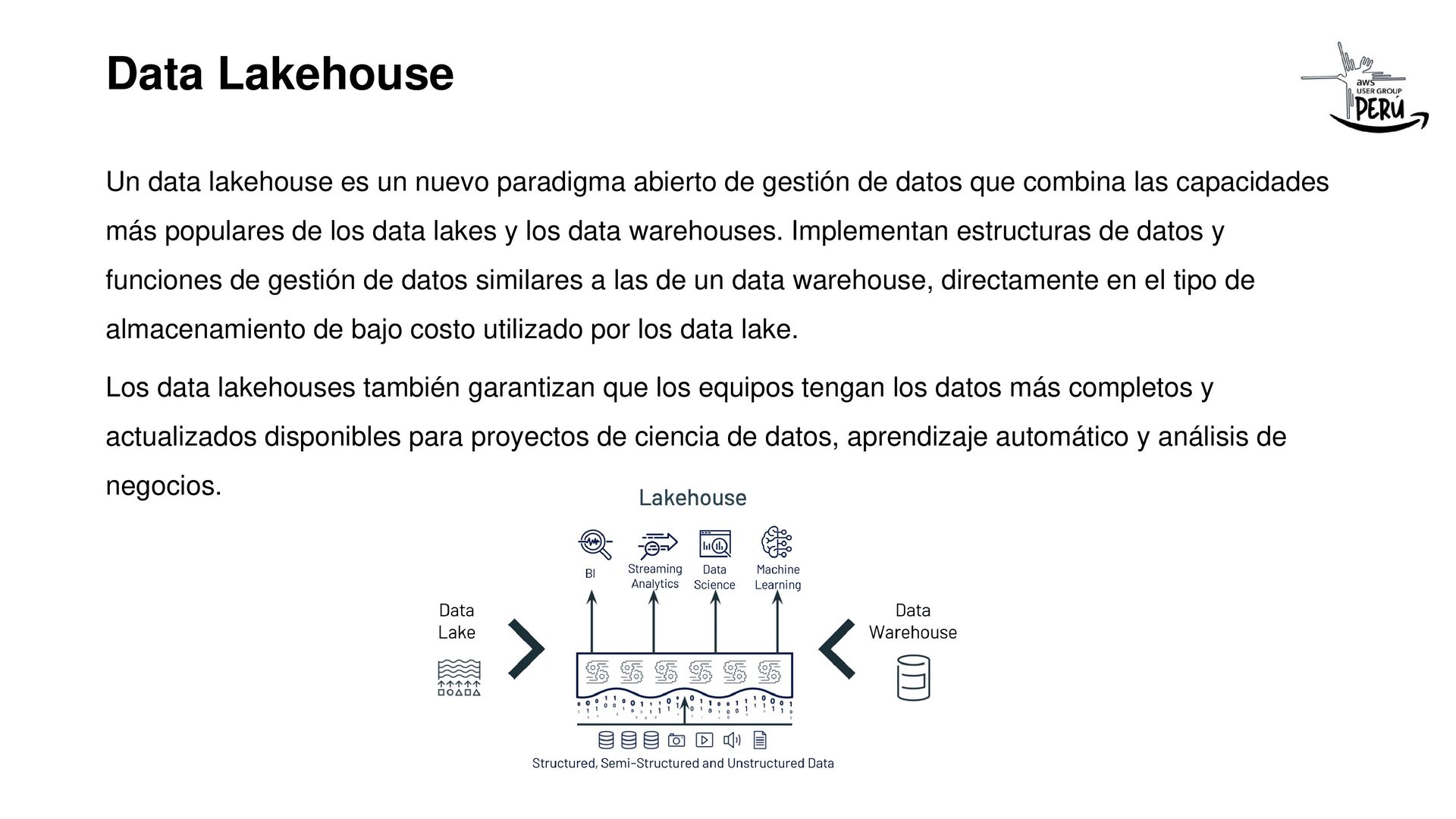
En esta sesión explico como partir primero de una estrategia de datos, bien definida con los stakeholders, detectar los casos de uso de más impacto en la organización y realizar las priorizaciones, para aterrizarlo con una solución de datos que tenga los sponsor que apoyen la iniciativa.
Siempre iniciemos con el problema o necesidad (objetivos estratégicos, OKR) de la organización antes de definir cualquier arquitectura tecnológica.
