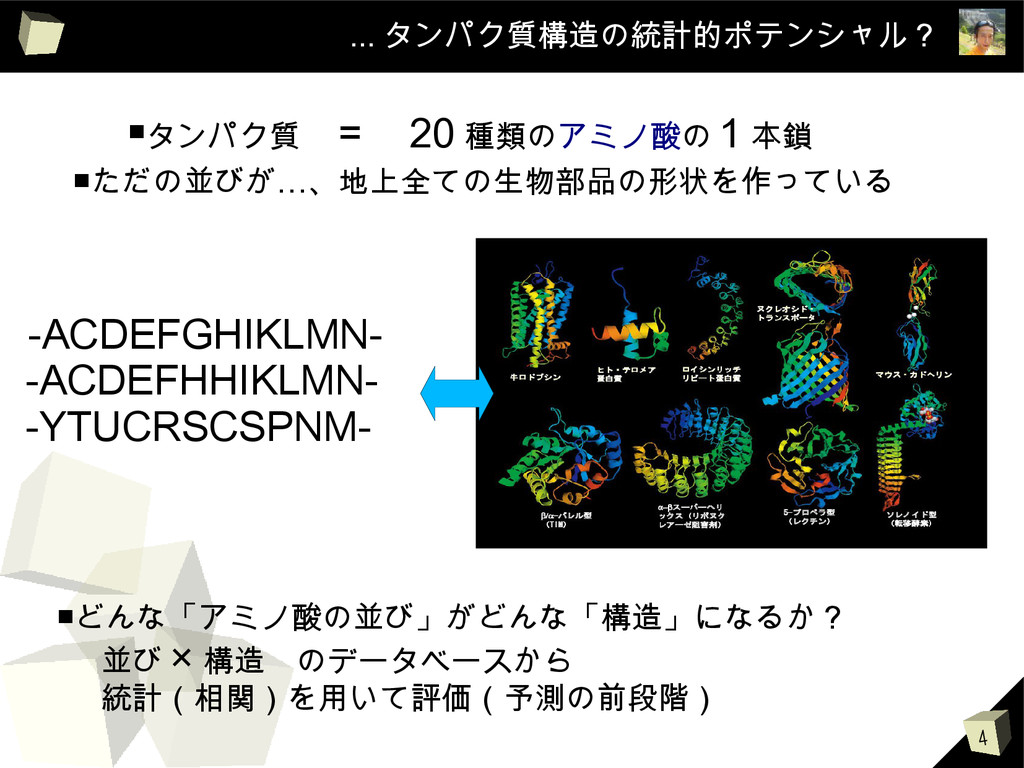
4 ... タンパク質構造の統計的ポテンシャル? ? ▪タンパク質 = 20 種類のアミノ酸の 1 本鎖
▪ただの並びが…、地上全ての生物部品の形状を作っている ▪どんな「アミノ酸の並び」がどんな「構造」になるか? 並び × 構造 のデータベースから 統計(相関)を用いて評価(予測の前段階) -ACDEFGHIKLMN- -ACDEFHHIKLMN- -YTUCRSCSPNM-
5 Agenda 統計って? 予測って? ベイジアン再考 次回に向けて
6 統計にできること ▪情報の山から、意味ある数値を抽出 中央値・最頻値・四分位点・類似度 標準偏差・主成分・相関・分布形状… ▪仮説・検証 推定と検定 「偶然か? 必然か?」 ▪予測 ※本日のメイン
7 予測? ▪過去 実績を蓄積し、参照する ▪現在 測定する ▪未来 予測する・推定する
8 予測? ▪測定したもの 実績を蓄積し、参照する ▪測定可能なもの 測定する ▪測定できないもの 予測する・推定する
9 予測方法の大別 演繹的手法 原理・原則から導出する 物理方程式からの分子の動態シミュレーション CAE による強度実験 予算案 JR の運行計画 経験的手法
測定の実績から導出する !統計の出番 統計値からの母集団の推定 線形計画法 ... 相関関数からの構造予測 レコメンド、人気サイトの紹介 勘 ハイブリッド 気象予測(物理方程式 * 類似気象パターン) Google の検索(全文検索 * クロール結果のランキング)
10 予測のモデル 基本形 Y = f(X, X',Y') for Y 予測結果空間 f
予測手法 X 測定値・パラメーター空間 X' 蓄積された測定値 Y' 蓄積された予測値の正解 中学・高校の数学だったら、 Y は 1 つだったり、 2 つだったり、グラフの線上になる。 が、実際そうは簡単にいかない。 答え Y が膨大 計算量 f(X...) が膨大 例:分子シミュレーション: 空間 × 分子数 × 時間変化
11 予測実行のための工夫 (1) 答えが膨大: ランク 答えに「確からしさ」 (= 順位)をつけて、上位を取る 閾値 答えの「確からしさ」で、一定値以下を除外する
クラスタリング 似た答えを、同一の答えとみなす 答えの解析 得られた解全体に対して、その傾向性を解析する •フーリエ変換で、モードを抽出
12 予測実行のための工夫 (2) 計算量が膨大: 枝刈り 可能性の低い部分は、計算途中で除外する 初期値 アタリをつけて、可能性の高い部分の周辺のみ計算する モデルの簡素化 影響の少ない関数・計算式を近似・除去
•計算のメッシュを荒くする •入力のパラメーターを減らす •寄与の弱い項を無視 ex. 20nm 以上の分子間力≒ 0 •連続関数を離散値に近似 •有効桁数を下げる •蓄積されたデータからのノイズ/偏りを除去(クリーニング) 計算容易な形に 変形 •乗算 → log で和算 ・パラメーターの正規化 (Z 値 ) •積分 → Σ 計算 ・行列演算 •分布関数 → 正規分布で近似 •多パラメーター X → 主成分分析で正規直行空間 X* に変換 再利用 •計算・答えの部分的なキャッシュ 並列計算 •グリッド計算 •ゲーム化して、世界中でコンテスト ほか ハードの最適化、ベクトル演算器、 DSL 構築&チューニング…
13 Agenda 統計って? 予測って? ベイジアン再考 次回に向けて
14 なぜベイジアン? ▪統計的な予測手法の中で、 2 番目に多用されている。 ※ 1 番目: 類似パターンを検索する 例 協調フィルタリング
例 タンパク質の構造予測
15 ベイジアンに関しての おねがい ▪「事前確率」「事後確率」とかいう言葉は、 忘れちゃってください 前後なんてまったくないです。 ちゃんちゃらです。 「条件付確率」ってのも…なんか違う。 ▪興味があるのは、「必然か、偶然か」!
