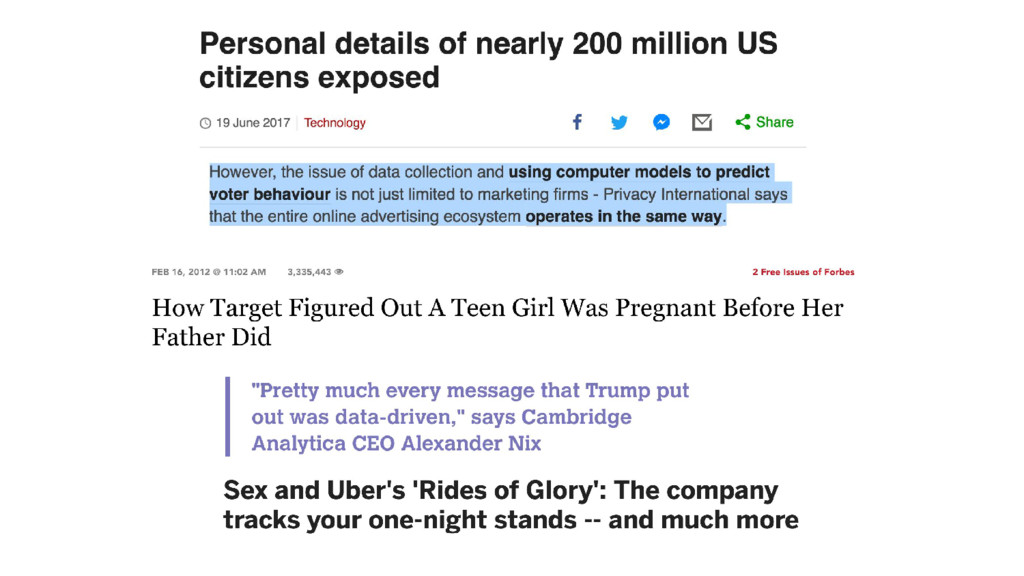
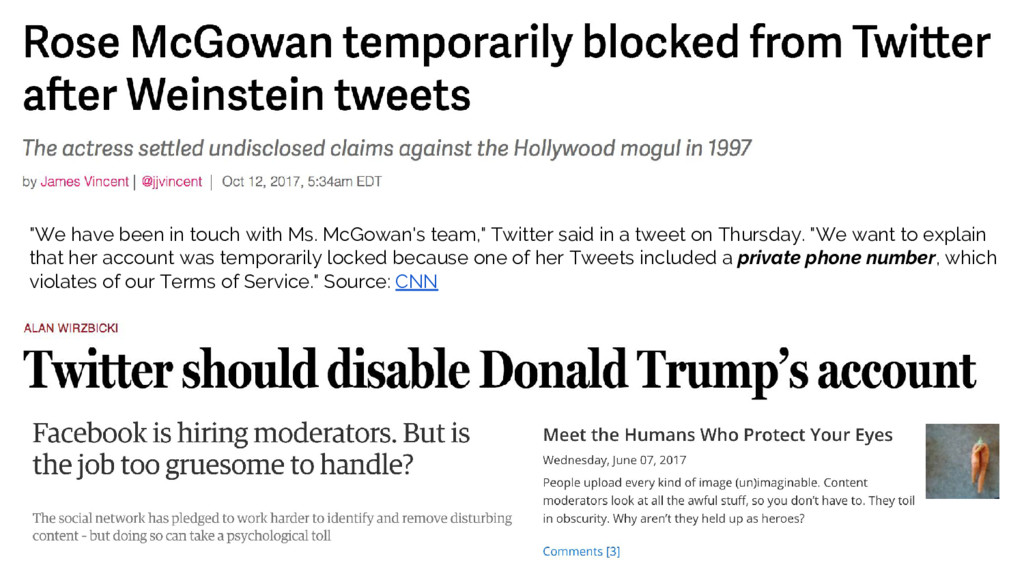
Your model is bias, but so is your data. The case for ethics in data science. Machine learning is increasingly used to make decisions for us as we rely more and more on applications and other technology in our daily