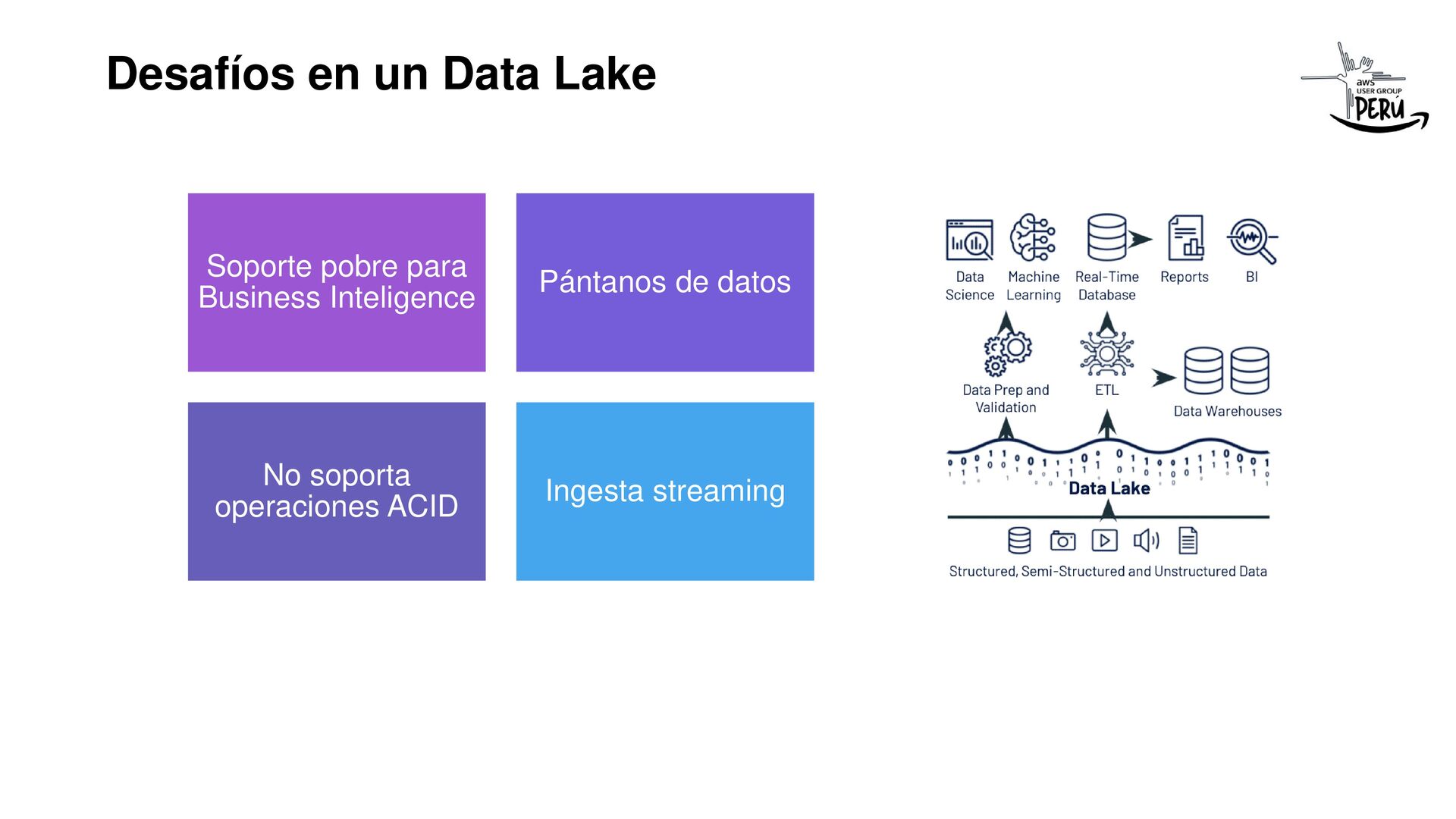
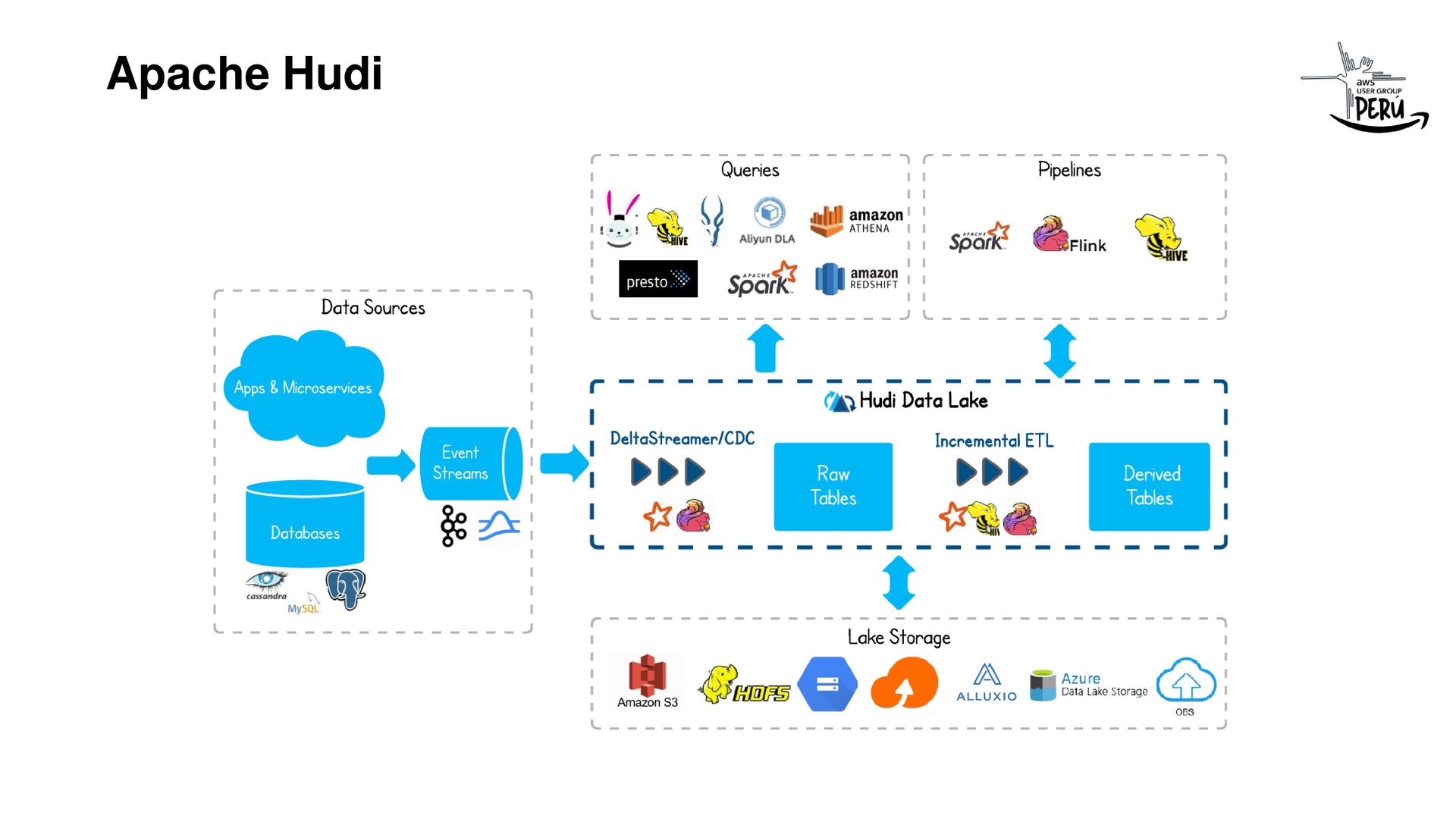
Apache Hudi que fue creado por Uber en el 2016, nos permite realizar transaccionalidad (ACID), viajes en el tiempo, evolución de esquemas, consultas en tiempo real, etc; a nuestros Data Lakes (S3, Cloud Storage, ADLS Gen2, HDFS).
