1 stage de 6 mois chez Dailymotion • Mise en place d’une infrastructure de tests • 1 stage de 6 mois chez Novapost puis 9 mois • Automatisation de l’infrastructure
(== plus grosses machines). • Modèle de réplication master - slave quand disponible sur les solutions open-source. • Des plugins disponibles au-dessus des solutions, mais pas de solutions intégrées. • Difficulté de mise à l’échelle de la capacité d’écriture et la perte du master est souvent problématique.
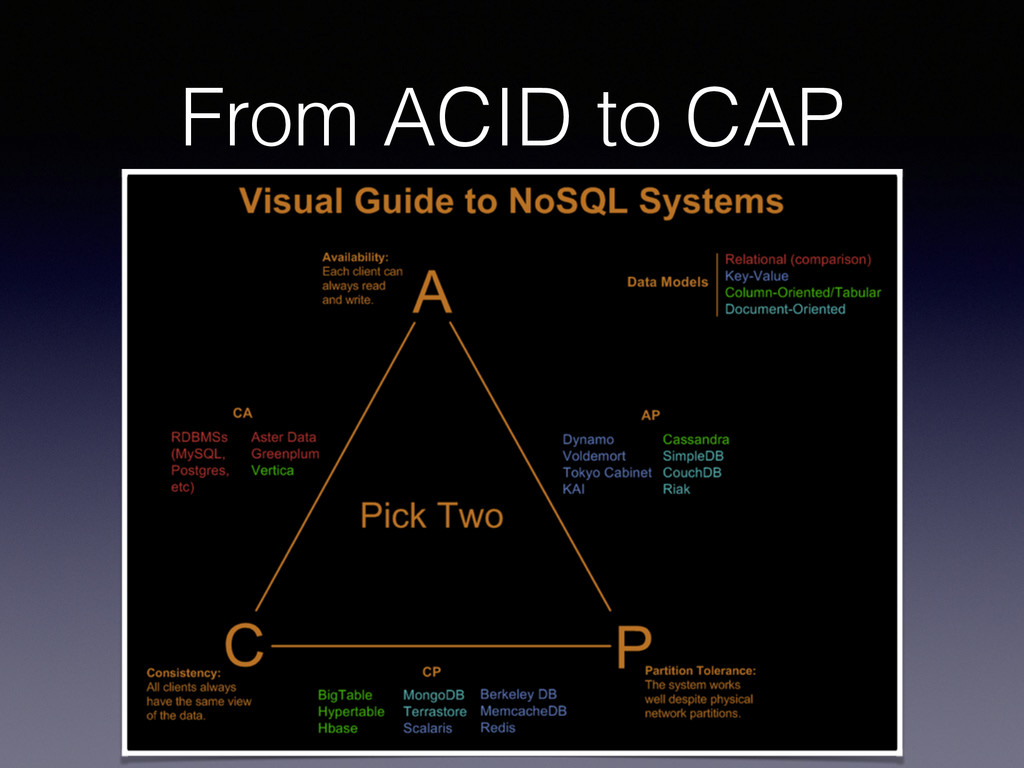
du tout. • Consistent – Une transaction ne peut rompre les contraintes d’intégrité de la base, qu’elle soit en succès ou non. • Isolated – Les résultats d’une transaction ne sont pas visibles tant que la transaction n’est pas terminée. • Durable – Le résultat des transactions en succès survivent à une panne ou à une transaction en échec.
• Meilleures performances. • Meilleure scalabilité horizontale. • Sacrifie la consistance (la valeur n’est pas toujours la dernière disponible). • Schema-less. • Plus dev-friendly.
et on récupère les résultats. • Requête en JSON-like. • SQL-Like. • Langage dédie (Cypher). • Map / Reduce, méthode de traitement de masse des données. • Materialized Map / Reduce.
