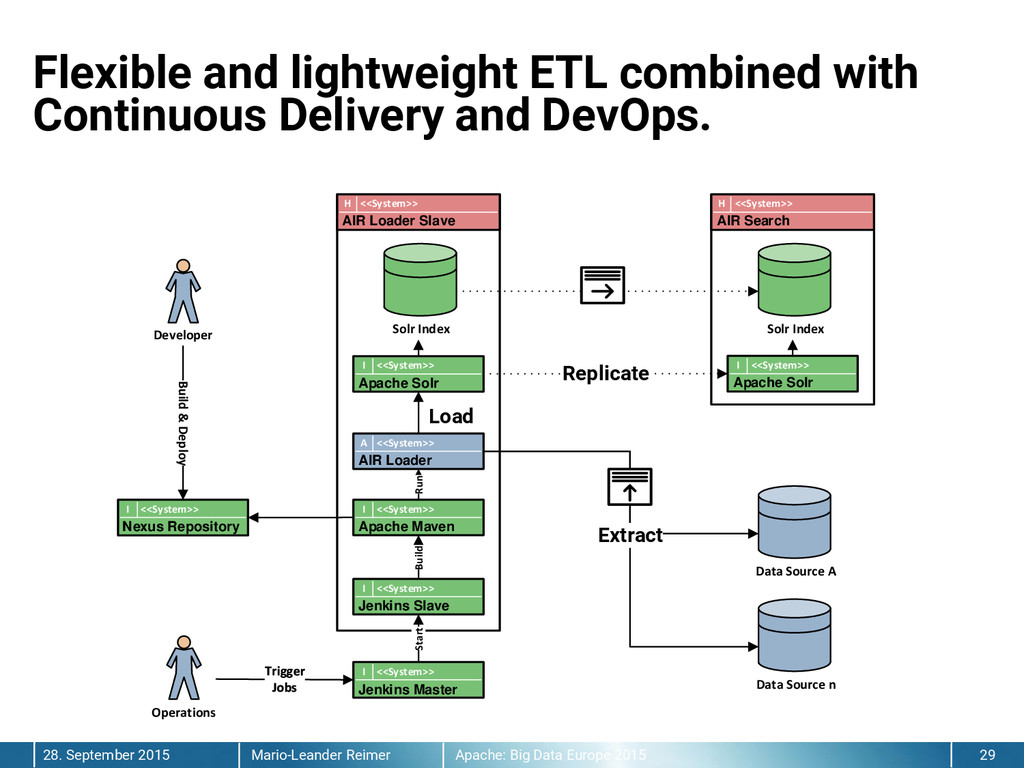
We are searching the unknown. How can you find hidden and unknown relationships in unrelated data silos? How can you find relevant information