Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
NISRA Course
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
loyo
April 17, 2012
Education
1
110
NISRA Course
主題:
戰鬥吧!打工戰士!身為工程師須具備的字串處理思維!
課程要點:
針對常用字串處理介紹 介紹常用工具及指令
loyo
April 17, 2012
Tweet
Share
Other Decks in Education
See All in Education
Activité_5_-_Les_indicateurs_du_climat_global.pdf
bernhardsvt
0
140
AWS re_Invent に全力で参加したくて筋トレを頑張っている話
amarelo_n24
2
120
NUTMEG紹介スライド
mugiiicha
0
890
Flinga
matleenalaakso
2
15k
2025-10-30 社会と情報2025 #05 CC+の代わり
mapconcierge4agu
0
110
CSS3 and Responsive Web Design - Lecture 5 - Web Technologies (1019888BNR)
signer
PRO
1
3.1k
外国籍エンジニアの挑戦・新卒半年後、気づきと成長の物語
hypebeans
0
730
Microsoft Office 365
matleenalaakso
0
2.1k
Security, Privacy and Trust - Lecture 11 - Web Technologies (1019888BNR)
signer
PRO
0
3.2k
あなたの言葉に力を与える、演繹的なアプローチ
logica0419
1
270
1216
cbtlibrary
0
140
ロータリー国際大会について~国際大会に参加しよう~:古賀 真由美 会員(2720 Japan O.K. ロータリーEクラブ・(有)誠邦産業 取締役)
2720japanoke
1
770
Featured
See All Featured
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
0
1.1k
Scaling GitHub
holman
464
140k
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
150
The browser strikes back
jonoalderson
0
370
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2k
Paper Plane (Part 1)
katiecoart
PRO
0
4.2k
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
1
440
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
0
140
Mobile First: as difficult as doing things right
swwweet
225
10k
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
240
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
55k
Abbi's Birthday