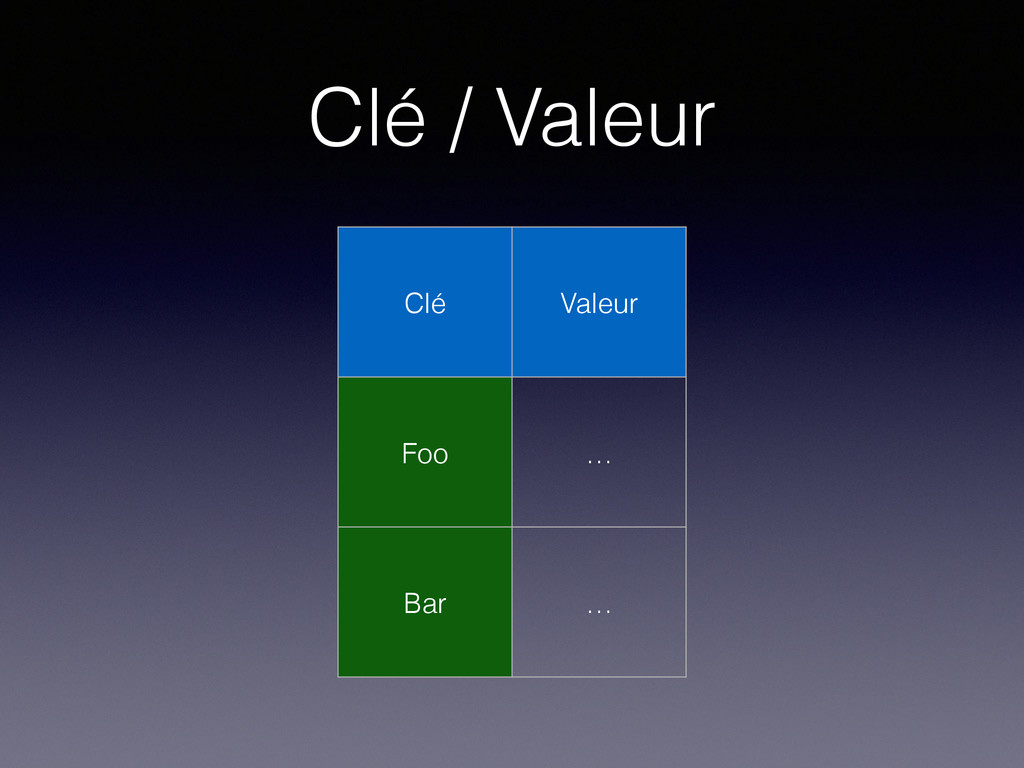
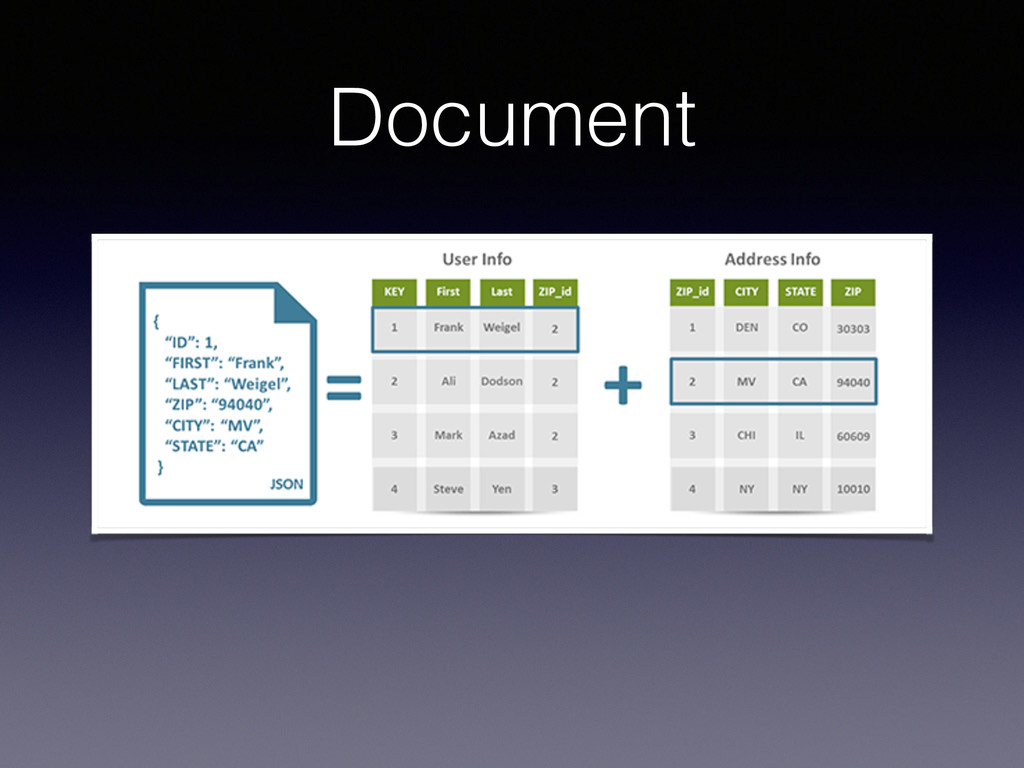
de données peut être implémentée au-dessus d’une base de données clé / valeur. • La valeur est arbitraire, soit un contenu binaire (string) soit un contenu plus structuré. • Très bonnes performances.