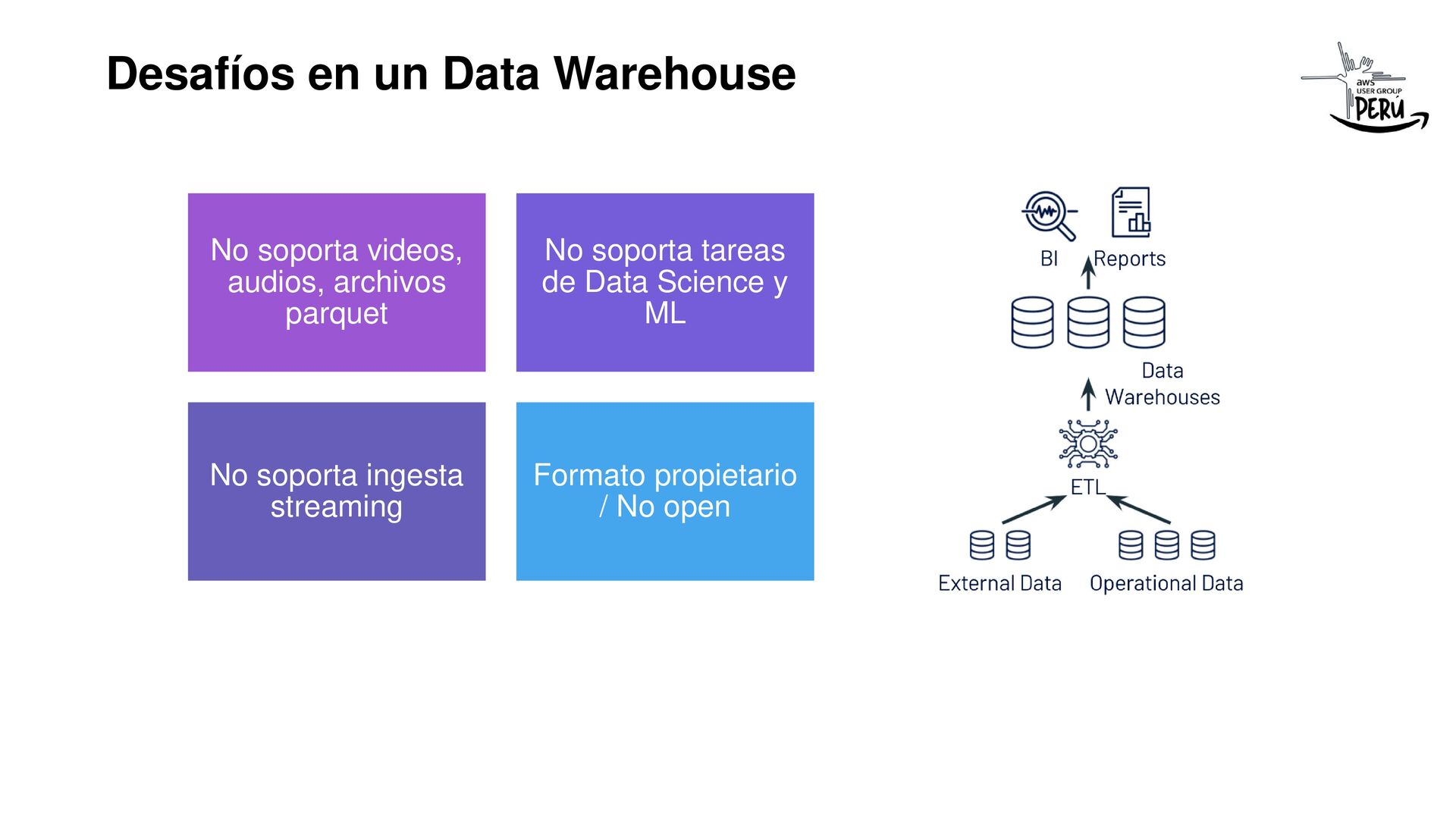
Si eres ingeniero de datos y te has topado con los problemas de hacer recargas diarias a tu Data Lake por cada fuente de datos, incluso solo por la modificación de una fila en tu input (BD Transaccional, File), esta charla te resultará interesante, el equipo de ingeniería de Uber lo resolvió hace pocos años para todos y es open source, gracias a Vinoth Chandar y todo su super equipo por esta iniciativa que ahora es un proyecto top en Apache.
