ok.ru is one of top 10 internet sites of the World, according to similarweb.com. Under the hood, it has several thousand servers. Each of those servers own only fraction of the data or business logic. Shared nothing architecture can be hardly applied to social network, due to its nature, so a lot of communication happens between these servers, diverse in kind and volume. This makes ok.ru one of the largest, complicated, yet highly loaded distributed systems in the world.
This talk is about our experience in building always available, resilient to failures distributed systems in Java, their basic and not so basic failure and recovery scenarios, methods of failure testing and diagnostics. We’ll also discuss on possible disasters and how to prevent or get over them.
![Distributed Systems @ OK.RU Oleg Anastasyev @m0nstermind [email protected]](https://files.speakerdeck.com/presentations/af297aa32f40461ba32d528507a2c654/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![12 App Server code https://github.com/odnoklassniki/one-nio long []friendsIds = graphService.getFriendsByFilter(userId, mask);](https://files.speakerdeck.com/presentations/af297aa32f40461ba32d528507a2c654/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
![15 A coding issue https://github.com/odnoklassniki/one-nio long []friendsIds = graphService.getFriendsByFilter(userId, mask);](https://files.speakerdeck.com/presentations/af297aa32f40461ba32d528507a2c654/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
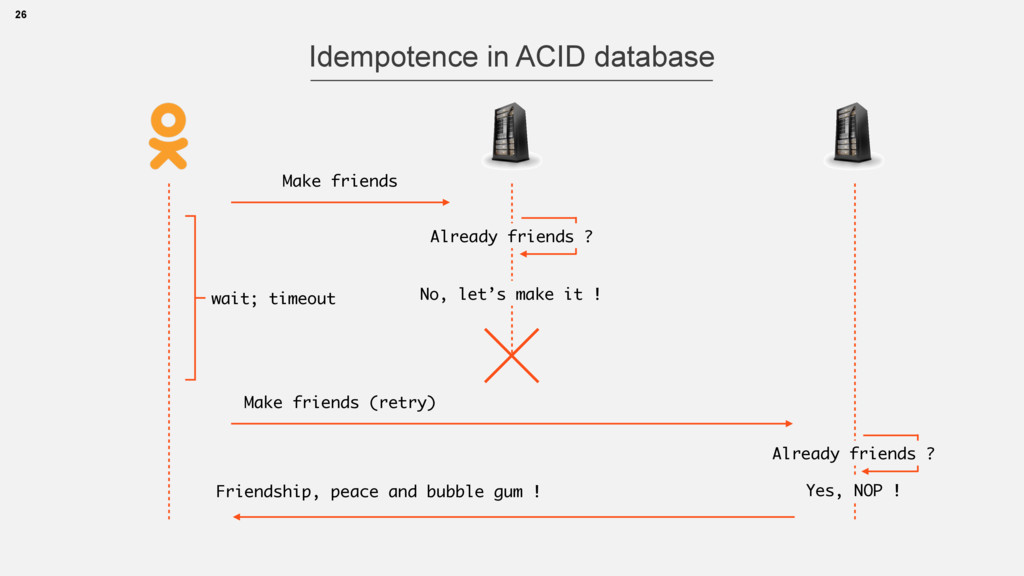{kind=link}
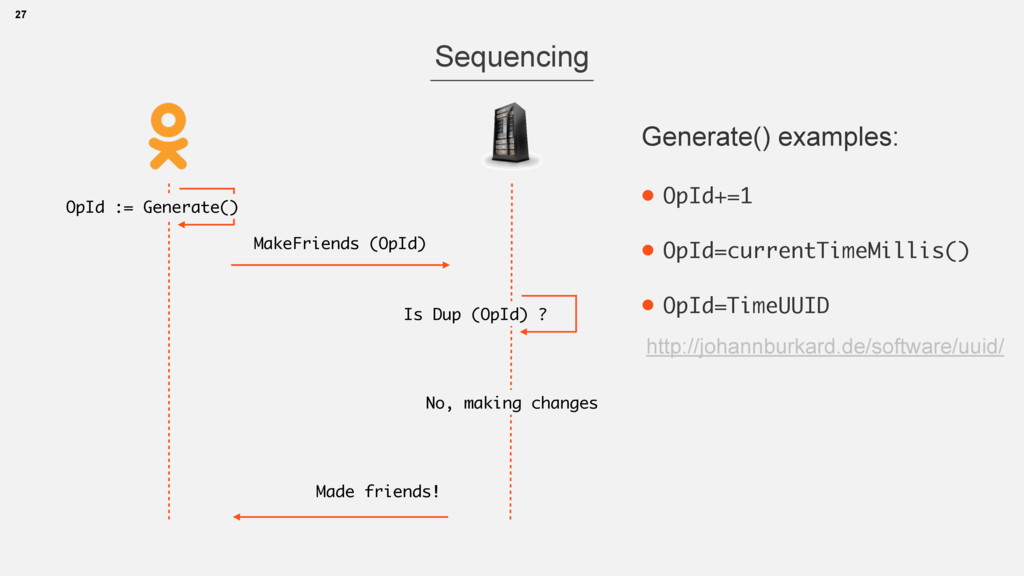{kind=link}
{kind=link}
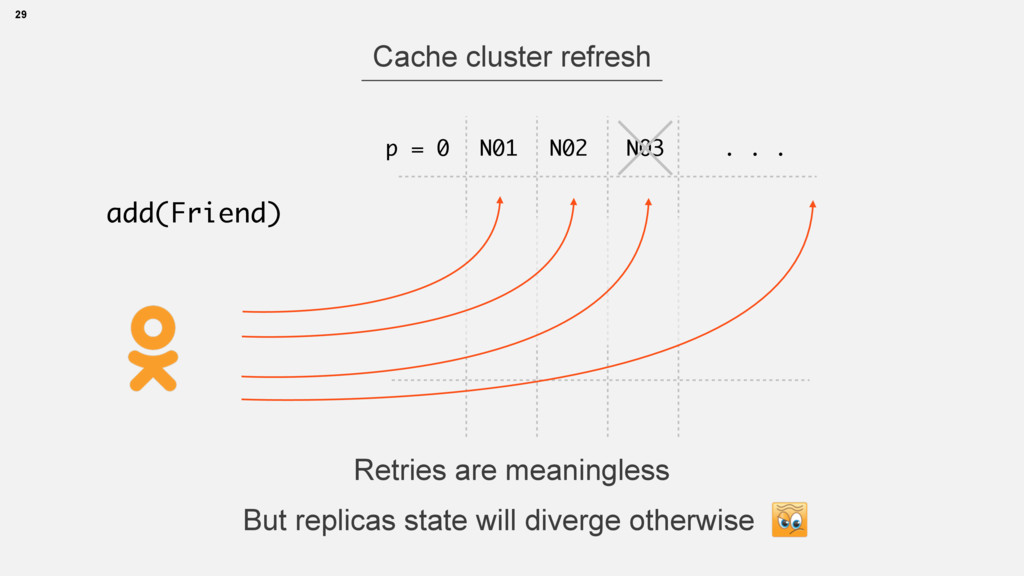{kind=link}
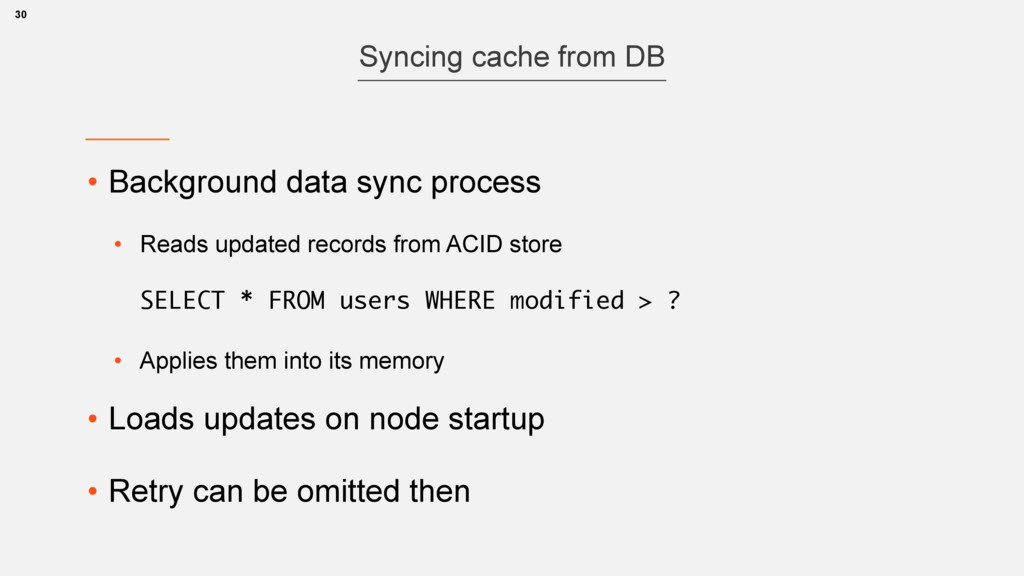{kind=link}
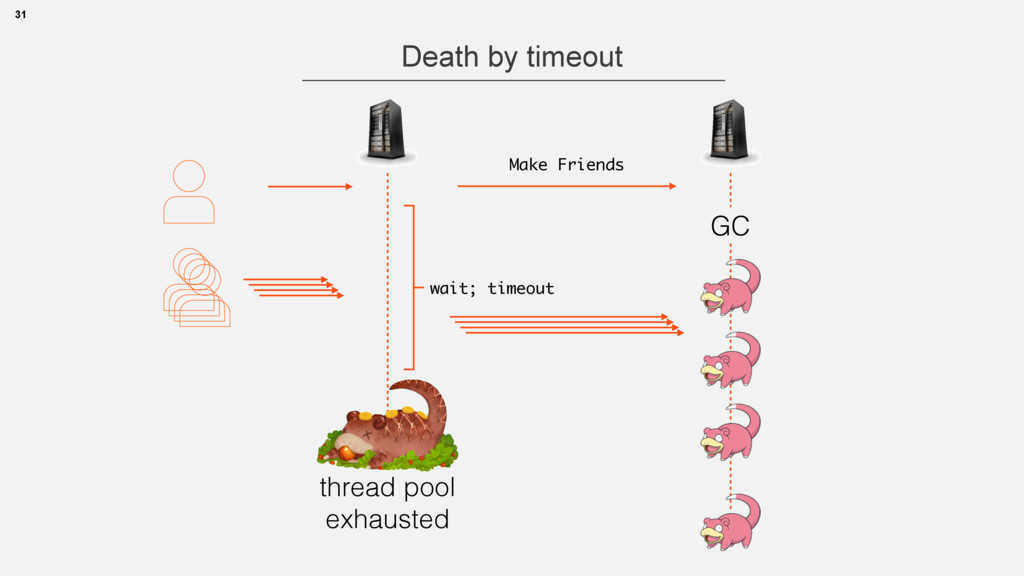{kind=link}
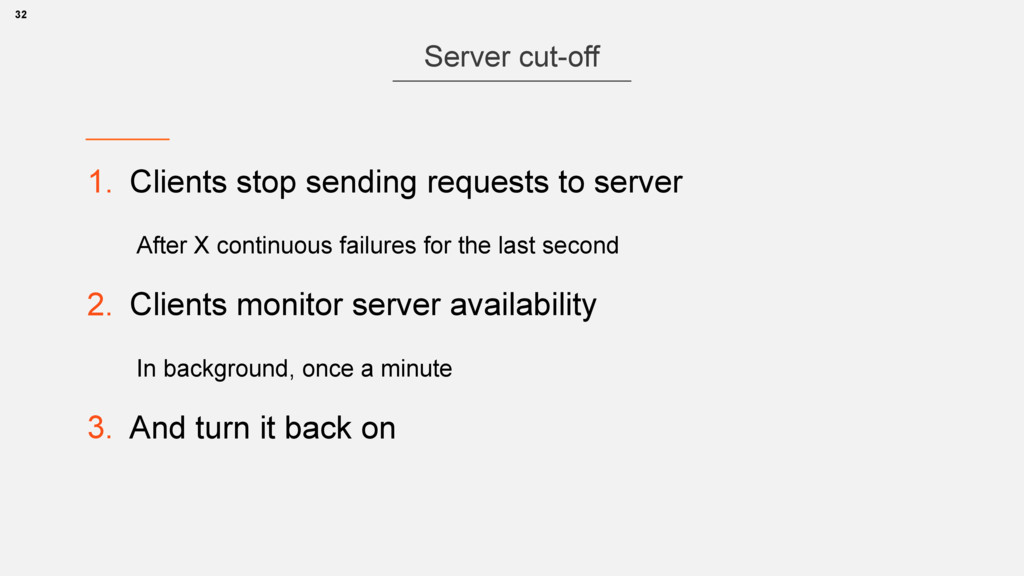{kind=link}
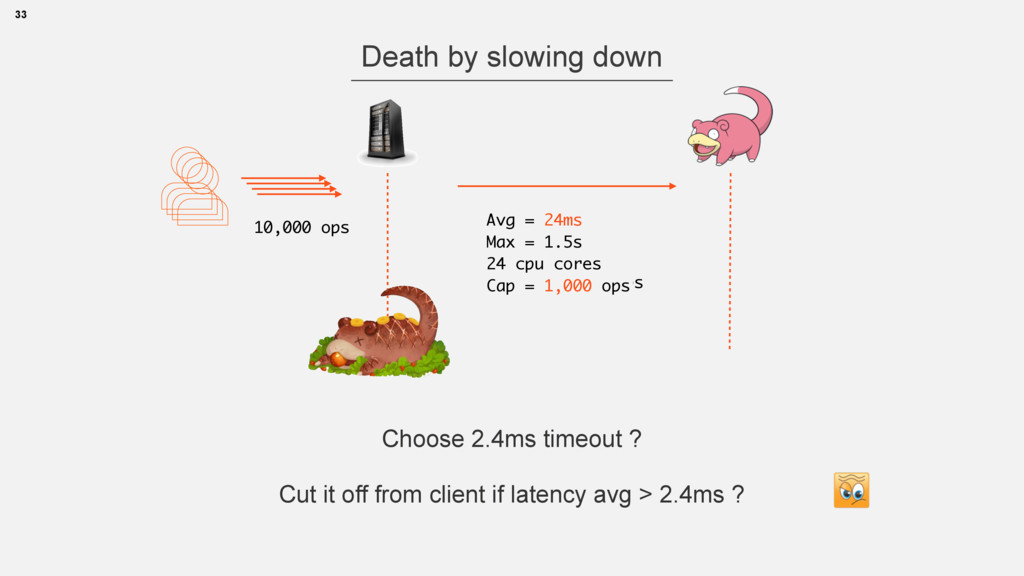{kind=link}