coloredviolet
1
4.7k
Transcript
戰鬥吧!打工戰士! 身為工程師須具備的字串處理思維! Loyo@NISRA
Before Start 任何提及之 圖片、影片皆為 原所有人所有
WHY 為什麼選擇此主題? 增加面對處理字串時… 的手感!!!
思維方式 甚麼時候要? 資料筆數? 是否要非常精準? 檔案是否有中文或特殊字元? 日後常常會用到? 手邊目前 有甚麼工具? 檔案格式?
STRING 字串
字串系三小… “ “ 這就是字串!!!!!!!
STRING 計算字串出現次數 字串 count 取代字串成目標字串(可能是換成空白字元) replace
STRING 抓取某特定字串 字串 select 將特定字串排列 sort
Linux Command Linux 常用指令
HEAD LESS CAT TAIL I > >> WC SORT UNIQ
GREP AWK LINUX常用指令
CAT, LESS cat <file> 顯示檔案內容 CAT less <file> LESS 一次倒出所有內容
可控制瀏覽內容 搜尋內容也很方便!
HEAD, TAIL head -n <file> also 顯示檔案內容 HEAD tail -n
<file> TAIL 選擇性從頭顯示內容 選擇性從最後顯示內容 *(參數) n :行數 *(參數) n :行數
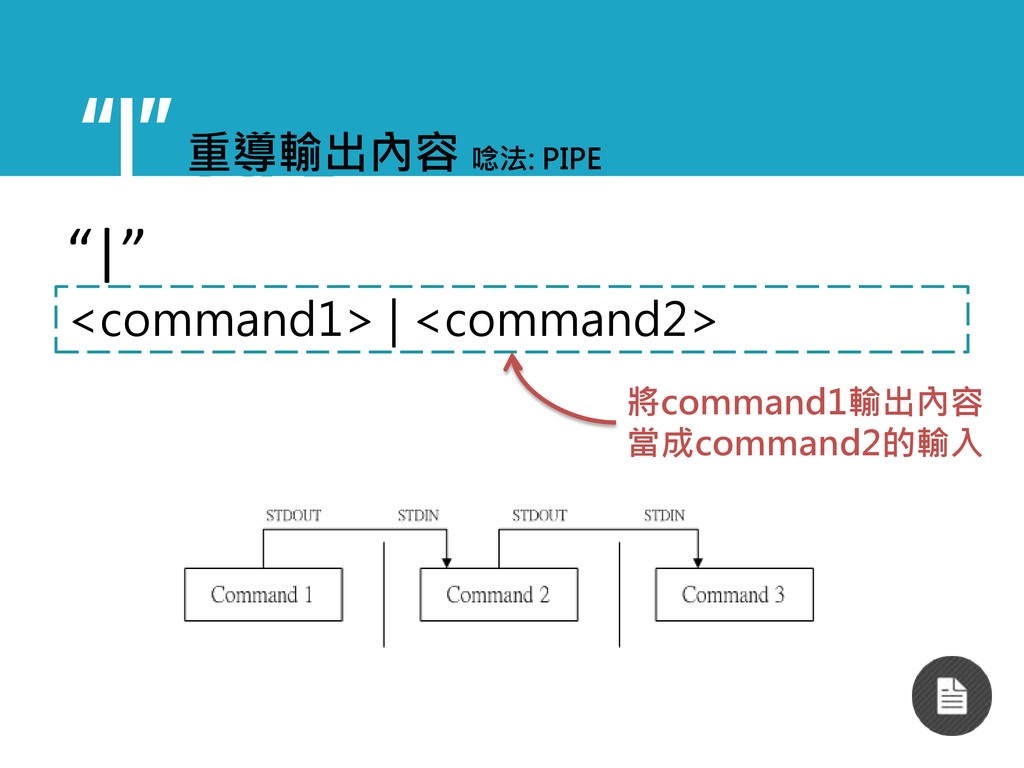
“|” PIPE <command1> | <command2> 重導輸出內容 唸法: PIPE “|” 將command1輸出內容
當成command2的輸入
“|” PIPE 重導輸出內容 唸法: PIPE 拜託不要打L… (會崩潰
>, >> <command>> <file> 資料流重導向 > <command>>> <file> >> 取代的概念
累加的概念 *經常搭配在處理指令輸出結果寫檔,會覆蓋前次結果 *經常搭配在處理指令輸出結果寫檔,會累加呈現
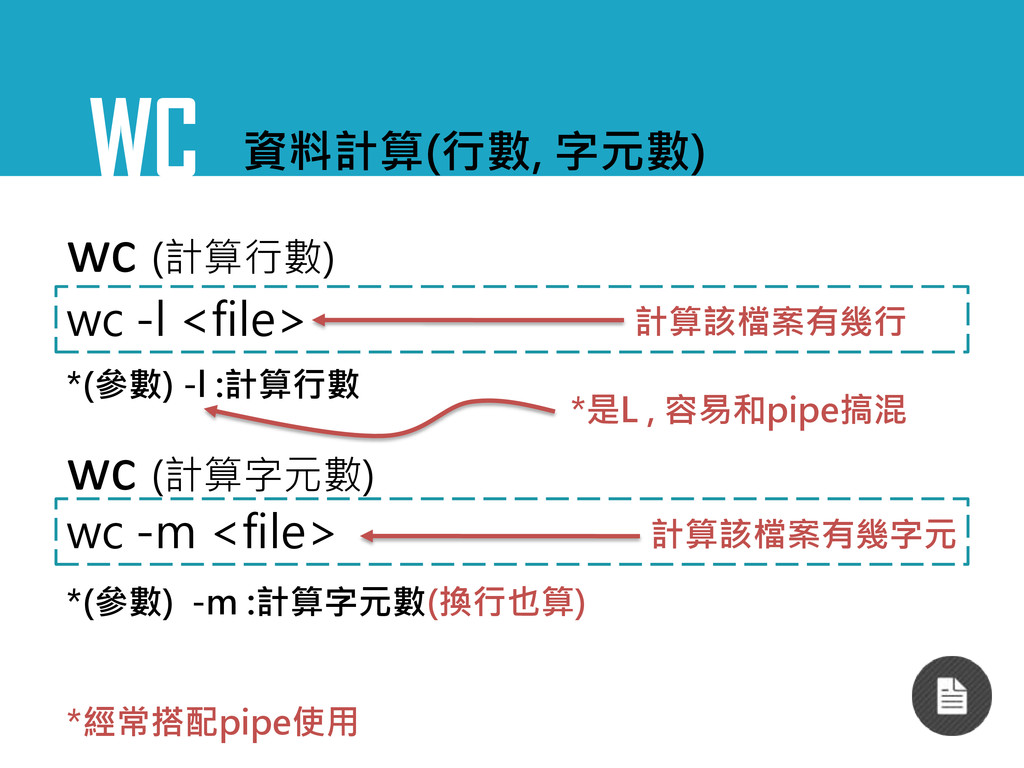
WC wc -l <file> 資料計算(行數, 字元數) wc (計算行數) wc -m
<file> wc (計算字元數) 計算該檔案有幾行 計算該檔案有幾字元 *(參數) -l :計算行數 *經常搭配pipe使用 *是L , 容易和pipe搞混 *(參數) -m :計算字元數(換行也算)
SORT sort <file> 資料排序 sort 排序檔案內容 *(參數) -f :忽略大小寫 (注意忽略大小寫,會因系統環境變數設定不同而有差異)
-b:忽略每行前方的空白 -r:反向排序 -u:將相同之選項排除,僅保留一項 *uniq 與 sort 視情境搭配使用
UNIQ uniq <file> 排除重覆資料 uniq 排除檔案內容重覆部分 *(參數) -i :忽略大小寫 -c:計算重覆次數
*uniq 指令是將重複的項目減少 所以需要『配合排序過的檔案』(sort command)
GREP grep PATTERN <file> 選取特定資料 grep 選取檔案中特定資料 *(參數) -i :
忽略大小寫 -E: PATTERN 使用 regexp -v: 反向選取,相當於列出不符合 PATTERN 的資料 *grep 指令使用的的機會非常高,建議多熟悉!
AWK awk -F'#' '{print $3}' <file> 資料處理工具 awk 選取檔案中特定 欄位資料
*(參數) F : 分隔符號 allenown#realpiyo#shaolin#anfa $1 $2 $3 $4 *awk的用法非常多,甚至可以針對IF去做判斷,可自行玩 玩實驗看看。 $3 = ?