life. Yet, what happens when the data we collect has bias? What does this do to our models? What can we do as technologists to challenge this? In this talk we review three case studies where ethical concerns are raised wrapping up with some steps to help you begin to build an ethical data practice at your organization.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
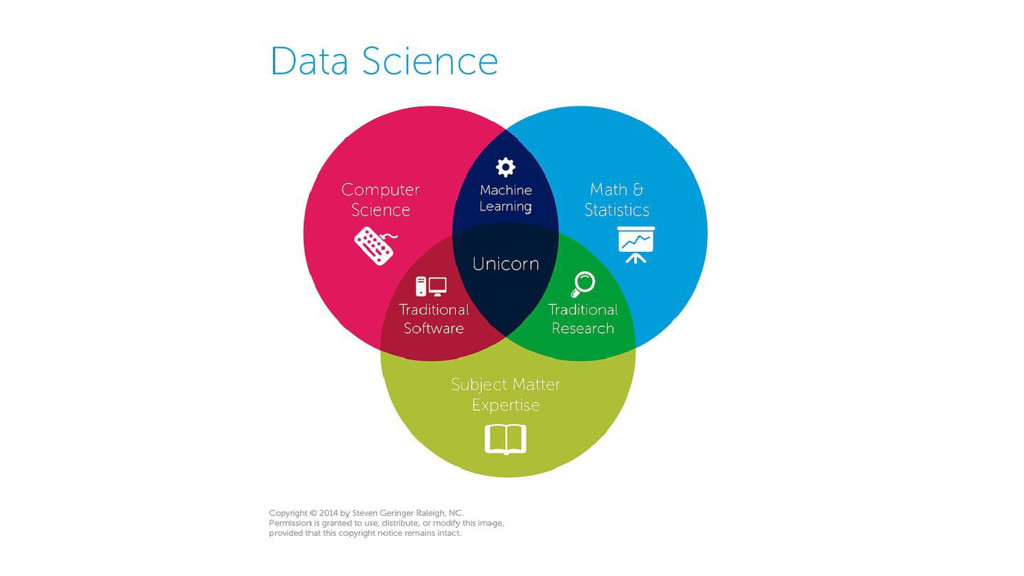
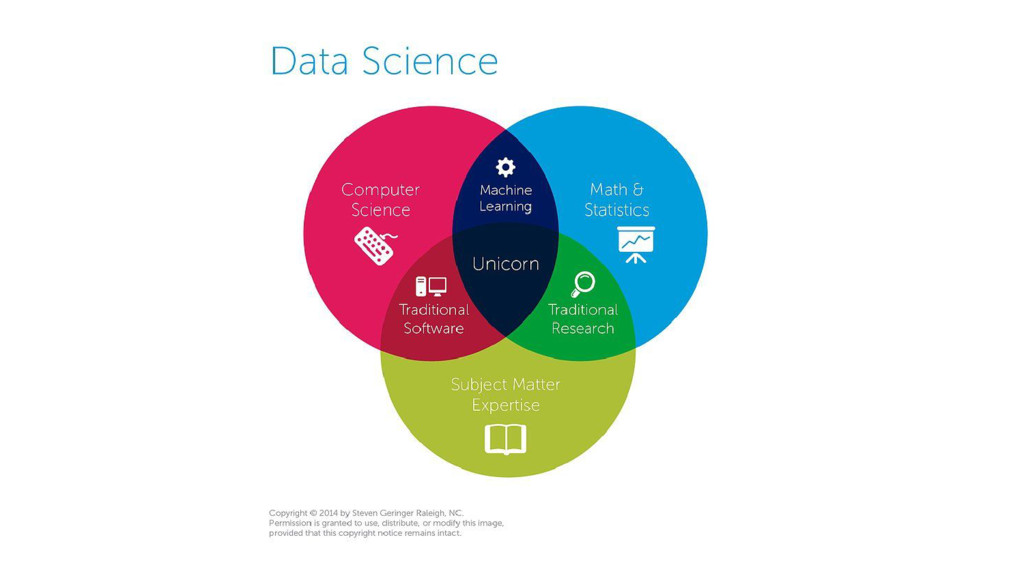
![Machine Learning is a subfield of computer science [that] stud[ies]](https://files.speakerdeck.com/presentations/254dde80be62436280d6730