in a 10^56 dimensional space? Sounds impossible? This talk will present a case study and success story about how Apache Solr has been used to build a search based business intelligence and information research application to answer these questions. The talk was delivered at the Apache: Big Data 2015 Conference in Budapast. #apachebigdataeu2015
{kind=link}
{kind=link}
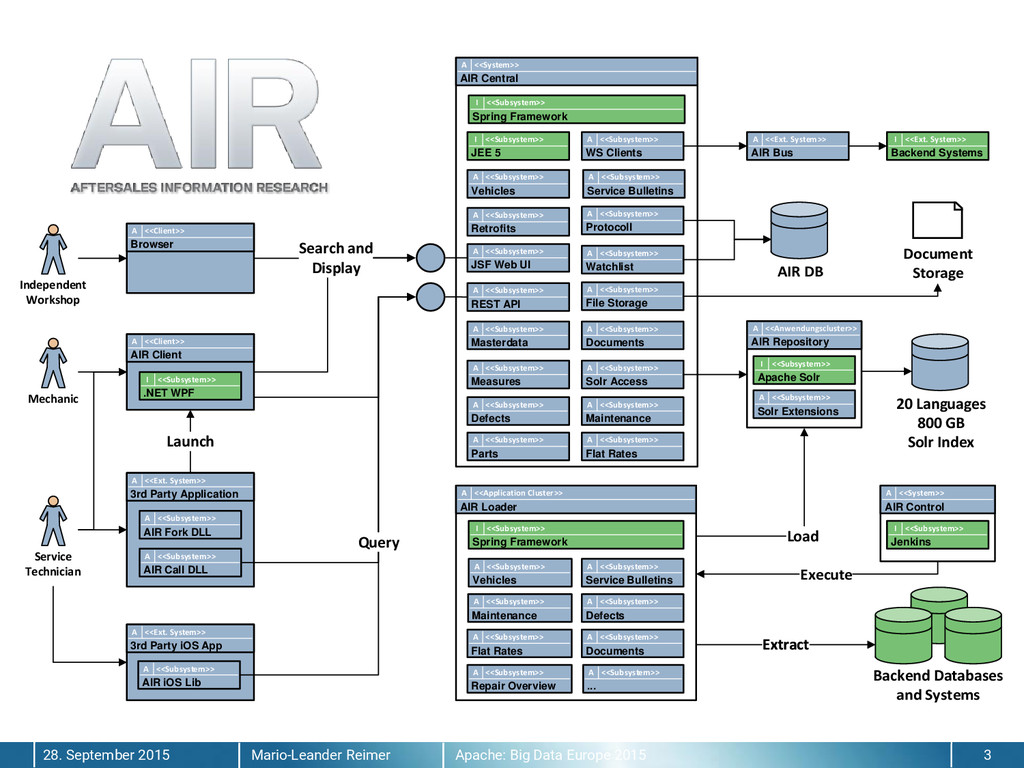{kind=link}
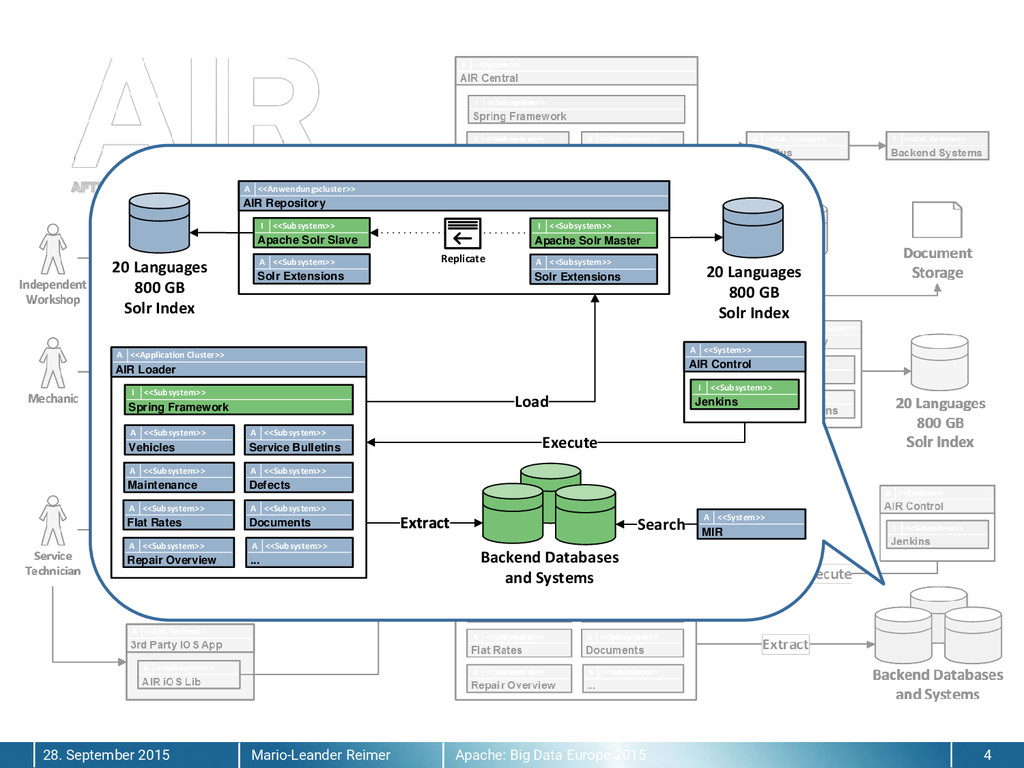{kind=link}
{kind=link}
{kind=link}
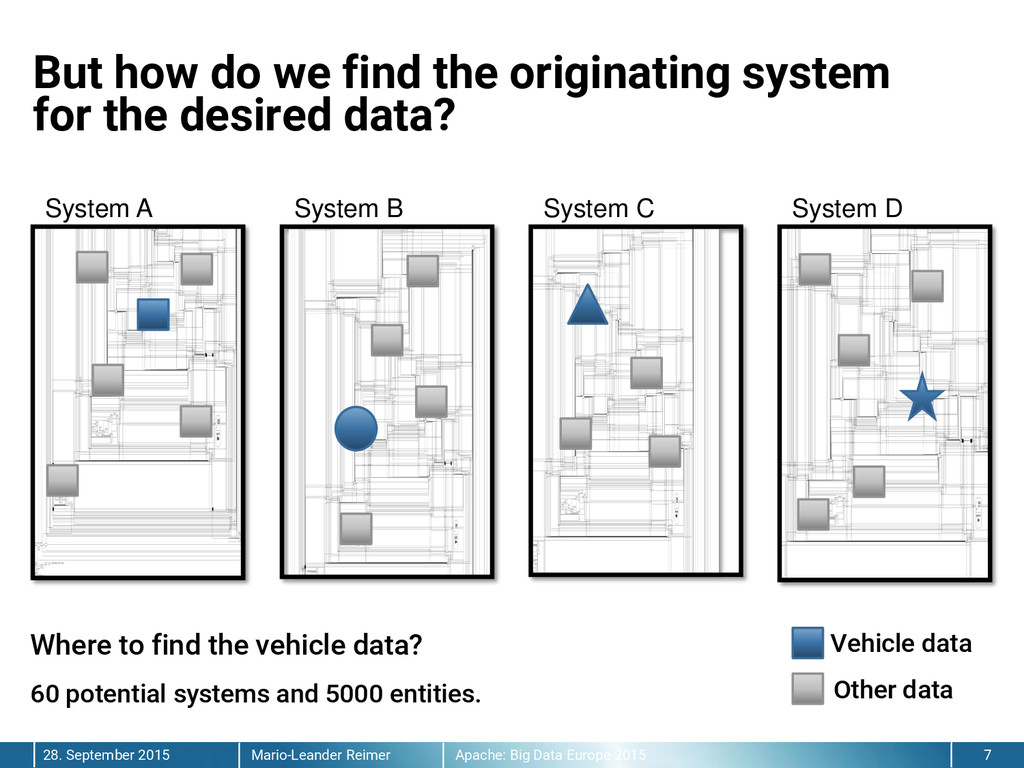{kind=link}