REGEXP 正規表達式 敘述符合某段句法規則之字串的字串 用來找尋與驗證或替換符合規則的字串。
包含大小寫A-Z的字元 REGEXP [A-Za-z] 正規表達式 篩選字串格式的描述語句 包含大小寫A-Z的四個字元 [A-Za-z]{4} 表示所有由四個A-Z字元所組 成的字串!(大小寫視同)
包含大小寫A-Z,0-9的字元,字元數最少3個,最多8個的字串 REGEXP [A-Za-z0-9] {3,8} 正規表達式 開頭是由4個0-9的數字所組成的字串 ^[0-9]{4} 結尾是由4個0-9的數字所組成的字串 [0-9]{4}$
手機號碼(09xx-xxx-xxx) REGEXP 09[0-9]{2}-[0-9]{3}-[0-9]{3} 正規表達式 手機號碼(09xx-xxxxxx) 09[0-9]{2}-[0-9]{6} 身分證字號 [A-Za-z][12][0-9]{8} 1或是2
REGEXP正規表達式 字母 縣市 A 臺北市 B 臺中市 C 基隆市 D
臺南市 E 高雄市 F 新北市 G 宜蘭縣 H 桃園縣 I 嘉義市 J 新竹縣 K 苗栗縣 字母 縣市 M 南投縣 N 彰化縣 O 新竹市 P 雲林縣 Q 嘉義縣 T 屏東縣 U 花蓮縣 V 臺東縣 W 金門縣 X 澎湖縣 Z 連江縣 第一碼數字: 2 -> 女 1 -> 男 第一碼字母:
MIKU 初音ミク A: 初音是誰? B:初音是個軟體而已...... C:什麼叫初音是個軟體而以.....想決鬥嗎?!!!! B:好啦 應該說她"本來"是個軟體 C:什麼叫做「本來」是個軟體! 你又要決鬥了嗎!????
ENCODING 字元編碼 Character encoding