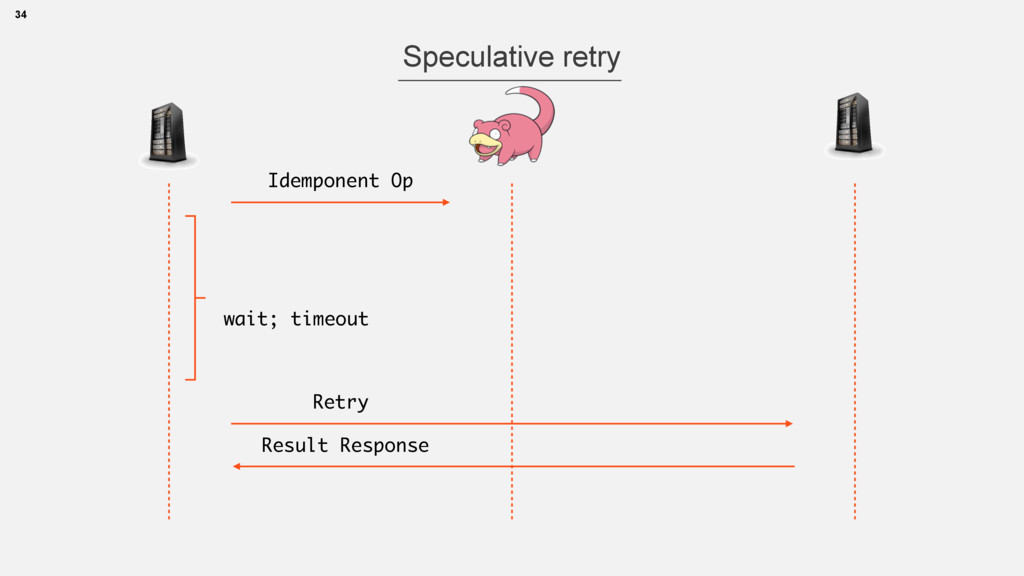{kind=link}
{kind=link}
{kind=link}
{kind=link}
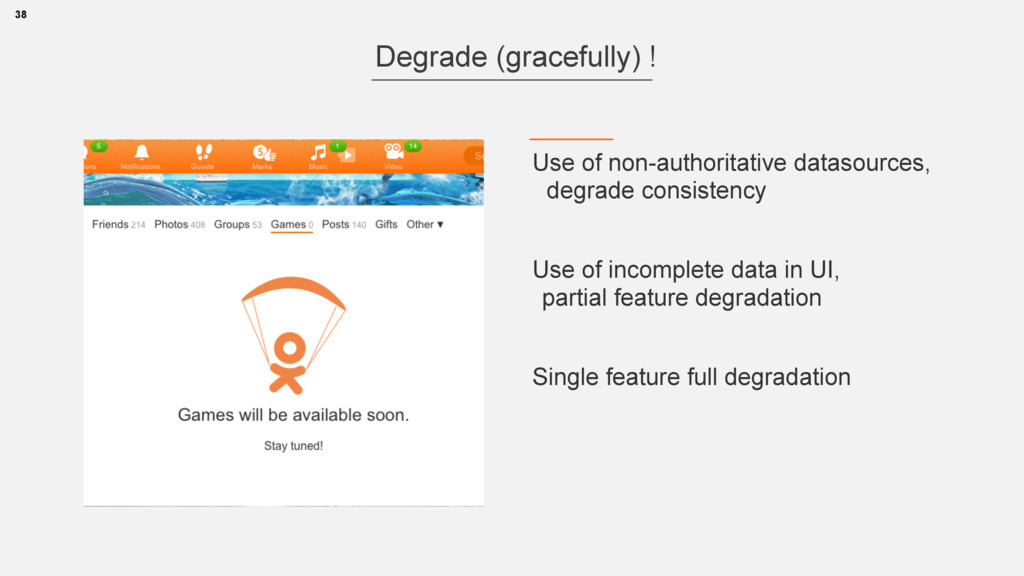{kind=link}
![39 The code interface UserCache { @RemoteMethod Distributed<Collection<User>> getUsersByIds(long[] keys);](https://files.speakerdeck.com/presentations/af297aa32f40461ba32d528507a2c654/slide_38.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
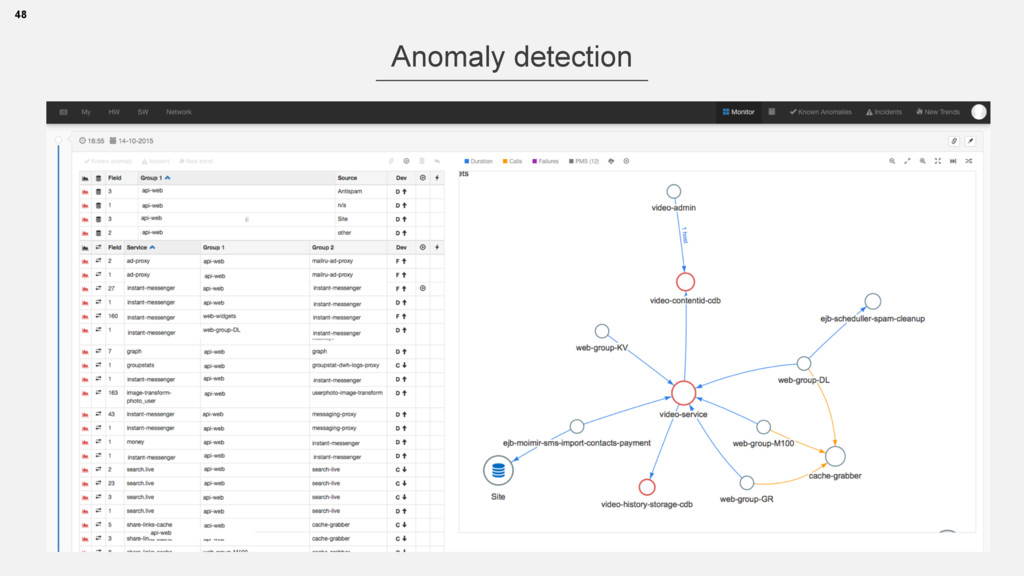{kind=link}
{kind=link}
{kind=link}