16 スタート地点は「必然か、偶然か」 ▪事象 A と 事象 B が同時に生じる。 必然か? 偶然か? A∩ B
が実際に生じる回数 : A∩ B が偶然に生じる回数 = A∩ B の実績値 : A∩ B の期待値 = N * P(A∩ B) : N * P(A) * P(B) = P(A∩ B) : P(A) * P(B) ※ 統計屋さんは、常に「確率」でものを考えます。 ∵ 確率は 全体の母数 N に対して不変。 cf. 検出数 N A ,N B ,N A∩ B 確率はモデル。理想像。ユートピア。
17 で、ベイジアンは・・・ ▪A∩ B が実際に生じる回数 : A∩ B が偶然に生じる回数 =
P(A∩ B) : P(A) * P(B) = P(A∩ B) / P(A) : P(B) = P(B|A) : P(B) ▪つまり…、「 B が生じる確率」に関して = A による影響(相関): 無影響(偶然) ▪同様に 「 A が生じる確率」に関しても = P(A|B) : P(A) = B による影響(相関) : 無影響(偶然)
18 では、数学的に加速しましょう・・・ 比はいろいろと面倒くさいので、除算にします score 1 = 実績値/期待値 = 左辺 /
右辺 = P(A∩ B) / P(A) * P(B) 一種の「相関係数」 A と B の同時の発生しやすさ。 >>1 同時に発生しやすい 1 相関はなさそう。偶然っぽい。 <<1 同時に発生しにくい A,B から、任意の N コの事象に拡張します。(添え字 i ) A 1 ,A 2 ,A 3 ...A n の同時の発生しやすさ。 score 1 = P(∩ i=0 n{A i }) / Π i=0 n{P(A i )}
19 続いて、統計予測屋さんの技巧・・・ score1 を -log します。 score 2 = -log(score
1 ) = -log(P(∩ i=0 n{A i }) / Π i=0 n{(P(A i ))}) = -log(P(∩ i=0 n{A i })) + Σ i=0 n{log(P(A i )} 統計屋さんとしては、「超美しい」式です。 ぞくぞくします。 理由は…
20 美しさ 1 2 3 4 s n = -log(P(∩
i=0 n{A i })) + Σ i=0 n{log(P(A i )} ▪理由1: 乗算→ 和算 計算が速い 確率計算は基本的に乗算なので。 ▪理由2: (負相関 , 偶然 , 正相関) = ( +∞ ,0,-∞ ) 正相関と負相関を、絶対値で相殺できる。 ▪理由3: 「情報量」のオーダーになる 情報学での「情報量 I 」に相当する ▪理由4: 二項相関 s 2 ・三項相関 s 3 ・・・ N 項相関 s n を 同形式で、足しこみして一括計算ができる イメージ) s 2-n = Σs 2 + Σs 3 + … + Σs n
21 最大の美しさ 5 s n = -log(P(∩ i=0 n{A i
})) + Σ i=0 n{log(P(A i )} ▪理由5: 実はエネルギーの次元 物理化学計算・エントロピー計算などと同形式。 ➔ 既存技法の転用 演繹的手法(シミュレーションなど)の技術 ➔ 既存技法・関数と対比可能 定数パラメーターの調整 や 未知の力学項の推測 ➔ 演繹的手法と足し合わせて、ハイブリッド実行可能
22 今日のベイジアンはここまで s{n} = Σ{log(P(Ai)} – log(P(∩ {Ai})) ▪ベイジアンは、統計的な予測でメジャーな方法 ▪相関係数の1手法
▪N次への拡張が容易 で 積算可能 ▪実は「エネルギー」 というか、確率は全てエネルギー。
23 Agenda 統計って? 予測って? ベイジアン再考 次回に向けて
24 なにがいいですか? ▪統計学ネタ 分布 主成分分析 クラスタリング ▪品質ネタ 基礎 製造業 手法・ツール紹介
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}