Jeremy Chan's short talk to the London Java Community on 8th September 2020.
In this talk, Jeremy will give us a brief history of Unicode and discuss some of the common pitfalls he's come across.
Jeremy Chan is currently a VP at Goldman Sachs. He has previously worked at Credit Suisse and Barclays Investment Bank and has a Masters in Computer Science and Engineering.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
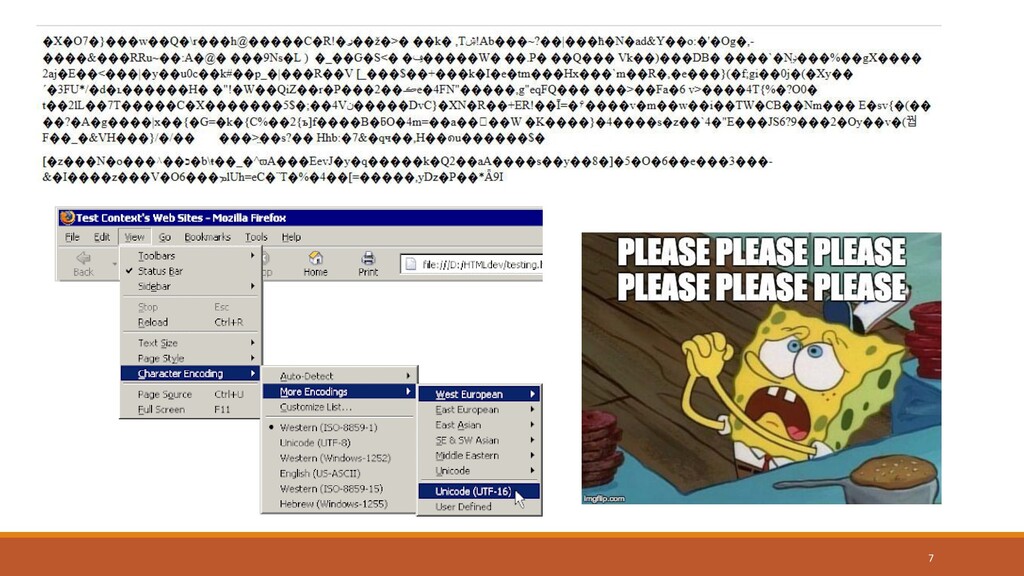{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
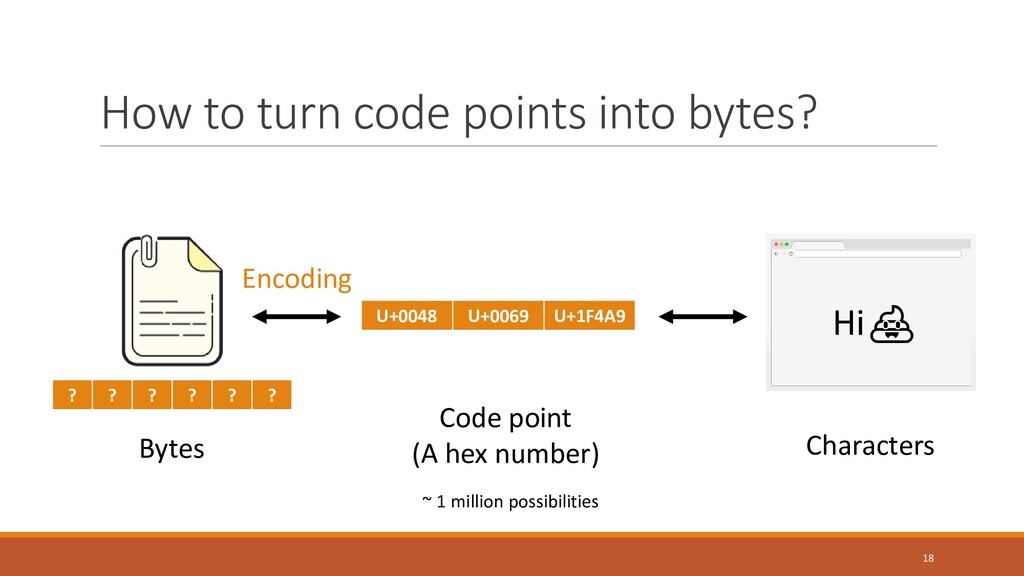{kind=link}
{kind=link}
{kind=link}
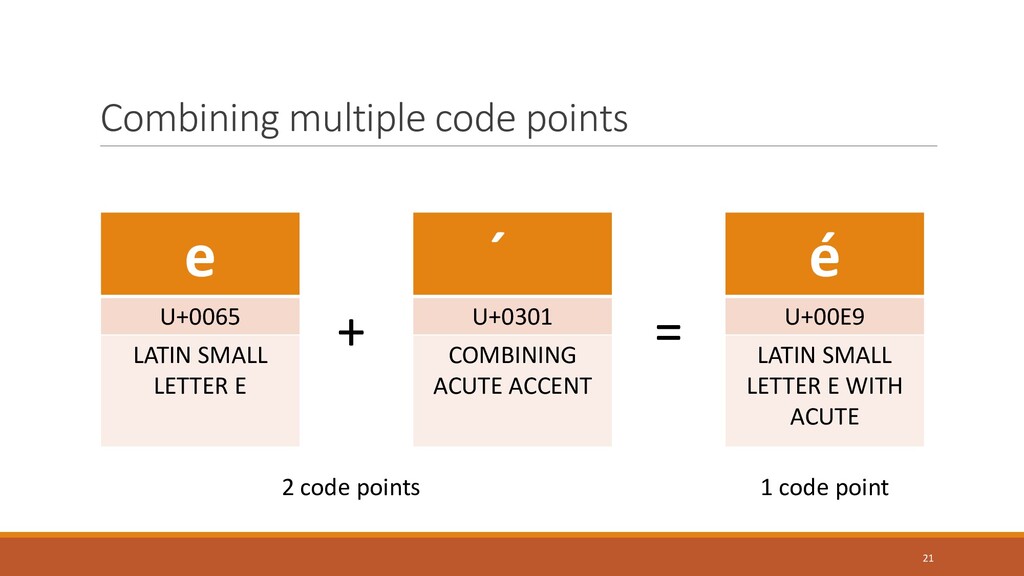{kind=link}