c565f16a0/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![“[Cyberbullying is] . . . the use of information and](https://files.speakerdeck.com/presentations/254dde80be62436280d6730c565f16a0/slide_21.jpg){kind=link}
{kind=link}
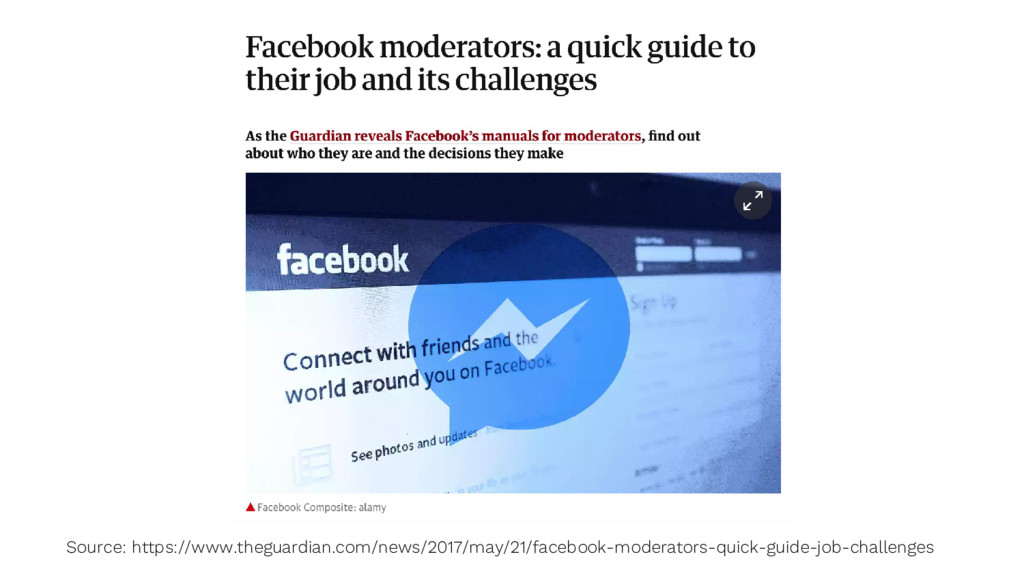{kind=link}