ENCODING 字元編碼 字元 凡舉看到的符號、字符皆可稱為字元。 字集 字元的集合,即為字集,不同國家因語言與文字上 的不同,會有不同的字集。 字碼 對於字集對應而產生的對應碼,即為字碼。
ENCODING 字元編碼 舉個例子…
None
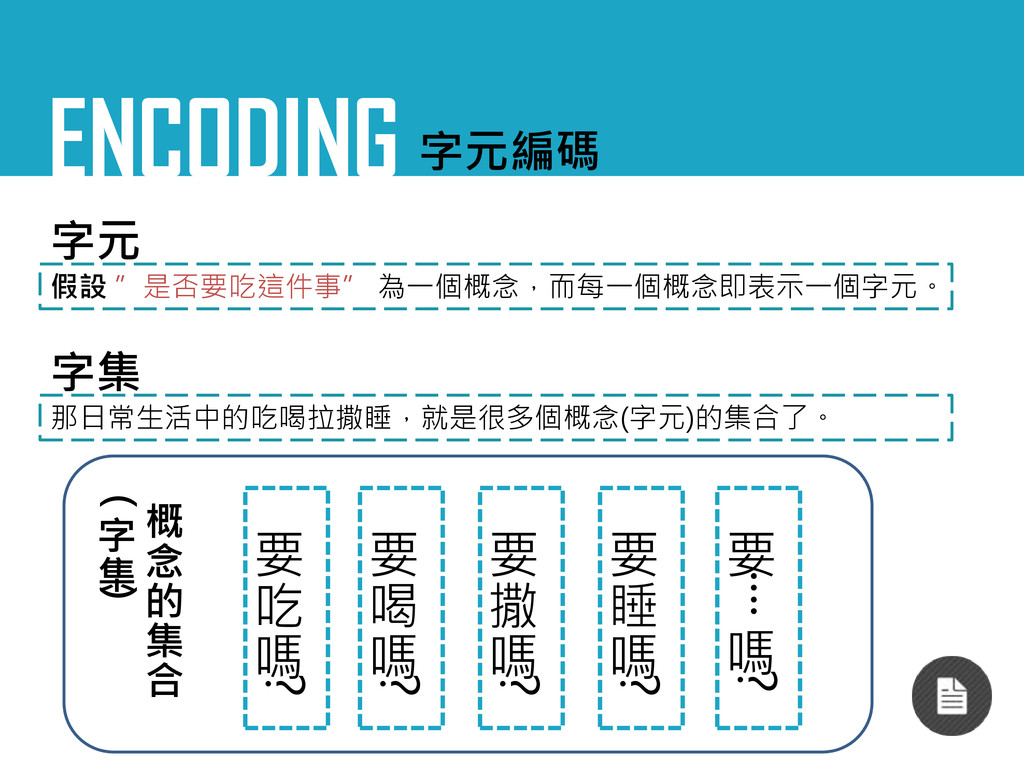
ENCODING 字元編碼 字元 假設 ”是否要吃這件事” 為一個概念,而每一個概念即表示一個字元。 字集 那日常生活中的吃喝拉撒睡,就是很多個概念(字元)的集合了。 要 吃
嗎 ? 要 喝 嗎 ? 要 撒 嗎 ? 要 睡 嗎 ? 要 ‧‧‧‧ 嗎 ? 概 念 的 集 合 ( 字 集 )
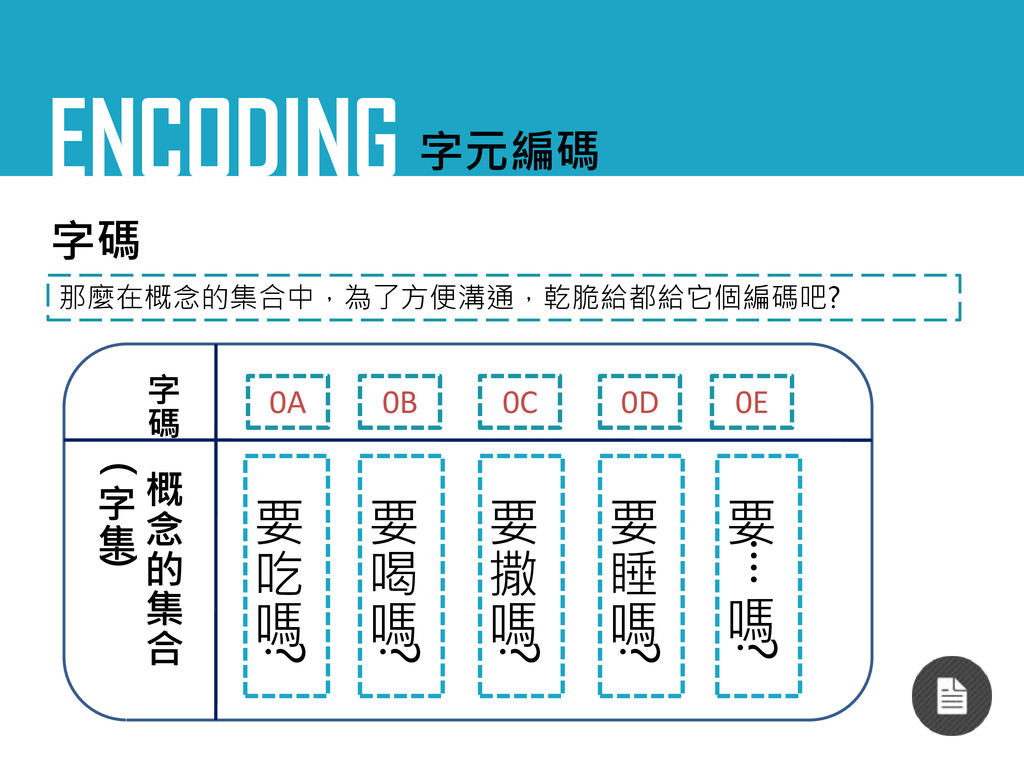
ENCODING 字元編碼 字碼 那麼在概念的集合中,為了方便溝通,乾脆給都給它個編碼吧? 要 吃 嗎 ? 要 喝
嗎 ? 要 撒 嗎 ? 要 睡 嗎 ? 要 ‧‧‧‧ 嗎 ? 概 念 的 集 合 ( 字 集 ) 0A 0B 0C 0D 0E 字 碼
ENCODING 字元編碼 0A 0B 要 吃 嗎 ? 要 喝
嗎 ?
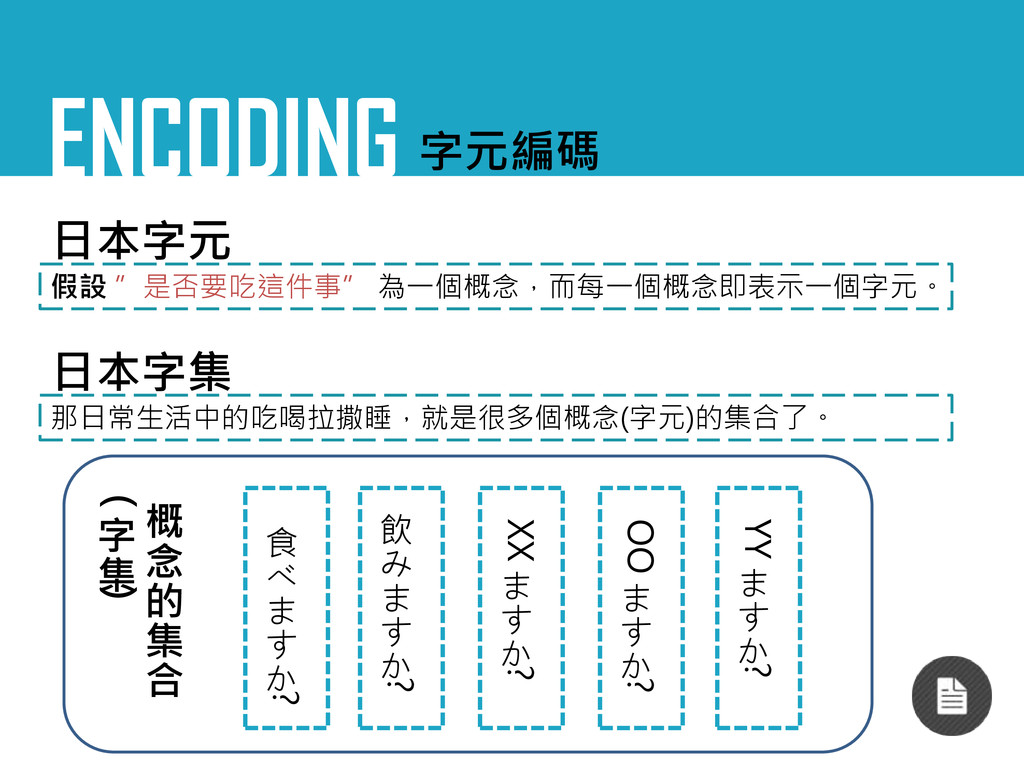
ENCODING 字元編碼 日本字元 假設 ”是否要吃這件事” 為一個概念,而每一個概念即表示一個字元。 日本字集 那日常生活中的吃喝拉撒睡,就是很多個概念(字元)的集合了。 概 念
的 集 合 ( 字 集 ) 食 べ ま す か ? 飲 み ま す か ? XX ま す か ? OO ま す か ? YY ま す か ?