{kind=link}
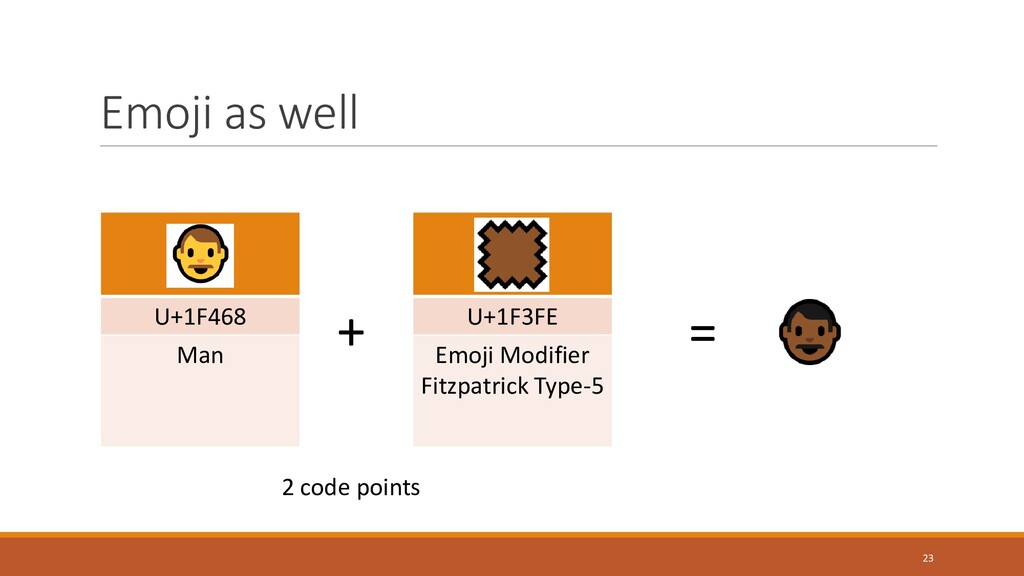{kind=link}
{kind=link}
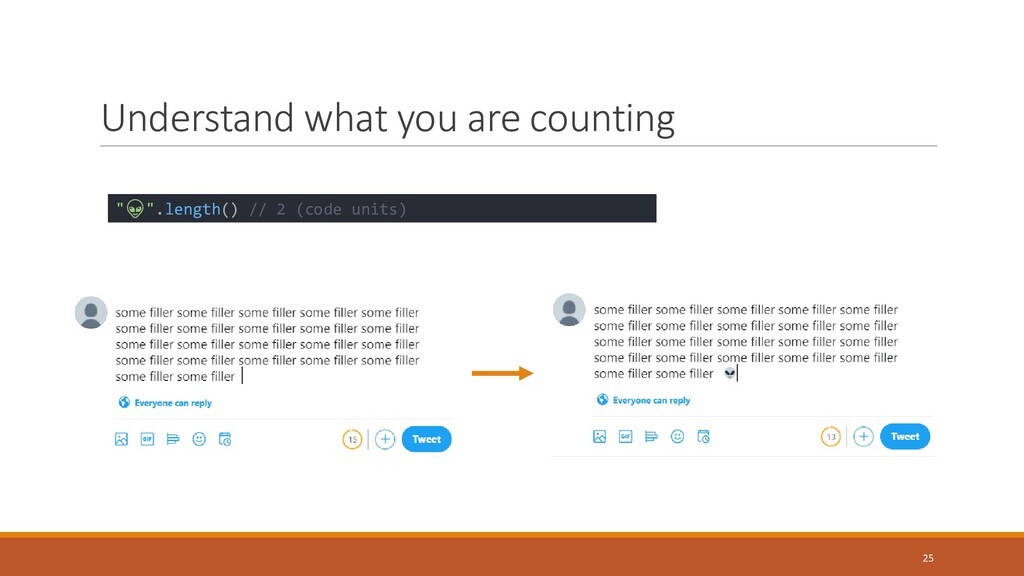{kind=link}
{kind=link}
{kind=link}
{kind=link}
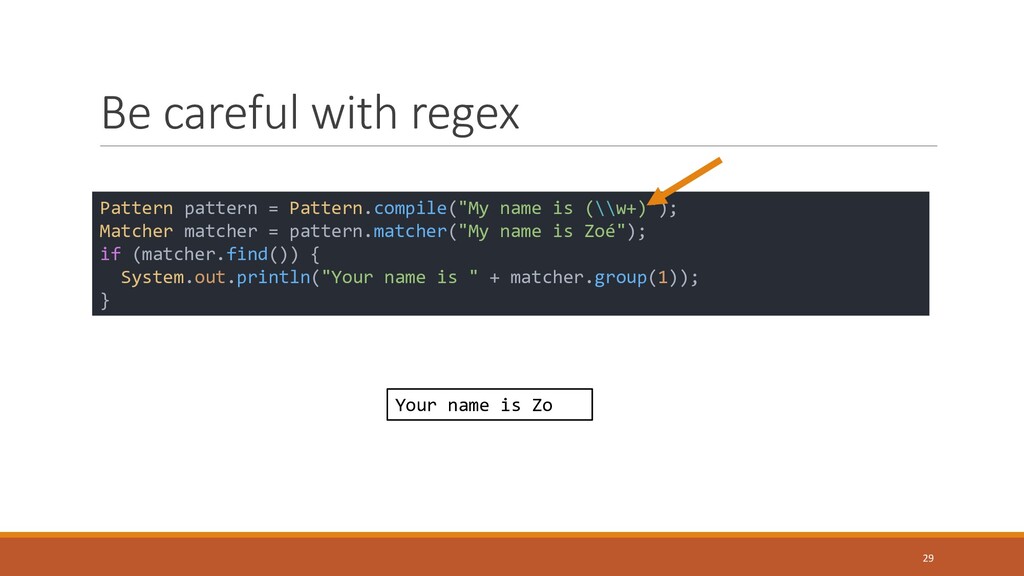{kind=link}
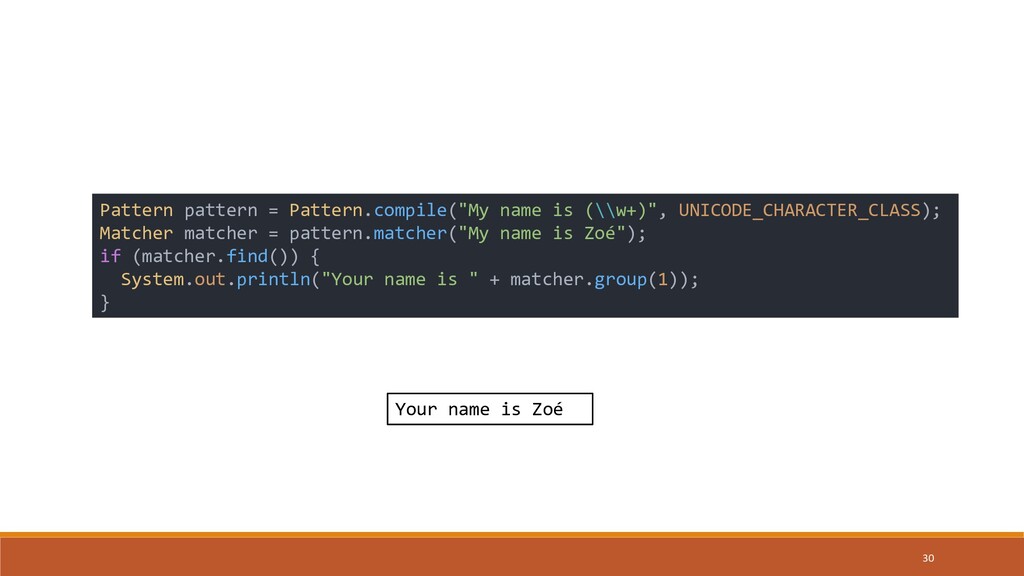{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}