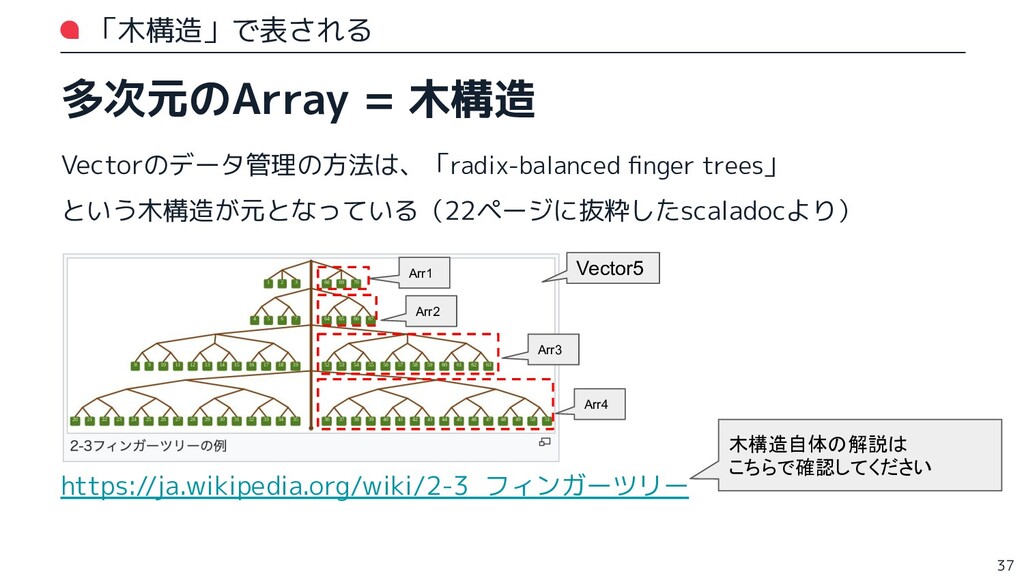
trees of width 32. > There is a separate subclass for each level (0 to 6, with 0 being the > empty vector and 6 a tree with a maximum width of 64 at the top level). Vectorは,幅32の基数平衡フィンガーツリー(訳あやしい)によって実装されま す。