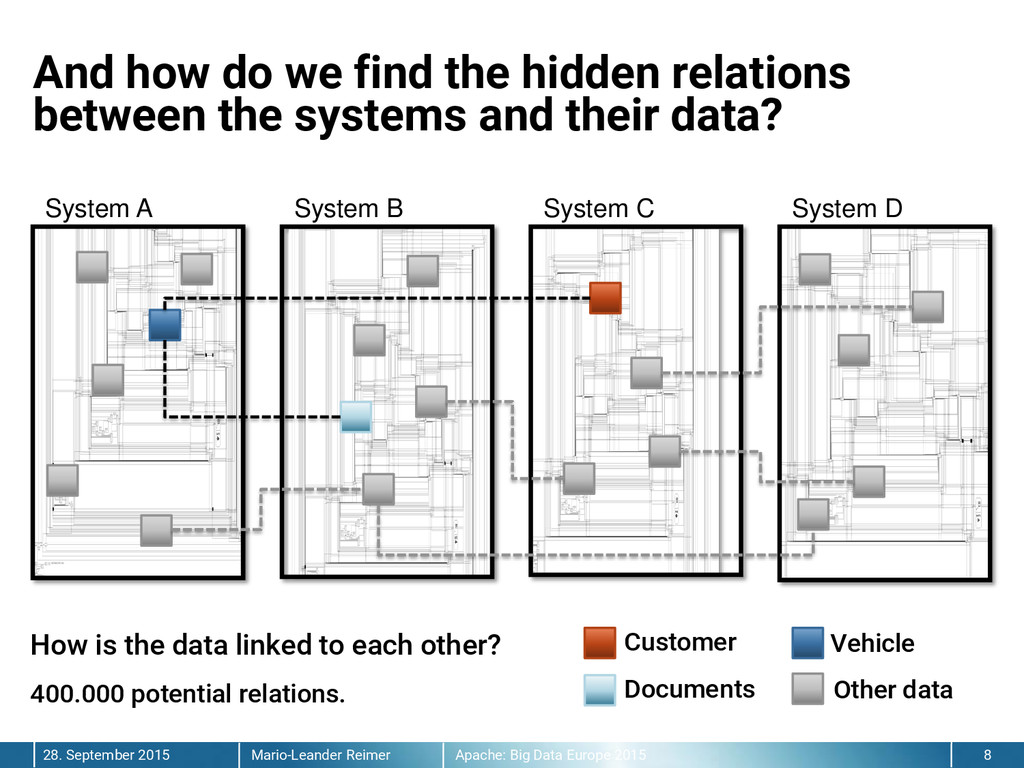{kind=link}
{kind=link}
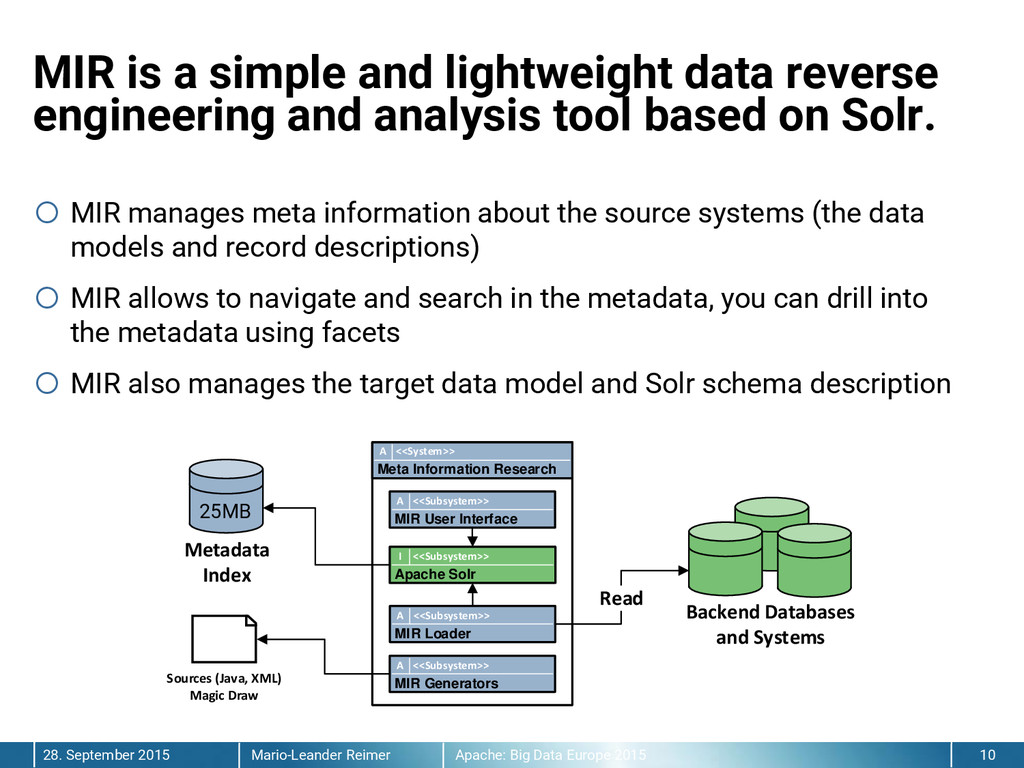{kind=link}
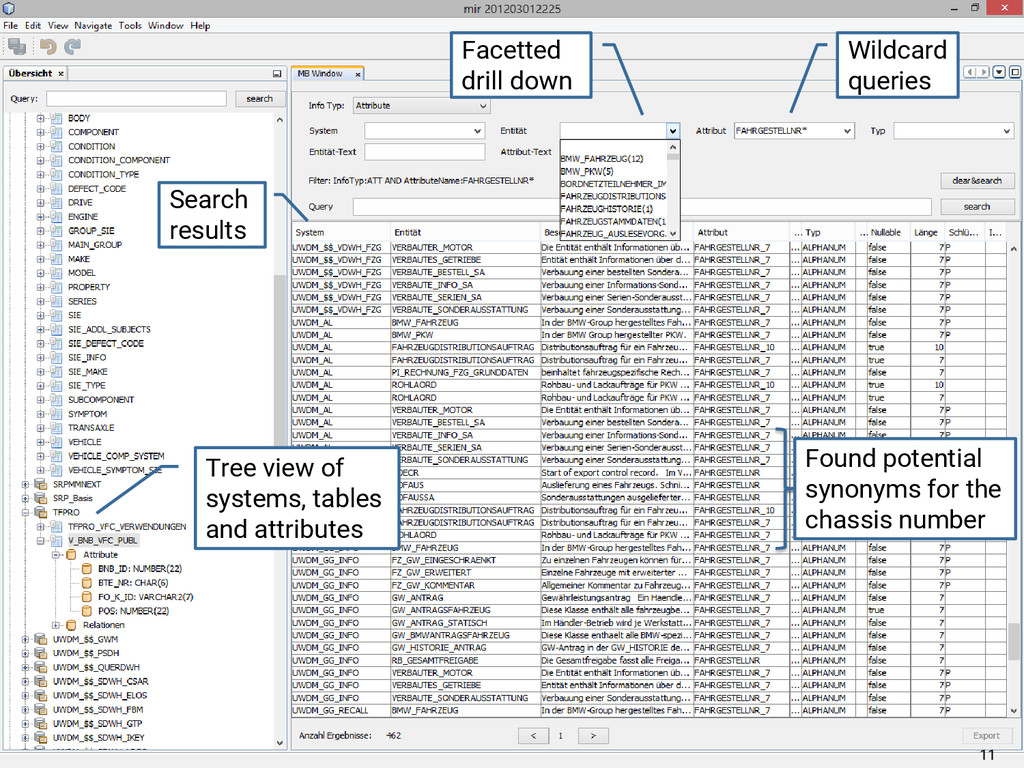{kind=link}