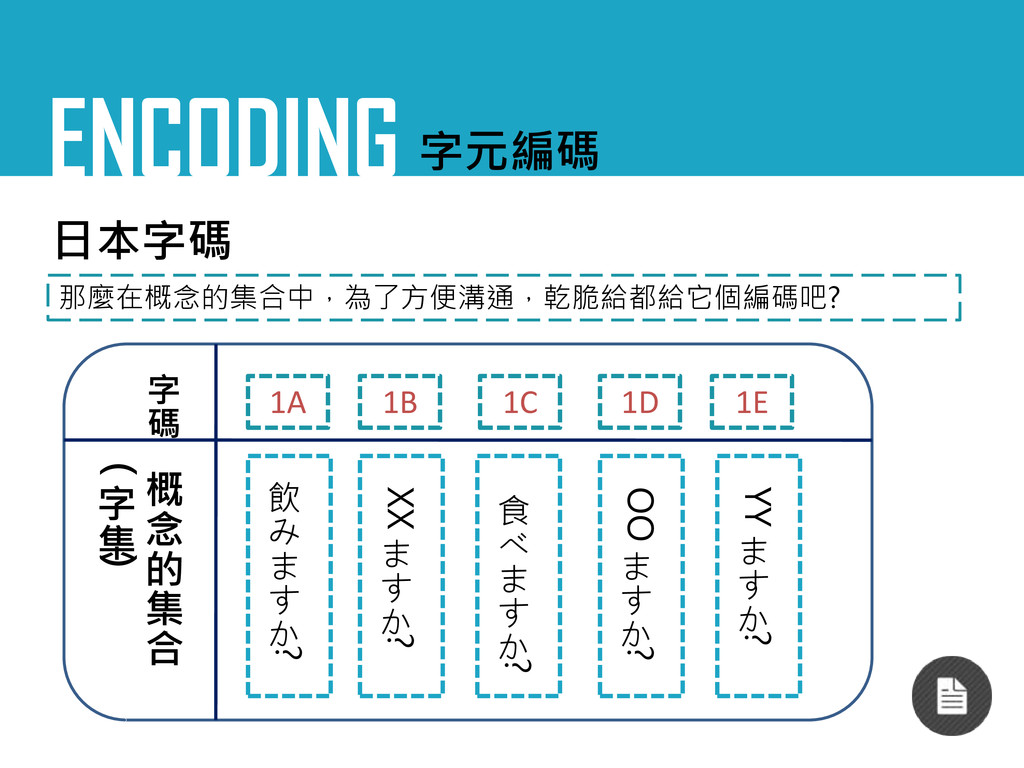
ENCODING 字元編碼 日本字碼 那麼在概念的集合中,為了方便溝通,乾脆給都給它個編碼吧? 食 べ ま す か ?