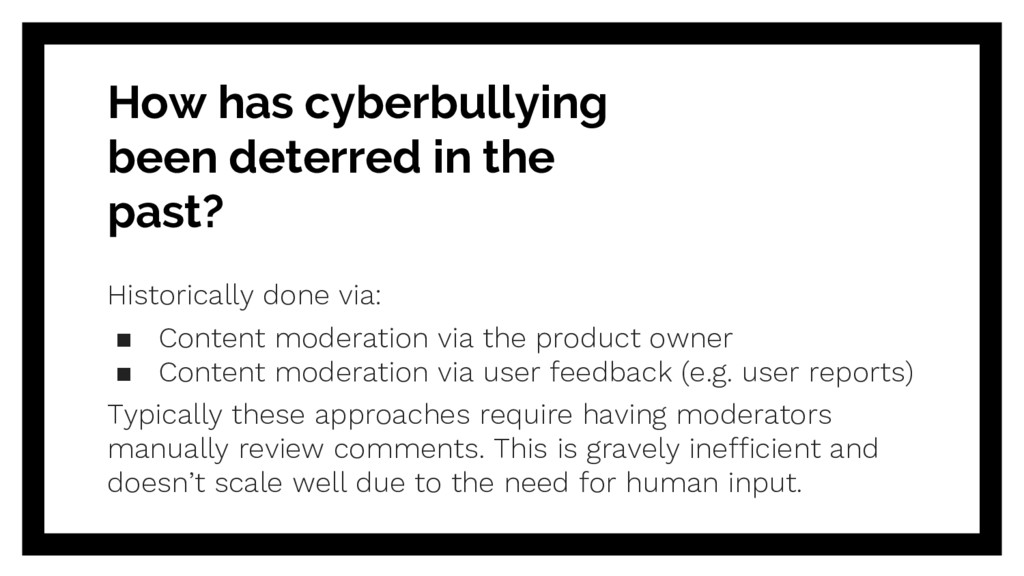{kind=link}
{kind=link}
{kind=link}
{kind=link}
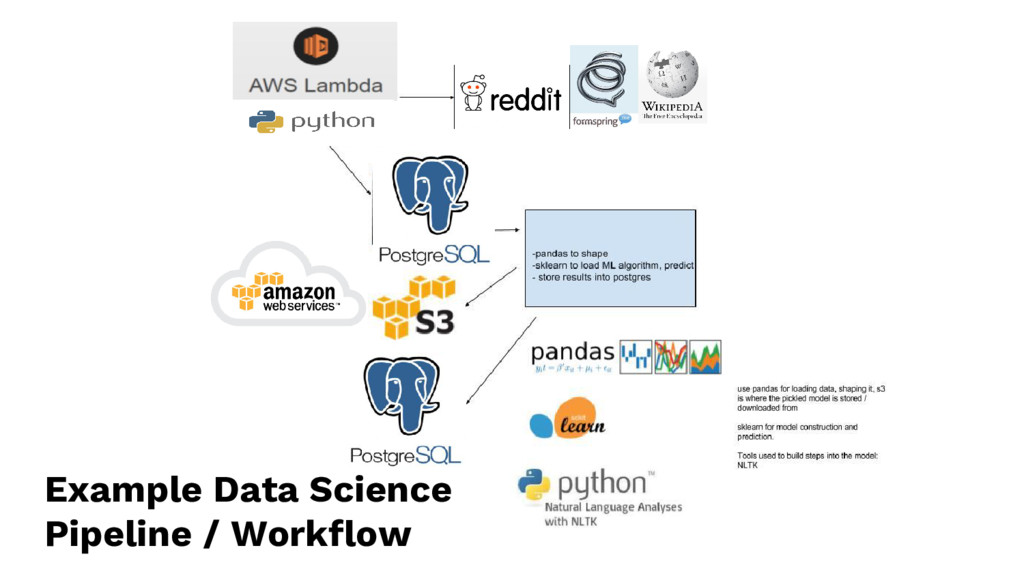{kind=link}
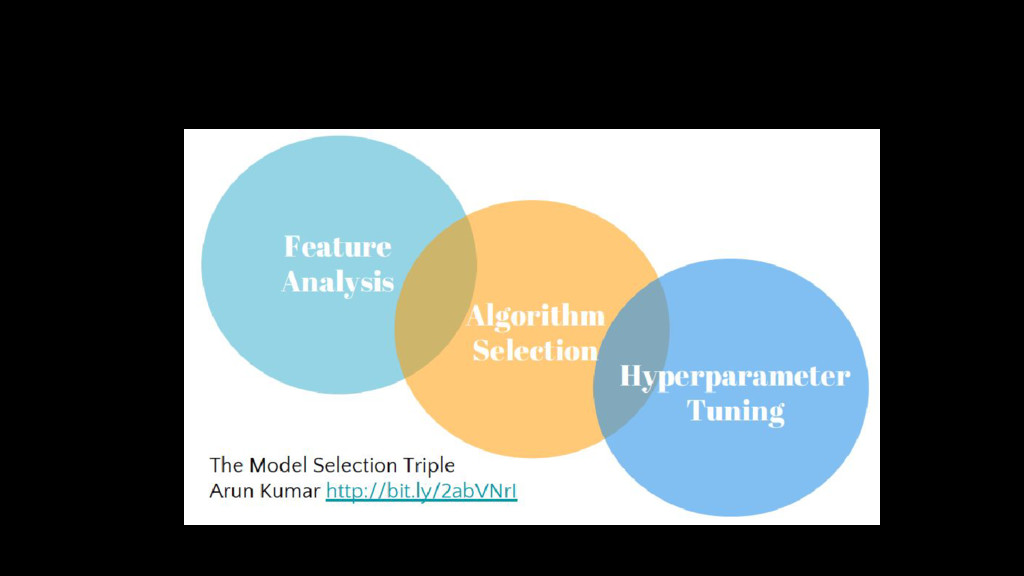{kind=link}
{kind=link}
{kind=link}
{kind=link}
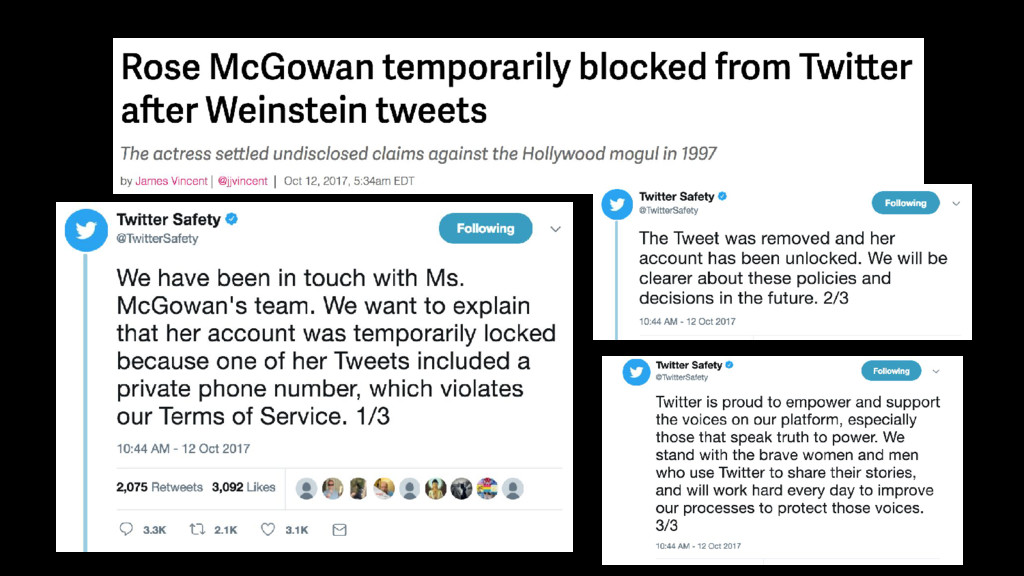{kind=link}
{kind=link}
{kind=link}