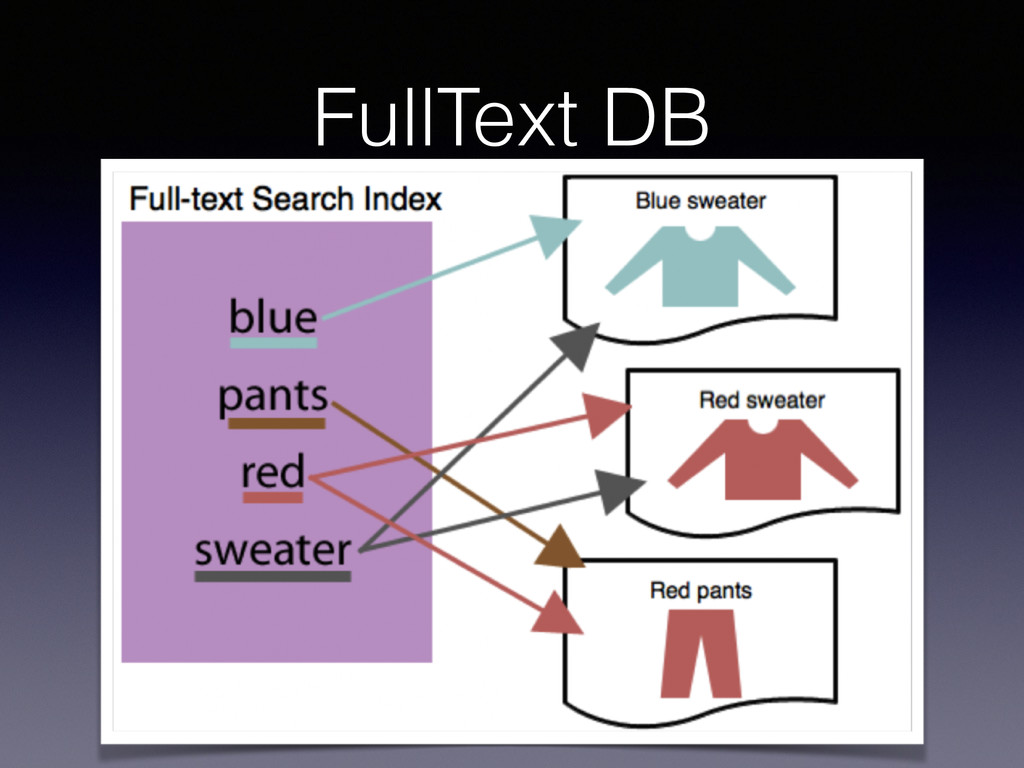
et l’une des bases de données NoSQL la plus connue. • Possibilité d’indexation secondaires. • Moteur d’agrégation plus simple que Map / Reduce. • Support de recherches Full-Text
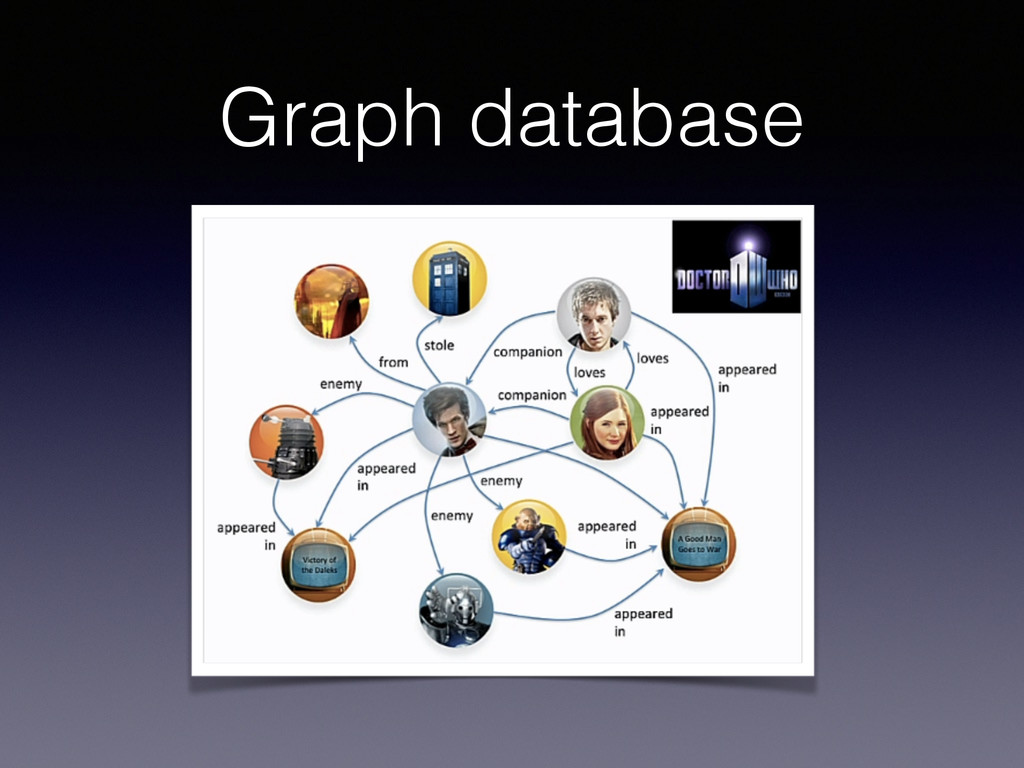
modèle orienté graphe. • Peu ou pas de besoin de design du schéma, le schéma