Short introduction to the key concepts of monitoring at scale.
Lightning talk for dotScale 2016. http://dotscale.io
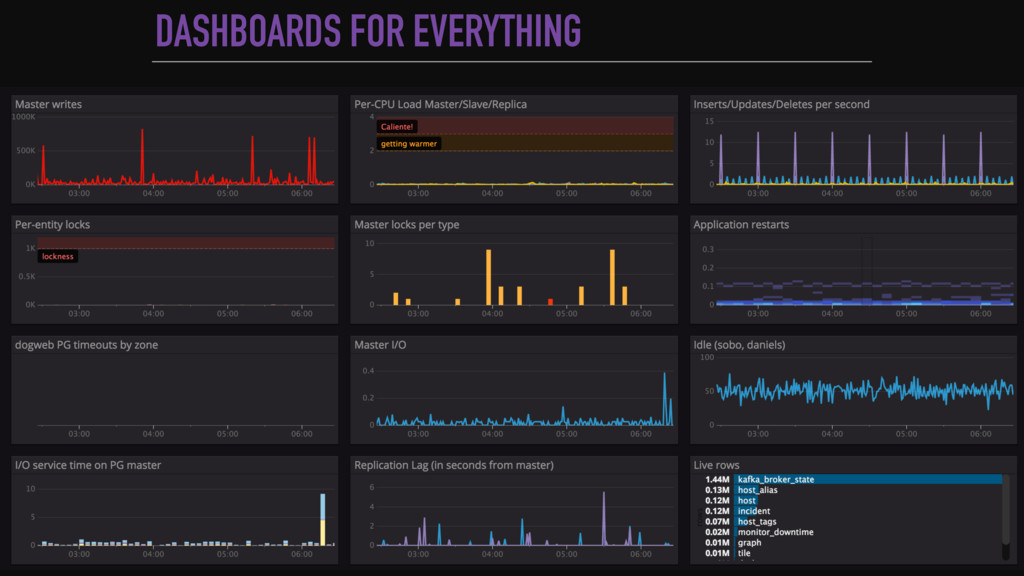
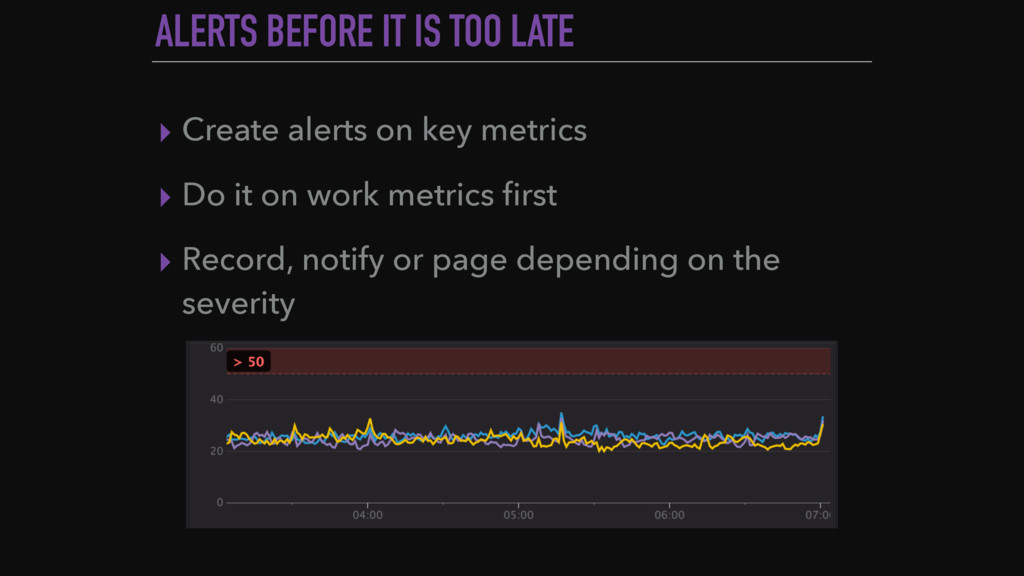
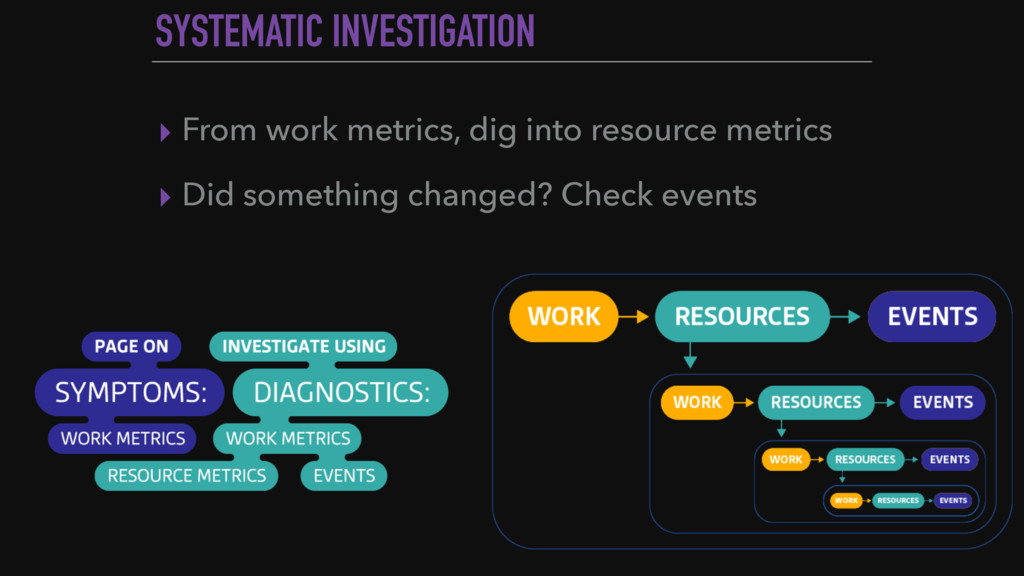