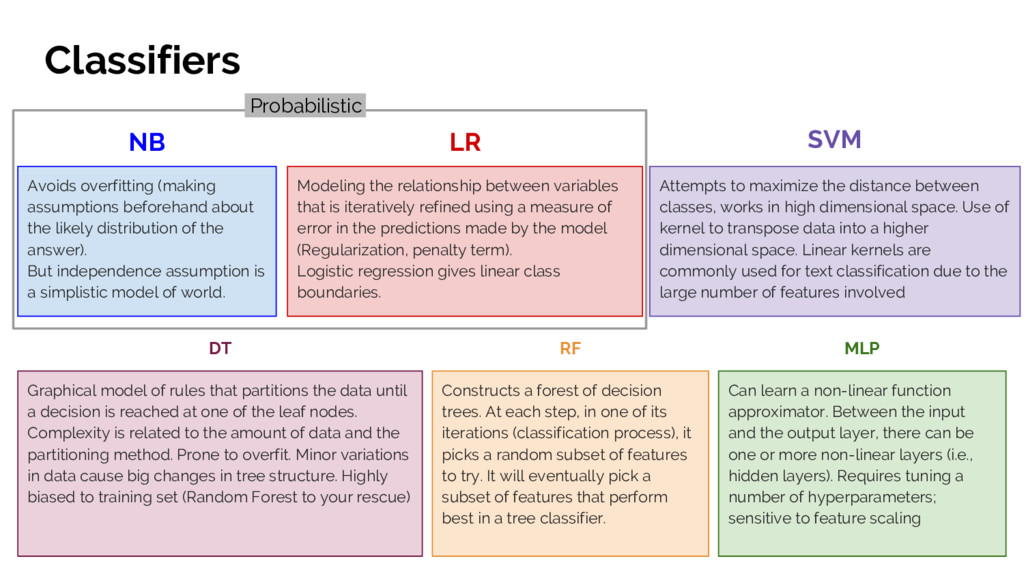{kind=link}
{kind=link}
{kind=link}
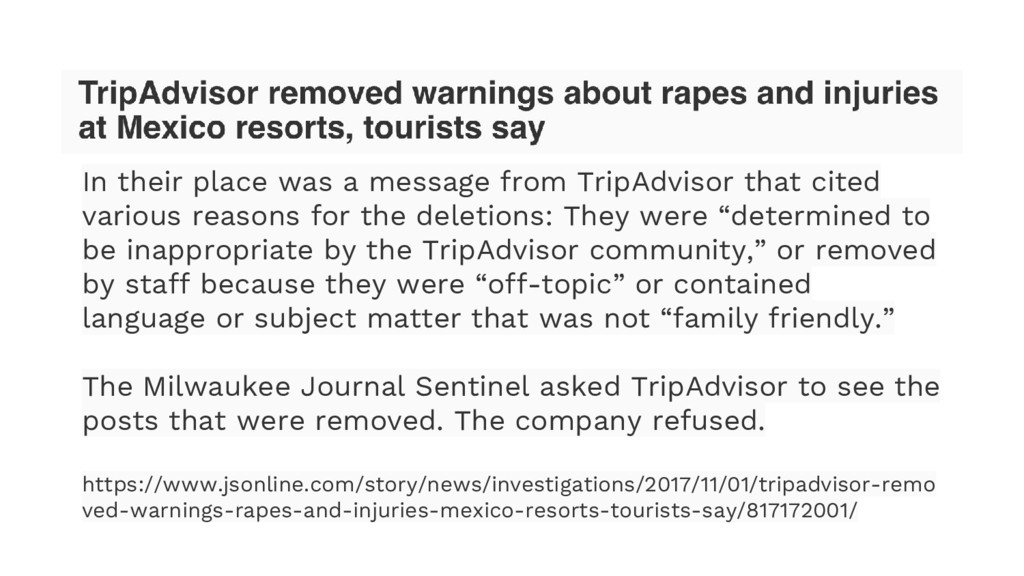{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
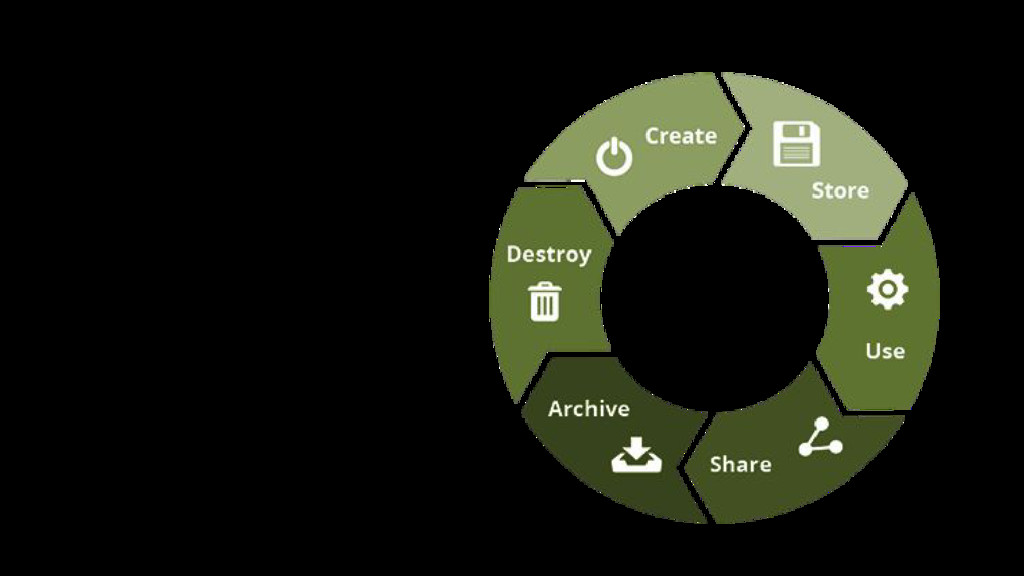{kind=link}
{kind=link}
{kind=link}
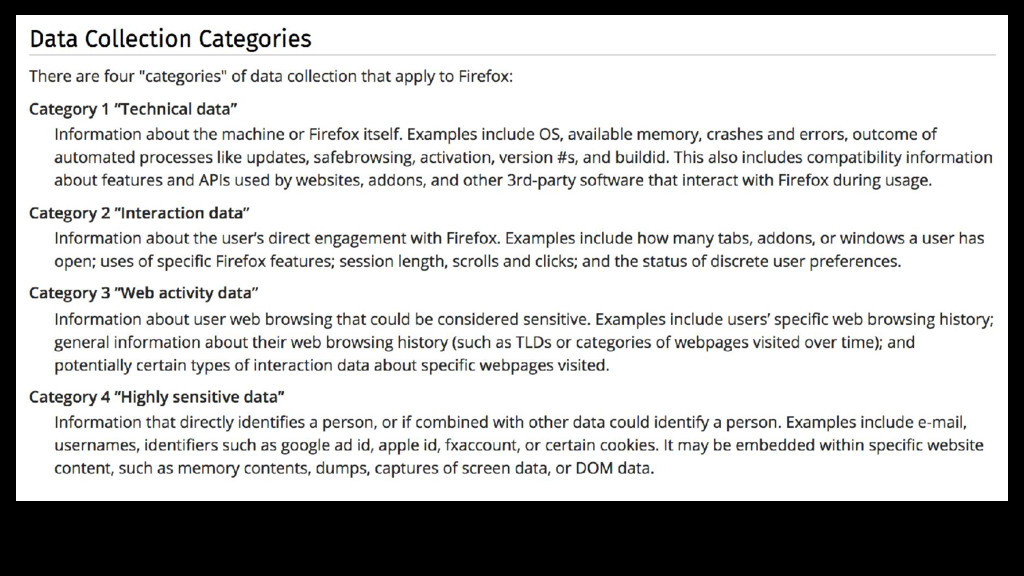{kind=link}
