Reproducible results can be the bane of a data engineer or data scientist’s existence. Perhaps a data scientist prototyped a model some months ago, tabled the project, only to return to it today. It’s now when they notice the inaccurate or lack of documentation in the feature engineering process. No one wins in that scenario.
In this talk we’ll walk through how you can use Django to spin up a Docker container to handle the feature engineering required for a machine learning project and spit out a pickled model. From the version controlled Docker container we can version our models, store them as needed and use scikit-learn to generate predictions moving forward. Django will allow us to easily bootstrap a machine learning project removing the downtown required to setup a project and permit us to move quickly to having a model ready for exploration and ultimately production.
Machine learning done a bit easier? Yes please!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Machine Learning http://bit.ly/2s5R01V is a subfield of computer science [that]](https://files.speakerdeck.com/presentations/5f0813c5ec5c44549c81e3fd677864cd/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
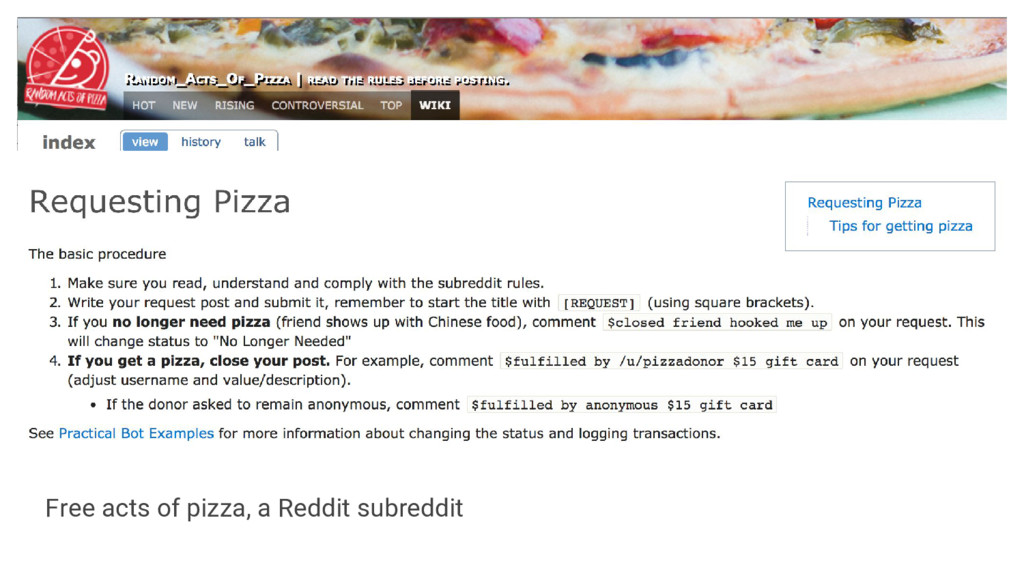{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
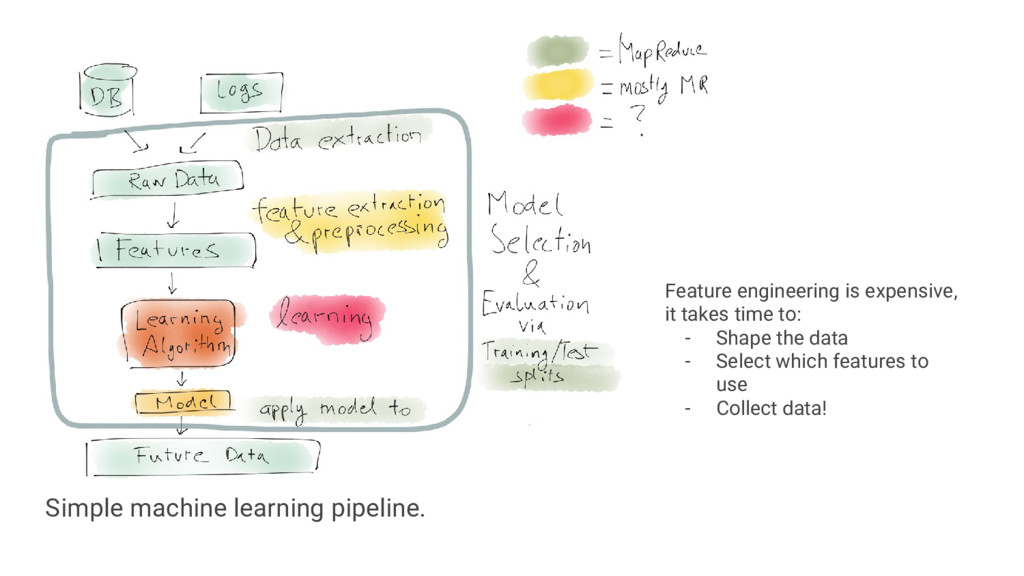{kind=link}
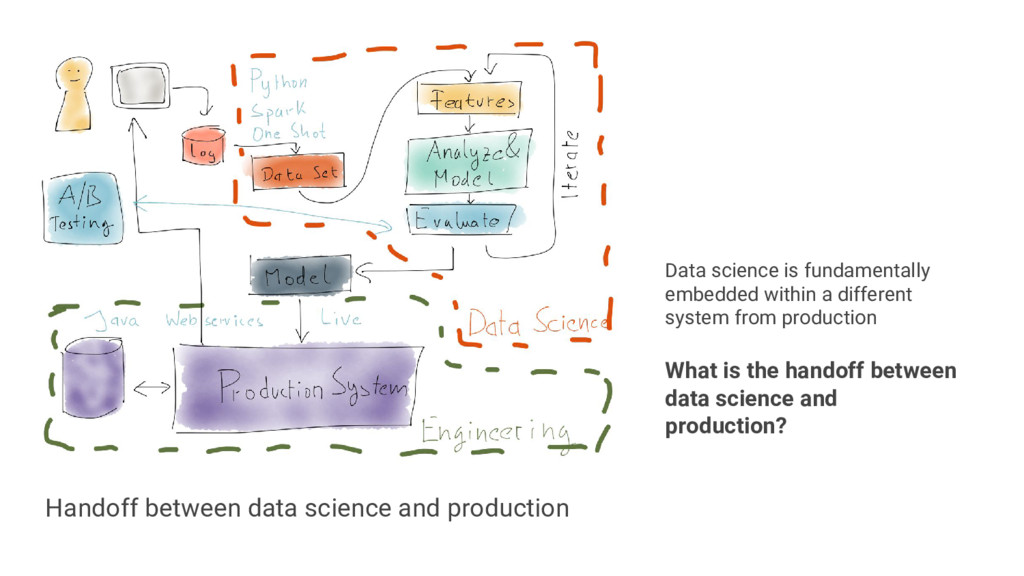{kind=link}
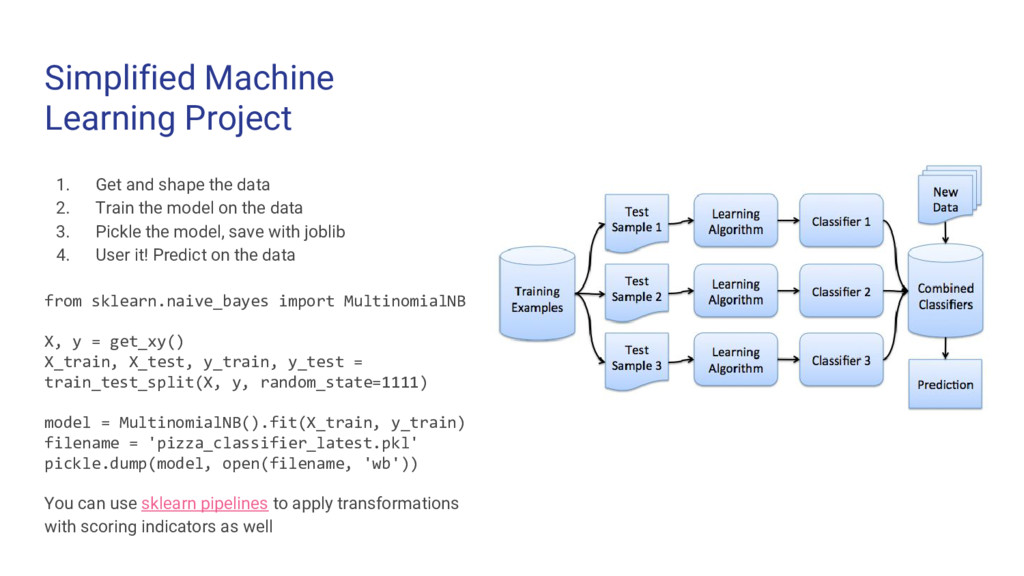{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}