各レベルに個別のサブクラスがあります(0 から 6 まであり、0 は空のVector で、6 は最上位レベルの最大幅 64 の木です)。 大事そうなところに下線を引いてみましたが、何のこっちゃわからん・・・ 22
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
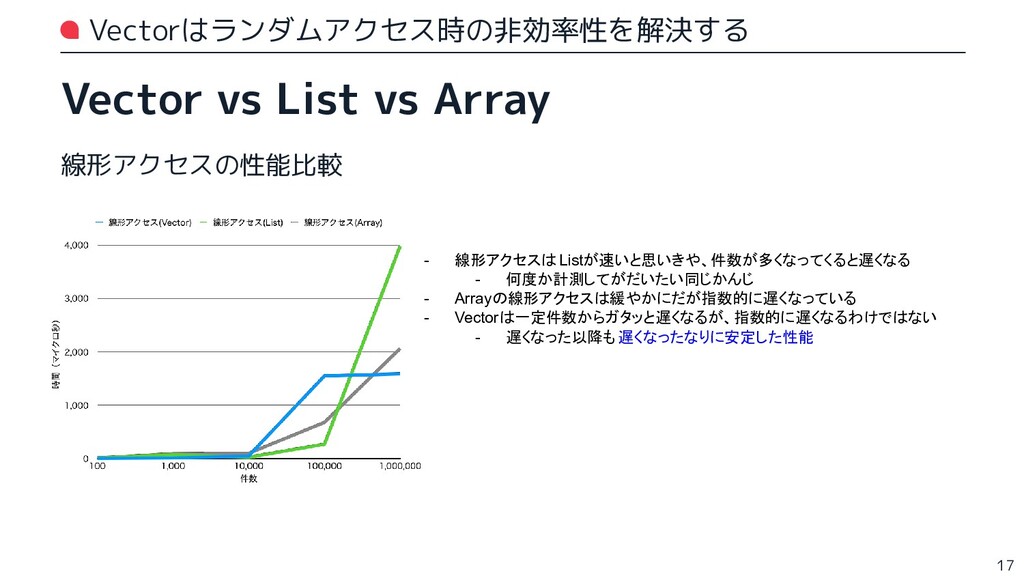{kind=link}