{kind=link}
{kind=link}
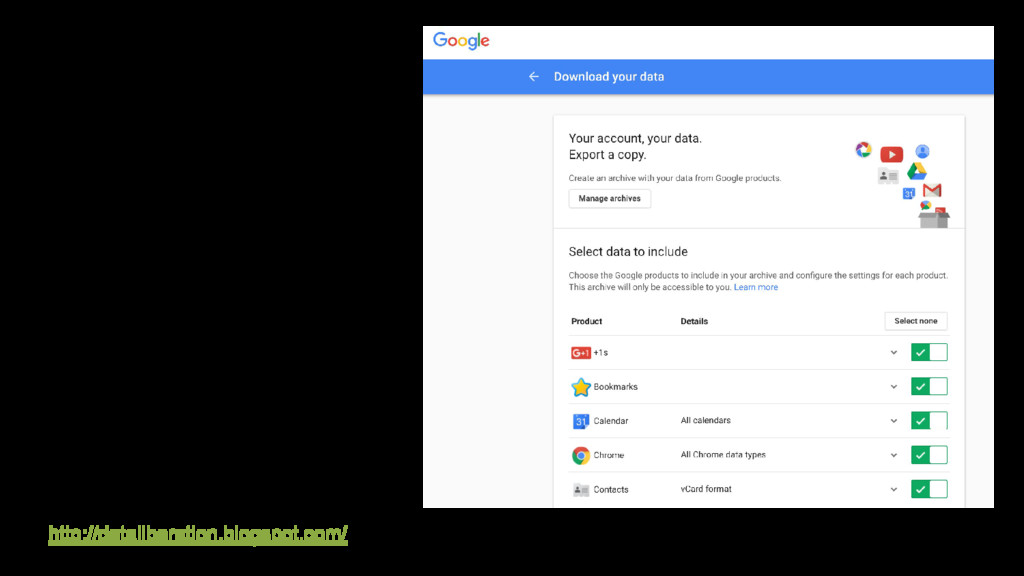{kind=link}
![Continue the conversation by learning more [TALK] Liz Rush, Write/Speak/Code](https://files.speakerdeck.com/presentations/254dde80be62436280d6730c565f16a0/slide_56.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}