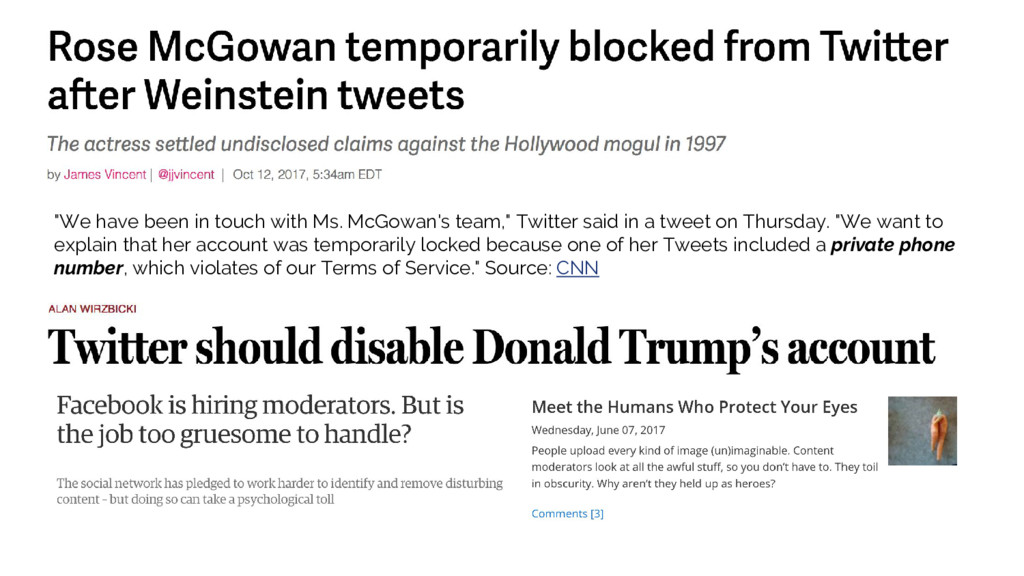
Cyberbullying is a very real threat for community users today, from
incidents like Gamer Gate to tragic incidents that target vulnerable
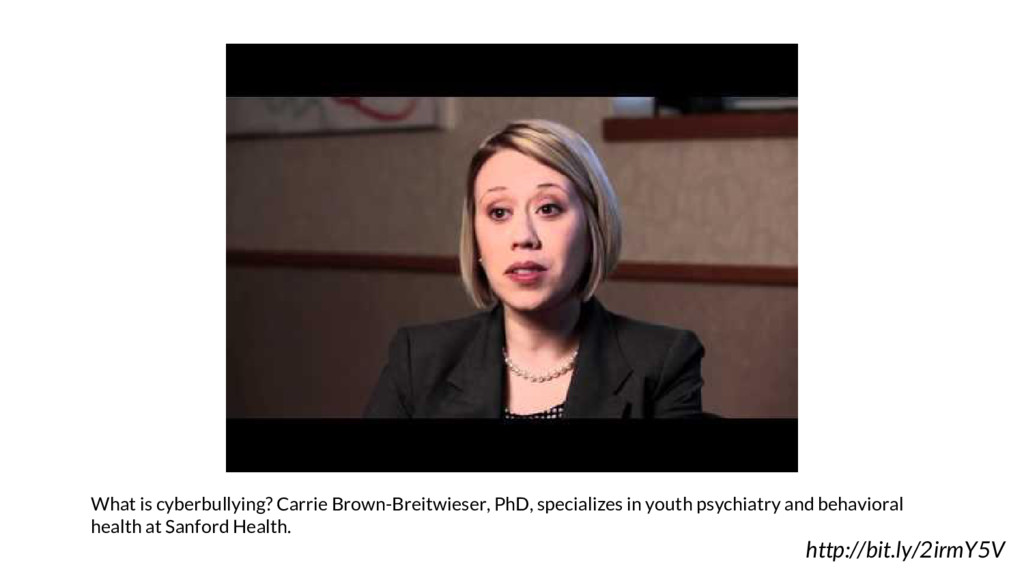
youth cyberbullying has become an increasing danger for online
communities. In this talk we'll frame cyberbullying as a machine
learning problem, using the Python scientific stack and natural
language learning to determine what, if any, insights can be made to
detect cyberbullying with it.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Machine Learning is a subfield of computer science [that] stud[ies]](https://files.speakerdeck.com/presentations/c2ffe0fe66074c04943f97fb2b6bb15c/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}