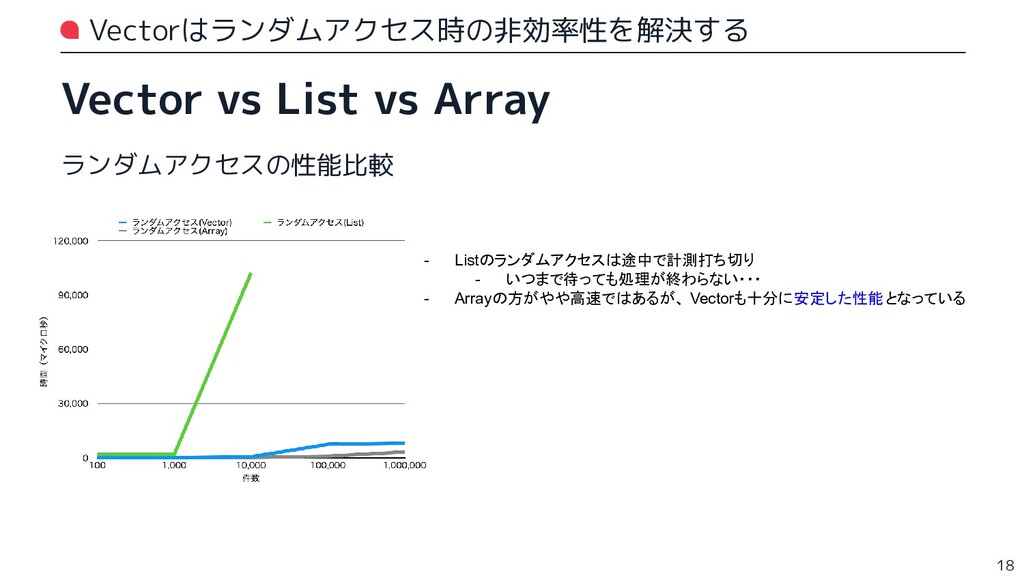{kind=link}
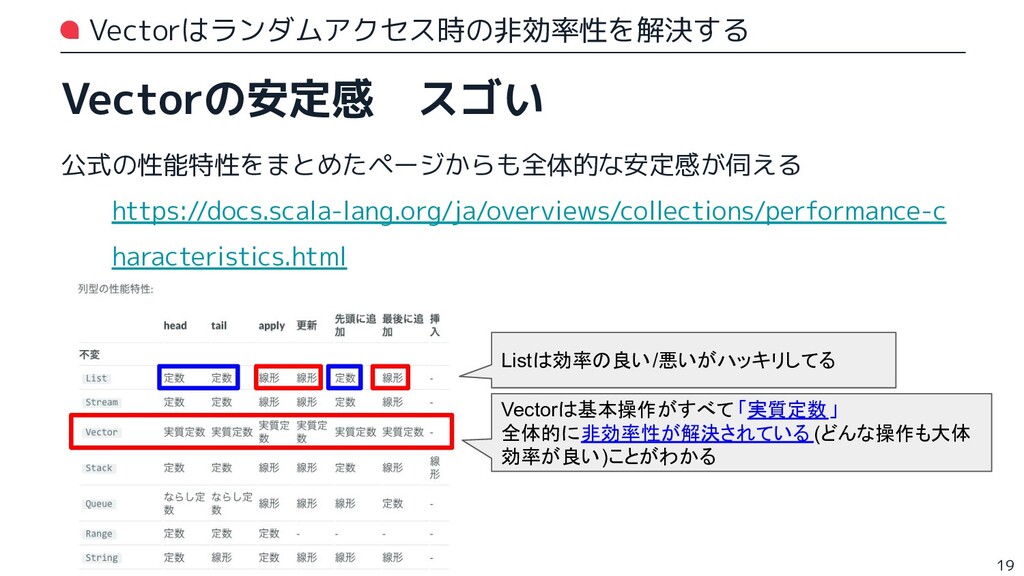{kind=link}
{kind=link}
{kind=link}
{kind=link}
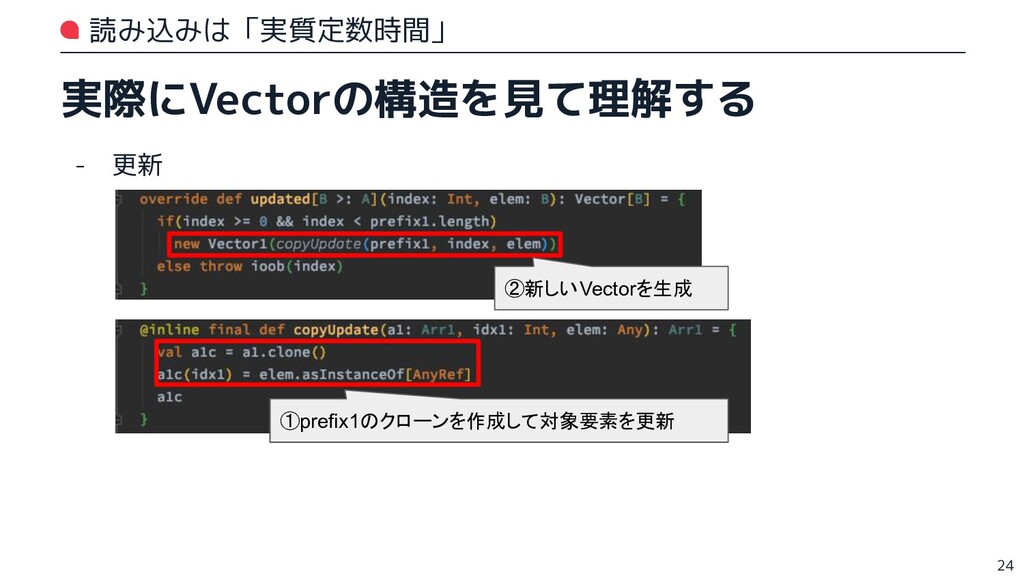
![読み込みは「実質定数時間」 実際にVectorの構造を見て理解する scaladocにあったようにVector0〜Vector6というサブクラスを発見! 