System monitoring is a wide topic, with hundred ways of doing it and tons of metrics to look at. Look at a growing web-application to illustrate the important monitoring concepts. Present what to look at first, how to exploit the data and what are the good practices at large scale.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
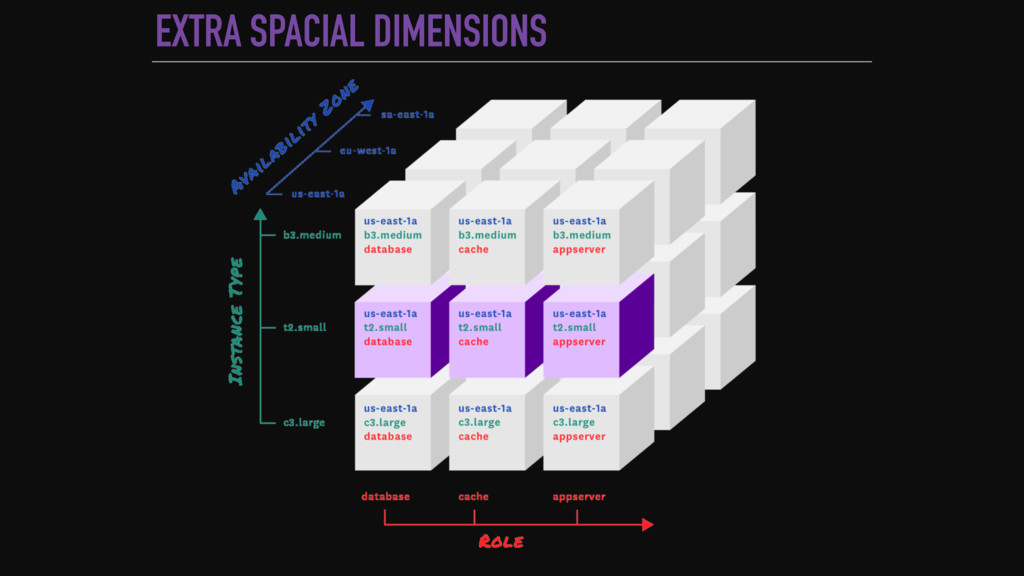{kind=link}
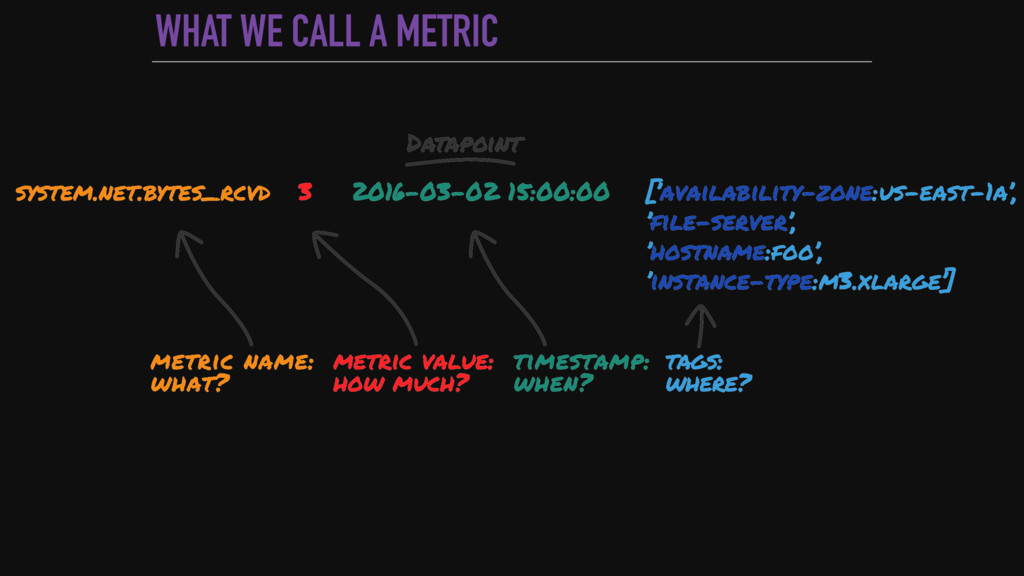{kind=link}
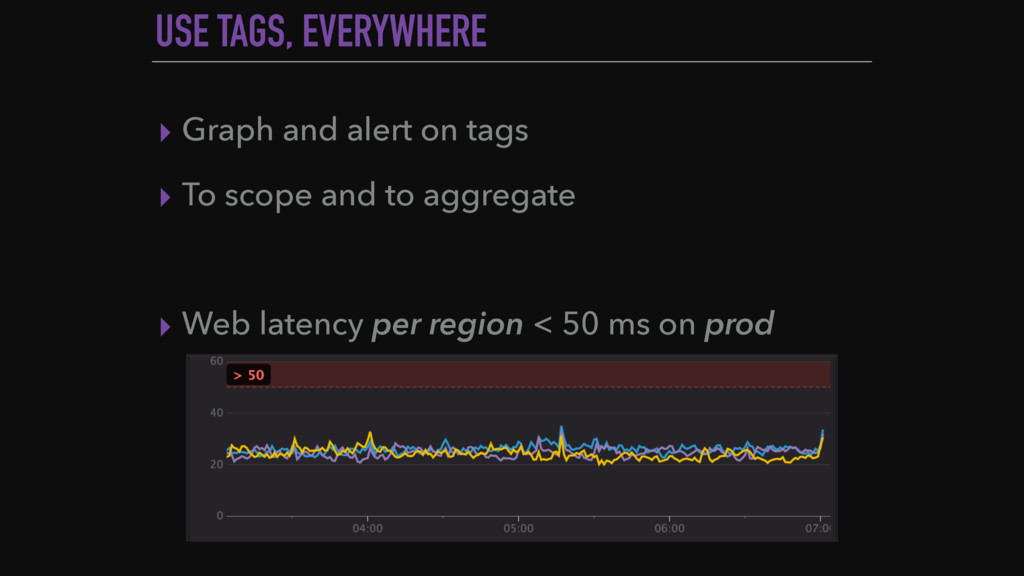{kind=link}
{kind=link}
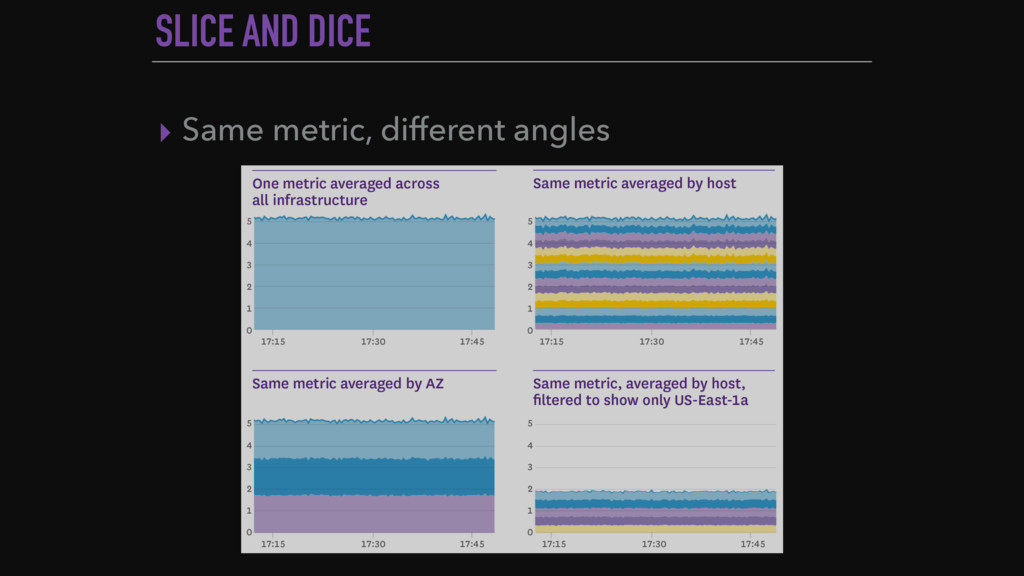{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}