飲 み ま す か ? XX ま す か ? OO ま す か ? YY ま す か ? 概 念 的 集 合 ( 字 集 ) 1A 1B 1C 1D 1E 字 碼
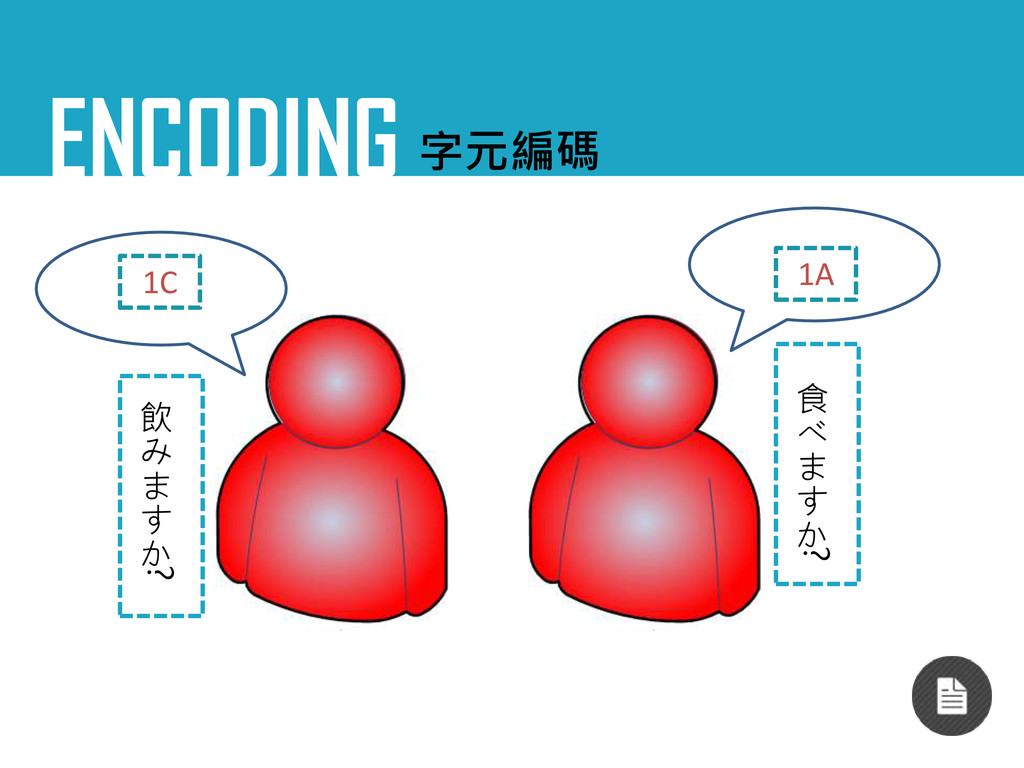
ENCODING 字元編碼 1C 1A 食 べ ま す か ?
飲 み ま す か ?
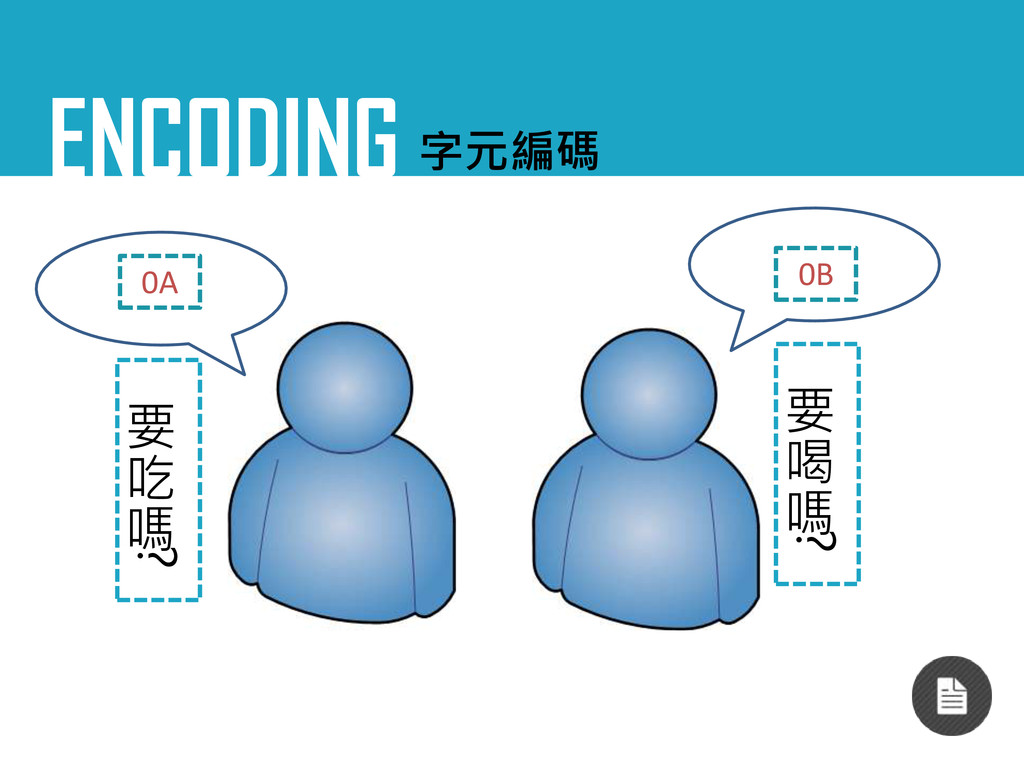
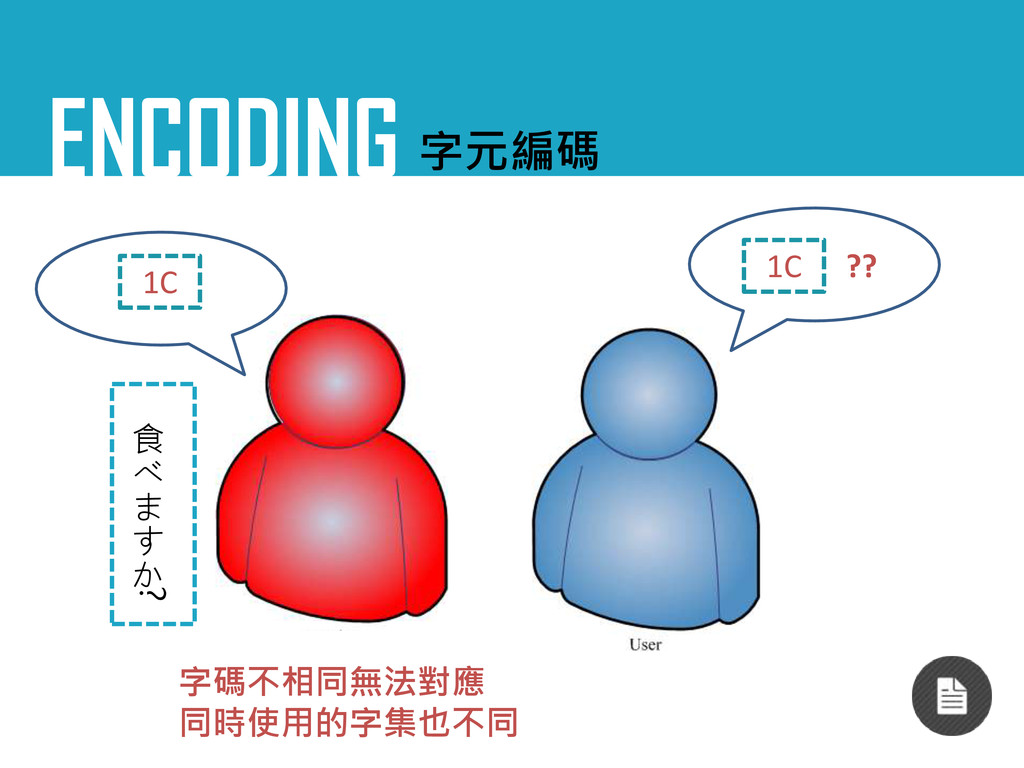
ENCODING 字元編碼 當日本人碰到台灣人…
ENCODING 字元編碼 1C 食 べ ま す か ? 1C
字碼不相同無法對應 同時使用的字集也不同 ??
BIG5 大五碼 五大碼
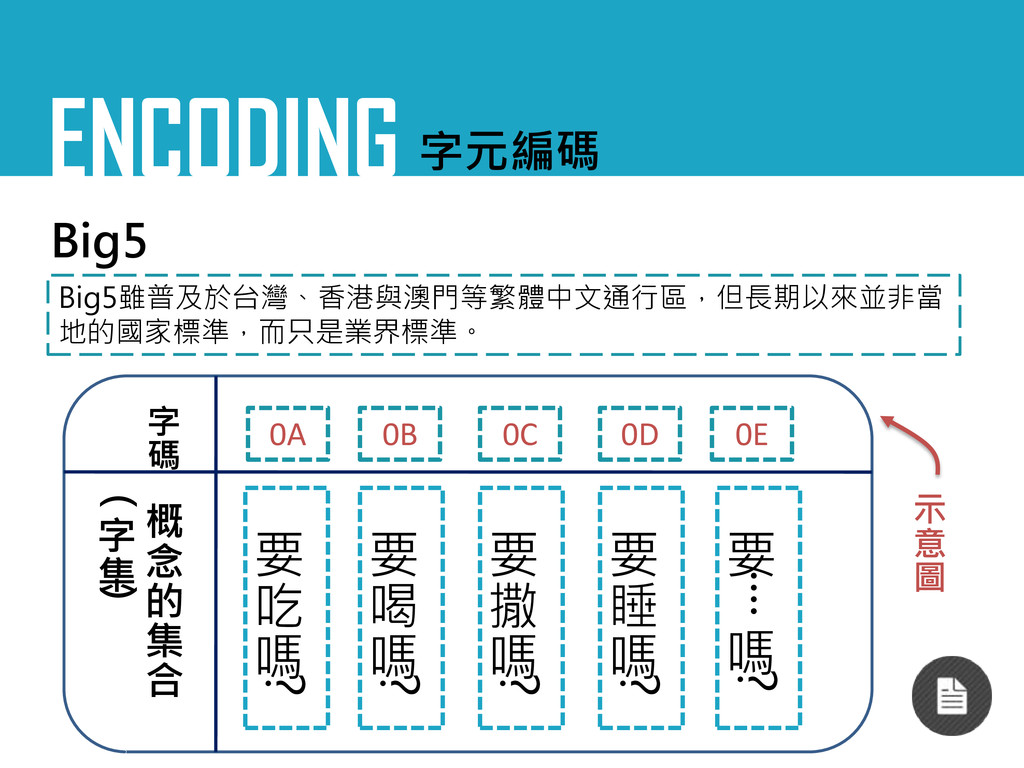
ENCODING 字元編碼 Big5 Big5雖普及於台灣、香港與澳門等繁體中文通行區,但長期以來並非當 地的國家標準,而只是業界標準。 要 吃 嗎 ? 要
喝 嗎 ? 要 撒 嗎 ? 要 睡 嗎 ? 要 ‧‧‧‧ 嗎 ? 概 念 的 集 合 ( 字 集 ) 0A 0B 0C 0D 0E 字 碼 示 意 圖
Unicode 統一碼、萬國碼、單一碼、標準萬國碼
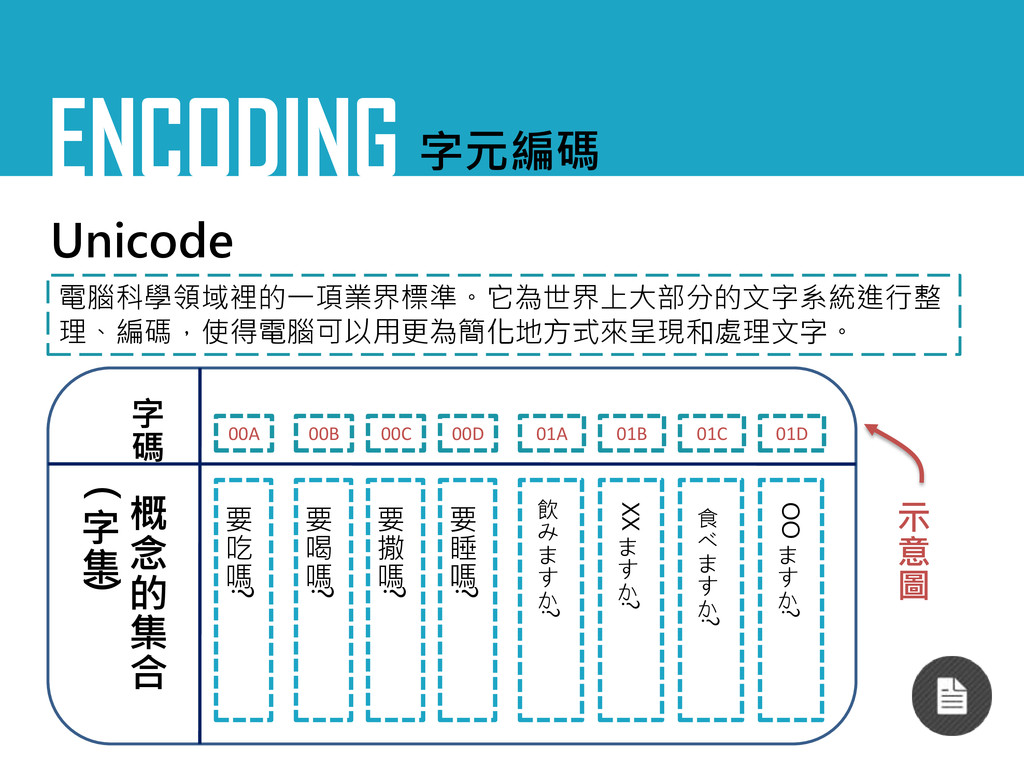