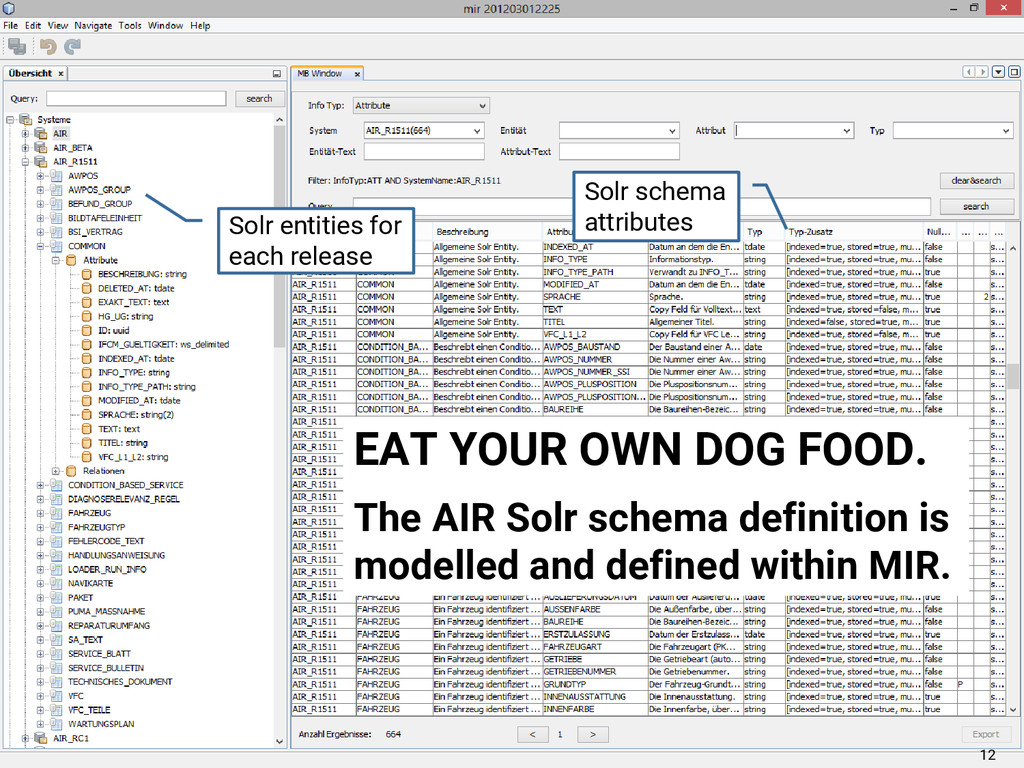{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
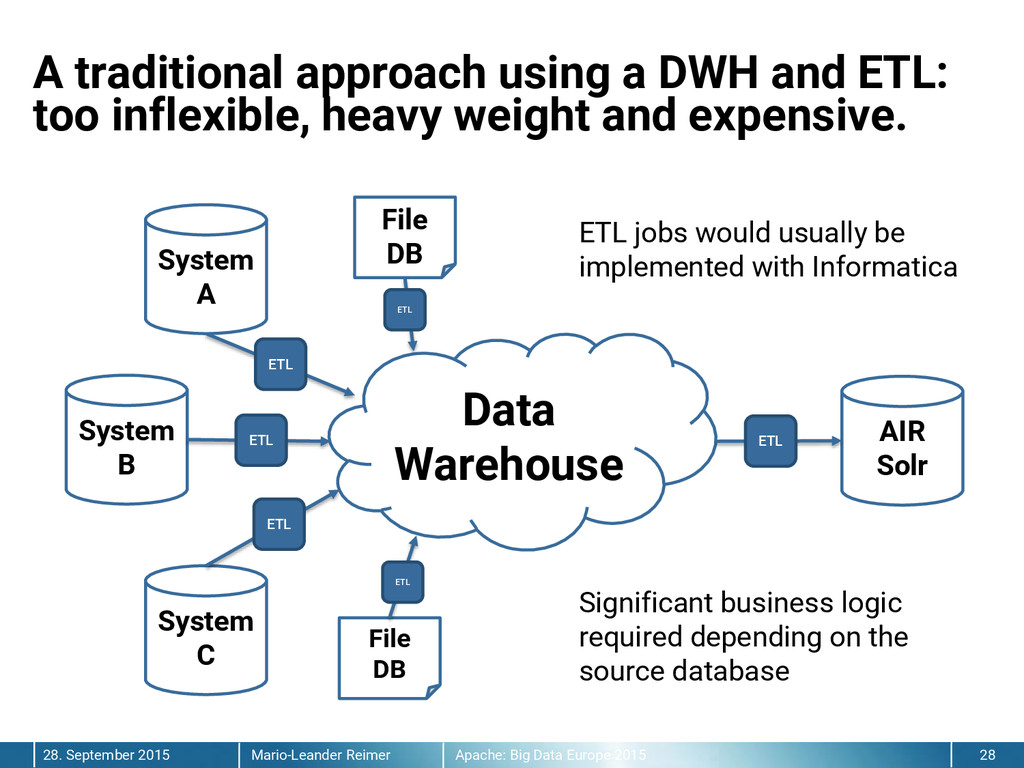{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}