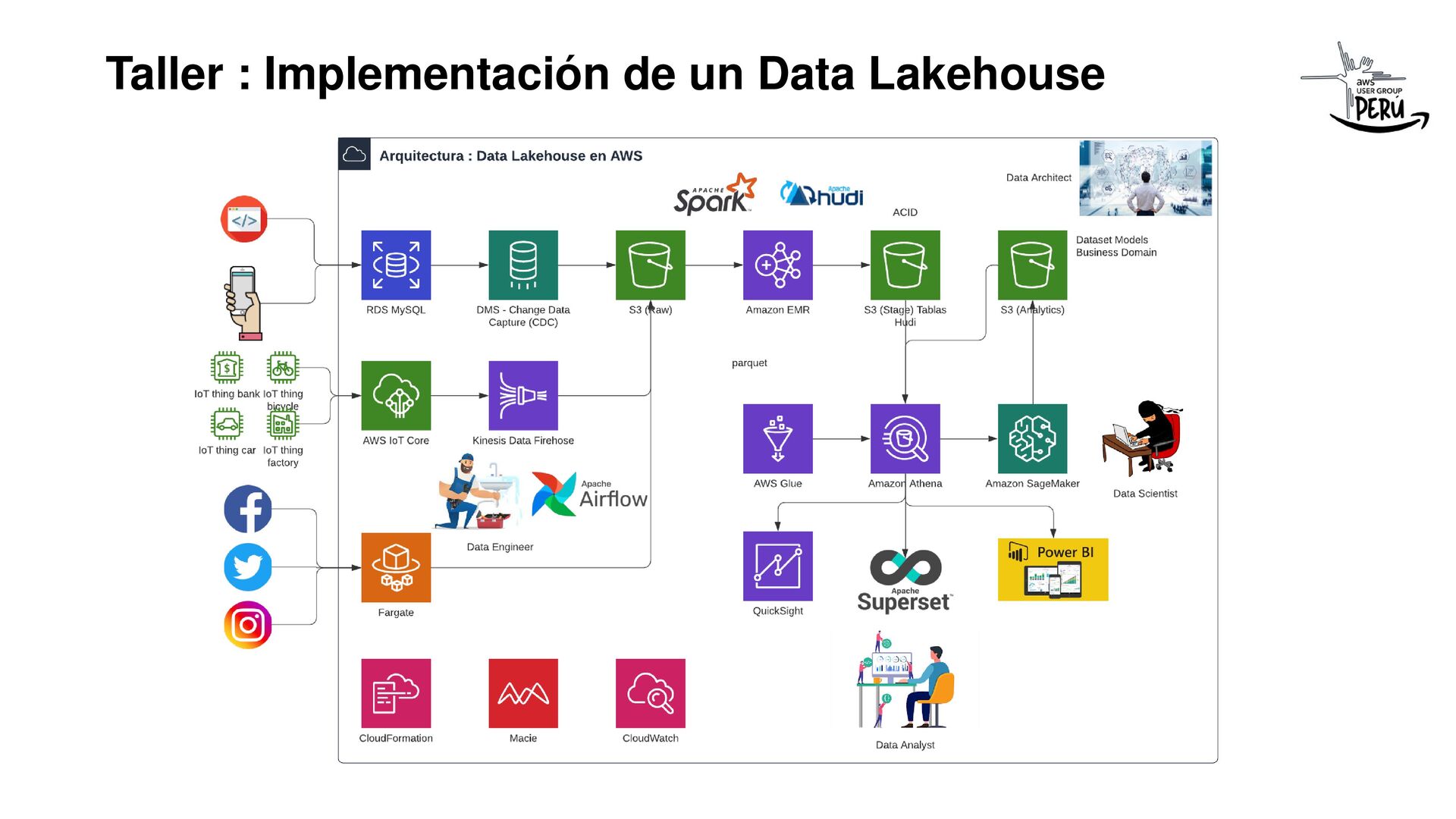
En la demo explicó su funcionamiento.
Link de la sesión : https://www.twitch.tv/awsugperu/video/1065234210
Gracias por leer hasta aquí. Si esta publicación te resultó útil, te agradecería mucho que la recomendaras para que otros también puedan encontrarla.
Linkedin : https://www.linkedin.com/in/luisgrados
GitHub : https://github.com/luisgradossalinas
Medium : https://medium.com/@luisgradossalinas
Speakerdeck : https://speakerdeck.com/luisgrados
#aws #datalakehouse #emr #athena #hudi #uber
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}