一番シンプルそうなVector1を見てみる - apply 23 ③Array[AnyRef]の要素番号を指定して取得している (実質Arrayのランダムアクセスと同じ処理 )](https://files.speakerdeck.com/presentations/5c1332c72bfd4b66b70c8185d6518b28/slide_22.jpg){kind=link}
{kind=link}
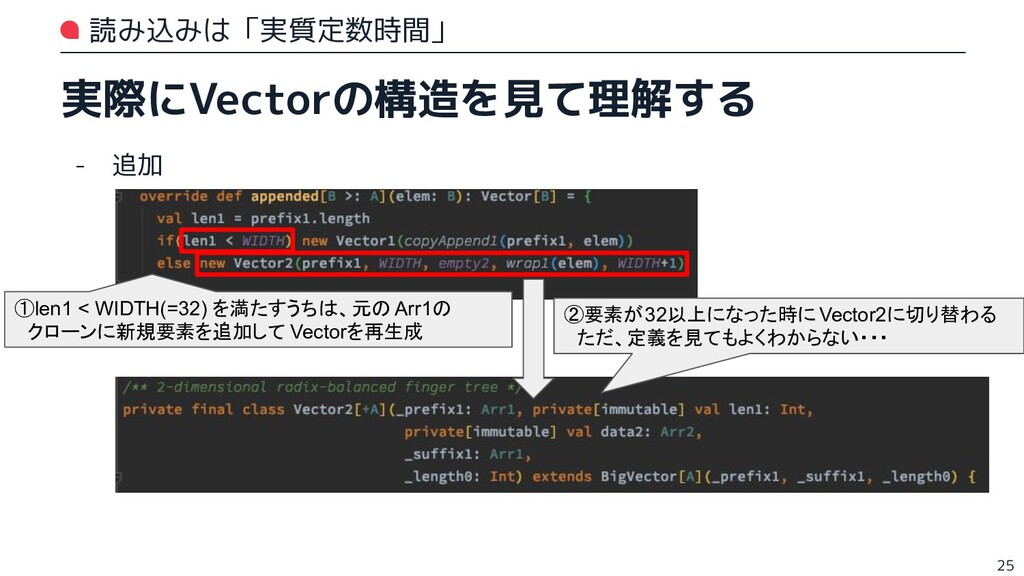{kind=link}
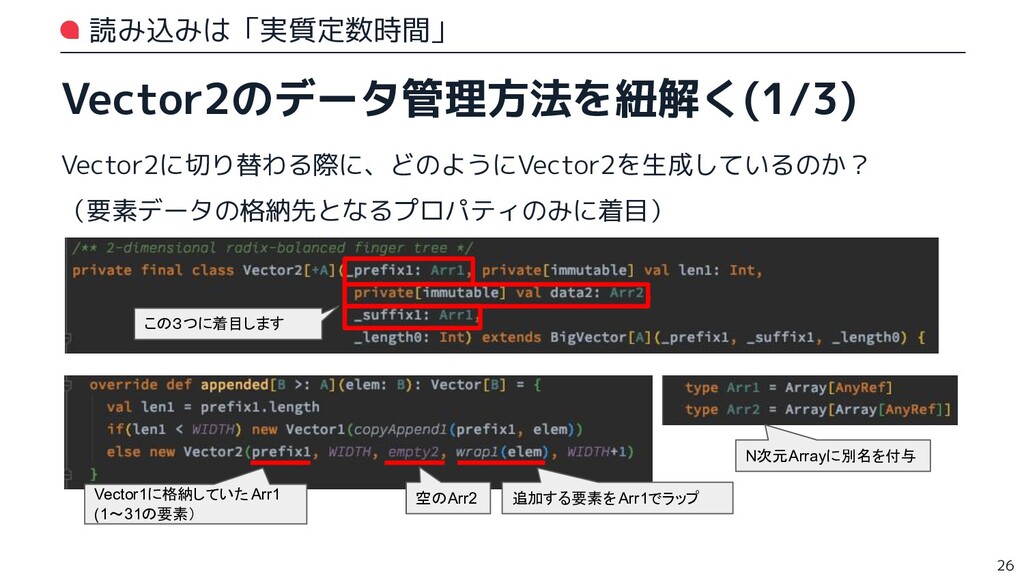{kind=link}
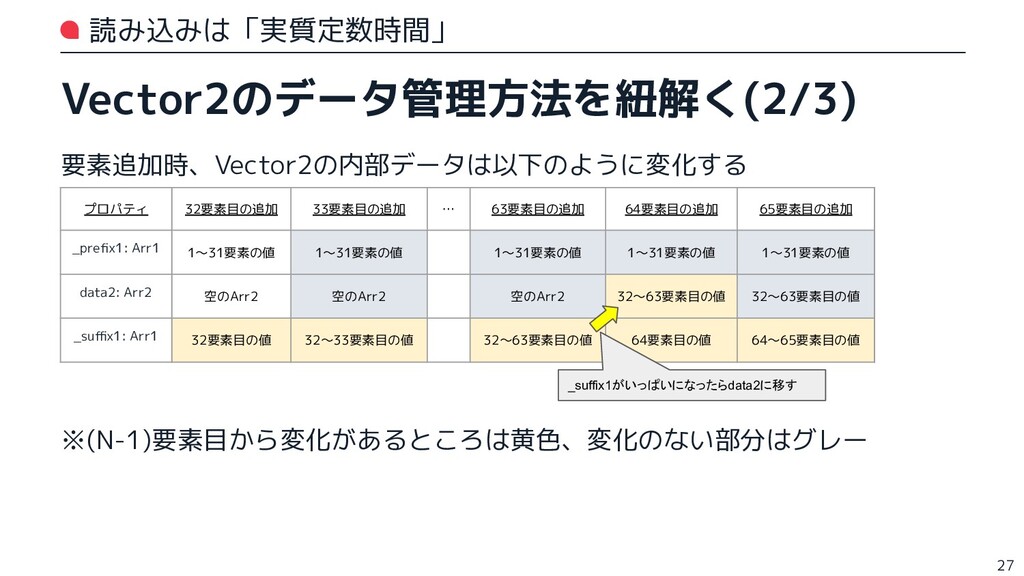{kind=link}
{kind=link}
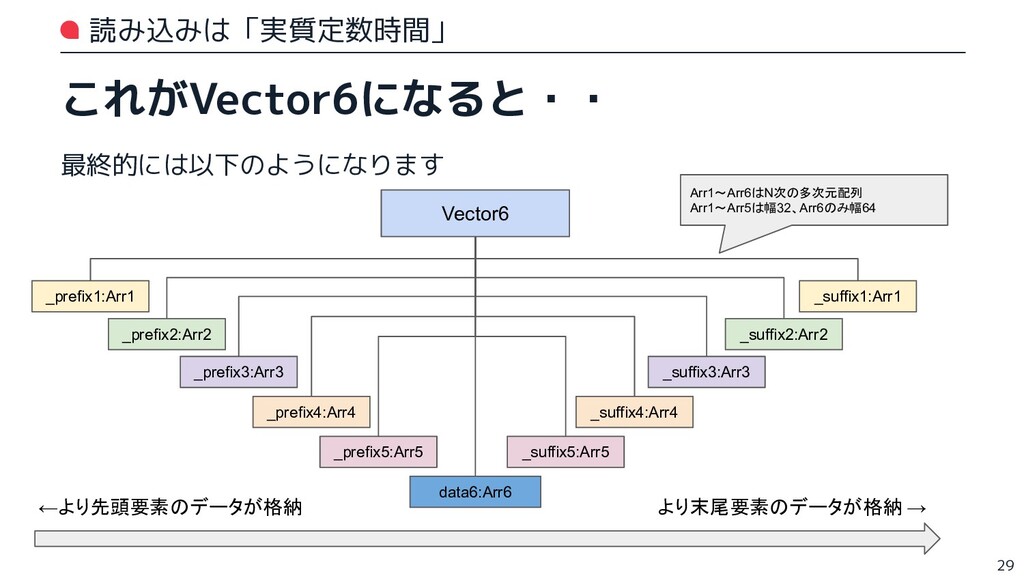{kind=link}
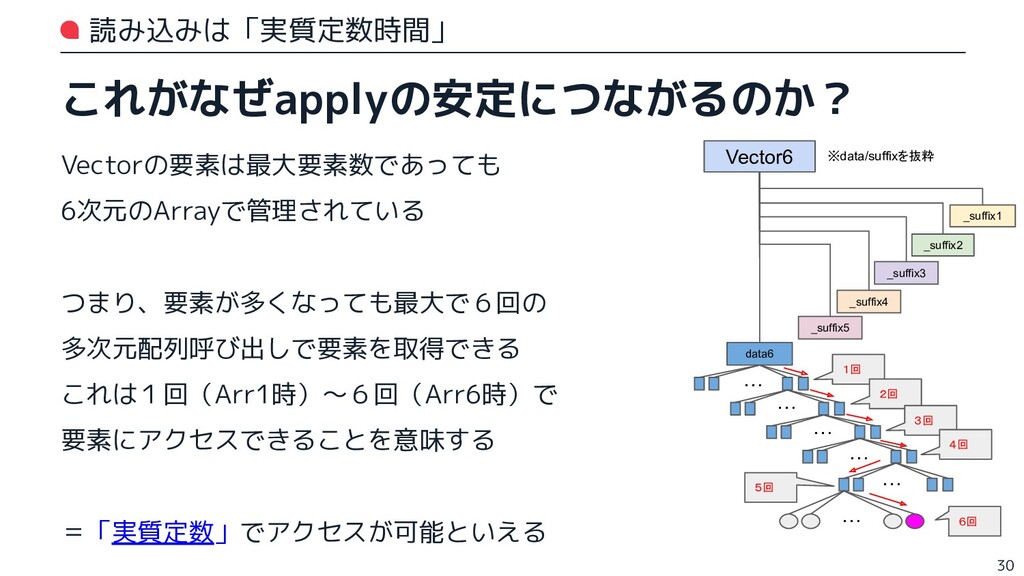{kind=link}