s’enrichit avec les nouveaux liens. • Bonne performance pour les requêtes orientées graphes sur un grand nombre de nœuds.
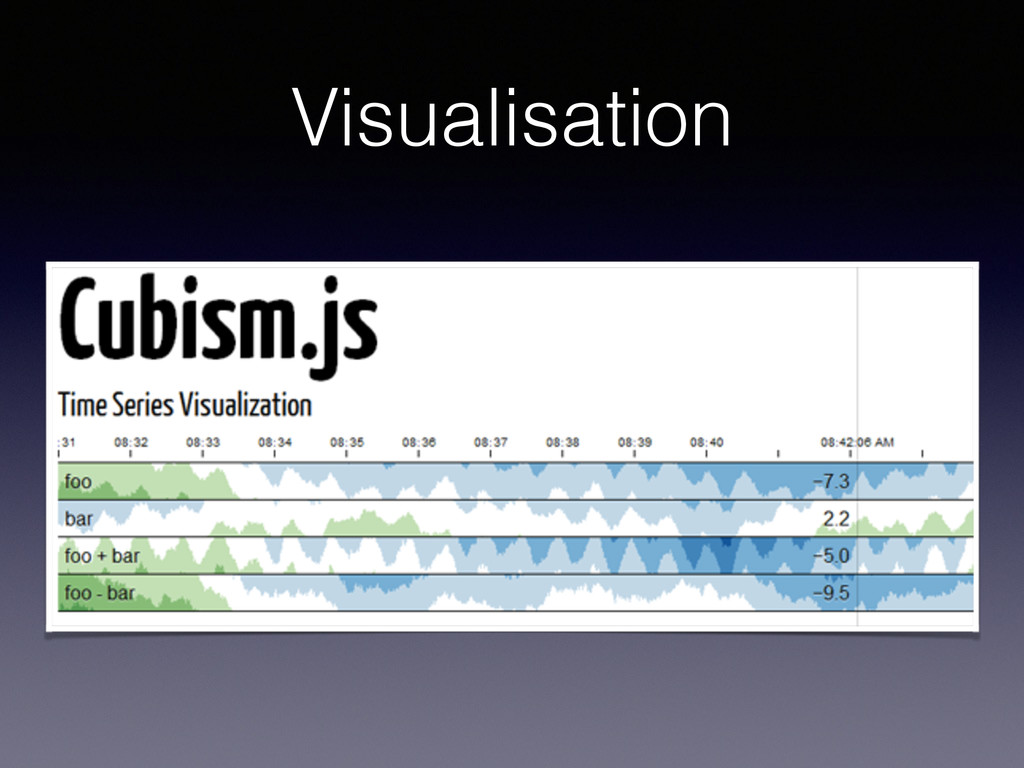
Somme des visiteurs sur telle page de mon site sur le dernier mois. • Moyenne de la charge des serveurs agrégé par serveur sur la dernière semaine par période de 5 minutes.