ENCODING 字元編碼 Unicode 電腦科學領域裡的一項業界標準。它為世界上大部分的文字系統進行整 理、編碼,使得電腦可以用更為簡化地方式來呈現和處理文字。 示 意 圖 要 吃
嗎 ? 要 喝 嗎 ? 要 撒 嗎 ? 要 睡 嗎 ? 概 念 的 集 合 ( 字 集 ) 00A 00B 00C 00D 01A 字 碼 食 べ ま す か ? 飲 み ま す か ? XX ま す か ? OO ま す か ? 01B 01C 01D
&*&%ˊ-=[_ 亂碼
ENCODING 字元編碼 亂碼 當使用的字集與字元編碼互相不符合的時候,就會出現亂碼。 Big5 vs UTF8 隞嗡��vs 電子郵件 NOTE:
UTF8是Unicode的一種編碼方式!
THE END
本著作由Loyo Fulamce製作,以創用CC 姓名標示- 非商業性-相同方式分享 3.0 台灣 授權條款釋出。 任何提及之圖片、影片其版權皆為原所有人所有
任何事情…
都要咬緊牙根!!!!
[轉錄] 若你把目標放在月球 那你將輕易越過樹梢
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![包含大小寫A-Z的字元 REGEXP [A-Za-z] 正規表達式 篩選字串格式的描述語句 包含大小寫A-Z的四個字元 [A-Za-z]{4} 表示所有由四個A-Z字元所組 成的字串!(大小寫視同)](https://files.speakerdeck.com/presentations/4f8da25c78ea6003db00c891/slide_21.jpg){kind=link}
![包含大小寫A-Z,0-9的字元,字元數最少3個,最多8個的字串 REGEXP [A-Za-z0-9] {3,8} 正規表達式 開頭是由4個0-9的數字所組成的字串 ^[0-9]{4} 結尾是由4個0-9的數字所組成的字串 [0-9]{4}$](https://files.speakerdeck.com/presentations/4f8da25c78ea6003db00c891/slide_22.jpg){kind=link}
![手機號碼(09xx-xxx-xxx) REGEXP 09[0-9]{2}-[0-9]{3}-[0-9]{3} 正規表達式 手機號碼(09xx-xxxxxx) 09[0-9]{2}-[0-9]{6} 身分證字號 [A-Za-z][12][0-9]{8} 1或是2](https://files.speakerdeck.com/presentations/4f8da25c78ea6003db00c891/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[轉錄] 若你把目標放在月球 那你將輕易越過樹梢](https://files.speakerdeck.com/presentations/4f8da25c78ea6003db00c891/slide_48.jpg){kind=link}