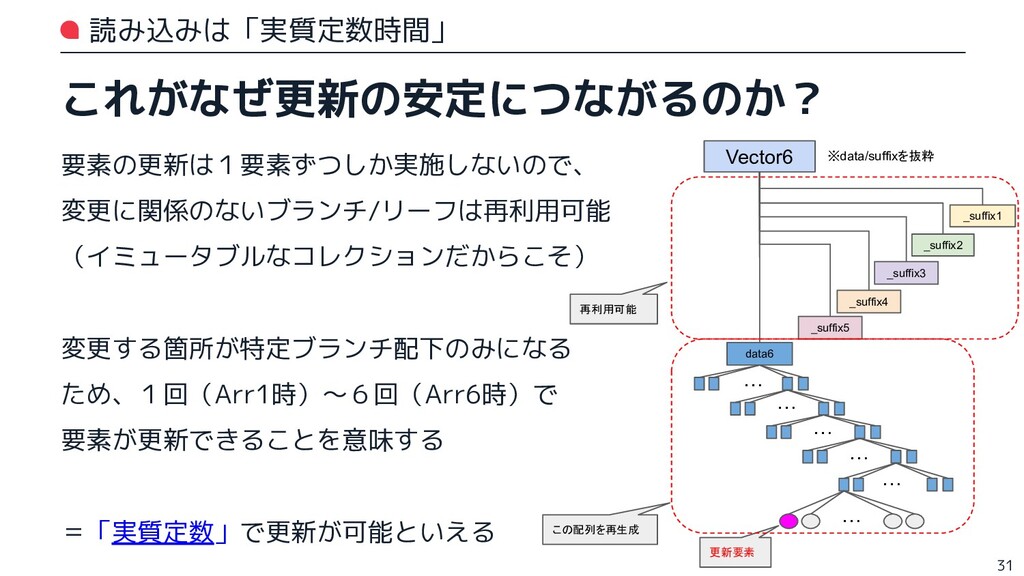{kind=link}
{kind=link}
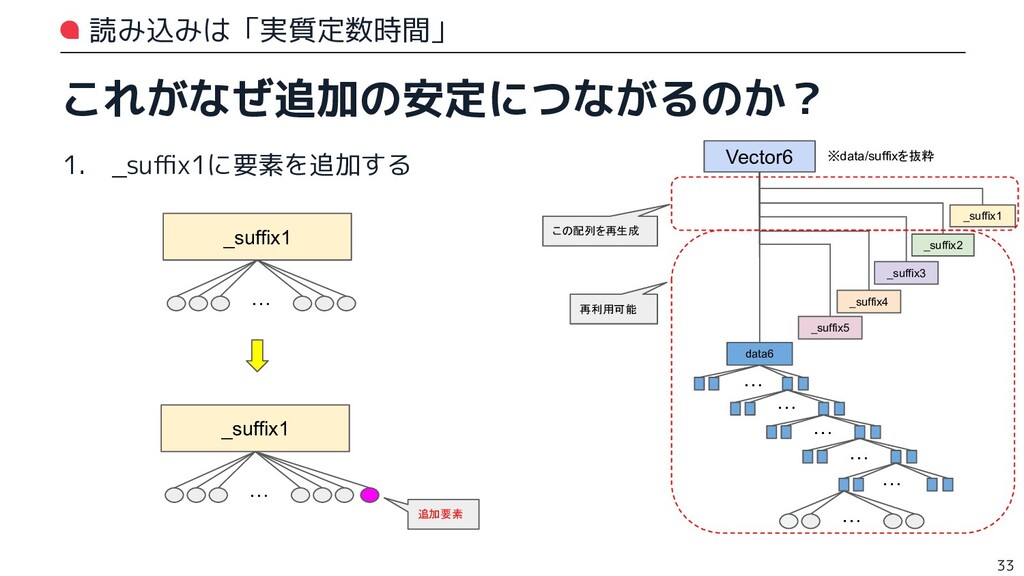{kind=link}
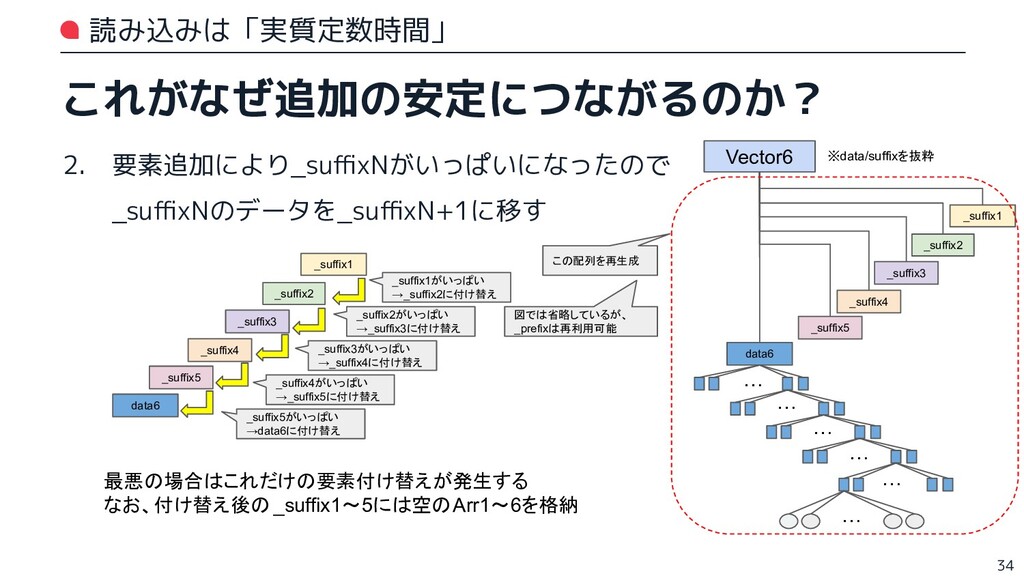{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}