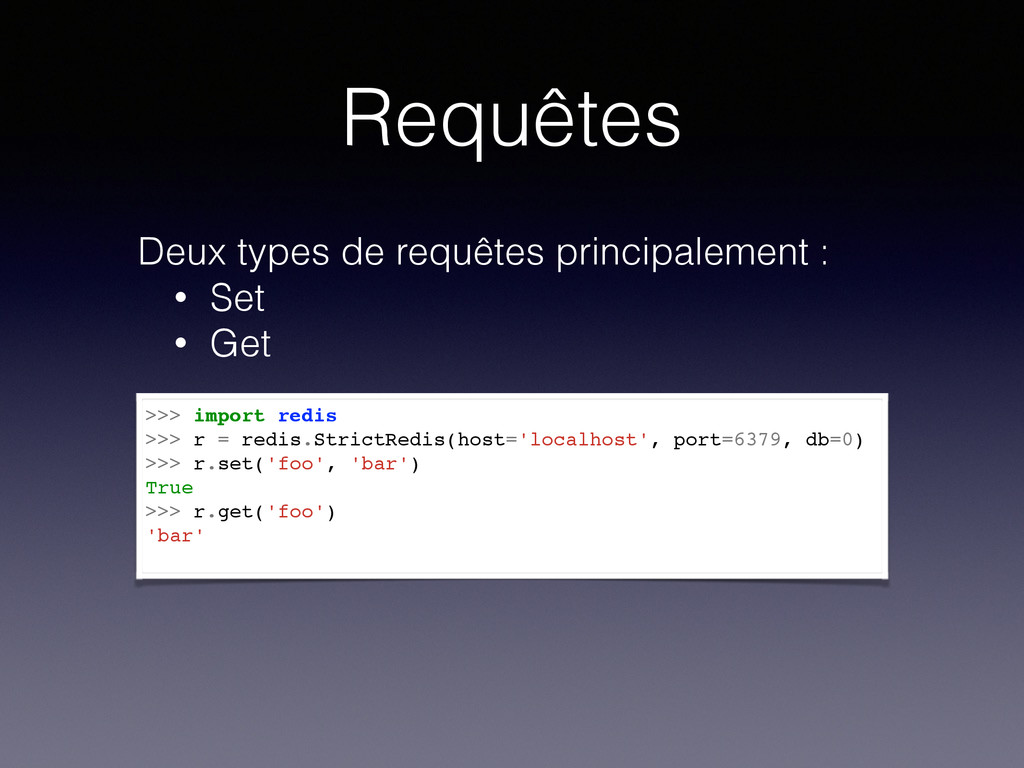
avancé (MongoDB) ou non (Redis). • Permet de scanner l’ensemble des éléments ou non même sans index. • Nécessite de préparer les requêtes à l’avance ou non.
de données crée par Google. • Recherche en deux étapes : • On extrait les données utiles ou on les calcule à partir des données brutes (Map). • Puis on les fusionne et on les trie (Reduce). • L’opération de Map est du coup facilement parallélisable, l’opération de Reduce un peu moins.
nœuds égaux. • Replication • On recopie les données entre plusieurs nœuds égaux. • Master-Slave • On recopie les données entre un maître et un slave, réplication uni-directionnelle.
plus difficile que le choix d’une solution SQL. • Comment votre schéma va s’adapter. • Quelles sont vos contraintes métiers ? • Le temps développeur vous coûtera toujours plus cher.
pour les requêtes. • CouchDB: préparer les requêtes, pas possible ou difficile d’en ajouter à postériori. • Au besoin, dupliquer la donnée et la démoraliser pour améliorer les requêtes.
peuvent vous suffire, le NoSQL n’est pas une solution magique. • Dans le cas contraire, les bases NoSQL peuvent vous aider • Mais c’est un choix qui doit être bien réfléchi, RTFM !
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Requête >>> import memcache >>> mc = memcache.Client(['127.0.0.1:11211']) >>> mc.set("foo",](https://files.speakerdeck.com/presentations/b494c79a9919456d95ea914593c20b3a/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Requêtes MATCH (charlie:Person { name:'Charlie Sheen' })-[:ACTED_IN]- (movie:Movie) RETURN movie](https://files.speakerdeck.com/presentations/b494c79a9919456d95ea914593c20b3a/slide_39.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}